
Python3爬取起点中文网阅读量信息,解决文字反爬~~~附源代码
起点中文网,在“数字”上设置了文字反爬,使用了自定义的文字文件ttf
通过浏览器的“检查”显示的是“□”,但是可以在网页源代码中找到映射后的数字
正则爬的是网页源代码,xpath是默认utf-8解析网页数据,用xpath爬出来的也是方框,因此只能使用正则匹配爬取关键数字信息
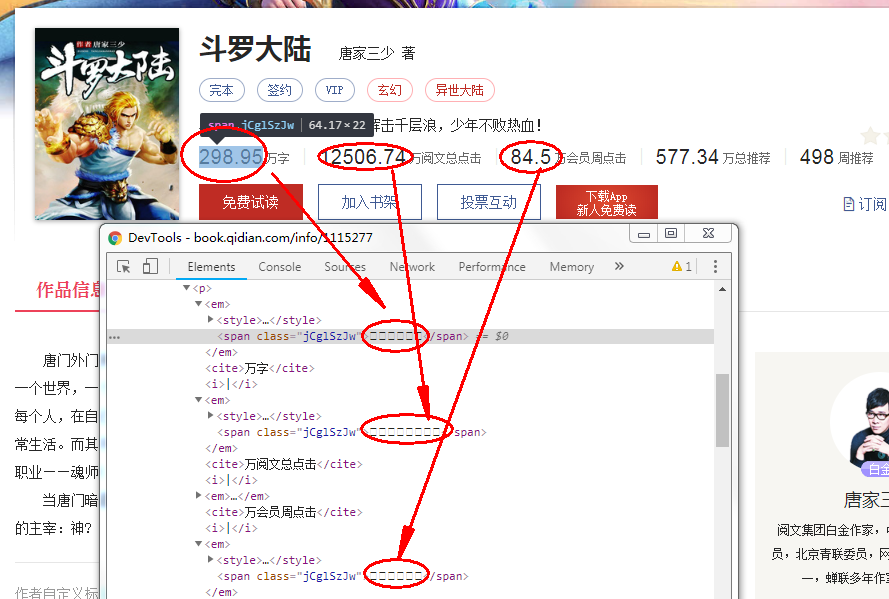

本例以小说《斗罗大陆》为例 https://book.qidian.com/info/1115277,爬取阅读量等数字信息
爬取思路:
1. 使用正则匹配爬取出网页源代码中的被设置反爬的数字信息(这里只能使用正则匹配)
2. 寻找数字的映射关系
2.1 爬取出网页中的字体文件地址,并下载这个文件
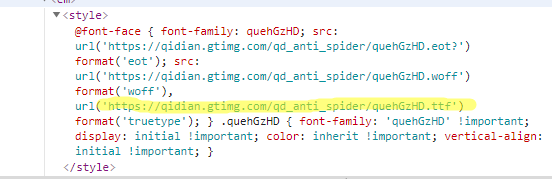
2.2 使用软件FontCreator(请度娘自行下载)打开文件,可以看到英文和数字的对应关系,写入字典
在本例中是按照习惯对应的(有可能有的文件自定义是打乱的)

#在fontcreator中查看此ttf文件中英文单词与阿拉伯数字的映射关系,写入字典 python_font_relation = { 'one':1, 'two':2, 'three':3, 'four':4, 'five':5, 'six':6, 'seven':7, 'eight':8, 'nine':9, 'zero':0, 'period':'.' }
2.3 在python中安装fontTools包,网页源代码中的数字与英文单词的对应关系
def get_font(url): """ 获取源代码中数字信息与英文单词之间的映射关系 :param url: <str> 网页源代码中的字体地址 :return: <dict> 网页字体映射关系 """ time.sleep(1) response = requests.get(url) font = TTFont(BytesIO(response.content)) web_font_relation = font.getBestCmap() font.close() return web_font_relation
结果是:

3. 通过2.2与2.3 可以看出来解码需要两步:
第一步:将正则匹配出来的6位数字先转换成英文单词
第二步:将英文单词转换成阿拉伯数字
然后就ok啦

源代码:
1. 正则匹配没有展开讲,自行度娘吧
2. 有一些简单的数据处理工作,细心点一步一步来,实在不行就每次都输出看一下
1 """ 2 起点中文网,在“数字”上设置了文字反爬,使用了自定义的文字文件ttf 3 浏览器渲染不出来,但是可以在网页源代码中找到映射后的数字 4 正则爬的是网页源代码 xpath是默认utf-8解析网页数据;网页源代码有数据,使用浏览器"检查"是方框,用xpath爬出来的也是方框 5 以小说《斗罗大陆》为例 https://book.qidian.com/info/1115277 6 """ 7 import requests, time, re, pprint 8 from fontTools.ttLib import TTFont 9 from io import BytesIO 10 from lxml import etree 11 12 #此代码使用bs和xpath均无法爬出,需使用正则匹配 13 #selector = etree.HTML(html_data.text) 14 #word1 = selector.xpath('//div[2]/div[6]/div[1]/div[2]/p[3]/em[1]/span/text()') 15 16 def get_font(url): 17 """ 18 获取源代码中数字信息与英文单词之间的映射关系 19 :param url: <str> 网页源代码中的字体地址 20 :return: <dict> 网页字体映射关系 21 """ 22 time.sleep(1) 23 response = requests.get(url) 24 font = TTFont(BytesIO(response.content)) 25 web_font_relation = font.getBestCmap() 26 font.close() 27 return web_font_relation 28 29 30 #在fontcreator中查看此ttf文件中英文单词与阿拉伯数字的映射关系,写入字典 31 python_font_relation = { 32 'one':1, 33 'two':2, 34 'three':3, 35 'four':4, 36 'five':5, 37 'six':6, 38 'seven':7, 39 'eight':8, 40 'nine':9, 41 'zero':0, 42 'period':'.' 43 } 44 45 def get_html_info(url): 46 """ 47 解析网页,获取文字文件的地址和需要解码的数字信息 48 :param url: <str> 需要解析的网页地址 49 :return: <str> 文字文件ttf的地址 50 <list> 反爬的数字,一维列表 51 """ 52 headers = { 53 'User-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' 54 } 55 html_data = requests.get(url, headers=headers) 56 # 获取网页的文字ttf文件的地址 57 url_ttf_pattern = re.compile('<style>(.*?)\s*</style>',re.S) 58 fonturl = re.findall(url_ttf_pattern,html_data.text)[0] 59 url_ttf = re.search('woff.*?url.*?\'(.+?)\'.*?truetype', fonturl).group(1) 60 61 # 获取所有反爬的数字 62 word_pattern = re.compile('</style><span.*?>(.*?)</span>', re.S)#制定正则匹配规则,匹配所有<span>标签中的内容 63 numberlist = re.findall(word_pattern, html_data.text) 64 65 return url_ttf,numberlist 66 67 68 def get_encode_font(numberlist): 69 """ 70 把源代码中的数字信息进行2次解码 71 :param numberlist: <list> 需要解码的一维数字信息 72 :return: 73 """ 74 data = [] 75 for i in numberlist: 76 fanpa_data = '' 77 index_i = numberlist.index(i) 78 words = i.split(';') 79 #print('words:',words) 80 for k in range(0,len(words)-1): 81 words[k] = words[k].strip('&#') 82 #print(words[k]) 83 words[k] = str(python_font_relation[web_font_relation[int(words[k])]]) 84 #print(words[k]) 85 fanpa_data += words[k] 86 #print(fanpa_data) 87 data.append(fanpa_data) 88 print(data[0],'万字') 89 print(data[1], '万阅文总点击') 90 print(data[2], '万会员周点击') 91 print(data[3], '万总推荐') 92 print(data[4], '万周推荐') 93 # return data 94 95 """程序主入口""" 96 if __name__=='__main__': 97 url = 'https://book.qidian.com/info/1115277' # 选取某一小说 98 get_html_info(url) 99 web_font_relation = get_font(get_html_info(url)[0]) 100 pprint.pprint(web_font_relation)#格式化打印网页文字映射关系 101 get_encode_font(get_html_info(url)[1])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号