1、正则表达式
基础实践
基础知识
基础知识
需求
我们之前的一些操作,很大程度上都是基于特定的关键字来进行实践的,尤其是面对一些灵活的场景,我们因为过于限定一些关键字,导致灵活性上表现比较差。在shell中,它其实有一种机制,能够让我们结合特定的符号,实现非常灵活的内容操作。
这就是正则表达式,正则表达式是用于描述字符排列和匹配模式的一种语法规则,通过它我们可以实现字符串的模式分割、匹配、查找及替换等操作。从而在各种业务逻辑的基础上,扩充数据层面的匹配,让脚本的适用性更大。
简介
REGEXP 全称Regular Expressions,它是我们通过一些字符所定义的’linux程序用来筛选文本的模式模板。linux相关程序(比如sed、awk、grep、等)在输入数据的时候,使用正则表达式对数据内容进行匹配,将匹配成功的信息返回给我们。
正则表达式被非常多的程序和开发语言支持:你能够想象到的编程语言,linux几乎所有编辑信息、查看信息的命令 等。
基本逻辑
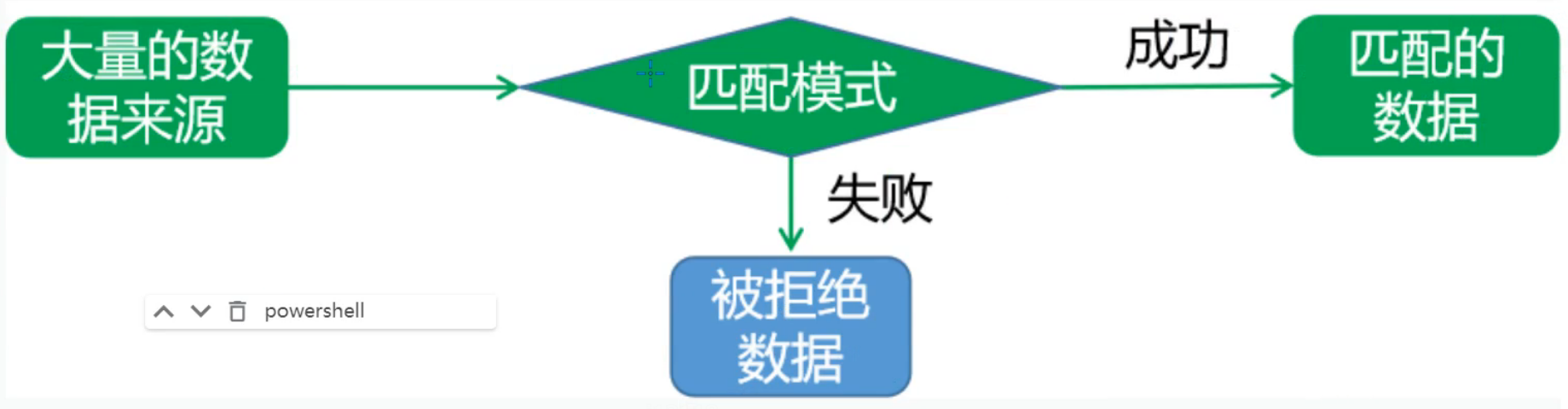
正则表达式模式,可以接收大量的数据来源,然后借助通配符、元字符、关键字等来标识数据流中的信息,将匹配成功的数据留存下来,为我们使用。
表达式分类
基本正则表达式:
BRE Basic Regular Expressions
- 借助于基本的属性信息实现内容的精准匹配
扩展正则表达式:
ERE Extended Regular Expressions
- 借助于扩展符号的能力,实现更大范围的信息匹配
简单实践
通配符和正则
1 正则表达式用来在文件中匹配符合条件的字符串,主要是目的是包含匹配。
- grep、awk、sed 等命令可以支持正则表达式。
2 通配符用来匹配符合条件的文件名,通配符是完全匹配。
- ls、find、cp 之类命令不支持正则表达式,可以借助于shell通配符来进行匹配。
. :匹配任意一个字符
* :匹配任意内容
? :匹配任意一个内容
[] :匹配中括号中的一个字符
通配符实践
创建基本环境
[root@localhost ~]# touch user-{1..3}.sh {a..d}.log
[root@localhost ~]# ls
a.log b.log d.log c.log
user-1.sh user-2.sh user-3.sh
*匹配任意字符
[root@localhost ~]# ls *.log
a.log b.log c.log d.log
[root@localhost ~]# ls u*
user-1.sh user-2.sh user-3.sh
?匹配一个字符
[root@localhost ~]# ls user?3*
user-3.sh
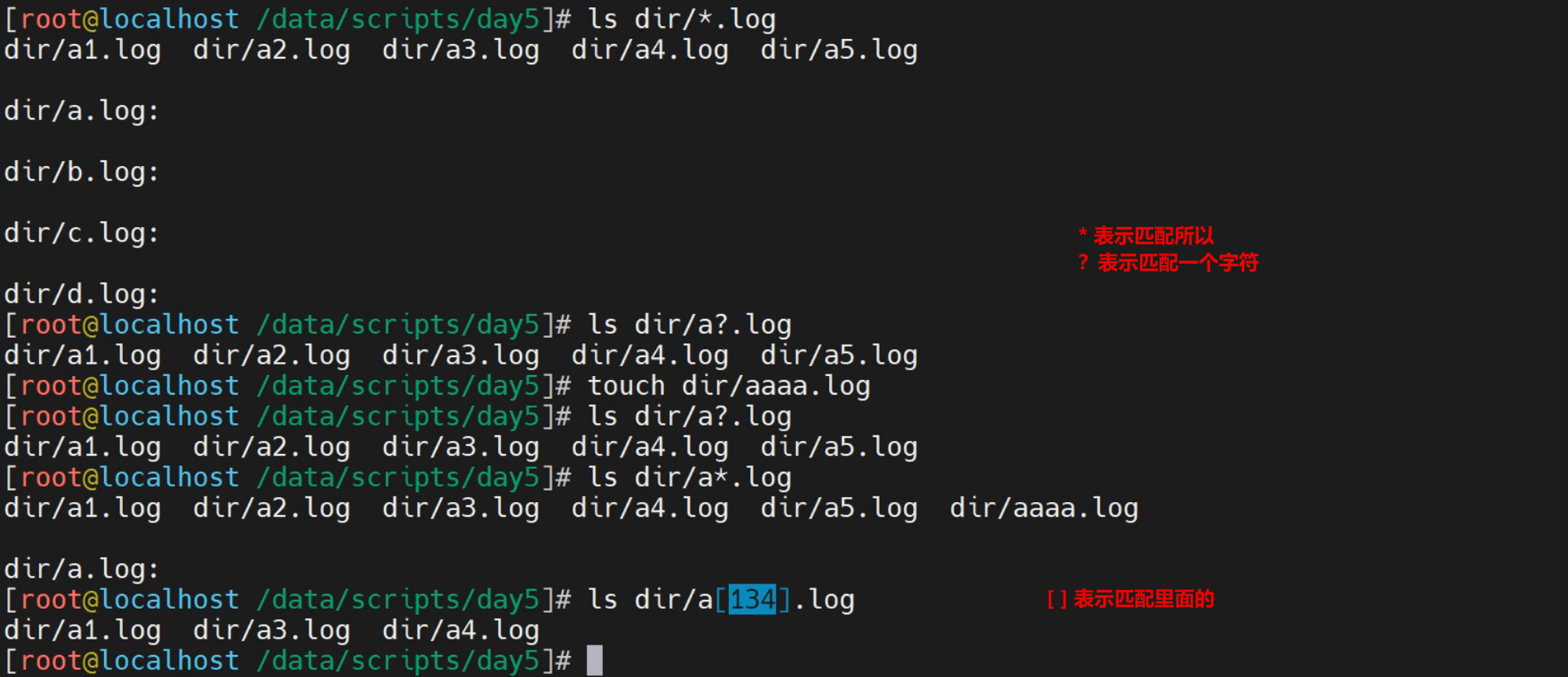
[]匹配中括号中的一个字符
[root@localhost ~]# ls user-[13]*
user-1.sh user-3.sh

字符匹配
基础知识
简介
正则存在的根本就是对数据的匹配,而数据基本上都是有字符组成的,而正则表达式提供了非常多的字符匹配表达式,常见的表达式模式有:
单字符匹配
. 匹配任意单个字符,当然包括汉字的匹配
[] 匹配指定范围内的任意单个字符
- 示例:[shuji]、[0-9]、[a-z]、[a-zA-Z]
[^] 匹配指定范围外的任意单个字符,取反的意思
- 示例:[^shuji]
| 匹配管道符左侧或者右侧的内容
简单实践
准备配置文件
[root@localhost ~]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id kpmaster
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 50
nopreempt
priority 100
advert_int 1
virtual_ipaddress {
192.168.8.100
}
}
实践1-单字符过滤
.过滤单个字符
[root@localhost ~]# grep 'st..e' keepalived.conf
