python3爬虫之验证码的识别——selenium自动识别验证码并点击提交,附源代码
https://aq.yy.com/p/reg/account.do?appid=&url=&fromadv=udbclsd_r
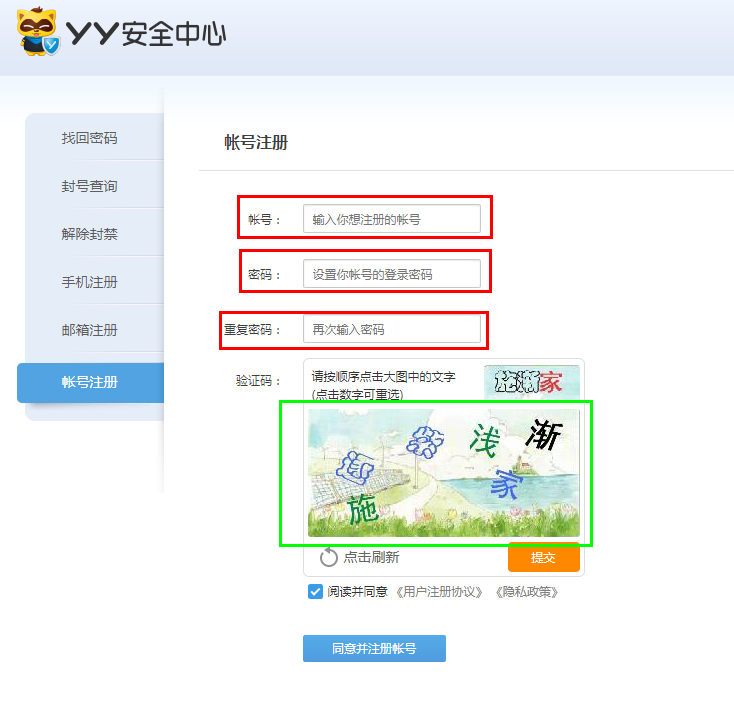
yy语音的注册页面,账号、密码、重复密码及提交按钮的实现这里不再讲解,利用selenium非常容易实现
本文只讲解如何识别绿色框里图片中文字的识别,并使用鼠标正确点击
思路:
1. 利用爬虫技术将绿色图片下载到本地
2. 使用第三方工具(本文使用超级鹰)识别图片中的文字,并返回每个文字的坐标位置
3. 根据坐标位置,使用鼠标点击
这么一说是不是显得非常简单啦!那么就一步一步来
1. 搞到这个图片,此处有一坑!
爬虫所下载下来的图片是这样的,应该是将图片切片重新排列了,然后应该是有一定的算法可以重新排列回来
但是这个算法不太好找,并且对于其他类型的网站不一定是通用的

那么我们换另外一种思路:既然原图搞不来,那么我们就利用截图!
如何截图呢?首先要定位这个元素并且获知其四个点的坐标位置
定位这个元素很简单,直接使用selenium定位class即可
image_element = browser.find_element_by_class_name('pw_subBg')
下面的问题就是获取这个元素四个点的(x,y)坐标或者其他可以确定位置的坐标
通过location方法可以获取这个元素左上角坐标;通过size可以获取这个元素的宽(width)和高(height)
location = image_element.location size = image_element.size print(location,size)
输出结果:{'x': 108.5625, 'y': 295} {'height': 128, 'width': 272}
怎样计算呢?下面画出一幅坐标图就清楚明了了!
