用深度优先搜索(DFS)解决多数图论问题
前言
本文大概是作者对图论大部分内容的分析和总结吧,\(\text{OI}\)和语文能力有限,且部分说明和推导可能有错误和不足,希望能指出。
创作本文是为了提供彼此学习交流的机会,也算是作者在忙碌的中考后对此部分的复习和延伸吧。
本文顾名思义是探讨\(\text{DFS}\)在图论中的重要作用,可能心情比较好会丢个链接作拓展,下面就步入正文。
目录
1 基础篇
\(1.1\) 图的定义和深度优先搜索
\(1.2\) 图的连通分量和二分图染色
2 进阶篇
\(2.1\) 割顶和桥
\(2.2\) 无向图的双连通分量(\(\text{BCC}\))和有向图的强连通分量(\(\text{SCC}\))
\(2.3\) 二分图匹配问题
关键字
深度优先搜索(\(\text{DFS}\))、图的遍历、连通分量、二分图染色、二分图匹配、割顶、桥、双连通分量、强连通分量、\(\text{Tarjan}\)、增广路。
1 基础篇
总言:这里是\(\text{PJ}\)内容,相对来说较为简单。
1.1 图的定义和深度优先搜索
这一部分比较简单,大佬可以直接跳过~
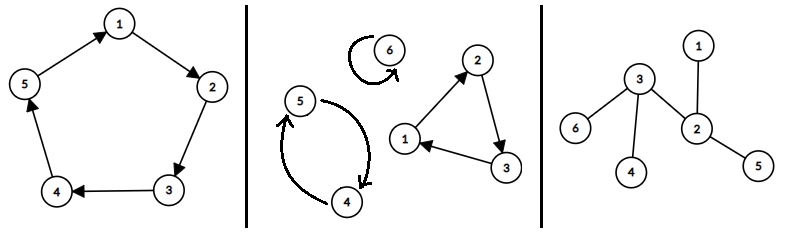
在\(\text{OI}\)中图被抽象成点和边,边连接着两个顶点,可分成无向边和有向边,所有的点和边组在一起构成一个图,记作\(G=<V,E>\),\(G\)表示图,\(V,E\)分别表示点集和边集。如下图所示,都可称作图。
图的存储主要有两种:邻接矩阵和邻接表。
邻接矩阵:就是用矩阵的行和列来记录两个结点之间是否有边相连,如果有边\(u \rightarrow v\),则\(e[u,v]=1\),否则为\(0\)。
优点:访问速度\(\text{O}(1)\)。
缺点:占用内存\(\text{O}(n^2)\)。
int e[maxn][maxn]; // 邻接矩阵
void add(int u, int v) { // 添加新边
e[u][v] = e[v][u] = 1; // 无向图
e[u][v] = 1; // 有向图
}
例如中间的图,邻接矩阵即为$$\begin{bmatrix} \text{u\v} & V1 & V2 & V3 & V4 & V5 & V6 \ V1 & 0 & 1 & 0 & 0 & 0 & 0 \ V2 & 0 & 0 & 1 & 0 & 0 & 0 \ V3 & 1 & 0 & 0 & 0 & 0 & 0 \ V4 & 0 & 0 & 0 & 0 & 1 & 0 \ V5 & 0 & 0 & 0 & 1 & 0 & 0 \ V6 & 0 & 0 & 0 & 0 & 0 & 1 \end{bmatrix}$$ 邻接矩阵:就是通过链表的形式将与当前结点有关联的结点连起来。
优点:所需内存大小只与边的多少有关。
缺点:随机访问某条边的速度较慢。不过如果按顺序遍历目标结点速度很快。
// 实现1 : STL
vector<int> e[maxn];
void add(int u, int v) {
e[u].push_back(v);
e[v].push_back(u); // 无向图时使用
}
// 实现2 : 前向星
struct Edge {
int u, v, pre; // e[i]表示第i+1条边,pre表示链接,若为-1则说明已经指向表头
} e[maxn * maxn];
int G[maxn], m; // G[i]表示所构成的i结点有关的结点构成的链的最后一条边,m表示边数
void init() {
m = 0;
memset(G, -1, sizeof(G)); // 清空G数组
}
void add(int u, int v) {
e[m++] = (Edge){u, v, G[u]}; // 添加新边,新边指向边G[u]
G[u] = m-1; // 将G[u]指向新边
// 处理无向图用以下
e[m++] = (Edge){v, u, G[v]};
G[v] = m-1;
}
// summary : 方案2比方案1好在常数较小
// 方案2中边的链接顺序相较于读入顺序相反。如果要一致可以改链接方式
例如最后一个图中,链接的情况:$$\begin{array}{ll} V1 \rightarrow 2 \ V2 \rightarrow 1 \rightarrow 3 \rightarrow 5 \ V3 \rightarrow 2 \rightarrow 4 \rightarrow 6 \ V4 \rightarrow 3 \ V5 \rightarrow 2 \ V6 \rightarrow 3 \end{array}$$ 接着再说深搜(\(\text{DFS}\))和遍历。深搜顾名思义就是一直往下搜索,遇到阻碍再回头一步,再继续向下,直到所有的情况都搜索过。
深搜用于遍历图的话,好处很多,比如说代码短小精悍且复杂度为线性。对于上面最后一个图,如果起点在\(1\)号结点,那么访问的顺序:\(1\rightarrow 2 \rightarrow 3 \rightarrow 6 \rightarrow 4 \rightarrow 5\)。