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
[root@localhost ~]# grep 'ens..' keepalived.conf
interface ens33

实践2-范围单字符过滤
[] 过滤范围字符
[root@localhost ~]# grep 'i[a-z]t' keepalived.conf
interface ens33
virtual_router_id 50
advert_int 1
virtual_ipaddress {
[root@localhost ~]# grep 'i[a-n]t' keepalived.conf
interface ens33
advert_int 1
[root@localhost ~]# grep '[b-c]' keepalived.conf
global_defs {
vrrp_instance VI_1 {
interface ens33
[root@localhost ~]# egrep '[x-z]' keepalived.conf
priority 100

实践3-反向单字符过滤
只要包括的内容,都不要显示
[root@localhost ~]# grep '[^a-Z_ }{0-5]' keepalived.conf
! Configuration File for keepalived
192.168.8.100
实践4-过滤特定的字符范围
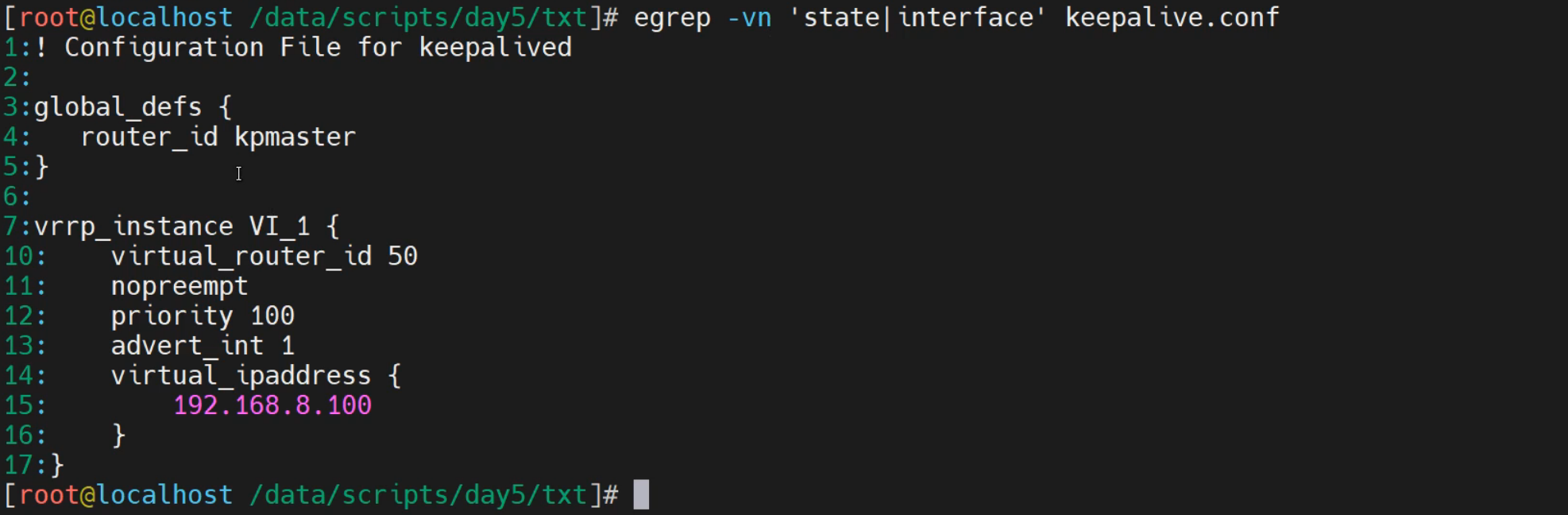
[root@localhost ~]# egrep 'state|priority' keepalived.conf
state MASTER
priority 100
[root@localhost ~]# egrep 'st|pri' keepalived.conf
router_id kpmaster
vrrp_instance VI_1 {
state MASTER
priority 100
锚定匹配
基础知识
简介
所谓的锚定匹配,主要是在字符匹配的前提下,增加了字符位置的匹配
常见符号
^ 行首锚定, 用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定,用于单词模式的右侧
\<PATTERN\> 匹配整个单词
注意:
单词是由字母,数字,下划线组成
简单实践
准备实践文件
[root@localhost ~]# cat nginx.conf
#user nobody;
worker_processes 1;
http {
sendfile on;
keepalive_timeout 65;
server {
listen 8000;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
}
}
实践1-行首位地址匹配
行首位置匹配
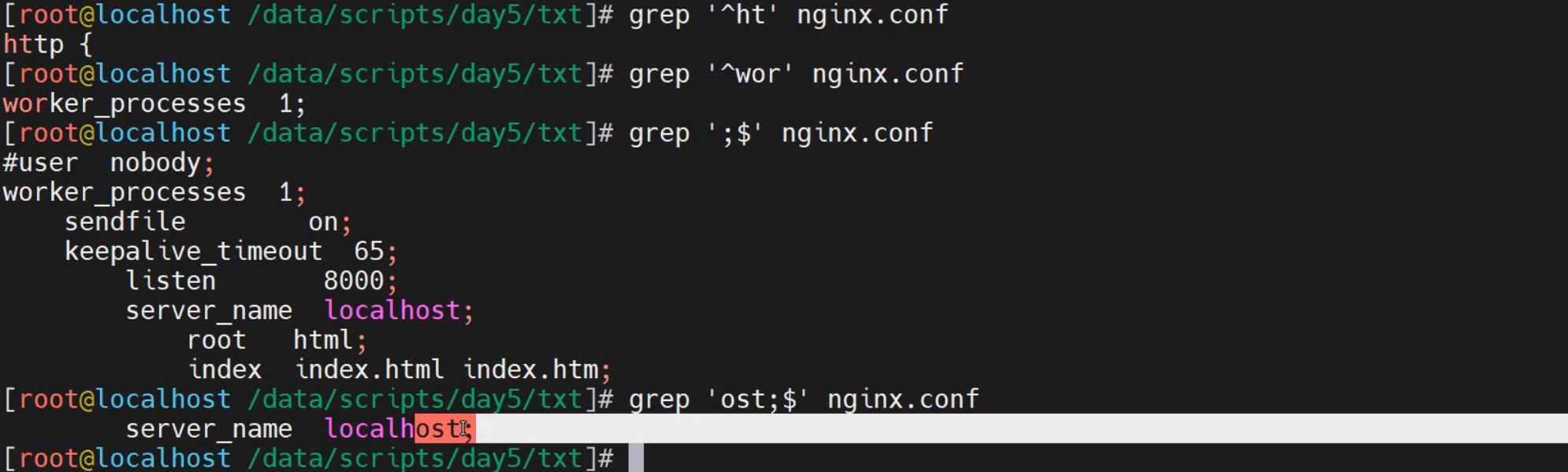
[root@localhost ~]# grep '^wor' nginx.conf
worker_processes 1;
行尾位置匹配
[root@localhost ~]# grep 'st;$' nginx.conf
server_name localhost;
实践2-关键字匹配
关键字符串匹配
[root@localhost ~]# grep '^http {$' nginx.conf
http {
[root@localhost ~]# grep '^w.*;$' nginx.conf
worker_processes 1;

实践3-空行匹配
空行匹配
[root@localhost ~]# grep '^$' nginx.conf
[root@localhost ~]# grep '^[[:space:]]*$' nginx.conf
# 反向过滤空行
[root@localhost ~]# grep -v '^$' nginx.conf
#user nobody;
worker_processes 1;
http {
sendfile on;
