
从零开始构建一个基于大模型和 RAG 的知识库问答系统
SimpleAbdQA
本项目所使用的大模型为:qwen1.8b
演示中所使用Embedding为:Word2vec
一、介绍
通过从本项目中,你可以得到:
- 了解基于大模型的本地知识库的运作原理
- 了解如何构建一个本地知识库
- 通过修改少量代码,定制专属于自己的知识库
二、预备知识点
什么是 RAG
在开始之前,我还是打算再次简要的介绍一下 RAG。
在 Meta 的官方 Blog 上有这样一段话:
Building a model that researches and contextualizes is more challenging, but it's essential for future advancements. We recently made substantial progress in this realm with our Retrieval Augmented Generation (RAG) architecture, an end-to-end differentiable model that combines an information retrieval component (Facebook AI’s dense-passage retrieval system) with a seq2seq generator (our Bidirectional and Auto-Regressive Transformers BART model). RAG can be fine-tuned on knowledge-intensive downstream tasks to achieve state-of-the-art results compared with even the largest pretrained seq2seq language models. And unlike these pretrained models, RAG’s internal knowledge can be easily altered or even supplemented on the fly, enabling researchers and engineers to control what RAG knows and doesn’t know without wasting time or compute power retraining the entire model.
这段话主要讲述了一个新的模型架构,也就是 RAG (检索增强生成) 的重要性和优势。可以概括为以下几点:
-
构建一个能够进行研究和上下文分析的模型虽然更具挑战性,但对未来的技术进步非常关键;
-
通过在知识密集的下游任务上微调,RAG 可以实现最先进的结果,比现有的最大的预训练序列到序列语言模型还要好;
-
与传统的预训练模型不同,RAG 的内部知识可以轻松地动态更改或补充。也就是说,研究人员和工程师可以控制 RAG 知道和不知道的内容,而不需要浪费时间或计算资源重新训练整个模型。
这段话信息量很大,但是作为初学者,简而言之:
RAG 的本质是在传递给 LLM 的提示语中,通过一个检索工具来添加自己的数据。
向量数据库介绍
在人工智能和机器学习领域,向量数据库扮演着至关重要的角色,尤其是在处理非结构化数据,如文本、图像和音频时。
向量数据库的核心功能是将各类数据转换成向量形式,这些向量在数学上表示为高维空间中的点。每个向量捕获了数据的含义和上下文信息,使得我们可以通过计算向量之间的距离来找到相似的数据点。
大模型外接知识库的流程
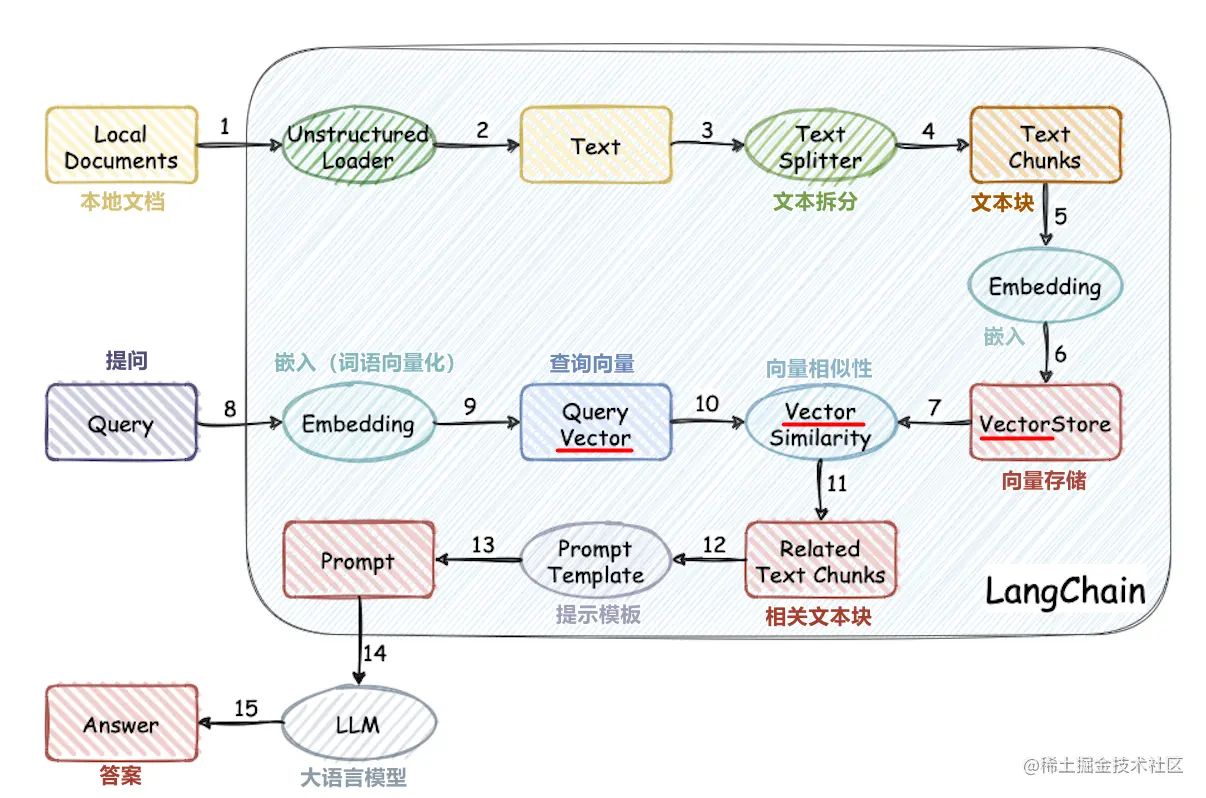
工作流程:加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
- 加载文件:将需要处理的文本文件加载到系统中。这些文本可以是百科全书、知识图谱或其他类型的知识源。
- 读取文本:从文件中读取文本内容,并将其转换为字符串格式。
- 文本分割:将输入的文本分割成单独的句子或段落。这可以通过正则表达式、分词器或其他文本处理方法实现。
- 文本向量化:将分割后的文本转换为数值向量。这可以通过词嵌入方法(如 Word2Vec、GloVe 等)或将文本转换为独热编码(one-hot encoding)来实现。
- 问句向量化:将用户输入的问句转换为数值向量。与文本向量化类似,可以使用词嵌入方法或独热编码来实现。
- 匹配查询:使用相似度计算方法(如余弦相似度、Jaccard 相似度等)在文本向量中找到与问句向量最相似的 top k 个文本片段。这些相似的文本片段可以作为上下文和问题的一部分,添加到 prompt 中。
- 构建 prompt:将匹配到的文本片段和原始问题组合成一个完整的 prompt。例如,“您的问题关于 […],以下是与您问题相关的上下文: […],请回答 […]”。
- 提交给 LLM 生成回答:将构建好的 prompt 提交给大型语言模型(如 GPT-3、ChatGPT 等)进行回答生成。模型根据 prompt 中的上下文和问题生成相应的回答。
- 输出回答:将模型生成的回答输出给用户,完成问答过程。
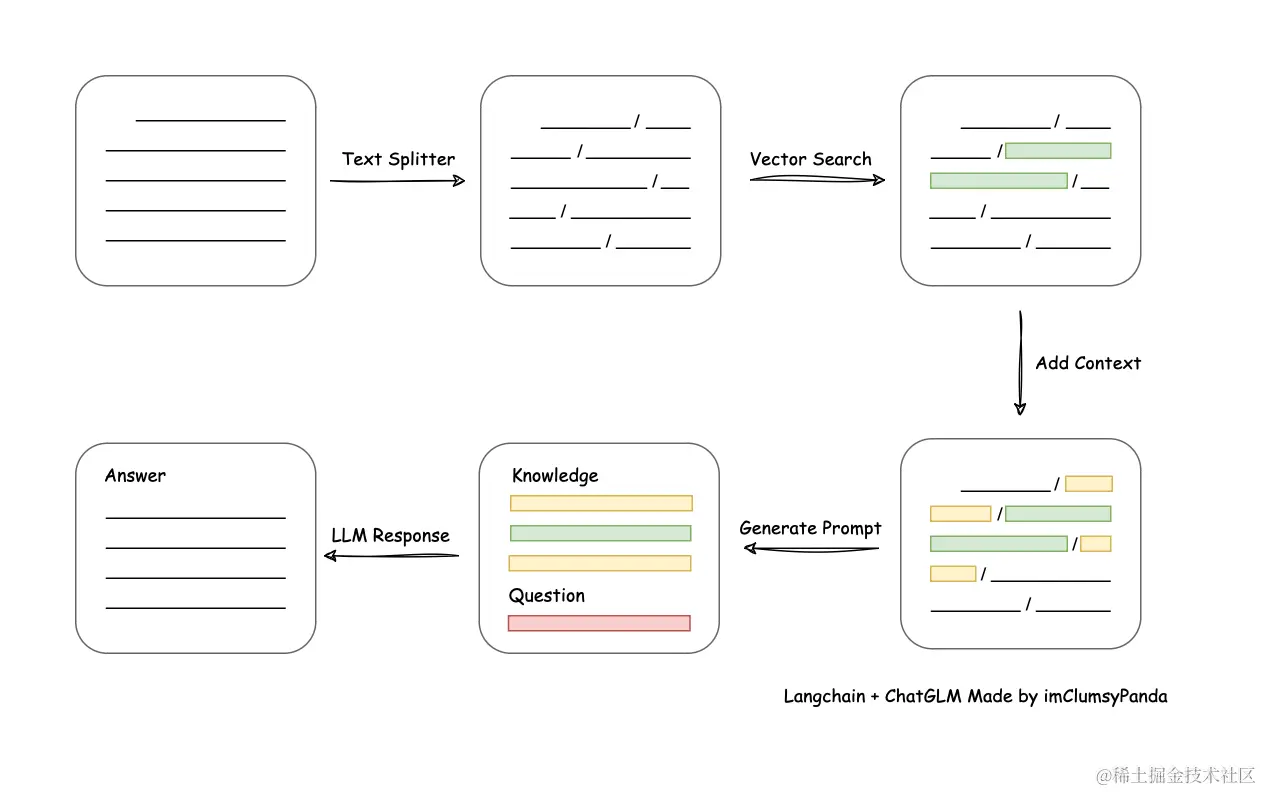
