RTMP 推流之 Native 开发(MacOS/IOS)
1. 项目介绍
使用 ffmpeg 中的 librtmp 模块,经过交叉编译,封装成 C++ 的接口,将其集成到 xcode 项目中,采集PCM编码aac,采集YUV编码H264,然后向 srs 服务端推流 flv。
该项目基于 Mac 平台,仅有极少量代码和 IOS 平台的不一致,不一致的地方主要有UI部分、用于视频预览显示的 CALayer 的使用、音频采集的通道数。其它基本都是可以互相移植的。在WebRTC、AppRTC、ffmpeg 的代码里也可以看见Mac、IOS平台的Audio、Video编程仅有少量的差异。
本文对librtmp的使用不做主要讲解。曾经花了很大功夫学习这一块的数据封装,要单独写的话又是很长一篇文章。
尝试了网上的很多Demo,对于IOS、MacOS的音频处理,得到的音质是在是差强人意,该程序最大的痛点就是解决了原生API编码、音频正确处理,最终得到高清晰的音频。尤其是在Mac平台下,能正确处理音频的参考程序,可以在Mac平台的Java源码中找到,可以在WebRTC中找到,可以在ffmpeg中找到,都是一些非常大型的项目,想要彻底掌握,不得不从头开始。
本文主要对 MacOS 上音视频编码、推流、区别于 IOS 的地方以及一些主要要注意的地方做总结。
数据采集:
使用 AVCaptureSession 捕获 interleaved 数据,分别将音视频编码后的数据存储到队列中,然后通过音视频发送线程将音视频发送到srs端。
音视频编码方式的选择:
为了学习更底层的原理,此处不使用第三方库编码,除了 librtmp,不使用任何和 ffmpeg 相关的内容,全部使用原生接口。
难点:
rtmp 封装 flv,网上有大量的Demo程序可以参考。在此之前自己已经完成了解封装 MP4 并将音视频封装成 flv 进行推流播放的程序,掌握了Annex-B 和 avcC 的互转,有了一定的基础。
音频编码使用 CoreAudio 的 API,对于该API的掌握,需要较多精力去熟悉,网上有大量复杂的程序可以参考,然而最核心的关键点却需要自己的掌握,对于IOS平台,这一块不是难点,但是在Mac上因为硬件的差异,数据的采集有了多通道的概念,并且部分参数受节能模式的影响,如果处理不好这些问题,就会导致程序总是崩溃。翻阅大量的参考资料,GIt代码,并未获得太大助益。最后,在参考了苹果官方 Demo 的基础上,才掌握并吃透。
对于视频编码,参考成熟稳定的硬件编码模块,对输出H264的格式进行分析,使其适用于 RTMP 的数据传输格式。
网上关于 Mac 的 CoreAudio 的资料非常之少,要想掌握到核心的技术,官方Demo成了最好的参考。虽然大部分Demo年代久远,代码混乱,但是经过整理加工,精简,吸收消化,还是比网上的其他教程资料要好很多。
补充:
音视频采集、编码部分的回调,涉及到多线程异步调用,而 RTMP 的数据发送是单个 socket 通道的,如果不把编码结果存储起来就直接发送,音视频编码后就同时直接对socket进行写操作,异步的操作导致两者可能同时发生,从而对同一fd的同时写操作触发 SIG ABORT,导致程序崩溃,因此,将音视频编码结果分开存储,然后再通过另一个线程交错发送,就能正常推流了。
为什么要在采集完数据后直接在各自的线程中进行编码?因为硬件编码耗时较少,且音视频的输出设置了缓冲队列,编码结果直接存储到队列,不会发生严重的阻塞导致数据被 Drop 掉。
