4. redis的集群
为什么要集群?如果是单节点的redis,会有什么问题?
1,单点故障
2,容量有限
3,压力
AKF
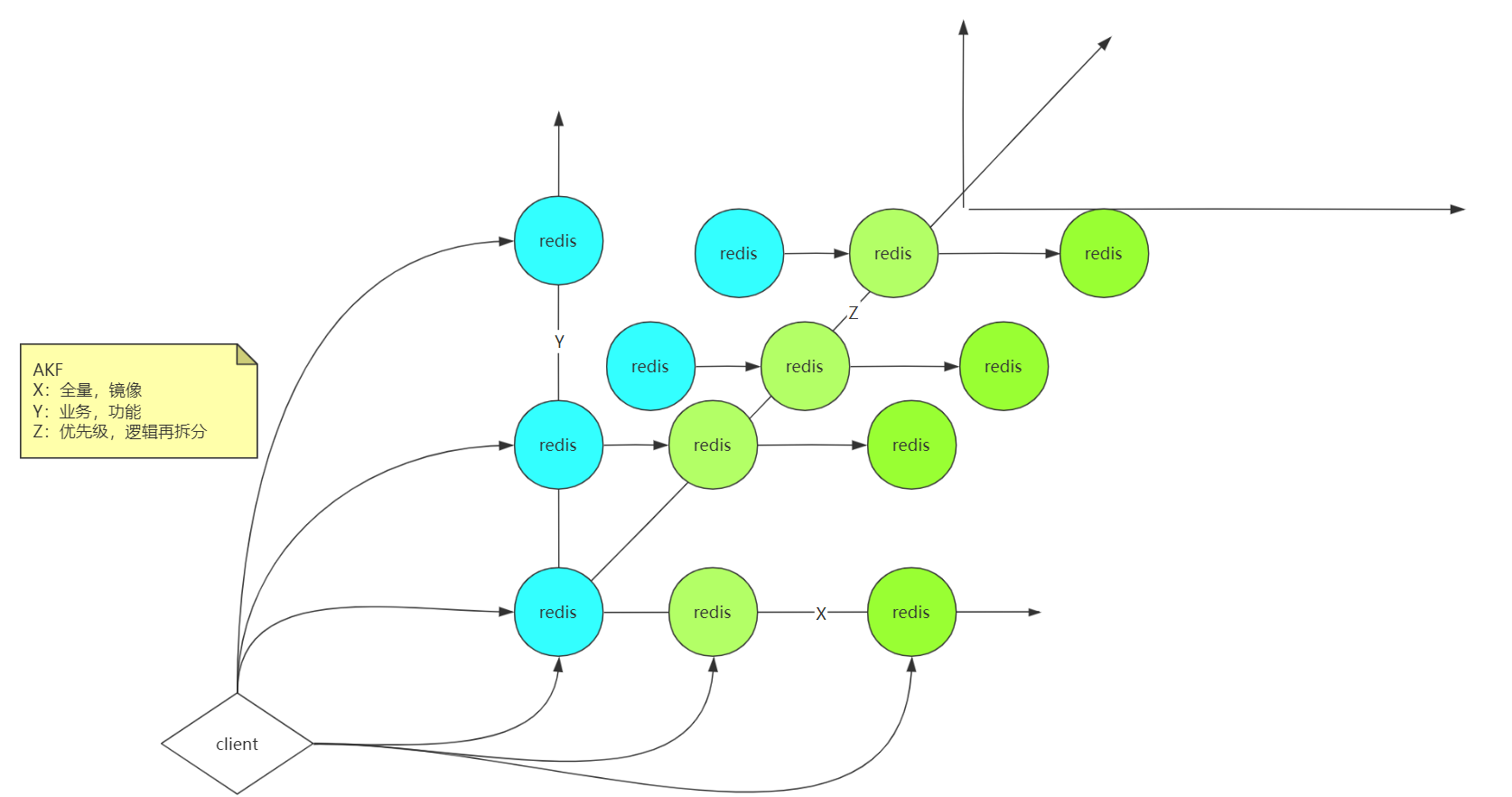
AKF的概念就是服务拆分,比如x轴,作为redis的服务集群,拷贝多个服务实例,保证服务高可用,
y轴表示业务拆分,比如支付、订单等数据,进行业务拆分,把数据拆分到不同redis里
z轴表示进行更细粒度的拆分,并且还保证服务高可用。
数据一致性
强一致性

比如客户端连接到redis集群,确保数据一致性,redis被连接的那个服务实例要把数据同步到其他服务,这样就一定能确保数据在其他redis实例中数据及时更新,这也是企业中追求的一致性效果,确保数据安全。
不过问题是在比如其中的一个服务执行比较忙,会卡很久,对于客户端来说,可能就是服务不可用,所以就会进行了数据回滚操作,但其实redis服务只是其中一个实例卡了一小会儿而已。
弱一致性
不想产生上面强一致性的问题,那就要容忍数据丢失一部分,这就是弱一致性。
