20201220蔡笃俊《信息安全系统设计与实现》第九章学习笔记
一、任务内容
- 自学教材第九章,提交学习笔记(10分)
本章是复习C语言中的文件操作内容,结构化从文本文件操作,二进制文件操作两个大内容考虑,以前可能只关注文本文件的操作,我们以后更多的是操作二进制文件。 文本文件中考虑字符读写,行读写,任意位置读写等 文件操作都有什么? 二进制文件和文本文件如何转换? 数据结构如何读写? ... - 知识点归纳以及自己最有收获的内容 (3分)
- 问题与解决思路(2分)
- 实践内容与截图,代码链接(3分)
- ...(知识的结构化,知识的完整性等,提交markdown文档,使用openeuler系统等)(2分)
二、知识点归纳以及自己最有收获的内容
1.文件操作都有什么?
文件操作有:
| - | 标准I/O | 文件I/O |
|---|---|---|
| 打开/创建 | fopen | open |
| 读 | getc,fgetc,getchar,fgets,gets,fread | read |
| 写 | putc,fputc,putc,fputs,puts,fwrite | write |
| 关闭 | fclose | close |
IO 指的是输入输出函数。
站在计算机的角度,输入是读操作,输出是写操作。
例如:我们从终端输入信息给计算机,计算机是从终端读取信息,而我们让计算机输出信息时,计算机是要向终端写信息。
而其中,IO又可以分为文件IO和标准IO
- 文件IO属于系统调用
- 标准IO属于库函数
那么,系统调用和库函数有什么区别?这点我们在稍后讨论。
2. 二进制文件和文本文件如何转换?
在这之前,我们首先要了解它们的定义:
从C语言的角度来看,所有的文件都可简单的分为两类:一类是文本文件,另外一类是二进制文件。
文本文件
- 所谓的文本文件,就是按照字符的编码规则(比如ASCII),1:1的根据你敲的字符形成的机器码文件。后缀习惯是以.txt结尾。一个典型的文本编辑器就是大家熟悉的记事本程序(notepad.exe)。
- 举个例子,一个标准的ASCII文本文件,就是按照ASCII表的编码规则来进行1:1转换的。当然如果你是按照unicode编码,所有的字符按照两个字节代表一个字符的方式进行编码。在解析Unicode编码的文本文件时,就要按照两个字节为一个字符的方式进行二进制到文本的转换,这样才能正确解析。
二进制文件
- 二进制文件是可以认为是所有非文本文件都称之为二进制文件。
- 要打开二进制文件,需要有形成这类文件的程序的内置的解析器,才能解读。这也解释了为什么不同的文件比如pdf,docx等文件,在编程的时候,必须要有相应的文档解析类函数来完成的原因了。
- 当然我们完全可以用二进制方式打开任何一个文本文件,因为底层上就是那些代码,我们只需要读取每一个字节,查找转化成相应字符予以显示就可以了,前提是我们要知道ASCII表的规则。
说白了,文本文件实际上是经过编码的,也就是规范了的二进制文件。它们之间如何转换其实非常好理解。我们用这个文件对应的编码方式先正确读出内容,再以我们想要输出的文件对应的编码方式输出就可以了。二进制其实和我们一般说的ASCLL中的FF,0F是一样的,只不过二进制符合的不是ASCLL的这套显示或者作用标准,它采用的是计算机CPU的处理标准。比如\x41在ASCLL中表示的是A,而到了计算机CPU那里他可能是另一个意思。
所以文本可以显示,而二进制却不能,是因为文本文件是通过文本文件查看器去重新给文本文件进行处理然后显示的,并不是我们想当然的“直接打开”就能看见,而二进制进行运行,则是不通过其他软件的,直接丢给CPU的。
如何转换?
