
SQL(DML)语法
1、SQL语言的分类
1.数据定义语言(DDL)(create,alter,drop)
2.数据操作语言(DML)(insert,delete,update语句操作表内容)
3.数据控制语言(DCL)GRANT 和REVOKE等
4.事物控制语言(TCL):commit。
2、数据的完整性
- 数据的完整性是指数据库中数据的准确性.
- 数据的完整性包括:
1.检验每行数据是否符合要求.
2.检验每一列数据是否符合要求.
- 四种类型的约束:
1. 实体完整性
通过添加主键约束实现唯一约束等方式实现
ALTER TABLE 表名 ADD CONSTRAINT 约束名 PRIMARY KEY(字段名)
ALTER TABLE 表名 ADD CONSTRAINT 约束名 UNIQUE(字段名);
2. 域完整性
通过限制数据类型 检查约束 默认值 非空等约束
ALTER TABLE student ADD CONSTRAINT chk_age CHECK (age>0)
3. 引用完整性
用来保持表之间已定义的关系,通过主键和外键之间的引用关系来实现
一个表中一列为主键约束或是唯一约束才能作为另一张表的外键约束。
创建外键约束的语法: ALTER TABLE子表 ADD CONSTRAINT 约束名 FOREING KEY (子表的外键) REFERENCES 主表 (主表的主键)
4. 自定义完整性
常借组于数据库的规则、存储过程或者触发器等对象来进行约束
ALTER TABLE 表名 DROP CONSTRAINT 约束名
消除mysql中的数据重复:
1.设置复合字段为Primary key
2.设置Unique索引
INSERT IGNORE INTO与INSERT INTO的区别就是INSERT IGNORE会忽略数据库中已经存在的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据。这样就可以保留数据库中已经存在数据, 达到在间隙中插入数据的目的。
INSERT IGNORE INTO person_tbl (last_name, first_name) VALUES ( 'Jay', 'Thomas');
INSERT IGNORE INTO当插入数据时,在设置了记录的唯一性后,如果插入重复数据,将不返回错误,只以警告形式返回。
而REPLACE INTO into如果存在primary 或 unique相同的记录,则先删除掉。再插入新记录。
--对结果进行排序,先按照年龄降序,如果年龄相同的按学号升序排序
SELECT stu_info ORDER BY stu_age DESC,stu_no ASC;
--利用已有的表添加备份表
CREATE TABLE emp_bak6 AS SELECT * FROM emp;
INSERT INTO emp_bak7 SELECT * FROM emp WHERE deptno =10;
CREATE TABLE emp_bak7 AS SELECT * FROM emp WHERE 1=2;--只添加列名备份表
--给字段起个别名:AS加不加都可以
SELECT empno 工号,ename AS 姓名 FROM emp WHERE sal BETWEEN 2000 AND 4000;
--利用现有的表创建新表,创建学生备份表
CREATE TABLE stu_info_brak AS SELECT * FROM stu_info
--使用列别名,两个字符串拼接用‘||’符号
SELECT ‘S’|| stu_no 学号,stu_name “姓 名” FROM stu_info
注意这里的 学号没有用双引号,而姓名用双引号是因为姓名中间有特殊字符空格
--查询所有员工信息按工资降序排列
SELECT * FROM emp ORDER BY sal DESC;
SELECT DISTINCT sal FROM emp;--清除重复项
--查询所有部门编号为10的员工信息并以sal降序,如果sal相同以comm降序排列信息
SELECT * FROM emp WHERE deptno=10 ORDER BY sal,comm DESC ;
3、查询语句中运用算术操作符
1.算术表达式由NUMBER数据类型的列名,数值常量和连接他们的算术操作符组成。算术操作符包括(+-*/)
2.查询语句中运用比较操作符:包括(=,!=,<,>,<=,>=,BETWEEN..AND ,IN ,LIKE 和IS NULL,IS NOT NULL等)
涉及NULL的条件是特殊的。不能使用= NULL或!= NULL来匹配查找列的NULL值。这样的比较总是失败,因为它是不可能告诉它们是否是true。 甚至 NULL = NULL 也是失败的。
要查找列的值是或不是NULL,使用IS NULL或IS NOT NULL。
--like:模糊查询 %表示任意多个字符,_表示一个任意字符
--名字中包含M的员工信息
SELECT * FROM emp WHERE ename LIKE '%M%'
--查询名字以M开头的员工信息
SELECT * FROM emp WHERE ename LIKE 'M%';
--名字中第二个字符是M的员工信息
SELECT * FROM emp WHERE ename='_M%';
4、mysql中使用正则表达式查询
以下是模式的表格,其可以连同REGEXP运算符使用
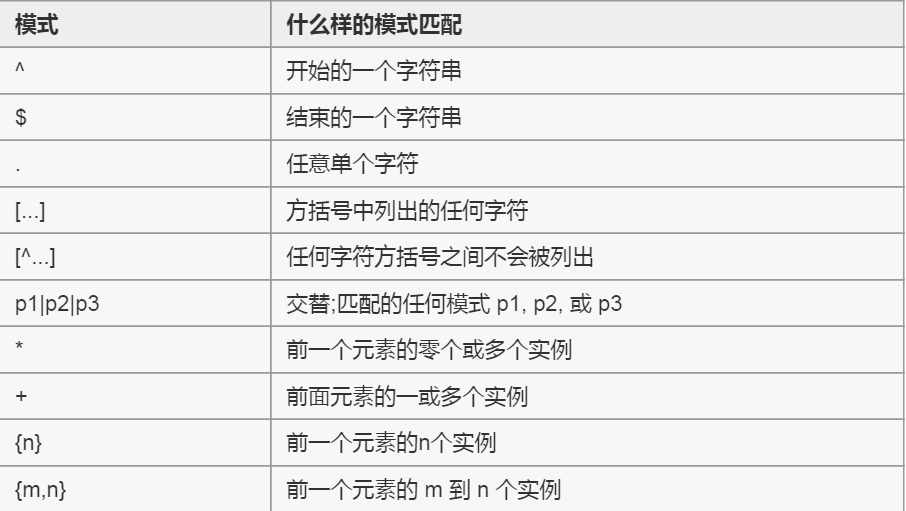
>查询以“夏”开头的名字:
select NAME from STUDENT WHERE NAME REGEXP '^夏';
>查询以“伟”结束的名字
select name from STUDENT WHERE NAME REGEXP "伟$";
>查询名字中包含“中”的所有名字
5、常用DML脚本
select name from STUDENT WHERE NAME REGEXP "中"; #创建雇员表 CREATE TABLE emp( empno BIGINT(4) PRIMARY KEY,#雇员编号 ename VARCHAR(4),#雇员名称 job VARCHAR(4),#雇员品种 mgr BIGINT(4),#上级经理编号 hiredate DATETIME ,#受雇佣的时间 sal INT,#雇员薪水 comm DOUBLE(7,2),#雇员福利 deptno BIGINT(2)#所属部门编号 ); #创建部门表 CREATE TABLE dept( deptno BIGINT(2) PRIMARY KEY,#部门编号 dname VARCHAR(14),#部门名称 loc VARCHAR(13)#部门所在城市 ); #数字函数round dual是一张虚拟的表 SELECT ROUND (12.35,1) FROM dual; #取小数点后一位四舍五入 SELECT ROUND (12.35,0) FROM dual; SELECT ROUND (12.35,-1) FROM dual; SELECT MOD (5,2) FROM dual;#取模运算 SELECT FLOOR(123.458) FROM dual;#向下取整 SELECT CEIL(123.232) FROM dual;#向上取整 #日期格式的使用 SELECT * FROM emp; INSERT INTO emp (empno, hiredate) VALUES (12, SYSDATE()); #聚合函数 #查询部门编号是10的平均工资,最高工资,最低工资,总工资 SELECT AVG(sal) FROM emp WHERE deptno=10; SELECT MAX(sal) FROM emp WHERE deptno=10; SELECT MIN(sal) FROM emp WHERE deptno=10; SELECT COUNT (*) FROM emp WHERE deptno=10; SELECT SUM(sal) FROM emp WHERE deptno=10; SELECT COUNT(DISTINCT deptno) FROM emp; SELECT AVG(sal) ,deptno 部门编号 FROM emp WHERE deptno>20 GROUP BY deptno HAVING AVG(sal)>1000 ORDER BY deptno ;#where必须在groutp前 #oracle中的分析函数 SELECT ENAME, JOB, DEPTNO, SAL, ROW_NUMBER() OVER(ORDER BY SAL DESC) AS SAL_RANK FROM SOCTT.EMP; SELECT empno,ename,sal,row_number()OVER(ORDER BY sal DESC) FROM emp; #查询部门编号和部门的最高薪水,平均薪水,最低薪水 SELECT deptno,MAX(sal) maxSal,AVG(sal) avgSal,MIN(sal) minSal FROM emp GROUP BY deptno #查询平均薪水在2000元以上的部门编号,最高薪水,平均薪水,最低薪水 SELECT deptno,MAX(sal) maxSal,AVG(sal) avgSal,MIN(sal) minSal FROM emp GROUP BY deptno HAVING AVG(sal)>2000 #按照每个部门分组,对薪水从大到小排序,每个部门序号从1开始,同一个部门相同薪水序号相同,且和下一条不同记录的排名之间空出排名 SELECT ename,deptno,sal, RANK() OVER (PARTITION BY deptno ORDER BY sal DESC) "RANK", #按照每个部门分组,对薪水从大到小排序,每个部门序号从1开始,同一个部门相同薪水序号相同,且和下一条不同记录的排名之间不空出排名 DENSE_RANK() OVER (PARTITION BY deptno ORDER BY sal DESC) "DENSE_RANK", #按照每个部门分组,对薪水从大到小排序,每个部门序号从1开始,同一个部门相同薪水序号继续递增,顺序排名 ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC) "ROW_NUMBER" FROM emp; SELECT deptno FROM emp WHERE ename='SCOTT'; #in关键字的子查询 SELECT empno,ename,deptno FROM emp WHERE deptno IN (SELECT deptno FROM emp WHERE ename='scott') #not in的子查询 不在财务部和销售不工作的雇员编号,姓名和部门编号 SELECT empno,ename,deptno FROM emp WHERE deptno NOT IN(SELECT deptno FROM dept WHERE dname