1. zookeeper介绍
官网:http://zookeeper.apache.org/
官网有描述:zookeeper是分布式协调服务,公开了一些简单的原语,我们可以构建这些原语,实现更高级的服务。
zookeeper允许分布式进程通过共享的分层命名空间相互协调,意思说的是zookeeper的数据模型和分层命名空间。
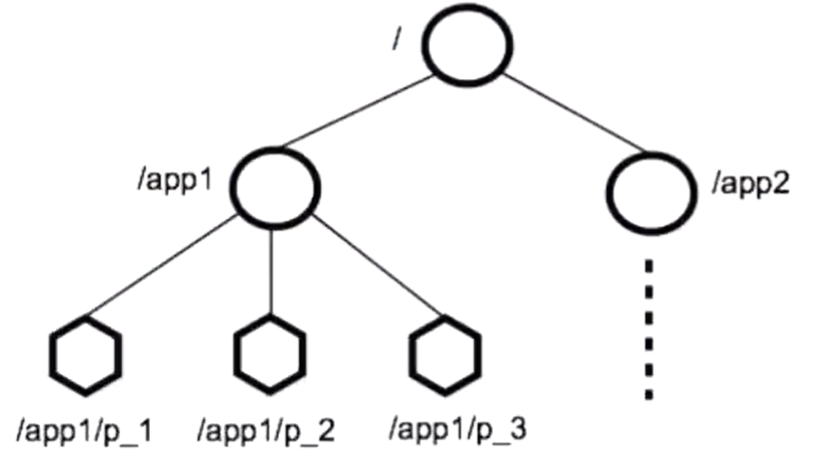
它是类似于文件系统,比如redis的数据模型就是key-value键值对的,zookeeper是这种文件系统,有层次结构,命名空间指的是根节点下面的子节点,比如app1、app2,分别表示不同的服务,就不会造成在同一目录,而是都有自己的子目录,就不会造成数据混乱,
zookeeper也可以启动多个搭建成一个集群,集群要不是主从模式的,要不是无主模型的,如果要在集群中存数据的话,要不就是复制集群,要不就是分片集群,zookeeper现在看来是复制集群,
