

数据结构--图
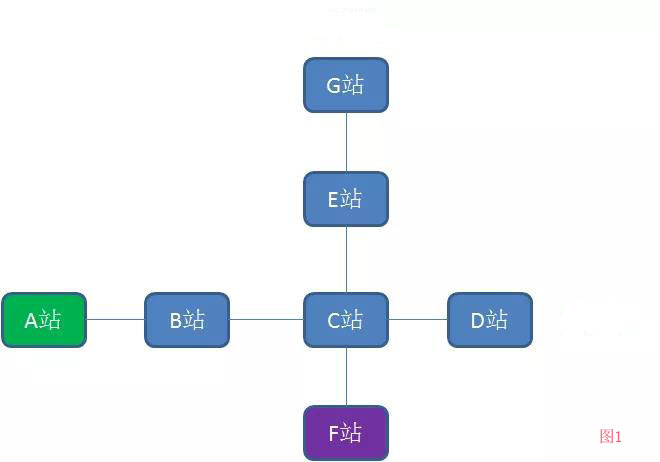
(如图1)图的顶点是多对多的关系,并且没有父子(层级)关系;
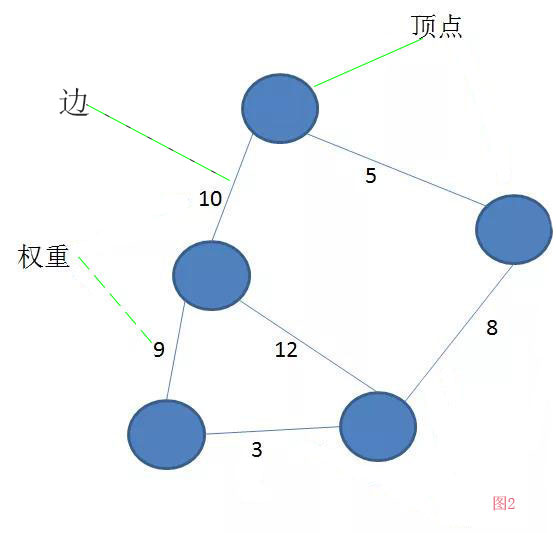
(如图2)最基本单元顶点,顶点之间的关系叫做边,边的长度叫做权重,涉及到权重的的图叫带权图。
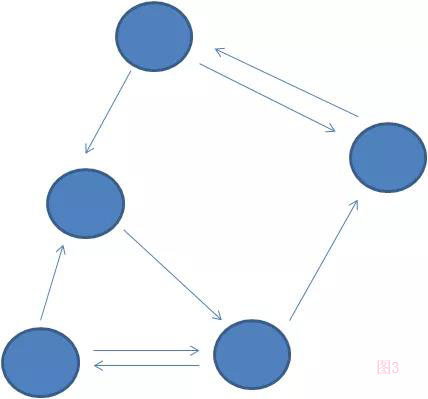
(如图3)带方向的图叫有向图
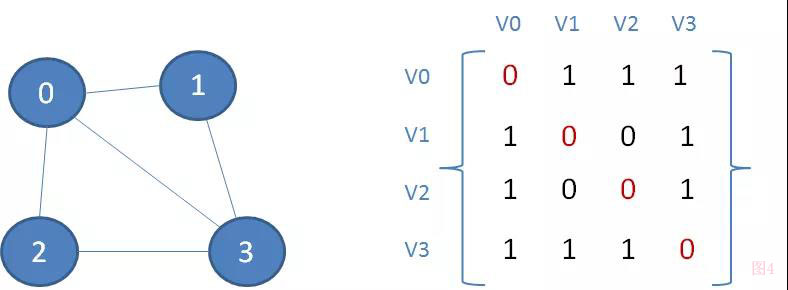
(图4)无向图邻接矩阵
拥有n个顶点的图,它所包含的连接数量最多是n(n-1)个。因此,要表达各个顶点之间的关联关系,最清晰易懂的方式是使用二维数组(矩阵)。
因为是无向图所以A[V0][V1]和A[V1][V0]的值是一样的。
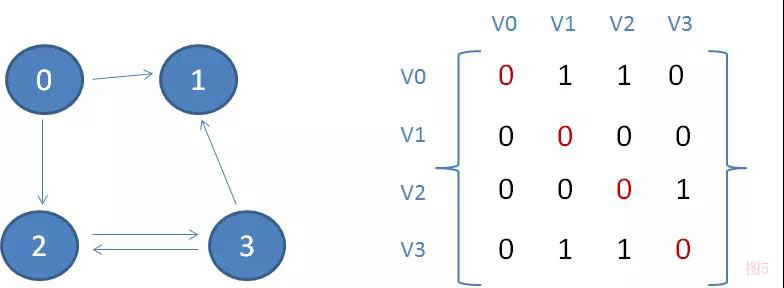
(如图5)有向图邻接矩阵,A[V0][V1]=1,A[V1][V0]=0因为单向不可达所以为0
邻接矩阵的缺点:用了太多的空间,如果一个图有1000个顶点,其中只有10个顶点之间有关联,却不得不建立一个1000X1000的二维数组,浪费空间。
(如图6)邻接表和逆邻接表(在邻接表中,图的每一个顶点都是一个链表的头节点,其后连接着该顶点能够直接达到的相邻顶点。)
