2、zookeeper原理
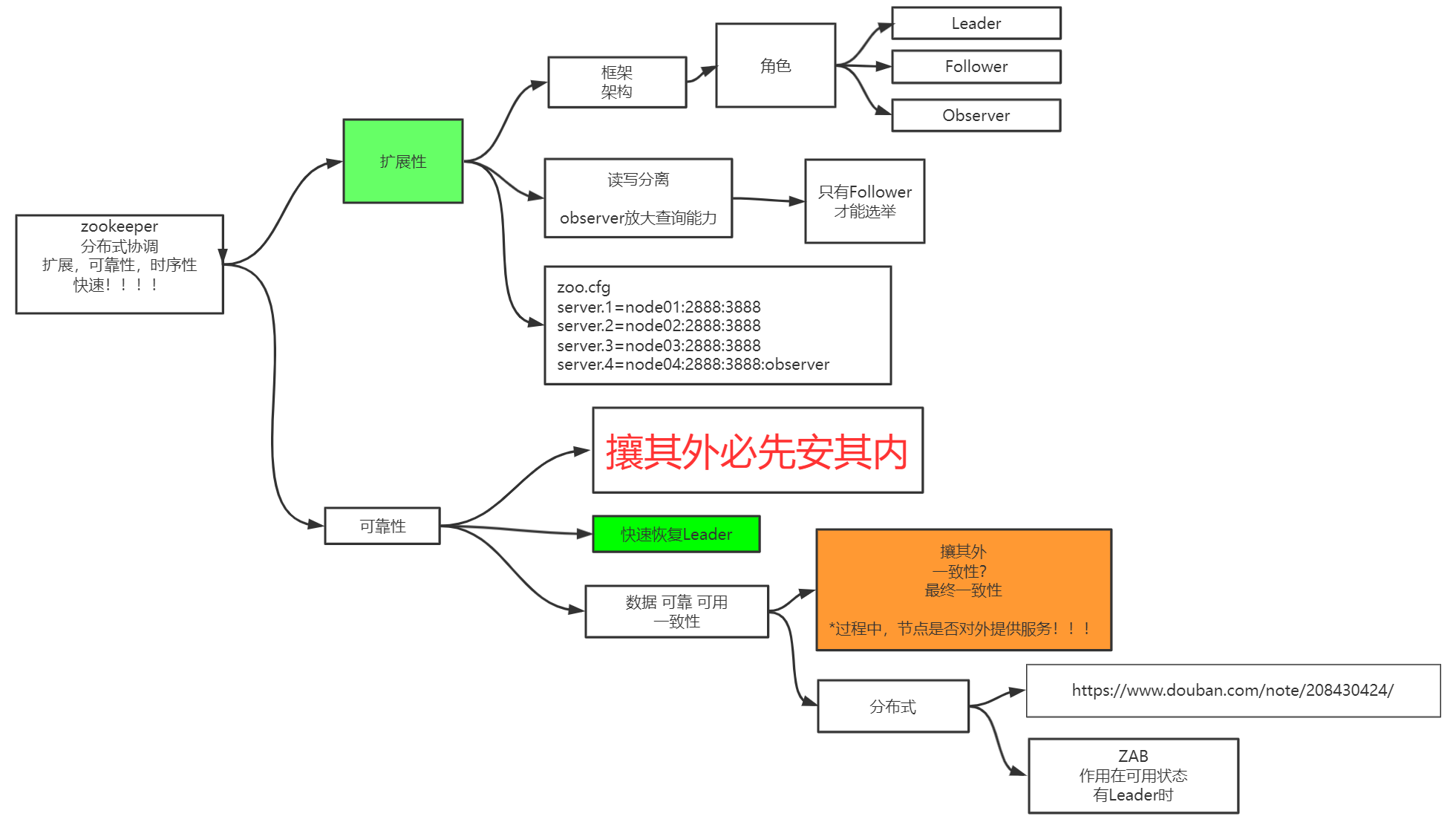
zookeeper是作为分布式协调的,它的特点就是扩展性和可靠性很好,然后保证了时序性,并且很快,响应快,并且服务挂掉后恢复的很快。
扩展性:
zookeeper分为三个角色,除了leader和follower以外,还有个角色是observer。
zookeeper还有个概念就是读写分离,写在leader节点上,读在follower或者observer上面,在集群中选举leader时候,只有follower才有选举权,observer是比follower更低级的角色。
为什么从节点要分follower和observer两种角色呢?