从文档处理角度来看,实现流程如下:
目前LLM存在最大的问题
-
研究成本高,如果搭建一个13B以及以上的模型,全量运行需要24GB以上显存,如果进行量化质量又达不到要求,前期研究就要投入大量成本并且如果有多个LLM项目并行开发就会遇到项目组之间抢资源问题;
-
训练成本高,回报率随机,对于广大进行“炼丹”的“仙人”们都知道,炼丹最大问题在于整理的训练集、训练轮数及各种参数可能导致炼出废丹,并且知识的日益更新,如果要更新知识就要重新训练;
-
胡乱说话(幻想),幻想就是你问一个问题,它有板有眼儿的给你回答,你不是专业人士可能就会被它的回答误导了。LLM的幻想并非真正的幻想,而是由其训练方式和数据源所决定的,LLM通过大量的互联网文本数据进行训练,这些数据包含了各种话题和语境。
以上就是目前LLM模型常见的问题,对于模型的研发者和使用者都是头痛问题。针对企业级AI应用,目前有个大家探索的方案就是向量数据库+LLM大模型结合,解决研究成本、训练及胡乱说话问题,通过知识库中准确的内容弥补数据的不足导幻想。
其原理就是将知识要点存储到向量数据库,在提问时通过分词或大模型对提问内容进行分解,从向量数据库提取出关键内容,然后再将内容喂给LLM模型,从而得到想要的答案,从而实现了AI数据库的可维护性,这个模型可以用于OpenAI API也可以用于LLM私有化模型。
NLP基础概念
自然语言处理,简称 NLP,是人工智能的一个分支,它允许机器理解、处理和操纵人类语言。
- 标记(Token): 是具有已知含义的字符串,标记可以是单词、数字或只是像标点符号的字符。“你好”、“123”和“-”是标记的一些示例。
- 句子(Sentence): 是一组意义完整的记号。“天气看起来不错” 是一个句子的例子,句子的标记是【“天气”, “看起来”, “不错“】。
- 段落(Paragraph): 是句子或短语的集合,也可以将句子视为段落的标记。
- 文档(Documents): 可能是一个句子、一个段落或一组段落。发送给个人的文本消息是文档的一个示例。
- 语料(Corpus): 通常是作为词袋的原始文档集合。语料库包括每个记录中每个单词的 id 和频率计数。语料库的一个例子是发送给特定人的电子邮件或文本消息的集合。
- 稀疏向量(SparseVector): 通常,我们可以略去向量中多余的0元素。此时,向量中的每一个元素是一个(index, value)的元组
- 模型(Model): 是一个抽象的术语。定义了两个向量空间的变换(即从文本的一种向量表达变换为另一种向量表达)。
词向量模型 Word2vec 介绍
Word2Vec是一种用于处理自然语言处理的模型,它是在2013年由Google的研究员Mikolov等人首次提出的。Word2Vec通过训练海量的文本数据,能够将每个单词转换为一个具有一定维度的向量。这个向量就可以代表这个单词的语义。因为这个向量是在大量语境中学到的,所以这个向量能很好的表达这个单词的语义。 Word2Vec包括Skip-Gram和CBOW两种模型,主要是通过优化模型计算词与词之间的关系,从而获得词的向量表示。 Skip-Gram模型是通过一个词预测其上下文。举个例子,给定词汇"苹果",Skip-Gram模型的目标是生成它的上下文"吃了一个大"和"感觉真满足"。 CBOW模型是给定一个词的上下文词汇,预测这个词。比如,给定上下文"吃了一个大"和"感觉真满足",CBOW模型会预测中间的词汇,也就是"苹果"。 这两种模型都是通过学习词汇与其上下文之间的关系,获得词的向量表示。这两个向量的距离可以用来衡量两个词语义上的相似度,距离越近意味着两个词语义上越相似。
实现 SimpleAbdQA
接下来,我们从探索的角度来研究向量数据库+LLM大模型的应用
数据处理
中文wiki
https://dumps.wikimedia.org/zhwiki/
zhwiki-20241201-pages-articles.xml下载地址:https://dumps.wikimedia.org/zhwiki/20241201/zhwiki-20241201-pages-articles.xml.bz2
数据提取
按照具体数据集的规范解压提取出数据
数据处理
opencc
Open Chinese Convert(OpenCC)是一个开源的中文简繁转换项目,致力于制作高质量的基于统计语料的简繁转换词库。还提供函数库(libopencc)、命令行简繁转换工具、人工校对工具、词典生成程序、在线转换服务及图形用户界面。
对于数据集我们需要依此进行四个操作:过滤中文、简化中文、中文分词、除去停用词
其中繁体转简体 和 分词 所花费的时间 占大头
from gensim.corpora import WikiCorpus
import os
def parse_corpora():
space = ''
idx = 0
dir_path = "./data/zhwiki-pages-articles"
# 检查你的目录是否存在,如果不存在,创建它
if not os.path.exists(dir_path):
os.makedirs(dir_path)
output = open(dir_path + "/zhwiki_{}.txt".format(idx),'w',encoding='utf-8')