keepalive_timeout 65;
server {
listen 8000;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
}
}

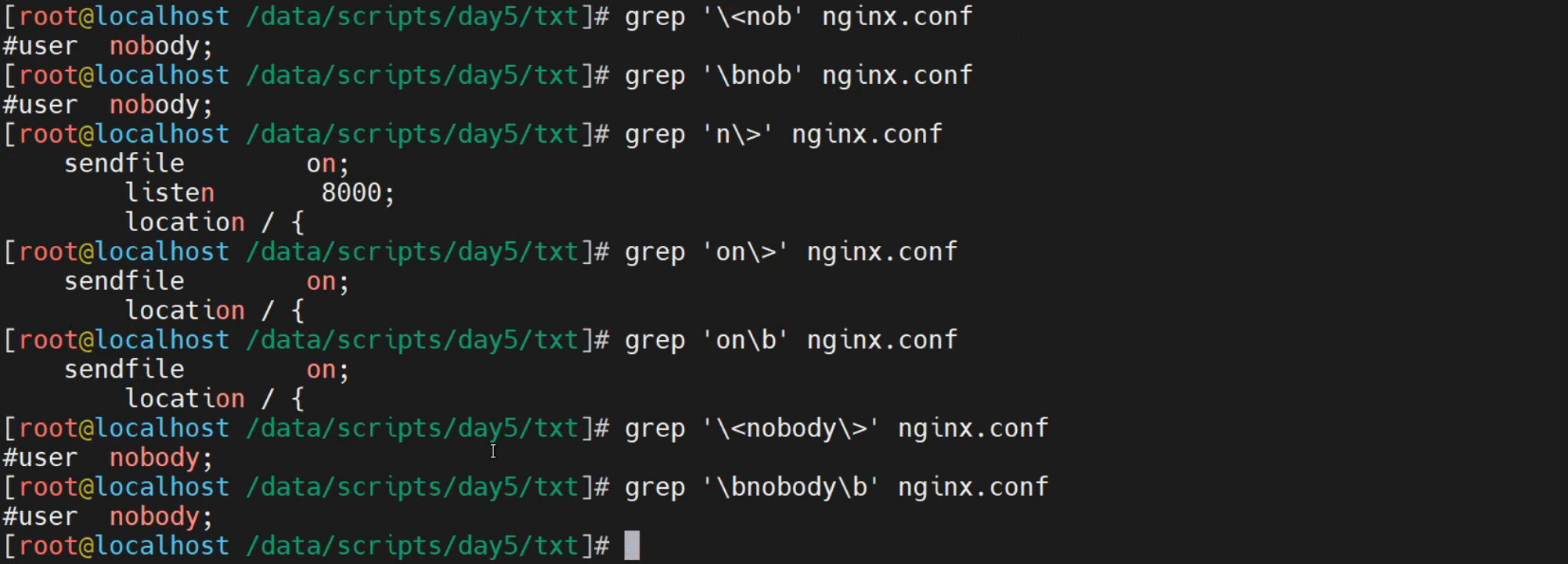
实践4-单词匹配
单词首部匹配
[root@localhost ~]# grep '\bloca' nginx.conf
server_name localhost;
location / {
[root@localhost ~]# grep '\<loca' nginx.conf
server_name localhost;
location / {
单词尾部匹配
[root@localhost ~]# grep 'ion\>' nginx.conf
location / {
[root@localhost ~]# grep 'ion\b' nginx.conf
location / {
单词内容匹配
[root@localhost ~]# grep '\<index\>' nginx.conf
index index.html index.htm;
[root@localhost ~]# grep '\<sendfile\>' nginx.conf
sendfile on;
分组符号
基础知识
简介
当我们使用正则模式匹配到的内容有很多项的时候,默认会全部输出。如果我们仅仅需要特定顺序的一个匹配内容的话,就用到我们这一节的知识点 -- 分组。
所谓的分组,其实指的是将我们正则匹配到的内容放到一个()里面
- 每一个匹配的内容都会在一个独立的()范围中
- 按照匹配的先后顺序,为每个()划分编号
- 第一个()里的内容,用 \1代替,第二个()里的内容,用\2代替,依次类推
- \0 代表正则表达式匹配到的所有内容
注意:
() 范围中支持|等字符匹配内容。从而匹配更多范围的信息
关于()信息的分组提取依赖于文件的编辑工具,我们可以借助于 sed、awk功能来实现
提示: sed -r 's/原内容/修改后内容/'
示例:
(M|m)any 可以标识 Many 或者 many
简单实践
准备配置文件
准备zookeeper的配置文件
[root@localhost ~]# cat zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/server/zookeeper/data
dataLogDir=/data/server/zookeeper/logs
clientPort=2181
server.1=10.0.0.12:2182:2183
server.2=10.0.0.13:2182:2183
server.3=10.0.0.14:2182:2183:observer
4lw.commands.whitelist=stat, ruok, conf, isro
实践1-分组信息匹配实践
获取zookeeper的集群相关信息
[root@localhost ~]# egrep '(server.[0-9])' zoo.cfg
server.1=10.0.0.12:2182:2183
server.2=10.0.0.13:2182:2183
server.3=10.0.0.14:2182:2183:observer
[root@localhost ~]# egrep '(init|sync)Limit' zoo.cfg
initLimit=10
syncLimit=5

实践2-信息的提取
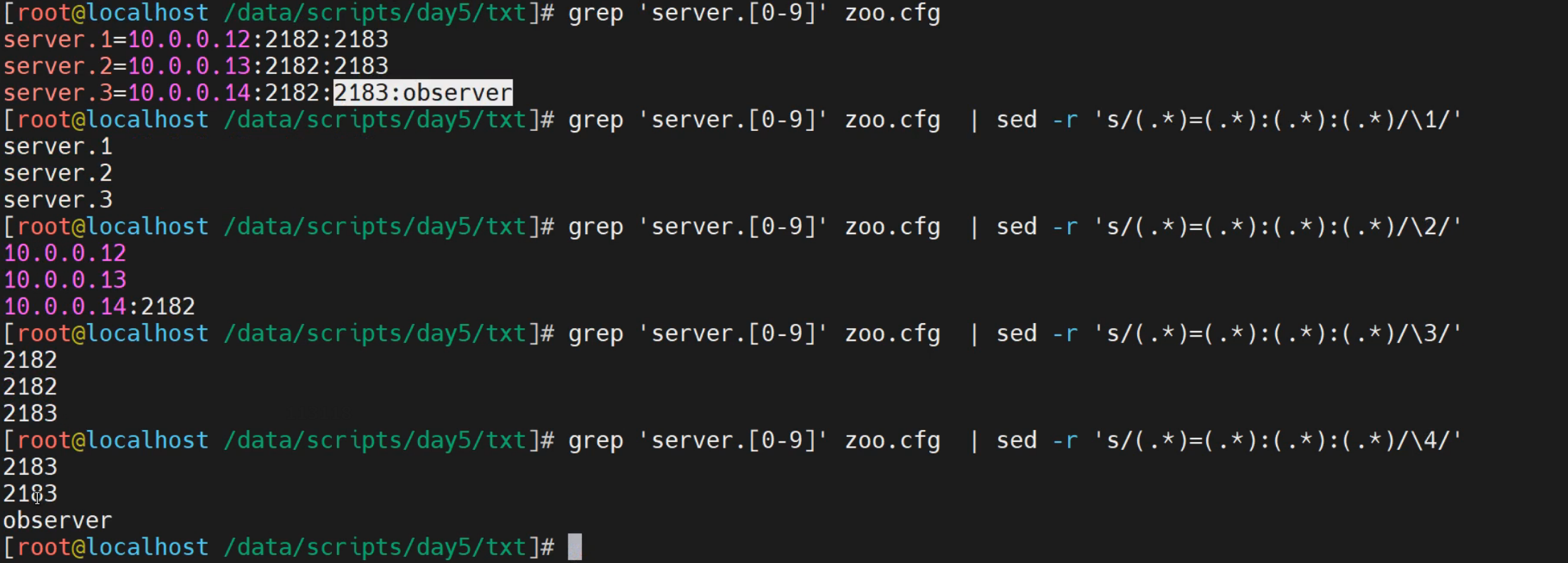
借助于sed的编辑文件功能,实现特定信息的提取
[root@localhost ~]# grep server.1 zoo.cfg | sed -r "s/(.*)=(.*):(.*):(.*)/\1/"
server.1
[root@localhost ~]# grep server.1 zoo.cfg | sed -r "s/(.*)=(.*):(.*):(.*)/\2/"
10.0.0.12