当一个zk集群的leader节点挂了以后,只有follower角色的节点才会进行选举出一个新的leader,observer只是在follower角色节点选出新的leader节点后,去追随leader节点,然后处理客户端的读请求。这样坐的原因很简单,比如一个国家要选举一个领导人,是3个人选举快?还是3亿人选举快?所以减少选举权的节点。
怎么配置用一个observer节点呢?
在配置文件zoo.cfg的最下面写配置集群的地址时候,后面加上:observer就好了,那它就是observer节点了。
可靠性:
把zookeeper的可靠性说明白,很简单的一句话:攘其外必先安其内。
什么意思呢?zk的可靠性是因为当它的leader节点挂了以后就不能用,但zk可以快速恢复出一个新的leader主节点。所以可以攘其外,因为可以保证可靠可用一致性。
在同步数据时候,节点是不应该对外提供服务的,因为不确定数据是不是最新的,所以要把数据从leader同步一下。
paxos
参考:https://www.douban.com/note/208430424/
zab——原子广播协议
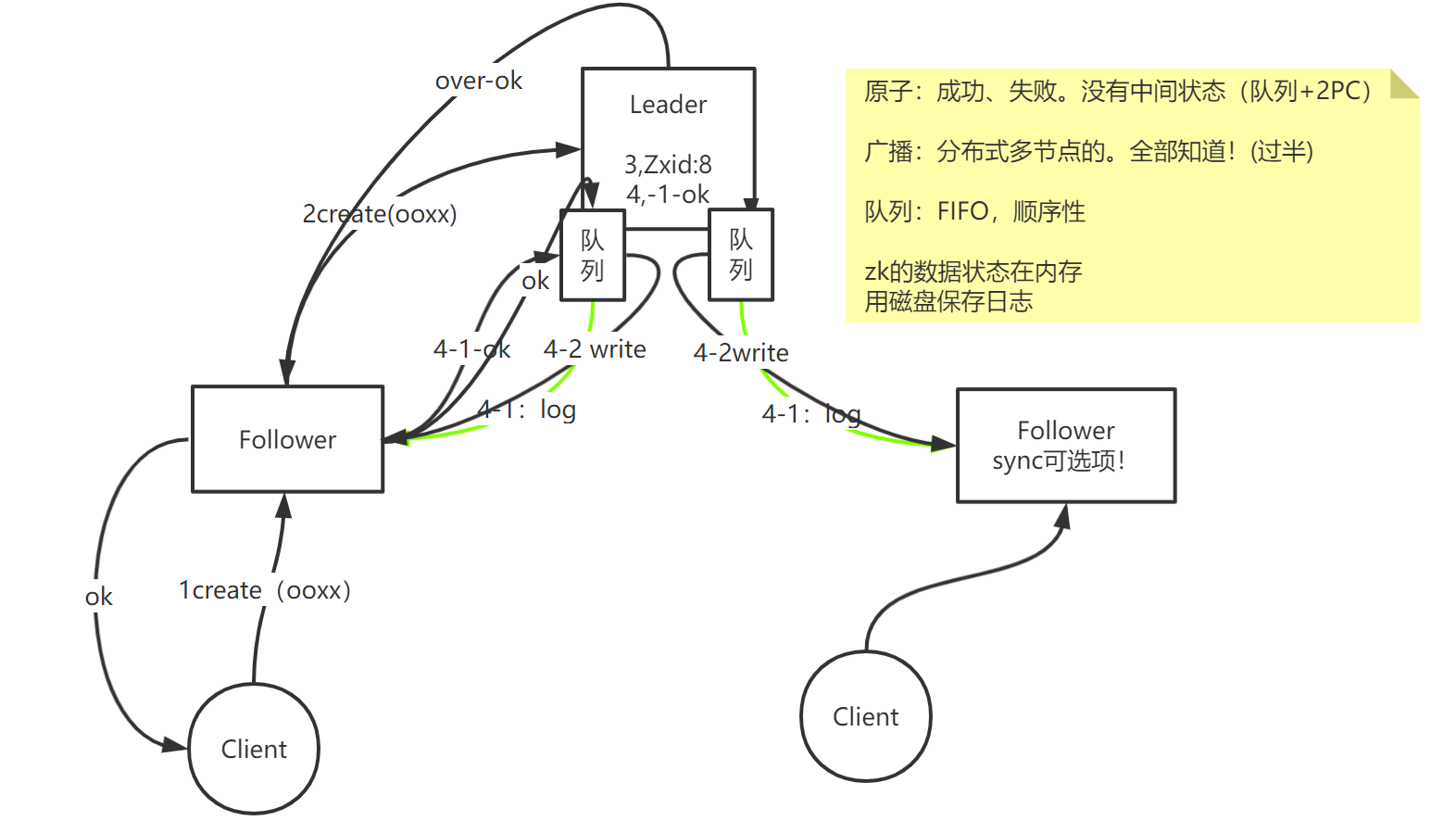
比如有个齐数的集群,1个leader和2个follower,
第1步:一个客户端发送一个写操作创建节点到1个follower,
第2步:这个follower肯定会转发给leader节点,
第3步:因为leader是个单节点的,所以传教事务id的递增,创建个事务id,比如是8,
第4步:会告诉这两个follower写日志的事,这时候使用了队列的概念,也就是说leader当中维护了队列,随着leader给follower发送写日志后,follower会给leader回送一个确认消息,leader收到确认ok的消息后,(如果这时候另一个follower不稳定,没有给