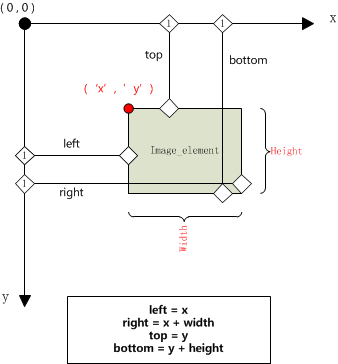
这里写出了所需位置的四个值(top, bottom, left, right),并且给出了计算公式,如果还看不明白那就帮不了你了诶……
有了位置坐标,再执行截图语句并保存图片到本地就ok了
screenshot = browser.get_screenshot_as_png() screenshot = Image.open(BytesIO(screenshot)) captcha = screenshot.crop((left,top,right,bottom)) captcha.save('captcha1.png')
验证一下保存的图片,好像截取的位置不太对,那么需要人工去设置一个偏移量
这个偏移量是我大概试出来的,暂没有研究一些好的自动测量方法
top, bottom, left, right = location['y']+128, location['y'] + size['height']+128, location['x']+181, location['x'] + size[ 'width']+181 # 手动测试偏移量
修正后的结果:423 551 289.5625 561.5625
问了度娘,这个偏移量的大小和电脑分辨率、浏览器、是否是无头模式有关系。因此可能每个人运行程序所设置的偏移量都不一样
截图结果如下:(因为每次运行程序都刷新了页面,因此本例中验证码可能不一样)

2. 调用第三方平台识别汉字并且返回所识别汉字的坐标
前提是已经下好了超级鹰的demo,并调试成功。详见我的文章《》,此次不再详述
但是需要改一个地方就是识别类型,可以改成910x,这个是返回汉字坐标值的

bytes_array = BytesIO() captcha.save(bytes_array,format('PNG')) chaojiying = Chaojiying('账户', '密码', '软件id') result = chaojiying.PostPic(bytes_array.getvalue(),9103) print(result)
运行结果:{'err_no': 0, 'err_str': 'OK', 'pic_id': '2077320412830000020', 'pic_str': '60,19|109,16|187,92', 'md5': 'c3d41675003cd44058347e591cf405e7'}
看pic_str字段,返回了3个坐标值,用 | 隔开了,需要对这个字符串进行处理
locations = result.get('pic_str').split('|') for i in locations: location = i.split(',') print(location)
3. 通过坐标值进行自动化点击操作
ActionChains(browser).move_to_element_with_offset(image_element,int(location[0]),int(location[1])).click().perform()

当然,仅到这一步还是没有完成的
注册的需求还需要识别右上角的小图中的文字,和大图中的文字做匹配,匹配成功了才点击,不成功的不点击
这里有个坑就是:超级鹰返回的要么是识别的文字,要么是坐标信息,无法同时返回两者。那么,每次返回的是一一对应的吗?这个我们现在来验证一下(为了省积分,用a.jpg):
首先先运行下
r1 = chaojiying.PostPic(im, 1902) r2 = chaojiying.PostPic(im, 9004) # 返回坐标
运行结果:
r1 = {'err_no': 0, 'err_str': 'OK', 'pic_id': '3077320552830000021', 'pic_str': '7261', 'md5': '265c70b7f6d88426fa2a77a06f450972'}
r2 = {'err_no': 0, 'err_str': 'OK', 'pic_id': '2077320552830000022', 'pic_str': '11,22|28,20|47,21|71,21', 'md5': '82948c8bf04e521
如果需要点击的数字或者汉字也是图片显示的,那么识别过程与大图一样;如果是直接给出了文本那就爬虫直接获取。这个步骤我省略了,这里假定需要点击数字7和2(无顺序)
def vs(list0,dict1,dict2): list1 = list(dict1.get('pic_str')) list2 = dict2.get('pic_str').split('|') print(list1) print(list2) dd = dict(zip(list1,list2)) print(dd) for i in list0: if i in dd: x = dd.get(i).split(',')[0] y = dd.get(i).split(',')[1] print(int(x),int(y)) # 调用点击的模块
调用结果
28 20
71 21
完美的get到了需要点击数字的坐标
源代码(全)
1 import time 2 from io import BytesIO 3 from PIL import Image 4 from selenium import webdriver 5 from selenium.webdriver import ActionChains 6 from selenium.webdriver.common.by import By 7 from selenium.webdriver.support.ui import WebDriverWait 8 from selenium.webdriver.support import expected_conditions as EC 9 from chaojiying import Chaojiying 10 11 12 # 初始化变量 13 14 EMAIL = 'diaongaodsing' 15 PASSWORD = 'mindomg301415' 16 REPASSWORD = PASSWORD 17 18 # 超级鹰用户登录名、密码、软件ID、待识别的验证码类型 19 CHAOJIYING_USERNAME = '用户名' 20 CHAOJIYING_PASSWORD = '密码' 21 CHAOJIYING_SOFT_ID = 软件ID 22 CHAOJIYING_KIND_XY = 9103 # 返回坐标 23 CHAOJIYING_KIND = 2003 #返回数字、字母或者汉字 24 25 26 class CrackTouClick(): 27 28 def __init__(self): 29 """ 30 31 """ 32 self.url = 