
「联合省选 2022」学术社区 Alternative solution
考场想法,然后修改了亿点+缩了个点就过了。
首先考虑有 C 性质怎么做。
考虑每句话接下来可以接哪些话,不难发现:
- 对于形如
A B loushang的话,其后只能接发出者为 B 的话 - 对于形如
A B louxia的话,其前只能接发出者为 B 的话
于是可以建图,第
于是就有个网络流思路了:
- 考虑将第
- 设发出者为
- 如果形如
A B loushang,再连接 - 如果形如
A B louxia,再连接
- 设发出者为
不难发现,这是一个类似二分图匹配的东西(只是优化了一下连边),当
直接跑网络流,可以发现第一问的答案均正确,接下来考虑如何构造方案。
首先不难通过残量网络的情况来推出每个点匹配了哪个点,进而可以知道每句话的下一句话是哪句话,于是可以把每句话向其下一句话连边。
然而,这显然可能不合法,原因是可能有环,可能出现
不过,这样得到的图显然由若干条链+若干个环组成,并且环上的点的类型均相同(都是楼上型或都是楼下型)。
考虑将环拆开,由于题目中保证每个人至少都有一条学术型消息,所以可以把环接到学术性消息去,以楼上型的环为例,如图:
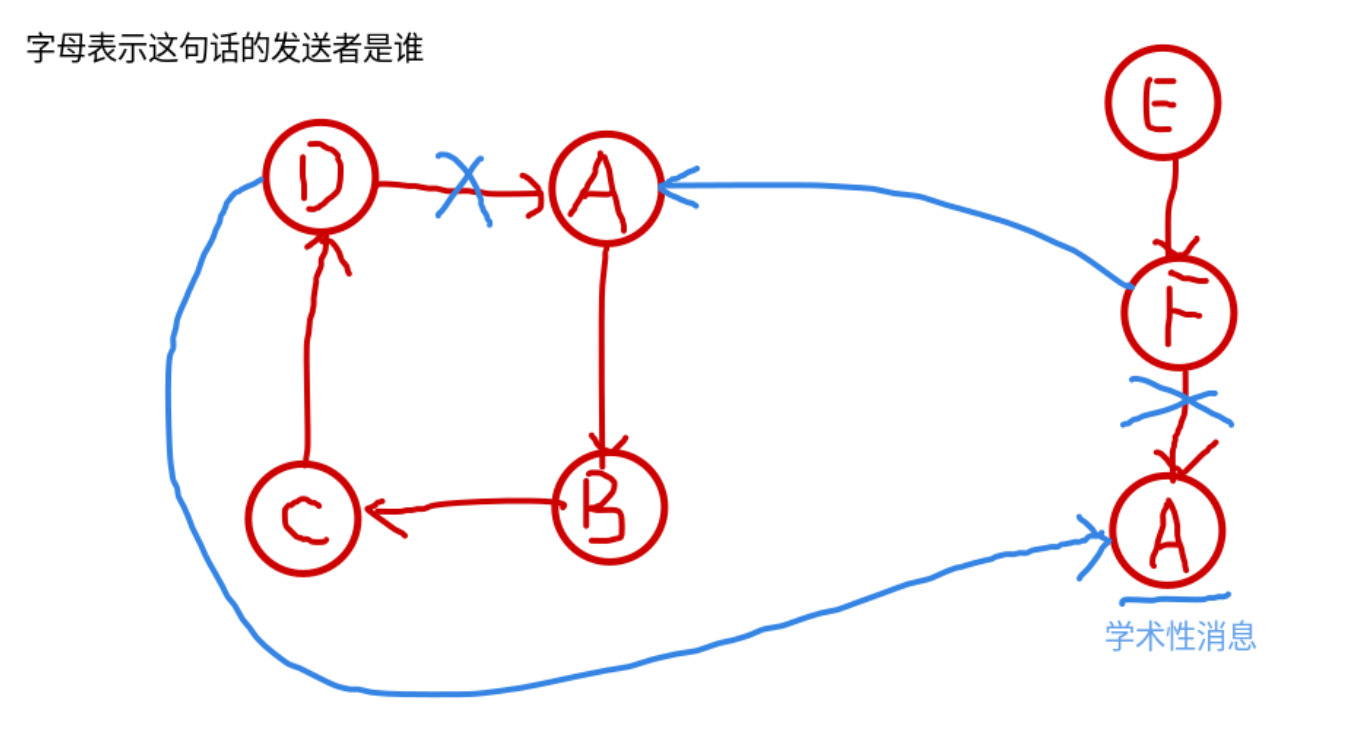
这样就可以把环接到学术性消息去,可以方便地用双向链表维护。楼下型的环同理。
最后没有环了,输出每条链即可。
至于没有 C 性质,不难发现把这样的两句话缩起来一定不劣,然后就变成类似学术的东西了(但不完全是学术),具体看代码吧。
不过还有一些奇技淫巧:直接跑网络流跑不过,那就把所有话的类型反过来,最后输出时再倒序。(代码这么长是格式化了...)