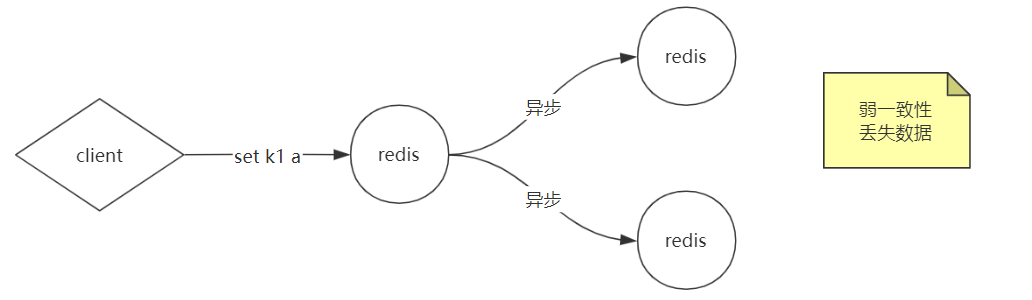
比如客户端请求k1的值过来,redis接收到以后,异步的方式把数据传送给其他两个实例,然后redis直接响应给客户端,意思就是不等那两个redis实例的响应了,结果这时候那两个redis实例响应失败,这样造成了丢失数据的风险。
最终一致性
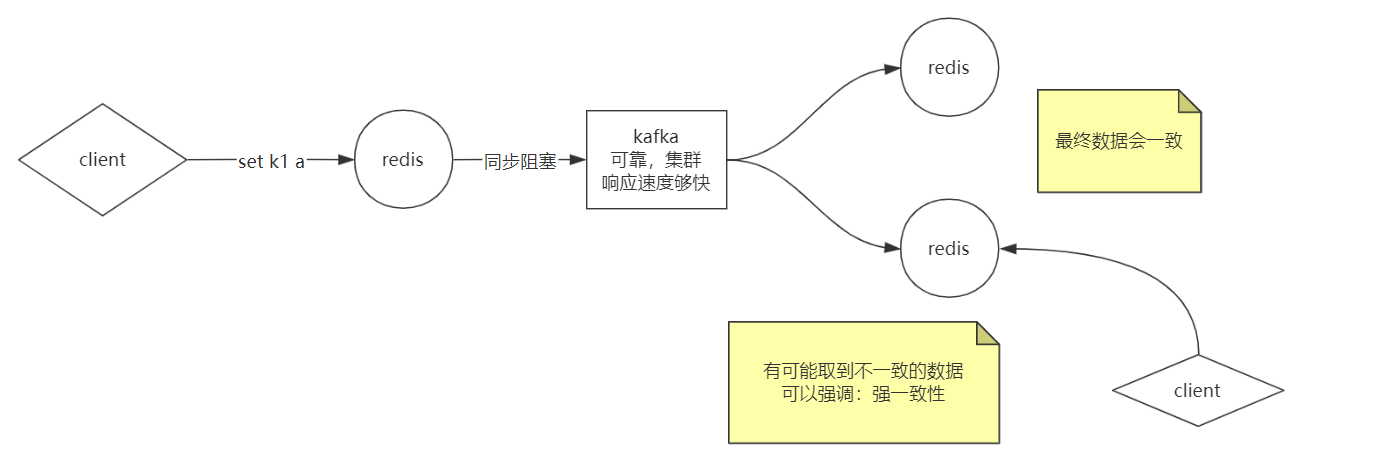
强一致性和弱一致性的问题上面已经说明白了,所以有了最终一致性,redis接收到了客户端请求以后,把数据交给kafka,当然首先要保证kafka的可靠,响应速度够快,可以很快的把那两个redis实例同步数据的结果响应回来,然后让kafka把数据同步到其他的redis,接收客户端消息的redis实例直接响应到客户端。
只要最终从每个redis实例取出的数据都是一致的,保证不丢数据。
有个极端的的问题,比如kafka把消息同步到其他两个redis时候,其他两个redis还没来得及消费消息,这时候如果客户端从这两个redis实例取数据,可能会数据不一致或者取不到。