[root@localhost ~]# grep server.1 zoo.cfg | sed -r "s/(.*)=(.*):(.*):(.*)/\3/"
2182
[root@localhost ~]# grep server.1 zoo.cfg | sed -r "s/(.*)=(.*):(.*):(.*)/\4/"
2183
进阶知识
限定符号
基础知识
简介
所谓的限定符号,主要指的是,我们通过正则表达式匹配到内容后,前面内容重复的次数,常见的服号如下:
常见符号
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
? 匹配其前面的字符出现0次或1次,即:可有可无
+ 匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
{m} 匹配前面的字符m次
{m,n} 匹配前面的字符至少m次,至多n次
{,n} 匹配前面的字符至多n次,<=n
{n,} 匹配前面的字符至少n次
简单实践
准备文件
[root@localhost ~]# cat file.txt
ac
abbcd
abbbce
abbbbbc
abcf
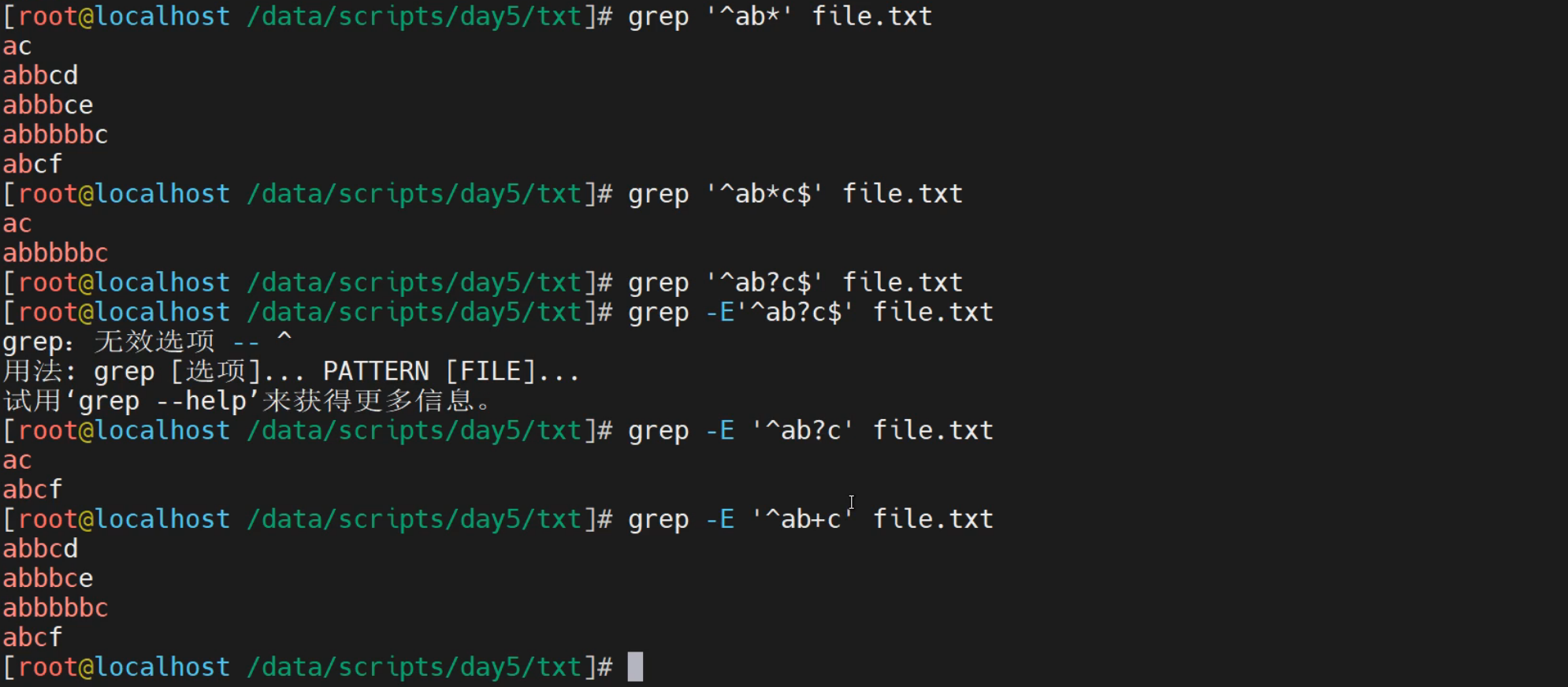
实践1-精确匹配
精确匹配 以a开头 c结尾 中间是有b或者没有b 长度不限的字符串
[root@localhost ~]# egrep "^ab*c$" file.txt
ac
abbbbbc
精确匹配 以a开头 c结尾 中间只出现一次b或者没有b的字符串
[root@localhost ~]# egrep "^ab?c$" file.txt
ac
精确匹配 以a开头 中间是有b且至少出现一次 长度不限的字符串
[root@localhost ~]# egrep "^ab+" file.txt
abbcd
abbbce
abbbbbc
abcf
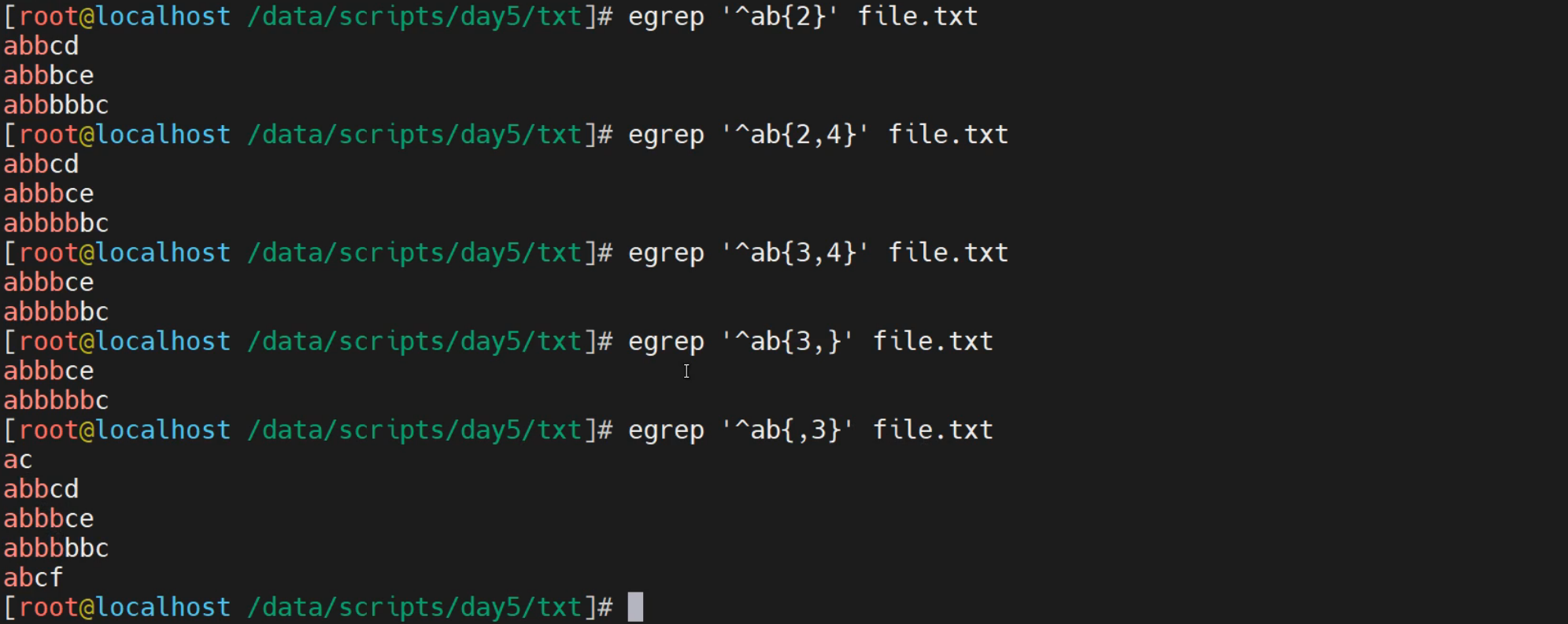
精确匹配 以a开头 中间是有b且至少出现两次最多出现四次 长度不限的字符串
[root@localhost ~]# egrep "^ab{2,4}" file.txt
abbcd
abbbce
abbbbbc
精确匹配 以a开头 中间是有b且正好出现三次的字符串
[root@localhost ~]# egrep "^ab{3}" file.txt
abbbce
abbbbbc
精确匹配 以a开头 中间是有b且至少出现两次的字符串
[root@localhost ~]# egrep "^ab{2,}" file.txt
abbcd
abbbce
abbbbbc
进阶知识
扩展符号
基础知识
简介
字母模式匹配
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
数字模式匹配
[:digit:] 十进制数字
[:xdigit:]十六进制数字
符号模式匹配
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
注意:
在使用该模式匹配的时候,一般用[[ ]],
- 第一个中括号是匹配符[] 匹配中括号中的任意一个字符
- 第二个[]是格式 如[:digit:]
属性模式匹配
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [\f\r\t\v]。
\S 匹配任何非空白字符。等价于 [^\f\r\t\v]
\w 匹配一个字母,数字,下划线,汉字,其它国家文字的字符,等价于[_[:alnum:]字]
\W 匹配一个非字母,数字,下划线,汉字,其它国家文字的字符,等价于[^_[:alnum:]字]
简单实践
准备文件
[root@localhost ~]# cat file1.txt
acd
abc
a_c
aZc
aZd
a c
a3c
精确匹配实践
以a开头c结尾 中间a-zA-Z0-9任意字符 长度为三个字节的字符串
[root@localhost ~]# egrep "^a[[:alnum:]]c$" file1.txt
abc
aZc
a3c
以a开头c结尾 中间是a-zA-Z任意字符 长度为三个字节的字符串