// 在此代码之后全部都采用前向星存储图
bool vis[maxn]; // 是否访问过某结点
void dfs(int u) {
vis[u] = 1; // 访问过的标记
cout << u; // 输出遍历顺序
for (register int i = G[u]; ~i; i = e[i].pre) { // 遍历邻接表,~i表示当i=-1时结束
int v = e[i].v; // 边指向的结点
// do something before dfs
if (!vis[v]) dfs(v); // 若未访问过指向的结点,访问
// do something after dfs
}
}
// 这个代码展现了dfs的基本框架,下文及以后的dfs基本上与此大同小异
1.2 图的连通分量和二分图染色
连通分量:在无向图中,如果从结点\(u\)可以到达结点\(v\),那么结点\(v\)必然可以到达结点\(u\)(对称性);如果从结点\(u\)可以到达结点\(v\),而结点\(v\)可以到达结点\(w\),则结点\(u\)一定可以到达结点\(w\)(传递性),再加上原地不动的话,结点自身可以到达自身(自反性),这些结点满足等价关系,可以组成一个等价类,我们把这些相互可达的结点称作一个连通分量(\(\text{CC, connected component}\))。例如下面的图,有\(3\)个连通分量,分别为\(\{1,2,3,4\},\{5,6,7\},\{8\}\)。
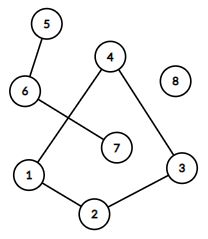
原理:找到一个未标记的点,然后将所有能够直接或间接到达的结点全部标记。不断重复其操作。
int cc[maxn], cc_cnt; // 记录结点所在连通分量的编号,同时若cc不为0,则说明该结点被访问过
void dfs(int u) {
cc[u] = cc_cnt; // 标记连通分量的编号
for (register int i = G[u]; ~i; i = e[i].pre) {
int v = e[i].v;
if (!cc[v]) dfs(v); // 继续访问
}
}
void work() {
cc_cnt = 0; // 清空连通分量数
memset(cc, 0, sizeof(cc)); // 清空 标号&&访问
for (register int i = 1; i <= N; i++)
if (!cc[i]) { // 没被标记
cc_cnt++; // 新的连通分量
dfs(i); // 将所有能访问到的连通分量访问
}
}
二分图:如果一个图\(G=<V,E>\),将\(V\)分成\(X\)和\(Y=V-X\),能使得\(E\)中任意一条边,两个端点分别在\(X\)集和\(Y\)集中,则此图为二分图。下图的左图即为二分图,而右图不是。
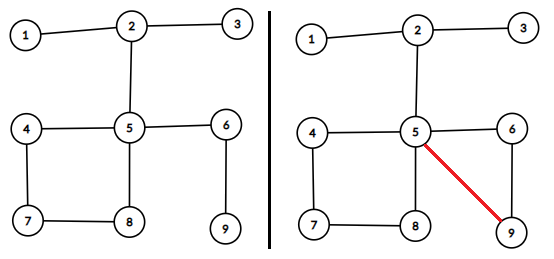
右图中出现了大小为\(3\)的奇环\(5\rightarrow 6 \rightarrow 9 \rightarrow 5\),显然无法将其分为两部分。
将二分图分成两部分即为二分图染色,\(X\)中所有结点染成黑色,\(Y\)中所有结点染成白色,如下图中\(X = \{1,\ 3,\ 5,\ 7,\ 9\}\),\(Y = \{2,\ 4,\ 6,\ 8\}\)是一种方案。
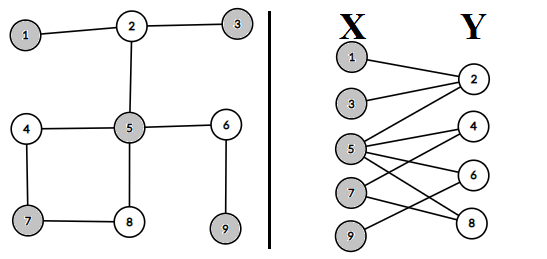
实现的思路就是随便找一个起始结点开始染色,然后将相邻的结点进行染色,如果相邻的结点已经染过色,判断颜色是否不同,如果相同,说明这条边连接着两个端点在同一个点集中。正确性在于只要不是二分图,图中存在奇环,那么一定存在某一时刻访问了该环中颜色相同的两个端点,染色会失败,反之一定会染色成功。
bool bipartite(int u) {
for (register int i = G[u]; ~i; i = e[i].pre) {
int v = e[i].v;
if (!color[v]) { // 未染色
color[v] = 3 - color[u]; // 染不同的颜色,这里是简洁的写法
if (!bipartite(v)) return false; // 继续向下染色+判断
} else if (color[v] == color[u]) return false; // 染过色,判断两个结点是否颜色相同而冲突
}
return true; // 是二分图
}
void work() {
memset(color, 0, sizeof(color)); // 清空
for (register int i = 1; i <= N; i++)
if (!color[i]) { // 未染色
color[i] = 1; // 染黑色,白色也行
if (!bipartite(i)) { // 染色+判断
printf("Failed"); // 失败
return;
}
}
// 打印结果
printf("Black :");
for (register int i = 1; i <= N; i++)