具体解决方案参考:http://zrrd.net.cn/1100.html
这个文章写的不错,真的是非常详细。
主从复制
CAP
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
因为强一致性肯定会破坏可用性。
首先要知道主从和主备的概念,但不管主从还是主备,反正都会有一个主,主是读写都可以的,然后这时候一个问题,主变成的一个节点,所以要对主节点进行高可用,并可以自动的故障转移。
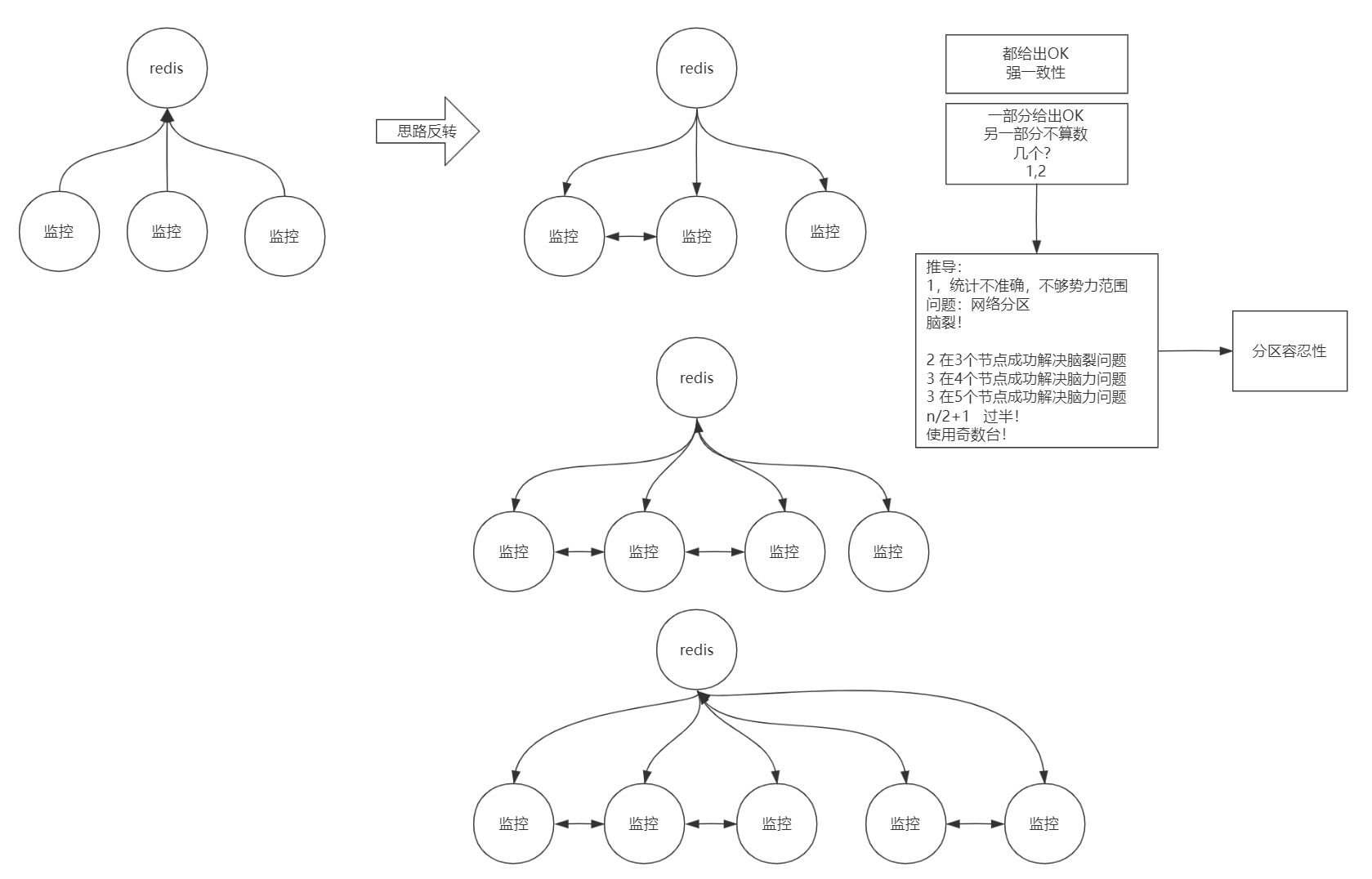
比如有3个监控服务,都去监控redis,这样可能会成为强一致性,要3个监控服务都确定redis服务是ok的。
所以可以思路反转,让redis给3个监控服务响应健康状态,这样的话一部分给出OK,另一部分没有响应的不算数,允许这种的情况,所以理解为分区容错性。
集群数量应该是奇数为好,这样选举时候可以大于一半的数量,避免了脑裂问题。