[root@localhost ~]# egrep "^a[[:alpha:]]c$" file1.txt
abc
aZc
以a开头c结尾 中间是0-9任意字符 长度为三个字节的字符串
[root@localhost ~]# egrep "^a[[:digit:]]c$" file1.txt
a3c
以a开头c结尾 中间是a-z任意字符 长度为三个字节的字符串
[root@localhost ~]# egrep "^a[[:lower:]]c$" file1.txt
abc
以a开头c结尾 中间是A-Z任意字符 长度为三个字节的字符串
[root@localhost ~]# egrep "^a[[:upper:]]c$" file1.txt
aZc
以a开头c结尾 中间是可打印符号 长度为三个字节的字符串
[root@localhost ~]# egrep "^a[[:print:]]c$" file1.txt
abc
a_c
aZc
a c
a3c
以a开头c结尾 中间是符号字符 长度为三个字节的字符串
[root@localhost ~]# egrep "^a[[:punct:]]c$" file1.txt
a_c
以a开头c结尾 中间是空格或者TAB符字符 长度为三个字节的字符串
[root@localhost ~]# egrep "^a[[:blank:]]c$" file1.txt
a c
[root@localhost ~]# egrep "^a[[:space:]]c$" file1.txt
a c
以a开头c结尾 中间是十六进制字符 长度为三个字节的字符串
[root@localhost ~]# egrep "^a[[:xdigit:]]c$" file1.txt
abc
a3c
目标检测
基础知识
需求
定制站点或目标主机的检测平台,在对站点域名和主机ip检测之前,判断输入的语法是否正确。
ip检测
定制ip地址文件
[root@localhost ~]# cat testip.txt
112.456.44.55
256.18.56.1
10.0.0.12
匹配ip地址
[root@localhost ~]# egrep '(^([1-9]|1[0-9]|1[1-9]{2}|2[0-4][0-9]|25[0-5])\.)(([0-9]{1,2}|1[1-9]{2}|2[0-4][0-9]|25[0-5])\.){2}([0-9]{1,2}|1[1-9]{2}|2[0-5][0-9]|25[0-4])$' testip.txt
10.0.0.12
网址检测
定制ip地址文件
[root@localhost ~]# cat testsite.txt
http://www.baidu.com
www.126.com
163.com
http.example.comcom
匹配ip地址
[root@localhost ~]# egrep '((http|https|ftp):\/\/)?(www\.)?([0-Z]+\.)([a-Z]{2,5})$' testsite.txt
http://www.baidu.com
www.126.com
163.com
简单实践
脚本内容
查看脚本内容
[root@localhost ~]# cat target_check.sh
#!/bin/bash
# 定制目标类型变量
target_type=(主机 网站)
# 定制检测ip地址格式的函数
check_ip(){
# 接收函数参数
IP=$1
ip_regex='(^([1-9]|1[0-9]|1[1-9]{2}|2[0-4][0-9]|25[0-5])\.)(([0-9]{1,2}|1[1-9]{2}|2[0-4][0-9]|25[0-5])\.){2}([0-9]{1,2}|1[1-9]{2}|2[0-5][0-9]|25[0-4])$'
# 判断ip地址是否有效
echo $IP | egrep "${ip_regex}" >/dev/null && echo "true" || echo "false"
}
# 定制网址的格式检测函数
check_url(){
# 接收函数参数
site=$1