'https://aq.yy.com/p/reg/account.do?appid=&url=&fromadv=udbclsd_r' # 待爬取的页面 33 self.browser = webdriver.Chrome() 34 self.wait = WebDriverWait(self.browser, 20) 35 self.input = EMAIL 36 self.password = PASSWORD 37 self.repassword = REPASSWORD 38 self.chaojiying = Chaojiying(CHAOJIYING_USERNAME, CHAOJIYING_PASSWORD, CHAOJIYING_SOFT_ID) 39 # def __del__(self): 40 # """ 41 # 析构函数,关闭浏览器 42 # """ 43 # self.browser.close() 44 def login(self): 45 """ 46 打开网页输入用户名、密码和再次验证密码 47 :return: None 48 """ 49 self.browser.get(self.url) 50 iframe = self.browser.find_elements_by_tag_name("iframe")[0] 51 self.browser.switch_to.frame(iframe) 52 53 input = self.browser.find_element_by_xpath('//*[@id="m_mainForm"]/div[2]/div[1]/span[2]/input') 54 password = self.browser.find_element_by_xpath('//*[@id="m_mainForm"]/div[2]/div[2]/span[2]/input') 55 repassword = self.browser.find_element_by_xpath('//*[@id="m_mainForm"]/div[2]/div[3]/span[2]/input') 56 57 input.send_keys(self.input) 58 password.send_keys(self.password) 59 repassword.send_keys(self.repassword) 60 self.browser.find_element_by_class_name('field_title').click()# 随便找一个地方单击一下,否则无法验证输入是否正确 61 def get_image_element(self): 62 """ 63 获取验证图片对象 64 :return: 图片对象 65 """ 66 image_element_b = self.browser.find_element_by_class_name('pw_subBg') # 大图 67 image_element_s = self.browser.find_element_by_class_name('pw_expic') # 小图 68 return image_element_s,image_element_b 69 def get_position(self,image_element): 70 """ 71 获取验证码位置 72 :return: 验证码位置 73 """ 74 75 time.sleep(2) 76 location = image_element.location 77 size = image_element.size 78 top, bottom, left, right = location['y'] + 128, location['y'] + size['height'] + 128, location['x'] + 181, location['x'] + size[ 79 'width'] + 181 80 return (top, bottom, left, right) 81 def get_screen_image(self, image_element,name): 82 """ 83 获取验证码截图图片 84 :return: 图片对象 85 """ 86 top, bottom, left, right = self.get_position(image_element) 87 #print('图片位置', top, bottom, left, right) 88 screenshot = self.browser.get_screenshot_as_png() 89 screenshot = Image.open(BytesIO(screenshot)) 90 captcha = screenshot.crop((left, top, right, bottom)) 91 captcha.save(str(name)+'.png') 92 return captcha 93 94 def get_recognation_result(self,image_element,chaojiying_kind): 95 """ 96 用第三方平台超级鹰进行图片识别,返回识别结果 97 :return: <dic> 识别结果(需要的字段是‘pic_str’) 98 """ 99 image = self.get_screen_image(image_element,chaojiying_kind) 100 bytes_array = BytesIO() 101 image.save(bytes_array, format('PNG')) 102 recognation_result = self.chaojiying.PostPic(bytes_array.getvalue(),chaojiying_kind) 103 print('识别结果:',recognation_result) 104 return recognation_result 105 106 # def click_points(self,image_element, recognation_result): 107 # """ 108 # 解析识别结果并进行点击 109 # :param captcha_result: <dic>第三方识别结果 110 # :return: None 111 # """ 112 # locations = recognation_result.get('pic_str').split('|') 113 # for i in locations: 114 # location = i.split(',') 115 # #print(location) 116 # ActionChains(self.browser).move_to_element_with_offset(image_element, int(location[0]),int(location[1])).click().perform() 