if (color[i] == 1) printf(" %d", i); // 黑
printf("\nWhite :");
for (register int i = 1; i <= N; i++)
if (color[i] == 2) printf(" %d", i); // 白
}
二分图除了染色,还有匹配等相关问题,这些放到后面再说。
2 进阶篇
总言:这里的算法难度有提升,大概在\(\text{NOIPtg}\)水平。
2.1 割顶和桥
在基础篇中,我们讨论了连通分量的问题。如果在一个无向图中,删去某一个结点可以使图中连通分量数目增加,则该结点被称为割顶;如果删去某一条边能使图中连通分量数目增加,则该边被称为桥。在某些问题中我们要通过找出割顶和桥来解决,首先来看如何找出割顶。
方案一:枚举所有结点,并求出删去这个结点后连通分量数目是否增加,但很遗憾,复杂度为\(\text{O}(n^2)\)。
方案二:利用\(\text{DFS}\)的特点来解决问题。期望为\(\text{O}(N+M)\)。
首先易知\(\text{DFS}\)访问图时按照遍历时的顺序可以得到一棵树,如下图所示。
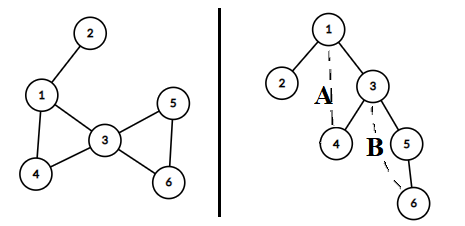
从\(1\)号结点开始,访问\(2\),再回来访问\(3\)、\(4\),又通过\(\text{A}\)边来到了\(1\),发现\(1\)来过,回头到\(3\)再到\(5\)、\(6\),又通过\(\text{B}\)边来到了\(3\),\(3\)来过,\(6\)退回了\(3\),之后又通过\(\text{B}\)来到了\(6\)(注意\(\text{DFS}\)过程中会这样子的),\(6\)来过,退回\(1\),然后发现还有\(\text{A}\)这条边没走,于是又来到了\(4\),发现\(4\)来过,回退,算法结束。
注意到\(\text{DFS}\)第一次发现某个结点时通过的边,在右图中用的是实线,这些构成了一棵树,我们将这些边称作树边;\(\text{A、B}\)两条边用的是虚线。这两条边在原图中存在,但不在这棵树上。我们发现在\(\text{DFS}\)过程中,有从\(4\rightarrow 1\)、\(6\rightarrow 3\)这两次,因为是这棵树上的结点通过这条边回到了其祖先结点(或者回到自身),我们将这条边称作反向边;还有两次从\(1\rightarrow 4\)、\(3 \rightarrow 6\),从树上的结点通过这条边来到了其子辈结点,这条边却又不是树边,我们将这条边称作前向边。然而在无向图中,前向边\(=\)反向边,所以这里就只讨论反向边。还有一种边叫做横跨边,就是除了以上\(3\)中边以外的边,比如说假如有一条边\(2\rightarrow 4\),然而在无向图中一定不会存在(这条边在\(\text{DFS}\)会以树边的形式呈现)。
我们看右边的树。手算可以知道\(\{1,3\}\)两个结点是割顶。割顶就是删去它能增加连通分量,如果某个结点它不是割顶,在\(\text{DFS}\)树中这个结点的所有子树中一定有一条反向边指向这个结点的祖先结点(不包括这个结点),在这个结点被删除后,其子树能通过这条边与祖先结点连通。如果存在一个子树中没有指向这个结点的祖先结点的边,说明删去这个结点后这颗子树中的所有结点会成为一个新的连通分量,也就说明这个结点是割顶。没有孩子自然就不是割顶了。比如说\(3\)号结点,其中一棵以\(5\)为根节点的子树中没有反向边指回\(1\),所以\(3\)是割顶。同理\(1\)是割顶。
这样子算法的大概框架就出来了。
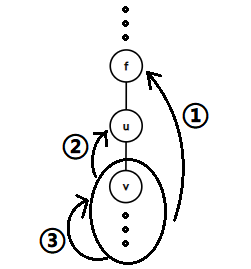
我们用\(low_u\)表示\(u\)结点能够访问到的最远的祖先。像上面这个图一样,如果对于结点\(u\),其所有子树如下图情况\(①\),即所有的\(v\)满足\(\text{dep}(low_u)<\text{dep}(u)\);反之如情况\(②、③\),\(\text{dep}(low_u)\geq \text{dep}(u)\),则\(u\)为割顶。因为没有横跨边,用深度判断没有问题,无需考虑连向其他结点的祖先。利用时间戳可以让算法更加简单:结点访问时间越靠前,越可能是其它结点的祖先,下面的代码用了这种方法。
还要考虑\(\text{DFS}\)树的根节点:如果它只有一个孩子,它也不是割顶。这个需要特判。
int cut[maxn], low[maxn], pre[maxn], dfs_clock;
// cut表示结点是否为割顶,low记录该结点以及后代能够访问到的最先前的结点(pre),pre记录第一次访问结点时的时间,dfs_clock表示时间
void dfs(int u, int fa) {
pre[u] = low[u] = ++dfs_clock; // 时间戳:访问一次加一次时间
int child = 0; // 用来记录dfs树中u结点的子结点数
for (register int i = G[u]; ~i; i = e[i].pre) {
int v = e[i].v;
if (!pre[v]) { // 该结点还未被访问
