麻瓜走入魔法世界 使用 Gradio 构建 Web UI
gradio 介绍
Gradio 是一个开源的 Python 套件,当你发想出各式各样的 AI 创意,想要分享给别人,这就是 Gradio 的初衷,让你快速简单建立互动人工智慧模型的互动网站
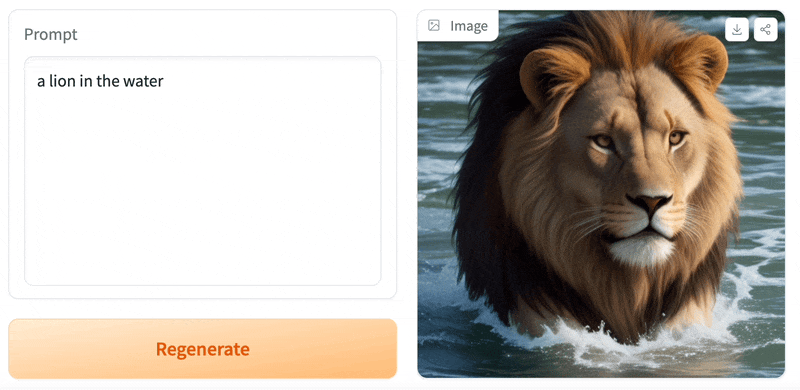
如果你也是 HuggingFace 的玩家,基本上其实很多模型贡献者的 Demosite 就是透过 Gradio 实作的。 Stable Diffusion WebUI也是 (https://stablediffusionweb.com/WebUI)
Gradio 可以提供多种不同的输入跟输出格式,像是图片,音讯档案等;使用者可以直接在浏览器中使用(测试),包括上传档案、调整参数、看到模型成效、行为表现、算法偏差。对于非工程开发人的操作与理解非常友善,可以熟悉模型的场景应用过程和结果。
最重要的是,Gradio 可以直接在 Jupyter Notebook 中呈现!
使用教程
版本要求: Python 3.8 以上
python -m venv gradio-env
.\gradio-env\Scripts\activate (Windows)
source gradio-env/bin/activate (MacOS/Linux)
pip install gradio
import gradio as gr
print(gr.__version__)
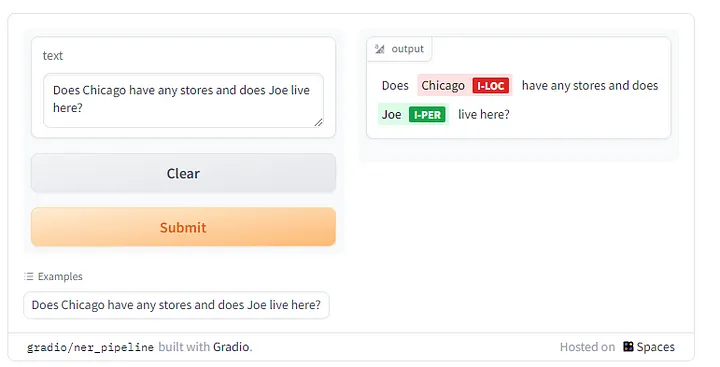
范例一: 命名实体识别
Pipeline : 简化我们使用模型的程式码,以接口的方式直接呼叫模型
使用launch启动 Gradio 界面,可以透过参数 server_name 和 server_port 自定义伺服器和端口
from transformers import pipeline
import gradio as gr
ner_pipeline = pipeline("ner") //ner is the model name
examples = [
"Does Chicago have any stores and does Joe live here?",
]
def ner(text):
output = ner_pipeline(text)
return {"text": text, "entities": output}
demo = gr.Interface(ner,
gr.Textbox(placeholder="Enter sentence here..."),
gr.HighlightedText(),
examples=examples)
demo.launch()
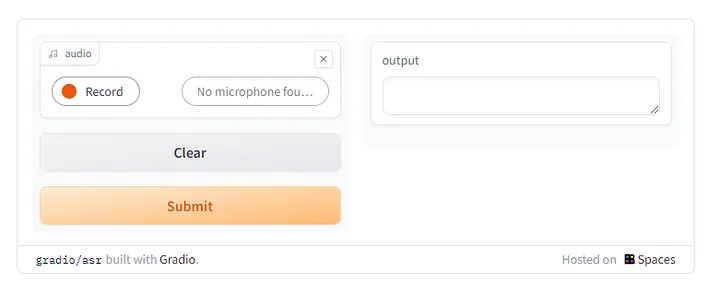
范例二 : 即时语音辨识
每当有新的片段音档产生,就会呼叫语音辨识模型 (transcriber),透过 stream 纪录音档。当音档完整被处理之后才会回传。
import gradio as gr
from transformers import pipeline
import numpy as np
transcriber = pipeline("automatic-speech-recognition", model="openai/whisper-base.en")
def transcribe(audio):
sr, y = audio
y = y.astype(np.float32)
y /= np.max(np.abs(y))
return transcriber({"sampling_rate": sr, "raw": y})["text"]
demo = gr.Interface(
transcribe,
gr.Audio(sources=["microphone"]),
"text",
)
demo.launch()