


复习爬虫
复习爬虫基础
正则
2、正则与re模块简介
概述: 正则表达式,又称规则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern)
正则匹配是一个 模糊的匹配(不是精确匹配)
re:python自1.5版本开始增加了re模块,该模块提供了perl风格的正则表达式模式,re模块是python语言拥有了所有正则表达式的功能
- 如下四个方法经常使用
- match()
- search()
- findall()
- finditer()
二、正则表达式
1、匹配单个字符与数字
| 匹配 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符,当flags被设置为re.S时,可以匹配包含换行符以内的所有字符 |
| [] | 里面是字符集合,匹配[]里任意一个字符 |
| [0123456789] | 匹配任意一个数字字符 |
| [0-9] | 匹配任意一个数字字符 |
| [a-z] | 匹配任意一个小写英文字母字符 |
| [A-Z] | 匹配任意一个大写英文字母字符 |
| [A-Za-z] | 匹配任意一个英文字母字符 |
| [A-Za-z0-9] | 匹配任意一个数字或英文字母字符 |
| [^lucky] | []里的^称为脱字符,表示非,匹配不在[]内的任意一个字符 |
| [1] | 以[]中内的某一个字符作为开头 |
| \d | 匹配任意一个数字字符,相当于[0-9] |
| \D | 匹配任意一个非数字字符,相当于[^0-9] |
| \w | 匹配字母、下划线、数字中的任意一个字符,相当于[0-9A-Za-z_] |
| \W | 匹配非字母、下划线、数字中的任意一个字符,相当于[^0-9A-Za-z_] |
| \s | 匹配空白符(空格、换页、换行、回车、制表),相当于[ \f\n\r\t] |
| \S | 匹配非空白符(空格、换页、换行、回车、制表),相当于[^ \f\n\r\t] |
2、匹配锚字符
锚字符:用来判定是否按照规定开始或者结尾
| 匹配 | 说明 |
|---|---|
| ^ | 行首匹配,和[]里的^不是一个意思 |
| $ | 行尾匹配 |
3、限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
| 匹配 | 说明 |
|---|---|
| (xyz) | 匹配括号内的xyz,作为一个整体去匹配 一个单元 子存储 |
| x? | 匹配0个或者1个x,非贪婪匹配 |
| x* | 匹配0个或任意多个x |
| x+ | 匹配至少一个x |
| x | 确定匹配n个x,n是非负数 |
| x | 至少匹配n个x |
| x | 匹配至少n个最多m个x |
| x|y | |表示或的意思,匹配x或y |
# [] 原子表 重点
[a] 匹配字母a
[ab] 匹配字母a或b
[abc] 匹配字母a或者b或者c
[a1] 匹配a或者1
[a-z] 匹配任意一位小写字母
[A-Z] 匹配任意一位大写字母
[0-9] 匹配任意一位数字
[a-zA-Z] 匹配任意一位字母
[a-zA-Z0-9] 匹配任意一位数字或字母
# [][] 俩个原子表
[a][b] 匹配字母ab 等同于 ab
[a][bc] 匹配字母ab或者ac 等同于 (ab)|(ac)
# {m} 代表匹配前面表达式m个 重点
[a-z][a-z][a-z][a-z][a-z] 匹配5个小写字母
[a-z]{5} 匹配5个小写字母
[0-9]{5} 匹配5个数字
# 匹配手机号码呢
1 二位 3-9 第三位0-9
[1][3-9][0-9]{9}
1[3-9][0-9]{9}
# {m, n} 代表匹配前面表达式m-n个 重点
[a-z]{2, 4} # 匹配2-4位的小写字母
# {m, } 代表匹配前面表达式的至少m个
[a-z]{2,} # 至少匹配2位小写字母
# ? 可有可无 0次或一次
[a-z]? 是否匹配到一位小写字母都可以
[a-z]{0, 1}
匹配一位1-9之间正负整数
-?[1-9]
# . 匹配除了换行符以外的任意字符 \r\n
# * 匹配前面的表达式0次到多次 {0,}
# .*? 重要的组合 匹配除换行符以外的任意字符任意次 拒绝贪婪 重点
# .* 重要的组合 匹配除换行符以外的任意字符任意次 贪婪模式
# + 匹配一次到多次 {1, }
# .+? 匹配除换行符以外的任意字符至少一次 拒绝贪婪
# .+ 匹配除换行符以外的任意字符至少一次 贪婪
# | 或 重点
匹配手机号码 或者 qq号码
手机号 | qq号码
1[3-9][0-9]{9} | [1-9][0-9]{4, 10}
# () 作用子存储 一个单元 重点
会把括号中的匹配到的结果进行单独返回
(1[3-9][0-9]{9})|([1-9][0-9]{4, 10})
# 作为爬虫来说 几乎用不到
# ^ 以...开头
# $ 以...结尾
# \d 代表匹配任意一位数字 等同于 [0-9]
# \D 代表匹配任意一位非数字 等同于 [^0-9]
# \w 匹配一位数字字母下划线 等同于 [a-zA-Z0-9_]
# \W 匹配一位非数字字母下划线 等同于 [^a-zA-Z0-9_]
三、re模块中常用函数
通用flags(修正符)
| 值 | 说明 |
|---|---|
| re.I | 是匹配对大小写不敏感 |
| re.S | 使.匹配包括换行符在内的所有字符 |
通用函数
-
获取匹配结果
-
使用group()方法 获取到匹配的值
-
groups() 返回一个包含所有小组字符串的元组(也就是自存储的值),从 1 到 所含的小组号。
-
1、match()函数
-
原型
def match(pattern, string, flags=0) -
功能
匹配成功返回 匹配的对象
匹配失败 返回 None
-
获取匹配结果
-
使用group()方法 获取到匹配的值
-
groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
-
-
注意:从第一位开始匹配 只匹配一次
-
参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式 -
代码
import re res = re.match('\d{2}','123') print(res.group()) #给当前匹配到的结果起别名 s = '3G4HFD567' re.match("(?P<value>\d+)",s) print(x.group(0)) print(x.group('value'))
2、search()函数
-
原型
def search(pattern, string, flags=0) -
功能
扫描整个字符串string,并返回第一个pattern模式成功的匹配
匹配失败 返回 None
-
参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式 -
注意:
只要字符串包含就可以
只匹配一次
-
示例
import re res = re.search('[a-z]', '131A3ab889s') print(res) print(res.group()
-
注意
与search的区别
相同点:
都只匹配一次
不同点:
- search是在要匹配的字符串中 包含正则表达式的内容就可以
- match 必须第一位就开始匹配 否则匹配失败
3、findall()函数(返回列表)
-
原型
def findall(pattern, string, flags=0) -
功能
扫描整个字符串string,并返回所有匹配的pattern模式结果的字符串列表
-
参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式 -
示例
myStr = """ <a href="http://www.baidu.com">百度</a> <A href="http://www.taobao.com">淘宝</A> <a href="http://www.id97.com">电 影网站</a> <i>我是倾斜1</i> <i>我是倾斜2</i> <em>我是倾斜2</em> """ # html里是不区分大小写 # (1)给正则里面匹配的 加上圆括号 会将括号里面的内容进行 单独的返回 res = re.findall("(<a href=\"http://www\.(.*?)\.com\">(.*?)</a>)",myStr) #[('<a href="http://www.baidu.com">百度</a>', 'baidu', '百度')] # 括号的区别 res = re.findall("<a href=\"http://www\..*?\.com\">.*?</a>",myStr) #['<a href="http://www.baidu.com">百度</a>'] #(2) 不区分大小写的匹配 res = re.findall("<a href=\"http://www\..*?\.com\">.*?</a>",myStr,re.I) #['<a href="http://www.baidu.com">百度</a>', '<A href="http://www.taobao.com">淘宝</A>'] res = re.findall("<[aA] href=\"http://www\..*?\.com\">.*?</[aA]>",myStr) #['<a href="http://www.baidu.com">百度</a>'] # (3) 使.支持换行匹配 res = re.findall("<a href="http://www..?.com">.?</a>",myStr,re.S) # # (4) 支持换行 支持不区分大小写匹配 res = re.findall("<a href="http://www..?.com">.?</a>",myStr,re.S|re.I) # print(res)
4、finditer()函数
-
原型
def finditer(pattern, string, flags=0) -
功能
与findall()类似,返回一个迭代器
-
参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式 -
代码
import re res = re.finditer('\w', '12hsakda1') print(res) print(next(res)) for i in res: print(i)
5、split()函数
-
作用:切割字符串
-
原型:
def split(patter, string, maxsplit=0, flags=0) -
参数
pattern 正则表达式
string 要拆分的字符串
maxsplit 最大拆分次数 默认拆分全部
flags 修正符
-
示例
import re myStr = "asdas\rd&a\ts12d\n*a3sd@a_1sd" #通过特殊字符 对其进行拆分 成列表 res = re.split("[^a-z]",myStr) res = re.split("\W",myStr)
6、修正符
-
作用
对正则进行修正
-
使用
search/match/findall/finditer 等函数 flags参数的使用
-
修正符
re.I 不区分大小写匹配
re.S 使.可以匹配换行符 匹配任意字符
-
使用
re.I
print(re.findall('[a-z]','AaBb')) print(re.findall('[a-z]','AaBb', flags=re.I))re.S
print(re.findall('<b>.*?</b>','<b>b标签</b>')) print(re.findall('<b>.*?</b>','<b>b标\n签</b>', flags=re.S))
四、正则高级
1、分组&起名称
-
概念
处理简单的判断是否匹配之外,正则表达式还有提取子串的功能,用()表示的就是要提取的分组
-
代码
#给当前匹配到的结果起别名 s = '3G4HFD567' re.match("(?P<value>\d+)",s) print(x.group(0)) print(x.group('value')) -
说明
- 正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来
- group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串
2、编译
-
概念
当在python中使用正则表达式时,re模块会做两件事,一件是编译正则表达式,如果表达式的字符串本身不合法,会报错。另一件是用编译好的正则表达式提取匹配字符串
-
编译优点
如果一个正则表达式要使用几千遍,每一次都会编译,出于效率的考虑进行正则表达式的编译,就不需要每次都编译了,节省了编译的时间,从而提升效率
-
compile()函数
-
原型
def compile(pattern, flags=0) -
作用
将pattern模式编译成正则对象
-
参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) flags 标识位,用于控制正则表达式的匹配方式 -
flags
值 说明 re.I 是匹配对大小写不敏感 re.S 使.匹配包括换行符在内的所有字符 -
返回值
编译好的正则对象
-
示例
import re re_phone = re.compile(r"(0\d{2,3}-\d{7,8})") print(re_phone, type(re_phone))
-
-
编译后其他方法的使用
原型
def match(self, string, pos=0, endpos=-1) def search(self, string, pos=0, endpos=-1) def findall(self, string, pos=0, endpos=-1) def finditer(self, string, pos=0, endpos=-1)参数
参数 说明 string 待匹配的字符串 pos 从string字符串pos下标开始 endpos 结束下标 示例
s1 = "lucky's phone is 010-88888888" s2 = "kaige's phone is 010-99999999" ret1 = re_phone.search(s1) print(ret1, ret1.group(1)) ret2 = re_phone.search(s2) print(ret2, ret2.group(1))
3、贪婪与非贪婪
-
贪婪模式
贪婪概念:匹配尽可能多的字符
- .+ 匹配换行符以外的字符至少一次
- .* 匹配换行符以外的字符任意次
实例
res = re.search('<b>.+</b>', '<b></b><b>b标签</b>') res = re.search('<b>.*</b>', '<b>b标签</b><b>b标签</b><b>b标签</b><b>b标签</b>') -
非贪婪模式
非贪婪概念:尽可能少的匹配称为非贪婪匹配,*?、+?即可
-
.+? 匹配换行符以外的字符至少一次 拒绝贪婪
- .*? 匹配换行符以外的字符任意次 拒绝贪婪
实例
res = re.search('<b>.+?</b>', '<b>b标签</b><b>b标签</b>') res = re.search('<b>.*?</b>', '<b>b标签</b><b>b标签</b><b>b标签</b><b>b标签</b>')
import re
# 匹配一位小写字母
# print(re.search('[a-z]', '123a'))
# print(re.search('[a-z]{2}', '123ab'))
# print(re.search('[a-z]{2,}', '123abc'))
# print(re.search('[A-Za-z0-9]{2,}', 'ABC123abcABC@'))
# print(re.search('[1][3-9][0-9]{9}', '18047701465'))
#
# print(re.search('^[0-9]', '1a'))
# print(re.search('^[0-9]', 'a1a'))
# print(re.search('[^0-9]{2,}', 'aaaaa1a')) # 从前往后
# print(re.match('^\d','1a1a1a2345'))
# print(re.match('\d+','1a1a2345'))
# print(re.match('\d*','1a1a2345'))
# 匹配所有
'''
print(re.findall('\d','12456asdf1234'))
print(re.findall('\d{2}','12456asdf1234'))
print(re.findall('\D','12456asdf'))
print(re.findall('^\d','12456asdf'))
print(re.findall('\d+','12456asdf'))
print(re.findall('\d*','12456asdf'))
print(re.findall('\D*','12456asdf'))
print(re.findall('\D+','12456asdf'))
'''
'''
mystr = '<div>我是HTML标签</div><div>div标签</div><div></div>'
print(re.findall('<div>.*?</div>',mystr))
print(re.findall('<div>.*</div>',mystr))
print(re.findall('<div>.+</div>',mystr))
print(re.findall('<div>(.*?)</div>',mystr))
print(re.findall('(<div>(.*?)</div>)',mystr))
print(re.findall('<div>(.+?)</div>',mystr))
print(re.findall('(<div>(.+?)</div>)',mystr))
'''
# 匹配换行
mystr = '''
<a href="http://www.baidu.com">百度</a>
<a href="http://www.taobao.com">淘宝</a>
<A href="http://www.taobao.com">淘宝2</A>
<a href="http://www.aiqiyi.com">爱奇
'''
'''
print(re.findall('<a href=".*?">.*?</a>',mystr))
print(re.findall('<a href=".*?">.*?</a>',mystr,re.S))
print(re.findall('<a href=".*?">.*?</a>',mystr,re.I))
print(re.findall('<[aA] href=".*?">.*?</[aA]>',mystr))
print(re.finditer('<a href=".*?">.*?</a>',mystr,re.S|re.I))
'''
# 取值
# data = re.search("<b>(.*?)</b>","<b>标签</b>")
# print(data.group())
# print(data.group(1))
# print(data.groups())
# split 拆分
print(re.split('\d','abc123abc'))
print(re.split('\d','ac123sdfcvb1234',1)) #按第一个字母拆
pattern = re.compile('\d','')
练习:
-
中信证券
# 将产品名称管理人 风险评级 认购金额 起点公示 信息 全部抓到import re with open('./maters/中信证券资管产品_中信证券 CITIC Securities.html',encoding="utf8") as f: data = f.read() # print(data) print(re.findall('<span class="th3" value=".*?">(.*?)</span>',data)) print(re.findall('<span class="th1" value=".*?">(.*?)</span>',data)) print(re.findall('<span class="th2" value=".*?">(.*?)</span>',data)) print(re.findall('<span class="th4" value=".*?">(.*?)</span>',data)) -
练习抓取股票 每一行数据
import re
f = open('../素材/股票.html', 'r')
data = f.read()
#第一次 抓取 包含 股票代码信息的数据
pattern = re.compile("<tbody class=\"tbody_right\" id=\"datalist\">(.*?)</tbody>",re.DOTALL)
tbodyData = pattern.findall(data)
# print(tbodyData[0])
#将抓取到的股票信息代码的数据 进行再次过滤 将html标签过滤掉
dataPatt = re.compile(">(.*?)<")
newData = dataPatt.findall(tbodyData[0])
#将 数据里面的空白字符 去掉
newData1 = newData.copy()
for i in newData1:
# print(i)
if i == '':
newData.remove(i)
# print(newData)
#进行数据的展示
print(len(newData))
#外侧走一次
for l in range(0,len(newData),12):
# print(l) l 0 12 24
# j 0-11 0-11 0-11
#走12次 将每列数据进行 显示
for j in range(12):
print(newData[j+l],end=" ")
print("")
-
豆瓣
抓取标题和图片img标签
BS4
beautifulsoup
一、beautifulsoup的简单使用
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
1、安装
pip install beautifulsoup4
1.1解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
pip install lxml
1.2 解析器对比
2、快速开始
下面的一段HTML代码将作为例子被多次用到.这是 爱丽丝梦游仙境的 的一段内容(以后内容中简称为 爱丽丝 的文档):
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
# html进行美化
print(soup.prettify())
匹配代码
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>
几个简单的浏览结构化数据的方法:
soup.title # 获取标签title
# <title>The Dormouse's story</title>
soup.title.name # 获取标签名称
# 'title'
soup.title.string # 获取标签title内的内容
# 'The Dormouse's story'
soup.title.parent # 获取父级标签
soup.title.parent.name # 获取父级标签名称
# 'head'
soup.p
# <p class="title"><b>The Dormouse's story</b></p>
soup.p['class'] # 获取p的class属性值
# 'title'
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find(id="link3") # 获取id为link3的标签
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
从文档中找到所有<a>标签的链接:
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
从文档中获取所有文字内容:
print(soup.get_text())
3、如何使用
将一段文档传入BeautifulSoup 的构造方法,就能得到一个文档的对象, 可以传入一段字符串或一个文件句柄.
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("index.html"))
soup = BeautifulSoup("<html>data</html>", 'lxml')
然后,Beautiful Soup选择最合适的解析器来解析这段文档,如果手动指定解析器那么Beautiful Soup会选择指定的解析器来解析文档。
二、beautifulsoup的遍历文档树
还拿”爱丽丝梦游仙境”的文档来做例子:
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
# lxml和html.parser解析的有时候会根据html是否完整而有解析不同的问题,需要注意
soup = BeautifulSoup(html_doc, 'html.parser')
通过这段例子来演示怎样从文档的一段内容找到另一段内容
1、子节点
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点.Beautiful Soup提供了许多操作和遍历子节点的属性.
注意: Beautiful Soup中字符串节点不支持这些属性,因为字符串没有子节点。
1.1 .contents
tag的 .contents 属性可以将tag的子节点以列表的方式输出:
head_tag = soup.head
head_tag
# <head><title>The Dormouse's story</title></head>
head_tag.contents
[<title>The Dormouse's story</title>]
title_tag = head_tag.contents[0]
title_tag
# <title>The Dormouse's story</title>
title_tag.contents
# [u'The Dormouse's story']
字符串没有 .contents 属性,因为字符串没有子节点:
text = title_tag.contents[0]
text.contents
# AttributeError: 'NavigableString' object has no attribute 'contents'
2、 节点内容
2.1 .string
如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点。如果一个tag仅有一个子节点,那么这个tag也可以使用 .string 方法,输出结果与当前唯一子节点的 .string 结果相同。
通俗点说就是:如果一个标签里面没有标签了,那么 .string 就会返回标签里面的内容。如果标签里面只有唯一的一个标签了,那么 .string 也会返回最里面的内容。例如:
print (soup.head.string)
#The Dormouse's story
# <title><b>The Dormouse's story</b></title>
print (soup.title.string)
#The Dormouse's story
如果tag包含了多个子节点,tag就无法确定,string 方法应该调用哪个子节点的内容, .string 的输出结果是 None
print (soup.html.string)
#None
2.2 .text
如果tag包含了多个子节点, text则会返回内部所有文本内容
print (soup.html.text)
注意:
strings和text都可以返回所有文本内容
区别:text返回内容为字符串类型 strings为生成器generator
3、 多个内容
.strings .stripped_strings 属性
3.1.strings
获取多个内容,不过需要遍历获取,比如下面的例子:
for string in soup.strings:
print(repr(string))
'''
'\n'
"The Dormouse's story"
'\n'
'\n'
"The Dormouse's story"
'\n'
'Once upon a time there were three little sisters; and their names were\n'
'Elsie'
',\n'
'Lacie'
' and\n'
'Tillie'
';\nand they lived at the bottom of a well.'
'\n'
'...'
'\n'
'''
3.2 .stripped_strings
输出的字符串中可能包含了很多空格或空行,使用 .stripped_strings 可以去除多余空白内容
for string in soup.stripped_strings:
print(repr(string))
'''
"The Dormouse's story"
"The Dormouse's story"
'Once upon a time there were three little sisters; and their names were'
'Elsie'
','
'Lacie'
'and'
'Tillie'
';\nand they lived at the bottom of a well.'
'...'
'''
4、 父节点
继续分析文档树,每个tag或字符串都有父节点:被包含在某个tag中
4.1 .parent
通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,<head>标签是<title>标签的父节点:
title_tag = soup.title
title_tag
# <title>The Dormouse's story</title>
title_tag.parent
# <head><title>The Dormouse's story</title></head>
文档的顶层节点比如<html>的父节点是 BeautifulSoup 对象:
html_tag = soup.html
type(html_tag.parent)
# <class 'bs4.BeautifulSoup'>
三、beautifulsoup的搜索文档树
1、find_all
find_all( name , attrs , recursive , string , **kwargs )
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件:
soup.find_all("title")
# [<title>The Dormouse's story</title>]
soup.find_all("p", "title")
# [<p class="title"><b>The Dormouse's story</b></p>]
soup.find_all("a")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find_all(id="link2")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
import re
# 模糊查询 包含sisters的就可以
soup.find(string=re.compile("sisters"))
# 'Once upon a time there were three little sisters; and their names were\n'
有几个方法很相似,还有几个方法是新的,参数中的 string 和 id 是什么含义? 为什么 find_all("p", "title") 返回的是CSS Class为”title”的<p>标签? 我们来仔细看一下 find_all() 的参数.
1.1 name 参数
name 参数可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉.
简单的用法如下:
soup.find_all("title")
# [<title>The Dormouse's story</title>]
搜索 name 参数的值可以使任一类型的 过滤器 ,字符串,正则表达式,列表,方法或是 True .
<1> 传字符串
最简单的过滤器是字符串.在搜索方法中传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容,下面的例子用于查找文档中所有的标签
soup.find_all('b')
# [<b>The Dormouse's story</b>]
<2> 传正则表达式
如果传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示<body>和<b>标签都应该被找到
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
# body
# b
<3> 传列表
如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回.下面代码找到文档中所有<a>标签和<b>标签
soup.find_all(["a", "b"])
# [<b>The Dormouse's story</b>,
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
1.2 keyword 参数
如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,如果包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性.
soup.find_all(id='link2')
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
import re
# 超链接包含elsie标签
print(soup.find_all(href=re.compile("elsie")))
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
# 以The作为开头的字符串
print(soup.find_all(text=re.compile("^The")))
# ["The Dormouse's story", "The Dormouse's story"]
# class选择器包含st的节点
print(soup.find_all(class_=re.compile("st")))
搜索指定名字的属性时可以使用的参数值包括 字符串 , 正则表达式 , 列表, True .
下面的例子在文档树中查找所有包含 id 属性的tag,无论 id 的值是什么:
soup.find_all(id=True)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
使用多个指定名字的参数可以同时过滤tag的多个属性:
soup.find_all(href=re.compile("elsie"), id='link1')
# [<a class="sister" href="http://example.com/elsie" id="link1">three</a>]
在这里我们想用 class 过滤,不过 class 是 python 的关键词,这怎么办?加个下划线就可以
print(soup.find_all("a", class_="sister"))
'''
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
]
'''
通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag:
data_soup.find_all(attrs={"data-foo": "value"})
# [<div data-foo="value">foo!</div>]
注意:如何查看条件id和class同时存在时的写法
print(soup.find_all('b', class_="story", id="x"))
print(soup.find_all('b', attrs={"class":"story", "id":"x"}))
1.3 text 参数
通过 text 参数可以搜搜文档中的字符串内容.与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表, True
import re
print(soup.find_all(text="Elsie"))
# ['Elsie']
print(soup.find_all(text=["Tillie", "Elsie", "Lacie"]))
# ['Elsie', 'Lacie', 'Tillie']
# 只要包含Dormouse就可以
print(soup.find_all(text=re.compile("Dormouse")))
# ["The Dormouse's story", "The Dormouse's story"]
1.4 limit 参数
find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果.
print(soup.find_all("a",limit=2))
print(soup.find_all("a")[0:2])
'''
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
'''
2、find()
find( name , attrs , recursive , string , **kwargs )
find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果.比如文档中只有一个<body>标签,那么使用 find_all() 方法来查找<body>标签就不太合适, 使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法.下面两行代码是等价的:
soup.find_all('title', limit=1)
# [<title>The Dormouse's story</title>]
soup.find('title')
# <title>The Dormouse's story</title>
唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果.
find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None .
print(soup.find("nosuchtag"))
# None
soup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法:
soup.head.title
# <title>The Dormouse's story</title>
soup.find("head").find("title")
# <title>The Dormouse's story</title>
四、beautifulsoup的css选择器
我们在写 CSS 时,标签名不加任何修饰,类名前加点,id名前加 #,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
1、通过标签名查找
print(soup.select("title")) #[<title>The Dormouse's story</title>]
print(soup.select("b")) #[<b>The Dormouse's story</b>]
2、通过类名查找
print(soup.select(".sister"))
'''
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
'''
3、id名查找
print(soup.select("#link1"))
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
4、组合查找
组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开
print(soup.select("p #link2"))
#[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
直接子标签查找
print(soup.select("p > #link2"))
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
查找既有class也有id选择器的标签
a_string = soup.select(".story#test")
查找有多个class选择器的标签
a_string = soup.select(".story.test")
查找有多个class选择器和一个id选择器的标签
a_string = soup.select(".story.test#book")
5、属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print(soup.select("a[href='http://example.com/tillie']"))
#[<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容:
for title in soup.select('a'):
print (title.get_text())
'''
Elsie
Lacie
Tillie
'''
练习
1、匹配三国演义中的回合 并写入html文本中