dfs(v, u); // 访问v及其后代
child++; // 树上子结点数增加
low[u] = min(low[u], low[v]); // 通过该子树能访问到的最远的祖先维护low
if (low[v] >= pre[u]) cut[u] = 1; // 如果该子树不能访问到u的祖先结点,则u为割顶
} else
if (v != fa) low[u] = min(low[u], pre[v]); // 通过该结点通过反向边能够访问到的结点维护low; v!=fa避免其又是树边
}
if (u == fa && child == 1) cut[u] = 0; // 特判dfs树的根节点
}
void work() {
memset(cut, 0, sizeof(cut));
memset(pre, 0, sizeof(pre));
// 图可能本身不连通
for (register int i = 1; i <= N; i++)
if (!pre[i])
dfs(i, i);
// 打印结果
printf("Cut-vertex :");
for (register int i = 1; i <= N; i++)
if (cut[i]) printf(" %d", i);
}
对于桥,在求割顶的代码上进行小改动即可。
首先,桥一定是树边,因为删了桥会产生新的连通分量,所以在遍历时一定会经过桥首次访问桥对面的结点。其次如果一个结点的所有子树中没有一条反向边连向这个结点的祖先结点,那么说明该结点与父亲结点连接的边是桥。
// >>符号表示其与求割顶的代码所添加的部分
int cut[maxn], low[maxn], pre[maxn], dfs_clock;
>> pair<int, int> bri[maxm]; // 桥记录
>> int bri_cnt; // 桥的总数
void dfs(int u, int fa) {
pre[u] = low[u] = ++dfs_clock;
int child = 0;
for (register int i = G[u]; ~i; i = e[i].pre) {
int v = e[i].v;
if (!pre[v]) {
dfs(v, u);
child++;
low[u] = min(low[u], low[v]);
if (low[v] >= pre[u]) cut[u] = 1;
} else
if (v != fa) low[u] = min(low[u], pre[v]); // 这里v!=fa很重要
}
>> if (u != fa && low[u] >= pre[u]) bri[bri_cnt++] = make_pair(u, fa); // 如果非根节点u的所有子树无法回到祖先结点,则(u,fa)是桥
if (u == fa && child == 1) cut[u] = 0;
}
void work() {
memset(cut, 0, sizeof(cut));
memset(pre, 0, sizeof(pre));
for (register int i = 1; i <= N; i++)
if (!pre[i])
dfs(i, i);
// 输出
printf("Bridge(s) : %d\n", bri_cnt);
for (register int i = 0; i < bri_cnt; i++)
printf("[%d] : (%d, %d)\n", i+1, bri[i].first, bri[i].second);
}
还有几种说法:\(①\)连接两个割点的边一定是桥;\(②\)桥连接的两个顶点一定都是割顶。
哪些是对的?如果是对的,为什么不从这些角度来实现上面的算法呢?大家可以来思考一下,这里就不说了。
2.2 无向图的双连通分量(BCC)和有向图的强连通分量(SCC)
在无向图中,对于一个连通图,如果任意两点间存在两条点不重复的路径,则说明这个图是点-双连通的(一般简称双连通)。这个的等价要求就是图中无割顶。
同理,对于一个连通图,如果任意两点间存在两条边不重复的路径,则说明这个图是边-双连通的。这个的等价要求就是每条边都在一个环中,也就是内部无桥。
对于无向图,点-双连通的极大子图被称为双连通分量(\(\text{Biconnected Component, BCC}\))。显然每条边都属于一个双连通分量,且两个双连通分量可能有且只有一个公共点,且其一定是割顶。反过来,任一割顶一定是两个或两个以上的双连通分量的公共点。
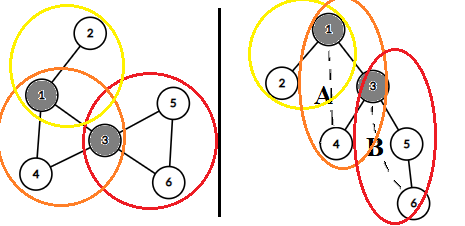
如上图所示,显然双连通分量为\(\{1,2\},\{1,3,4\},\{3,5,6\}\)。对于每一条边,都一定出现在某一个双连通分量中,且仅此一个双连通分量。对应右边的图,如果一个结点的某个子树能追溯的最远的祖先就是这个结点,那么这个结点和这个子树中的所有不在其它双连通分量的边和边连接的顶点都囊括在这个新的双连通分量中。前提是以\(\text{DFS}\)遍历顺序,这样就能找全。换句话说就是根据割顶找双连通分量,利用一个栈就可以实现。