site_regex='((http|https|ftp):\/\/)?(www\.)?([0-Z]+\.)([a-Z]{2,5})$'
# 判断网址地址是否有效
echo $site | egrep "${site_regex}" >/dev/null && echo "true" || echo "false"
}
# 定制服务的操作提示功能函数
menu(){
echo -e "\e[31m---------------确定检测目标类型---------------"
echo -e " 1: 主机 2: 网站"
echo -e "-------------------------------------------\033[0m"
}
# 目标主机检测过程
host_ip_check(){
read -p "> 请输入要检测的主机ip: " ip_addr
result=$(check_ip ${ip_addr})
if [ ${result} == "true" ];then
ping -c1 -W1 ${ip_addr} &> /dev/null && echo "${ip_addr} 状态正常" || echo "${ip_addr} 状态不可达"
else
echo "目标ip格式异常"
fi
}
# 目标站点检测过程
net_site_check(){
read -p "> 请输入要检测的网站地址: " site_addr
result=$(check_url ${site_addr})
if [ ${result} == "true" ];then
curl -s -o /dev/null ${site_addr} && echo "${site_addr} 状态正常" || echo "${site_addr} 状态异常"
else
echo "目标网址格式异常"
fi
}
# 定制帮助信息
Usage(){
echo "请输入正确的检测目标类型"
}
# 定制业务逻辑
while true
do
menu
read -p "> 请输入要检测的目标类型: " target_id
if [ ${target_type[$target_id-1]} == "主机" ];then
host_ip_check
elif [ ${target_type[$target_id-1]} == "网站" ];then
net_site_check
else
Usage
fi
done
脚本执行效果
[root@localhost ~]# /bin/bash target_check.sh
---------------确定检测目标类型---------------
1: 主机 2: 网站
-------------------------------------------
> 请输入要检测的目标类型: 1
> 请输入要检测的主机ip: 1aaa
目标ip格式异常
---------------确定检测目标类型---------------
1: 主机 2: 网站
-------------------------------------------
> 请输入要检测的目标类型: 1
> 请输入要检测的主机ip: 10.0.0.12
10.0.0.12 状态正常
---------------确定检测目标类型---------------
1: 主机 2: 网站
-------------------------------------------
> 请输入要检测的目标类型: 1
> 请输入要检测的主机ip: 10.0.0.13
10.0.0.13 状态不可达
---------------确定检测目标类型---------------
1: 主机 2: 网站
-------------------------------------------
> 请输入要检测的目标类型: 2
> 请输入要检测的网站地址: www
目标网址格式异常
---------------确定检测目标类型---------------
1: 主机 2: 网站
-------------------------------------------
> 请输入要检测的目标类型: 2