2、匹配天气信息 城市与温度
只要城市与气温

匹配后结果为

3、匹配广州二手房 房源信息
匹配红色框内的内容

# 豆瓣
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('./mater/豆瓣.html','r',encoding='UTF-8'),'lxml')
# print(soup)
div_list = soup.find_all('div',class_='detail-frame')
# print(div_list)
for d in div_list:
# print(d)
title = d.a.string
# print(title)
print(d.find('span',class_='font-small color-lightgray').string)
print(d.find('p',class_='color-gray').string)
print(d.find('p',class_='detail').string)
print(d.find_all('p')[-1].string)
# 二手房
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('./mater/广州二手房.html','r',encoding='utf-8'),'lxml')
# print(soup)
div_list = soup.find_all('div',class_='house-item house-itemB clearfix')
for d in div_list:
print(list(d.stripped_strings))
print(d.select('.cBlueB')[0].text)
print(d.select('.house-txt')[0].text)
xpath
1、xpath安装与使用
安装
-
安装lxml库
pip install lxml -i pip源
2、解析流程与使用
解析流程
- 实例化一个etree的对象,把即将被解析的页面源码加载到该对象
- 调用该对象的xpath方法结合着不同形式的xpath表达进行标签定位和数据提取
使用
-
导入lxml.etree
from lxml import etree
-
etree.parse()
解析本地html文件
html_tree = etree.parse('XX.html')
-
etree.HTML()(建议)
解析网络的html字符串
html_tree = etree.HTML(html字符串)
-
html_tree.xpath()
使用xpath路径查询信息,返回一个列表
注意:如果lxml解析本地HTML文件报错可以安装如下添加参数
parser = etree.HTMLParser(encoding="utf-8")
selector = etree.parse('./lol_1.html',parser=parser)
result=etree.tostring(selector)
3、xpath语法
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
-
路径表达式
表达式 描述 / 从根节点选取。 // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 ./ 当前节点再次进行xpath @ 选取属性。 实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
路径表达式 结果 /html 选取根元素。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! //li 选取所有li 子元素,而不管它们在文档中的位置。 //ul//li 选择属于 ul元素的后代的所有 li元素,而不管它们位于 ul之下的什么位置。 节点对象.xpath('./div') 选择当前节点对象里面的第一个div节点 //@href 选取名为 href 的所有属性。 -
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
路径表达式 结果 /ul/li[1] 选取属于 ul子元素的第一个 li元素。 /ul/li[last()] 选取属于 ul子元素的最后一个 li元素。 /ul/li[last()-1] 选取属于 ul子元素的倒数第二个 li元素。 //ul/li[position()❤️] 选取最前面的两个属于 ul元素的子元素的 li元素。 //a[@title] 选取所有拥有名为 title的属性的 a元素。 //a[@title='xx'] 选取所有 a元素,且这些元素拥有值为 xx的 title属性。 //a[@title>10] > < >= <= !=选取 a元素的所有 title元素,且其中的 title元素的值须大于 10。 /bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 -
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
通配符 描述 * 匹配任何元素节点。 一般用于浏览器copy xpath会出现 @* 匹配任何属性节点。 node() 匹配任何类型的节点。 实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果 /ul/* 选取 ul元素的所有子元素。 //* 选取文档中的所有元素。 //title[@*] 选取所有带有属性的 title 元素。 //node() 获取所有节点 选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果 //book/title | //book/price 选取 book 元素的所有 title 和 price 元素。 //title | //price 选取文档中的所有 title 和 price 元素。 /bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 -
逻辑运算
-
查找所有id属性等于head并且class属性等于s_down的div标签
//div[@id="head" and @class="s_down"] -
选取文档中的所有 title 和 price 元素。
//title | //price注意: “|”两边必须是完整的xpath路径
-
-
属性查询
-
查找所有包含id属性的div节点
//div[@id] -
查找所有id属性等于maincontent的div标签
//div[@id="maincontent"] -
查找所有的class属性
//@class -
//@attrName
//li[@name="xx"]//text() # 获取li标签name为xx的里面的文本内容
-
-
获取第几个标签 索引从1开始
tree.xpath('//li[1]/a/text()') # 获取第一个 tree.xpath('//li[last()]/a/text()') # 获取最后一个 tree.xpath('//li[last()-1]/a/text()') # 获取倒数第二个 -
模糊查询
-
查询所有id属性中包含he的div标签
//div[contains(@id, "he")] -
查询所有id属性中包以he开头的div标签
//div[starts-with(@id, "he")]
-
-
内容查询
查找所有div标签下的直接子节点h1的内容
//div/h1/text() -
属性值获取
//div/a/@href 获取a里面的href属性值 -
获取所有
//* #获取所有 //*[@class="xx"] #获取所有class为xx的标签 -
获取节点内容转换成字符串
c = tree.xpath('//li/a')[0] result=etree.tostring(c, encoding='utf-8') print(result.decode('UTF-8'))
练习:
-
豆瓣
匹配出虚构类和非虚构类中的图片,标题和简介
-
股票数据
抓到每一行股票数据
前情摘要
一、web请求全过程剖析
我们浏览器在输入完网址到我们看到网页的整体内容, 这个过程中究竟发生了些什么?
我们看一下一个浏览器请求的全过程



接下来就是一个比较重要的事情了. 所有的数据都在页面源代码里么? 非也~ 这里要介绍一个新的概念
那就是页面渲染数据的过程, 我们常见的页面渲染过程有两种,
-
服务器渲染, 你需要的数据直接在页面源代码里能搜到
这个最容易理解, 也是最简单的. 含义呢就是我们在请求到服务器的时候, 服务器直接把数据全部写入到html中, 我们浏览器就能直接拿到带有数据的html内容. 比如,

由于数据是直接写在html中的, 所以我们能看到的数据都在页面源代码中能找的到的.
这种网页一般都相对比较容易就能抓取到页面内容.
-
前端JS渲染, 你需要的数据在页面源代码里搜不到
这种就稍显麻烦了. 这种机制一般是第一次请求服务器返回一堆HTML框架结构. 然后再次请求到真正保存数据的服务器, 由这个服务器返回数据, 最后在浏览器上对数据进行加载. 就像这样:

js渲染代码(示例)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>案例:动态渲染页面</title> <style> table{ width: 300px; text-align: center; } </style> </head> <body> <table border="1" cellspacing="0"> <thead> <tr> <th>ID</th> <th>姓名</th> <th>年龄</th> </tr> </thead> <tbody> <!-- js渲染--> </tbody> </table> <script> //提前准备好的数据 var users = [ {id: 1, name: '张三', age: 18}, {id: 2, name: '李四', age: 28}, {id: 3, name: '王麻子', age: 38} ] //获取tbody标签 var tbody = document.querySelector('tbody') //1.循环遍历users数据 users.forEach(function (item) { //这里的item 就是数组中的每一个对象 console.log(item) //2. 每一个对象生成一个tr标签 var tr = document.createElement('tr') //循环遍历item for(var key in item){ //生成td标签 var td = document.createElement('td') td.innerHTML = item[key] //5.把td 插入到tr内部 tr.appendChild(td) } //把本次的tr插入到tbody的内部 tbody.appendChild(tr) }) </script> </body> </html>这样做的好处是服务器那边能缓解压力. 而且分工明确. 比较容易维护. 典型的有这么一个网页

那数据是何时加载进来的呢? 其实就是在我们进行页面向下滚动的时候, jd就在偷偷的加载数据了, 此时想要看到这个页面的加载全过程, 我们就需要借助浏览器的调试工具了(F12)



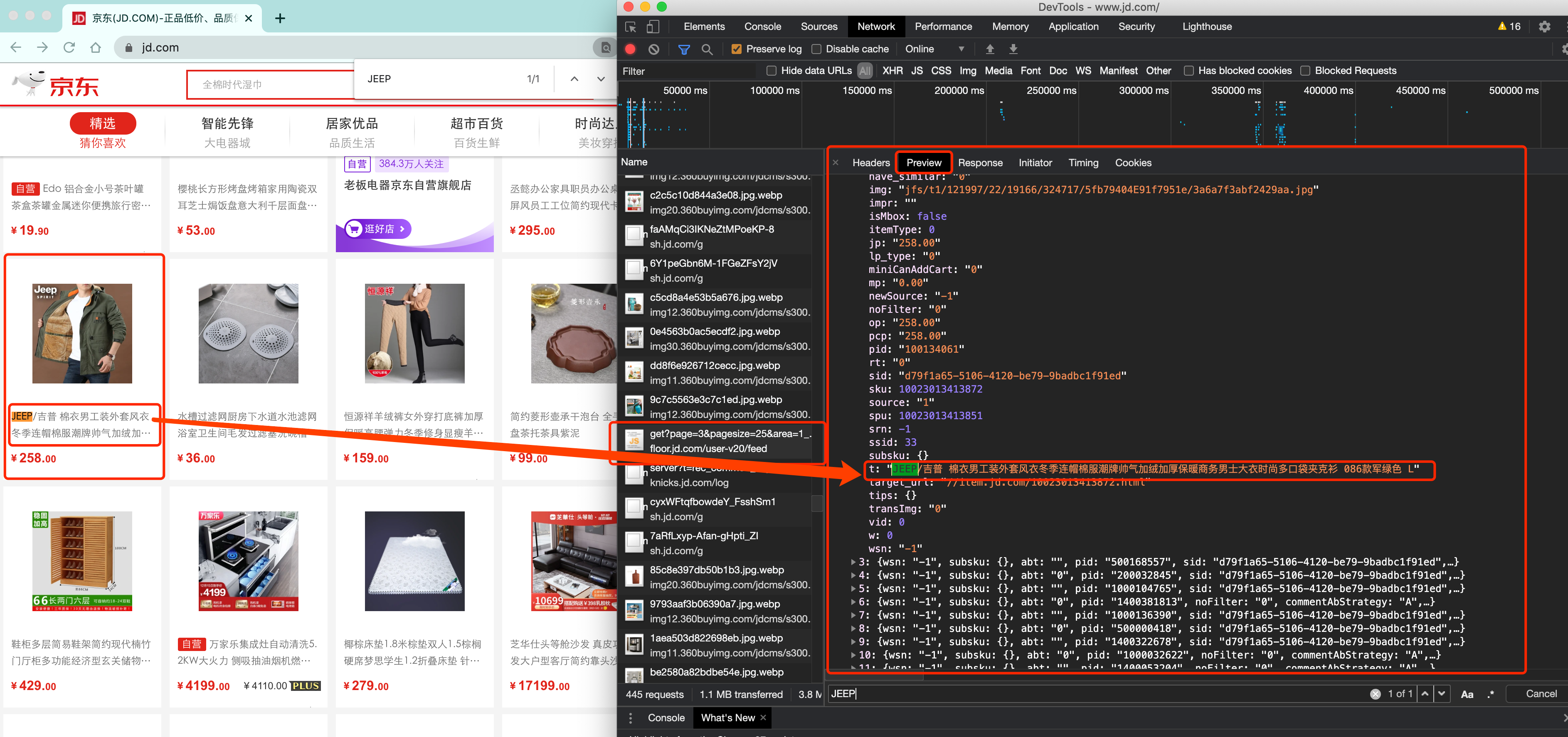
看到了吧, 页面上看到的内容其实是后加载进来的.
OK, 在这里我不是要跟各位讲jd有多牛B, 也不是说这两种方式有什么不同, 只是想告诉各位, 有些时候, 我们的数据不一定都是直接来自于页面源代码. 如果你在页面源代码中找不到你要的数据时, 那很可能数据是存放在另一个请求里.
1.你要的东西在页面源代码. 直接拿`源代码`提取数据即可
2.你要的东西,不在页面源代码, 需要想办法找到真正的加载数据的那个请求. 然后提取数据
二、浏览器工具的使用
Chrome是一款非常优秀的浏览器. 不仅仅体现在用户使用上. 对于我们开发人员而言也是非常非常好用的.
对于一名爬虫工程师而言. 浏览器是最能直观的看到网页情况以及网页加载内容的地方. 我们可以按下F12来查看一些普通用户很少能使用到的工具.

其中, 最重要的Elements, Console, Sources, Network.
Elements是我们实时的网页内容情况, 注意, 很多兄弟尤其到了后期. 非常容易混淆Elements以及页面源代码之间的关系.
注意,
- 页面源代码是执行js脚本以及用户操作之前的服务器返回给我们最原始的内容
- Elements中看到的内容是js脚本以及用户操作之后的当时的页面显示效果.
你可以理解为, 一个是老师批改之前的卷子, 一个是老师批改之后的卷子. 虽然都是卷子. 但是内容是不一样的. 而我们目前能够拿到的都是页面源代码. 也就是老师批改之前的样子. 这一点要格外注意.
在Elements中我们可以使用左上角的小箭头.可以直观的看到浏览器中每一块位置对应的当前html状况. 还是很贴心的.

第二个窗口, Console是用来查看程序员留下的一些打印内容, 以及日志内容的. 我们可以在这里输入一些js代码自动执行.

等咱们后面讲解js逆向的时候会用到这里.
第三个窗口, Source, 这里能看到该网页打开时加载的所有内容. 包括页面源代码. 脚本. 样式, 图片等等全部内容.

第四个窗口, Network, 我们一般习惯称呼它为抓包工具. 在这里, 我们能看到当前网页加载的所有网路网络请求, 以及请求的详细内容. 这一点对我们爬虫来说至关重要.




其他更加具体的内容. 随着咱们学习的展开. 会逐一进行讲解.
三、反爬虫的一般手段
爬虫项目最复杂的不是页面信息的提取,反而是爬虫与反爬虫、反反爬虫的博弈过程
-
User-Agent
浏览器的标志信息,会通过请求头传递给服务器,用以说明访问数据的浏览器信息
反爬虫:先检查是否有UA,或者UA是否合法
-
代理IP
-
验证码访问
-
动态加载网页
-
数据加密
-
...
四、常见HTTP状态码
-
200:这个是最常见的http状态码,表示服务器已经成功接受请求,并将返回客户端所请
-
100-199 用于指定客户端应相应的某些动作。
-
200-299 用于表示请求成功。
-
300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息。
-
400-499 用于指出客户端的错误。
- 404:请求失败,客户端请求的资源没有找到或者是不存在
-
500-599 服务器遇到未知的错误,导致无法完成客户端当前的请求。
urllib与requests
一、urllib的学习
学习目标
了解urllib的基本使用
1、urllib介绍
除了requests模块可以发送请求之外, urllib模块也可以实现请求的发送,只是操作方法略有不同!
urllib在python中分为urllib和urllib2,在python3中为urllib
下面以python3的urllib为例进行讲解
2、urllib的基本方法介绍
2.1 urllib.Request
-
构造简单请求
import urllib #构造请求 request = urllib.request.Request("http://www.baidu.com") #发送请求获取响应 response = urllib.request.urlopen(request) -
传入headers参数
import urllib #构造headers headers = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"} #构造请求 request = urllib.request.Request(url, headers = headers) #发送请求 response = urllib.request.urlopen(request) -
传入data参数 实现发送post请求(示例)
import urllib.request import urllib.parse import json url = 'https://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_ciba&sign=99730f3bf66b2582' headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.0 Safari/605.1.15', } data = { 'from': 'zh', 'to': 'en', 'q': 'lucky 是一个帅气的老' } # 使用post方式 # 需要 data = urllib.parse.urlencode(data).encode('utf-8') req = urllib.request.Request(url, data=data, headers=headers) res = urllib.request.urlopen(req) print(res.getcode()) print(res.geturl()) data = json.loads(res.read().decode('utf-8')) print(data)
2.2 response.read()
获取响应的html字符串,bytes类型
#发送请求
response = urllib.request.urlopen("http://www.baidu.com")
#获取响应
response.read()
3、urllib请求百度首页的完整例子
import urllib
import json
url = 'http://www.baidu.com'
#构造headers
headers = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"}
#构造请求
request = urllib.request.Request(url, headers = headers)
#发送请求
response = urllib.request.urlopen(request)
#获取html字符串
html_str = response.read().decode('utf-8')
print(html_str)
4、小结
- urllib.request中实现了构造请求和发送请求的方法
- urllib.request.Request(url,headers,data)能够构造请求
- urllib.request.urlopen能够接受request请求或者url地址发送请求,获取响应
- response.read()能够实现获取响应中的bytes字符串
requests模块的入门使用
一、requests模块的入门使用
学习目标:
- 了解 requests模块的介绍
- 掌握 requests的基本使用
- 掌握 response常见的属性
- 掌握 requests.text和content的区别
- 掌握 解决网页的解码问题
- 掌握 requests模块发送带headers的请求
- 掌握 requests模块发送带参数的get请求
1、为什么要重点学习requests模块,而不是urllib
- 企业中用的最多的就是requests
- requests的底层实现就是urllib
- requests在python2 和python3中通用,方法完全一样
- requests简单易用
2、requests的作用与安装
作用:发送网络请求,返回响应数据
安装:pip install requests
3、requests模块发送简单的get请求、获取响应
需求:通过requests向百度首页发送请求,获取百度首页的数据
import requests
# 目标url
url = 'https://www.baidu.com'
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.text)
response的常用属性:
-
response.text响应体 str类型 -
response.encoding从HTTP header中猜测的响应内容的编码方式 -
respones.content响应体 bytes类型 -
response.status_code响应状态码 -
response.request.headers响应对应的请求头 -
response.headers响应头 -
response.cookies响应的cookie(经过了set-cookie动作) -
response.url获取访问的url -
response.json()获取json数据 得到内容为字典 (如果接口响应体的格式是json格式时) -
response.ok如果status_code小于200,response.ok返回True。
如果status_code大于200,response.ok返回False。
思考:text是response的属性还是方法呢?
- 一般来说名词,往往都是对象的属性,对应的动词是对象的方法
3.1 response.text 和response.content的区别
response.text- 类型:str
- 解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
- 如何修改编码方式:
response.encoding="gbk/UTF-8"
response.content- 类型:bytes
- 解码类型: 没有指定
- 如何修改编码方式:
response.content.deocde("utf8")
获取网页源码的通用方式:
response.content.decode()response.content.decode("UTF-8")response.text
以上三种方法从前往后尝试,能够100%的解决所有网页解码的问题
所以:更推荐使用response.content.deocde()的方式获取响应的html页面
3.2 练习:把网络上的图片保存到本地
我们来把
www.baidu.com的图片保存到本地
思考:
- 以什么方式打开文件
- 保存什么格式的内容
分析:
- 图片的url: https://www.baidu.com/img/bd_logo1.png
- 利用requests模块发送请求获取响应
- 以2进制写入的方式打开文件,并将response响应的二进制内容写入
import requests
# 图片的url
url = 'https://www.baidu.com/img/bd_logo1.png'
# 响应本身就是一个图片,并且是二进制类型
response = requests.get(url)
# print(response.content)
# 以二进制+写入的方式打开文件
with open('baidu.png', 'wb') as f:
# 写入response.content bytes二进制类型
f.write(response.content)
4、发送带header的请求
我们先写一个获取百度首页的代码
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(response.content)
# 打印响应对应请求的请求头信息
print(response.request.headers)
4.1 思考
对比浏览器上百度首页的网页源码和代码中的百度首页的源码,有什么不同?
代码中的百度首页的源码非常少,为什么?
4.2 为什么请求需要带上header?
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
4.3 header的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
4.4 用法
requests.get(url, headers=headers)
4.5 完整的代码
import requests
url = 'https://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 在请求头中带上User-Agent,模拟浏览器发送请求
response = requests.get(url, headers=headers)
# print(response.content)
# 打印请求头信息
print(response.request.headers)
5、发送带参数的请求
我们在使用百度搜索的时候经常发现url地址中会有一个
?,那么该问号后边的就是请求参数,又叫做查询字符串
5.1 什么叫做请求参数:
例1: http://www.webkaka.com/tutorial/server/2015/021013/
例2:https://www.baidu.com/s?wd=python&a=c
例1中没有请求参数!例2中?后边的就是请求参数
5.2 请求参数的形式:字典
kw = {'wd':'长城'}
5.3 请求参数的用法
requests.get(url,params=kw)
5.4 关于参数的注意点
在url地址中, 很多参数是没有用的,比如百度搜索的url地址,其中参数只有一个字段有用,其他的都可以删除 如何确定那些请求参数有用或者没用:挨个尝试! 对应的,在后续的爬虫中,越到很多参数的url地址,都可以尝试删除参数
5.5 两种方式:发送带参数的请求
-
对
https://www.baidu.com/s?wd=python发起请求可以使用requests.get(url, params=kw)的方式# 方式一:利用params参数发送带参数的请求 import requests headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # 这是目标url # url = 'https://www.baidu.com/s?wd=python' # 最后有没有问号结果都一样 url = 'https://www.baidu.com/s?' # 请求参数是一个字典 即wd=python kw = {'wd': 'python'} # 带上请求参数发起请求,获取响应 response = requests.get(url, headers=headers, params=kw) # 当有多个请求参数时,requests接收的params参数为多个键值对的字典,比如 '?wd=python&a=c'-->{'wd': 'python', 'a': 'c'} print(response.content) -
也可以直接对
https://www.baidu.com/s?wd=python完整的url直接发送请求,不使用params参数# 方式二:直接发送带参数的url的请求 import requests headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} url = 'https://www.baidu.com/s?wd=python' # kw = {'wd': 'python'} # url中包含了请求参数,所以此时无需params response = requests.get(url, headers=headers)
6、小结
- requests模块的介绍:能够帮助我们发起请求获取响应
- requests的基本使用:
requests.get(url) - 以及response常见的属性:
response.text响应体 str类型respones.content响应体 bytes类型response.status_code响应状态码response.request.headers响应对应的请求头response.headers响应头response.request._cookies响应对应请求的cookieresponse.cookies响应的cookie(经过了set-cookie动作)
- 掌握 requests.text和content的区别:text返回str类型,content返回bytes类型
- 掌握 解决网页的解码问题:
response.content.decode()response.content.decode("UTF-8")response.text
- 掌握 requests模块发送带headers的请求:
requests.get(url, headers={}) - 掌握 requests模块发送带参数的get请求:
requests.get(url, params={})
二、requests模块的深入使用
学习目标:
- 能够应用requests发送post请求的方法
- 能够应用requests模块使用代理的方法
- 了解代理ip的分类
1、使用requests发送POST请求
思考:哪些地方我们会用到POST请求?
- 登录注册( POST 比 GET 更安全)
- 需要传输大文本内容的时候( POST 请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方回去模拟浏览器发送post请求
1.1 requests发送post请求语法:
-
用法:
response = requests.post("http://www.baidu.com/", data = data, headers=headers) -
data 的形式:字典
1.2 POST请求练习
下面面我们通过金山翻译的例子看看post请求如何使用:
思路分析
-
抓包确定请求的url地址

-
确定请求的参数

-
确定返回数据的位置

-
模拟浏览器获取数据
import requests import json headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} url = 'https://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_ciba&sign=99730f3bf66b2582' data = { 'from': 'zh', 'to': 'en', 'q': 'lucky 是一个帅气的老师' } res = requests.post(url, headers=headers, data=data) # print(res.status_code) # 返回的是json字符串 需要在进行转换为字典 data = json.loads(res.content.decode('UTF-8')) # print(type(data)) print(data) print(data['content']['out'])
1.3 小结
在模拟登陆等场景,经常需要发送post请求,直接使用requests.post(url,data)即可
2、使用代理
2.1 为什么要使用代理
- 让服务器以为不是同一个客户端在请求
- 防止我们的真实地址被泄露,防止被追究
2.2 理解使用代理的过程

2.3 理解正向代理和反向代理的区别

通过上图可以看出:
- 正向代理:对于浏览器知道服务器的真实地址,例如VPN
- 反向代理:浏览器不知道服务器的真实地址,例如nginx
详细讲解:
正向代理是客户端与正向代理客户端在同一局域网,客户端发出请求,正向代理 替代客户端向服务器发出请求。服务器不知道谁是真正的客户端,正向代理隐藏了真实的请求客户端。
反向代理:服务器与反向代理在同一个局域网,客服端发出请求,反向代理接收请求 ,反向代理服务器会把我们的请求分转发到真实提供服务的各台服务器Nginx就是性能非常好的反向代理服务器,用来做负载均衡