哨兵(Sentinel)
哨兵就是上面所说的监控节点,它可以自动做出故障转移,通过选组选出新的master节点。
已经有了三个redis服务实例,分别是6379、6380、6381

现在新建配置文件26379.conf,内容如下

mymaster是哨兵的名称,随便起的,因为一套哨兵可以监控多套redis服务
2表示选举的投票数
新建配置文件26380.conf,内容如下

新建配置文件26381.conf,内容如下

编写好3个哨兵的配置文件后,分别启动3个redis实例
启动6379
启动6380去跟随6379

启动6381跟随6379

启动好redis以后,再去启动哨兵
启动26379

启动26380

启动26381

都启动以后,手动关掉6379这个master节点的redis,这时候不会立马选取新的master,会等一会儿,因为要判断是不是网络延迟,等了一定时间后,才会选举新的master
最后选举6381为master
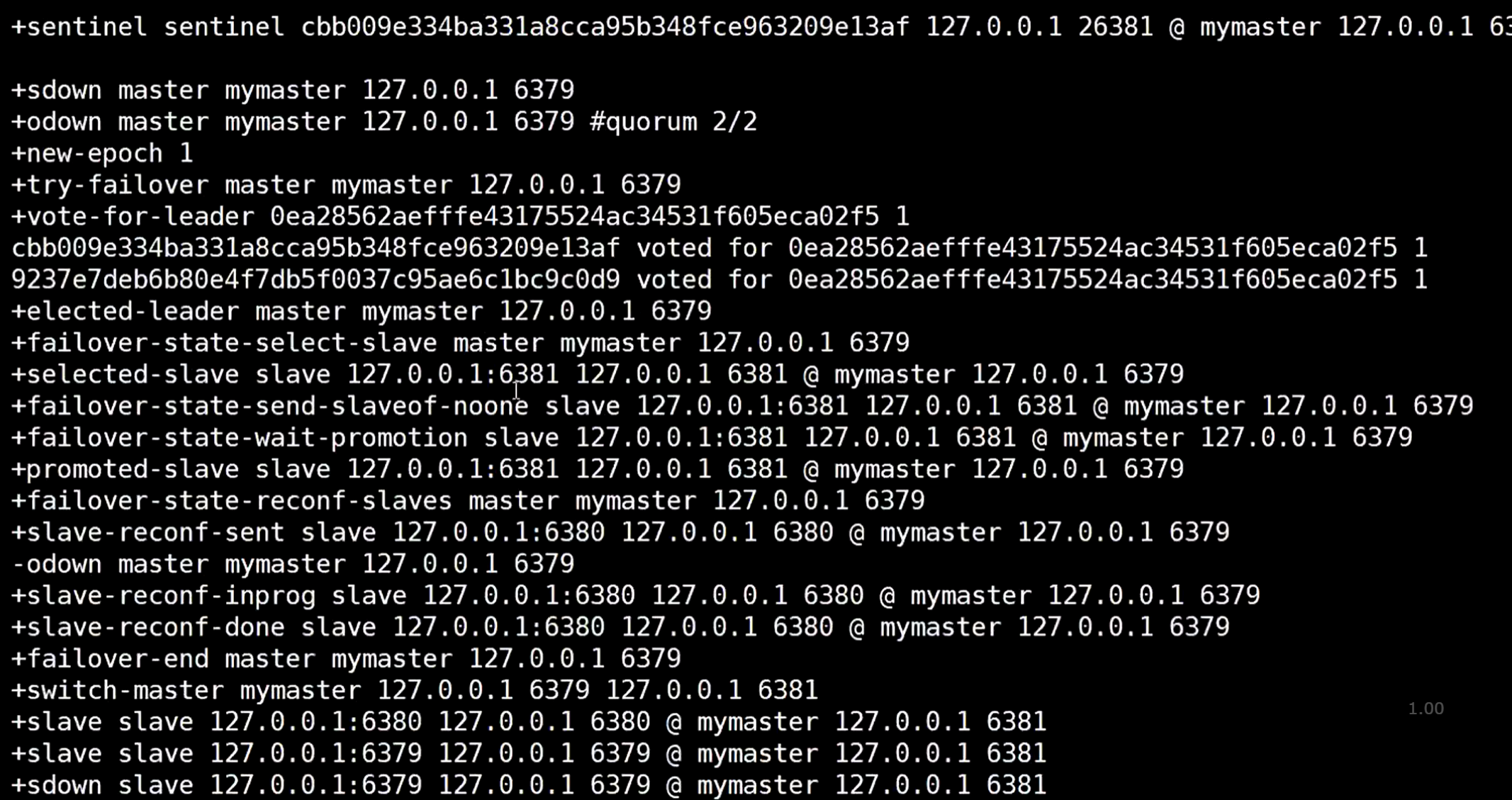