wiki = WikiCorpus("./data/zhwiki-20241201-pages-articles.xml.bz2",dictionary={})
for text in wiki.get_texts():
output.write(space.join(text) + '\n')
idx += 1
if(idx % 10000 == 0):
print("save" + str(idx) + "articles")
output = open(dir_path + "/zhwiki_{}.txt".format(int(idx / 10000)),'w',encoding='utf-8')
output.close()
print("finish saved")
parse_corpora()
import re
import opencc
import jieba
import os
zhwiki_dir_path = "./data/zhwiki-pages-articles"
stopword_dir_path = zhwiki_dir_path + '/stopword_txt'
seg_dir_path = zhwiki_dir_path + '/parse_txt'
stopwords_table_path = './data/四川大学机器智能实验室停用词库.txt'
cc = opencc.OpenCC('t2s')
# 读取停词表,并使用set来存储
with open(stopwords_table_path, 'r', encoding='utf-8') as file:
stopwords_set = set(line.strip() for line in file)
def checkDir():
# 检查你的目录是否存在,如果不存在,创建它
if not os.path.exists(zhwiki_dir_path):
os.makedirs(zhwiki_dir_path)
if not os.path.exists(stopword_dir_path):
os.makedirs(stopword_dir_path)
if not os.path.exists(seg_dir_path):
os.makedirs(seg_dir_path)
def simplified_Chinese(txt):
txt_sim = []
for sentence in txt.split('\n'):
txt_sim.append(cc.convert(sentence) + '\n')
#print("第{}句话转化成简体成功".format(i))
txt = ''.join(txt_sim)
return txt
def remove_stopwords(idx):
in_path = seg_dir_path
out_path = stopword_dir_path
with open(f'{in_path}/zhwikiSegDone_{idx}.txt', 'r', encoding='utf-8') as file_in,\
open(f'{out_path}/zhwikiStopWord_{idx}.txt', 'w', encoding='utf-8') as file_out:
# 读取所有行,并将每一行分割成单词
lines = file_in.readlines()
sentence_list = [line.split(' ') for line in lines]
# 对每一行的每一个单词,如果它不在停词表中,就保留
result = []
for words in sentence_list:
result.append(' '.join(word for word in words if word not in stopwords_set))
# 将结果写入文件
file_out.write('\n'.join(result))
def seg_done(idx, txt):
# 以下为分词部分
out_path = seg_dir_path
file = open(out_path + '/zhwikiSegDone_{}.txt'.format(idx),'w',encoding='utf-8')
file.write(' '.join(jieba.cut(txt, cut_all=False)).replace(' \n ', '\n'))
file.close()
def parse_txt():
in_path = zhwiki_dir_path
for i in range(0, 47): # 理论上应该是从0至47
file = open(in_path+'/zhwiki_{}.txt'.format(i),'r',encoding='utf-8')
txt = file.read()
file.close()
# 1. 提取汉字
txt = ''.join(re.findall('[\u4e00-\u9fa5|\n]',txt)) # 只保留汉字,如果其后有空格则保留
print('第' + str(i) + '个txt文件提取汉字成功')
# 2. 简化汉字
txt = simplified_Chinese(txt)
print('第' + str(i) + '个txt文件繁体汉字转化简体汉字成功')