2. 要点解析
① 添加音视频输出队列:
videoOutputQueue = dispatch_queue_create("videoDataOutputQueue", DISPATCH_QUEUE_SERIAL); [videoOutput setSampleBufferDelegate : (id)self queue : videoOutputQueue]; videoOutput.alwaysDiscardsLateVideoFrames = NO;
音频也是一样的代码结构,参照如上添加即可。
② 音频格式设置:
在 AVCaptureSesion 中,以下的内容是需要配置的,这一点只在官方的Demo中找到了。以下的每个键值都要设置才行。
NSDictionary *settings =
[NSDictionary dictionaryWithObjectsAndKeys :
[NSNumber numberWithUnsignedInt : kAudioFormatLinearPCM], AVFormatIDKey,
[NSNumber numberWithFloat : canonicalAUFormat.mSampleRate], AVSampleRateKey,
[NSNumber numberWithUnsignedInteger : canonicalAUFormat.mChannelsPerFrame], AVNumberOfChannelsKey,
[NSNumber numberWithInt : canonicalAUFormat.mBitsPerChannel], AVLinearPCMBitDepthKey,
[NSNumber numberWithBool : isFloat], AVLinearPCMIsFloatKey,
[NSNumber numberWithBool : isNonInterleaved], AVLinearPCMIsNonInterleaved,
[NSNumber numberWithBool : isBigEndian], AVLinearPCMIsBigEndianKey,
nil];
audioOutput.audioSettings = settings;
在CaptureSession开始运行后,将以上PCM格式设置进去,才能输出适合转码的数据格式。
多通道的 PCM 数据转 AAC 要求非交错的 PCM 数据。
③ 数据回调:
- (void)captureOutput : (AVCaptureOutput *) output didOutputSampleBuffer : (CMSampleBufferRef) sampleBuffer fromConnection : (AVCaptureConnection *) connection { // 自定义协议 CameraCaptureDelegate,通过 CapturerOutputAudioDataCallback 、CapturerOutputVideoDataCallback 获取数据 if (! self.delegate) { return; } if (output == videoOutput) { if ([_delegate respondsToSelector : @selector(CapturerOutputVideoDataCallback:)]) { [_delegate CapturerOutputVideoDataCallback : sampleBuffer]; } } else { if ([_delegate respondsToSelector : @selector(CapturerOutputAudioDataCallback:)]) { [_delegate CapturerOutputAudioDataCallback : sampleBuffer]; } } }
输出的 Raw Data 经过判断后,视频输入到视频编码器,音频输入到音频编码器。
2.1 视频编码
这里的关键在于要关注数据输出格式,网上的代码要经过调整才能适用于RTMP的推流。
先说 srs 的 h264 推流要求:
① h264的 nalu 可以不带 startcode,直接发送给srs,但是中间如果有分隔符则不能省略,3字节的还是4字节不影响什么,但是就是不能省;
② sps、pps的发送,中间不需要增强帧,sps、pps不带 startcode,中间用三或四字节的分隔符分隔,一次性完整发送过去;
③ 发送完sps、pps后才能发送其它nalu,IDR 帧和 Non-IDR 帧要被标记成为关键帧和非关键帧才能发送;
④ 视频的时间戳不能有连续重复的,否则会被自动断开连接,导致推流总是莫名其妙挂掉;
⑤ 视频的时间戳按照帧率计算可能会产生累加误差,这一点可以借助多种方式消除,计算出正确的PTS。
因此,编码的时候就要注意数据输出格式、时间戳的获取、计算:
① CMTime是存储时间戳的结构体,这里有很好的说明:参考;
② 时间戳参见以下函数获取转换,需要注意的是,如果将获取到 YUV 的 CMSampleBuffer 传入硬件编码器进行编码,编码的时候一定要传入时间戳,否则编码以后再从CMSampleBuffer去获取时间戳,就会不正确;
CMTime pts = CMSampleBufferGetOutputPresentationTimeStamp(sampleBuffer); double dPTS = (double)(pts.value) / pts.timescale * 1000; // CMSampleBufferGetOutputDecodeTimeStamp 用于获取DTS。
在视频编码器的入参处,获取到pts并经过计算传入进去:

③ 视频输出格式应符合如下要求:
将编码器输出的 annexb 进行转换,转为avcC的格式,只保留 sps、pps、IDR、Non-IDR,选择性保留SEI帧。实际上编码器输出的也就是这些帧了。
我们可以看看经过转换后编码器输出数据的格式,等号间是一帧完整的YUV编码后的nalu:
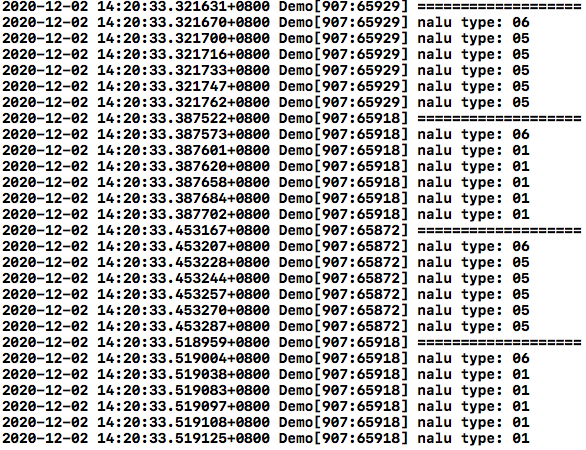
可见硬件编码器编码后的数据将一帧 IDR 或 Non-IDR 分成多了nalu,我们的程序要全部打包,使用分隔符连接连续的这几个IDR或Non-IDR,标记是否关键帧,并打上时间戳,然后一起发送给srs。
2.2 音频编码
音频数据获取的两种方式。
① 获取数据到 AudioBufferList 中,通过该函数:
size_t bufferListSizeNeededOut; CMBlockBufferRef blockBuffer = nil; XAssert_OsType(CMSampleBufferGetAudioBufferListWithRetainedBlockBuffer(sampleBuffer, &bufferListSizeNeededOut, &inPcmAbl, // Get PCM offsetof(AudioBufferList, mBuffers) + sizeof(AudioBuffer) * 2, kCFAllocatorSystemDefault, kCFAllocatorSystemDefault, kCMSampleBufferFlag_AudioBufferList_Assure16ByteAlignment, &blockBuffer));
在使用完 inPcmAbl 中获取的数据的时候,要使用 CFRelease 释放 blockBuffer 中的数据。inPcmAbl 中的数据指向 blockBuffer,数据量和交错与否、通道数有关。
② 获取数据指针,指向 blockBuffer 的PCM数据:
CMBlockBufferRef blockBuffer = CMSampleBufferGetDataBuffer(sampleBuffer); CFRetain(blockBuffer); size_t offset = 0, lengthAtOffset, totalLength; char *pBuf; CMBlockBufferGetDataPointer(blockBuffer, offset * 0, &lengthAtOffset, &totalLength, &pBuf); inAbl->mBuffers[0].mDataByteSize = (UInt32)lengthAtOffset; memcpy(inAbl->mBuffers[0].mData, pBuf, offset);
这是网上的程序用的最多的一种方式,注意多通道情况下,这里的用法很不一样。
如果不二次按照 lengthAtOffset 获取,则会越界访问,获取到脏数据,产生极大的噪音。
③ 补充:
在 Mac 上受节能模式的影响,AVCaptureSession产生的音频数据会发生变化,有时候大一些,有时候小一些,再加上多通道的数据,给整个编程调试造成了较大的困难,如果处理不好,很容易会造成程序崩溃。
④ PCM 转 AAC 要注意的地方:
Mac和IOS都可以使用 AudioConverterNew 函数创建转化器。注意封装该函数的时候如果把转换器 AudioConverterRef 参数按照传值的方式传递进来是错误的做法,创建必然会改变其值,必须使用传引用或传二级指针或用结构体封装传入,以在创建成功之后供其它函数调用。
IOS上使用硬件编码创建转换器的函数 AudioConverterNewSpec 是完全可以使用该函数代替的。
转换器需要足够数量的PCM数据才可以工作,Mac/IOS上一般为1024、2048。如果不做缓冲队列来完成转换,可能会出现各种问题。按照官方文档的说明,aac硬件编码属于转换器独占的程序,如果同时使用同一个转换器来进行 aac 编码可能会出现问题。
同样,Mac上输入的PCM数据要注意多通道的数据处理,否则可能导致程序崩溃。aac 的输出格式的 asbd 通常都是固定的,只有通道数需要调整。
⑤ 踩坑总结
总之,网上的解答也好,Demo示例也好,都不可以照搬,必须吃透这些数据结构,研究清楚这些API特性,掌握官方 Demo 的精髓,才能从根本上掌握CoreAudio的数据编码转换。
