

python的初识
解释型语言 和编译型语言
计算机本身不能识别高级语言,当我们运行一个程序的时候,需要一个“翻译” 来把 高级语言转换成计算机能读懂的语言。 “翻译”过程分两种:
- 编译 编译型语言在执行程序前,首先会通过编译器执行一个编译的过程,把程序编译成机器语言。 之后,程序再次运行的时候,就不要“翻译”了,而是可以直接执行。比如C语言。 编译型语言的优点在于在运行程序的时候不用解释,可直接利用已经翻译过的文件。
- 解释 解释型语言就没有编译的过程,而是在程序运行的时候,通过解释器逐行解释代码,然后运行。比如python。
java等基于虚拟机的语言兴起之后,编程语言又不能单纯的在划分为编译型语言或解释型语言。 java是首先通过编译器将代码编译成字节码文件,然后在JVM执行java字节码,将其解释成机器语言。 所以我们说java是一种半编译半解释的语言。
C#,在第一次执行的时候,将代码编译成IL中间码文件,然后由JIT编译器编译成本地的机器码执行。 相当于编译了两次。
关于python,看下面详解。
python环境部署:
一、安装python:(2.7和3.6通用)
1、windows:


1 (1)、下载安装包 2 https://www.python.org/downloads/ 3 4 (2)、安装 5 默认安装路径:C:\python27 6 7 (3)、配置环境变量 8 【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】 9 如:原来的值;C:\python27,切记前面有分号
2、linux:
1 无需安装,原装Python环境 2 ps:如果自带2.6,请更新至2.7
二、python的更新:
1、windows:
1 重新安装即可。
2、python:
1 查看默认Python版本 2 python -V 3 4 1、安装gcc,用于编译Python源码 5 yum install gcc 6 7 2、下载源码包,https://www.python.org/ftp/python/ 8 9 3、解压并进入源码文件 10 11 4、编译安装 12 ./configure 13 make all 14 make install 15 16 5、查看版本 17 /usr/local/bin/python2.7 -V 18 19 6、修改默认Python版本 20 mv /usr/bin/python /usr/bin/python2.6 21 ln -s /usr/local/bin/python2.7 /usr/bin/python 22 23 7、防止yum执行异常,修改yum使用的Python版本 24 vi /usr/bin/yum 25 将头部 #!/usr/bin/python 修改为 #!/usr/bin/python2.6
python的入门:
一、python的操作模式:
1、交互模式:
1 >>> import sys 2 >>> print(sys.path) 3 ['D:\\软件\\pychar\\PyCharm 5.0.3\\helpers\\pydev', 'E:\\python35\\lib\\site-packages\\pymysql3-0.5-py3.5.egg', 'D:\\软件\\pychar\\PyCharm 5.0.3\\helpers\\pydev', 'E:\\python35\\python35.zip', 'E:\\python35\\DLLs', 'E:\\python35\\lib', 'E:\\python35', 'E:\\python35\\lib\\site-packages', 'D:\\软件\\pychar\\data']
2、文本模式:
1 vim test.py 2 3 #!/usr/bin/env python 4 # -*- coding:utf8 -*- 5 print 'hellp world' 6 保存退出 7 8 python text.py
3、客户端模式:
1 使用pychar 5进行编译
二、python的代码:
1、错误提示:
1 >>> prtin 'hello world' 2 File "<stdin>", line 1 3 prtin 'hello world' 4 ^ 5 SyntaxError: invalid syntax 6 异常类型: 7 SyntaxError:语法错误。 8 invalid syntax:无效的语法。
1 >>> print 'hello world' 2 hello world 3 4 >>> exit()
2、正常代码
在 /data/python 目录下创建 hello.py 文件,内容如下:
1 print "hello,world"
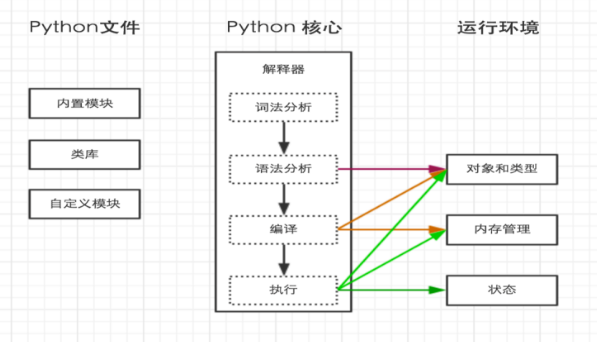
python内部执行过程如下:
3、编辑器:
Shebang 是一个由井号和叹号构成的字符串行(#!), 其出现在文本文件的第一行的前两个字符. 在文件中存在Shebang的情况下, 类Unix操作系统的程序载入器会分析Shebang后的内容, 将这些内容作为解释器指令, 并调用该指令, 并将载有Shebang的文件路径作为该解释器的参数。#!先用于帮助内核找到Python解释器, 但是在导入模块时, 将会被忽略. 因此只有被直接执行的文件中才有必要加入#!.