117 # #print('ok') 118 119 def vs(self,image_element,res_s, res_b, res_b_xy): 120 """ 121 对比,选出需要点击的汉字和坐标,并点击 122 :param image_element: 123 :param res_s: <dic> 小图识别结果(汉字) 124 :param res_b: <dic> 大图识别结果(汉字) 125 :param res_b_xy: <dic> 大图识别结果(坐标) 126 :return: None 127 """ 128 list_res_s = list(res_s.get('pic_str')) 129 list_res_b = list(res_b.get('pic_str')) 130 list_res_b_xy = res_b_xy.get('pic_str').split('|') 131 #print(list_res_s) 132 # print(list_res_b) 133 # print(list_res_b_xy) 134 dic_res_b = dict(zip(list_res_b, list_res_b_xy)) 135 print('字典格式:',dic_res_b) 136 for i in list_res_s: 137 if i in dic_res_b: 138 x = dic_res_b.get(i).split(',')[0] 139 y = dic_res_b.get(i).split(',')[1] 140 #print(int(x), int(y)) 141 ActionChains(self.browser).move_to_element_with_offset(image_element, int(x),int(y)).click().perform() 142 143 def verify_info(self): 144 """ 145 验证用户名、密码、再次密码是否符合规则,符合返回True,否则返回False 146 :return: <bool> 147 """ 148 try: 149 input_v = self.browser.find_elements_by_class_name('icon_suc')[0] 150 password_v = self.browser.find_elements_by_class_name('icon_suc')[1] 151 repassword_v = self.browser.find_elements_by_class_name('icon_suc')[2] 152 print('注册信息正确!') 153 return True 154 except: 155 print('注册信息错误!') 156 return False 157 def verify_recognation(self): 158 """ 159 验证验证码是否正确,正确返回True,否则返回False 160 :return: 161 """ 162 try: 163 self.wait.until(EC.text_to_be_present_in_element((By.CLASS_NAME, 'done_text'), '验证成功')) 164 # 使用text_to_be_present_in_element方法不能使用find_element,因为发现一直在 165 print('验证码正确!') 166 return True 167 except: 168 print('验证码错误!') 169 return False 170 def get_verify_button(self): 171 """ 172 获取验证“提交”按钮,并点击 173 :return: None 174 """ 175 verify_button = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'pw_submit'))) 176 verify_button.click() 177 def get_login_button(self): 178 """ 179 获取“同意并注册账号”按钮,并点击 180 :return: None 181 """ 182 submit_button = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="m_mainForm"]/div[2]/div[7]/a/span'))) 183 submit_button.click() 184 print('登录成功') 185 186 187 def crack(self): 188 """ 189 破解入口 190 :return: None 191 """ 192 self.login() # 登陆 193 194 image_element_s = self.get_image_element()[0]# 获取小图 195 res_s = self.get_recognation_result(image_element_s,2003) # 获取第三方识别结果 196 197 image_element_b = self.get_image_element()[1]# 获取大图 198 res_b = self.get_recognation_result(image_element_b,2006) # 获取第三方识别结果 199 200 res_b_xy = self.get_recognation_result(image_element_b,9008) # 获取第三方识别结果 201 202 self.vs(image_element_b,res_s,res_b,res_b_xy) 203 204 self.get_verify_button() # 点击“验证”按钮 205 if self.verify_info() is True and self.verify_recognation() is True: 206 #如果信息符合规则且验证码正确,点击“注册”按钮 207 time.sleep(2) 208 self.get_login_button() 209 210 211 if __name__ == '__main__': 212 crack = CrackTouClick() 213 crack.crack()
测试了几次发现题分没了……赶紧去充钱,好在1元=1000题分
试了几次只有一次是完全正确的,但是单独识别某一个图是没有问题的呀!难道是我刷新的太快了吗……因为无法同时获取汉字和其坐标,导致两次返回的数量很有可能不一致!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号