期间参考了很多资料,包括 WebRTC 的 Mac 平台的音频转换程序,发现是 PCM 到 PCM 之间的转换,并不适用,参考了 ffmpeg,发现是 PCM 转 aac 的程序,但是太庞杂没那没容易搬运出来。最后自己花大力气琢磨了几个官方Demo,再自己手动调试很久,才搞定这一块的 native aac 的编码。
3. 补充:AudioUnit的音频采集
除了AVCaptureSession获取音频数据外,还可以使用AudioUnit、AudioQueue、AVAudioSession等获取音频数据。这一块网上有很多讲解,这里只说 Mac 平台上要注意的地方:
音频输入单元的数据输入端(麦克风硬件采集的数据格式)不支持设置采样率。官方推荐的做法是使用PCM转AAC兼具PCM格式调整功能的那个函数对数据进行降速处理。在 voip 的那篇文章里介绍了一种方法就是使用降速单元。
经自己测试发现,如果同时添加了数据输出端(扬声器),则可以对音频输入单元(麦克风)的数据输出端设置较低的采样速率。但是我们的程序并不需要扬声器的输出。
以上是一个坑,翻了很多文章才在苹果的bug讨论中找到相关的解释,发现原来是硬件的问题。
在 IOS 上,本来就是较低的采样速率,可以直接转aac封装成 flv,不存在该问题。
IOS上如果使用AudioUnit是有自带的 API 可以直接支持回声消除的,Mac上虽然也有该API,但是调用总是失败,貌似不支持,官方文档未有清晰说明。
对于音频输入单元的设置,Mac 和 IOS 是有区别的,IOS是使用 RemoteIO,Mac上是使用 AUHAL,这一点参考官方文档就足够了。
4. 内存管理
刚开始,推流的时候,内存猛增,找不到原因在哪里,该 free 的数据也 free 了,为什么内存丝毫没有趋于平稳的趋势呢?
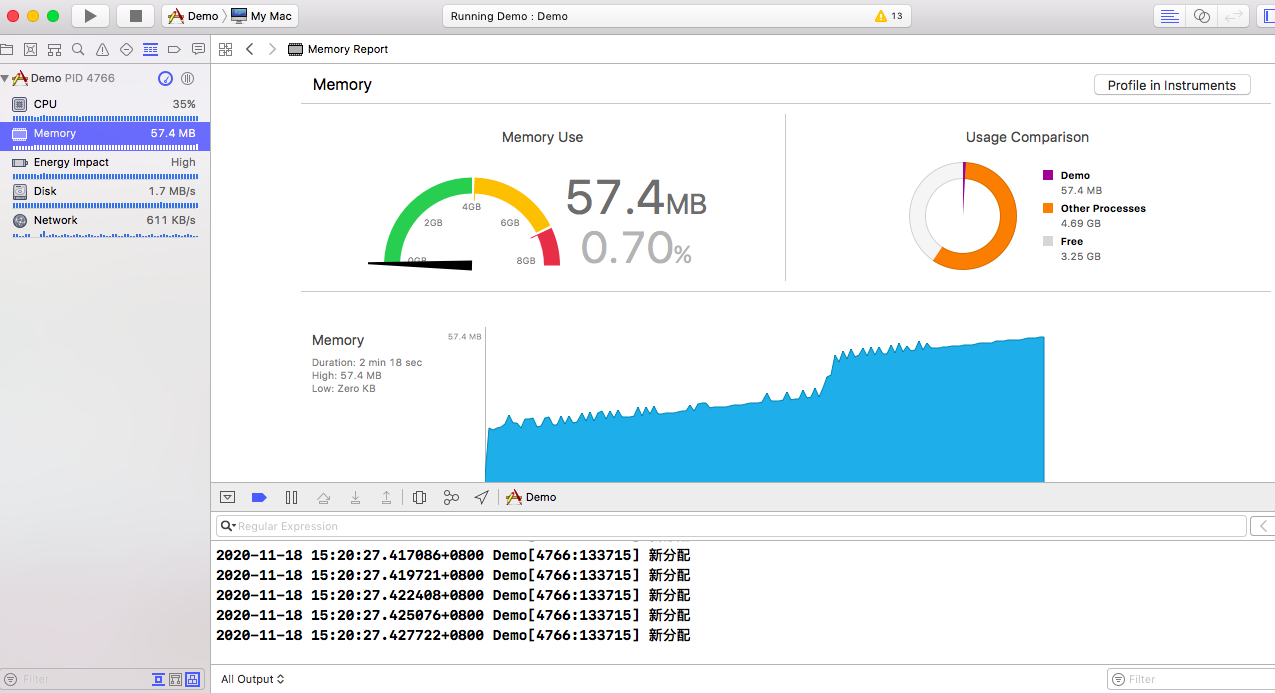
调试了半天,发现注释掉一些free函数和没有注释掉的内存增速是一样的,难道是free出了问题?但是内存空间就是 malloc 对应的 free 啊,以前遇到过new的空间用free会出现一些问题,但是增速依然没有那么快,这是为什么,好奇怪?突然想起来,CFRelease好像没有用上,加上以后,果然平稳了很多,但是依然还在增加:

然后就考虑如何进行内存回收再利用,最终决定采用如下的结构体对内存进行回收管理:
核心思想是:对于PCM、AAC、H264数据,分配固定大小的内存进行存储,PCM用来传给音频编码器,获取PCM数据之前先查询 pcm_queue_for_reuse 里面是否有可用空间,如果有则使用已有的,从 pcm_queue_for_reuse 获取内存空间存储 PCM 数据,否则新创建存储空间,获取到数据以后存储到 pcm_queue 中,编码器从 pcm_queue 中获取数据进行编码,编码完成后将本该释放的节点,重新加入到 pcm_queue_for_reuse 队列中以供下次获取数据继续使用,从而达到能存空间重复使用的目的,避免了更复杂的代码逻辑和可能发生的内存泄露。
其它两个,AAC、H264 数据队列也是采用这种思想,将发送完的数据重新加入到 resuse 队列中以供下次使用。
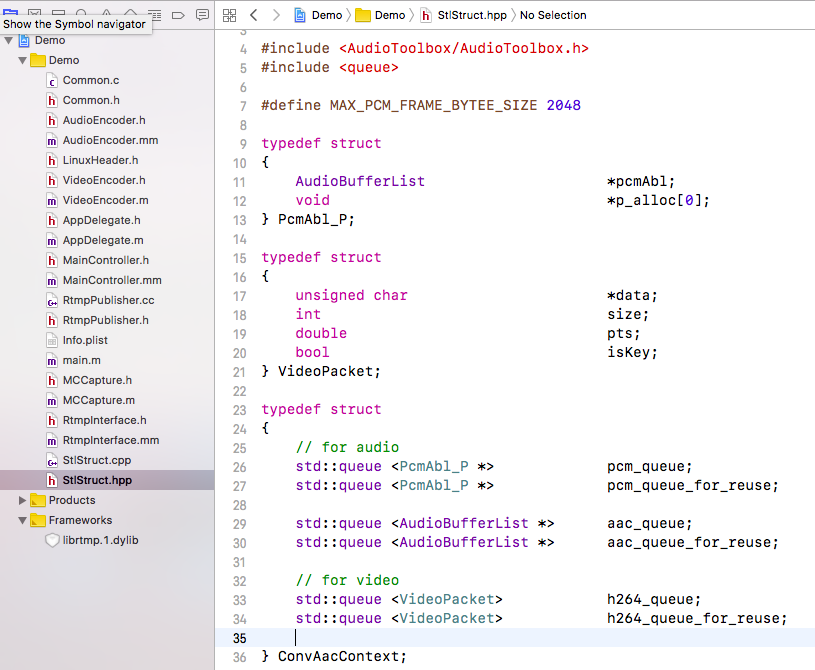
为什么采用这种方式管理内存?