2.4 代理的使用
-
用法:
requests.get("http://www.baidu.com", proxies = proxies) -
proxies的形式:字典
-
例如:
proxies = { "http": "http://12.34.56.79:9527", "https": "https://12.34.56.79:9527", }
2.5 代理IP的分类
根据代理ip的匿名程度,代理IP可以分为下面四类:
- 透明代理(Transparent Proxy):透明代理的意思是客户端根本不需要知道有代理服务器的存在,但是它传送的仍然是真实的IP。使用透明代理时,对方服务器是可以知道你使用了代理的,并且他们也知道你的真实IP。你要想隐藏的话,不要用这个。透明代理为什么无法隐藏身份呢?因为他们将你的真实IP发送给了对方服务器,所以无法达到保护真实信息。
- 匿名代理(Anonymous Proxy):匿名代理隐藏了您的真实IP,但是向访问对象可以检测是使用代理服务器访问他们的。会改变我们的请求信息,服务器端有可能会认为我们使用了代理。不过使用此种代理时,虽然被访问的网站不能知道你的ip地址,但仍然可以知道你在使用代理,当然某些能够侦测ip的网页也是可以查到你的ip。(https://wenku.baidu.com/view/9bf7b5bd3a3567ec102de2bd960590c69fc3d8cf.html)
- 高匿代理(Elite proxy或High Anonymity Proxy):高匿名代理不改变客户机的请求,这样在服务器看来就像有个真正的客户浏览器在访问它,这时客户的真实IP是隐藏的,完全用代理服务器的信息替代了您的所有信息,就象您就是完全使用那台代理服务器直接访问对象,同时服务器端不会认为我们使用了代理。IPDIEA覆盖全球240+国家地区ip高匿名代理不必担心被追踪。
在使用的使用,毫无疑问使用高匿代理效果最好
从请求使用的协议可以分为:
- http代理
- https代理
- socket代理等
不同分类的代理,在使用的时候需要根据抓取网站的协议来选择
2.6 代理IP使用的注意点
-
反反爬
使用代理ip是非常必要的一种
反反爬的方式但是即使使用了代理ip,对方服务器任然会有很多的方式来检测我们是否是一个爬虫,比如:
-
一段时间内,检测IP访问的频率,访问太多频繁会屏蔽
-
检查Cookie,User-Agent,Referer等header参数,若没有则屏蔽
-
服务方购买所有代理提供商,加入到反爬虫数据库里,若检测是代理则屏蔽
所以更好的方式在使用代理ip的时候使用随机的方式进行选择使用,不要每次都用一个代理ip
-
-
代理ip池的更新
购买的代理ip很多时候大部分(超过60%)可能都没办法使用,这个时候就需要通过程序去检测哪些可用,把不能用的删除掉。
-
代理服务器平台的使用:
当然还有很多免费的,但是大多都不可用需要自己尝试
3、配置
-
浏览器配置代理
右边三点==> 设置==> 高级==> 代理==> 局域网设置==> 为LAN使用代理==> 输入ip和端口号即可
参考网址:https://jingyan.baidu.com/article/a681b0dece76407a1843468d.html
-
代码配置
urllib
handler = urllib.request.ProxyHandler({'http': '114.215.95.188:3128'}) opener = urllib.request.build_opener(handler) # 后续都使用opener.open方法去发送请求即可requests
# 用到的库 import requests # 写入获取到的ip地址到proxy # 一个ip地址 proxy = { 'https':'https://221.178.232.130:8080' } """ # 多个ip地址 proxy = [ {'https':'221.178.232.130:8080'}, {'https':'221.178.232.130:8080'} ] import random proxy = random.choice(proxy) """ # 用百度检测ip代理是否成功 url = 'https://www.baidu.com/s?' # 请求网页传的参数 params={ 'wd':'ip地址' } # 请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' } # 发送get请求 response = requests.get(url=url,headers=headers,params=params,proxies=proxy) # 获取返回页面保存到本地,便于查看 with open('ip.html','w',encoding='utf-8') as f: f.write(response.text)
4、小结
- requests发送post请求使用requests.post方法,带上请求体,其中请求体需要时字典的形式,传递给data参数接收
- 在requests中使用代理,需要准备字典形式的代理,传递给proxies参数接收
- 不同协议的url地址,需要使用不同的代理去请求
三、requests模块处理cookie相关的请求
学习目标
掌握requests处理cookie的三种方法
1 爬虫中使用cookie
为了能够通过爬虫获取到登录后的页面,或者是解决通过cookie的反扒,需要使用request来处理cookie相关的请求
1.1 爬虫中使用cookie的利弊
- 带上cookie的好处
- 能够访问登录后的页面
- 能够实现部分反反爬
- 带上cookie的坏处
- 一套cookie往往对应的是一个用户的信息,请求太频繁有更大的可能性被对方识别为爬虫
- 那么上面的问题如何解决 ?使用多个账号
1.2 requests处理cookie的方法
使用requests处理cookie有三种方法:
- cookie字符串放在headers中
- 把cookie字典放传给请求方法的cookies参数接收
- 使用requests提供的session模块
2、cookie添加在heades中
2.1 headers中cookie的位置

- headers中的cookie:
- 使用分号(;)隔开
- 分号两边的类似a=b形式的表示一条cookie
- a=b中,a表示键(name),b表示值(value)
- 在headers中仅仅使用了cookie的name和value
2.2 cookie的具体组成的字段

由于headers中对cookie仅仅使用它的name和value,所以在代码中我们仅仅需要cookie的name和value即可
2.3 在headers中使用cookie
复制浏览器中的cookie到代码中使用
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Cookie":" Pycharm-26c2d973=dbb9b300-2483-478f-9f5a-16ca4580177e; Hm_lvt_98b9d8c2fd6608d564bf2ac2ae642948=1512607763; Pycharm-26c2d974=f645329f-338e-486c-82c2-29e2a0205c74; _xsrf=2|d1a3d8ea|c5b07851cbce048bd5453846445de19d|1522379036"}
requests.get(url,headers=headers)
注意:
cookie有过期时间 ,所以直接复制浏览器中的cookie可能意味着下一程序继续运行的时候需要替换代码中的cookie,对应的我们也可以通过一个程序专门来获取cookie供其他程序使用;当然也有很多网站的cookie过期时间很长,这种情况下,直接复制cookie来使用更加简单
3、使用cookies参数接收字典形式的cookie
- cookies的形式:字典
cookies = {"cookie的name":"cookie的value"}
- 使用方法:
requests.get(url,headers=headers,cookies=cookie_dict)
-
实例(爬取雪球网)
在网络中找到当前请求的网址 点击cookies 将当前的k,value复制到代码中

cookie_dict = { 'u': '1990923459', 'bid': '1f110dfd43538f4b8362dfcd21ffbb64_l27g4lfl', 'xq_is_login': '1', 'xq_r_token': '5dcbe83944f0b75325f91246061d4a2a01999367' }完整代码
import requests # 携带cookie登录雪球网 抓取完善个人资料页面 headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36', 'Referer': 'https://xueqiu.com/u/1990923459', 'Host': 'xueqiu.com', } url = 'https://xueqiu.com/users/connectnew?redirect=/setting/user' cookie_dict = { 'u': '1990923459', 'bid': '1f110dfd43538f4b8362dfcd21ffbb64_l27g4lfl', 'xq_is_login': '1', 'xq_r_token': '5dcbe83944f0b75325f91246061d4a2a01999367' } res = requests.get(url, headers=headers, cookies=cookie_dict) with open('雪球网.html', 'w') as f: f.write(res.content.decode('UTF-8')) print(res.content.decode('UTF-8'))成果

4、使用requests.session处理cookie
前面使用手动的方式使用cookie,那么有没有更好的方法在requets中处理cookie呢?
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持
会话保持有两个内涵:
- 保存cookie,下一次请求会带上前一次的cookie
- 实现和服务端的长连接,加快请求速度
4.1 使用方法
session = requests.session()
response = session.get(url,headers)
session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie
4.2 动手练习:模拟登陆
-
17k小说网 https://passport.17k.com/
-
打码平台
思路分析
- 准备url地址和请求参数
- 构造session发送post请求
- 使用session请求个人主页,观察是否请求成功
5、小结
- cookie字符串可以放在headers字典中,键为Cookie,值为cookie字符串
- 可以把cookie字符串转化为字典,使用请求方法的cookies参数接收
- 使用requests提供的session模块,能够自动实现cookie的处理,包括请求的时候携带cookie,获取响应的时候保存cookie
四、requests模块的其他方法
学习目标
- 掌握requests中cookirJar的处理方法
- 掌握requests解决https证书错误的问题
- 掌握requests中超时参数的使用
1、requests中cookirJar的处理方法
使用request获取的resposne对象,具有cookies属性,能够获取对方服务器设置在本地的cookie,但是如何使用这些cookie呢?
1.1 方法介绍
- response.cookies是CookieJar类型
- 使用requests.utils.dict_from_cookiejar,能够实现把cookiejar对象转化为字典
1.2 方法展示
import requests
url = "http://www.baidu.com"
#发送请求,获取resposne
response = requests.get(url)
print(type(response.cookies))
#使用方法从cookiejar中提取数据 等同于 dict(response.cookies)
cookies = requests.utils.dict_from_cookiejar(response.cookies)
print(cookies)
输出为:
<class 'requests.cookies.RequestsCookieJar'>
{'BDORZ': '27315'}
注意:
在前面的requests的session类中,我们不需要处理cookie的任何细节,如果有需要,我们可以使用上述方法来解决
2、requests处理证书错误
经常我们在网上冲浪时,经常能够看到下面的提示:

出现这个问题的原因是:ssl的证书不安全导致
2.1 代码中发起请求的效果
那么如果在代码中请求会怎么样呢?
import requests
url = "https://www.12306.cn/mormhweb/"
response = requests.get(url)
返回证书错误,如下:
ssl.CertificateError ...
2.2 解决方案
为了在代码中能够正常的请求,我们修改添加一个参数
import requests
url = "https://www.12306.cn/mormhweb/"
response = requests.get(url, verify=False)
3、超时参数的使用
在平时网上冲浪的过程中,我们经常会遇到网络波动,这个时候,一个请求等了很久可能任然没有结果
在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这个时候我们就需要对请求进行强制要求,让他必须在特定的时间内返回结果,否则就报错
3.1 超时参数使用方法如下:
response = requests.get(url,timeout=3)
通过添加timeout参数,能够保证在3秒钟内返回响应,否则会报错
注意:
这个方法还能够拿来检测代理ip的质量,如果一个代理ip在很长时间没有响应,那么添加超时之后也会报错,对应的这个ip就可以从代理ip池中删除
高效编程
一、多任务原理
-
概念
现代操作系统比如Mac OS X,UNIX,Linux,Windows等,都是支持“多任务”的操作系统
-
什么叫多任务?
就是操作系统可以同时运行多个任务
-
单核CPU实现多任务原理
操作系统轮流让各个任务交替执行,QQ执行2us(微秒),切换到微信,在执行2us,再切换到陌陌,执行2us……。表面是看,每个任务反复执行下去,但是CPU调度执行速度太快了,导致我们感觉就像所有任务都在同时执行一样

-
多核CPU实现多任务原理
真正的秉性执行多任务只能在多核CPU上实现,但是由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行