打开26379.conf 文件,可以发现哨兵自己修改了配置文件
然后可以手动给redis添加数据,看其他分支能不能查询的到
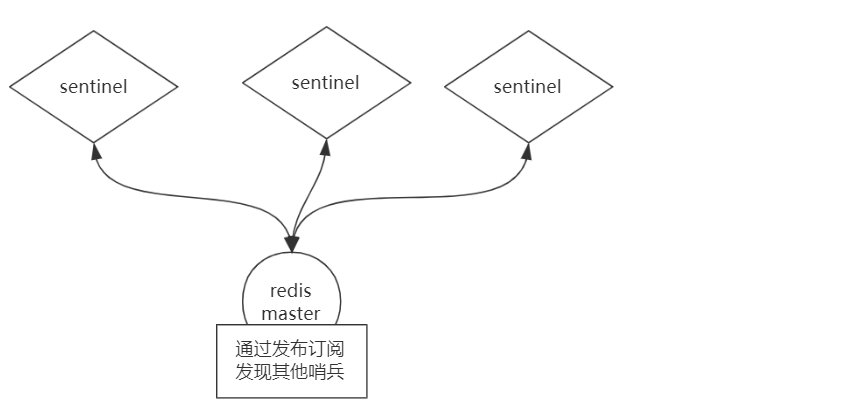
问题来了,哨兵之间怎么互相通信的?使用发布订阅功能。
上面的主从复制时候,redis的集群没有经过Y轴做集群,
意思就是,当需要进行业务拆分时候,这个redis存这些数据,那个redis存另一些数据,数据是不一样的,分放在不同的redis服务里,所以衍生了下面一些方案
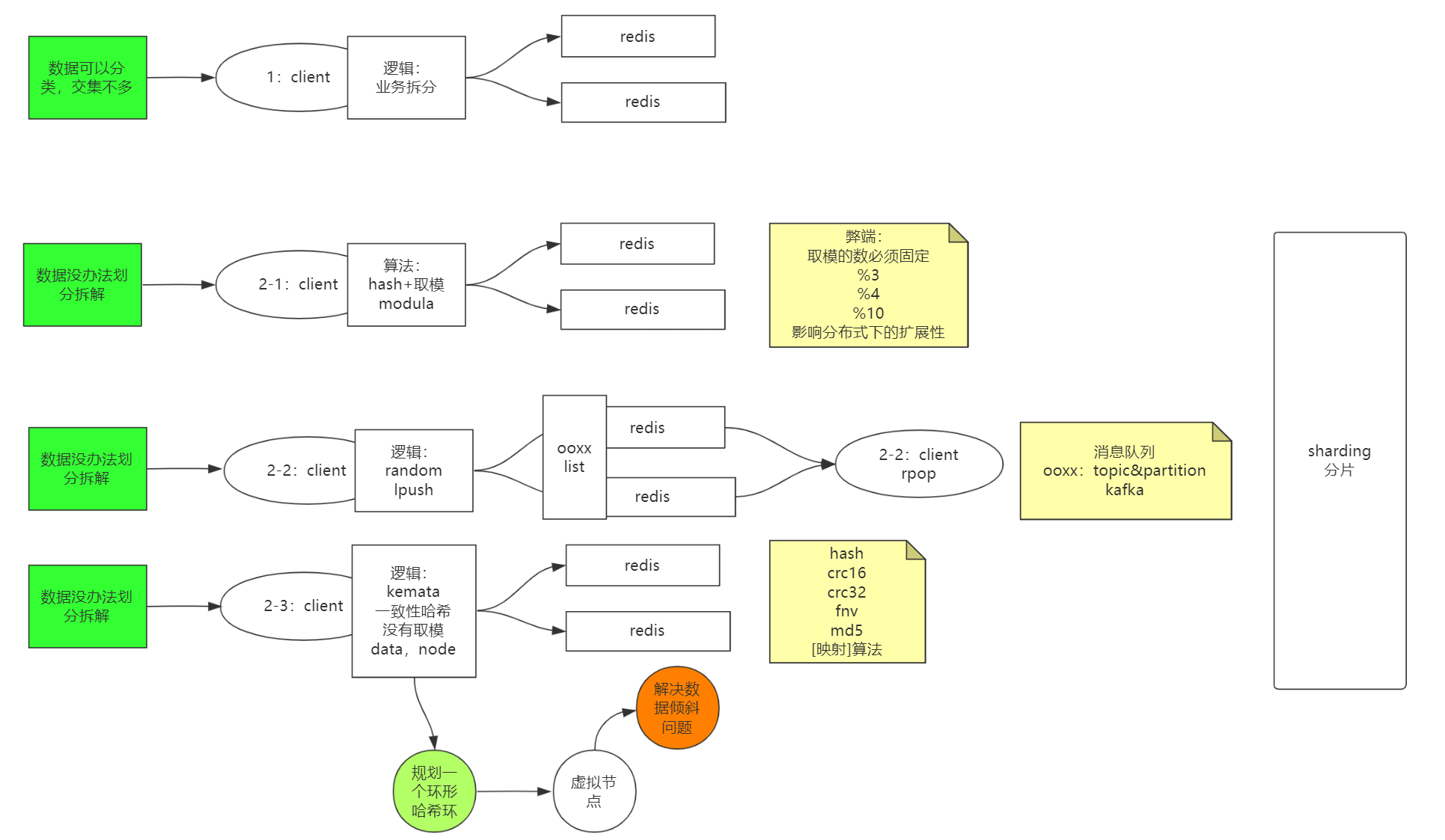
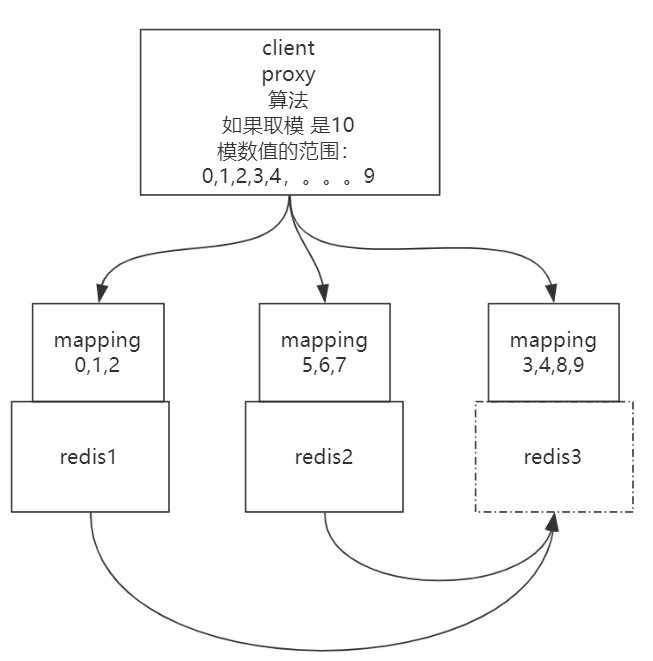
首先是通过hash取模选择哪个redis保存数据,但这样影响扩展性,如果后面需要新加进来几个redis服务呢?取模数量就发生变化了,需要修改。
使用随机的时候肯定也不可以的,首先从数据业务逻辑上来说,就没法划分好,为什么会有这种方案的场景?