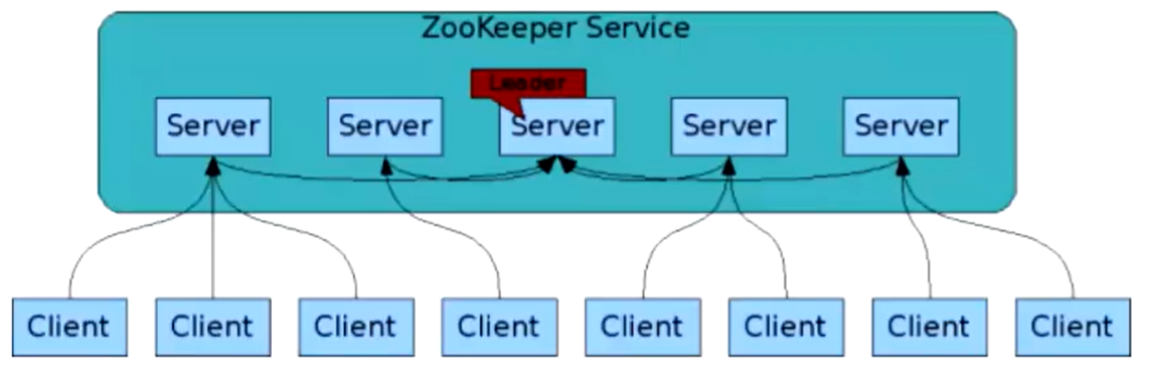
如图可以看出,zookeeper集群中有个服务是leader,说明是主从模式的集群,既然是主从集群,必然要先联想到一个问题,主节点是单点的,万一主节点挂了怎么办,是不是需要一个引入一个新的技术来解决这个问题。
可以从图中看出来,客户端可以连接任意的zookeeper服务,但是follower只能读,写的话要必须给到leader节点,那leader肯定会挂的场景,zookeeper会有快速修复的的作用。
所以zookeeper中有2种状态:
- 可用状态
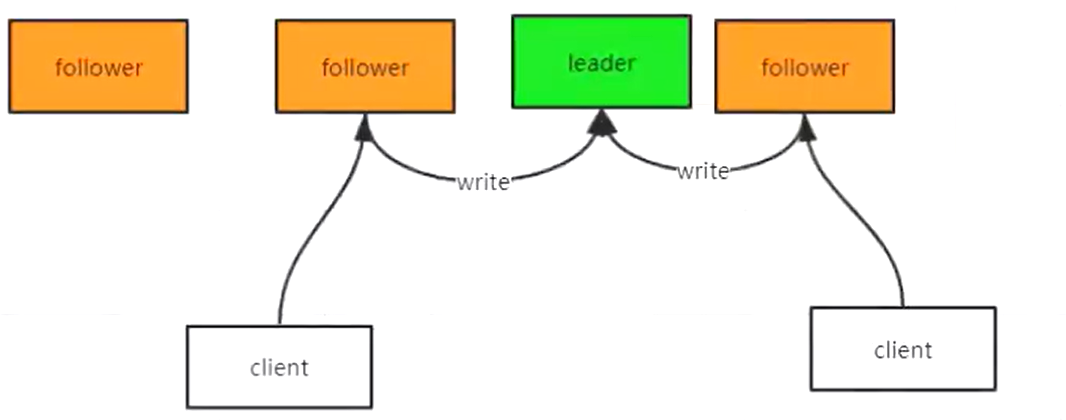
- 不可用状态
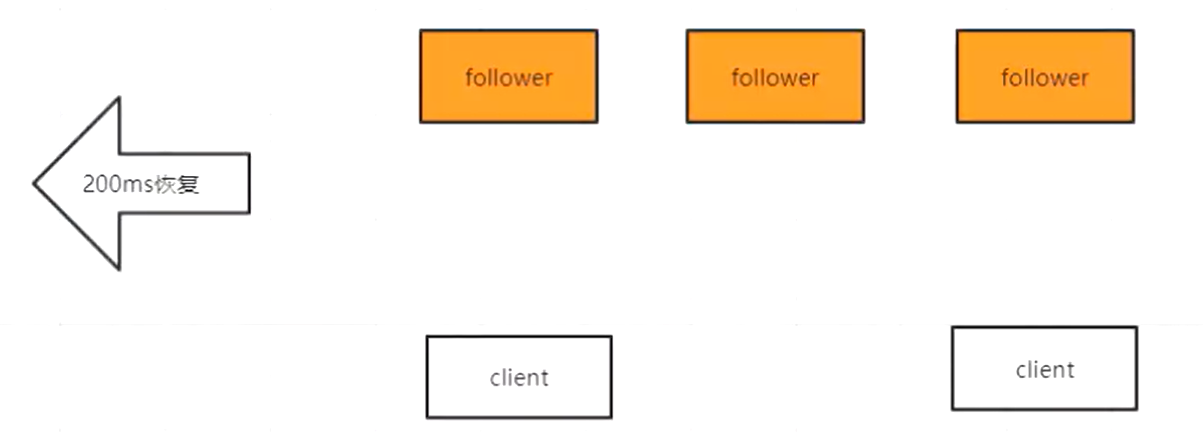