leader回送确认消息,但其实因为过半了),再次执行写操作并同步给follower,这时候另一个follower后面会慢慢执行后面操作,所以是最终一致性,保证了数据同步。
leader执行完写操作后,会把结果返回给follower节点,最终返回给客户端,创建节点ok。
快速恢复
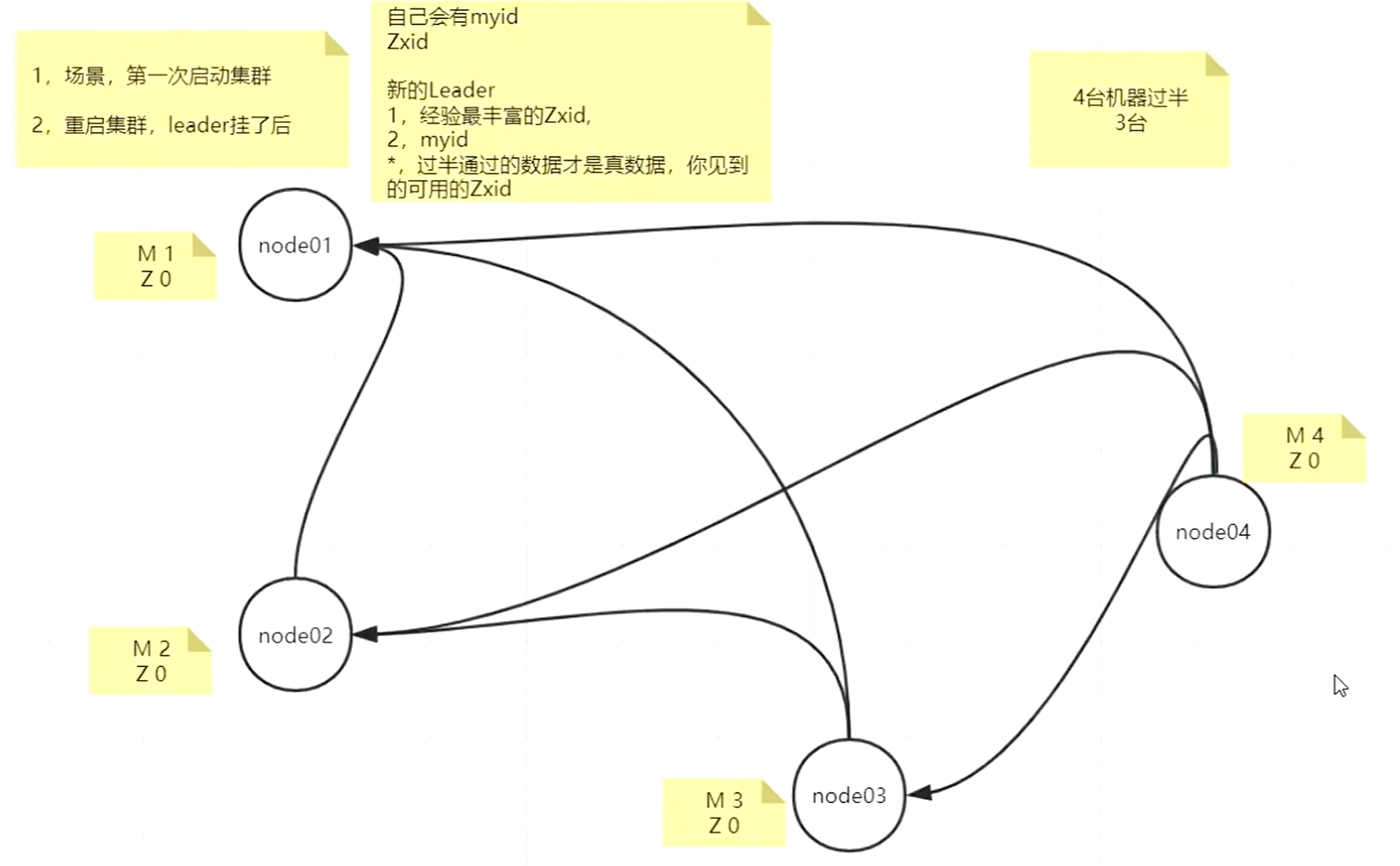
场景一
第一次启动时候,各节点都是没有数据没有状态的。
刚开始的时候,4台机器每个节点都有自己的myid,1到4这4个数,它们的事务id都是0,这4台机器上的节点不管什么顺序启动,只要3个节点启动时候,就会出现选举leader,先比较zxid事务id,如果zxid相同(刚开始都是0),再比较myid,所以刚开始启动时候,myid最大的那个节点就会成为leader。
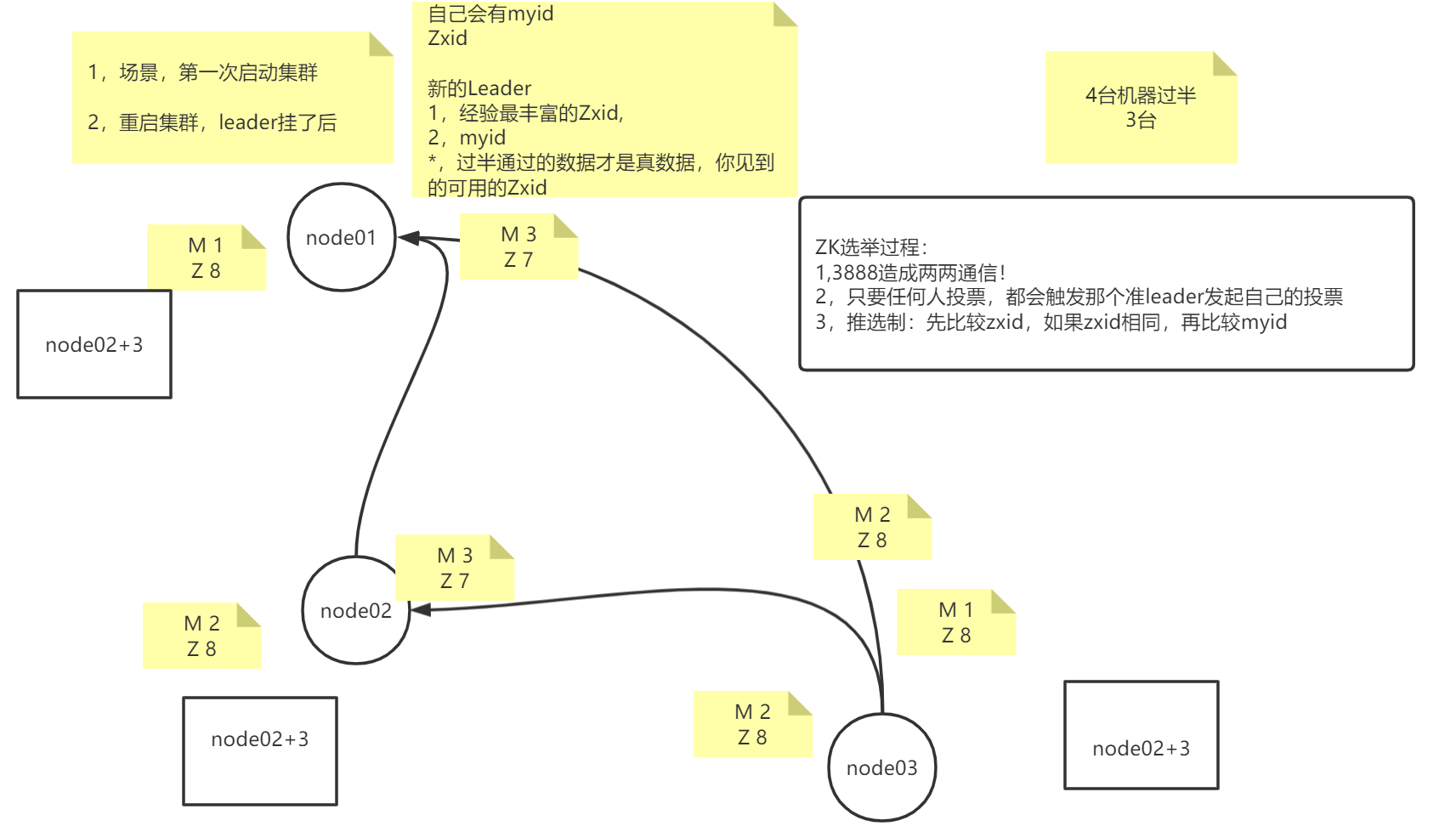