-
并发与并行
-
并发
CPU调度执行速度太快了,看上去一起执行,任务数多于CPU核心数
-
并行
真正一起执行,任务数小于等于CPU核心数
-
并发是逻辑上的同时发生,并行更多是侧重于物理上的同时发生。
-
-
实现多任务的方式
-
多进程模式
启动多个进程,每个进程虽然只有一个线程,但是多个进程可以一起执行多个任务
-
多线程模式
启动一个进程,在一个进程的内部启动多个线程,这样多个线程也可以一起执行多个任务
-
多进程+多线程
启动多个进程,每个进程再启动多个线程
-
协程
-
多进程+协程
-
二、进程
1、概念
-
什么是进程?
是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。
-
对于操作系统
一个任务就是一个进程。比方说打开浏览器就是启动一个浏览器的进程,在打开一个记事本就启动一个记事本进程,如果打开两个记事本就启动两个记事本进程
2、使用进程
-
单进程现象
需要等待代码执行完后再执行下一段代码
import time def run1(): while 1: print("lucky is a good man") time.sleep(1) def run2(): while 1: print("lucky is a nice man") time.sleep(1) if __name__ == "__main__": run1() # 不会执行run2()函数,只有上面的run1()结束才能执行run2() run2() -
启动进程实现多任务
-
multiprocessing模块
跨平台的多进程模块,提供了一个Process类用来实例化一个进程对象
-
Process类
作用:创建进程(子进程)
-
__name__
这是 Windows 上多进程的实现问题。在 Windows 上,子进程会自动 import 启动它的这个文件,而在 import 的时候是会执行这些语句的。如果你这么写的话就会无限递归创建子进程报错。所以必须把创建子进程的部分用那个 if 判断保护起来,import 的时候
__name__不是__main__,就不会递归运行了。参数 说明 target 指定进程执行的任务 args 给进程函数传递的参数,是一个元组 注意:此时进程被创建,但是不会启动进程执行
-
启动进程实现多任务
from multiprocessing import Process
创建子进程
P = Process(target=run,args=("nice",),name='当前进程名称')
-
target指定 子进程运行的函数
-
args 指定传递的参数 , 是元组类型
-
启动进程:Process对象.start()
获取进程信息
- os.getpid() 获取当前进程id号
- os.getppid() 获取当前进程的父进程id号
- multiprocessing.current_process().name 获取当前进程名称
父子进程的先后顺序
-
默认 父进程的结束不能影响子进程 让父进程等待子进程结束再执行父进程
-
p.join() 阻塞当前进程,直到调用join方法的那个进程执行完,再继续执行当前进程。
-
全局变量在过个进程中不能共享
注意: 在子线程中修改全局变量时对父进程中的全局变量没有影响
-
-
示例代码
import time from multiprocessing import Process def run1(name): while 1: print("%s is a good man"%name) time.sleep(1) def run2(): while 1: print("lucky is a nice man") time.sleep(1) if __name__ == "__main__": # 程序启动时的进程称为主进程(父进程) # 创建进程并启动 p = Process(target=run1, args=("lucky",)) p.start() # 主进程执行run2()函数 run2()
-
-
主进程负责调度
主进程主要做的是调度相关的工作,一般不负责具体业务逻辑
import time from multiprocessing import Process def run1(): for i in range(7): print("lucky is a good man") time.sleep(1) def run2(name, word): for i in range(5): print("%s is a %s man"%(name, word)) time.sleep(1) if __name__ == "__main__": t1 = time.time() # 创建两个进程分别执行run1、run2 p1 = Process(target=run1) p2 = Process(target=run2, args=("lucky", "cool")) # 启动两个进程 p1.start() p2.start() # 查看耗时 t2 = time.time() print("耗时:%.2f"%(t2-t1)) -
父子进程的先后顺序
主进程的结束不能影响子进程,所以可以等待子进程的结束再结束主进程,等待子进程结束,才能继续运行主进程
p.join() 阻塞当前进程,直到调用join方法的那个进程执行完,再继续执行当前进程。
import time from multiprocessing import Process def run1(): for i in range(7): print("lucky is a good man") time.sleep(1) def run2(name, word): for i in range(5): print("%s is a %s man"%(name, word)) time.sleep(1) if __name__ == "__main__": t1 = time.time() p1 = Process(target=run1) p2 = Process(target=run2, args=("lucky", "cool")) p1.start() p2.start() # 主进程的结束不能影响子进程,所以可以等待子进程的结束再结束主进程 # 等待子进程结束,才能继续运行主进程 p1.join() p2.join() t2 = time.time() print("耗时:%.2f"%(t2-t1))
3、全局变量在多个子进程中不能共享
原因:
在创建子进程时对全局变量做了一个备份,父进程中num变量与子线程中的num不是一个变量
from multiprocessing import Process
#全局变量在进程中 不能共享
num = 10
def run():
print("我是子进程的开始")
global num
num+=1
print(num)
print("我是子进程的结束")
if __name__=="__main__":
p = Process(target=run)
p.start()
p.join()
print(num)
尝试列表是否能共享
from multiprocessing import Process
#全局变量在进程中 不能共享
mylist = []
def run():
print("我是子进程的开始")
global mylist
mylist.append(1)
mylist.append(2)
mylist.append(3)
print("我是子进程的结束")
if __name__=="__main__":
p = Process(target=run)
p.start()
p.join()
print(mylist)
4、启动大量子进程
-
获取CPU核心数
print('CPU number:' + str(multiprocessing.cpu_count()))
-
导入
from multiprocesssing import Pool
-
开启并发数
pp = Pool([参数]) #开启并发数 默认是你的核心数
-
创建子进程,并放入进程池管理
apply_async为非阻塞模式(并发执行)
pp.apply_async(run,args=(i,)) #args参数 可以为元组 或者是列表[]
-
关闭进程池
pp.close()关闭进程池
-
join()
在调用join之前必须先调用close,调用close之后就不能再继续添加新的进程了
pp.join()
进程池对象调用join,会等待进程池中所有的子进程结束完毕再去执行父进程
-
实例
# Pool类:进程池类 from multiprocessing import Pool import time import random import multiprocessing def run(index): print('CPU number:' + str(multiprocessing.cpu_count())) print("子进程 %d 启动"%(index)) t1 = time.time() time.sleep(random.random()* 5+2) t2 = time.time() print("子进程 %d 结束,耗时:%.2f" % (index, t2-t1)) if __name__ == "__main__": print("启动主进程……") # 创建进程池对象 # 由于pool的默认值为CPU的核心数,假设有4核心,至少需要5个子进程才能看到效果 # Pool()中的值表示可以同时执行进程的数量 pool = Pool(2) for i in range(1, 7): # 创建子进程,并将子进程放到进程池中统一管理 pool.apply_async(run, args=(i,)) # 等待子进程结束 # 关闭进程池:在关闭后就不能再向进程池中添加进程了 # 进程池对象在调用join之前必须先关闭进程池 pool.close() #pool对象调用join,主进程会等待进程池中的所有子进程结束才会继续执行主进程 pool.join() print("结束主进程……")get方法:获取进程的返回值
from multiprocessing import Lock, Pool import time def function(index): print('Start process: ', index) time.sleep(2) print('End process', index) return index if name == 'main': pool = Pool(processes=3) for i in range(4): result = pool.apply_async(function, (i,)) print(result.get()) #获取每个 子进程的返回值 print("Started processes") pool.close() pool.join() print("Subprocess done.")注意:这样来获取每个进程的返回值 那么就会变成单进程
5、map方法
-
概述
如果你现在有一堆数据要处理,每一项都需要经过一个方法来处理,那么map非常适合
比如现在你有一个数组,包含了所有的URL,而现在已经有了一个方法用来抓取每个URL内容并解析,那么可以直接在map的第一个参数传入方法名,第二个参数传入URL数组。
-
概述
from multiprocessing import Pool import requests from requests.exceptions import ConnectionError def scrape(url): try: print(requests.get(url)) except ConnectionError: print('Error Occured ', url) finally: print('URL', url, ' Scraped') if __name__ == '__main__': pool = Pool(processes=3) urls = [ 'https://www.baidu.com', 'http://www.meituan.com/', 'http://blog.csdn.net/', 'http://xxxyxxx.net' ] pool.map(scrape, urls)在这里初始化一个Pool,指定进程数为3,如果不指定,那么会自动根据CPU内核来分配进程数。
然后有一个链接列表,map函数可以遍历每个URL,然后对其分别执行scrape方法。
6、单进程与多进程复制文件对比
-
单进程复制文件
import time def copy_file(path, toPath): with open(path, "rb") as fp1: with open(toPath, "wb") as fp2: while 1: info = fp1.read(1024) if not info: break else: fp2.write(info) fp2.flush() if __name__ == "__main__": t1 = time.time() for i in range(1, 5): path = r"/Users/lucky/Desktop/file/%d.mp4"%i toPath = r"/Users/lucky/Desktop/file2/%d.mp4"%i copy_file(path, toPath) t2 = time.time() print("单进程耗时:%.2f"%(t2-t1)) -
多进程复制文件
import time from multiprocessing import Pool import os def copy_file(path, toPath): with open(path, "rb") as fp1: with open(toPath, "wb") as fp2: while 1: info = fp1.read(1024) if not info: break else: fp2.write(info) fp2.flush() if __name__ == "__main__": t1 = time.time() path = r"/Users/xialigang/Desktop/视频" dstPath = r"/Users/xialigang/Desktop/1视频" fileList = os.listdir(path) pool = Pool() for i in fileList: newPath1 = os.path.join(path, i) newPath2 = os.path.join(dstPath, i) pool.apply_async(copy_file, args=(newPath1, newPath2)) pool.close() pool.join() t2 = time.time() print("耗时:%.2f"%(t2-t1))
7、进程间通信
-
队列共享
-
导入
from multiprocessing import Queue
-
使用
que = Queue() #创建队列
que.put(数据) #压入数据
que.get() #获取数据
-
队列常用函数
Queue.empty() 如果队列为空,返回True, 反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.get([block[, timeout]]) 获取队列,timeout等待时间
Queue.get_nowait() 相当Queue.get(False)
Queue.put(item) 阻塞式写入队列,timeout等待时间
Queue.put_nowait(item) 相当Queue.put(item, False)
-
特点:先进先出
-
注意:
get方法有两个参数,blocked和timeout,意思为阻塞和超时时间。默认blocked是true,即阻塞式。
当一个队列为空的时候如果再用get取则会阻塞,所以这时候就需要吧blocked设置为false,即非阻塞式,实际上它就会调用get_nowait()方法,此时还需要设置一个超时时间,在这么长的时间内还没有取到队列元素,那就抛出Queue.Empty异常。
当一个队列为满的时候如果再用put放则会阻塞,所以这时候就需要吧blocked设置为false,即非阻塞式,实际上它就会调用put_nowait()方法,此时还需要设置一个超时时间,在这么长的时间内还没有放进去元素,那就抛出Queue.Full异常。
另外队列中常用的方法
-
队列的大小
Queue.qsize() 返回队列的大小 ,不过在 Mac OS 上没法运行。
实例
import multiprocessing queque = multiprocessing.Queue() #创建 队列 #如果在子进程 和主进程 之间 都压入了数据 那么在主进程 和 子进程 获取的就是 对方的数据 def fun(myque): # print(id(myque)) #获取当前的队列的存储地址 依然是拷贝了一份 myque.put(['a','b','c']) #在子进程里面压入数据 # print("子进程获取",myque.get())#获取队列里面的值 if __name__=='__main__': # print(id(queque)) queque.put([1,2,3,4,5]) #将列表压入队列 如果主进程也压入了数据 那么在主进程取的就是在主进程压入的数据 而不是子进程的 p = multiprocessing.Process(target=fun,args=(queque,)) p.start() p.join() print("主进程获取",queque.get())#在主进程进行获取 print("主进程获取",queque.get())#在主进程进行获取 # print("主进程获取",queque.get(block=True, timeout=1))#在主进程进行获取 -
-
字典共享
-
导入
import multiprocess
-
概述
Manager是一个进程间高级通信的方法 支持Python的字典和列表的数据类型
-
创建字典
myDict = multiprocess.Manager().dict()
实例
import multiprocessing def fun(mydict): # print(mylist) mydict['x'] = 'x' mydict['y'] = 'y' mydict['z'] = 'z' if name=='main': # Manager是一种较为高级的多进程通信方式,它能支持Python支持的的任何数据结构。 mydict = multiprocessing.Manager().dict() p = multiprocessing.Process(target=fun,args=(mydict,)) p.start() p.join() print(mydict) -
-
列表共享
-
导入
import multiprocess
-
创建列表
myDict = multiprocess.Manager().list()
实例(字典与列表共享)
import multiprocessing def fun(List): # print(mylist) List.append('x') List.append('y') List.append('z') if __name__=='__main__': # Manager是一种较为高级的多进程通信方式,它能支持Python支持的的任何数据结构。 List = multiprocessing.Manager().list() p = multiprocessing.Process(target=fun,args=(List,)) p.start() p.join() print(List) -
-
注意
进程名.terminate() 强行终止子进程
-
deamon
在这里介绍一个属性,叫做deamon。每个进程程都可以单独设置它的属性,如果设置为True,当父进程结束后,子进程会自动被终止。
进程.daemon = True
设置在start()方法之前
import multiprocessing import time def fun(): time.sleep(100) if __name__=='__main__': p = multiprocessing.Process(target=fun) p.daemon = True p.start() print('over') -
进程名.terminate() 强行终止子进程
import multiprocessing import time def fun(): time.sleep(100) if __name__=='__main__': p = multiprocessing.Process(target=fun) p.start() p.terminate() p.join() print('over')
8、进程实现生产者消费者
生产者消费者模型描述:
生产者是指生产数据的任务,消费者是指消费数据的任务。
当生产者的生产能力远大于消费者的消费能力,生产者就需要等消费者消费完才能继续生产新的数据,同理,如果消费者的消费能力远大于生产者的生产能力,消费者就需要等生产者生产完数据才能继续消费,这种等待会造成效率的低下,为了解决这种问题就引入了生产者消费者模型。
生产者/消费者问题可以描述为:两个或者更多的进程(线程)共享同一个缓冲区,其中一个或多个进程(线程)作为“生产者”会不断地向缓冲区中添加数据,另一个或者多个进程(线程)作为“消费者”从缓冲区中取走数据。
-
代码
from multiprocessing import Process from multiprocessing import Queue import time def product(q): print("启动生产子进程……") for data in ["good", "nice", "cool", "handsome"]: time.sleep(2) print("生产出:%s"%data) # 将生产的数据写入队列 q.put(data) print("结束生产子进程……") def t(q): print("启动消费子进程……") while 1: print("等待生产者生产数据") # 获取生产者生产的数据,如果队列中没有数据会阻塞,等待队列中有数据再获取 value = q.get() print("消费者消费了%s数据"%(value)) print("结束消费子进程……") if __name__ == "__main__": q = Queue() p1 = Process(target=product, args=(q,)) p2 = Process(target=customer, args=(q,)) p1.start() p2.start() p1.join() # p2子进程里面是死循环,无法等待它的结束 # p2.join() # 强制结束子进程 p2.terminate() print("主进程结束")
9、案例(抓取斗图)
from multiprocessing import Process,Queue
from concurrent.futures import ThreadPoolExecutor
from lxml import etree
import time
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
def get_img_src(url, q):
"""
进程1: 负责提取页面中所有的img的下载地址
将图片的下载地址通过队列. 传输给另一个进程进行下载
"""
resp = requests.get(url, headers=headers)
tree = etree.HTML(resp.text)
srcs = tree.xpath("//li[@class='list-group-item']//img[@referrerpolicy='no-referrer']/@data-original")
for src in srcs:
q.put(src.strip())
resp.close()
def download_img(q):
"""
进程2: 将图片的下载地址从队列中提取出来. 进行下载.
"""
with ThreadPoolExecutor(20) as t:
while 1:
try:
s = q.get(timeout=20)
t.submit(donwload_one, s)
except Exception as e:
print(e)
break
def donwload_one(s):
# 单纯的下载功能
resp = requests.get(s, headers=headers)
file_name = s.split("/")[-1]
# 请提前创建好img文件夹
with open(f"img/{file_name}", mode="wb") as f:
f.write(resp.content)
print("一张图片下载完毕", file_name)
resp.close()
if __name__ == '__main__':
t1 = time.time()
q = Queue() # 两个进程必须使用同一个队列. 否则数据传输不了
p_list = []
for i in range(1, 11):
url = f"https://www.pkdoutu.com/photo/list/?page={i}"
p = Process(target=get_img_src, args=(url, q))
p_list.append(p)
for p in p_list:
p.start()
p2 = Process(target=download_img, args=(q,))
p2.start()
for p in p_list:
p.join()
p2.join()
print((time.time()-t1)/60)
# 0.49572664896647134
一、线程
1、概念
-
线程
在一个进程的内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”叫做线程
是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程
线程通常叫做轻型的进程。线程是共享内存空间的并发执行的多任务,每一个线程都共享一个进程的资源
线程是最小的执行单元,而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统决定,程序自己不能决定什么时候执行,执行多长时间
-
多线程
是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。具有这种能力的系统包括对称多处理机、多核心处理器以及芯片级多处理(Chip-level multithreading)或同时多线程(Simultaneous multithreading)处理器。
-
主线程:
任何进程都会有一个默认的主线程 如果主线程死掉 子线也程也死掉 所以 子线程依赖于主线程
-
GIL(了解)
其他语言,CPU 是多核是支持多个线程同时执行。但在 Python 中,无论是单核还是多核,同时只能由一个线程在执行。其根源是 GIL 的存在。
GIL 的全称是 Global Interpreter Lock(全局解释器锁),来源是 Python 设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到 GIL,我们可以把 GIL 看作是“通行证”,并且在一个 Python 进程中,GIL 只有一个。拿不到通行证的线程,就不允许进入 CPU 执行。
并且由于 GIL 锁存在,Python 里一个进程永远只能同时执行一个线程(拿到 GIL 的线程才能执行),这就是为什么在多核CPU上,Python 的多线程效率并不高的根本原因。
-
模块
_thread模块:低级模块
threading模块:高级模块,对_thread进行了封装
2、使用_thread 模块 去创建线程
-
导入模块
import _thread
-
开启线程
_thread.start_new_thread(函数名,参数)
-
注意:
- 参数必须为元组类型
- 如果主线程执行完毕 子线程就会死掉
- 如果线程不需要传参数的时候 也必须传递一个空元组占位
-
实例
import win32api import _thread #引入线程的模块 比较老的模块 新的 threading def run(i): win32api.MessageBox(0,"您的{}号大宝贝上线了".format(i),"来自凤姐以及陆源凯的问候",2) for i in range(5): _thread.start_new_thread(run,(i,)) #发起多个线程 传参的情况 参数为元组 # _thread.start_new_thread(run,()) #发起多个线程 不传参 页需要俩个参数 第二个为空元组 print('会先执行我') #如果主线程 不死 那么 所有的次线程 就都会正常执行 while True: pass提高效率
import _thread import time def run(): for i in range(10): print(i,'------------') time.sleep(1) """ for i in range(5): #50秒 run() """ for i in range(5): _thread.start_new_thread(run,()) #发起五个线程去执行 时间大大缩短 for i in range(10): #循环10秒 计算 线程执行完毕所需要的时间 类似与一个劫停 time.sleep(1) print('xxxx')
3、threading创建线程(重点)
-
导入模块
import threading
-
threading创建线程的方式
myThread = threading.Thread(target=函数名[,args=(参数,),name="你指定的线程名称"])
参数
- target:指定线程执行的函数
- name:指定当前线程的名称
- args:传递各子线程的参数 ,(元组形式)
-
开启线程
myThread.start()
-
线程等待
myThread.join()
-
返回当前线程对象
-
threading.current_thread()
-
threading.currentThread()
-
-
获取当前线程的名称
- threading.current_thread().name
- threading.currentThread().getName()
-
设置线程名
setName()
Thread(target=fun).setName('name') -
返回主线程对象
threading.main_thread()
-
获取当前活着的所有线程总数,包括主线程main
threading.active_count() 或 threading.activeCount()
-
判断线程是不是活的,即线程是否已经结束
-
Thread.is_alive()
-
Thread.isAlive()
-
-
线程守护
设置子线程是否随主线程一起结束
有一个布尔值的参数,默认为False,该方法设置子线程是否随主线程一起结束 True一起结束
Thread.setDaemon(True)
还有个要特别注意的:必须在start() 方法调用之前设置
if __name__ == '__main__': t = Thread(target=fun, args=(1,)) t.setDaemon(True) t.start() print('over') -
获取当前所有的线程名称
threading.enumerate() # 返回当前包含所有线程的列表
4、启动线程实现多任务
import time
import threading
def run1():
# 获取线程名字
print("启动%s子线程……"%(threading.current_thread().name))
for i in range(5):
print("lucky is a good man")
time.sleep(1)
def run2(name, word):
print("启动%s子线程……" % (threading.current_thread().name))
for i in range(5):
print("%s is a %s man"%(name, word))
time.sleep(1)
if __name__ == "__main__":
t1 = time.clock()
# 主进程中默认有一个线程,称为主线程(父线程)
# 主线程一般作为调度而存在,不具体实现业务逻辑
# 创建子线程
# name参数可以设置线程的名称,如果不设置按顺序设置为Thread-n
th1 = threading.Thread(target=run1, name="th1")
th2 = threading.Thread(target=run2, args=("lucky", "nice"))
#启动
th1.start()
th2.start()
#等待子线程结束
th1.join()
th2.join()
t2 = time.clock()
print("耗时:%.2f"%(t2-t1))
5、线程间共享数据
概述
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在每个进程中,互不影响。而多线程中,所有变量都由所有线程共享。所以,任何一个变量都可以被任意一个线程修改,因此,线程之间共享数
据最大的危险在于多个线程同时修改一个变量,容易把内容改乱了。
import time
import threading
money = 0
def run1():
global money
money = 1
print("run1-----------", money)
print("启动%s子线程……"%(threading.current_thread().name))
for i in range(5):
print("lucky is a good man")
time.sleep(1)
def run2(name, word):
print("run2-----------", money)
print("启动%s子线程……" % (threading.current_thread().name))
for i in range(5):
print("%s is a %s man"%(name, word))
time.sleep(1)
if __name__ == "__main__":
t1 = time.clock()
th1 = threading.Thread(target=run1, name="th1")
th2 = threading.Thread(target=run2, args=("lucky", "nice"))
th1.start()
th2.start()
th1.join()
th2.join()
t2 = time.clock()
print("耗时:%.2f"%(t2-t1))
print("main-----------", money)
6、Lock线程锁(多线程内存错乱问题)
-
概述
Lock锁是线程模块中的一个类,有两个主要方法:acquire()和release() 当调用acquire()方法时,它锁定锁的执行并阻塞锁的执行,直到其他线程调用release()方法将其设置为解锁状态。锁帮助我们有效地访问程序中的共享资源,以防止数据损坏,它遵循互斥,因为一次只能有一个线程访问特定的资源。
-
作用
避免线程冲突
-
锁:确保了这段代码只能由一个线程从头到尾的完整执行阻止了多线程的并发执行,包含锁的某段代码实际上只能以单线程模式执行,所以效率大大的降低了 由于可以存在多个锁,不同线程持有不同的锁,并试图获取其他的锁, 可能造成死锁,导致多个线程只能挂起,只能靠操作系统强行终止
-
注意:
- 当前线程锁定以后 后面的线程会等待(线程等待/线程阻塞)
- 需要release 解锁以后才正常
- 不能重复锁定
-
内存错乱实例
import threading i = 0 def sum1(): global i for x in range(1000000): i += x i -= x print('sum1', i) def sum2(): global i for x in range(1000000): i += x i -= x print('sum2', i) if __name__ == '__main__': thr1 = threading.Thread(target=sum1) thr2 = threading.Thread(target=sum2) thr1.start() thr2.start() thr1.join() thr2.join() print('over')
问题:两个线程对同一数据同时进行读写,可能造成数据值的不对,我们必须保证一个线程在修改money时其他的线程一定不能修改,线程锁解决数据混乱问题
-
线程锁Lock使用方法
import threading
创建一个锁
lock = threading.Lock()
lock.acquire() #进行锁定 锁定成功返回True
lock.release() #进行解锁
+ Lock锁的使用:
```python
import threading
#创建一个lock对象
lock = threading.Lock()
#初始化共享资源
abce = 0
def sumOne():
global abce
#锁定共享资源
lock.acquire()
abce = abce + 1
#释放共享资源
lock.release()
def sumTwo():
global abce
#锁定共享资源
lock.acquire()
abce = abce + 2
#释放共享资源
lock.release()
#调用函数
sumOne()
sumTwo()
print(abce)
在上面的程序中,lock是一个锁对象,全局变量abce是一个共享资源,sumOne()和sumTwo()函数扮作两个线程,在sumOne()函数中共享资源abce首先被锁定,然后增加了1,然后abce被释放。sumTwo()函数执行类似操作。 两个函数sumOne()和sumTwo()不能同时访问共享资源abce,一次只能一个访问共享资源。
-
解决资源混乱
import threading Lock = threading.Lock() i = 1 def fun1(): global i if Lock.acquire(): # 判断是否上锁 锁定成功 for x in range(1000000): i += x i -= x Lock.release() print('fun1-----', i) def fun2(): global i if Lock.acquire(): # 判断是否上锁 锁定成功 for x in range(1000000): i += x i -= x Lock.release() print('fun2----', i) t1 = threading.Thread(target=fun1) t2 = threading.Thread(target=fun2) t1.start() t2.start() t1.join() t2.join() print('mian----',i) -
线程锁的简写(不需要手动解锁)
import threading i = 0 lock = threading.Lock() def sum1(): global i with lock: for x in range(1000000): i += x i -= x print('sum1', i) def sum2(): global i with lock: for x in range(1000000): i += x i -= x print('sum2', i) if __name__ == '__main__': thr1 = threading.Thread(target=sum1) thr2 = threading.Thread(target=sum2) thr1.start() thr2.start() thr1.join() thr2.join() print('over')结果一样
7、Timer定时执行
-
概述
Timer是Thread的子类,可以指定时间间隔后在执行某个操作
-
使用
import threading def go(): print("走我了") # t = threading.Timer(秒数,函数名) t = threading.Timer(3,go) t.start() print('我是主线程的代码')
8、线程池ThreadPoolExecutor
-
模块
concurrent.futures
-
导入 Executor[ɪɡˈzekjətər]
from concurrent.futures import ThreadPoolExecutor -
方法
- submit(fun[, args]) 传入放入线程池的函数以及传参
- map(fun[, iterable_args]) 统一管理
区别:
- submit与map参数不同 submit每次都需要提交一个目标函数和对应参数 map只需要提交一次目标函数 目标函数的参数 放在一个可迭代对象(列表、字典...)里就可以
-
使用
from concurrent.futures import ThreadPoolExecutor import time # import threadpool #线程池 统一管理 线程 def go(str): print("hello",str) time.sleep(2) name_list = ["lucky","卢yuan凯","姚青","刘佳俊","何必喆"] pool = ThreadPoolExecutor(5) #控制线程的并发数 -
线程池运行的方式
方式一
# 逐一传参扔进线程池 for i in name_list: pool.submit(go, i) -
简写
all_task = [pool.submit(go, i) for i in name_list] -
方式二
# 统一放入进程池使用 pool.map(go, name_list) # 多个参数 # pool.map(go, name_list1, name_list2...)*map(fn, iterables, timeout=None)
fn: 第一个参数 fn 是需要线程执行的函数;iterables:第二个参数接受一个可迭代对象;
timeout: 第三个参数 timeout 跟 wait() 的 timeout 一样,但由于 map 是返回线程执行的结果,如果 timeout小于线程执行时间会抛异常 TimeoutError。
注意:使用 map 方法,无需提前使用 submit 方法,map 方法与 python 高阶函数 map 的含义相同,都是将序列中的每个元素都执行同一个函数。
-
获取返回值
-
方式一
import random from concurrent.futures import ThreadPoolExecutor, as_completed import time # import threadpool #线程池 统一管理 线程 def go(str): print("hello", str) time.sleep(random.randint(1, 4)) return str name_list = ["lucky","卢yuan凯","姚青","刘佳俊","何必喆"] pool = ThreadPoolExecutor(5) #控制线程的并发数 all_task = [pool.submit(go, i) for i in name_list] # 统一放入进程池使用 for future in as_completed(all_task): print("finish the task") obj_data = future.result() print("obj_data is ", obj_data)as_completed
当子线程中的任务执行完后,使用 result() 获取返回结果
该方法是一个生成器,在没有任务完成的 时候,会一直阻塞,除非设置了 timeout。 当有某个任务完成的时候,会yield这个任务,就能执行for循环下面的语句,然后继续阻塞住,循环到所有任务结束,同时,先完成的任务会先返回给主线程
-
-
方式二
for result in pool.map(go, name_list): print("task:{}".format(result)) -
wait 等待线程执行完毕 在继续向下执行
from concurrent.futures import ThreadPoolExecutor, wait import time # 参数times用来模拟下载的时间 def down_video(times): time.sleep(times) print("down video {}s finished".format(times)) return times executor = ThreadPoolExecutor(max_workers=2) #通过submit函数提交执行的函数到线程池中,submit函数立即返回,不阻塞 task1 = executor.submit(down_video, (3)) task2 = executor.submit(down_video, (1)) # done方法用于判定某个任务是否完成 print("任务1是否已经完成:", task1.done()) time.sleep(4) print(wait([task1, task2])) print('wait') print("任务1是否已经完成:", task1.done()) print("任务1是否已经完成:", task2.done()) #result方法可以获取task的执行结果 print(task1.result()) -
线程池与线程对比
线程池是在程序运行开始,创建好的n个线程,并且这n个线程挂起等待任务的到来。而多线程是在任务到来得时候进行创建,然后执行任务。
线程池中的线程执行完之后不会回收线程,会继续将线程放在等待队列中;多线程程序在每次任务完成之后会回收该线程。