不可用状态恢复到可用状态应该越快越好
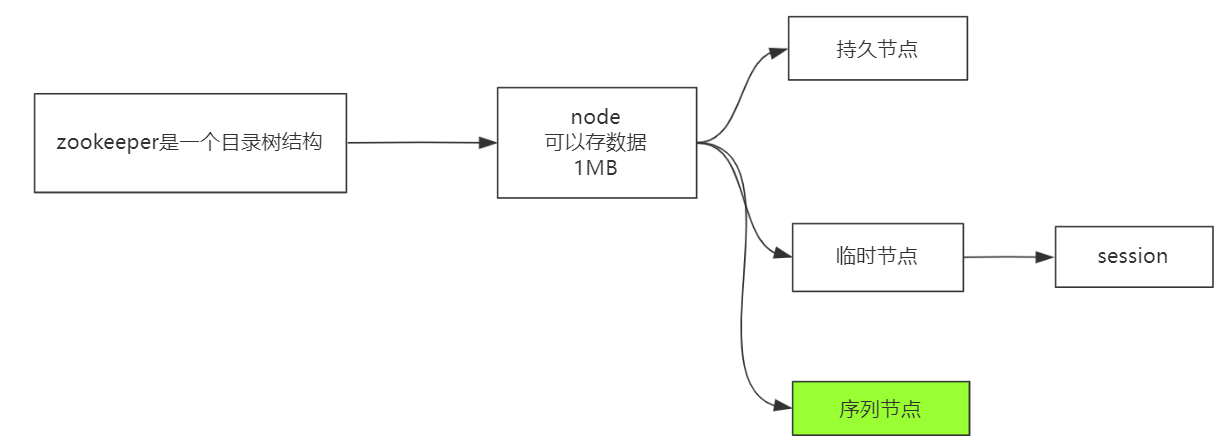
zookeeper本来就是目录树结构的概念,当然每个节点也是可以存数据的,节点可以分为持久节点和临时节点的概念,每个客户端连接到zookeeper时候肯定会产生session来代表客户端,临时节点就是依赖于session的概念,为啥要有临时节点的概念呢?什么情况下使用呢?
如果在使用zookeeper时候,建立了一个session会话,在里面创建了一把锁,(在redis中,如果加了一把锁后执行的操作,我们要给锁加上过期时间,但是可能需要执行时长超过了锁的时长,所以要使用多线程重新给锁设置时长,所以对连接的客户端来说是很麻烦的),如果是用zookeeper中session的概念的话,比如会话还在的话,说明还在锁着,如果释放锁了,session就会消失,这个临时节点也就消失。