# 3. 汉字分词
seg_done(i, txt)
print('第' + str(i) + '个txt文件分词成功')
# 4. 去除停用词
remove_stopwords(i)
print('第' + str(i) + '个txt文件去除停用词成功')
checkDir()
parse_txt()
清华大学自然语言处理实验室数据集
https://thuctc.thunlp.org/#样例程序
THUCNews.zip下载地址:https://thunlp.oss-cn-qingdao.aliyuncs.com/THUCNews.zip
数据提取
我们下载的是.zip文件,先原地解压THUCNews.zip
数据处理
对于数据集我们需要依此进行四个操作:过滤中文、简化中文、中文分词、除去停用词
import re
import jieba
stopwords_table_path = './data/四川大学机器智能实验室停用词库.txt'
# 读取停词表,并使用set来存储
with open(stopwords_table_path, 'r', encoding='utf-8') as file:
stopwords_set = set(line.strip() for line in file)
NewsCatalog = ['体育','娱乐','家居','彩票','房产','教育','时尚','时政','星座','游戏','社会','科技','股票','财经']
dir_path = './data/THUCNews'
def list_all_files(path):
result = []
for root, dirs, files in os.walk(path):
for file in files:
if file != '.DS_Store': # 添加此行来跳过.DS_Store文件
result.append(os.path.join(root, file))
return result
for category in NewsCatalog:
categorya_dir_path = dir_path + "/" + category
if not os.path.exists(categorya_dir_path):
os.makedirs(categorya_dir_path)
combine = open(dir_path + '/' + '{}.txt'.format(category), 'w', encoding='utf-8')
sentence = []
idx = 0
print("处理类型:{}".format(category))
for file_path in list_all_files(categorya_dir_path):
if idx % 10000 == 0:
print(" 已处理{}:{}".format(category,idx))
file = open(file_path, 'r', encoding='utf-8')
txt = file.read().replace('\n ',' ') # 一篇文章为一排
file.close()
# 提取中文
txt = ''.join(re.findall('[\u4e00-\u9fa5| |]', txt))
# 分词
txt = ' '.join(jieba.cut(txt, cut_all=False)).replace(' ',' ')
# 删除停用词
for word in txt.split(' '):
if word in stopwords_set:
txt = txt.replace(word+' ','')
sentence.append(txt+'\n')
idx += 1
combine.write(''.join(sentence))
print("总和:{}".format(idx))
print('文本处理完毕')
数据合并
需要把所有数据集合并为一个数据集,作为最终训练模型用的数据集
NewsCatalog = ['体育','娱乐','家居','彩票','房产','教育','时尚','时政','星座','游戏','社会','科技','股票','财经']
path = './data'
wiki_path = './data/zhwiki-pages-articles/stopword_txt'
THUCNews_path = './data/THUCNews'
Data = open(path + '/data.txt', 'a', encoding='utf-8')
for i in range(47): # 合并中文wiki百科文件
file = open(wiki_path + '/zhwikiStopWord_{}.txt'.format(i), 'r', encoding='utf-8')
txt = file.read().strip('\n').strip(' ')
Data.write(txt + '\n')
file.close()
print('中文wiki百科文件合并完成')
for item in NewsCatalog: # 合并THU数据集