-
首先用vim以二进制格式打开需要编辑或查看的文件:
vim -b xxx.dat -
然后用xxd把文件转换成十六进制格式:
:%!xxd -
接着我们只需像对待普通文本一样查看和编辑二进制文件,修改完成使用xxd把十六进制转换回二进制:
:%!xxd -r -
然后我们需要把二进制文件转化成其他文本文件搜索ASCII字符,先使用iconv命令(IGNORE忽略那些翻译不了的):
iconv -f GB2312 -t UTF-8//IGNORE {} -o $filename.text -
最后我们使用grep 对 *.text 进行搜索想要查找的ASCII字符;
3. 数据结构如何读写?
1. 读操作
Read()将n个字节从打开的文件描述符读入用户空间中的buf[]。返回值是实际读取的字节数,如果read()失败,会返回-1,例如当fd无效时。注意,buf[]区必须有足够的空间来接收n个字节,并且返回值可能小于n个字节,例如文件小于n个字节,或者文件无更多需要读取的数据。还要注意,返回值是一个整数,而不是文件结束(EOF)符,因为文件中没有文件结束符。文件结束符是I/O库函数在文件流无更多数据时返回的一个特殊整数值(-1)。
#include<unistd.h>
int read(int fd,void *buf,int nbytes);
2. 写操作
write()将n个字节从用户空间中的buf[]写入文件描述符,必须打开该文件描述符进行 写、读写或追加。返回值是实际写入的字节数,通常等于n个字节,如果write()失败,则为-1,例如由于出现无效的fd或打开fd用于只读等。
#include<unistd.h>
Int write(int fd,void *buf,int nbytes);
3. 数据结构的读写示例
使用open()、read()、Iseek()、write()和close()系统调用,将文件的第一个1KB字节复制到2048字节。
char buf[1024];
int fd=open("file",O_RDWR); // open file for READ-WRITE
read(fd, buf[ ],1024); // read first 1KB into buf[ ]
lseek(fd, 2048, SEEK_SET); // lseek to byte 2048
write(fd, buf,1024); // write 1024 bytes
close(fd); // close fd
4. 教材知识点归纳与收获