上一步中执行 python /data/python/hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
1 #!/usr/bin/env python 2 3 print (hello,world)
如此一来,执行: ./hello.py 即可。
注意:执行前需给予 hello.py 执行权限,chmod 755 hello.py
三、python的架构:
了解了python程序的执行过程,那么也应该了解python的整体架构是什么。 python的整体架构可以分为三个主要的部分。
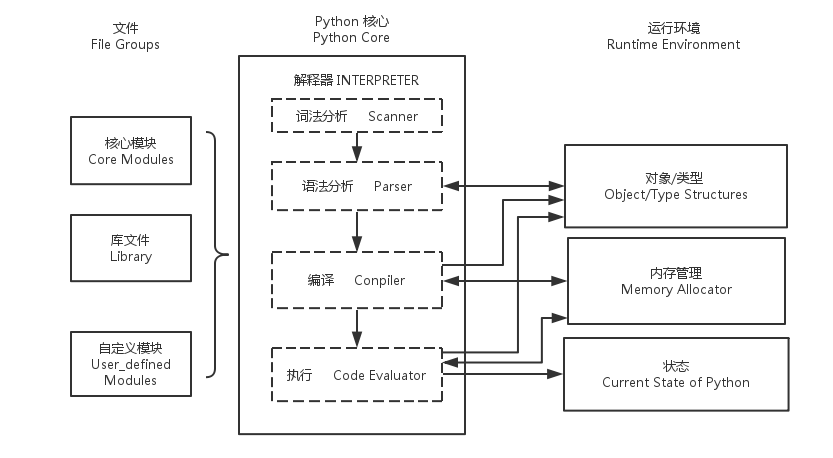
1 左边的部分 python提供的大量模块、库 和用户自定义的模块。 2 中间的部分 python的核心——解释器,也可以叫虚拟机,这里的箭头方向是python运行过程中数据流的方向, Scanner对应词法分析,用来将文件或命令输入的每一行代码切分为一个个的token; Parser对应语法分析,在Scanner的分析结果上进行语法分析,建立抽象语法树(AST); Compiler 则根据建立的AST 生成指令集合——字节码; Code Evaluator 执行字节码文件,所以又被称为虚拟机。 3 右边的部分 对象/类型、内存分配 和解释器之间的箭头表示两者之间的“使用”关系; 运行时状态与解释器之间的箭头表示“修改”关系。python在执行的过程中会不断的修改当前解释器的所处的状态,在不同的状态之间切换。
四、内容编码
我们在显示器看见的文字图片等信息在电脑上存储的时候并不是我们看到的样子。如果你拆开硬盘,把里面的盘片拿出来用显微镜来看就会看到上面有很多凹凸的地方。和我们平时见到的光盘类似。凹凸的位置分别表示0和1。这是因为在电脑中电信号只有两种状态,有电和没电。在存储数据的时候,如果我们要保存一个字母“A”,那么就可以用一定长度的0和1来表示。比如说用“01000001”来表示A。有了这样的对应关系,我们就可以保存我们平时见到的一些字符了。
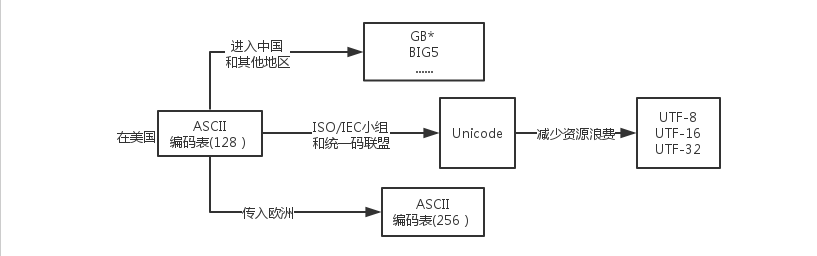
于是就是有ASCII(美国(国家)信息交换标准(代)码),使用7个或8个二进制位进行编码的方案,最多可以给256个字符。使用了ASCII码,不同的计算机之间就可以实现数据的标准化。
但是ASCII使用的时候有一些限制。他最多之可以表示256个字符。如果有其他的字符就无能为力了。ASCII只能表示26个基本的拉丁字母、阿拉伯数字和英式标点。因此也只能用于显示现代美国英语。
后来计算机世界开始有了其他语言,ASCII码已经无法满足需求。后来不同语言的人各自为自己定制了一套属于自己的编码,同时与ASCII保持兼容。这些编码统称MBCS,到了这里大家都开始好似用双字节。(中国的叫GB*,比如GBK).