stack<pair<int, int> > s;
vector<int> bcc[maxn];
int bcc_cnt, bccno[maxn];
int cut[maxn], pre[maxn], low[maxn], dfs_clock;
void dfs(int u, int fa) {
low[u] = pre[u] = ++dfs_clock;
int child = 0;
for (register int i = G[u]; ~i; i = e[i].pre) {
int v = e[i].v;
if (!pre[v]) {
child++;
s.push(make_pair(u, v));
dfs(v, u);
if (low[v] >= pre[u]) {
cut[u] = 1;
bcc_cnt++; // 找到一个双连通分量,此时栈顶的一部分就在这个双连通分量中
for (;;) {
pair<int, int> e = s.top(); s.pop();
if (bccno[e.first] != bcc_cnt) bccno[e.first] = bcc_cnt, bcc[bcc_cnt].push_back(e.first); // 如果这个结点的编号不是当前编号,更新并计入双连通分量
if (bccno[e.second] != bcc_cnt) bccno[e.second] = bcc_cnt, bcc[bcc_cnt].push_back(e.second);
if (e.first == u) break; // 直到边的起点已经是u结束
}
}
low[u] = min(low[u], low[v]);
} else
if (v != fa) low[u] = min(low[u], pre[v]);
}
if (u == fa && child == 1) cut[u] = 0;
}
边双连通分量十分类似。理解起来更加简单:删去桥后找连通分量。不过下面的算法不需要这样麻烦,一次\(\text{DFS}\)解决。
int cut[maxn], pre[maxn], low[maxn], dfs_clock;
stack<int> s;
vector<int> bcc[maxn]; // 记录每个边-双连通分量
int bcc_cnt, bccno[maxn]; // 边-双连通分量的数量、编号
void dfs(int u, int fa) {
low[u] = pre[u] = ++dfs_clock;
s.push(u);
int child = 0;
for (register int i = G[u]; ~i; i = e[i].pre) {
int v = e[i].v;
if (!pre[v]) {
child++;
dfs(v, u);
if (low[v] >= pre[u]) cut[u] = 1;
low[u] = min(low[u], low[v]);
}
else if (v != fa) low[u] = min(low[u], pre[v]);
}
// 遇到了桥就将栈内所有元素弹出,此时弹出的即为一个边-双连通分量
if (low[u] == pre[u]) {
bcc_cnt++;
for (;;) {
int x = s.top(); s.pop();
bccno[x] = bcc_cnt; // 根据需要一般和下面一句二选一
bcc[bcc_cnt].push_back(x);
if (x == u) break; // 找完了
}
}
if (u == fa && child == 1) cut[u] = 0;
}
在有向图中,和无向图的连通分量类似,有向图中有强连通分量(\(\text{Strongly Connected Componet, SCC}\))。在一个强连通分量中,任意两点相互可达,也构成了一个等价类。如果把每一个强连通分量看成一个点,也叫做缩点,那么所有的\(\text{SCC}\)构成了一个\(\text{SCC}\)图,这个图中一定不会存在环,所以是一个\(\text{DAG}\)。

如何去求强连通分量呢?我们还是通过\(\text{DFS}\)来求。
前面说无向图中没有横跨边,前向边等于反向边,但在有向图中这四种边都是独立的,事实上前向边依然没有价值:通过前向边连通的两个结点等价于通过树边连通。但思路仍然很简单:在\(\text{DFS}\)树中,如果当前结点的所有子树中没有一个结点能返回到当前结点的祖先结点,那么其父节点到当前结点的有向边一定不在任一\(\text{SCC}\)中。如此下去,剩下的若干连通块,每个连通块就是一个\(\text{SCC}\)。
正确性在于我们这样划分后所有连通块中可以通过树边和反向边或横跨边构成环使得结点两两互相可达,而且无法通过删去的边和已有的边在两个或多个\(\text{SCC}\)之间构成另一个环(否则某个结点一定会被子树的结点连回,导致这些点都在\(\text{SCC}\)中)。
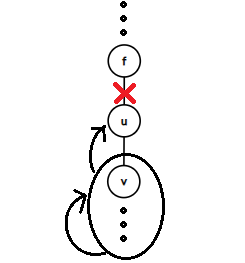
