5. redis常见问题
击穿
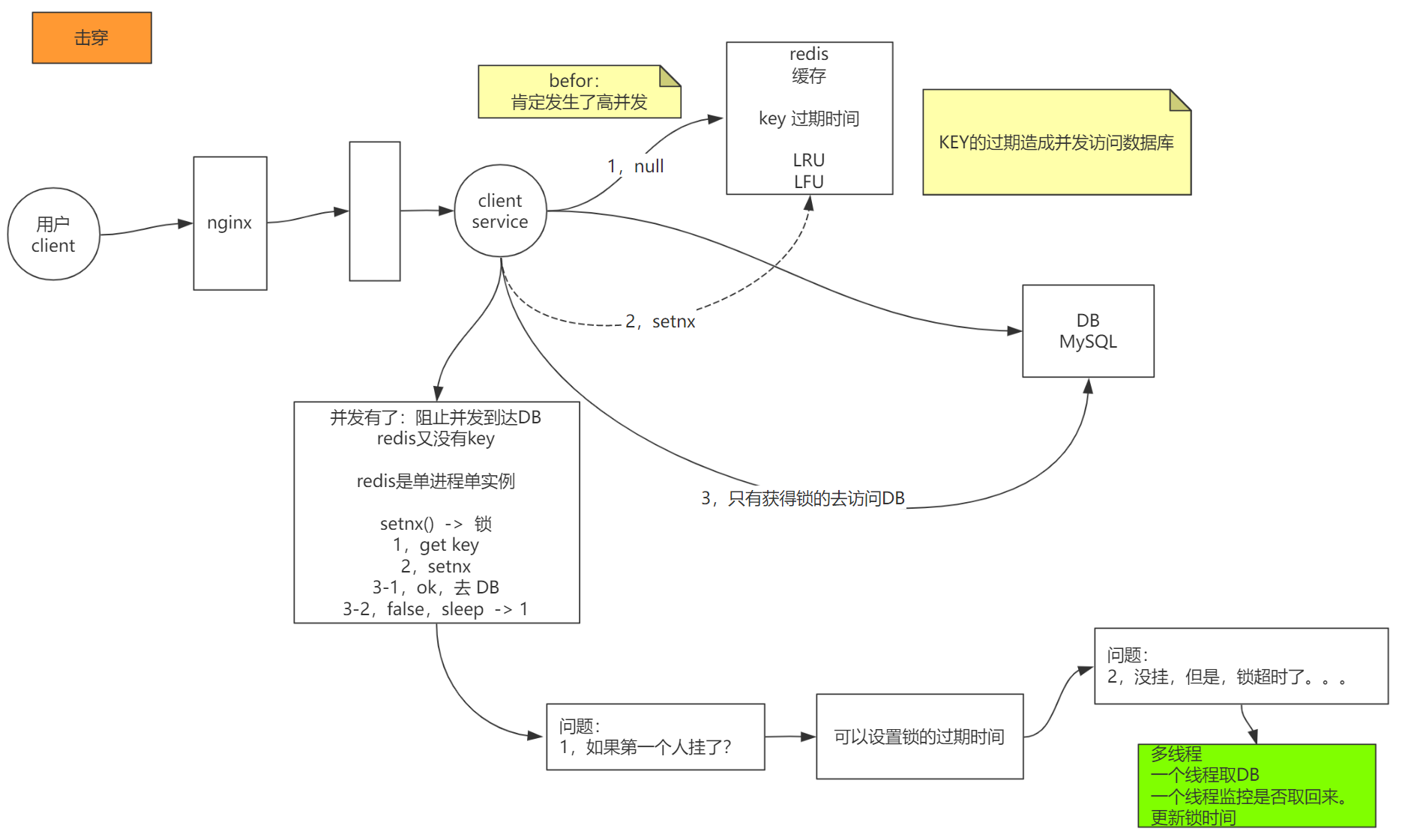
当用户请求到用户的服务端时候,服务要去查询redis,如果redis里没有对应的数据,(或者key的有效时间到了,或者通过LRU算法把数据清楚了)要去数据库查找了。
但是就这么巧,这时候发生了高并发,同时都去请求这一个被删除的key了。
所以解决思路就是:发生了并发,要阻止直接请求到数据库。
因为redis是单线程的,它没有其他线程做什么处理,所以它的做法是这样的:
比如一堆线程排队请求redis,当第一个线程请求发现没有这个key,添加一个锁,给了有效时间,然后它再去请求数据库。给到锁以后,后面的线程当然都会失败,然后这些线程过一小会儿时间再去取数据。
如果第一个线程执行时候宕机了咋办?
设置锁的过期时间,等到时间过了以后,还是一样的逻辑,再去加锁。
那锁的时间多久合适?