由于线程池中线程是创建好的,所以在效率上相对于多线程会高很多。
线程池也在高并发的情况下有着较好的性能;不容易挂掉。多线程在创建线程数较多的情况下,很容易挂掉。
9、队列模块queue
-
导入队列模块
import queue
-
概述
queue是python标准库中的线程安全的队列(FIFO)实现,提供了一个适用于多线程编程的先进先出的数据结构,即队列,用来在生产者和消费者线程之间的信息传递
-
基本FIFO队列
queue.Queue(maxsize=0)
FIFO即First in First Out,先进先出。Queue提供了一个基本的FIFO容器,使用方法很简单,maxsize是个整数,指明了队列中能存放的数据个数的上限。一旦达到上限,插入会导致阻塞,直到队列中的数据被消费掉。如果maxsize小于或者等于0,队列大小没有限制。
举个栗子:
import queue q = queue.Queue() for i in range(5): q.put(i) while not q.empty(): print q.get() -
一些常用方法
-
task_done()
意味着之前入队的一个任务已经完成。由队列的消费者线程调用。每一个get()调用得到一个任务,接下来的task_done()调用告诉队列该任务已经处理完毕。
如果当前一个join()正在阻塞,它将在队列中的所有任务都处理完时恢复执行(即每一个由put()调用入队的任务都有一个对应的task_done()调用)。
-
join()
阻塞调用线程,直到队列中的所有任务被处理掉。
只要有数据被加入队列,未完成的任务数就会增加。当消费者线程调用task_done()(意味着有消费者取得任务并完成任务),未完成的任务数就会减少。当未完成的任务数降到0,join()解除阻塞。
-
put(item[, block[, timeout]])
将item放入队列中。
- 如果可选的参数block为True且timeout为空对象(默认的情况,阻塞调用,无超时)。
- 如果timeout是个正整数,阻塞调用进程最多timeout秒,如果一直无空空间可用,抛出Full异常(带超时的阻塞调用)。
- 如果block为False,如果有空闲空间可用将数据放入队列,否则立即抛出Full异常
- 其非阻塞版本为
put_nowait等同于put(item, False)
-
get([block[, timeout]])
从队列中移除并返回一个数据。block跟timeout参数同
put方法其非阻塞方法为
get_nowait()相当与get(False) -
empty()
如果队列为空,返回True,反之返回False
-
10、案例
http://www.boxofficecn.com/boxofficecn
我们抓取从1994年到2021年的电影票房.
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
def get_page_source(url):
resp = requests.get(url)
resp.encoding = 'utf-8'
return resp.text
def parse_html(html):
try:
tree = etree.HTML(html)
trs = tree.xpath("//table/tbody/tr")[1:]
result = []
for tr in trs:
year = tr.xpath("./td[2]//text()")
year = year[0] if year else ""
name = tr.xpath("./td[3]//text()")
name = name[0] if name else ""
money = tr.xpath("./td[4]//text()")
money = money[0] if money else ""
d = (year, name, money)
if any(d):
result.append(d)
return result
except Exception as e:
print(e) # 调bug专用
def download_one(url, f):
page_source = get_page_source(url)
data = parse_html(page_source)
for item in data:
f.write(",".join(item))
f.write("\n")
def main():
f = open("movie.csv", mode="w", encoding='utf-8')
lst = [str(i) for i in range(1994, 2022)]
with ThreadPoolExecutor(10) as t:
# 方案一
# for year in lst:
# url = f"http://www.boxofficecn.com/boxoffice{year}"
# # download_one(url, f)
# t.submit(download_one, url, f)
# 方案二
t.map(download_one, (f"http://www.boxofficecn.com/boxoffice{year}" for year in lst), (f for i in range(len(lst))))
if __name__ == '__main__':
main()
二、进程VS线程
-
多任务的实现原理
首先,要实现多任务,通常我们会设计Master-Worker模式,Master负责分配任务,Worker负责执行任务,因此,多任务环境下,通常是一个Master,多个Worker。
如果用多进程实现Master-Worker,主进程就是Master,其他进程就是Worker。
如果用多线程实现Master-Worker,主线程就是Master,其他线程就是Worker。
-
多进程
主进程就是Master,其他进程就是Worker
-
优点
稳定性高:多进程模式最大的优点就是稳定性高,因为一个子进程崩溃了,不会影响主进程和其他子进程。(当然主进程挂了所有进程就全挂了,但是Master进程只负责分配任务,挂掉的概率低)著名的Apache最早就是采用多进程模式。
-
缺点
创建进程的代价大:在Unix/Linux系统下,用fork调用还行,在Windows下创建进程开销巨大
操作系统能同时运行的进程数也是有限的:在内存和CPU的限制下,如果有几千个进程同时运行,操作系统连调度都会成问题
-
-
多线程
主线程就是Master,其他线程就是Worker
-
优点
多线程模式通常比多进程快一点,但是也快不到哪去
在Windows下,多线程的效率比多进程要高
-
缺点
任何一个线程挂掉都可能直接造成整个进程崩溃:所有线程共享进程的内存。在Windows上,如果一个线程执行的代码出了问题,你经常可以看到这样的提示:“该程序执行了非法操作,即将关闭”,其实往往是某个线程出了问题,但是操作系统会强制结束整个进程
-
-
计算密集型 vs IO密集型
-
计算密集型(多进程适合计算密集型任务)
要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数
-
IO密集型 (线程适合IO密集型任务)
涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用
-
-
GIL
多线程存在GIL锁,同一时刻只能有一条线程执行;在多进程中,每一个进程都有独立的GIL,不会发生GIL冲突;但在这个例子中,爬虫属于IO密集型,多进程适用于CPU计算密集型,所以用时较长,速度慢于多线程并发。
一、协程
概念
-
协程
又称微线程(纤程),是一种用户态的轻量级线程
-
子程序
在所有的语言中都是层级调用的,比如A中调用B,B在执行过程中调用C,C执行完返回,B执行完返回,最后是A执行完毕。这是通过栈实现的,一个函数就是一个执行的子程序,子程序的调用总是有一个入口、一次返回,调用的顺序是明确的
-
理解协程
普通理解:线程是系统级别的,它们是由操作系统调度。协程是程序级别,由程序员根据需求自己调度。我们把一个线程中的一个个函数称为子程序,那么一个子程序在执行的过程中可以中断去执行别的子程序,这就是协程。也就是说同一个线程下的一段代码1执行执行着就中断,然后去执行另一段代码2,当再次回来执行代码1时,接着从之前的中断的位置继续向下执行
-
优点
a、最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
b、不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
-
缺点
a、无法利用多核CPU,协程的本质是单个线程,它不能同时将多个CPU的多个核心使用上,失去了标准线程使用多CPU的能力。
b、进行阻塞操作(操作IO)会阻塞整个程序
二、同步与异步
1、同步与异步的概念
-
前言
python由于GIL(全局锁)的存在,不能发挥多核的优势,其性能一直饱受诟病。然而在IO密集型的网络编程里,异步处理比同步处理能提升成百上千倍的效率
IO密集型就是磁盘的读取数据和输出数据非常大的时候就是属于IO密集型
由于IO操作的运行时间远远大于cpu、内存运行时间,所以任务的大部分时间都是在等待IO操作完成,IO的特点是cpu消耗小,所以,IO任务越多,cpu效率越高,当然不是越多越好,有一个极限值。 -
同步
指完成事务的逻辑,先执行第一个事务,如果阻塞了,会一直等待,直到这个事务完成,再执行第二个事务,顺序执行
-
异步
是和同步相对的,异步是指在处理调用这个事务的之后,不会等待这个事务的处理结果,直接处理第二个事务去了,通过状态、通知、回调来通知调用者处理结果
2、同步与异步代码
-
同步
import time def run(index): print("lucky is a good man", index) time.sleep(2) print("lucky is a nice man", index) for i in range(1, 5): run(i) -
异步
说明:后面的课程中会使用到asyncio模块,现在的目的是使同学们理解异步思想
import time import asyncioasync def run(i):
print("lucky is a good man", i)
# 模拟一个耗时IO
await asyncio.sleep(2)
print("lucky is a nice man", i)if name == "main":
loop = asyncio.get_event_loop()
tasks = []
t1 = time.time()for url in range(1, 5): coroutine = run(url) task = asyncio.ensure_future(coroutine) tasks.append(task) loop.run_until_complete(asyncio.wait(tasks)) t2 = time.time() print("总耗时:%.2f" % (t2 - t1))
三、asyncio模块
1、概述
-
asyncio模块
是python3.4版本引入的标准库,直接内置了对异步IO的操作
-
编程模式
是一个消息循环,我们从asyncio模块中直接获取一个EventLoop的引用,然后把需要执行的协程扔到EventLoop中执行,就实现了异步IO
-
说明
到目前为止实现协程的不仅仅只有asyncio,tornado和gevent都实现了类似功能
-
关键字的说明
关键字 说明 event_loop 消息循环,程序开启一个无限循环,把一些函数注册到事件循环上,当满足事件发生的时候,调用相应的协程函数 coroutine 协程对象,指一个使用async关键字定义的函数,它的调用不会立即执行函数,而是会返回一个协程对象。协程对象需要注册到事件循环,由事件循环调用 task 任务,一个协程对象就是一个原生可以挂起的函数,任务则是对协程进一步封装,其中包含了任务的各种状态 async/await python3.5用于定义协程的关键字,async定义一个协程,await用于挂起阻塞的异步调用接口
2、asyncio基本使用
-
定义一个协程
import asyncio import time # 通过async关键字定义了一个协程,协程是不能直接运行的,需要将协程放到消息循环中 async def run(x): print("waiting:%d"%x) await asyncio.sleep(x) print("结束run") #得到一个协程对象 coroutine = run(2) asyncio.run(coroutine)等同于
import asyncio import time # 通过async关键字定义了一个协程,协程是不能直接运行的,需要将协程放到消息循环中 async def run(x): print("waiting:%d"%x) await asyncio.sleep(x) print("结束run") #得到一个协程对象 coroutine = run(2) # 创建一个消息循环 loop = asyncio.get_event_loop() #将协程对象加入到消息循环 loop.run_until_complete(coroutine) -
创建一个任务
import asyncio import time async def run(x): print("waiting:%d"%x) await asyncio.sleep(x) print("结束run") coroutine = run(2) #创建任务 task = asyncio.ensure_future(coroutine) loop = asyncio.get_event_loop() # 将任务加入到消息循环 loop.run_until_complete(task) -
阻塞和await
async可以定义协程,使用await可以针对耗时操作进行挂起,就与生成器的yield一样,函数交出控制权。协程遇到await,消息循环会挂起该协程,执行别的协程,直到其他协程也会挂起或者执行完毕,在进行下一次执行
-
获取返回值
import time import asyncio async def run(url): print("开始向'%s'要数据……"%(url)) # 向百度要数据,网络IO await asyncio.sleep(5) data = "'%s'的数据"%(url) print("给你数据") return data # 定义一个回调函数 def call_back(future): print("call_back:", future.result()) coroutine = run("百度") # 创建一个任务对象 task = asyncio.ensure_future(coroutine) # 给任务添加回调,在任务结束后调用回调函数 task.add_done_callback(call_back) loop = asyncio.get_event_loop() loop.run_until_complete(task)
3、多任务
-
同步
同时请求"百度", "阿里", "腾讯", "新浪"四个网站,假设响应时长均为2秒
import time def run(url): print("开始向'%s'要数据……"%(url)) # 向百度要数据,网络IO time.sleep(2) data = "'%s'的数据"%(url) return data if __name__ == "__main__": t1 = time.time() for url in ["百度", "阿里", "腾讯", "新浪"]: print(run(url)) t2 = time.time() print("总耗时:%.2f"%(t2-t1)) -
异步
同时请求"百度", "阿里", "腾讯", "新浪"四个网站,假设响应时长均为2秒
使用ensure_future创建多任务
import time import asyncio async def run(url): print("开始向'%s'要数据……"%(url)) await asyncio.sleep(2) data = "'%s'的数据"%(url) return data def call_back(future): print("call_back:", future.result()) if __name__ == "__main__": loop = asyncio.get_event_loop() tasks = [] t1 = time.time() for url in ["百度", "阿里", "腾讯", "新浪"]: coroutine = run(url) task = asyncio.ensure_future(coroutine) task.add_done_callback(call_back) tasks.append(task) # 同时添加4个异步任务 # asyncio.wait(tasks) 将任务的列表又变成 <coroutine object wait at 0x7f80f43408c0> loop.run_until_complete(asyncio.wait(tasks)) t2 = time.time() print("总耗时:%.2f" % (t2 - t1))-
封装成异步函数
import time import asyncioasync def run(url):
print("开始向'%s'要数据……" % (url))
await asyncio.sleep(2)
data = "'%s'的数据" % (url)
return datadef call_back(future):
print("call_back:", future.result())async def main():
tasks = []
t1 = time.time()for url in ["百度", "阿里", "腾讯", "新浪"]: coroutine = run(url) task = asyncio.ensure_future(coroutine) task.add_done_callback(call_back) tasks.append(task) # 同时添加4个异步任务 await asyncio.wait(tasks) t2 = time.time() print("总耗时:%.2f" % (t2 - t1))if name == "main":
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
使用loop.create_task创建多任务
import time import asyncio async def run(url): print("开始向'%s'要数据……" % (url)) await asyncio.sleep(2) data = "'%s'的数据" % (url) return data def call_back(future): print("call_back:", future.result()) if __name__ == "__main__": loop = asyncio.get_event_loop() tasks = [] t1 = time.time() for url in ["百度", "阿里", "腾讯", "新浪"]: coroutine = run(url) # task = asyncio.ensure_future(coroutine) task = loop.create_task(coroutine) task.add_done_callback(call_back) tasks.append(task) # 同时添加4个异步任务 loop.run_until_complete(asyncio.wait(tasks)) t2 = time.time() print("总耗时:%.2f" % (t2 - t1))-
封装成异步函数
import time import asyncioasync def run(url):
print("开始向'%s'要数据……" % (url))
await asyncio.sleep(2)
data = "'%s'的数据" % (url)
return datadef call_back(future):
print("call_back:", future.result())async def main():
tasks = []
t1 = time.time()
for url in ["百度", "阿里", "腾讯", "新浪"]:
coroutine = run(url)
task = loop.create_task(coroutine)
task.add_done_callback(call_back)
tasks.append(task)
# 同时添加4个异步任务
await asyncio.wait(tasks)
t2 = time.time()
print("总耗时:%.2f" % (t2 - t1))if name == "main":
# asyncio.run(main())
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
使用asyncio.create_task创建多任务
import time import asyncio async def run(url): print("开始向'%s'要数据……" % (url)) await asyncio.sleep(2) data = "'%s'的数据" % (url) return data def call_back(future): print("call_back:", future.result()) async def main(): tasks = [] t1 = time.time() for url in ["百度", "阿里", "腾讯", "新浪"]: coroutine = run(url) task = asyncio.create_task(coroutine) task.add_done_callback(call_back) tasks.append(task) # 同时添加4个异步任务 await asyncio.wait(tasks) t2 = time.time() print("总耗时:%.2f" % (t2 - t1)) if __name__ == "__main__": # asyncio.run(main()) loop = asyncio.get_event_loop() loop.run_until_complete(main())
-
4、Task 概念及用法
-
Task,是 python 中与事件循环进行交互的一种主要方式。
创建 Task,意思就是把协程封装成 Task 实例,并追踪协程的 运行 / 完成状态,用于未来获取协程的结果。
-
Task 核心作用: 在事件循环中添加多个并发任务;
具体来说,是通过 asyncio.create_task() 创建 Task,让协程对象加入时事件循环中,等待被调度执行。
注意:Python 3.7 以后的版本支持 asyncio.create_task() ,在此之前的写法为 loop.create_task() ,开发过程中需要注意代码写 法对不同版本 python 的兼容性。
-
需要指出的是,协程封装为 Task 后不会立马启动,当某个代码 await 这个 Task 的时候才会被执行。
当多个 Task 被加入一个 task_list 的时候,添加 Task 的过程中 Task 不会执行,必须要用
await asyncio.wait()或await asyncio.gather()将 Task 对象加入事件循环中异步执行。 -
一般在开发中,常用的写法是这样的:
-- 先创建 task_list 空列表;
-- 然后用 asyncio.create_task() 创建 Task;-- 再把 Task 对象加入 task_list ;
-- 最后使用 await asyncio.wait 或 await asyncio.gather 将 Task 对象加入事件循环中异步执行。
注意: 创建 Task 对象时,除了可以使用 asyncio.create_task() 之外,还可以用最低层级的 loop.create_task() 或 asyncio.ensure_future() ,他们都可以用来创建 Task 对象,其中关于 ensure_future 相关内容本文接下来会一起讲。
-
Task 简单用法
import asyncio
async def func():
print(1)
await asyncio.sleep(2)
print(2)
return "test"
async def main():
print("main start")
# python 3.7及以上版本的写法
task1 = asyncio.create_task(func())
task2 = asyncio.create_task(func())
# python3.7以前的写法
# task1 = asyncio.ensure_future(func())
# task2 = asyncio.ensure_future(func())
print("main end")
ret1 = await task1
ret2 = await task2
print(ret1, ret2)
# python3.7以后的写法
asyncio.run(main())
# python3.7以前的写法
# loop = asyncio.get_event_loop()
# loop.run_until_complete(main())
"""
在创建task的时候,就将创建好的task添加到了时间循环当中,所以说必须得有时间循环,才可以创建task,否则会报错
"""
-
task用法实例
import asyncio import arrow def current_time(): ''' 获取当前时间 :return: ''' cur_time = arrow.now().to('Asia/Shanghai').format('YYYY-MM-DD HH:mm:ss') return cur_timeasync def func(sleep_time):
func_name_suffix = sleep_time # 使用 sleep_time (函数 I/O 等待时长)作为函数名后缀,以区分任务对象
print(f"[{current_time()}] 执行异步函数 {func.name}-{func_name_suffix}")
await asyncio.sleep(sleep_time)
print(f"[{current_time()}]函数{func.name}-{func_name_suffix} 执行完毕")
return f"【[{current_time()}] 得到函数 {func.name}-{func_name_suffix} 执行结果】"async def run():
task_list = []
for i in range(5):
task = asyncio.create_task(func(i))
task_list.append(task)
done, pending = await asyncio.wait(task_list)
for done_task in done:
print((f"[{current_time()}]得到执行结果 {done_task.result()}"))
def main():
loop = asyncio.get_event_loop()
loop.run_until_complete(run())if name == 'main':
main() -
代码执行结果如下:
/usr/local/bin/python3.7 /Users/xialigang/PycharmProjects/爬虫/123.py [2022-07-01 16:44:57] 执行异步函数 func-0 [2022-07-01 16:44:57] 执行异步函数 func-1 [2022-07-01 16:44:57] 执行异步函数 func-2 [2022-07-01 16:44:57] 执行异步函数 func-3 [2022-07-01 16:44:57] 执行异步函数 func-4 [2022-07-01 16:44:57]函数func-0 执行完毕 [2022-07-01 16:44:58]函数func-1 执行完毕 [2022-07-01 16:44:59]函数func-2 执行完毕 [2022-07-01 16:45:00]函数func-3 执行完毕 [2022-07-01 16:45:01]函数func-4 执行完毕 [2022-07-01 16:45:01]得到执行结果 【[2022-07-01 16:44:59] 得到函数 func-2 执行结果】 [2022-07-01 16:45:01]得到执行结果 【[2022-07-01 16:44:57] 得到函数 func-0 执行结果】 [2022-07-01 16:45:01]得到执行结果 【[2022-07-01 16:45:00] 得到函数 func-3 执行结果】 [2022-07-01 16:45:01]得到执行结果 【[2022-07-01 16:44:58] 得到函数 func-1 执行结果】 [2022-07-01 16:45:01]得到执行结果 【[2022-07-01 16:45:01] 得到函数 func-4 执行结果】 Process finished with exit code 0
5、协程嵌套与返回值
使用async可以定义协程,协程用于耗时的io操作,我们也可以封装更多的io操作过程,这样就实现了嵌套的协程,即一个协程中await了另外一个协程,如此连接起来

import time
import asyncio
async def run(url):
print("开始向'%s'要数据……"%(url))
await asyncio.sleep(2)
data = "'%s'的数据"%(url)
return data
def call_back(future):
print("call_back:", future.result())
async def main():
tasks = []
for url in ["百度", "阿里", "腾讯", "新浪"]:
coroutine = run(url)
task = asyncio.ensure_future(coroutine)
# task.add_done_callback(call_back)
tasks.append(task)
# #1、可以没有回调函数
# dones, pendings = await asyncio.wait(tasks)
# #处理数据,类似回调,建议使用回调
# for t in dones:
# print("数据:%s"%(t.result()))
# #2、可以没有回调函数
# results = await asyncio.gather(*tasks)
# # 处理数据,类似回调,建议使用回调
# for result in results:
# print("数据:%s"%(result))
# 3、有无回调函数均可以
# return await asyncio.wait(tasks)
# 4、有无回调函数均可以
# return await asyncio.gather(*tasks)
if __name__ == "__main__":
t1 = time.time()
loop = asyncio.get_event_loop()
#1、
# loop.run_until_complete(main())
# asyncio.run(main()) # 等同于上面两行代码
#2、
# loop.run_until_complete(main())
# # 3、
# dones, pendings = loop.run_until_complete(main())
# #处理数据,类似回调,建议使用回调
# for t in dones:
# print("数据:%s"%(t.result()))
# 4、
# results = loop.run_until_complete(main())
# for result in results:
# print("数据:%s"%(result))
t2 = time.time()
print("总耗时:%.2f" % (t2 - t1))
-
asyncio.wait和asyncio.gather的异同
- 异同点综述
相同:从功能上看, asyncio.wait 和 asyncio.gather 实现的效果是相同的,都是把所有 Task 任务结果收集起来。
不同: asyncio.wait 会返回两个值: done 和 pending , done 为已完成的协程 Task , pending 为超时未完成的协程 Task ,需通过 future.result 调用 Task 的 result ;而 asyncio.gather 返回的是所有已完成 Task 的 result ,不需要再进行调用或其他操作,就可以得到全部结果。
- asyncio.wait 用法:
最常见的写法是:
await asyncio.wait(task_list) 。import asyncio import arrow def current_time(): ''' 获取当前时间 :return: ''' cur_time = arrow.now().to('Asia/Shanghai').format('YYYY-MM-DD HH:mm:ss') return cur_time async def func(sleep_time): func_name_suffix = sleep_time # 使用 sleep_time (函数 I/O 等待时长)作为函数名后缀,以区分任务对象 print(f"[{current_time()}] 执行异步函数 {func.__name__}-{func_name_suffix}") await asyncio.sleep(sleep_time) print(f"[{current_time()}]函数{func.__name__}-{func_name_suffix} 执行完毕") return f"【[{current_time()}] 得到函数 {func.__name__}-{func_name_suffix} 执行结果】" async def run(): task_list = [] for i in range(5): task = asyncio.create_task(func(i)) task_list.append(task) done, pending = await asyncio.wait(task_list) for done_task in done: print((f"[{current_time()}]得到执行结果 {done_task.result()}")) def main(): loop = asyncio.get_event_loop() loop.run_until_complete(run()) if __name__ == '__main__': main()代码执行结果如下:
/usr/local/bin/python3.7 /Users/xialigang/PycharmProjects/爬虫/123.py [2022-07-04 15:31:47] 执行异步函数 func-0 [2022-07-04 15:31:47] 执行异步函数 func-1 [2022-07-04 15:31:47] 执行异步函数 func-2 [2022-07-04 15:31:47] 执行异步函数 func-3 [2022-07-04 15:31:47] 执行异步函数 func-4 [2022-07-04 15:31:47]函数func-0 执行完毕 [2022-07-04 15:31:48]函数func-1 执行完毕 [2022-07-04 15:31:49]函数func-2 执行完毕 [2022-07-04 15:31:50]函数func-3 执行完毕 [2022-07-04 15:31:51]函数func-4 执行完毕 [2022-07-04 15:31:51]得到执行结果 【[2022-07-04 15:31:49] 得到函数 func-2 执行结果】 [2022-07-04 15:31:51]得到执行结果 【[2022-07-04 15:31:47] 得到函数 func-0 执行结果】 [2022-07-04 15:31:51]得到执行结果 【[2022-07-04 15:31:50] 得到函数 func-3 执行结果】 [2022-07-04 15:31:51]得到执行结果 【[2022-07-04 15:31:48] 得到函数 func-1 执行结果】 [2022-07-04 15:31:51]得到执行结果 【[2022-07-04 15:31:51] 得到函数 func-4 执行结果】 Process finished with exit code 0- asyncio.gather 用法:
最常见的用法是:
await asyncio.gather(*task_list),注意这里task_list前面有一个*。import asyncio import arrow def current_time(): ''' 获取当前时间 :return: ''' cur_time = arrow.now().to('Asia/Shanghai').format('YYYY-MM-DD HH:mm:ss') return cur_time async def func(sleep_time): func_name_suffix = sleep_time # 使用 sleep_time (函数 I/O 等待时长)作为函数名后缀,以区分任务对象 print(f"[{current_time()}] 执行异步函数 {func.__name__}-{func_name_suffix}") await asyncio.sleep(sleep_time) print(f"[{current_time()}]函数{func.__name__}-{func_name_suffix} 执行完毕") return f"【[{current_time()}] 得到函数 {func.__name__}-{func_name_suffix} 执行结果】" async def run(): task_list = [] for i in range(5): task = asyncio.create_task(func(i)) task_list.append(task) results = await asyncio.gather(*task_list) for result in results: print((f"[{current_time()}]得到执行结果 {result}")) def main(): loop = asyncio.get_event_loop() loop.run_until_complete(run()) if __name__ == '__main__': main()代码执行结果如下:
/usr/local/bin/python3.7 /Users/xialigang/PycharmProjects/爬虫/123.py [2022-07-04 15:33:24] 执行异步函数 func-0 [2022-07-04 15:33:24] 执行异步函数 func-1 [2022-07-04 15:33:24] 执行异步函数 func-2 [2022-07-04 15:33:24] 执行异步函数 func-3 [2022-07-04 15:33:24] 执行异步函数 func-4 [2022-07-04 15:33:24]函数func-0 执行完毕 [2022-07-04 15:33:25]函数func-1 执行完毕 [2022-07-04 15:33:26]函数func-2 执行完毕 [2022-07-04 15:33:27]函数func-3 执行完毕 [2022-07-04 15:33:28]函数func-4 执行完毕 [2022-07-04 15:33:28]得到执行结果 【[2022-07-04 15:33:24] 得到函数 func-0 执行结果】 [2022-07-04 15:33:28]得到执行结果 【[2022-07-04 15:33:25] 得到函数 func-1 执行结果】 [2022-07-04 15:33:28]得到执行结果 【[2022-07-04 15:33:26] 得到函数 func-2 执行结果】 [2022-07-04 15:33:28]得到执行结果 【[2022-07-04 15:33:27] 得到函数 func-3 执行结果】 [2022-07-04 15:33:28]得到执行结果 【[2022-07-04 15:33:28] 得到函数 func-4 执行结果】 Process finished with exit code 0
四、aiohttp与aiofiles
1、安装与使用
pip install aiohttp
2、简单实例使用
aiohttp的自我介绍中就包含了客户端和服务器端,所以我们分别来看下客户端和服务器端的简单实例代码。
客户端:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, "http://httpbin.org/headers")
print(html)
asyncio.run(main())
"""输出结果:
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "Python/3.7 aiohttp/3.6.2"
}
}
"""
这个代码是不是很简单,一个函数用来发起请求,另外一个函数用来下载网页。
3、入门
简单示范
首先是学习客户端,也就是用来发送http请求的用法。首先看一段代码,会在代码中讲述需要注意的地方:
import aiohttp
import asyncio
async def main():
async with aiohttp.ClientSession() as session:
async with session.get('http://httpbin.org/get') as resp:
print(resp.status)
print(await resp.text())
asyncio.run(main())
代码解释:
在网络请求中,一个请求就是一个会话,然后aiohttp使用的是ClientSession来管理会话,所以第一个重点,看一下ClientSession:
class ClientSession:
"""First-class interface for making HTTP requests."""
在源码中,这个类的注释是使用HTTP请求接口的第一个类。然后上面的代码就是实例化一个ClientSession类然后命名为session,然后用session去发送请求。这里有一个坑,那就是ClientSession.get()协程的必需参数只能是str类和yarl.URL的实例。
当然这只是get请求,其他的请求都是支持的:
session.post('http://httpbin.org/post', data='data')
session.get('http://httpbin.org/get')
4、在URL中传递参数
有时候在发起网络请求的时候需要附加一些参数到url中,这一点也是支持的。
import aiohttp
import asyncio
async def main():
async with aiohttp.ClientSession() as session:
params = {'key1': 'value1', 'key2': 'value2'}
async with session.get('http://httpbin.org/get',
params=params) as resp:
print(resp.url)
asyncio.run(main())
我们可以通过params参数来指定要传递的参数,
同时如果需要指定一个键对应多个值的参数,那么MultiDict就在这个时候起作用了。你可以传递两个元祖列表来作为参数:
import aiohttp
import asyncio
async def main():
async with aiohttp.ClientSession() as session:
params = [('key', 'value1'), ('key', 'value2')]
async with session.get('http://httpbin.org/get',
params=params) as r:
expect = 'http://httpbin.org/get?key=value2&key=value1'
# assert str(r.url) == expect
print(r.url)
asyncio.run(main())
5、读取响应内容
我们可以读取到服务器的响应状态和响应内容,这也是使用请求的一个很重要的部分。通过status来获取响应状态码,text()来获取到响应内容,当然也可以之计指明编码格式为你想要的编码格式:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get('http://httpbin.org/get') as resp:
print(resp.status)
print(await resp.text(encoding=utf-8))
"""输出结果:
200
<!doctype html>
<html lang="zh-CN">
<head>
......
"""
6、非文本内容格式
对于网络请求,有时候是去访问一张图片,这种返回值是二进制的也是可以读取到的:
await resp.read()
将text()方法换成read()方法就好。
7、请求的自定义
ClientResponse(客户端响应)对象含有request_info(请求信息),主要是url和headers信息。 raise_for_status结构体上的信息会被复制给ClientResponseError实例。
(1) 自定义Headers