算法的实现上还要注意横跨边:如果它指向已标记的\(\text{SCC}\)中,更新\(low\)会出错,所以要判掉。
int pre[maxn], low[maxn], dfs_clock;
int sccno[maxn], scc_cnt; // 结点的SCC编号和总数量
vector<int> scc[maxn]; // 对应编号的结点
stack<int> s;
void dfs(int u, int fa) {
s.push(u);
low[u] = pre[u] = ++dfs_clock;
for (register int i = G[u]; ~i; i = e[i].pre) {
int v = e[i].v;
if (!pre[v]) {
dfs(v, u);
low[u] = min(low[u], low[v]);
}
else if (!sccno[v]) low[u] = min(low[u], pre[v]); // 这里的!sccno[v]判断很重要:因为可能遇到横跨边指向更先前标记的SCC使得结果不正确。
}
if (low[u] >= pre[u]) { // 判断是否分离出SCC
scc_cnt++;
for (;;) {
int v = s.top(); s.pop();
sccno[v] = scc_cnt;
scc[scc_cnt].push_back(v);
if (u == v) break; // 分离完毕
}
}
}
从2.1到这里的算法,都是一位有名的计算机科学家\(\text{Tarjan}\)提出的。在这里%%%。
求强连通分量还有一个叫\(\text{Kosaraju}\)算法。该算法理解起来十分简单:因为将所有强连通分量缩点后是一个\(\text{DAG}\),所以我们可以通过拓扑顺序来求出强连通分量,从拓扑序靠后的开始遍历所有未遍历过的结点,能遍历到的一定与其在同一个\(\text{SCC}\)中(根据\(\text{SCC}\)相互可达的性质)。但一开始我们不知道拓扑序,不过没关系,因为遍历时越靠前访问到的结点所在的\(\text{SCC}\)拓扑序一定尽可能靠前,再通过转置图(将所有边反向,名称和矩阵的转置有关),拓扑序靠前的就会变成靠后的,这样一个一个访问即可分离\(\text{SCC}\)。
代码上有一些细节要注意。
// G为原图,G2为转置图。e在这里只是存边,(u,v)和(v,u)两条对应与e中的边不同
int vis[maxn];
vector<int> s;
int sccno[maxn], scc_cnt;
vector<int> scc[maxn];
void dfs(int u) {
vis[u] = 1;
for (register int i = G[u]; ~i; i = e[i].pre) {
int v = e[i].v;
if (!vis[v])
dfs(v);
}
s.push_back(u); // 放后面可以保证多次dfs后s整体上从后往前大致上(不一定就是)呈拓扑顺序,但一定不影响后面操作
}
void find(int u) {
sccno[u] = scc_cnt;
scc[scc_cnt].push_back(u);
for (register int i = G2[u]; ~i; i = e[i].pre) {
int v = e[i].v;
if (!sccno[v])
find(v);
}
}
void work() {
memset(vis, 0, sizeof(vis));
s.clear();
scc_cnt = 0;
for (register int i = 1; i <= N; i++)
if (!vis[i])
dfs(i);
for (register int i = N-1; ~i; i--) // 从后往前通过转置图依次标记SCC
if (!sccno[s[i]]) scc_cnt++, find(s[i]);
}
这两种算法的复杂度均为\(\text{O}(N+M)\)。
2.3 二分图匹配问题
前面讨论过二分图染色,本部分将讨论二分图匹配。首先先说二分图最大匹配。
图论中匹配指两两没有公共点的边集,而二分图最大匹配是指找一个边数最大的匹配,即选择尽可能多的边,使得任意两条选中的边均没有公共点。如果所有的点都被匹配,那么称这个匹配是完美匹配。
如下图所示,两图均为该二分图的最大匹配,其中\((\text{b})\)是二分图的完美匹配。
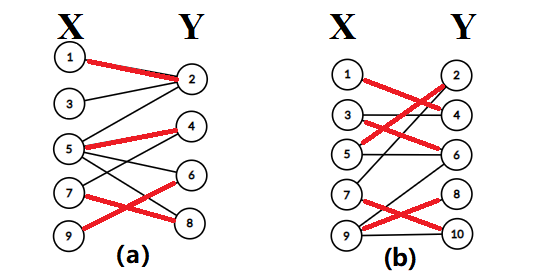
后面方便叙述用\(\text{X}\)和\(\text{Y}\)或左右来表示两边的点集。
该问题的解法可以利用网络流:设两个结点源点和汇点,源点向所有\(\text{X}\)的结点连一条边,所有\(\text{Y}\)的结点向汇点连一条边,图中所有边的容量为\(1\),跑一遍最大流,流量即为匹配数,而载有流量的边即为匹配上的边。
网络流太复杂了,有一个比它更简单的算法:匈牙利算法。叙述这个算法前要叙述下增广路定理。
