三、Self-Attn 与 Deformable-Attn
1、Deformable Attention 的理解
Deforable Attention,是Deforable DETR 架构中使用的一个注意力模块,与传统Transformer 查询所有空间位置不同,Deformable Attention 只关注 参考点(reference Points) 附近的一组关键采样点,无需考虑特征图的大小。
2、单尺度的 Deformable Attention
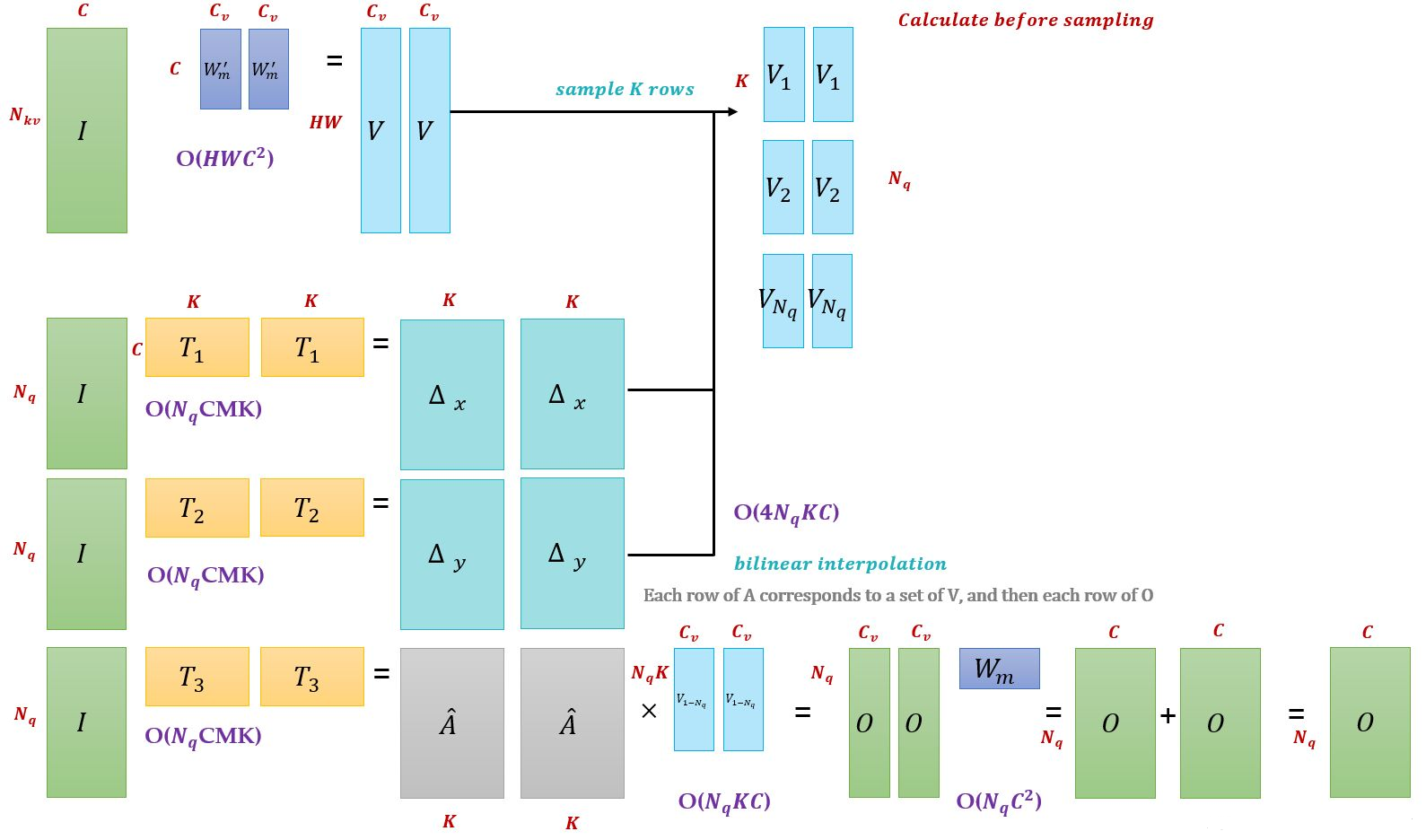
首先给出 MultiHead Attn 和 Deformable Attn 的公式,对于给定输入特征图 x∈RC×H×W,有:
在 Self Attn 中,m 表示多头注意力中的第 m 个头,z∈RC×H×W 为 query 的输入特征, 可分解为N×W 个 zq∈RC。 x∈RC×H×W 是 key 和 value 的输入特征, 可分解为N×W 个 xk∈RC。 q 是 query 的索引,k 是 key 的索引。
W′m∈RCv×C (其中Cv=C/M,分为多头) 是输入特征 xk 到 value 的转移矩阵(通常和生成 query 方式一样,也是线性变换),Wm∈RCv×C 是对注意力施加在 value 后的结果进行线性变换从而得到不同头部的输出结果。
对比下这两个公式,在 MultiHeadAttn 中:
红色部分,pq∈R2 代表 zq 的位置,即参考点 (reference points), Δpmqk∈R2 表示第 m 个注意力头中的第 k 个采样集合点相对参考点的位置偏移(offsets)。
蓝色部分, K 表示采样的 key 的总数,k∈[1,K](K<<HW), 即每个 query 在每个注意力头中采样 K 个位置,只需要和这些位置的特征进行交互,不需要和 Transformer 一样从全局位置开始学习才能逐步关注到局部、稀疏的位置。x(pq+Δpmqk) 即为基于采样点通过 双线性插值(bilinear interpolation) 转为 feature map 上的特征点得到的 value。
其中,位置偏移 Δpmqk 是可学习的,由 query 特征 zq∈RC 经过全连接层得到,注意力权重同样由 query 特征 zq∈RC 通过全连接层得到,同时在 K 个采样点之间归一化,而非像 Transformer 是由 query 与 key 交互计算得出的, Ampk∈[0,1],并且 ∑Kk=1Amqk=1.
TODO
3、多尺度的 Deformable Attention
4、源码注释
本文作者:Abyss_J
本文链接:https://www.cnblogs.com/abyss-130/p/17403238.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步