有时候做请求的时候需要自定义headers,主要是为了让服务器认为我们是一个浏览器。然后就需要我们自己来定义一个headers:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/78.0.3904.108 Safari/537.36"
}
await session.post(url, headers=headers)
(2) 如果出现ssl验证失败的处理
import aiohttp
import asyncio
from aiohttp import TCPConnector
async def main():
async with aiohttp.ClientSession(connector=TCPConnector(ssl=False)) as session:
pass
asyncio.run(main())
(3) 自定义cookie
发送你自己的cookies给服务器,你可以为ClientSession对象指定cookies参数:
url = 'http://httpbin.org/cookies'
cookies = {'cookies_are': 'working'}
async with ClientSession(cookies=cookies) as session:
async with session.get(url) as resp:
assert await resp.json() == {
"cookies": {"cookies_are": "working"}}
(4) 使用代理
有时候在写爬虫的时候需要使用到代理,所以aiohttp也是支持使用代理的,我们可以在发起请求的时候使用代理,只需要使用关键字proxy来指明就好,但是有一个很难受的地方就是它只支持http代理,不支持HTTPS代理。使用起来大概是这样:
proxy = "http://127.0.0.1:10809
async with aiohttp.ClientSession(headers=headers) as session:
async with session.get(url=login_url, proxy=proxy) as response:
resu = await response.text()
使用起来大概是这样,然后代理记得改成自己的。
8、aiofiles文件读写
8.1 概述
平常使用的file操作模式为同步,并且为线程阻塞。当程序I/O并发次数高的时候,CPU被阻塞,形成闲置。
线程开启文件读取异步模式
用线程(Thread)方式来解决。硬盘缓存可以被多个线程访问,因此通过不同线程访问文件可以部分解决。但此方案涉及线程开启关闭的开销,而且不同线程间数据交互比较麻烦。
from threading import Thread
for file in list_file:
tr = Thread(target=file.write, args=(data,))
tr.start()
使用已编写好的第三方插件-aiofiles,支持异步模式
使用aio插件来开启文件的非阻塞异步模式。
8.2 安装方法
pip install aiofiles
这个插件的使用和python原生open 一致,而且可以支持异步迭代
8.3 实例
打开文件
import asyncio
import aiofiles
async def main():
async with aiofiles.open('first.m3u8', mode='r') as f:
contents = await f.read()
print(contents)
if __name__ == '__main__':
asyncio.run(main())
迭代
import asyncio
import aiofiles
async def main():
async with aiofiles.open('filename') as f:
async for line in f:
print(line)
if __name__ == '__main__':
asyncio.run(main())
9、并发控制
semaphore,控制并发
semaphore = asyncio.Semaphore(10)
实例
#!/usr/bin/python
import asyncio
import os
import aiofiles
import aiohttp
import requests
from bs4 import BeautifulSoup
def get_page_source(web):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36'
}
response = requests.get(web, headers=headers)
response.encoding = 'utf-8'
return response.text
def parse_page_source(html):
book_list = []
soup = BeautifulSoup(html, 'html.parser')
a_list = soup.find_all('div', attrs={'class': 'mulu-list quanji'})
for a in a_list:
a_list = a.find_all('a')
for href in a_list:
chapter_url = href['href']
book_list.append(chapter_url)
return book_list
def get_book_name(book_page):
book_number = book_page.split('/')[-1].split('.')[0]
book_chapter_name = book_page.split('/')[-2]
return book_number, book_chapter_name
async def aio_download_one(chapter_url, signal):
number, c_name = get_book_name(chapter_url)
for c in range(10):
try:
async with signal:
async with aiohttp.ClientSession() as session:
async with session.get(chapter_url) as resp:
page_source = await resp.text()
soup = BeautifulSoup(page_source, 'html.parser')
chapter_name = soup.find('h1').text
p_content = soup.find('div', attrs={'class': 'neirong'}).find_all('p')
content = [p.text + '\n' for p in p_content]
chapter_content = '\n'.join(content)
if not os.path.exists(f'{book_name}/{c_name}'):
os.makedirs(f'{book_name}/{c_name}')
async with aiofiles.open(f'{book_name}/{c_name}/{number}_{chapter_name}.txt', mode="w",
encoding='utf-8') as f:
await f.write(chapter_content)
print(chapter_url, "下载完毕!")
return ""
except Exception as e:
print(e)
print(chapter_url, "下载失败!, 重新下载. ")
return chapter_url
async def aio_download(url_list):
tasks = []
semaphore = asyncio.Semaphore(10)
for h in url_list:
tasks.append(asyncio.create_task(aio_download_one(h, semaphore)))
await asyncio.wait(tasks)
if __name__ == '__main__':
url = 'https://www.51shucheng.net/daomu/guichuideng'
book_name = '鬼吹灯'
if not os.path.exists(book_name):
os.makedirs(book_name)
source = get_page_source(url)
href_list = parse_page_source(source)
loop = asyncio.get_event_loop()
loop.run_until_complete(aio_download(href_list))
loop.close()
抓取m3u8视频
1、思路分析
视频url:https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-1.html
- 打开网址分析当前视频是由多个片段组成还是单独一个视频 如果是一个单独视频,则找到网址,直接下载即可,如果为多个片段的视频,则需要找到片段的文件进行处理,本案例以m3u8为例
- 找到m3u8文件后进行下载,下载后打开文件分析是否需要秘钥,需要秘钥则根据秘钥地址进行秘钥下载,然后下载所有ts文件
- 合并所有视频
2、实现
分析index.m3u8
-
通过网络查找发现有俩个m3u8文件
url分别为
https://new.qqaku.com/20211117/iHVkqQMI/index.m3u8
https://new.qqaku.com/20211117/iHVkqQMI/2523kb/hls/index.m3u8
通过分析 第一个index.m3u8请求返回的内容中包含了第二个m3u8请求的url地址
也就是说通过第一个index.m3u8url请求返回包含第二个index.m3u8文件地址,通过拼接请求第二个index.m3u8后 返回了包含当前所有ts文件的地址内容
现在分析出了第二个真正的index.m3u8的地址,但是第一个地址从哪里来的呢,别慌,接下来我们来查找一下第一个url是从哪里来的


-
查找第一个index.m3u8的url地址
打开source
发现url存在页面源代码中的js里 知道了位置,在代码中通过正则匹配就可以获取到了
现在我们缕一下思路,通过页面源代码可以找到第一个index.m3u8的url,通过请求返回包含第二个index.m3u8文件的url内容,进行拼接,请求第二个m3u8的url,以此返回所有的ts内容

3、代码实现
3.1 获取最后一个m3u8的url地址
import re
from urllib.parse import urljoin
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
session = requests.Session()
session.get('https://www.9meiju.cc/', headers=headers)
url = 'https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-2.html'
response = session.get(url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
# print(data)
'''
<script>
var zanpiancms_player = {"player":"\/public\/","url":"https:\/\/new.qqaku.com\/20211124\/nLwncbZW\/index.m3u8","next":"https:\/\/www.9meiju.cc\/mohuankehuan\/shandianxiadibaji\/1-3.html","name":"wjm3u8","apiurl":null,"adtime":"0","adurl":"","copyright":0,"danmu":{"status":0}};
</script>
'''
# 正则抓取上面的源代码中的m3u8的url
m3u8_uri = re.search('"url":"(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 写入文件 分析当前的页面源代码
with open('99.html', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
f.write(response.content.decode('UTF-8'))
# 请求可以获取index.m3u8文件
response = session.get(m3u8_uri, headers=headers)
with open('m3u8_uri.text', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
f.write(response.content.decode('UTF-8'))
response.encoding = 'UTF-8'
data = response.text
# 拆分返回的内容获取真整的index.m3u8文件的url
url = data.split('/', 3)[-1]
print(data)
print('m3u8_uri', m3u8_uri)
print('url', url)
print(urljoin(m3u8_uri, url))
3.2 多线程下载ts文件与视频合并
import time
import requests
import os
from concurrent.futures import ThreadPoolExecutor, wait
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36"
}
def down_video(url, i):
'''
下载ts文件
:param url:
:param i:
:return:
'''
# print(url)
# 下载ts文件
resp = requests.get(url, headers=headers)
with open(os.path.join(path, str(i)+'.ts'), mode="wb") as f3:
f3.write(resp.content)
print('{} 下载完成!'.format(url))
def download_all_videos(url, path):
'''
下载m3u8文件以及多线程下载ts文件
:param url:
:param path:
:return:
'''
# 请求m3u8文件进行下载
resp = requests.get(url, headers=headers)
with open("first.m3u8", mode="w", encoding="utf-8") as f:
f.write(resp.text)
if not os.path.exists(path):
os.mkdir(path)
# 开启线程 准备下载
pool = ThreadPoolExecutor(max_workers=50)
# 1. 读取文件
tasks = []
i = 0
with open("first.m3u8", mode="r", encoding="utf-8") as f:
for line in f:
# 如果不是url 则走下次循环
if line.startswith("#"):
continue
print(line, i)
# 开启线程
tasks.append(pool.submit(down_video, line.strip(), i))
i += 1
print(i)
# 统一等待
wait(tasks)
# 处理m3u8文件中的url问题
def do_m3u8_url(path, m3u8_filename="index.m3u8"):
# 这里还没处理key的问题
if not os.path.exists(path):
os.mkdir(path)
# else:
# shutil.rmtree(path)
# os.mkdir(path)
with open(m3u8_filename, mode="r", encoding="utf-8") as f:
data = f.readlines()
fw = open(os.path.join(path, m3u8_filename), 'w', encoding="utf-8")
abs_path = os.getcwd()
i = 0
for line in data:
# 如果不是url 则走下次循环
if line.startswith("#"):
# 判断处理是存在需要秘钥
fw.write(line)
else:
fw.write(f'{abs_path}/{path}/{i}.ts\n')
i += 1
def merge(filePath, filename='output'):
'''
进行ts文件合并 解决视频音频不同步的问题 建议使用这种
:param filePath:
:return:
'''
os.chdir(path)
cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4'
os.system(cmd)
if __name__ == '__main__':
# 抓取99美剧闪电侠
# ts文件存储目录
path = 'ts'
url = 'https://new.qqaku.com/20211124/nLwncbZW/1100kb/hls/index.m3u8'
# 下载m3u8文件以及ts文件
download_all_videos(url, path)
do_m3u8_url(path)
# 文件合并
merge(path, 'ts2')
print('over')
注意:当前视频合并所用的工具为ffmpeg 如需安装 查看我的另外一篇博客ffmpeg的使用
3.3 合并获取上面俩个代码段的代码
import re
from urllib.parse import urljoin
import requests
import os # 执行cmd/控制台上的命令
from concurrent.futures import ThreadPoolExecutor, wait
from retrying import retry
def get_m3u8_url(url):
'''
获取页面中m3u8的url
:param url: 电影页面的url
:return:
'''
session = requests.Session()
# 访问首页获取cookie
session.get('https://www.9meiju.cc/', headers=headers)
# url = 'https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-2.html'
response = session.get(url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
# print(data)
m3u8_uri = re.search('"url":"(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 写入文件 分析当前的页面源代码
# with open('99.html', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
# f.write(response.content.decode('UTF-8'))
# 请求可以获取index.m3u8文件
response = session.get(m3u8_uri, headers=headers)
# with open('m3u8_uri.text', 'w', encoding='UTF-8') as f:
# 写入response.content bytes二进制类型
# f.write(response.content.decode('UTF-8'))
response.encoding = 'UTF-8'
data = response.text
# 拆分返回的内容获取真整的index.m3u8文件的url
# 注意 一定要strip
url = data.split('/', 3)[-1].strip()
print(data)
print('m3u8_uri', m3u8_uri)
url = urljoin(m3u8_uri, url)
print('url', url)
return url
@retry(stop_max_attempt_number=3)
def down_video(url, i):
'''
下载ts文件
:param url:
:param i:
:return:
'''
# print(url)
# 下载ts文件
# try:
resp = requests.get(url, headers=headers)
with open(os.path.join(path, str(i)+'.ts'), mode="wb") as f3:
f3.write(resp.content)
assert resp.status_code == 200
def download_all_videos(url, path):
'''
下载m3u8文件以及多线程下载ts文件
:param url:
:param path:
:return:
'''
# 请求m3u8文件进行下载
resp = requests.get(url, headers=headers)
with open("index.m3u8", mode="w", encoding="utf-8") as f:
f.write(resp.content.decode('UTF-8'))
if not os.path.exists(path):
os.mkdir(path)
# 开启线程 准备下载
pool = ThreadPoolExecutor(max_workers=50)
# 1. 读取文件
tasks = []
i = 0
with open("index.m3u8", mode="r", encoding="utf-8") as f:
for line in f:
# 如果不是url 则走下次循环
if line.startswith("#"):
continue
print(line, i)
# 开启线程
tasks.append(pool.submit(down_video, line.strip(), i))
i += 1
print(i)
# 统一等待
wait(tasks)
# 如果阻塞可以给一个超时参数
# wait(tasks, timeout=1800)
def do_m3u8_url(path, m3u8_filename="index.m3u8"):
# 这里还没处理key的问题
if not os.path.exists(path):
os.mkdir(path)
# else:
# shutil.rmtree(path)
# os.mkdir(path)
with open(m3u8_filename, mode="r", encoding="utf-8") as f:
data = f.readlines()
fw = open(os.path.join(path, m3u8_filename), 'w', encoding="utf-8")
abs_path = os.getcwd()
i = 0
for line in data:
# 如果不是url 则走下次循环
if line.startswith("#"):
fw.write(line)
else:
fw.write(f'{abs_path}/{path}/{i}.ts\n')
i += 1
def merge(path, filename='output'):
'''
进行ts文件合并 解决视频音频不同步的问题 建议使用这种
:param filePath:
:return:
'''
os.chdir(path)
cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4'
os.system(cmd)
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 电影的url 返回index.m3u8的url地址
url = get_m3u8_url('https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-2.html')
# ts文件存储目录
path = 'ts'
# 下载m3u8文件以及ts文件
download_all_videos(url, path)
do_m3u8_url(path)
# 文件合并
merge(path, '第二集')
print('over')
4、注意事项
4.1 说明
在获取index.m3u8文件的内容时,有的文件内容会显示...jpg/png的情况,并没显示...ts,那么遇到这种情况需要单独处理 内容如下:

这种情况使用上面的代码就无法进行正常合并,合并后的视频无法播放
但使用ffprobe分析,发现识别为png,进而导致无法正常拼接

在这种情况下,只需要将其中PNG文件头部分全部使用FF填充,即可处理该问题
填充后的效果如图

4.2 使用代码进行处理
# 解析伪装成png的ts
def resolve_ts(src_path, dst_path):
'''
如果m3u8返回的ts文件地址为
https://p1.eckwai.com/ufile/adsocial/7ead0935-dd4f-4d2f-b17d-dd9902f8cc77.png
则需要下面处理后 才能进行合并
原因在于 使用Hexeditor打开后,发现文件头被描述为了PNG
在这种情况下,只需要将其中PNG文件头部分全部使用FF填充,即可处理该问题
:return:
'''
if not os.path.exists(dst_path):
os.mkdir(dst_path)
file_list = sorted(os.listdir(src_path), key=lambda x: int(x.split('.')[0]))
for i in file_list:
origin_ts = os.path.join(src_path, i)
resolved_ts = os.path.join(dst_path, i)
try:
infile = open(origin_ts, "rb") # 打开文件
outfile = open(resolved_ts, "wb") # 内容输出
data = infile.read()
outfile.write(data)
outfile.seek(0x00)
outfile.write(b'\xff\xff\xff\xff')
outfile.flush()
infile.close() # 文件关闭
outfile.close()
except:
pass
print('resolve ' + origin_ts + ' success')
4.3 完整代码
import shutil
import time
from urllib.parse import urljoin
import requests
import os
import re
from concurrent.futures import ThreadPoolExecutor, wait
def get_m3u8_url(url):
'''
获取页面中m3u8的url
:param url: 电影页面的url
:return:
'''
session = requests.Session()
# 访问首页获取cookie
session.get('https://www.9meiju.cc/', headers=headers)
# url = 'https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-2.html'
response = session.get(url, headers=headers)
response.encoding = 'UTF-8'
data = response.text
# print(data)
m3u8_uri = re.search('"url":"(.+?index.m3u8)"', data).group(1).replace('\\', '')
# 请求可以获取index.m3u8文件
response = session.get(m3u8_uri, headers=headers)
response.encoding = 'UTF-8'
data = response.text
# 拆分返回的内容获取真整的index.m3u8文件的url
# 注意 一定要strip
url = data.split('/', 3)[-1].strip()
print(data)
print('m3u8_uri', m3u8_uri)
url = urljoin(m3u8_uri, url)
print('url', url)
return url
def down_video(url, i):
'''
下载ts文件
:param url:
:param i:
:return:
'''
# print(url)
# 下载ts文件
resp = requests.get(url, headers=headers)
with open(os.path.join(path, str(i)+'.ts'), mode="wb") as f3:
f3.write(resp.content)
# print('{} 下载完成!'.format(url))
def download_all_videos(url, path):
'''
下载m3u8文件以及多线程下载ts文件
:param url:
:param path:
:return:
'''
# 请求m3u8文件进行下载
resp = requests.get(url, headers=headers)
with open("index.m3u8", mode="w", encoding="utf-8") as f:
f.write(resp.content.decode('UTF-8'))
if not os.path.exists(path):
os.mkdir(path)
# 开启线程 准备下载
pool = ThreadPoolExecutor(max_workers=50)
# 1. 读取文件
tasks = []
i = 0
with open("index.m3u8", mode="r", encoding="utf-8") as f:
for line in f:
# 如果不是url 则走下次循环
if line.startswith("#"):
continue
print(line, i)
# 开启线程
tasks.append(pool.submit(down_video, line.strip(), i))
i += 1
print(i)
# 统一等待
wait(tasks)
# 解析伪装成png的ts
def resolve_ts(src_path, dst_path):
'''
如果m3u8返回的ts文件地址为
https://p1.eckwai.com/ufile/adsocial/7ead0935-dd4f-4d2f-b17d-dd9902f8cc77.png
则需要下面处理后 才能进行合并
原因在于 使用Hexeditor打开后,发现文件头被描述为了PNG
在这种情况下,只需要将其中PNG文件头部分全部使用FF填充,即可处理该问题
:return:
'''
if not os.path.exists(dst_path):
os.mkdir(dst_path)
file_list = sorted(os.listdir(src_path), key=lambda x: int(x.split('.')[0]))
for i in file_list:
origin_ts = os.path.join(src_path, i)
resolved_ts = os.path.join(dst_path, i)
try:
infile = open(origin_ts, "rb") # 打开文件
outfile = open(resolved_ts, "wb") # 内容输出
data = infile.read()
outfile.write(data)
outfile.seek(0x00)
outfile.write(b'\xff\xff\xff\xff')
outfile.flush()
infile.close() # 文件关闭
outfile.close()
except:
pass
"""
else:
# 删除目录
shutil.rmtree(src_path)
# 将副本重命名为正式文件
os.rename(dst_path, dst_path.rstrip('2'))
"""
print('resolve ' + origin_ts + ' success')
# 处理m3u8文件中的url问题
def do_m3u8_url(path, m3u8_filename="index.m3u8"):
# 这里还没处理key的问题
if not os.path.exists(path):
os.mkdir(path)
with open(m3u8_filename, mode="r", encoding="utf-8") as f:
data = f.readlines()
fw = open(os.path.join(path, m3u8_filename), 'w', encoding="utf-8")
abs_path = os.getcwd()
i = 0
for line in data:
# 如果不是url 则走下次循环
if line.startswith("#"):
fw.write(line)
else:
fw.write(f'{abs_path}/{path}/{i}.ts\n')
i += 1
def merge(path, filename='output'):
'''
进行ts文件合并 解决视频音频不同步的问题 建议使用这种
:param filePath:
:return:
'''
os.chdir(path)
cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4'
os.system(cmd)
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36"
}
url = get_m3u8_url('https://www.9meiju.cc/mohuankehuan/shandianxiadibaji/1-20.html')
# 抓取99美剧闪电侠
# ts文件存储目录
path = 'ts'
# 下载m3u8文件以及ts文件
download_all_videos(url, path)
# 合并png的ts文件
src_path = path
dst_path = path+'2'
resolve_ts(src_path, dst_path)
do_m3u8_url(dst_path)
merge(dst_path, '闪电侠')
print('over')
5、解密处理
-
上面我们讲的是没有经过加密的 ts 文件,这些文件下载后直接可以播放,但经过AES-128加密后的文件下载后会无法播放,所以还需要进行解密。
-
如何判断是否需要加密?观察视频网站是否有m3u8的文件传输,下载下来并打开:
无需解密index.m3u8文件
#EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:4 #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-MEDIA-SEQUENCE:0 #EXTINF:3.086, https://hey05.cjkypo.com/20211215/FMbNtNzz/1100kb/hls/7qs6gJc0.ts #EXTINF:2.085, https://hey05.cjkypo.com/20211215/FMbNtNzz/1100kb/hls/rYpHhq0I.ts #EXTINF:2.085, https://hey05.cjkypo.com/20211215/FMbNtNzz/1100kb/hls/bfays5sw.ts需要解密index.m3u8文件
index.m3u8:https://s7.fsvod1.com/20220622/5LnZiDXn/index.m3u8
#EXT-X-VERSION:3 #EXT-X-TARGETDURATION:1 #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-MEDIA-SEQUENCE:0 #EXT-X-KEY:METHOD=AES-128,URI="/20220418/671fJxOB/2000kb/hls/key.key" # 当前路径为解密秘钥的位置 需要使用代码拼凑成完整路径 进行请求 域名+/20220418/671fJxOB/2000kb/hls/key.key #EXTINF:1.235, /20220418/671fJxOB/2000kb/hls/kj6uqHoP.ts # 并且这里ts的url也要拼凑完整 #EXTINF:1.001, /20220418/671fJxOB/2000kb/hls/ZXX8LYPa.ts #EXTINF:1.001, /20220418/671fJxOB/2000kb/hls/sOezpD2H.ts #EXTINF:1.001, ... -
如果你的文件是加密的,那么你还需要一个key文件,Key文件下载的方法和m3u8文件类似,如下所示 key.key 就是我们需要下载的 key 文件,并注意这里 m3u8 有2个,需要使用的是像上面一样存在 ts 文件超链接的 m3u8 文件
-
下载所有 ts 文件,将下载好的所有的 ts 文件、m3u8、key.key 放到一个文件夹中,将 m3u8 文件改名为 index.m3u8,将 key.key 改名为 key.m3u8 。更改 index.m3u8 里的 URL,变为你本地路径的 key 文件,将所有 ts 也改为你本地的路径
文件路径
project/
ts/
0.ts
1.ts
...
index.m3u8
key.m3u8
修改后的index.m3u8内容如下所示:
#EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:1 #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-MEDIA-SEQUENCE:0 #EXT-X-KEY:METHOD=AES-128,URI="/Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/key.m3u8" #EXTINF:1.235, /Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/0.ts #EXTINF:1.001, /Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/1.ts #EXTINF:1.001, /Users/xialigang/PycharmProjects/爬虫/抓取带秘钥的电影/ts/2.ts处理index.m3u8内容的代码如下所示
import time from urllib.parse import urljoin import requests import os from concurrent.futures import ThreadPoolExecutor, wait import re headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36" } def down_video(url, i): ''' 下载ts文件 :param url: :param i: :return: ''' # print(url) # 下载ts文件 resp = requests.get(url, headers=headers) with open(os.path.join(path, str(i) + '.ts'), mode="wb") as f3: f3.write(resp.content) # print('{} 下载完成!'.format(url)) def download_all_videos(path, host): ''' 下载m3u8文件以及多线程下载ts文件 :param url: :param path: :return: ''' if not os.path.exists(path): os.mkdir(path) # 开启线程 准备下载 pool = ThreadPoolExecutor(max_workers=50) # 1. 读取文件 tasks = [] i = 0 with open("index.m3u8", mode="r", encoding="utf-8") as f: for line in f: # 如果不是url 则走下次循环 if line.startswith("#"): continue line = host + line print(line, i) # 开启线程 tasks.append(pool.submit(down_video, line.strip(), i)) i += 1 # 统一等待 wait(tasks) # 处理m3u8文件中的url问题 def do_m3u8url(url, path, m3u8filename="index.m3u8"): # 这里还没处理key的问题 if not os.path.exists(path): os.mkdir(path) with open(m3u8_filename, mode="r", encoding="utf-8") as f: data = f.readlines() fw = open(os.path.join(path, m3u8_filename), 'w') abs_path = os.getcwd() i = 0 for line in data: # 如果不是url 则走下次循环 if line.startswith("#"): # 判断处理是存在需要秘钥 if line.find('URI') != -1: line = re.sub('(#EXT-X-KEY:METHOD=AES-128,URI=")(.*?)"', f'\\1{os.path.join(abs_path, path)}/key.m3u8"', line) host = url.rsplit('/', 1)[0] # 爬取key download_m3u8(host + '/key.key', os.path.join(path, 'key.m3u8')) fw.write(line) else: fw.write(f'{abs_path}/{path}/{i}.ts\n') i += 1 def download_m3u8(url, m3u8_filename="index.m3u8", state=0): print('正在下载index.m3u8文件') resp = requests.get(url, headers=headers) with open(m3u8_filename, mode="w", encoding="utf-8") as f: f.write(resp.text) def merge(filePath, filename='output'): ''' 进行ts文件合并 解决视频音频不同步的问题 建议使用这种 :param filePath: :return: ''' os.chdir(path) cmd = f'ffmpeg -i index.m3u8 -c copy {filename}.mp4' os.system(cmd) def get_m3u8data(first_m3u8url): session = requests.Session() # 请求第一次m3u8de url resp = session.get(first_m3u8_url, headers=headers) resp.encoding = 'UTF-8' data = resp.text # 第二次请求m3u8文件地址 返回最终包含所有ts文件的m3u8 second_m3u8_url = urljoin(first_m3u8_url, data.split('/', 3)[-1].strip()) resp = session.get(second_m3u8_url, headers=headers) with open('index.m3u8', 'wb') as f: f.write(resp.content) return second_m3u8_url if __name__ == '__main__': # ts文件存储目录 path = 'ts' # 带加密的ts文件的 index.m3u8 url url = 'https://s7.fsvod1.com/20220622/5LnZiDXn/index.m3u8' meu8_url = get_m3u8_data(url) # 下载m3u8文件以及ts文件 host = 'https://s7.fsvod1.com' # 主机地址 用于拼凑完整的ts路径和秘钥路径 download_all_videos(path, host) do_m3u8_url(meu8_url, path) # 文件合并 merge(path, '奇异博士') print('over') -
这样就大功告成了!我们成功解密并使用 ffmpeg 合并了这些 ts 视频片段,实际应用场景可能和这不一样,具体网站具体分析
多进程下载视频代码