file = open(THUCNews_path + '/{}.txt'.format(item), 'r', encoding='utf-8')
txt = file.read().strip('\n').strip(' ')
Data.write(txt + '\n')
file.close()
print('THU数据集合并完成')
模型训练
数据集并不大,m2 pro性能也很能打了,直接在本地硬造就行。 训练10轮,m2 pro 32g大约一个半小时可以完成
from gensim.models import Word2Vec
from gensim.models import word2vec
from loguru import logger
import time
from gensim.models.callbacks import CallbackAny2Vec
# 定义回调函数类,用于在每个epoch结束时记录训练信息
class EpochLogger(CallbackAny2Vec):
def __init__(self):
self.epoch = 0
self.time = time.time()
def on_epoch_begin(self, model):
logger.info("Epoch #{} start".format(self.epoch))
def on_epoch_end(self, model):
loss = model.get_latest_training_loss()
duration = time.time() - self.time
logger.info("Epoch #{} end, loss: {}, duration: {}".format(self.epoch, loss, duration))
model.save('word2vec_model_{}.model'.format(self.epoch)) # 保存模型,模型名中包含epoch数
self.epoch += 1
self.time = time.time()
# 打印日志
logger.add("word2vec_training.log")
path = './data/data.txt'
logger.info('Starting to load sentences from %s', path)
sentences = word2vec.LineSentence(path)
logger.info('Finished loading sentences')
# 提前定义callback
epoch_logger = EpochLogger()
# sg——word2vec两个模型的选择。如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型
# hs——word2vec两个解法的选择,如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling
# negative——即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间
# min_count——需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值
# iter——随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值
# alpha——在随机梯度下降法中迭代的初始步长。算法原理篇中标记为η,默认是0.025
# min_alpha——由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值
# 训练模型
logger.info('Starting to build Word2Vec model')
model = Word2Vec(sentences, vector_size=300, window=5, epochs=10, compute_loss=True, callbacks=[epoch_logger])
logger.info('Finished building Word2Vec model')
model_path = 'word2vec.model'
logger.info('Starting to save model to %s', model_path)
model.save(model_path)
logger.info('Finished saving model')
模型使用
句向量生成
word2vec模型本身只能对词语进行embedding操作,如果想对句子进行embedding,可以使用平均值方法
平均值:最简单的做法是将句子中所有词的向量进行平均。这会给你一个固定长度的向量,可以用作句子的embedding,但是这种方法不包含句子的语序信息。
import os
import time
from typing import List, Union, Dict
from gensim.models import Word2Vec
import jieba
import numpy as np
from loguru import logger
from numpy import ndarray
from tqdm import tqdm