#include <bits/stdc++.h>
using namespace std;
using pii = pair<int, int>;
using vi = vector<int>;
using ll = long long;
template <typename T> T read() {
T x = 0, f = 0;
char ch = getchar();
while (!isdigit(ch))
f |= (ch == '-'), ch = getchar();
while (isdigit(ch))
x = x * 10 + (ch - '0'), ch = getchar();
return f ? -x : x;
}
#define rdi read<int>
#define rdll read<ll>
#define fi first
#define se second
#define mp make_pair
#define pb push_back
const int N = 240010;
const int INF = 0x3f3f3f3f;
map<string, int> nam;
int n, m;
struct Edge {
int to, nxt, f;
} e[N * 10];
int head[N * 4], tot = 1;
void addedge(int x, int y, int f) {
e[++tot] = {y, head[x], f};
head[x] = tot;
e[++tot] = {x, head[y], 0};
head[y] = tot;
}
struct Mes {
int fr, to, typ;
ll id;
} me[N];
bool operator<(const Mes &a, const Mes &b) {
return make_tuple(a.typ, a.fr, a.to) < make_tuple(b.typ, b.fr, b.to);
}
inline int idd(int x, int typ) {
return 2 * m + x * 2 - 1 + typ;
}
namespace MF {
int dep[N * 4];
bool bfs(int S, int T) {
memset(dep, 0, sizeof(int) * (T + 2));
queue<int> q;
q.push(S), dep[S] = 1;
while (!q.empty()) {
int x = q.front();
q.pop();
if (x == T)
return true;
for (int i = head[x]; i; i = e[i].nxt) {
int y = e[i].to;
if (e[i].f && !dep[y]) {
dep[y] = dep[x] + 1;
q.push(y);
}
}
}
return false;
}
int dfs(int x, int fl, int T) {
if (x == T)
return fl;
int rest = fl;
for (int i = head[x]; i; i = e[i].nxt) {
int y = e[i].to;
if (e[i].f && dep[y] == dep[x] + 1) {
int tmp = dfs(y, min(fl, e[i].f), T);
if (tmp < min(fl, e[i].f))
dep[y] = 0;
e[i].f -= tmp, e[i ^ 1].f += tmp, rest -= tmp;
if (!rest)
break;
}
}
return fl - rest;
}
int mf(int S, int T) {
int sum = 0;
while (bfs(S, T))
sum += dfs(S, INF, T);
return sum;
}
} // namespace MF
int S, T, ans, m1;
void build() {
// find parallel edges
m1 = m;
multiset<Mes> s;
for (int i = 1; i <= m; i++)
s.insert(me[i]);
while (!s.empty()) {
auto tmp = *s.begin();
s.erase(s.begin());
if (tmp.typ != 1)
continue;
auto it = s.find({tmp.to, tmp.fr, 2, 0});
if (it != s.end()) {
//删除不满足性质 C 的两句话,加入新点
me[tmp.id].typ = me[it->id].typ = -1, ans += 2;
me[++m] = {tmp.fr, tmp.to, 3, (tmp.id << 20) | it->id};
s.erase(it);
}
}
S = 2 * m + 2 * n + 1, T = 2 * m + 2 * n + 2;
for (int i = 1; i <= m; i++) {
if (me[i].typ == -1)
continue;
int x = me[i].fr, y = me[i].to;
addedge(S, i, 1);
addedge(i + m, T, 1);
if (me[i].typ < 3) {
addedge(i, idd(x, 0), 1);
addedge(idd(x, 1), i + m, 1);
if (me[i].typ == 1)
addedge(i, idd(y, 1), 1);
else if (me[i].typ == 2)
addedge(idd(y, 0), i + m, 1);
} else if (me[i].typ == 3) {
//如果是两句话缩起来的点,则建图有点区别,不过应该好理解
addedge(idd(x, 1), i + m, 1);
addedge(i, idd(y, 0), 1);
}
}
}
vi s1[N * 2], s2[N * 2];
int nxt[N], seq[N], pos;
int pre[N], id[N];
void construct() {
//寻找每句话的下一句话(即 out_i 匹配了谁)
for (int x = 1; x <= n; x++) {
for (int i = head[idd(x, 0)]; i; i = e[i].nxt) {
if (i & 1)
continue;
if (!e[i].f)
s2[idd(x, 0)].pb(e[i].to - m);
}
for (int i = head[idd(x, 1)]; i; i = e[i].nxt) {
if (i & 1)
continue;
if (!e[i].f)
s2[idd(x, 1)].pb(e[i].to - m);