场景二
重启集群,重启时候各节点肯定都是有之前的数据,leader挂了之前,leader肯定也有写过的一些数据。
首先来说,每个节点都有自己的myid,选举新的leader时候,肯定选举数据最全的,通过事务id最高的,就说明是它了。
比如刚才场景一中的节点4挂了,要选举新的leader,节点3的事务id是7,节点1和节点2的事务id都是8,这时候比如节点3先发现节点4这个leader挂了,要进行选举了,它会把自己的事务id和myid发给节点1和节点2,节点1和节点8通过节点3的事务id和myid对比后,节点3的投票给否决了,然后节点1和节点2还会把自己的事务id和myid发回去给节点3,通过对比事务id和myid后,最后确定节点2有3个投票。所以还是根据先比较zxid,如果zxid相同,再比较myid的规则选举的。
watch——监控、观察
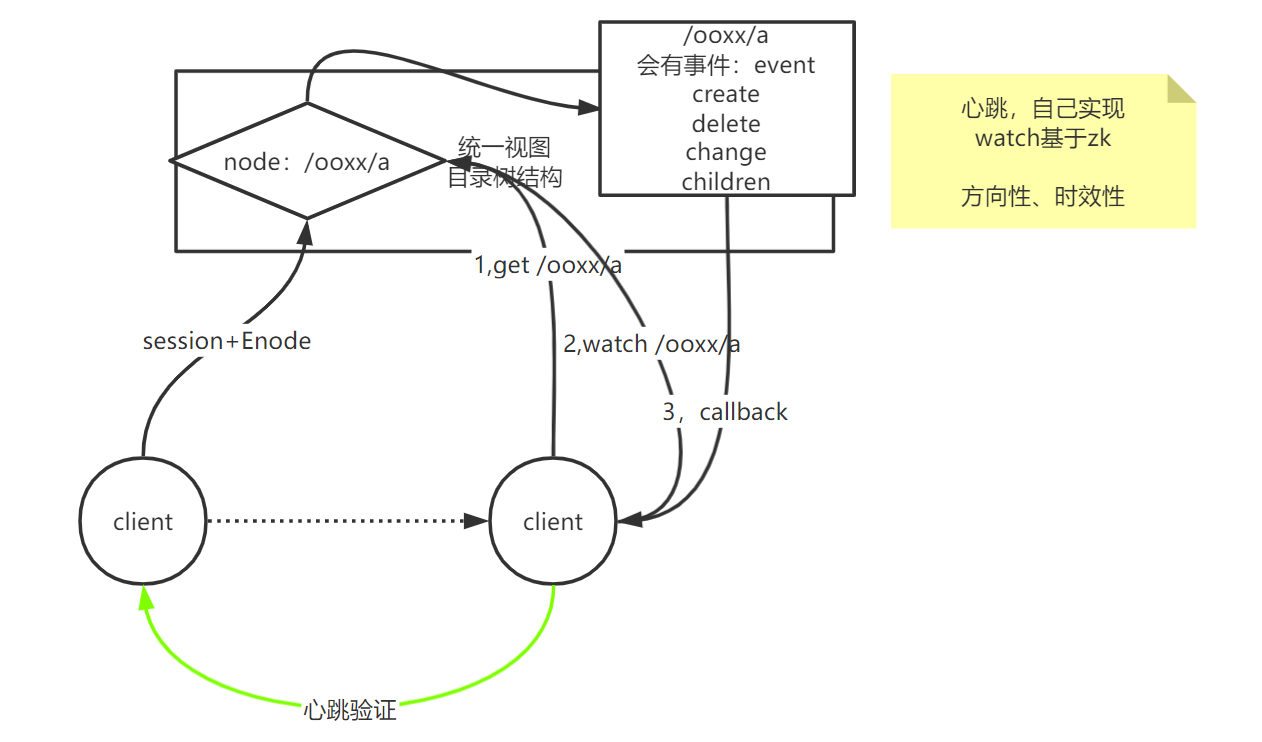
zookeeper进来的可以做到统一视图(所有人访问zk的每个节点得到的数据都是一样的),它的数据结构是目录树结构,有父级目录节点的关系,在这个基础上,zk又加了一个watch,比如有个客户端想要创建a在/ooxx目录下代表这个客户端,然后另一个客户端肯定是可以获取到这个a的,但如果第一个客户端挂掉了,第二客户端可能停掉服务或不和别人通信了。
其实这两个客户端之间是有点关系的,不是和zk直接有什么事,而是这两个客户端之间,因为zk是分布式协调服务,是协调别人的,而不是提供服务的。
如果这两个客户端服务在代码里互相没有绑定或监听,可能一个客户端服务挂了以后,另一个客户端服务不知道,所以zk解决了这件事。
比如第二个客户端获取了a,另外还可以观察这个a所在的目录有没有发生变化。其实这时候应该能想到客户端自己可以自己去实现另一个客户端的状态变化的,但问什么要zk里提供watch呢?