IN( 'SALES' ,'accounting')); #使用比较运算符的子查询 SELECT empno,ename,deptno FROM emp WHERE deptno =(SELECT deptno FROM emp WHERE ename='scott') SELECT * FROM emp; #在emp表中,找出其中工资超过所在部门平均工资的雇员 SELECT empno ,ename,sal,deptno FROM emp e1 WHERE sal >(SELECT AVG(sal) FROM emp e2 WHERE e1.deptno=e2.deptno); #查询其他部门中比30号部门某一雇员薪水少的雇员信息 SELECT empno ,ename,deptno FROM emp e1 WHERE sal<ALL (SELECT sal FROM emp WHERE deptno=30)AND deptno<>30; #查询雇员薪水大于3000的部门名称 SELECT dname FROM dept d WHERE EXISTS (SELECT * FROM emp e WHERE d.deptno=e.deptno AND sal>3000); #内连接 等值连接查询所有雇员姓名和部门名称 SELECT ename,dname FROM emp e INNER JOIN dept d ON e.deptno=d.deptno; SELECT ename,e.deptno,dname FROM emp e,dept d WHERE e.deptno=d.deptno; --查询雇员姓名以及所在部门名称 SELECT e.ename,e.deptno,d.dname FROM emp e INNER JOIN dept d ON e.deptno=d.deptno; #不等值连接,从emp表中找到在工资等级表中对in个的工资等级 #创建工资等级表salgrade CREATE TABLE salgrade( grade NUMBER ,--级别编号 losal NUMBER ,--最低薪水 hisal NUMBER--最高薪水 ); INSERT INTO salgrade VALUES (1,700,1200); INSERT INTO salgrade VALUES (2,1201,1400); INSERT INTO salgrade VALUES (3,1401,2000); INSERT INTO salgrade VALUES (4,2001,3000); INSERT INTO salgrade VALUES (5,3001,9999); SELECT e.ename,e.job,e.sal,e.grade FROM emp e INNER JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal ; #自然连接 SELECT * FROM emp NATURAL JOIN dept; #w为工人表work m为经理表manager SELECT w.ename 雇员,m.ename 经理 FROM emp w INNER JOIN emp m ON w.mgr =e.empno ORDER BY w.ename #雇员表和部门表的交叉连接 SELECT COUNT(*) FROM emp CROSS JOIN dept; #rownum和排序 #取得某雇员表薪水大小排名第5的雇员信息 SELECT * FROM (SELECT emp.*,dense_rank() OVER (ORDER BY sal DESC) RANK FROM emp) WHERE RANK=5; #返回雇员表中薪水最高的前5人 SELECT * FROM (SELECT * FROM emp ORDER BY sal DESC ) WHERE ROWNUM<6; #返回雇员表中薪水从高到底排序的第5-9条记录 SELECT * FROM (SELECT e.* ,ROWNUM rn FROM (SELECT * FROM emp ORDER BY sal DESC ) e) WHERE rn>=5 AND rn<9; #分页查询 SELECT e.*,ROWNUM FROM emp e WHERE deptno=10; SELECT * FROM (SELECT * FROM EMP ORDER BY SAL DESC) WHERE ROWNUM<3;--伪列 #1.处理数据,2.固化rownum,3.确定rn的取值范围 SELECT T2.* FROM (SELECT T1.*, ROWNUM RN FROM ((SELECT * FROM EMP ORDER BY SAL DESC) T1)) T2 WHERE RN >5 AND rn<10 ; SELECT T2.* FROM (SELECT T1.*, ROWNUM RN FROM ((SELECT * FROM EMP ORDER BY SAL DESC) T1)) T2 WHERE RN >= 6 AND RN <= 10; #在where后的多条数据 从右往左加载的,可以把条件严格的放右边加快执行效率 #每页显示5条(pageSize),显示第2页数据(pageIndex) #rn<=pageSize*pageIndex rn>=(pageIndex-1)*pageSize+1
6、mysql中的alter命令:
alter table 表名 drop 列名