第九章的主要内容是Linux操作系统中的I/O库函数,前面我也简略提到过。对于I/O库函数的介绍,分别为以下几个方面:
- I/O库函数的作用及其相对于系统调用的优势
- I/O库函数和系统调用之间的相同点和不同点
- I/O库函数的算法
- I/O库函数的不同模式
- 文件流缓冲方案
1.知识点归纳:I/O库函数的作用及其相对于系统调用的优势
Linux下对文件操作有两种方式:系统调用system call和库函数调用Library functions。系统调用只支持数据块的读写,而I/O库函数可以指出更多逻辑单元的读写,例如行、字符、结构化记录等。系统调用实际上就是指最底层的一个调用,在linux程序设计里面就是底层调用的意思面向的是硬件。而库函数调用则面向的是应用开发的,相当于应用程序的api,采用这样的方式有很多种原因,第一:双缓冲技术的实现。第二,可移植性。第三,底层调用本身的一些性能方面的缺陷。第四:让api也可以有了级别和专门的工作面向。
前面也提到过,文件IO属于系统调用,标准IO属于库函数,I/O库函数的根都在对应的系统调用函数中。首先我们来看系统调用:
1. 系统调用
系统调用提供的函数如open, close, read, write, ioctl等,通常用于底层文件访问(low-level file access),例如在驱动程序中对设备文件的直接访问。它是操作系统相关的,因此一般没有跨操作系统的可移植性。
附上系统调用函数:
open():用来打开或创建一个文件,若成功返回文件描述符,否则返回-1。
read() :逐个字节或者字符读取文件中的内容;
write() :把参数buf 所指的内存写入count 个字节到参数fd 所指的文件内。如果顺利write()会返回实际写入的字节数。当有错误发生时则返回-1,错误代码存入erro 中。
lseek() :每一个已打开的文件都有一个读写位置,当read()或write()时, 读写位置会随之改变,lseek函数是用来控制该文件的读写位置。
close():用于关闭由open函数所打开的文件。
再来看看库函数调用:
2. 标准IO库函数调用
标准IO库函数提供的文件操作函数如fopen, fread, fwrite, fclose, fflush, fseek等,通常用于应用程序中对一般文件的访问,是系统无关的,因此可移植性好。由于库函数调用是基于C库的,因此也就不可能直接用于内核空间的驱动程序中对设备的操作。
fopen():用于打开文件,第一个形式参数表示文件名,可以包含路径和文件名两部分。其调用格式为:FILE *fopen(char *xxx, *type)。