从未被匹配的顶点开始,依次经过非匹配边、匹配边、非匹配边、匹配边······所得到的路径被称作交替路,若交替路的终点也是一个未被匹配的顶点,则称之为增广路。不难发现增广路中非匹配边一定比匹配边多一条,而且如果将增广路中的边取反(匹配边变成非匹配边,非匹配边变成匹配边),匹配中不会出现冲突且匹配数\(+1\),事实上是通过这种方法将两个未被匹配的顶点纳入了匹配中。当无法再找到增广路时,此时为最大匹配。不难证明,假设不是最大匹配,则一定有两个未纳入匹配的顶点之间存在增广路,矛盾,所以一定为最大匹配。
举下面一个例子。有这样的一个二分图,
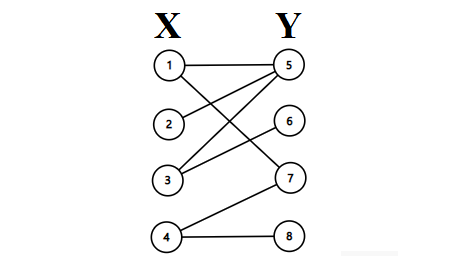
首先从\(①\)开始找增广路,取反;
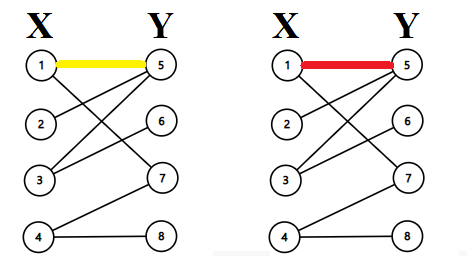
再从\(②\)开始找增广路,取反;
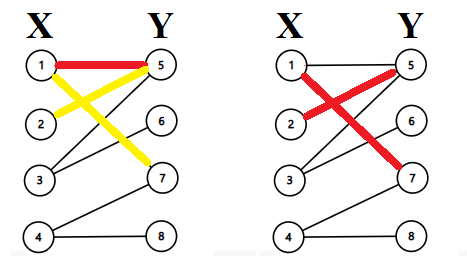
继续,直到结束。
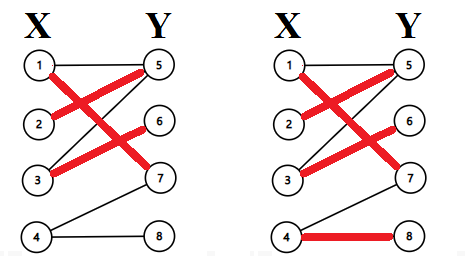
代码如下:
// 这里的e中(u,v)指X点集中的点u和Y点集中的点v有一条边,u=v并不是同一个点
int maxmatch; // 最大匹配数
int vis[maxn], link[maxn]; // vis表示Y点集的点是否访问过;link表示Y点集中的点所匹配的X点集中的点
bool dfs(int u) { // 通过dfs寻找增广路,同时进行取反,若成功返回true
for (register int i = G[u]; ~i; i = e[i].pre) {
int v = e[i].v;
if (!vis[v]) { // 这里是一个优化:在一次增广中,如果通过这个顶点无法找到增广路,则之后也无法通过此找到
vis[v] = 1;
if (!link[v] || dfs(link[v])) {
link[v] = u;
return true;
}
}
}
return false;
}
void hungarian() {
memset(link, 0, sizeof(link));
maxmatch = 0;
for (register int i = 1; i <= N; i++) {
memset(vis, 0, sizeof(vis));
if (dfs(i))
maxmatch++;
}
}
匈牙利算法的复杂度为\(\text{O}(NM)\),相较于网络流中\(\text{Dinic}\)的\(\text{O}(M\sqrt{N})\),理论复杂度要更大,但事实上匈牙利算法并不能完全达到理论上限,实测结果比较优秀,且代码较短。匈牙利算法的实现也可用\(\text{BFS}\)实现。
接下来说二分图最佳完美匹配。
假设有一个完美二分图\(G\)(所有顶点都能够被匹配),每条边都有一个权值(可以为负数),当匹配边的权值和最大时称之为最佳完美匹配。
如何解决呢?\(\text{Kuhn-Munkres}\)算法(\(\text{KM}\)算法)可以解决。
该算法引入了顶标解决问题。顶标就是每个点设有一个权值,在这个问题中,点集\(\text{X}\)的顶标记作\(Lx\),\(\text{Y}\)的顶标记作\(Ly\),对于所有的边,满足:\(Lx_i+Ly_j\geq e_{ij}\)。所有点和满足\(Lx_i+Ly_j=e_{ij}\)的边所构成的图称作相等子图。如果相等子图中有完美匹配,则这个完美匹配就是该二分图的最优匹配。证明很简单,因为相等子图中匹配上的边的权值和\(=\Sigma Lx_i + \Sigma Ly_i\),即所有顶标和,而\(\Sigma Lx_i + \Sigma Ly_i \geq \Sigma e_{ij}, e_{ij} \in \text{任一匹配中的边集E'}\)。
\(\text{KM}\)算法的思路是:首先使\(Lx_i=\max\{e_{ij}\},1\leq j\leq N\),即与\(\text{X}\)的点\(i\)关联的权值最大的边,这样能保证不等式\(Lx_i+Ly_j\geq e_{ij}\)恒成立;依次增广左边\(\text{X}\)点\(1\text{、}2···N\),每次增广如果成功,继续下一个点的增广,否则调整顶标直到这个点增广成功。从这个点增广的过程中一条条交替路组成了一棵交错树(又叫匈牙利树),比如说下面的图,图中的黑边和部分黄边为交错树上的边,其中黄边表示匹配上的边,\(\text{S}\)表示在交错树中的\(\text{X}\)点集的点,\(\text{T}\)表示在交错树中的\(\text{Y}\)点集中的点,\(\overline{\text{S}}\)表示不在交错树中的\(\text{X}\)点集中的点,依次类推。
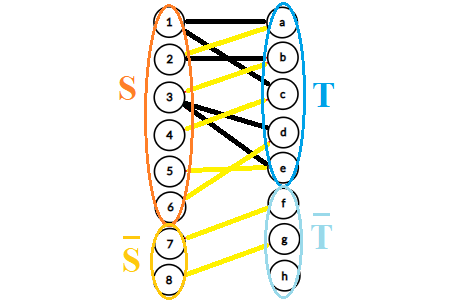
我们希望通过调整能使更多的边加入相等子图中,且连接着\(\text{S}\)和\(\overline{\text{T}}\)中的点,只有这样才能使交错树扩展,结点更有可能被匹配。
我们把所有在\(\text{S}\)中的点的顶标\(+d\),\(d\)是一个常数,把\(\text{T}\)中的点的顶标\(-d\),这样有什么好处呢?