stopwords_table_path = './data/四川大学机器智能实验室停用词库.txt'
def load_stopwords(file_path):
# 读取停词表,并使用set来存储
with open(stopwords_table_path, 'r', encoding='utf-8') as file:
stopwords_set = set(line.strip() for line in file)
return stopwords_set
class Word2VecManager:
"""Pre-trained word2vec embedding"""
def __init__(self, model_name_or_path: str = './word2vec.model',
w2v_kwargs: Dict = None,
stopwords: List[str] = None):
"""
Init word2vec model
Args:
model_name_or_path: word2vec file path
w2v_kwargs: dict, params pass to the ``load_word2vec_format()`` function of ``gensim.models.KeyedVectors`` -
https://radimrehurek.com/gensim/models/keyedvectors.html#module-gensim.models.keyedvectors
stopwords: list, stopwords
"""
from gensim.models import KeyedVectors # noqa
self.w2v_kwargs = w2v_kwargs if w2v_kwargs is not None else {}
t0 = time.time()
# w2v.init_sims(replace=True)
logger.debug('Load w2v from {}, spend {:.2f} sec'.format(model_name_or_path, time.time() - t0))
self.stopwords = stopwords if stopwords else load_stopwords(default_stopwords_file)
self.model = Word2Vec.load(model_name_or_path)
self.w2v = self.model.wv
self.jieba = jieba
self.model_name_or_path = model_name_or_path
def __str__(self):
return f"<Word2Vec, word count: {len(self.w2v.key_to_index)}, emb size: {self.w2v.vector_size}, " \
f"stopwords count: {len(self.stopwords)}>"
def encode(self, sentences: Union[List[str], str], show_progress_bar: bool = False) -> ndarray:
"""
Encode sentences to vectors
"""
if self.w2v is None:
raise ValueError('No model for embed sentence')
input_is_string = False
if isinstance(sentences, str) or not hasattr(sentences, '__len__'):
sentences = [sentences]
input_is_string = True
all_embeddings = []
for sentence in tqdm(sentences, desc='Word2Vec Embeddings', disable=not show_progress_bar):
emb = []
count = 0
for word in sentence:
# 过滤停用词
if word in self.stopwords:
continue
# 调用词向量
if word in self.w2v.key_to_index:
emb.append(self.w2v.get_vector(word, norm=True))
count += 1
else:
if len(word) == 1:
continue
# 再切分
ws = self.jieba.lcut(word, cut_all=True, HMM=True)
for w in ws:
if w in self.w2v.key_to_index:
emb.append(self.w2v.get_vector(w, norm=True))
count += 1
tensor_x = np.array(emb).sum(axis=0) # 纵轴相加
if count > 0:
avg_tensor_x = np.divide(tensor_x, count)
else:
avg_tensor_x = np.zeros(self.w2v.vector_size, dtype=float)
all_embeddings.append(avg_tensor_x)
all_embeddings = np.array(all_embeddings, dtype=float)
if input_is_string:
all_embeddings = all_embeddings[0]
return all_embeddings
stop_word_set = load_stopwords(stopwords_table_path)
model = Word2VecManager(stopwords=stop_word_set)
model.encode("你好我是中国人")
文档分块
def split_sentences(text):
sent_delimiters = ['。', '?', '!', '?', '!', '.']
for delimiter in sent_delimiters:
text = text.replace(delimiter, '\n')
sentences = text.split('\n')
sentences = [sent for sent in sentences if sent.strip()]
return sentences
向量相似度计算
向量相似度的计算通常基于一种叫做余弦相似度(Cosine Similarity)的度量方法。余弦相似度直观地表示了两个向量间的夹角,其值越接近于1,表示两个向量越相似。
def cosine_similarity(vec1, vec2):
norm_vec1 = numpy.linalg.norm(vec1)
norm_vec2 = numpy.linalg.norm(vec2)
if norm_vec1 == 0 or norm_vec2 == 0:
return 0
else:
dot_product = numpy.dot(vec1, vec2)
return dot_product / (norm_vec1 * norm_vec2)
知识库检索
知识库端
- 将各类文档统一转为纯文本格式
- 文档分块
- 对各文档块进行向量化
- 将所有文本向量存储起来(持久化或非持久化均可)
查询端
- 将用户的查询语句向量化
- 将查询向量放入知识库进行相似性检索
- 获取检索到的向量,加入大模型的上下文中
- 获取大模型问答结果
将知识加入大模型上下文常用prompt模板:
使用以下背景段落来回答问题,如果段落内容不相关就返回未查到相关信息:
背景:{{knowledge}}
问题:{{userInput}}
知识库持久化
如果我们想把知识库作为大模型的外接知识库,就需要借助向量数据库来存储之前被向量化的文档。我们选用Qdrant来部署
docker pull qdrant/qdrant
docker run -p 6333:6333 -p 6334:6334 -v .\qdrant_storage:/qdrant/storage:z qdrant/qdrant
pip3 install qdrant-client
将知识库存储到向量数据库
if __name__ == '__main__':
collection_name = global_config['COLLECTION_NAME']
vc_size = 300
# 创建collection
db_client.recreate_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=vc_size, distance=Distance.COSINE),
)
count = 0
for root, dirs, files in os.walk("../corpus"):
for file in tqdm.tqdm(files):
file_path = os.path.join(root, file)
print("加载知识文档:{}\n".format(file))
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
parts = split_sentences(text)
for part in parts:
print(part)
embedding = create_embeddings(part)
db_client.upsert(
collection_name=collection_name,
wait=True,
points=[
PointStruct(id=count, vector=embedding, payload={"text": part}),
],
)
count += 1
ollama
ollama 是一个管理大语言模型的工具,帮助我们在本地快速创建、部署、使用大语言模型。它本身并不是一个大语言模型!还有一个名词 llama,它跟 ollama 很像,但是区别可就大了。llama 是由 Meta 开发的大语言模型,所以我们可以使用 ollama 加载 llama 这样的大语言模型。
安装 ollama
进入 ollama 官网,点击下载按钮,安装到自己电脑上即可。安装完成后可以使用 ollama -v 测试是否安装成功