}
}
for (int x = 1; x <= m; x++) {
for (int i = head[x]; i; i = e[i].nxt) {
if (i & 1)
continue;
if (!e[i].f)
s1[e[i].to].pb(x);
}
}
//nxt_i 即为第 i 句话的下一句话
for (int x = 1; x <= n; x++) {
for (int j = 0; j <= 1; j++) {
int now = idd(x, j);
for (auto x : s1[now])
nxt[x] = s2[now].back(), s2[now].pop_back();
}
}
static int vis[N];
static vi s[N];
auto doit = [&](int typ) {
vector<vi> lp;
vi st;
for (int i = 0; i <= m; i++)
vis[i] = 0;
for (int i = 0; i <= n; i++)
s[i].clear();
for (int x = 1; x <= m; x++)
vis[nxt[x]] = 1;
for (int x = 1; x <= m; x++)
if (!vis[x])
st.pb(x);
for (int x = 1; x <= m; x++)
vis[x] = 0;
//先把链给去掉
for (auto x : st) {
int now = x;
while (now)
vis[now] = 1, now = nxt[now];
}
// 找环
for (int x = 1; x <= m; x++)
if (!vis[x]) {
int now = x;
if (me[now].typ == typ)
lp.pb({});
while (!vis[now]) {
vis[now] = 1;
if (me[now].typ == typ)
lp.back().pb(now);
now = nxt[now];
}
}
//id_i 表示发送者为 i 的学术消息的编号
for (int i = 1; i <= m; i++) {
if (nxt[i])
pre[nxt[i]] = i;
if (!me[i].typ)
id[me[i].fr] = i;
else if (me[i].typ == 3)
id[typ == 1 ? me[i].fr : me[i].to] = i;
}
auto link = [&](int x, int y) {
nxt[x] = y, pre[y] = x;
};
if (typ == 1) {
for (auto &tmp : lp) {
int fr = me[tmp[0]].to;
int x1 = tmp[0], y1 = nxt[tmp[0]], x2 = pre[id[fr]],
y2 = id[fr];
link(x1, y2), link(x2, y1);
}
} else {
for (auto &tmp : lp) {
int fr = me[tmp[0]].fr;
int x1 = tmp[0], y1 = nxt[tmp[0]], x2 = id[fr],
y2 = nxt[id[fr]];
link(x1, y2), link(x2, y1);
}
}
};
doit(1);
doit(2);
vi st;
for (int i = 0; i <= m; i++)
vis[i] = 0;
for (int x = 1; x <= m; x++)
vis[nxt[x]] = 1;
for (int x = 1; x <= m; x++)
if (!vis[x])
st.pb(x);
for (int i = 1; i <= m; i++)
vis[i] = 0;
for (auto x : st) {
if (me[x].typ == -1)
continue;
while (x)
seq[++pos] = x, x = nxt[x];
}
reverse(seq + 1, seq + pos + 1);
}
void clear() {
memset(head, 0, sizeof(int) * (T + 2));
tot = 1;
nam.clear();
pos = ans = 0;
for (int i = 0; i <= m; i++)
nxt[i] = pre[i] = id[i] = 0;
for (int i = 1; i <= n; i++)
for (int j : {0, 1})
s1[idd(i, j)].clear(), s2[idd(i, j)].clear();
}
void solve() {
cin >> n >> m;
for (int i = 1; i <= n; i++) {
string s;
cin >> s;
nam[s] = i;
}
for (int i = 1; i <= m; i++) {
string s1, s2, s3;
cin >> s1 >> s2 >> s3;
int fr = nam[s1], to = 0, typ = 0;
map<string, int>::iterator it;
//注意:这里 loushang louxia 反过来了,原因见题解
if (s3 == "louxia" && (it = nam.find(s2)) != nam.end())
typ = 1, to = it->se;
else if (s3 == "loushang" && (it = nam.find(s2)) != nam.end())
typ = 2, to = it->se;
else
typ = 0;
me[i] = {fr, to, typ, i};
}
build();
ans += MF::mf(S, T);
construct();
cout << ans << '\n';
for (int i = 1; i <= pos; i++) {
int x = seq[i];
if (me[x].typ <= 2)
cout << seq[i] << ' ';
else
//如果是两句话缩起来的,则输出两个
cout << (me[x].id & ((1 << 20) - 1)) << ' ' << (me[x].id >> 20)
<< ' ';
}
cout << '\n';
clear();
}
int main() {
freopen("community.in", "r", stdin);
freopen("community.out", "w", stdout);
ios::sync_with_stdio(false);
int T;
cin >> T;
while (T--)
solve();
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】