#
# 'https://vip.lz-cdn6.com/20220327/31_c992ca39/index.m3u8'
# 'https://vip.lz-cdn6.com/20220327/31_c992ca39/'
# '1200k/hls/mixed.m3u8'
import os
import re
from fileinput import filename
from operator import index
from os.path import exists
from concurrent.futures import ThreadPoolExecutor, wait
import urllib3
urllib3.disable_warnings()
import requests
# 第一次m3u8
def index1_m3u8(url):
res = requests.get(url=url, headers=headers, verify=False)
if res.status_code == 200:
# print(res.text)
text = res.text
index_m3u8 = re.search('var now="(.*?index.m3u8)"', text).group(1)
print(index_m3u8)
index2_m3u8 = index_m3u8
b_index2_m3u8 = index2_m3u8.strip(index2_m3u8.split('/')[-1])
print(b_index2_m3u8)
index2_m3u8 = requests.get(url=index2_m3u8, headers=headers, verify=False)
index2_m3u8 = b_index2_m3u8 + re.search('(.*?mixed.m3u8)', index2_m3u8.text).group(1)
print(index2_m3u8)
# 获取m3u8文件
index2_m3u8 = index2_m3u8
res = requests.get(index2_m3u8, headers=headers, verify=False)
# print(res.text)
with open('index_m3u8.txt', 'w', encoding='utf8') as f:
f.write(res.text)
# 下载单个ts
def download_one_m3u8(url, i, path):
'''
:param url: 下载链接
:param i: i
:param path:路径
:return:
'''
while True:
try:
res = requests.get(url=url, headers=headers, verify=False, timeout=60)
file_path = os.path.join(path, str(i) + '.ts')
print(res.status_code)
if res.status_code == 200:
with open(file_path, 'wb') as f:
f.write(res.content)
print('下载成功')
break
except:
print(url, '请求超时,从新下载')
# 判断当前存储ts文件
def download_ts(path, filename='index_m3u8.txt'):
with open(filename, 'r', encoding='utf8') as f:
url_list = f.readlines()
print(url_list)
# 683de4afba9000000.ts
# https://vip.lz-cdn6.com/20220327/31_c992ca39/1200k/hls/683de4afba9000038.ts
path = path
if not exists(path):
os.mkdir(path)
# 创建线程池
pool = ThreadPoolExecutor(1000)
tasks = []
i = 0
for uri in url_list:
if uri.startswith('#'):
continue
uri = uri.strip()
uri = 'https://vip.lz-cdn6.com/20220327/31_c992ca39/1200k/hls/' + uri
print(uri)
# with open('index2_m3u8.txt','w', encoding='utf8') as f:
# f.write(url)
# https://vip.lz-cdn6.com/20220327/31_c992ca39/1200k/hls/683de4afba9000011.ts
tasks.append(pool.submit(download_one_m3u8, uri, i, path))
i += 1
# 集体等待
wait(tasks)
# 处理m3u8文件
def download_m3u8(url, m3u8_filename):
print('正在下载index.m3u8文件')
resp = requests.get(url, headers=headers)
with open(m3u8_filename, mode="w", encoding="utf-8") as f:
f.write(resp.content.decode('UTF-8'))
def do_index_m3u8(path, filename='index_m3u8.txt'):
with open(filename, 'r', encoding='utf8') as f:
lines = f.readlines()
path = path
if not exists(path):
os.mkdir(path)
file_path = os.path.join(path, filename)
f = open(file_path, 'w', encoding='utf8')
i = 0
for line in lines:
if line.startswith('#'):
# 判断处理是存在需要秘钥
if line.find('URI') != -1:
line = line.split('/')[0] + 'key.m3u8"\n'
print(line)
host = url.rsplit('/', 1)[0]
# 爬取key
download_m3u8(host + '/key.key', os.path.join(path, 'key.m3u8'))
f.write(line)
else:
f.write(str(i) + '.ts\n')
i += 1
def merge(path, filename='output'):
os.chdir(path)
cmd = f'ffmpeg -i index_m3u8.txt -c copy {filename}.mp4'
os.system(cmd)
# 解析伪装成png的ts
def resolve_ts(src_path, dst_path):
'''
如果m3u8返回的ts文件地址为
https://p1.eckwai.com/ufile/adsocial/7ead0935-dd4f-4d2f-b17d-dd9902f8cc77.png
则需要下面处理后 才能进行合并
原因在于 使用Hexeditor打开后,发现文件头被描述为了PNG
在这种情况下,只需要将其中PNG文件头部分全部使用FF填充,即可处理该问题
:return:
'''
if not os.path.exists(dst_path):
os.mkdir(dst_path)
file_list = sorted(os.listdir(src_path), key=lambda x: int(x.split('.')[0]))
for i in file_list:
origin_ts = os.path.join(src_path, i)
resolved_ts = os.path.join(dst_path, i)
try:
infile = open(origin_ts, "rb") # 打开文件
outfile = open(resolved_ts, "wb") # 内容输出
data = infile.read()
outfile.write(data)
outfile.seek(0x00)
outfile.write(b'\xff\xff\xff\xff')
outfile.flush()
infile.close() # 文件关闭
outfile.close()
except:
pass
print('resolve ' + origin_ts + ' success')
if __name__ == '__main__':
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
url = 'https://www.kankanmeiju.com/play/3310-0-0.html'
# file_m3u8()
# 获取所有的下载链接
index1_m3u8(url)
path = 'ts'
# 下载ts视频
do_index_m3u8(path)
dst_path = path+'2'
download_ts(dst_path)
resolve_ts(path,dst_path)
merge(dst_path)
协程下载视频代码
#
# 'https://vip.lz-cdn6.com/20220327/31_c992ca39/index.m3u8'
# 'https://vip.lz-cdn6.com/20220327/31_c992ca39/'
# '1200k/hls/mixed.m3u8'
import os
import re
from fileinput import filename
from operator import index
from os.path import exists
from concurrent.futures import ThreadPoolExecutor, wait
import urllib3
import asyncio
import aiohttp
import aiofiles
from aiohttp import TCPConnector
urllib3.disable_warnings()
import requests
# 第一次m3u8
async def index1_m3u8(url):
async with aiohttp.ClientSession(connector=TCPConnector(ssl=False), headers=headers) as session:
async with session.get(url=url) as resp:
if resp.status == 200:
# print(res.text)
text = await resp.text(encoding='utf-8')
# print(text)
index_m3u8 = re.search('var now="(.*?index.m3u8)"', text).group(1)
print(index_m3u8)
index2_m3u8 = index_m3u8
b_index2_m3u8 = index2_m3u8.strip(index2_m3u8.split('/')[-1])
print(b_index2_m3u8)
async with session.get(url=index2_m3u8) as resp1:
index2_m3u8 = b_index2_m3u8 + re.search('(.*?mixed.m3u8)',
await resp1.text(encoding='utf-8')).group(
1)
print(index2_m3u8)
# 获取m3u8文件
index2_m3u8 = index2_m3u8
async with session.get(index2_m3u8) as resp2:
# print(res.text)
with open('index_m3u8.txt', 'w', encoding='utf8') as f:
f.write(await resp2.text(encoding='utf-8'))
# 下载单个ts
async def download_one_m3u8(url, i, path, sem):
'''
:param url: 下载链接
:param i: i
:param path:路径
:return:
'''
while True:
async with sem:
try:
async with aiohttp.ClientSession(connector=TCPConnector(ssl=False), headers=headers) as session:
print(url, '正在下载')
async with session.get(url=url, timeout=60) as resp:
data = await resp.read()
file_path = os.path.join(path, str(i) + '.ts')
print(resp.status)
if resp.status == 200:
async with aiofiles.open(file_path, 'wb') as f:
await f.write(data)
print('下载成功')
break
except:
print(url, '请求超时,重新下载')
# 判断当前存储ts文件
async def download_ts(path, filename='index_m3u8.txt'):
with open(filename, 'r', encoding='utf8') as f:
url_list = f.readlines()
print(url_list)
# 683de4afba9000000.ts
# https://vip.lz-cdn6.com/20220327/31_c992ca39/1200k/hls/683de4afba9000038.ts
path = path
if not exists(path):
os.mkdir(path)
# 创建线程池
# pool = ThreadPoolExecutor(1000)
sem = asyncio.Semaphore(100)
tasks = []
i = 0
for uri in url_list:
if uri.startswith('#'):
continue
uri = uri.strip()
uri = 'https://vip.lz-cdn6.com/20220327/31_c992ca39/1200k/hls/' + uri
print(uri)
# with open('index2_m3u8.txt','w', encoding='utf8') as f:
# f.write(url)
# https://vip.lz-cdn6.com/20220327/31_c992ca39/1200k/hls/683de4afba9000011.ts
# tasks.append(pool.submit(download_one_m3u8, uri, i, path))
tasks.append(asyncio.create_task(download_one_m3u8(uri, i, path, sem)))
i += 1
# 集体等待
await asyncio.wait(tasks)
# 处理m3u8文件
def download_m3u8(url, m3u8_filename):
print('正在下载index.m3u8文件')
resp = requests.get(url, headers=headers)
with open(m3u8_filename, mode="w", encoding="utf-8") as f:
f.write(resp.content.decode('UTF-8'))
def do_index_m3u8(path, filename='index_m3u8.txt'):
with open(filename, 'r', encoding='utf8') as f:
lines = f.readlines()
path = path
if not exists(path):
os.mkdir(path)
file_path = os.path.join(path, filename)
f = open(file_path, 'w', encoding='utf8')
i = 0
for line in lines:
if line.startswith('#'):
# 判断处理是存在需要秘钥
if line.find('URI') != -1:
line = line.split('/')[0] + 'key.m3u8"\n'
print(line)
host = url.rsplit('/', 1)[0]
# 爬取key
download_m3u8(host + '/key.key', os.path.join(path, 'key.m3u8'))
f.write(line)
else:
f.write(str(i) + '.ts\n')
i += 1
def merge(path, filename='output'):
os.chdir(path)
cmd = f'ffmpeg -i index_m3u8.txt -c copy {filename}.mp4'
os.system(cmd)
async def main(url, path):
task = asyncio.create_task(index1_m3u8(url))
await asyncio.gather(task)
task = asyncio.create_task(download_ts(path))
await asyncio.gather(task)
do_index_m3u8(path)
merge(path, '1')
# 解析伪装成png的ts
def resolve_ts(src_path, dst_path):
'''
如果m3u8返回的ts文件地址为
https://p1.eckwai.com/ufile/adsocial/7ead0935-dd4f-4d2f-b17d-dd9902f8cc77.png
则需要下面处理后 才能进行合并
原因在于 使用Hexeditor打开后,发现文件头被描述为了PNG
在这种情况下,只需要将其中PNG文件头部分全部使用FF填充,即可处理该问题
:return:
'''
if not os.path.exists(dst_path):
os.mkdir(dst_path)
file_list = sorted(os.listdir(src_path), key=lambda x: int(x.split('.')[0]))
for i in file_list:
origin_ts = os.path.join(src_path, i)
resolved_ts = os.path.join(dst_path, i)
try:
infile = open(origin_ts, "rb") # 打开文件
outfile = open(resolved_ts, "wb") # 内容输出
data = infile.read()
outfile.write(data)
outfile.seek(0x00)
outfile.write(b'\xff\xff\xff\xff')
outfile.flush()
infile.close() # 文件关闭
outfile.close()
except:
pass
print('resolve ' + origin_ts + ' success')
if __name__ == '__main__':
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
url = 'https://www.kankanmeiju.com/play/3310-0-0.html'
# file_m3u8()
# 获取所有的下载链接
# index1_m3u8(url)
# path = 'ts'
# # 下载ts视频
# do_index_m3u8(path)
# dst_path = path + '2'
# resolve_ts(path, dst_path)
# download_ts(dst_path)
# merge(dst_path)
path = 'ts'
# asyncio.run(main(url, path))
loop = asyncio.get_event_loop()
loop.run_until_complete(main(url, path))
selenium
一、前期准备
1、概述
selenium本身是一个自动化测试工具。它可以让python代码调用浏览器。并获取到浏览器中加载的各种资源。 我们可以利用selenium提供的各项功能。 帮助我们完成数据的抓取。
2、学习目标
- 掌握 selenium发送请求,加载网页的方法
- 掌握 selenium简单的元素定位的方法
- 掌握 selenium的基础属性和方法
- 掌握 selenium退出的方法
3、安装
安装:pip install selenium
它与其他库不同的地方是他要启动你电脑上的浏览器, 这就需要一个驱动程序来辅助.
这里推荐用chrome浏览器
chrome驱动地址:http://chromedriver.storage.googleapis.com/index.html


根据你电脑的不同自行选择吧. win64选win32即可.
然后关键的来了. 把你下载的浏览器驱动放在python解释器所在的文件夹
Windwos: py -0p 查看Python路径
Mac: open + 路径
例如:open /usr/local/bin/

前期准备工作完毕. 上代码看看 感受一下selenium
from selenium.webdriver import Chrome # 导入谷歌浏览器的类
# 创建浏览器对象
web = Chrome() # 如果你的浏览器驱动放在了解释器文件夹
web.get("http://www.baidu.com") # 输入网址
print(web.title) # 打印title
运行一下你会发现神奇的事情发生了. 浏览器自动打开了. 并且输入了网址. 也能拿到网页上的title标题.

二、selenium的基本使用
1、加载网页:
selenium通过控制浏览器,所以对应的获取的数据都是elements中的内容
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# 访问百度
driver.get("http://www.baidu.com/")
# 截图
driver.save_screenshot("baidu.png")
2、定位和操作:
# 搜索关键字 杜卡迪
driver.find_element(By.ID, "kw").send_keys("杜卡迪")
# 点击id为su的搜索按钮
driver.find_element(By.ID, "su").click()
3、查看请求信息:
driver.page_source # 获取页面内容
driver.get_cookies()
driver.current_url
4、退出
driver.close() # 退出当前页面
driver.quit() # 退出浏览器
小结
- selenium的导包:
from selenium import webdriver - selenium创建driver对象:
webdriver.Chrome() - selenium请求数据:
driver.get("http://www.baidu.com/") - selenium查看数据:
driver.page_source - 关闭浏览器:
driver.quit() - 根据id定位元素:
driver.find_element_by_id("kw")/driver.find_element(By.ID, "kw") - 操作点击事件:
click() - 给输入框赋值:
send_keys()
三、元素定位的方法
学习目标
- 掌握 selenium定位元素的方法
- 掌握 selenium从元素中获取文本和属性的方法
通过selenium的基本使用可以简单定位元素和获取对应的数据,接下来我们再来学习下 定位元素的其他方法
1、selenium的定位操作
-
元素定位的两种写法:
-
直接调用型
el = driver.find_element_by_xxx(value) # xxx是定位方式,后面我们会讲,value为该方式对应的值 -
使用By类型(需要导入By) 建议使用这种方式
# 直接掉用的方式会在底层翻译成这种方式 from selenium.webdriver.common.by import By driver.find_element(By.xxx,value)
-
-
元素定位的两种方式:
-
精确定位一个元素,返回结果为一个element对象,定位不到则报错
driver.find_element(By.xx, value) # 建议使用 driver.find_element_by_xxx(value) -
定位一组元素,返回结果为element对象列表,定位不到返回空列表
driver.find_elements(By.xx, value) # 建议使用 driver.find_elements_by_xxx(value)
-
-
元素定位的八种方法:
以下方法在element之后添加s就变成能够获取一组元素的方法
-
By.ID 使用id值定位
el = driver.find_element(By.ID, '') el = driver.find_element_by_id() -
By.XPATH 使用xpath定位
el = driver.find_element(By.XPATH, '') el = driver.find_element_by_xpath() -
By.TAG_NAME. 使用标签名定位
el = driver.find_element(By.TAG_NAME, '') el = driver.find_element_by_tag_name() -
By.LINK_TEXT使用超链接文本定位
el = driver.find_element(By.LINK_TEXT, '') el = driver.find_element_by_link_text() -
By.PARTIAL_LINK_TEXT 使用部分超链接文本定位
el = driver.find_element(By.PARTIAL_LINK_TEXT , '') el = driver.find_element_by_partial_link_text() -
By.NAME 使用name属性值定位
el = driver.find_element(By.NAME, '') el = driver.find_element_by_name() -
By.CLASS_NAME 使用class属性值定位
el = driver.find_element(By.CLASS_NAME, '') el = driver.find_element_by_class_name() -
By.CSS_SELECTOR 使用css选择器定位
el = driver.find_element(By.CSS_SELECTOR, '') el = driver.find_element_by_css_selector()
-
注意:
-
建议使用find_element/find_elements
-
find_element和find_elements的区别 -
by_link_text和by_partial_link_text的区别:
全部文本和包含某个文本
-
使用: 以豆瓣为例
import time from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.implicitly_wait(10) # 等待节点加载完成 driver.get("https://www.douban.com/search?q=%E6%9D%B0%E6%A3%AE%E6%96%AF%E5%9D%A6%E6%A3%AE") time.sleep(2) # 使用id的方式获取右上角的搜索框 # ret1 = driver.find_element(By.ID, 'inp-query') # ret1 = driver.find_element(By.ID, 'inp-query').send_keys("杰森斯坦森") # ret1 = driver.find_element_by_id("inp-query") # print(ret1) # 输出为:<selenium.webdriver.remote.webelement.WebElement (session="ea6f94544ac3a56585b2638d352e97f3", element="0.5335773935305805-1")> # 搜索输入框 使用find_elements进行获取 # ret2 = driver.find_elements(By.ID, "inp-query") # ret2 = driver.find_elements_by_id("inp-query") # print(ret2) #输出为:[<selenium.webdriver.remote.webelement.WebElement (session="ea6f94544ac3a56585b2638d352e97f3", element="0.5335773935305805-1")>] # 搜索按钮 使用xpath进行获取 # ret3 = driver.find_elements(By.XPATH, '//*[@id="inp-query"]') # ret3 = driver.find_elements_by_xpath("//*[@id="inp-query"]") # print(len(ret3)) # print(ret3) # 匹配图片标签 ret4 = driver.find_elements(By.TAG_NAME, 'img') for url in ret4: print(url.get_attribute('src')) #ret4 = driver.find_elements_by_tag_name("img") print(len(ret4)) ret5 = driver.find_elements(By.LINK_TEXT, "浏览发现") # ret5 = driver.find_elements_by_link_text("浏览发现") print(len(ret5)) print(ret5) ret6 = driver.find_elements(By.PARTIAL_LINK_TEXT, "浏览发现") # ret6 = driver.find_elements_by_partial_link_text("浏览发现") print(len(ret6)) # 使用class名称查找 ret7 = driver.find_elements(By.CLASS_NAME, 'nbg') print(ret7) driver.close()
注意:
find_element与find_elements区别
- 只查找一个元素的时候:可以使用find_element(),find_elements()
find_element()会返回一个WebElement节点对象,但是没找到会报错,而find_elements()不会,之后返回一个空列表 - 查找多个元素的时候:只能用find_elements(),返回一个列表,列表里的元素全是WebElement节点对象
- 找到都是节点(标签)
- 如果想要获取相关内容(只对find_element()有效,列表对象没有这个属性) 使用 .text
- 如果想要获取相关属性的值(如href对应的链接等,只对find_element()有效,列表对象没有这个属性):使用 .get_attribute("href")
2、元素的操作
find_element_by_xxx方法仅仅能够获取元素对象,接下来就可以对元素执行以下操作 从定位到的元素中提取数据的方法
- 从定位到的元素中获取数据
el.get_attribute(key) # 获取key属性名对应的属性值
el.text # 获取开闭标签之间的文本内容
- 对定位到的元素的操作
el.click() # 对元素执行点击操作
el.submit() # 对元素执行提交操作
el.clear() # 清空可输入元素中的数据
el.send_keys(data) # 向可输入元素输入数据
使用示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver =webdriver.Chrome()
driver.get("https://www.douban.com/")
# 打印页面内容 (获取到以后可以进行后续的xpath,bs4 或者存储等)
print(driver.page_source)
ret4 = driver.find_elements(By.TAG_NAME, "h1")
print(ret4[0].text)
#输出:豆瓣
ret5 = driver.find_elements(By.LINK_TEXT, "下载豆瓣 App")
print(ret5[0].get_attribute("href"))
#输出:https://www.douban.com/doubanapp/app?channel=nimingye
driver.close()
小结
- 根据xpath定位元素:
driver.find_elements(By.XPATH,"//*[@id='s']/h1/a") - 根据class定位元素:
driver.find_elements(By.CLASS_NAME, "box") - 根据link_text定位元素:
driver.find_elements(By.LINK_TEXT, "下载豆瓣 App") - 根据tag_name定位元素:
driver.find_elements(By.TAG_NAME, "h1") - 获取元素文本内容:
element.text - 获取元素标签属性:
element.get_attribute("href") - 向输入框输入数据:
element.send_keys(data)
四、selenium的其他操作
学习目标
- 掌握 selenium处理cookie等方法
- 掌握 selenium中switch的使用
- 掌握selenium中无头浏览器的设置
1、无头浏览器
我们已经基本了解了selenium的基本使用了. 但是呢, 不知各位有没有发现, 每次打开浏览器的时间都比较长. 这就比较耗时了. 我们写的是爬虫程序. 目的是数据. 并不是想看网页. 那能不能让浏览器在后台跑呢? 答案是可以的
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
opt = Options()
opt.add_argument("--headless")
opt.add_argument('--disable-gpu')
opt.add_argument("--window-size=4000,1600") # 设置窗口大小
web = Chrome(options=opt)
1、selenium 处理cookie
通过driver.get_cookies()能够获取所有的cookie
-
获取cookie
dictCookies = driver.get_cookies() -
设置cookie
driver.add_cookie(dictCookies) -
删除cookue
#删除一条cookie driver.delete_cookie("CookieName") # 删除所有的cookie driver.delete_all_cookies()
2、页面等待
-
为什么需要等待
如果网站采用了动态html技术,那么页面上的部分元素出现时间便不能确定,这个时候就可以设置一个等待时间,强制等待指定时间,等待结束之后进行元素定位,如果还是无法定位到则报错 -
页面等待的三种方法
-
强制等待
import time time.sleep(n) # 阻塞等待设定的秒数之后再继续往下执行 -
显式等待(自动化web测试使用,爬虫基本不用)
from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC WebDriverWait(driver, 10,0.5).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) # 显式等待指定某个条件,然后设置最长等待时间10,在10秒内每隔0.5秒使用指定条件去定位元素,如果定位到元素则直接结束等待,如果在10秒结束之后仍未定位到元素则报错 -
隐式等待 隐式等待设置之后代码中的所有元素定位都会做隐式等待
driver.implicitly_wait(10) # 在指定的n秒内每隔一段时间尝试定位元素,如果n秒结束还未被定位出来则报错
-
注意:
Selenium显示等待和隐式等待的区别
1、selenium的显示等待
原理:显示等待,就是明确要等到某个元素的出现或者是某个元素的可点击等条件,等不到,就一直等,除非在规定的时间之内都没找到,就会跳出异常Exception
(简而言之,就是直到元素出现才去操作,如果超时则报异常)
2、selenium的隐式等待
原理:隐式等待,就是在创建driver时,为浏览器对象创建一个等待时间,这个方法是得不到某个元素就等待一段时间,直到拿到某个元素位置。
注意:在使用隐式等待的时候,实际上浏览器会在你自己设定的时间内部断的刷新页面去寻找我们需要的元素
3、switch方法切换的操作
3.1 一个浏览器肯定会有很多窗口,所以我们肯定要有方法来实现窗口的切换。切换窗口的方法如下:
也可以使用 window_handles 方法来获取每个窗口的操作对象。例如:
# 1. 获取当前所有的窗口
current_windows = driver.window_handles
# 2. 根据窗口索引进行切换
driver.switch_to.window(current_windows[1])
driver.switch_to.window(web.window_handles[-1]) # 跳转到最后一个窗口
driver.switch_to.window(current_windows[0]) # 回到第一个窗口
3.2 iframe是html中常用的一种技术,即一个页面中嵌套了另一个网页,selenium默认是访问不了frame中的内容的,对应的解决思路是
driver.switch_to.frame(name/el/id) 传入的参数可以使iframe对应的id值,也可以是用元素定位之后的元素对象
动手:qq邮箱
在使用selenium登录qq邮箱的过程中,我们会发现,无法在邮箱的登录input标签中输入内容,通过观察源码可以发现,form表单在一个frame中,所以需要切换到frame中
3.3 当你触发了某个事件之后,页面出现了弹窗提示,处理这个提示或者获取提示信息方法如下:
alert = driver.switch_to_alert()
4. 页面前进和后退
driver.forward() # 前进
driver.back() # 后退
driver.refresh() # 刷新
driver.close() # 关闭当前窗口
5、设置浏览器最大窗口
driver.maximize_window() #最大化浏览器窗口
4、selenium的优缺点
- 优点
- selenium能够执行页面上的js,对于js渲染的数据和模拟登陆处理起来非常容易
- 使用难度简单
- 爬取速度慢,爬取频率更像人的行为,天生能够应对一些反爬措施
- 缺点
- 由于selenium操作浏览器,因此会将发送所有的请求,因此占用网络带宽
- 由于操作浏览器,因此占用的内存非常大(相比较之前的爬虫)
- 速度慢,对于效率要求高的话不建议使用
小结
- 获取cookie:
get_cookies() - 删除cookie:
delete_all_cookies() - 切换窗口:
switch_to.window() - 切换iframe:
switch_to.frame()
5、selenium的配置
https://blog.csdn.net/qq_35999017/article/details/123922952
https://blog.csdn.net/qq_27109535/article/details/125468643
MySQL数据库
一、MySQL数据库的介绍
1、发展史
1996年,MySQL 1.0
2008年1月16号 Sun公司收购MySQL。
2009年4月20,Oracle收购Sun公司。
MySQL是一种开放源代码的关系型数据库管理系统(RDBMS),使用最常用的数据库管理语言--结构化查询语言(SQL)进行数据库管理。
MySQL是开放源代码的,因此任何人都可以在General Public License的许可下下载并根据个性化的需要对其进行修改。
MySQL因为其速度、可靠性和适应性而备受关注。大多数人都认为在不需要事务化处理的情况下,MySQL是管理内容最好的选择。
2、MySQL简介
MySQL是一个关系型数据库管理系统,由瑞典MySQLAB 公司开发,目前属于 Oracle 旗下产品。MySQL是最流行的关系型数据库管理系统之一,在WEB 应用方面,MySQL是最好的 RDBMS (RelationalDatabase Management System,关系数据库管理系统)应用软件MySQL所使用的SQL 语言是用于访问数据库的最常用标准化语言。MySQL软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择MySQL 作为网站数据库
3、社区版本和企业版本的区别
主要的区别有以下两点。
- 企业版只包含稳定之后的功能,社区版包含所有Mysql的最新功能。
也就是说,社区版是企业版的测试版,但是,前者的功能要比后者多。
- 官方的支持服务只针对企业版,用户在使用社区版时出现任何问题,Mysql官方概不负责。
MySQL如何下载
进入MySQL官网(https://www.mysql.com)
查看底部下载-https://dev.mysql.com/downloads/mysql/
二、数据库的分类
关系型与非关系型数据库
1、关系型数据库的优势:
-
复杂查询
可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询
-
事物支持
使得对于安全性能很高的数据访问要求得以实现
2、非关系型数据库的优势:
-
性能
NOSQL是基于键值对的 可以想象成表中的主键和值的对应关系 不需要经过SQL层的解析 所以性能很高
-
可扩展性
同样也是也因为基于键值对 数据之间没有偶尔性 所以非常容易水平扩展
三、安装与Navicat使用
1、MySQL安装
先去mysql官网下载好安装包. (https://dev.mysql.com/downloads/)








接下来是MySQL的图形化界面工具. 推荐用Navicat. 好多年了, 很好用. 安装的时候一路确定.
2、Navicat使用




哦了, 至此, Navicat可以操纵你的数据库了.
四、进入到MySQL数据库
1、简单模式
C:\Users\xlg>mysql -uroot -p
Enter password: ******
2、标准模式
C:\Users\xlg>mysql -h127.0.0.1 -uroot -p
mysql -hlocalhost -uroot -p
3、参数所代表的含义:
h:host 主机(localhost IPV4 127.0.0.1)
u:root 用户
p:password 密码
五、对于MySQL数据库的操作
1、对于库与表进行操作
-
查看所有的数据库
show databases;
-
选择数据库
use 库名
-
查看当前库下有哪些表
show tables;
-
查看当前所在库
select database();
-
创建数据库
create database 库名;
-
查看创建库信息
show create database 库名;
-
删除库/表
drop database 库名;drop table 表名;
-
创建库并设置字符编码
create database lucky character set utf8;
-
查看表结构
desc 表名;
-
查看创建表语句
show create table lucky;
-
撤销当前命令
\c
-
数据库的退出
- \q
- exit
- quit
2、注意
- MySQL命令以英文的分号作为结束
- SQL命令不区分大小写
- 在进入到一个数据库中在进入到另外一个的时候 不需要退出数据库 而是使用use再次进行数据库的切换
- windows下表名库名不区分大小写 Linux下严格区分
- MySQL数据库的名称具有唯一性 每个库中的表的名称也具有唯一性(库名或者一个库中的表名不要出现相同的名称)
- 当在输入命令的时候输入完以后 添加分号不能执行命令 那么查看一下左侧是否存在引号没有闭合的情况
六. 表的操作
1、表的概念
在所有关系型数据库中, 所有的数据都是以表格的形式进行存储的. 那表格应该如何进行设计呢? 其实这里蕴含了一个映射关系的.
比如, 我们想要存学生信息. 那我们先思考. 在你未来的规划中, 一个学生应该会有哪些数据存在?
学生: 学号(唯一标识), 姓名, 生日, 家庭住址, 电话号等信息. OK. 我们抛开数据库不谈. 想要存储这些数据, 表格创建起来的话应该是是这样的:

OK. 按照这个规则来看. 每一条数据对应的就是一个人的信息.
2、创建表
创建表有两种方案:
-
用SQL语句创建表格
create table student( sno int(10) primary key auto_increment, sname varchar(50) not null, sbirthday date not null, saddress varchar(255), sphone varchar(12), class_name varchar(50) )数据类型:
int 整数
double小数
varchar 字符串
text 大文本
约束条件:
primary key 主键, 全表唯一值. 就像学号. 身份证号. 能够唯一的确定一条数据
auto_increment 主键自增.
not null 不可以为空.
null 可以为空
default 设置默认值
-
用Navicat图形化工具来创建



七、MySQL表的创建
字段类型
1、数值类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| tinyint | 1字节 | (-128,127) | (0,255) | 小整数值 |
| int | 4字节 | (-2147483648, 2147483647) | (0,4294967295) | 大整数值 |
| float | 4字节 | 单精度浮点型 | ||
| double | 8字节 | 双精度浮点型 |
创建表语句
mysql> create table testnum(
-> ttinyint tinyint,
-> tint int,
-> tfloat float(6,2),
-> tdouble double(6,2),
-> );
创建表的主体结构:
create table if not exists 表名(
字段名称 字段类型 约束条件 字段说明,
字段名称 字段类型 约束条件 字段说明,
...
)
表插入数据语句
指定字段名称插入值
insert into 表名(字段1,字段2...) values(值1,值2...)
不指定字段插入之
insert into 表名 values(值1,值2...)
2、字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| char | 0-255字节 | 定长字符串 |
| varchar | 0-255字节 | 变长字符串 |
| text | 0-65535字节 | 长文本数据 |
| longtext | 0-4294697295字节 | 极大文本数据 |
字符串类型注意事项:
- char和varchar的区别
- char执行效率高于varchar (但占用空间大)
- varchar相对于char节省空间
- char和varchar 类型的长度范围都在0-255之间
- varchar类型传入的值小于给定的长度 不会使用空格填充
七、INSERT 数据的添加
-
指定字段添加值
insert into 表名(字段1,字段2....) values(值1,值2...)
insert into user(sex,username) values(0,'lucky');
-
不指定字段添加值
insert into 表名 values(值1,值2...)
insert into user values(null,0,'lucky','我是lucky老师');
-
指定字段添加多个值
insert into 表名(字段1,字段2....) values(值1,值2...),(值1,值2...)...
insert into user(sex,username) values(1,'苍苍'),(0,'蒹葭');
-
不指定字段添加多个值
insert into 表名 values(值1,值2...),(值1,值2...)...
insert into user values(null,1,'xxx','xxx'),(null,0,'xxl','xxl');
注意事项:
指定字段与不指定字段在添加值的时候 按照从左至右依次对应给值
八、SELECT查询
-
不指定字段的查询(不建议)
select * from 表名
-
指定字段的数据查询(建议)
select 字段名1,字段名2... from 表名
select username,userinfo from user;
-
对查询的字段起别名
select username as u from user;
select username u from user;
九、UPDATE修改
-
修改一个字段的值
update 表名 set 字段名=值;
update user set username='帅气的lucky' where id = 3;
-
修改多个字段的值
update 表名 set 字段名1=值1,字段名2=值2...;
update user set sex=0,userinfo='xxx的个人简介' where id=7;
-
给字段的值在原有的基础上改变值
update user set sex=sex+2;
注意:
在进行数据的修改的时候 一定记得给定where条件 如果没有给定where条件 则修改的为整张表当前字段的值
十、DELETE 删除
主体结构:
delete from 表名 [where ...]
实例:
delete from user; 删除user表中所有的数据
注意:
删除 一定注意添加 where 条件 否则会删除整张表中的数据 并且auto_increment自增所记录的值不会改变 所以需要将自增归位
truncate 表名; 清空表数据
十一、WHERE条件
实例表结构:
+----------+-------------+------+-----+-----------------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+-----------------------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| sex | tinyint(4) | NO | | 1 | |
| username | varchar(20) | YES | | NULL | |
| age | tinyint(4) | NO | | 18 | |
| userinfo | varchar(50) | NO | | 我是帅气的lucky老师啊 | |
+----------+-------------+------+-----+-----------------------+----------------+
(1) 比较运算符
-
>将id大于5 的性别 更改为0 年龄改为20岁
update user set sex=0,age=20 where id>5;
-
<将id小于3 的性别 更改为0 年龄改为23岁
update user set sex=0,age=23 where id<3;
查看id小于4的 性别和用户名的字段数据
select sex,username from user where id<4;
-
>=删除 id大于等于6的数据
delete from user where id>=6;
-
<=查询年龄小于等于23的数据
select * from user where age<=23;
-
=
查询性别为0的数据
select * from user where sex=0;
-
!=/<>查询 用户名不等于lucky的所有数据
select * from user where username!='lucky';
select * from user where username<>'lucky';
(2) 逻辑运算符
-
and 逻辑与 俩侧为真结果为真
查询年龄在18到23之间 不包括本身
select * from user where age>18 and age<23;
修改年龄为30 id大于1 小于等于2
update user set age=30 where id>1 and id<=2;
-
or 逻辑或运算 俩侧条件满足一侧就可以
select * from user where age=10 or age=30;
select * from user where age>=10 or age<=30;
(3) order by 排序 升序/降序
升序
查询数据 按照年龄升序(默认)
select * from user order by age;
select * from user order by age asc;
查询数据 按照年龄降序
select * from user order by age desc;
(4) limit 取值
结构:
limit x 取出x条数据
limit x,y 从x的位置取出y条数据
取出3条数据
select * from user limit 3;
取出年龄最大/最小的一条数据
select * from user order by age desc limit 1;
select * from user order by age limit 1;
(6) like 模糊查询
-
’%字符‘ 查询以字符结尾的数据
查询以三字为结束的username的数据
select * from user where username like '%三';
-
'字符%' 查询以字符开头的数据
select * from user where username like '赵%';
-
'%字符%' 查询包含字符的数据
查询 userinfo中包含lucky的数据
select * from user where userinfo like '%lucky%';
十二、 聚合函数
- count 统计个数
- max 最大值
- min 最小值
- Sum 求和
- avg 求平均数
select count(*) as count,max(age),min(age),avg(age),sum(age) from user;
十三、 数据库的导入导出
-
导入
mysql -uroot -p 库名<demo.sql
-
导出
mysqldump -uroot -p 库名>demo.sql
十四、Python操作MySQL
安装:
pip install pymysql
使用:
import pymysql
(1) 链接MySQL数据库
db = pymysql.connect(主机名,用户名,密码,数据库名)
db = pymysql.connect(host='localhost', user='root', password='123456', database='test')
(2) 设置字符集
db.set_charset('utf8')
(3) 创建游标对象
cursor = db.cursor()
(4) 执行SQL语句
cursor.execute(sql语句)
(5) 获取结果集
获取所有
cursor.fetchall()
获取一条
cursor.fetchone()
(6) 获取受影响的行数
cursor.rowcount
(7) 事物
pymysql默认开启了事物处理 所以在添加数据的时候 需要commit 或者rollback
实例:
try:
sql = 'insert into user values(null,1,"曹操",100,"曹操第一奸雄","魏国")'
print(sql)
cursor.execute(sql)
db.commit()
except:
db.rollback()
对于支持事务的数据库, 在Python数据库编程中,当游标建立之时,就自动开始了一个隐形的数据库事务。
commit()方法游标的所有更新操作,rollback()方法回滚当前游标的所有操作。每一个方法都开始了一个新的事务。
(8) 关闭数据库连接
db.close()
(9) 拼凑正常完整的sql语句
print("select name,password from user where name=\""+username+"\"")
print("select name,password from user where name='"+username+"'")
print("select name,password from user where name='%s'"%(username))
print("select name,password from user where name='{}'".format(username))
print(f"select name,password from user where name='{username}'")
NoSQL Mongodb
- 下载mongodb的版本,两点注意
- 根据业界规则,偶数为稳定版,如1.6.X,奇数为开发版,如1.7.X
- 32bit的mongodb最大只能存放2G的数据,64bit就没有限制
性能
BSON格式的编码和解码都是非常快速的。它使用了C风格的数据表现形式,这样在各种语言中都可以高效地使用。
NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
一、安装(windows)
下载mongodb的版本,两点注意
- 根据业界规则,偶数为稳定版,如1.6.X,奇数为开发版,如1.7.X
- 32bit的mongodb最大只能存放2G的数据,64bit就没有限制
首先去官网下载MongoDB的安装包, https://www.mongodb.com/try/download/community











将mongodb目录下的bin文件夹添加到环境变量







对于mac的安装可以使用homebrew安装. 或参考这里https://www.runoob.com/mongodb/mongodb-osx-install.html
一、MongoDB 概念解析
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
二、注意事项
需要注意的是:
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
- .和$有特别的意义,只有在特定环境下才能使用。
- 以下划线"_"开头的键是保留的(不是严格要求的)。
四、连接Mongodb
(1) cd mongo安装的目录/bin
输入 mongod.exe --dbpath=路径
(2) 重新启动一个Windows的终端 再次进入到 mongo安装的目录/bin
cd mongo安装的目录/bin
mongo.exe #此刻 进入到Mongodb数据库了
五、 对于库的操作
(1) 查看所有的库
show dbs
(2) 选择数据库 (如果使用的数据库存在 则使用 不存在 则创建)
use 库名
注意:
新创建的数据库 默认你是看不到的 可以使用db/db.getName() 去查看当前所在的库 往新的库里创建集合
(3) 查看当前所在的数据库
1. db
2. db.getName()
(4) 创建集合(也就是创建表)
-
db.createCollection("集合名")
remo例如:db.createCollection("user") #创建一个user的集合 在当前的库里
-
db.集合名.insert(文档) #如果 当前的集合名不存在 那么就创建该集合 并插入文档(数据)
注意:
1. 在库里对于文档 集合的操作 统一使用db. (db代表当前的库)
2. 严格区分大小写
(5) 查看当前库下的所有集合
show collections
(6) 删除集合
db.集合名.drop()
六、INSERT
使用insert
db.集合名.insert(文档) #如果是添加数据 建议使用 insert
插入多条数据:
db.集合名.insert([文档]) #注意 一定要加[] 否则可能只会把 第一条文档插入进去
db.user.insert({'name':'lisi', 'age': 20})
db.user.insert([{'name':'lisi', 'age': 20},{'name': 'wangwu', 'age': 30}])
3.2 版本后还有以下几种语法可用于插入文档:(建议使用)
- db.collection.insertOne():向指定集合中插入一条文档数z据
- db.collection.insertMany():向指定集合中插入多条文档数据
db.user.insertOne({'name':'lisi', 'age': 20})
db.user.insertMany([{'name':'lisi', 'age': 20},{'name': 'wangwu', 'age': 30}])
七、FIND 查询
(1) find 查询所有
db.集合名.find([条件],{key1:1[,[key2:1]]}) #查询所有的数据 代表 显示哪些字段名
db.collection.find(query, {title: 1, by: 1}) // inclusion模式 指定返回的键,不返回其他键
db.collection.find(query, {title: 0, by: 0}) // exclusion模式 指定不返回的键,返回其他键
注意:
两种模式不可混用(因为这样的话无法推断其他键是否应返回)
db.collection.find(query, {title: 1, by: 0}) // 错误
_id 键默认返回,需要主动指定 _id:0 才会隐藏
只能全1或全0,除了在inclusion模式时可以指定_id为0
db.collection.find(query, {_id:0, title: 1, by: 1}) // 正确
实例
db.user.find({}, {'name': 0})
db.user.find({'age': 18}, {'name': 1}) # 只返回那么字段
db.user.find({'age': 18}, {'name': 0}) # 不返回name字段
(2) findOne() 查询一条
db.集合名.findOne([条件],{key1:1[,[key2:1]]}) #查询一条数据 代表 显示哪些字段名
db.user.findOne({}, {name:1})
(3) count 统计数据条数
db.集合名.find([条件]).count()
db.user.find({}).count()
(4) pretty() 展开来查看
db.集合名.find([条件]).pretty()
db.user.find({}).pretty()
(5) 查询条件的操作符
| 符号 | 符号说明 | 实例 | 说明 |
|---|---|---|---|
| $gt | 大于 | db.user.find({age:{$gt:18}}) | 年龄大于18 的 |
| $gte | 大于等于 | db.user.find({age:{$gte:18}}) | 年龄大于等于18的 |
| $lt | 小于 | db.user.find({age:{$lt:18}}) | 年龄小于18 |
| $lte | 小于等于 | db.user.find({age:{$lte:18}}) | 年龄小于等于18 |
| 等于 | db.user.find({age:18}) | 年龄等于18 | |
| /值/ | 模糊查询 | db.user.find({username:/小/}) | 查询年龄中包含小字的文档 |
| /^值/ | 以...作为开头 | db.user.find({username:/^小/}) | 查询username中以小字作为开头的文档 |
| /值$/ | 以...作为结尾 | db.user.find({username:/小$/}) | 查询username中以小字作为结尾的文档 |
| $in | 在...内 | db.user.find({age:{$in:[18,20,30]}) | 查询年龄在18,20,30的文档 |
| $nin | 不在...内 | db.user.find({age:{$nin:[18,20,30]}}) | 查询年龄不在 1,20,30的文档 |
| $ne | 不等于 != | db.user.find({age:{$ne:18}}) | 查询年龄不为18的文档 |
(6) AND 查询
db.col.find({key1:value1, key2:value2}).pretty()
db.集合名.find({条件一,条件二,,,})
例如:
db.user.find({name:"张三",age:{$gt:10}}) #查询name为张三的 且 年龄 大于10岁的
db.user.find({name:"张三",age:10}) #查询name为张三的 且 年龄为10岁的
(7) OR 查询
db.集合名.find({$or:[{条件一},{条件二},,,]})
例如:
db.user.find({$or:[{name:"张三"},{name:"赵六"}]}) #查询name为张三 或者为赵六的所有数据
(8) AND 和 OR 的使用
db.集合名.find({条件一,,,$or:[{条件1},{条件2}]})
例如:
db.user.find({name:"张三",$or:[{age:10},{age:28}]}) #name为张三 年龄为10岁或者28岁的所有数据
(9) LIMIT 取值
db.集合名.find().limit(num) #从第0个开始取几个
例如:
db.user.find().limit(5) #从0开始取5条数据
(10) skip 跳过几个
db.集合名.find().skip(num) #跳过几条数据
例如:
db.user.find().skip(2) #从第三条数据 取到最后
(11) limit skip 配合使用
db.集合名.find().skip().limit(num)
例如:
db.user.find().skip(2).limit(2) #从第三个开始 取2个
(12) SORT 排序
在MongoDB中使用使用sort()方法对数据进行排序,sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
db.集合名.find().sort({key:1|-1}) #升序或者降序
例如:
db.user.find().sort({age:1}) #查询所有数据 按照年龄 升序
db.user.find().sort({age:-1}) #查询所有数据 按照年龄 降序
八、UPDATE 文档的修改
结构:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)u
- **query **: update的查询条件,类似sql update查询内where后面的。
- **update **: update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
(1) 更新操作符 $set直接修改 $inc累加修改
-
db.集合名.update(条件,数据,{multi:true}) 更改
db.user.update({name:"张三"},{$inc:{age:5}}) #修改name为张三的文档 将age在原有的基础上 加5 db.user.update({name:"张三"},{$set:{age:5}}) #修改name为张三的文档 将age的值 修改为5 db.user.update({name:"张三"},{$set:{age:5}}) #将name为张三的文档 的年龄 修改为 5 -
只更新第一条记录:
db.col.update({"count" : {$gt:1}} , { $set : {"test2" : "OK"}}); -
全部更新:
db.col.update({"count" : {$gt: 3 }} , {$set : {"test2" : "OK"} }); -
只添加第一条:
db.col.update({ "count" : { $gt : 4 }} , {$set : {"test5" : "OK"} });
3.2版本以后(建议使用)
updateOne() 更新一条
db.user.updateOne({'name':'lisi'}, {$inc:{'age':5}})
updateMany(query,update) 更新多条
db.user.updateMany({'name':'lisi'}, {$inc:{'age':5}})
九、REMOVE 文档的删除
主体结构
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
(1)参数说明:
- **query **:(可选)删除的文档的条件。
- **justOne **: (可选)如果设为 true 或 1,则只删除一个文档。
- **writeConcern **:(可选)抛出异常的级别。
(2) 主体结构
db.集合名.remove(条件) #默认将所有都匹配到的数据进行删除
db.集合名.remove(条件,1) #只删除 第一个匹配到的数据
db.集合名.remove(条件,,{justOne:true}) #只删除 第一个匹配到的数据
示例
b.user.remove({'age':{$gt: 30}}) # 删除年龄大于30的所有数据
b.user.remove({'age':{$gt: 30}}, 1) # 删除年龄大于30的一条数据
db.col.remove({}) 清空集合 "col" 的数据
(3) 3.2 版本后还有以下几种语法可用于删除文档:(建议)
remove() 方法已经过时了,现在官方推荐使用
deleteOne() 删除一条
db.user.deleteOne({'age':{$gt: 0}})
deleteMany() 删除多条
db.user.deleteMany({'age':{$gt: 0}})
十、数据库删除与退出
(1) 数据库删除
- 删除之前 最好use一下
- db.dropDatabase()
(2) 数据库的退出
exit
十一、Python操作MongoDB
1、导入 pymongo
from pymongo import MongoClient
2、连接服务器 端口号 27017
(1) 连接MongoDB
连接MongoDB我们需要使用PyMongo库里面的MongoClient,一般来说传入MongoDB的IP及端口即可,第一个参数为地址host,第二个参数为端口port,端口如果不传默认是27017。
(2) 代码
conn = MongoClient("localhost")
MongoClient(host='127.0.0.1',port=27017)
3、连接数据库
db = conn.数据库名称
连接集合
collection = db.collection_name
4、插入数据
(1) 在3.x以上 建议 使用
insert_one 插入一条数据
insert_many() 插入多条数据
(2) 返回 id 使用insert_one()
data.inserted_id
data.inserted_ids
5、查询数据
(1) 查询一条
db.user.find_one()
(2) 带条件查询
db.user.find({"name":"张三"})
(3) 查询 id
**from **bson.objectid **import **ObjectId*#用于ID查询
data = db.user.find({"_id":ObjectId("59a2d304b961661b209f8da1")})
data = db.user.find({'_id': ObjectId('59f290b01683f9339214746d')}) #_id': ObjectId('59f290b01683f9339214746d')
(5) 模糊查询
-
{"name":{'$regex':"张"}}
6、sort limit skip
(1) sort 排序
年龄 大于10
data = db.user.find({"age":{"$gt":10}}).sort("age",1) #年龄 升序 查询 pymongo.ASCENDING --升序
data = db.user.find({"age":{"$gt":10}}).sort("age",-1) #年龄 降序 查询 pymongo.DESCENDING --降序
(2) limit 取值
取三条数据
db.user.find().limit(3)
m= db.user.find({"age":{"$gt":10}}).sort("age",-1).limit(3)
(3) skip 从第几条数据开始取
db.user.find().skip(2)
7、update 修改
update()方法其实也是官方不推荐使用的方法,在这里也分了update_one()方法和update_many()方法,用法更加严格,
(1) update_one() 第一条符合条件的数据进行更新
db.user.update_one({"name":"张三"},{"$set":{"age":99}})
(2) update_many() 将所有符合条件的数据都更新
db.user.update_many({"name":"张三"},{"$set":{"age":91}})
(3) 其返回结果是UpdateResult类型,然后调用matched_count和modified_count属性分别可以获得匹配的数据条数和影响的数据条数。
- result.matched_count
- result.modified_count
8、remove 删除
删除操作比较简单,直接调用remove()方法指定删除的条件即可,符合条件的所有数据均会被删除,
(1) 删除一条
delete_one()即删除第一条符合条件的数据
collection.delete_one({“name”:“ Kevin”})
(2) 删除多条
delete_many()即删除所有符合条件的数据,返回结果是DeleteResult类型
collection.delete_many({“age”: {$lt:25}})
(4) 可以调用deleted_count属性获取删除的数据条数。
result.deleted_count
9、关闭连接
conn.close()
Redis数据库
Redis 简介
Redis是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis与其他 key- value 缓存产品有以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
redis: 半持久化,存储于内存和硬盘
Redis和MongoDB的区别
Redis是完全在内存中保存数据的数据库,使用磁盘只是为了持久性目的,Redis数据全部存在内存,定期写入磁盘,当内存不够时,可以选择指定的LRU算法删除数据,持久化是使用RDB方式或者aof方式。
mongodb是文档型的非关系型数据库,MongoDB更类似MySQL,支持字段索引、游标操作,其优势在于查询功能比较强大,擅长查询JSON数据,能存储海量数据,但是不支持事务。
一 前期准备
下载地址:
https://github.com/ServiceStack/redis-windows
https://github.com/MSOpenTech/redis/releases
设置 redis.windows.conf
455行 maxheap 1024000000 设置最大的数据堆的大小
387行 requirepass 123456 设置数据库的密码
二 启动服务
cd C:\redis64-2.8.2101
C:\redis64-2.8.2101>redis-server.exe redis.windows.conf #执行 redis-server.exe 并加载Windows的配置文件
C:\redis64-2.8.2101—>dump.rdb 为数据文件
mac 下安装也可以使用 homebrew,homebrew 是 mac 的包管理器。
1、执行 brew install redis
2、启动 redis,可以使用后台服务启动 brew services start redis。或者直接启动:redis-server /usr/local/etc/redis.conf
三 测试是否连接成功
再打开一个新的终端
输入密码 (这个密码就是在redis.windows.conf里面设置的密码)
C:\redis64-2.8.2101>redis-cli.exe
127.0.0.1:6379>auth '123456'
注意:
密码 为 字符串类型
四 Redis值的类型
-
字符串 String
-
哈希 hash
-
列表 list
-
集合 set
-
有序集合 zset
数据操作的全部命令:
config get databases 查看所有的数据库 数据库以0开始 一共16个
(1) String
概述:String是redis最基本的类型,最大能存储512MB的数据,String类型是二进制安全的,即可以存储任何数据、比如数字、图片、序列化对象等
一个key对应一个value
string类型是Redis最基本的数据类型,一个键最大能存储512MB。
1、设置键值
A、设置键值
set key value
set name "zhangsan"
B、设置键值及过期时间,以秒为单位
setex key seconds value
setex name 10 'zhangsan'
C、查看有效时间,以秒为单位
ttl key
ttl name
D、取消过期时间
persist key
persist name
E、只有在 key 不存在时设置 key 的值
setnx key value
setnx name 'a'
E、设置多个键值
mset key value [key value ……]
mset name 'zs' age 18
2、key的操作
A.根据键获取值,如果键不存在则返回None(null 0 nil)
get key
get name
B、根据多个键获取多个值
mget key [key ……]
mget name age
C、返回 key 中字符串值的子字符
getrange key start end
getrange name 0 4
D、将给定 key 的值设为 value ,并返回 key 的旧值(old value)
getset key value
getset name 'x'
3、运算
要求:值是字符串类型的数字
A、将key对应的值加1
incr key
incr age
B、将key对应的值减1
decr key
decr age
C、将key对应的值加整数
incrby key intnum
incrby age 10
D、将key对应的值减整数
decrby key intnum
decrby age 10
E、获取值长度
strlen key
strlen age
key 键的操作
A、查找所有的 key
keys *
B、判断键是否存在,如果存在返回1,不存在返回0
exists key
exists name
C、查看键对应的value类型
type key
type name
D、删除键及对应的值
del key [key ……]
E、设置过期时间,以秒为单位
expire key seconds
expire age 10
F、查看有效时间,以秒为单位
ttl key
H、以毫秒为单位返回 key 的剩余的过期时间
pttl key
I、移除 key 的过期时间,key 将持久保持
persist key
J、删除所有的key
flushdb 删除当前数据库中的所有
flushall 删除所有数据库中的key
K、修改 key 的名称(仅当 newkey 不存在时,将 key 改名为 newkey)
rename key newkey
L、将key移动到指定的数据库中
Move key db
move name 1 # 将name 移动到数据库1
M、随机返回一个key
randomkey
(2) hash
概述:hash用于存储对象
{
name:"tom",
age:18
}
Redis hash 是一个键值(key=>value)对集合。
1、设置
a、设置单个值
hset key field value
redis> hset myhash name lucky
(integer) 1
redis> HGET myhash name
"Hello"
b、设置多个值
hmset key field value [field value ……]
hmset myhash a 1 b 2 c 3
C 为哈希表 key 中的指定字段的整数值加上增量 increment
hincrby key field incrment
hincrby hh age 10
D 只有在字段 field 不存在时,设置哈希表字段的值
hsetnx key field value
hget hh name
2、获取
A、获取一个属性的值
hget key field
hget name field1
B、获取多个属性的值
hmget key filed [filed ……]
C、获取所有字段和值
hgetall key
D、获取所有字段
hkeys key
E、获取所有值
hvals key
F、返回包含数据的个数
hlen key
3、其它
A、判断属性是否存在,存在返回1,不存在返回0
hexists key field
hexists a x
B、删除字段及值
hdel key field [field ……]
hdel a x y z
C、返回值的字符串长度 起始版本 3.2
hstrlen key field
(3) 列表 list
概述:Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
1、设置
A、在头部插入
lpush key value [vlaue ……]
lpush demo 2 3`
将一个值插入到已存在的列表头部,列表不存在时操作无效
Lpushx key val
lpushx list 'a'
B、在尾部插入
rpush key value [vlaue ……]
rpush demo 2 1
为已存在的列表添加值
rpushx key val
rpushx mm 'a'
2、获取
A、移除并返回key对应的list的第一个元素
lpop key
lpop demo
B、移除并返回key对应的list的最后一个元素
rpop key
rpop demo
C、返回存储在key的列表中的指定范围的元素
lrange key start end
lrange demo 0 -1 #查看列表中的所有元素
注意:start end都是从0开始
注意:偏移量可以是负数
3、其它
A、裁剪列表,改为原集合的一个子集
ltrim key start end
ltrim demo 1 -1 #将索引为1 到 -1的元素裁剪出来
注意:start end都是从0开始
注意:偏移量可以是负数
B、返回存储在key里的list的长度
llen key
C、返回列表中索引对应的值
lindex key index
LINDEX mylist 0
四 集合 set
概述:无序集合,元素类型为String类型,元素具有唯一性,不重复
{ 'a','b'}
1、设置
A、添加元素
sadd key member [member ……]
sadd set 'a' 'b' 'c'
2、获取
A、返回key集合中所有元素
smembers key
smembers set
B、返回集合元素个数
scard key
scard set
C、移除并返回集合中的一个随机元素
spop key
spop set
D、返回集合中一个或多个随机数
srandmember key count
s set #返回一个随机元素
srandmember set 2 #返回2个随机元素
E、移除集合中一个或多个成员
srem key member1 [memkber2]
srem set 'd' 'b'ss
3、集合的其它操作
A、求多个集合的交集s
sinter key [key ……]
sinter m l #求集合l和集合m的交集
B、求多个集合的差集
sdiff key [key ……]
sdiff m l #求差集 注意比较顺序
D、判断元素是否在集合中,存在返回1,不存在返回0
sismember key member
sissmember m 'a' #集合m中是否存在元素'a'
五 有序集合 zset
概述:
a、有序集合,元素类型为String,元素具有唯一性,不能重复
b、每个元素都会关联一个double类型的score(表示权重),通过权重的大小排序,元素的score可以相同
1、设置
A、添加
zadd key score member [score member ……]
zadd zset 1 a 5 b 3 c 2 d 4 e
B、有序集合中对指定成员的分数加上增量 increment
Zincrby key increment mcfaember
zincrby zset 10 'a' #给a的权重上加10
2、获取
A、返回指定范围的元素
zrange key start end
zrange z1 0 -1
B、返回元素个数
zcard key
zcard z1
C、返回有序集合key中,score在min和max之间的元素的个数
zcount key min max
D、返回有序集合key中,成员member的score值
zscore key member
zscore l 'c' #s返回c的权重
E、当前集合所有的值和权重
ZRANGE key 0 -1 WITHSCORES
F、返回有序集合中指定分数区间内的成员,分数由低到高排序。
ZRANGEBYSCORE key min max [WITHSCORES][LIMIT offset count]
区间及无限
min和max可以是-inf和+inf,这样一来,你就可以在不知道有序集的最低和最高score值的情况下,使用ZRANGEBYSCORE这类命令。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGEBYSCORE myzset -inf +inf
1) "one"
2) "two"
3) "three"
redis> ZRANGEBYSCORE myzset 1 2
1) "one"
2) "two"
3、删除
A 从排序的集合中删除一个或多个成员
当key存在,但是其不是有序集合类型,就返回一个错误。
ZREM key member [member ...]
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREM myzset "two"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "three"
4) "3"
redis>
数据库:
默认在 数据库 0
select num 进行数据库的切换
select 1 #进入到数据库1
五、Redis 安全
注意:当前密码修改后如果服务重启则需要重新设定
我们可以通过 redis 的配置文件设置密码参数,这样客户端连接到 redis 服务就需要密码验证,这样可以让你的 redis 服务更安全。
实例
我们可以通过以下命令查看是否设置了密码验证:
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) ""
默认情况下 requirepass 参数是空的,这就意味着你无需通过密码验证就可以连接到 redis 服务。
你可以通过以下命令来修改该参数:
127.0.0.1:6379> CONFIG set requirepass "lucky"
OK
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) "lucky"
设置密码后,客户端连接 redis 服务就需要密码验证,否则无法执行命令。
语法
AUTH 命令基本语法格式如下:
127.0.0.1:6379> AUTH password
实例
127.0.0.1:6379> AUTH "lucky"
OK
127.0.0.1:6379> SET mykey "Test value"
OK
127.0.0.1:6379> GET mykey
"Test value"
六、Redis 数据备份与恢复
Redis SAVE 命令用于创建当前数据库的备份。
语法
redis Save 命令基本语法如下:
redis 127.0.0.1:6379> SAVE
实例
redis 127.0.0.1:6379> SAVE
OK
该命令将在 redis 安装目录中创建dump.rdb文件。
恢复数据
如果需要恢复数据,只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。获取 redis 目录可以使用 CONFIG 命令,如下所示:
redis 127.0.0.1:6379> CONFIG GET dir
1) "dir"
2) "/usr/local/redis/bin"
以上命令 CONFIG GET dir 输出的 redis 安装目录为 /usr/local/redis/bin。
Bgsave
创建 redis 备份文件也可以使用命令 BGSAVE,该命令在后台执行。
实例
127.0.0.1:6379> BGSAVE
Background saving started
七、Python操作redis
1、安装
pip install redis
导入
import redis
2、连接方式
redis提供了2个方法
- StrictRedis:实现大部分官方的命令
- Redis:是StrictRedis的子类,用于向后兼容旧版的redis。
官方推荐使用StrictRedis方法。
举例(普通连接):
import redis
# decode_responses=True 自动解码
r = redis.Redis(host='127.0.0.1',port=6379,password='123c456',db=0,decode_responses=True) #默认数据库为0
r = redis.StrictRedis(host='10.10.2.14',port=6379,password='123456',decode_responses=True)
连接池:connection pool
管理对一个redis server的所有连接,避免每次建立,释放连接的开销。默认,每个redis实例都会维护一个自己的连接池,可以直接建立一个连接池,作为参数传给redis,这样可以实现多个redis实例共享一个连接池。
举例(连接池):
pool = redis.ConnectionPool(host='127.0.0.1',port=6379,db=0,password='123456',decode_responses=True)
r = redis.Redis(connection_pool=pool)
lucky ↩︎