ollama 常用命令
# 查看模型列表
ollama list
# 查看目前启动的模型
ollama ps
# 删除模型
ollama rm ${模型名}
# 启动模型
ollama run ${模型名}
# 停止模型
ollama stop ${模型名}
运行 qwen1.8b
ollama run qwen:1.8b
在 python 使用 ollama
pip install ollama
import ollama
response = ollama.chat(model='qwen:1.8b', messages=[
{
'role': 'user',
'content': '为什么天空是蓝色的?',
},
])
print(response['message']['content'])
将知识库和大模型结合起来
def test_query(text):
def create_prompt(question, knowledge):
bg = ""
for i, v in enumerate(knowledge):
bg += f"{i}. {v}"
prompt = f"""下面为你提供了一些有助于回答问题的背景,结合背景和你所知道的知识回答下列问题:
背景:{bg}
问题:{question}"""
return prompt
sentence_embedding = create_embeddings(text)
search_result = db_client.search(
collection_name="suzume_collection",
query_vector=sentence_embedding,
limit=5,
search_params={"exact": False, "hnsw_ef": 128}
)
answers = [res.payload["text"] for res in search_result]
response = ollama.chat(model='qwen:1.8b', messages=[
{
'role': 'user',
'content': create_prompt(text, answers),
},
])
print(response['message']['content'])
if __name__ == '__main__':
test_query("《铃芽户缔》铃芽是一个什么样的人")
根据你提供的背景信息,《铃芽户缔》是一部描述铃芽自我治愈的成长之旅的电视剧。以下是关于这部剧中的铃芽形象的一些概述:
- 自我治愈者:铃芽自幼患有严重的慢性疾病,如心脏病、糖尿病等。这种长期的身体健康问题对铃芽的生活造成了极大的困扰和不便。然而,幸运的是,铃芽从小就有一个强烈的自我治愈的愿望和决心,她希望通过自己的努力和坚持,能够有效地改善和治疗自己身体上的各种慢性疾病。
- 爱情故事:《铃芽户缔》是一部描绘铃芽与草太爱情故事的电视剧。这部剧通过讲述铃芽和草太的爱情故事,以及他们在旅途中遇见的各种陌生人所引发的一系列埋怨和吐苦水的故事,来展现铃芽对爱情的执着追求和热爱守护的精神风貌和高尚情操。
- 关闭1. 芹泽、橘子少女、酒吧阿姨等一系列铃芽在旅途中遇见的陌生人所引发的一系列埋怨和吐苦水的故事,可以形象地反映出《铃芽户缔》这部剧中的铃芽在旅途中遇见的陌生人所引发的一系列埋怨和吐苦水的故事,可以生动地展现出《铃芽户缔》这部剧中的铃芽对爱情的执着追求和热爱守护的精神风貌和高尚情操。
到此完。

本文为学习工程
https://github.com/OceanPresentChao/llm-corpus/记录的笔记
其它相关项目
- https://github.com/chatchat-space/Langchain-Chatchat
- https://github.com/1Panel-dev/MaxKB
- https://github.com/GanymedeNil/document.ai
- https://github.com/DemoGit4LIANG/Chat2Anything
- https://github.com/OceanPresentChao/llm-corpus
- https://github.com/yatengLG/Simple-Local-QA/
- https://github.com/newlxj/Crawling_VectorDB_LLM
- https://github.com/wzdavid/ThinkRAG
- https://github.com/littlewwwhite/KnowledgeGraph-based-on-Raw-text-A27
- https://github.com/karpathy/nanoGPT
- https://github.com/jingyaogong/minimind
- https://github.com/charent/ChatLM-mini-Chinese
- https://github.com/charent/Phi2-mini-Chinese
- https://github.com/wdndev/tiny-llm-zh



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· 易语言 —— 开山篇