客户端自己实现心跳验证另一个客户端,和基于zk的watch区别就是,如果客户端自己去实现,总是不停的发送心跳包(比如每隔3秒),看另一个客户端是否正常,如果是基于zk的watch,比如第一个客户端连接了zk后,会产生一个session,然后基于这个session去创建一个临时节点,zk是这种目录树结构,所以节点的变化就会产生一些事件:增删改,所以第二个客户端只要watch监控了那个节点后,那个节点如果发生了一些变化,产生了事件,就可以回调通知到第二个客户端,并且这是时效性的,立马就能知道。如果是客户端发送心跳包给另一个客户端,中间还会延迟几秒,几秒后才知道原来另一个客户端早就已经挂了。
API
创建maven项目,导入依赖,版本要和zk的服务端版本一样
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.9</version>
</dependency>
测试类:
public class App {
public static void main(String[] args) throws Exception {
/*
参数1: 集群地址
参数2: 有效时间,单位毫秒
参数3: 传入watch, watch只发生在读事件里
第一类: session级别,跟path或node没有关系
*/
// 使用CountDownLatch原因是因为zk会异步直接返回ing..状态,这时还没连接好
CountDownLatch cd = new CountDownLatch(1);
ZooKeeper zk = new ZooKeeper("10.10.10.101:2181," +
"10.10.10.102:2181," +
"10.10.10.103:2181," +
"10.10.10.104:2181",
3000,
new Watcher() {
// 这个就是回调方法
@Override
public void process(WatchedEvent watchedEvent) {
// 可以获取状态,类型,路径等
Event.KeeperState state = watchedEvent.getState();
Event.EventType type = watchedEvent.getType();
String path = watchedEvent.getPath();
System.out.println(watchedEvent.toString());
switch (state) { // state可以匹配很多中
case Unknown:
break;
case Disconnected:
break;
case NoSyncConnected:
break;
case SyncConnected:
// 连接成功打印一句话
System.out.println("connected...");
cd.countDown();
break;
case AuthFailed:
break;
case ConnectedReadOnly:
break;
case SaslAuthenticated:
break;
case Expired:
break;
case Closed:
break;
}
switch (type) { // type也可以匹配很多种类型
case None:
break;
case NodeCreated:
break;
case NodeDeleted:
break;
case NodeDataChanged:
break;
case NodeChildrenChanged:
break;
case DataWatchRemoved:
break;
case ChildWatchRemoved:
break;
}
}
});
// 开始使用zk
// 使用zk时候确保正常连接成功,否则就阻塞
cd.await();
ZooKeeper.States state = zk.getState();
switch (state) {
case CONNECTING:
System.out.println("ing...");
break;
case ASSOCIATING:
break;
case CONNECTED:
System.out.println("ed...");
break;
case CONNECTEDREADONLY:
break;
case CLOSED:
break;
case AUTH_FAILED:
break;
case NOT_CONNECTED:
break;
}
// 创建节点:
/*
参数1: 创建目录
参数2: 往里面放数据,是二进制安全的,所以要给字节
参数3: 是否要限制等控制
参数4: 节点类型,比如:临时的,序列的等等
*/
String pathName = zk.create("/ooxx", "olddata".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
// 取数
Stat stat1 = new Stat();
byte[] data = zk.getData("/ooxx", new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println("getData: " + watchedEvent.toString());
try {
// 回调后再次取数
// 为true, 是default watch, 被重新注册, 这是new zk的那个watch
// 所以要用this
zk.getData("/ooxx", this, stat1);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, stat1);
System.out.println(new String(data));
// 修改数据, 会除法回调
Stat stat2 = zk.setData("/ooxx", "newData".getBytes(), 0);
// 再改一次, 看回调是否还会触发
Stat stat3 = zk.setData("/ooxx", "newData02".getBytes(), stat2.getVersion());
// 使用异步回调
System.out.println("async start");
zk.getData("/ooxx", false, new AsyncCallback.DataCallback() {
@Override
public void processResult(int i, String s, Object o, byte[] bytes, Stat stat) {
System.out.println("async call back");
System.out.println(o.toString());
System.out.println(new String(data));
}
}, "abc");
System.out.println("async over");
Thread.sleep(22222); // 阻塞,测试异步回调, 结束后才调用回调方法,打印数据
}
}
可以自己简单测试玩一下,验证一下原理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号