fread():用于从文件流中读取数据。
fwrite():写入文件(可安全用于二进制文件)返回写入的字符数,出现错误时则返回 false。
fseek():用于重定位流上的文件指针,成功则返回0,否则返回其他值。
fclose():用来关闭一个由fopen()函数打开的文件,其调用格式为int fclose(FILE *stream)。该函数返回一个整型数。当文件关闭成功时,返回0,否则返回一个非零值。可以根据函数的返回值判断文件是否关闭成功。
显而易见的,系统调用发生在内核空间,因此如果在用户空间的一般应用程序中使用系统调用来进行文件操作,会有用户空间到内核空间切换的开销。事实上,即使在用户空间使用库函数来对文件进行操作,因为文件总是存在于存储介质上,因此不管是读写操作,都是对硬件(存储器)的操作,都必然会引起系统调用。也就是说,库函数对文件的操作实际上是通过系统调用来实现的。例如C库函数fwrite()就是通过write()系统调用来实现的。使用系统调用,只需要一次复制,就可以完成任务,而I/O库函数需要两次复制,即从内核到内部缓冲区再到程序缓冲区。
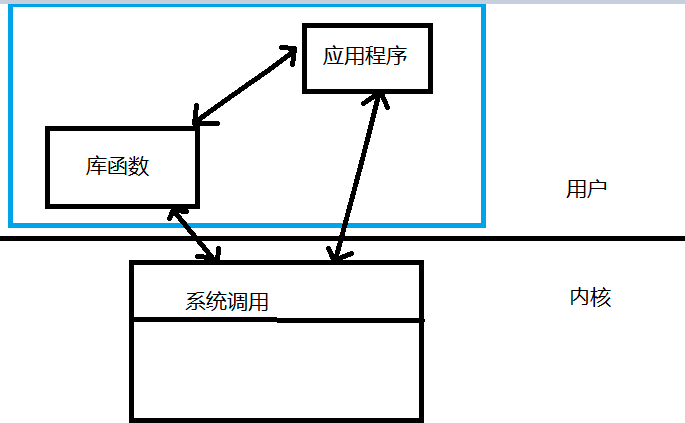
虽然系统调用的复制次数更少,但只适用于以数据块大小为单位的请求中,因为系统调用只支持数据块的读写。而I/O库函数可以适用于其他逻辑单元,如行、字符等。
3. I/O库函数算法
书中详细讲述了I/O库函数的算法:
fread算法:
- 第一次调用时,fread()使用保存的文件扫描符fd发出 n=read(fd, fbuffer, BLKSIZE);
- 系统调用,用数据块填充内部的fbuff[];
- 初始化fbuff[]指针、计数器和状态变量;
- 将数据复制到程序缓冲区;
- 若内部缓冲没有足够的数据,则使用read()继续填充内部缓冲区,并将数据从内部缓冲区复制到程序缓冲区;
- 复制完之后,更新内部缓冲区的指针、计数器,为下次read()做准备
fwrite算法:
- 将数据写入内部缓冲区,调整缓冲区指针、计数器和状态变量;
- 若缓冲区满,则调用write()将缓冲区写入系统内核。
fclose算法:
- 关闭文件流局部缓冲区;
- 发出close(fd)系统调用关闭file结构体文件描述符;
- 释放file结构体,并将file指针重置为null。
关于算法的更多学习可以参考这篇博客https://blog.csdn.net/xiaxiaoyule/article/details/44050507