序列节点的概念,不管是临时节点还是持久节点,也可以有序列号的,排序的效果。
保证
ZooKeeper 非常快速且非常简单。但是,由于它的目标是成为构建更复杂服务(例如同步)的基础,因此它提供了一组保证。这些都是:
- 顺序一致性: 来自客户端的更新将按照它们发送的顺序应用。(主节点执行写操作会排号)
- 原子性: 更新成功或失败。没有部分结果。(数据在主节点写,主节点肯定会把数据同步其他从节点,但是如果使用强一致性,肯定会造成服务不能高可用,既然zookeeper是高可用的,所以它肯定使用的最终一致性)
- 单一系统映像: 客户端将看到相同的服务视图,而不管它连接到的服务器如何。即,即使客户端故障转移到具有相同会话的不同服务器,客户端也永远不会看到系统的旧视图。(客户端不管连接哪个节点都可以查找相应的数据)
- 可靠性: 应用更新后,它将从那时起持续存在,直到客户端覆盖更新。(可以持久化,所以保证可靠性)
- 及时性: 系统的客户视图保证在一定的时间范围内是最新的。(最终一致性的概念,说的是一定时间内是最新的,而不是立刻就是最新的)
搭建集群
把压缩包上传到服务器解压,然后进入bin目录,可以查看它的启动脚本
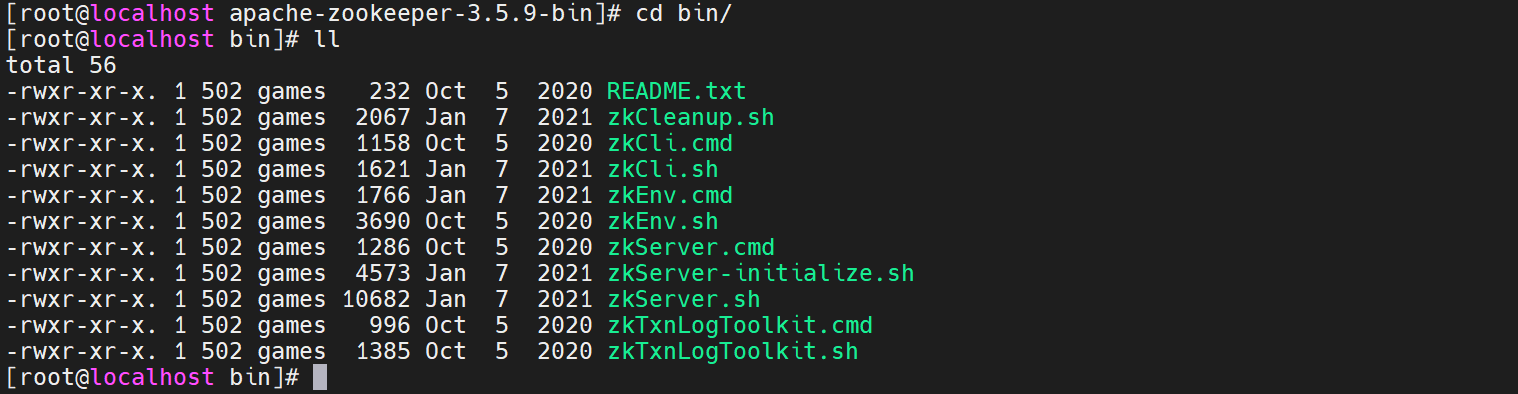
到conf目录,复制zoo_sample.cfg 改名字为zoo.cfg
修改zoo.cfg 内容
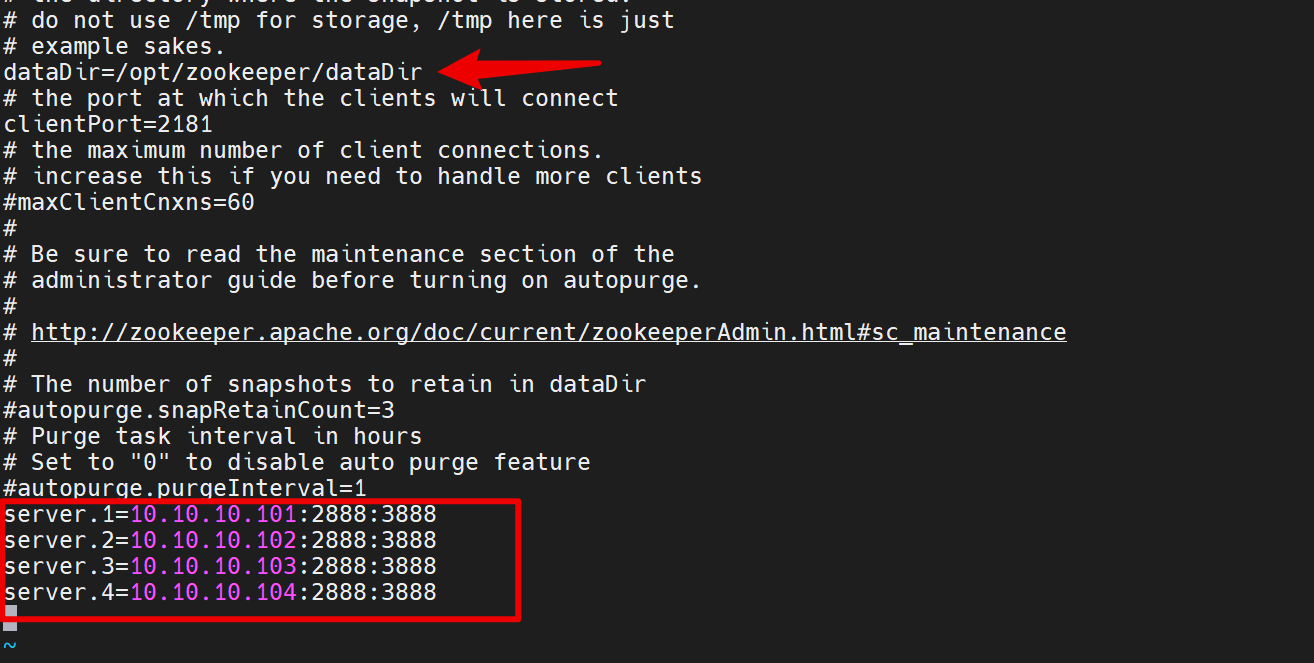
配置持久化数据的输出位置
配置每个节点,需要自己手动添加进来
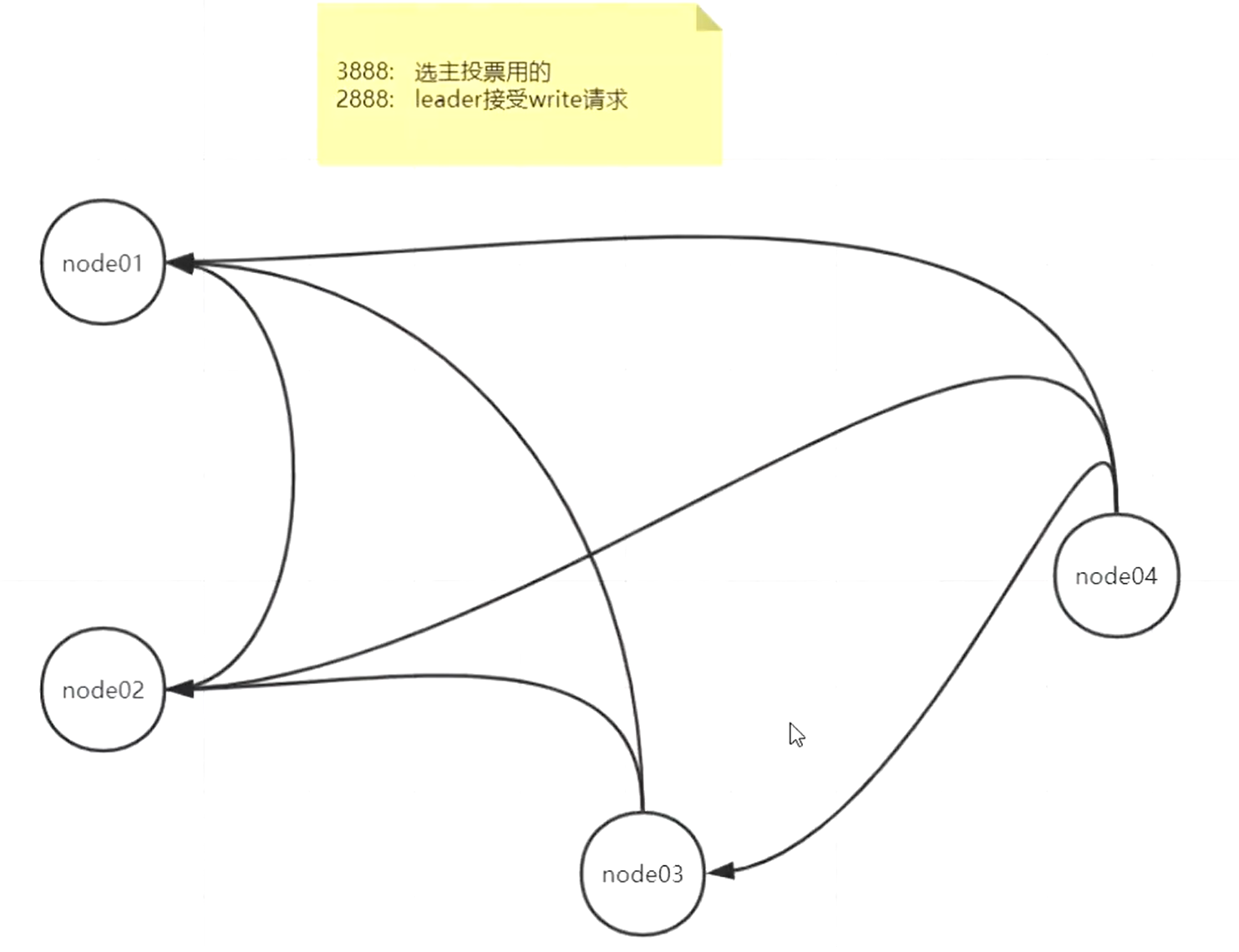
3888端口是zookeeper每个节点来进行通讯的,来选举新的leader节点
选举了新的leader节点后,其他节点是通过2888这个端口来进行通信的
添加数据持久化的目录