> 请输入要检测的网站地址: www.baidu.com
www.baidu.com 状态正常
---------------确定检测目标类型---------------
1: 主机 2: 网站
-------------------------------------------
> 请输入要检测的目标类型: 2
> 请输入要检测的网站地址: www.nihaoxxxxxx.com
www.nihaoxxxxxx.com 状态异常
---------------确定检测目标类型---------------
1: 主机 2: 网站
-------------------------------------------
> 请输入要检测的目标类型: ^C
[root@localhost ~]#
登录检测
基础知识
简介
在很多的应用交互页面,经常会出现一些用户输入的信息:
账号登录场景: 比如用户名、密码、手机号、邮箱之类的校验信息
手机号匹配
准备手机号文件
[root@localhost ~]# cat phone.txt
13412345678
135666666667
13a12345678
198123456
过滤真正的手机号
[root@localhost ~]# egrep '\<1[3-9][0-9]{9}\>' phone.txt
13412345678
邮箱地址匹配
定制邮箱地址文件
[root@localhost ~]# cat testemail.txt
admin@qq.com
1881111@gmail.eduedu
10.0.0.12
"shuji@qq.com
123_shuji@12306.cn
匹配邮箱地址
[root@localhost ~]# egrep "^[0-Z_]+\@[0-Z]+\.[0-Z]{2,5}$" testemail.txt
admin@qq.com
123_shuji@12306.cn
简单实践
脚本内容
查看脚本内容
[root@localhost ~]# cat register_login_manager.sh
#!/bin/bash
# 定制目标类型变量
target_type=(登录 注册)
# 定制普通变量
user_regex='^[0-Z_@.]{6,15}$'
passwd_regex='^[0-Z.]{6,8}$'
phone_regex='^\<1[3-9][0-9]{9}\>$'
email_regex='^[0-Z_]+\@[0-Z]+\.[0-Z]{2,5}$'
# 检测用户名规则
check_func(){
# 接收函数参数
target=$1
target_regex=$2
# 判断目标格式是否有效
echo $target | egrep "${target_regex}" >/dev/null && echo "true" || echo "false"
}
# 定制服务的操作提示功能函数
menu(){
echo -e "\e[31m---------------管理平台登录界面---------------"
echo -e " 1: 登录 2: 注册"
echo -e "-------------------------------------------\033[0m"
}
# 定制帮助信息
Usage(){
echo "请输入正确的操作类型"
}
# 管理平台用户注册过程
user_register_check(){
read -p "> 请输入用户名: " login_user
user_result=$(check_func ${login_user} ${user_regex})
if [ ${user_result} == "true" ];then
read -p "> 请输入密码: " login_passwd
passwd_result=$(check_func ${login_passwd} ${passwd_regex})
if [ ${passwd_result} == "true" ];then
read -p "> 请输入手机号: " login_phone
phone_result=$(check_func ${login_phone} ${phone_regex})