在后来有人开始觉得,这么多编码,有些编码之间还不兼容,太让人头大了,于是有这么一群人就坐在一起想出了一个办法:所有的语言都使用同一种编码,这种编码就是Unicode。 Unicode使用最少2个字节(1个字节=1BYTE=8bit=一个长度为8的二进制数) 来表示字母和符号等,有时候是4个字节。这样就解决了上面遇到的问题。
Unicode又叫万国码,是业界的一种标准。但是有人又觉得如果我要表示一个ASCII里的字符,使用unicode来表示不是太浪费空间了吗,于是就有人想出了另外一种解决方案——UTF-8。
UTF-8是对Unicode编码的压缩和优化,最大的特点是它采用了变长的编码方式,他不再是最少使用2个字节,而是将所有的字符进行分类。ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存…
1、ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。

2、不同编码之间的关系
python2中文件的默认编码为ASCII,在文件中含有中文的时候就会报错,这时,我们需要是设置一下文件的默认编码,如下:
#!/usr/bin/env python # -*- coding: UTF-8 -*- # 指定python文件编码方式
在python3中,文件的默认编码为UTF-8,已经不存在这个问题。
五、注释
当行注视:# 被注释内容
多行注释:""" 被注释内容 """
六、执行脚本传入参数
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
- Python内部提供的模块
- 业内开源的模块
- 程序员自己开发的模块
Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 import sys 5 6 print sys.argv
七、 pyc 文件
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
八、Python标识符:
1 1、在python里,标识符有字母、数字、下划线组成。 2 3 2、在python中,所有标识符可以包括英文、数字以及下划线(_),但不能以数字开头。 4 5 3、python中的标识符是区分大小写的。 6 7 4、以下划线开头的标识符是有特殊意义的: 8 a、以单下划线开头(_foo)的: 9 代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用"from xxx import *"而导入; 10 11 b、以双下划线开头的(__foo)的: 12 代表类的私有成员; 13 14 c、以双下划线开头和结尾的(__foo__)的: 15 代表python里特殊方法专用的标识,如__init__()代表类的构造函数。
九、python保留字符:
1 and exec not 2 assert finally or 3 break for pass 4 class from print 5 continue global raise 6 def if return 7 del import try 8 elif in while 9 else is with 10 except lambda yield
十、行和缩进:
学习Python与其他语言最大的区别就是,Python的代码块不使用大括号({})来控制类,函数以及其他逻辑判断。python最具特色的就是用缩进来写模块。
缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。
1 if True: 2 3 print "True" 4 else: 5 print "False" 6 7 8 9 以下代码将会执行错误: 10 11 if True: 12 print "Answer" print "True" 13 else: 14 print "Answer" 15 print "False"
因此,在Python的代码块中必须使用相同数目的行首缩进空格数。
十一、多行语句:
Python语句中一般以新行作为为语句的结束符。
但是我们可以使用斜杠( \)将一行的语句分为多行显示,如下所示:
1 total = item_one + \ 2 item_two + \ 3 item_three 4 5 语句中包含[], {} 或 () 括号就不需要使用多行连接符。如下实例: 6 days = ['Monday', 'Tuesday', 'Wednesday', 7 'Thursday', 'Friday']
十二、python的引号:
Python 接收单引号(' ),双引号(" ),三引号(''' """) 来表示字符串,引号的开始与结束必须的相同类型的。
其中三引号可以由多行组成,编写多行文本的快捷语法,常用语文档字符串,在文件的特定地点,被当做注释
1 word = 'word' 2 sentence = "This is a sentence." 3 paragraph = """This is a paragraph. It is 4 made up of multiple lines and sentences."""
注意:''' ''' 引号除了能当字符串格式化,还能当做注释来使用
十三、python空行:
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
空行与代码缩进不同,空行并不是Python语法的一部分。书写时不插入空行,Python解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
记住:空行也是程序代码的一部分。
十四、同一行显示多条语句:
python 可以在同一行中使用多条语句,语句之间使用分号(;)分割,以下是一个简单的实例:
1 #!/usr/bin/python 2 import sys; x = 'foo'; sys.stdout.write(x + '\n')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号