alter table 表名 add 列名 数据类型[first/after 列名](添加列是第一行或某行后,可选);
mysql > alter table STUDENT ADD address varchar(20) after age
mysql > alter table STUDENT MODIFY AGE CHAR(2);// 修改列age类型从char(1)到char(2)
mysql > alter table STUDENT CHANGE NAME REAL_NAME VARCHAR(10); //修改name字段为real_name
mysql > alter table STUDENT MODIFY AGE CHAR(2) NOT NULL DEFAULT 10;// 修改列并添加默认值
mysql > alter table STUDENT alter age set default 20;// 修改列的默认值
mysql > alter table STUDENT alter agt drop default;// 删除默认值
mysql > alter table STUDENT rename to TBL_STUDENT;// 表重命名
FIRST 和 AFTER 关键字只占用于 ADD 子句,
所以如果你想重置数据表字段的位置就需要先使用 DROP 删除字段然后使用 ADD 来添加字段并设置位置。
修改字段类型以及名称:
如果需要修改字段类型及名称, 你可以在ALTER命令中使用 MODIFY 或 CHANGE 子句 。
例如,把字段 c 的类型从 CHAR(1) 改为 CHAR(10),可以执行以下命令:
ALTER TABLE testalter_tbl MODIFY c CHAR(10);
// 修改字段并定义不为null,和定义默认值
ALTER TABLE testalter_tbl MODIFY j BIGINT NOT NULL DEFAULT 100;
// 修改默认值
ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000;
// 删除默认值
ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;
// 修改表名
ALTER TABLE testalter_tbl RENAME TO alter_tbl;
使用 CHANGE 子句, 语法有很大的不同。 在 CHANGE 关键字之后,紧跟着的是你要修改的字段名,然后指定新字段名及类型。尝试如下实例:
ALTER TABLE testalter_tbl CHANGE i j INT;
7、mysql中的索引:
增加索引的目的是增加数据查询的速度。根据数据库功能可在数据库设计器中创建三种索引:
1.主键索引,2.唯一索引,3.聚集索引
create unique index 索引名 on 表名 (列名。。。)
create unique index index_exam on STUDENT_EXAM (EXAM,CLASS DESC);// 索引列的值按降序排序
alter table TBL_NAME add primary key (column);// 添加主键
alter table TBL_NAME add unique INDEX_NAME(column);// 添加唯一索引
alter table TBL_NAME add index INDEX_NAME(column);// 添加普通索引
alter table TBL_NAME add fulltext INDEX_NAME(column);//文本搜索目的的文本索引
删除索引:
alter table TBL_NAME drop primary key ;//删除主键索引
查询索引:
show index from tbl_name;
8、mysql中的常用函数
1.字符串转日期函数:select date_format("2016-06-16 05:22:10",'%Y-%c-%d %h:%i:%s') as date;
select date_format(now(),"%Y-%c-%d %h:%i:%s");//系统函数对象转换为日期格式
//字符串转日期 如果字符串日期是"2016-06-15 00:00:00"转换后输出"2016-06-15 12:00:00";
str_TO_DATE(X,Y);select str_to_date("2016-06-16 05:22:10",'%Y-%c-%d %h:%i:%s');
区别:date_format(x,y)可以转换日期对象和字符串,str_to_date(x,y);只能转换日期字符串。
2.四舍五入函数:ROUND(X,Y);
3.取随机数:RAND(X);
9. GROUP BY 语句将数据表按名字进行分组
使用 WITH ROLLUP
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。
SELECT name, SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
我们可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce 语法:
select coalesce(a,b,c);
参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号