if [ ${phone_result} == "true" ];then
read -p "> 请输入邮箱: " login_email
email_result=$(check_func ${login_email} ${email_regex})
if [ ${email_result} == "true" ];then
echo -e "\e[31m----用户注册信息内容----"
echo -e " 用户名称: ${login_user}"
echo -e " 登录密码: ${login_passwd}"
echo -e " 手机号码: ${login_phone}"
echo -e " 邮箱地址: ${login_email}"
echo -e "------------------------\033[0m"
read -p "> 是否确认注册[yes|no]: " login_status
[ ${login_status} == "yes" ] && echo "用户 ${login_user} 注册成功" && exit || return
else
echo "邮箱地址格式不规范"
fi
else
echo "手机号码格式不规范"
fi
else
echo "登录密码格式不规范"
fi
else
echo "用户名称格式不规范"
fi
}
# 定制业务逻辑
while true
do
menu
read -p "> 请输入要操作的目标类型: " target_id
if [ ${target_type[$target_id-1]} == "登录" ];then
echo "开始登录管理平台..."
elif [ ${target_type[$target_id-1]} == "注册" ];then
user_register_check
else
Usage
fi
done
脚本执行效果
[root@localhost ~]# /bin/bash register_login_manager.sh
---------------管理平台登录界面---------------
1: 登录 2: 注册
-------------------------------------------
> 请输入要操作的目标类型: 2
> 请输入用户名: root12345
> 请输入密码: 12345678
> 请输入手机号: 13412345678
> 请输入邮箱: qq@123.com
----用户注册信息内容----
用户名称: root12345
登录密码: 12345678
手机号码: 13412345678
邮箱地址: qq@123.com
------------------------
> 是否确认注册[yes|no]: yes
用户 root12345 注册成功
[root@localhost ~]# /bin/bash register_login_manager.sh
---------------管理平台登录界面---------------
1: 登录 2: 注册
-------------------------------------------
> 请输入要操作的目标类型: 2
> 请输入用户名: admin123
> 请输入密码: 12345678
> 请输入手机号: 14456789090
> 请输入邮箱: qq@qq.com
----用户注册信息内容----
用户名称: admin123
登录密码: 12345678
手机号码: 14456789090
邮箱地址: qq@qq.com
------------------------
> 是否确认注册[yes|no]: no
---------------管理平台登录界面---------------
1: 登录 2: 注册
-------------------------------------------
> 请输入要操作的目标类型:
1
《三体》中有句话——弱小和无知不是生存的障碍,傲慢才是。
所以我们不要做一个小青蛙

 浙公网安备 33010602011771号
浙公网安备 33010602011771号