比如有个ooxx的key作为数据存在多个redis服务里,是个list类型,对于redis服务来说是不知道具体全量数据的,但是对客户端来说,只要取出数据就行了,可以通过list来实现消息队列。
最后一种方案是通过一些算法来映射,规划出一个环形的逻辑图概念。
一致性hash理解
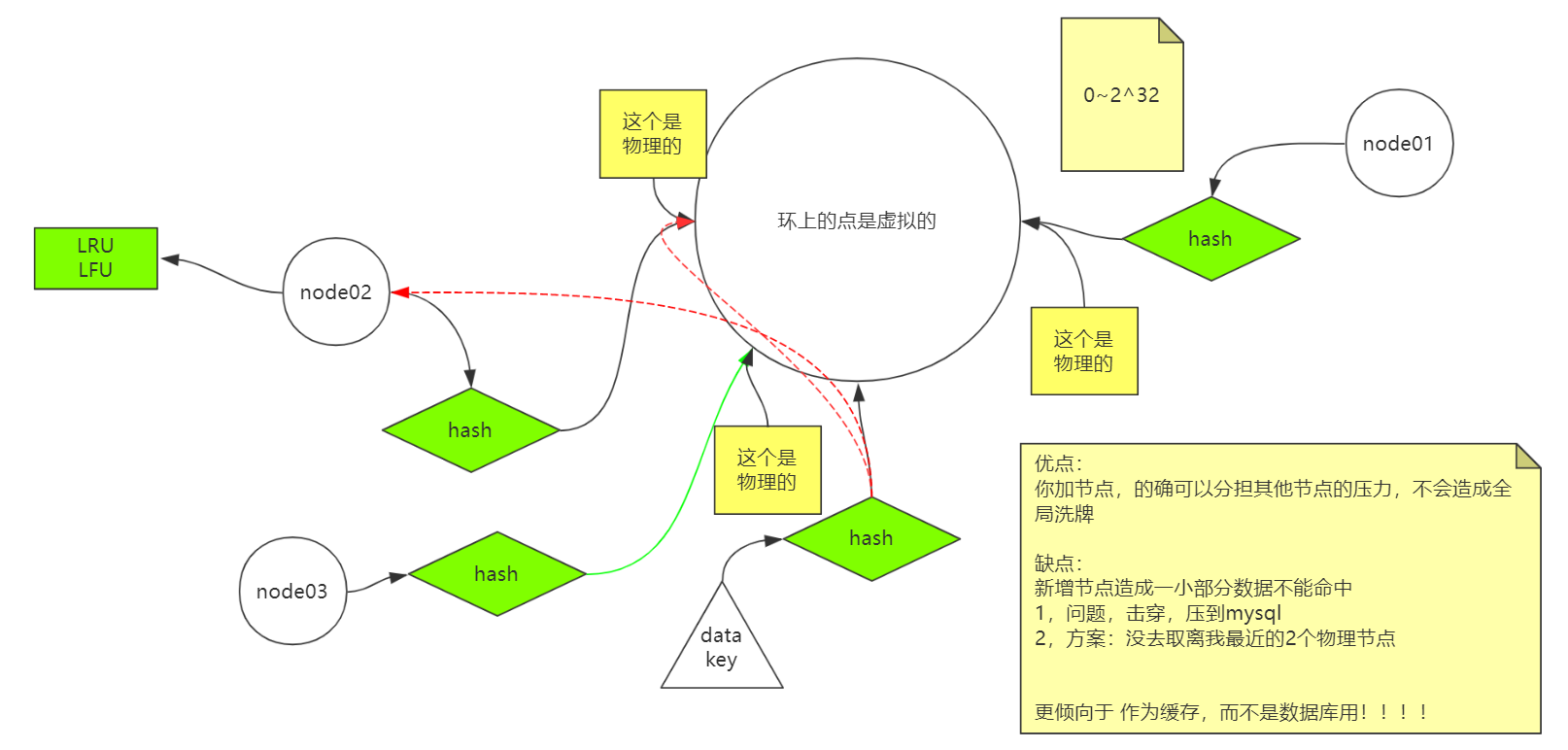
比如有一个节点,拿到它的hash值,不管通过算法什么运算,得到一个值,这个值对应着映射到了环形的某一个点上(这些点都是物理的)。
如果有个数据过来了,拿着这个数据的key和一些东西进行算法运算,得到的值也是映射到环形的点上(这些点是虚拟的)。
知道了上面这些后,其实可以通过一个算法,就是拿到这些虚拟的点,也就是存数据的点的值大于物理的点的位置,离物理的点最近的那个虚拟点,把数据通过这个物理的点存在对应的节点上。
如果这个时候新加进来一个redis节点node03,刚好它的物理点在node02节点数据最近的位置,那就会有问题了。
虽然这个新家的node03也可以分担压力,去存数据,但是可能会有一些数据是查不到的,通过数据的虚拟点找到了离它最近的位置node03的物理点,结果没查到数据,所以会造成击穿。
所以redis只适合做缓存,而不是数据库,当数据查不到时候去数据库里查一下数据。
所以redis有个LRU、LFU等一些算法,去淘汰一些数据。
上面3种模式都决定了redis不能做数据库使用,只能当缓存。
有个问题,当客户端连接redis服务的时候,会给redis服务造成很大的连接成本