当初遇到存储在 stl 的 queue 的结构中的内存空间(使用malloc分配),使用 free 却不能有效释放,网上有这样的解答,说要做内存池来解决这个问题,由于音视频数据的大小是有边界的,就统一采用了固定大小的空间统一管理。
关于使用 free 不能有效释放的问题,可能是受到ARC的影响,但是本人在测试中,发现在同一函数中是可以有效释放的,后来想起来是不是ARC+跨函数malloc、free导致的问题,有待进一步验证。时间所限,还是以学习音视频为主,并且本人也只是主攻C/C++这一套技术栈。
果然,这下子终于好多了:
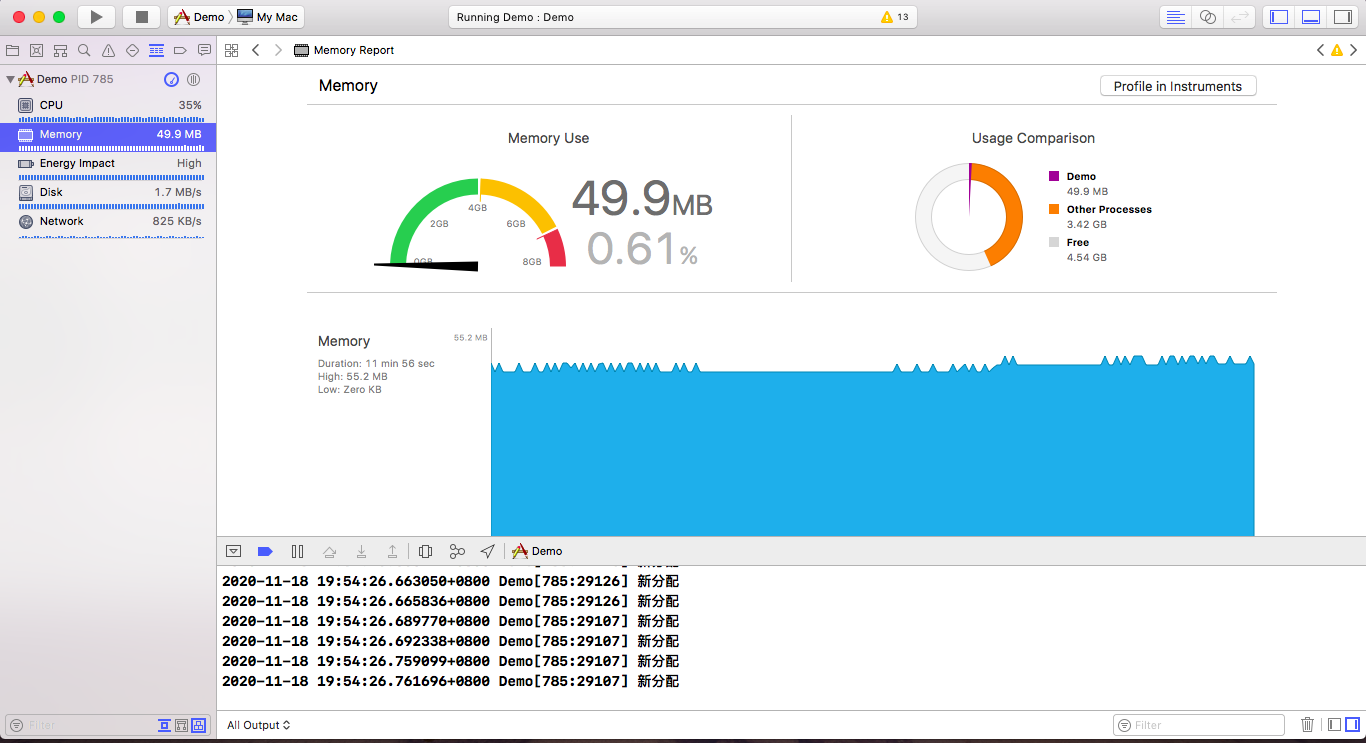
终于开始平稳运行,上面锯齿状的地方,就是使用 CFRelease 造成的结果。
5. 总结
该项目基于过去大量的RTMP的推流、H264编解码、CoreAudio、MacOS混合编程等诸多经验,参考文章无数,手写上千行代码,终于做出了自己想要的效果,音质完美,画面清晰!
如果能再加上GPUImage进行美颜就更好了,但由于时间所限,这一块不能深耕了。
通过对苹果音视频官方文档、SampleCode的学习,对音视频领域的很多知识有了较为全面的认识,真的是很好的教材。还有很多内容可以分享,在此不一一而足。
该程序虽然还有很多不完善的地方,但是整个主要的流程已经全部跑通,在通畅的局域网环境下可以长时间运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号