①对于一端在\(\text{S}\),另一端在\(\text{T}\)中的边(指在交错树中的边),修改过后仍然在相等子图中;对于一端不在\(\text{S}\),另一端也不在\(\text{T}\)中的边(比如说不在交错树中的边但却是匹配边)也不会影响。
②一端在\(\text{S}\)中,另一端不在\(\text{T}\)中的边,修改之后可能会加入相等子图中(因为顶标和\(-d\),可能会与边权相等了)。这正是我们想要的。
③一端不在\(\text{S}\)中,另一端在\(\text{S}\)中的边的变化与否不影响。
那么关键在于\(d\)等于多少,应取\(d=\min\{Lx_i+Ly_j-e_{ij}\}\),其中结点\(i\)在\(\text{S}\)中,结点\(j\)在\(\text{T}\)中。\(d\)取这个值,一方面要有边加入,取得更小,就会导致没有边加入;另一方面,\(d\)取得更大,会导致上面关于顶标和的不等式不成立。
直到全部匹配上时,算法结束。
int N, M, e[maxn][maxn]; // e[i][j]表示i->j的权值
int S[maxn], T[maxn], Lx[maxn], Ly[maxn], link[maxn]; // S、T、Lx、Ly如上文所述,link表示右边结点匹配上的左边的结点
bool dfs(int u) { // 增广
S[u] = 1;
for (register int v = 1; v <= N; v++) if (!T[v] && Lx[u] + Ly[v] == e[u][v]) { // 条件是v未被访问且该边在相等子图中
T[v] = 1;
if (!link[v] || dfs(link[v])) {
link[v] = u;
return true;
}
}
return false;
}
void update() {
int d = 1<<30;
for (register int i = 1; i <= N; i++) if (S[i])
for (register int j = 1; j <= N; j++) if (!T[j])
d = min(d, Lx[i] + Ly[j] - e[i][j]); // 寻找最小的d
for (register int i = 1; i <= N; i++) { // 顶标修改
if (S[i]) Lx[i] -= d;
if (T[i]) Ly[i] += d;
}
}
void KM() {
memset(Lx, 0, sizeof(Lx));
memset(Ly, 0, sizeof(Ly));
memset(link, 0, sizeof(link));
for (register int i = 1; i <= N; i++)
for (register int j = 1; j <= N; j++)
Lx[i] = max(Lx[i], e[i][j]); // 初始化
for (register int i = 1; i <= N; i++) // 依次增广每个结点
for (;;) { // 无限循环
memset(S, 0, sizeof(S));
memset(T, 0, sizeof(T));
if (dfs(i)) break; else update(); // 增广成功退出循环,否则修改顶标继续
}
int ans = 0; // 求出答案
for (register int i = 1; i <= N; i++) ans += Lx[i] + Ly[i];
printf("%d", ans);
}
分析复杂度:增广\(\text{O}(N)\)次,每次最坏又要\(\text{O}(N)\)次\(dfs\)(每次\(dfs\)交错树最少扩大左右各\(1\)个结点,最多能扩大\(\text{O}(N)\)次),\(dfs\)最坏又要\(\text{O}(M)=\text{O}(N^2)\)次,与此同时\(\text{update}\)又需要\(\text{O}(N^2)\)次,总复杂度为\(\text{O}(N^4+N^2\times M)=\text{O}(N^4)\)。
考虑优化:对于总复杂度的第一项,用\(slack_j=\min\{Lx_i+Ly_j-e_{ij}\}\),那么最后修改顶标时就变成求\(d=\min\{slack_j\}\)了。如果在\(dfs\)的过程中顺带把\(slack_j\)维护,最后\(\text{update}\)时的复杂度就能降成\(\text{O}(N)\)了;对于总复杂度的第二项,将\(dfs\)改进,因为在修改顶标的过程中,交错树只是扩大,没有必要重新进行\(dfs\),而是在原有的基础上\(dfs\),这样\(\text{O}(N)\)次的\(dfs\)的总复杂度就变成了\(\text{O}(M)\)了。
通过这样,\(\text{KM}\)算法的复杂度降为\(\text{O}(N^3)\)。
后记
原本想说更多的,但说多了就不得再深了。且难免会有疏漏,甚至会有错误之处,希望大家能不吝指出。
本文就介绍到此,其实内容仍有很多很多,详见我的别的博文。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号