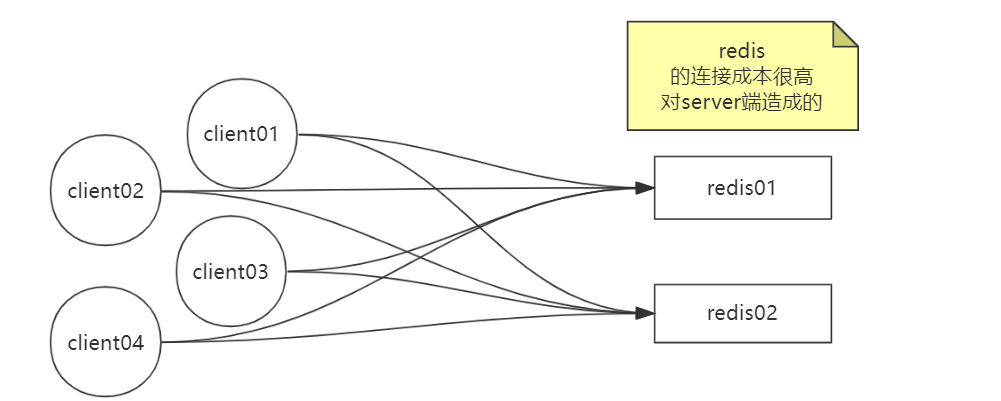
如果有个代理的话,客户端的连接过来都去连接这个代理服务,代理服务只是转到的redis的服务,就能解决问题。
代理服务是无状态的,它没有任何的逻辑,只是做个代理而已,所以可以直接做集群,不用考虑其他逻辑问题。
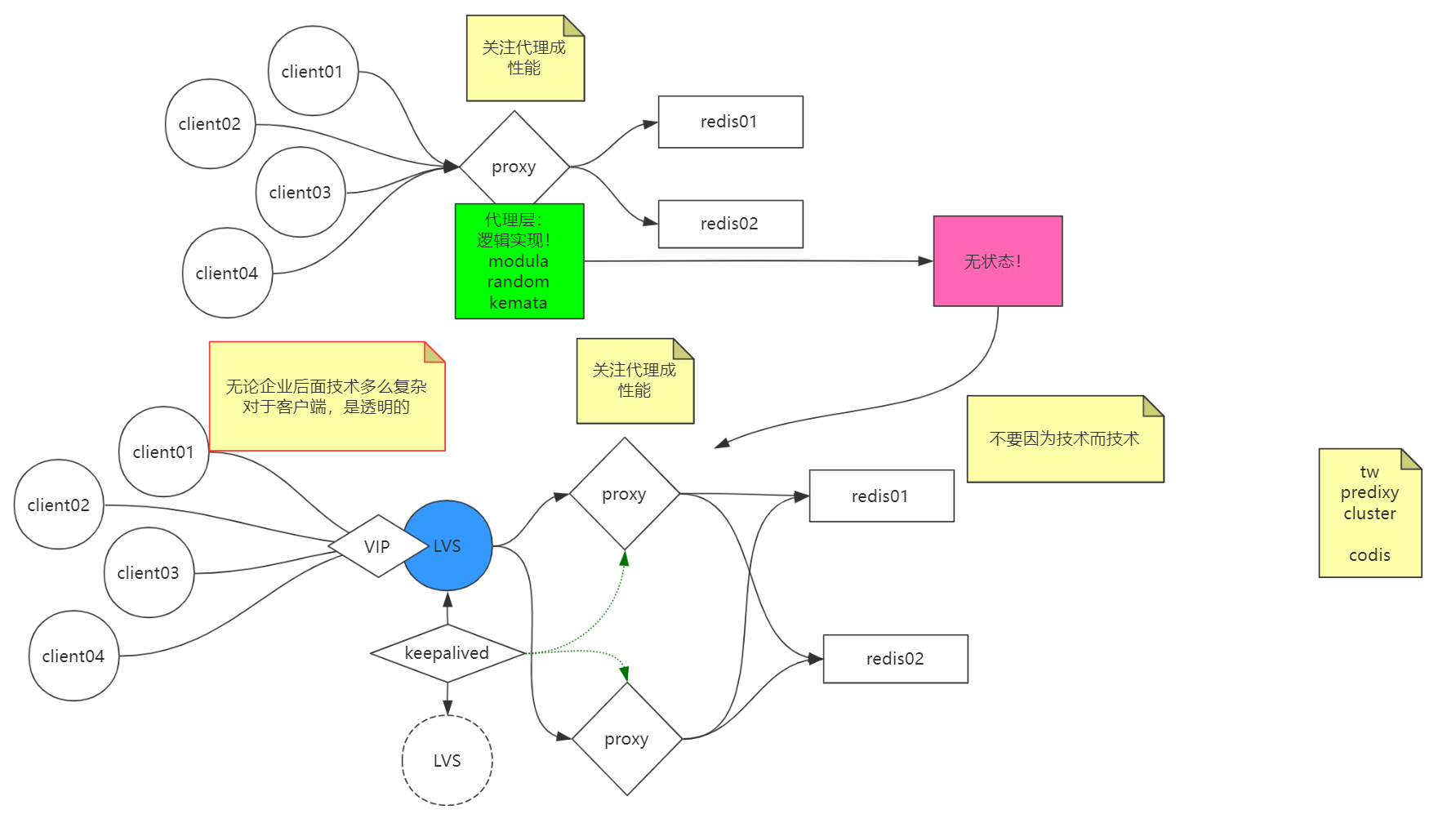
如果说有很多的客户端连接,一个代理服务可能压力很大,那一样可以给它做集群,如果集群还是不行,那可以在它前面做一个lvs,所有的人都去请求的这个lvs,然后给lvs做主备,使用keepalived来管理lvs做一个替换备选方案,并且keepalived还可以顺便去监控代理服务的监控状况。
cluster分片集群
redis的cluster是无主模型的集群,每个节点都一样,不分master和slave
先来思考一个问题,如下图
比如之前只有2台redis服务,现在要新加进来一台redis来分担数据承载的压力,那么肯定要做数据拷贝,
比如之前的0-10个槽位是在2台redis服务上,现在新加的redis要分担数据,就把一些的槽位分过来到这个新的redis上。
明白上图后,现在来说一下redis的cluster模型
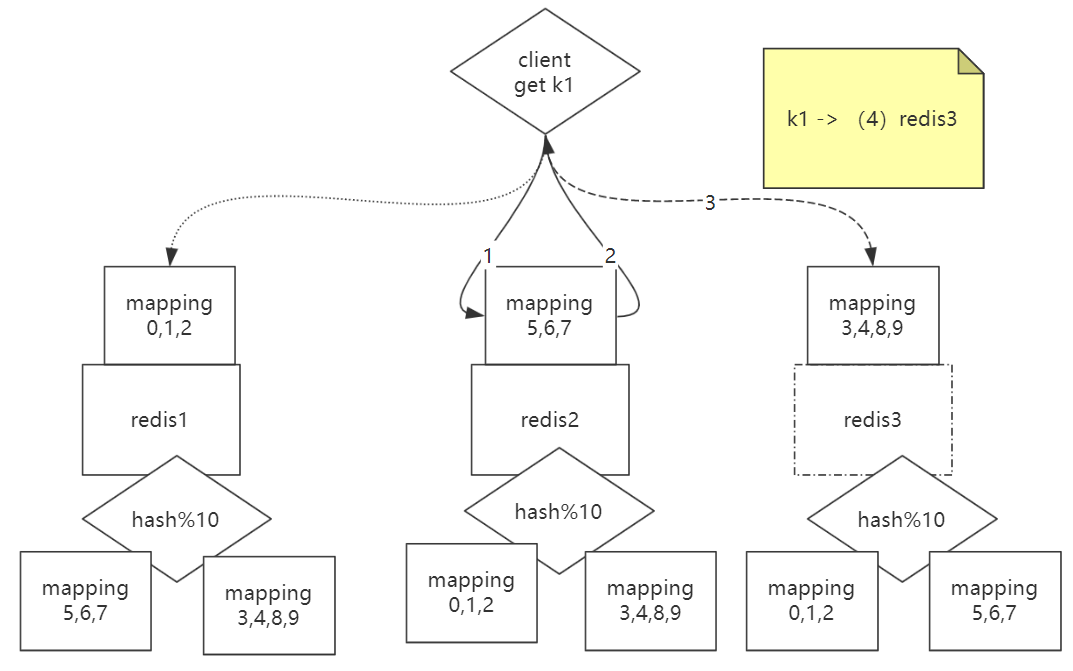
还是和之前说的一样,有2个redis服务,现在新加1个redis服务,把一些槽位分给了新加的第3个redis。
问题来了,如果客户端请求到的redis,这个redis没有客户端查找的数据,就是说这个数据在其他的redis上,那怎么办?