其中,I/O库函数中有不同的模式,书中着重介绍了三种I/O库函数模式,分别是:字符模式I/O、行模式I/O库函数和格式化I/O库函数,下面进行归纳:
4. 标准I/O库函数调用
- 字符模式I/O
int fgetc(FILE *fp):
int ungetc(int c ,FILE *fp);
int fputc(int c,FILE *fp);
fgetc()返回的是整数,而不是字符,因为他必须在文件结束时返回文件结束符。文件结束符通常是-1,将他与文件流中的任何字符分开。
- 行模式I/O
char *fgets(char *buf,int size,FILE *fp):从fp中读取最多为一行(以\n结尾)的字符。
int fputs(char *buf,FILE *fp):将buf中的一行写入fp中。
- 格式化I/O
格式化输入:
scanf(char *FMT ,&items);
fscanf(fp,char *FMT ,&items);
格式化输出:
printf(char *FMT,items);
fprintf(fp,char *FMT,items);
- 内存中的转换函数
sscanf(buf ,FMT,&items);
sprintf(buf ,FMT, items);
2.收获
这一章主要是讲述了文件流的操作,在上学期的计算机实习和Java选修中,我们也大量学习并使用了文件流的操作,尤其是在Java中各种I/O操作层出不穷,所以在接触到这一部分并不是很难。最大的收获就是对于系统调用和库函数调用的学习,之前只是有了文件流的概念,却没有系统的深入学习,这一章让我们更加了解了c语言中的I/O操作。库函数是语言或应用程序的一部分,可以运行在用户空间中。而系统调用是操作系统的一部分,是内核提供给用户的程序接口,运行在内核空间中,而且许多的库函数都会使用系统调用实现功能,如在linux下C中的fopen、fclose、fwrite等文件操作函数其底层就是通过open、close、write等系统调用是实现的。没有使用系统调用的库函数,执行效率通常比系统调用高。因为使用系统调用时,需要通过中断进行上下文的切换以及由用户态向内核态的转移。
三、问题与解决思路
在对第九章的学习中,fopen并没有过多的解释,有些地方模模糊糊的,故查阅资料解决补充:
C 库函数 FILE *fopen(const char *filename, const char *mode) 使用给定的模式 mode 打开 filename 所指向的文件。
其中参数
filename -- 字符串,表示要打开的文件名称。