添加一个myid文件,里面只写了数字1,每个节点都写一个序号

拷贝配置好的文件到其他机器

然后到第二台机器上,
配置文件都是一样的,把myid给改成2

按照这个方法,给第三台机器和第四台机器也给传送文件,分别把myid改成3和4
修改环境变量vi /etc/profile,找到最下面,添加zookeeper配置

然后使用. /etc/profile或者source /etc/profile加入到内存,

这样的话不管在任何地方,输入zk后,按TAB键就可以提示相应的指令
配置文件是死的,给其他机器上都分发一下配置文件

然后给每个机器上都执行source /etc/profile,每个机器上都可以在任何地方执行zk的相应指令

运行集群
开始运行zk集群
每个节点都启动zk,使用命令zkServer.sh start-foreground启动zk,这样会打印日志在前台阻塞的方式启动
先启动3个机器上的zk,启动前几个机器的zk有报错是正常的,会报错连接错误,因为是集群,其他机器上的zk还没启动时候,肯定连接不上,就会报错
启动3个机器上的zk后,新开窗口查看这3个zk的状态,使用zkServer.sh status
发现myid文件是1和2的机器,节点是follwer

第3个机器的zk状态是leader

因为3个机器已经符合了过半选举的机制,所以会出来zk的节点状态
这时候去启动第4个机器的zk,然后查看状态,也是follwer,
因为已经有了leader角色,所以后面再起来的zk,就是你的myid更大,也只能追随leader节点,然后把数据从leader节点拷贝过来
如果这时候把第3个机器的leader给干死呢?
直接Ctrl + c 把第3个机器的zk给关掉,就会发现这时候因为第4个机器的myid比较大,并且数据可能也比较完整,所以第4个机器的zk变成了leader
客户端连接
启动zk集群后,随便一个机器上使用命令zkCli.sh直接回车,就可以进入客户端连接模式,
然后输入help查看客户端命令的使用
然后就可以自己测试玩了
zookeeper可以做些什么
- zookeeper可以做统一配置管理:所有的分布式客户端只要记住一个节点,它里面肯定有个1M的数据。
- 分组管理:通过path结构,父子级的概念
- 统一命名:通过事务id的序列
- 同步机制:通过临时节点实现
所以现在再看来分布式锁,用zookeeper的临时节点的特性来做一个分布式锁,再合适不过了,
并且可以给一个父节点下创建多个临时节点,这些临时节点肯定都有自己的事务id吧,后面的临时节点在业务逻辑上去依赖于前面的临时节点的分布式锁,这样就可以形成一个锁的队列。
并且可以用zk去做选举,让多个节点去抢同一把分布式锁,谁抢到了谁就是leader节点
使用命令netstat -natp | egrep '(2888|3888)'查看第1个机器的网络连接,这个命令是使用正则匹配只有2888和3888的相关的网络

可以看到有一个3888的网络时LISTEN状态的,因为要一直监听有没有新的节点会连接到集群里,然后其他3个机器的各个端口号和3888端口进行连接,
另外这台机器上还专门起了一个端口和其他机器2888端口连接了,因为这个2888的端口时leader节点
然后使用命令netstat -natp | egrep '(2888|3888)'在每个机器上都查看一下网络,会发现,每个机器上的网络连接整理后,每个节点都是可以跟其他节点连接到了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号