比如redis加了1秒的锁,但请求数据库时候的响应超过了1秒,还在阻塞,其他线程获取到了redis的锁,又来请求数据库,导致全都阻塞在数据库。
可以使用多线程,给redis加了锁以后,使用另一个线程查看请求数据库的那个线程有没有返回,如果快超过了一秒还没响应,就把锁的时间给刷新一下。
所以自己实现分布式协调很麻烦。
穿透
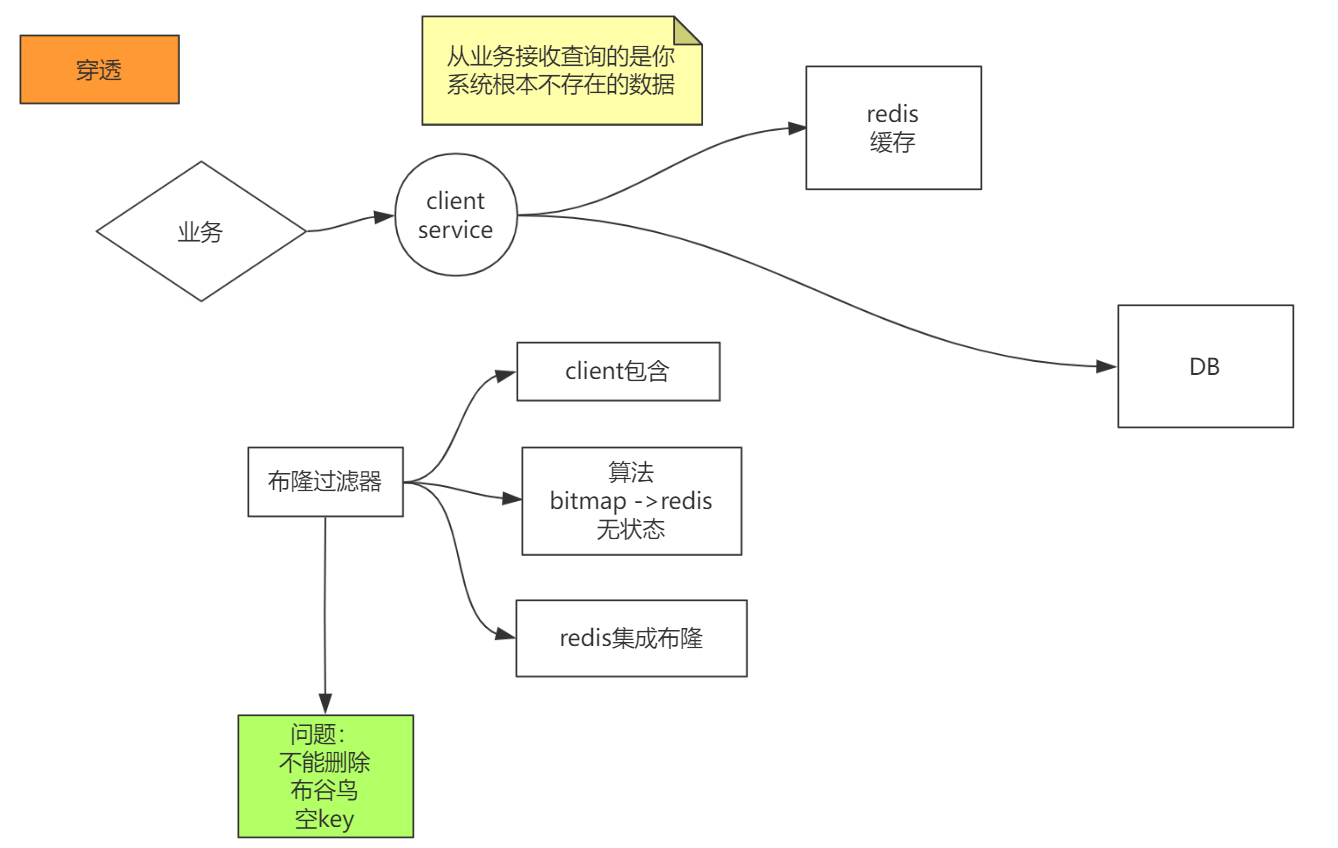
和击穿相比,穿透指的是,请求查找的数据是数据库根本不存在的数据。
所以可以使用过滤器,比如布隆过滤器,配置包含了所有的数据,过滤时候如果拦截,直接返回。
不过布隆过滤器有缺点,不能删除,比如数据库可能删除数据了,数据肯定需要同步到请求服务,所以可以使用布谷鸟过滤器,或者给设置空的key,查到为空直接返回等等一些的方案来处理穿透。
雪崩
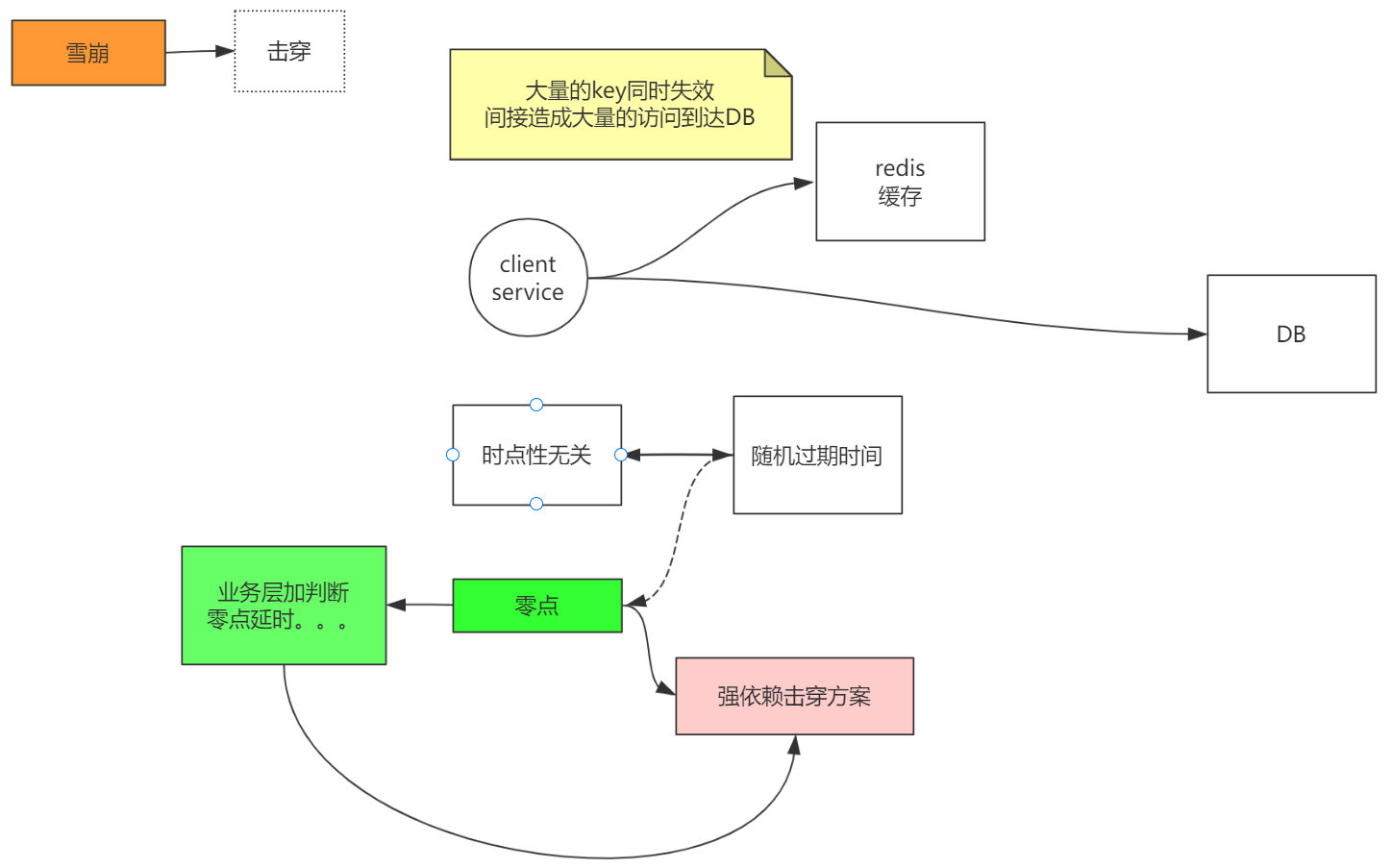
雪崩和击穿相比,不是同一个key失效并且高并发访问数据库,而是大量的key失效,并且并发访问到了数据库。
什么样的场景下会出现大量的key失效呢?
比如零点时候(晚上12点),公司有很多设置的这个时候随机删除一些数据,这时候redis里面没有这些数据了,刚好这是并发请求时候,就雪崩了。
处理方法是跟击穿的解决方案一样的,加锁,或者在零点时候延时一段时间去失效数据。
分布式锁
如果使用redis做分布式锁怎么做,大致思路是使用setnx 命令,那要考虑过期时间,如果锁时间到了还没执行完,所以要使用多线程,没执行完时候就延长锁的时间。
redis做分布式锁不是很常见,一般大部分都使用zookeeper。
既然是锁,对性能就要求没那么高了,要求的是数据一致性,虽然zookeeper 没有redis 快,但它肯定会做到数据可靠性,和api 开发的简单性。
这篇文章写的非常详细:http://zrrd.net.cn/1632.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号