
数据分析 | 数据清理的方法
数据清理的步骤
# 一、读取数据
导入NumPy和Pandas数据库,用Pandas的read_csv函数读取原始数据集’e_commerce.csv’,使其转换成DataFrame格式,并赋值给变量df。
展示数据集的前5行和后5行。
# 二、评估数据(整洁度、干净度)
创建一个新的变量cleaned_data = df(相当于复制一个,对备份进行操作)
评估主要从两个方面进行:结构和内容,即整齐度和干净度。'''df.info/df.describe 看整体'''
1. 数据的结构性问题:
* 每列是一个变量,
* 每行是一个观察值,
* 每个单元格是一个值
2. 数据的内容性问题包括存在丢失数据、重复数据、无效数据等:
* 缺失,df.isnull.sum
* 重复,df.duplicated
* 评估填写不一致的数据,df['某列'].value_counts >> 这个函数可以统计这一列各种值的数据,比如部门列,可以直接统计各个部门有多少实例
* 数据类型 df.info
* 评估无效/错误数据 df.describe()
# 三、清理数据
根据前面评估时候的记录来进行清理
1. 处理结构问题:
* 每列是一个变量:df.melt()
* 每行是一个观察值:df.melt()
* 每个单元格是一个值:df.explode()
2. 处理内容问题:
* 缺失:df.fillna填充 ,或者直接删除 df.dropna(subset = 某列)
* 重复:df.drop_duplicates() 删除重复值
* 评估填写不一致的数据:df.replace([旧1,旧2],新,inplace = True) 用替代来统一
* 数据类型 df.astype() 修改数据类型
* 评估无效/错误数据:df.drop() 直接删了
# 四、保存数据
cleaned_df.to_csv('e_commerce_cleaned.csv', index=False)
方法详解
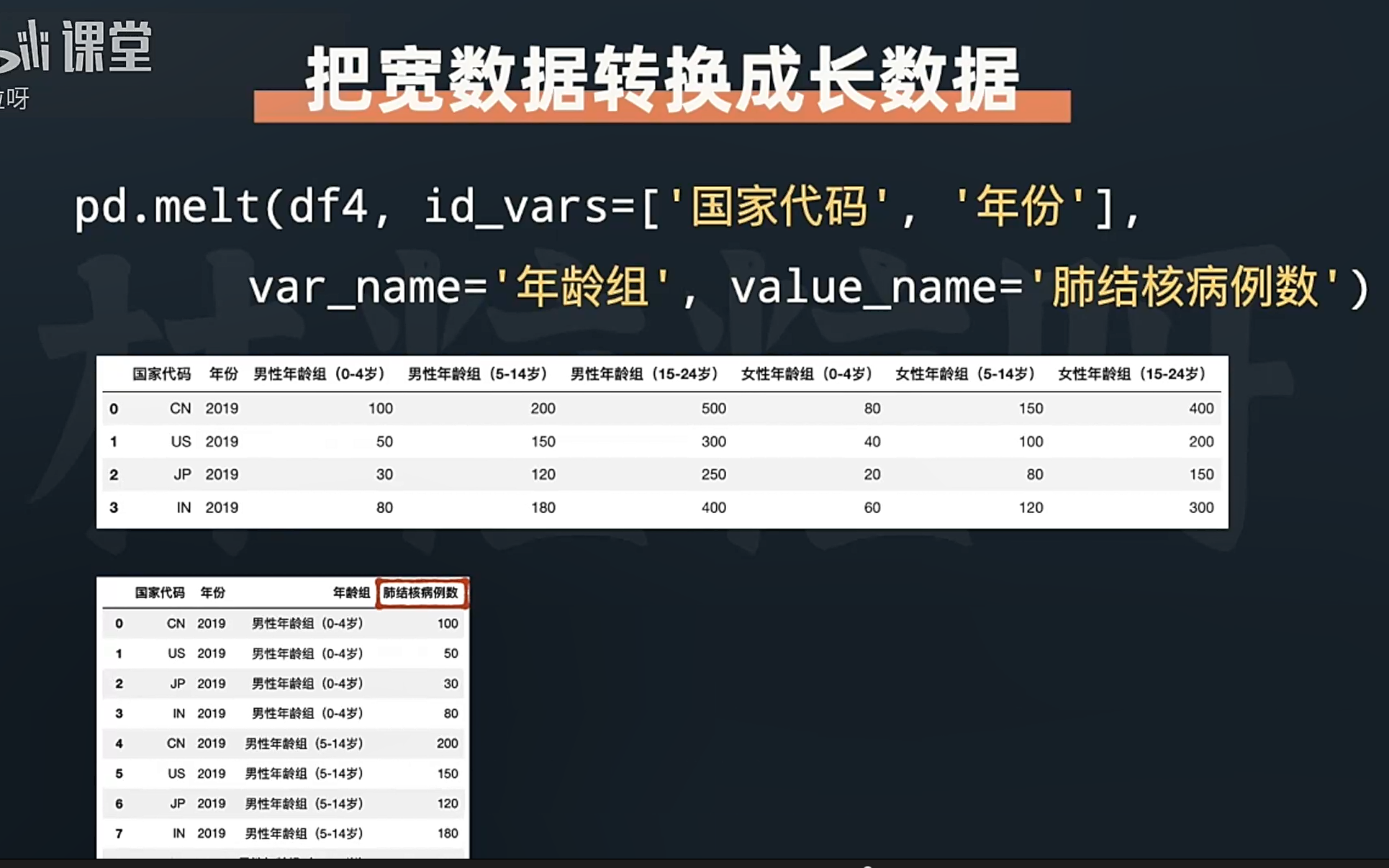
df.melt
# 适用场景:主要用于将宽数据转换成长数据
df.explode()
# 适用场景:主要用于将一个包含列表或数组等可迭代对象的列展开。
如果一列中有很多内容(比如一列中包含一个列表),想让内容分开单独成行,则可使用explode。
——————如果非列表或数组,则不行

df.fillna(直接写值)/df[某行列].fillna({列名:替换值,列名:替换值})
# 适用场景:主要用于 自动找到缺失值进行填充

**df.dropna()
df.dropna(subset = [关注的列名])
df['某列'].dropna()
df.dropna(axis = 1)
如果中间有其他条件,就要.index,相当于告诉系统按这个索引删除行
**
# 适用场景:主要用于 直接删除存在缺失值的行
如果传入了subset,那么只要关注列没有缺失,如果有,删除整行;如果没有,其他列有缺失也不会删除;
如果是df['某列'].dropna(),则只删除该列的缺失值,不会删除整行,导致最后各列长短不一
如果axis = 1,就变成了关注列,只要某列有空缺,直接删除整列

df.drop_duplicates()
# 适用场景:删除重复数据
如果希望是两列同时重复,才删除,就df.drop_duplicates(subset = [关注的列名1,关注的列名2])
一般遇到重复值,会删除后面出现的值,如果想删除前面的重复值,则drop_duplicates(keep = 'last')

df.replace(原值,替换值)/dr.replace(字典)
# 适用场景:将值进行统一的时候
如果有很多个值都想替换成同一个值,直接在原值处放列表即可
如果放字典,键为原值,值为替换值

df.astype(类型)
# 适用场景:需要转换值的类型的时候,比如str转int
有一个特殊的类型是“category”,意思是一些有限的分类的值,比如颜色【蓝,红,黄】;部门【人事部,财务部,销售部】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号