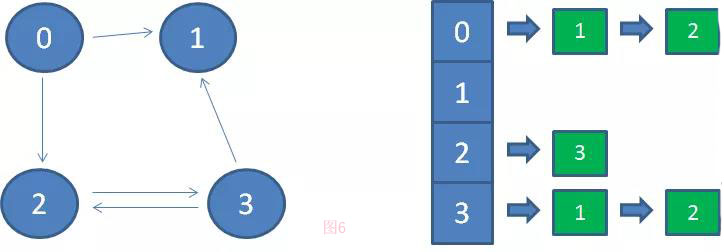
很明显,这种邻接表的存储方式,占用的空间比邻接矩阵要小得多。
要想查出从顶点0能否到达顶点1,该怎么做呢?很简单,我们从顶点0开始,顺着链表的头节点向后遍历,看看后继的节点中是否存在顶点1。
要想查出顶点0能够到达的所有相邻节点,也很简单,从顶点0向后的所有链表节点,就是顶点0能到达的相邻节点。
那么,要想查出有哪些节点能一步到达顶点1,又该怎么做呢?这样就麻烦一些了,我们要遍历每一个顶点所在的链表,看看链表节点中是否包含节点1,最后发现顶点0和顶点3可以到达顶点1。
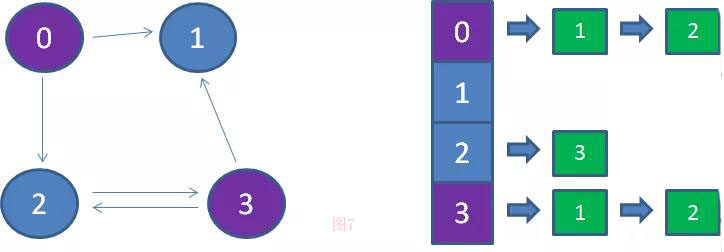
像这种逆向查找的麻烦,该如何解决呢?我们可以是用逆邻接表(图7)来解决。
逆邻接表每一个顶点作为链表的头节点,后继节点所存储的是能够直接达到该顶点的相邻顶点。
因此,我们可以根据实际需求,选择使用邻接表还是逆邻接表。
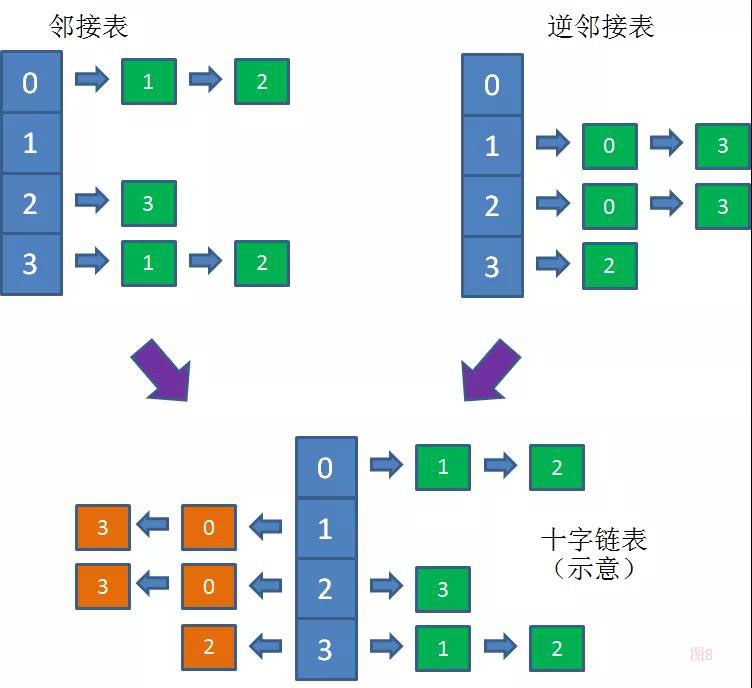
如图所示,十字链表的每一个顶点,都是两个链表的根节点,其中一个链表存储着该顶点能到达的相邻顶点,另一个链表存储着能到达该顶点的相邻节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号