mode -- 字符串,表示文件的访问模式,可以是以下的值:
“r”:打开一个用于读取的文件。该文件必须存在。
“w”:创建一个用于写入的空文件。如果文件名称与已存在的文件相同,则会删除已有文件的内容,文件被视为一个新的空文件。
“a”:追加到一个文件。写操作向文件末尾追加数据。如果文件不存在,则创建文件。
“r+”:打开一个用于更新的文件,可读取也可写入。该文件必须存在。
“w+”:创建一个用于读写的空文件。
“a+”:打开一个用于读取和追加的文件。
还有个问题:即使我们使用库函数也会有系统调用的开销,那为什么不直接使用系统调用呢?这样不是更省事?
解决思路:这是因为,文件的读写操作通常是大量的数据(大量是底层实现而言),这时,使用库函数可以大大减少系统调用的次数。这一结果源于缓冲区技术,在内核空间和用户空间,对文件操作都使用了缓冲区,例如用fwrite()写文件,都是先将内容写到用户空间缓冲区,当用户空间缓冲去写满或者写操作结束时,才将用户缓冲区的内容写到内核缓冲区,同样的道理,当内核缓冲区写满或者写结束时才将内核缓冲区的内容写到文件对应的硬件媒介上。
参考:https://blog.csdn.net/leikun153/article/details/82385249
四、实践内容与代码链接
#include <stdio.h>
int main ()
{
FILE * pFile;
pFile = fopen ( "example.txt" , "wb" );
fputs ( "This is an apple." , pFile );
fseek ( pFile , 9 , SEEK_SET );
fputs ( " exam" , pFile );
fclose ( pFile );
return 0; }
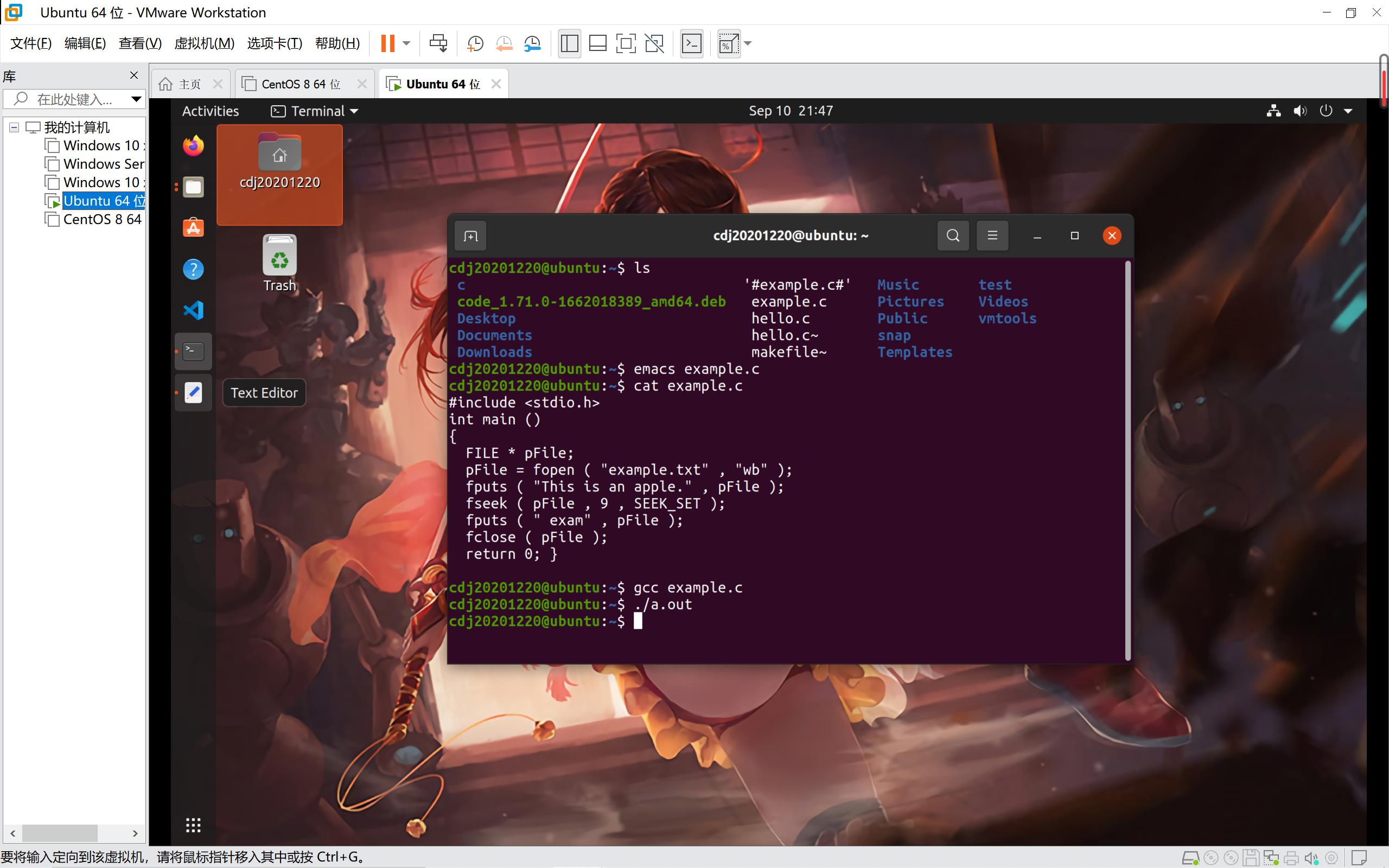
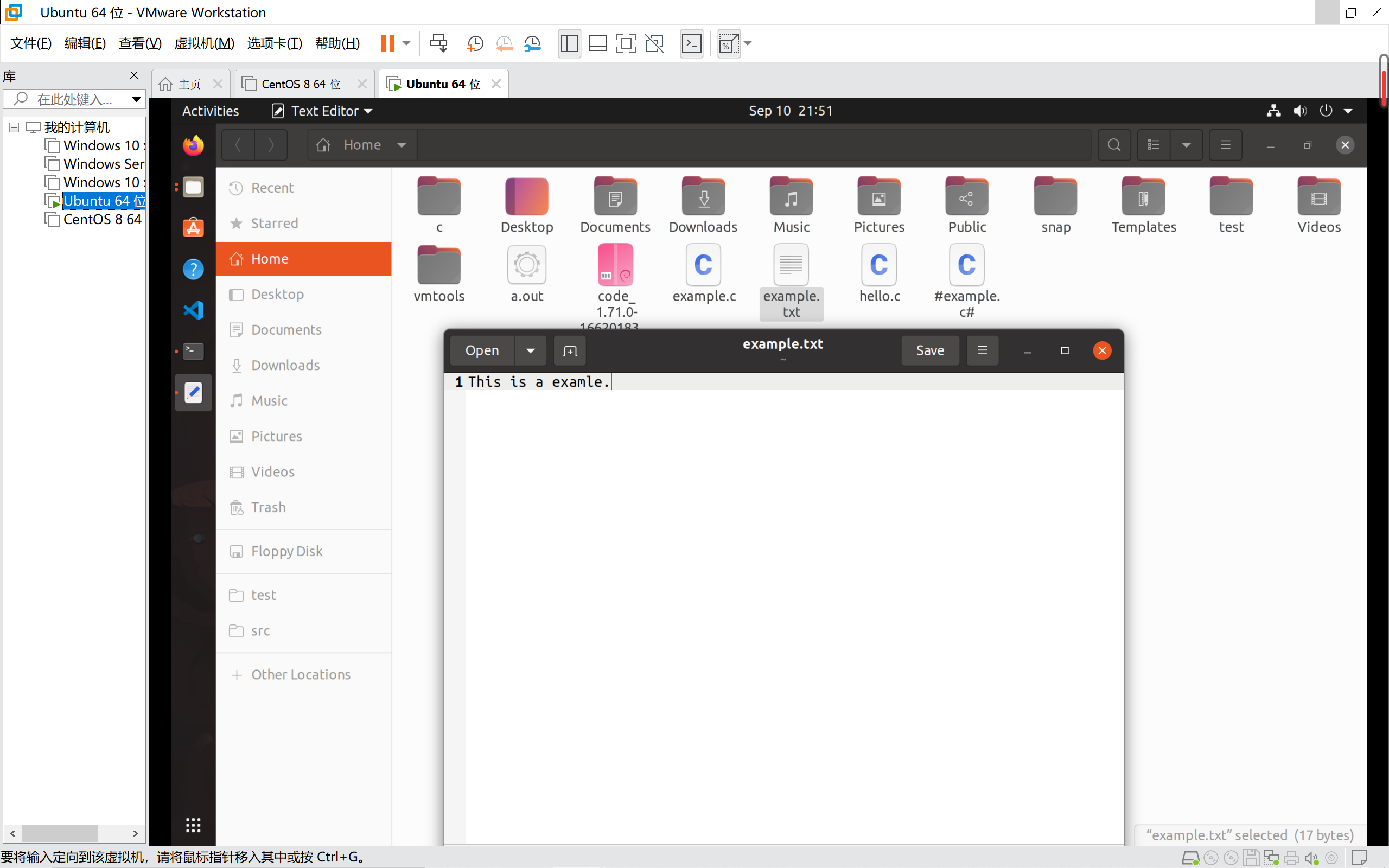
为什么最后在记事本中打印出的结果是This is a example.呢?
原因是在第一次fputs中是把This is an apple.先放入记事本当中,当调用fseek函数时,从当前的文件指针处向后偏移9个字节,文件指针一开始默认指向的是文件的首地址处。因此向后偏移9个字节后(偏移一个字节包括空格)指向的是最后一个空格的地址处。而第二次fputs函数是将“ exam”这个内容在上次文件指针指向的地址处开始写入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号