每个redis里面都有通过hash的一些算法,具有其他redis的映射地址,如果客户端请求查找k1的值,比如这个k1的值在槽位4里面存放的,也就是第3个redis服务里,比如客户端随意请求一个redis,请求到了第2个redis服务,这个redis发现自己没有k1的值,但是通过自己里面的算法知道k1在槽位4,那么槽位4在第3个redis服务里,就会把这个信息返回给客户端,就重定向到了第3个redis服务,就可以查到数据了。
这就是redis的cluster集群模型。
不区分主从节点,每个节点都一样,客户端不管连接谁都可以查到所有数据。
twemproxy
参考:https://github.com/twitter/twemproxy
查看README.md
首先下载源码,随便连接一个redis服务的机器,如果下载报错,执行yum update nss升级一下,然后再次下载执行git clone 命令

先安装automake 和 libtool

执行autoreconf -fvi命令,
如果报错,去阿里云找epel仓库,找到仓库地址复制过来,到系统的仓库地址给系统重定向一下
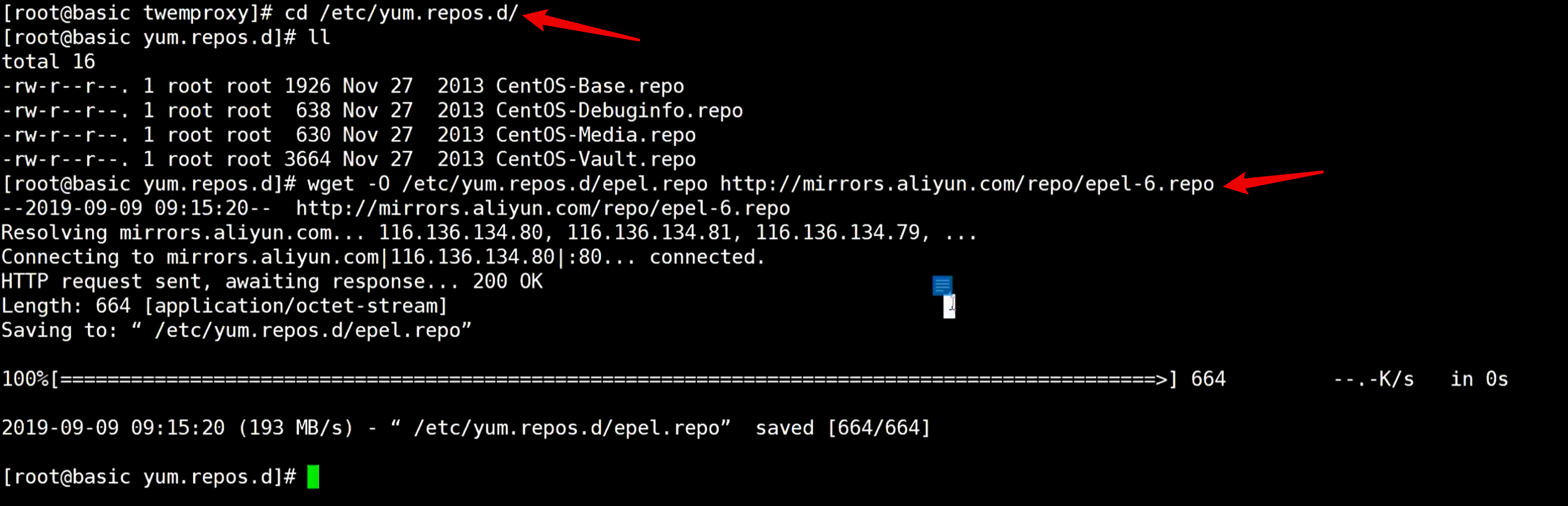
执行后多出一个文件epel.repo,执行命令yum clean all给它清空一下
然后回到下载twemproxy 源码的目录,执行yum search autoconf查找autoconf版本,如果有就安装
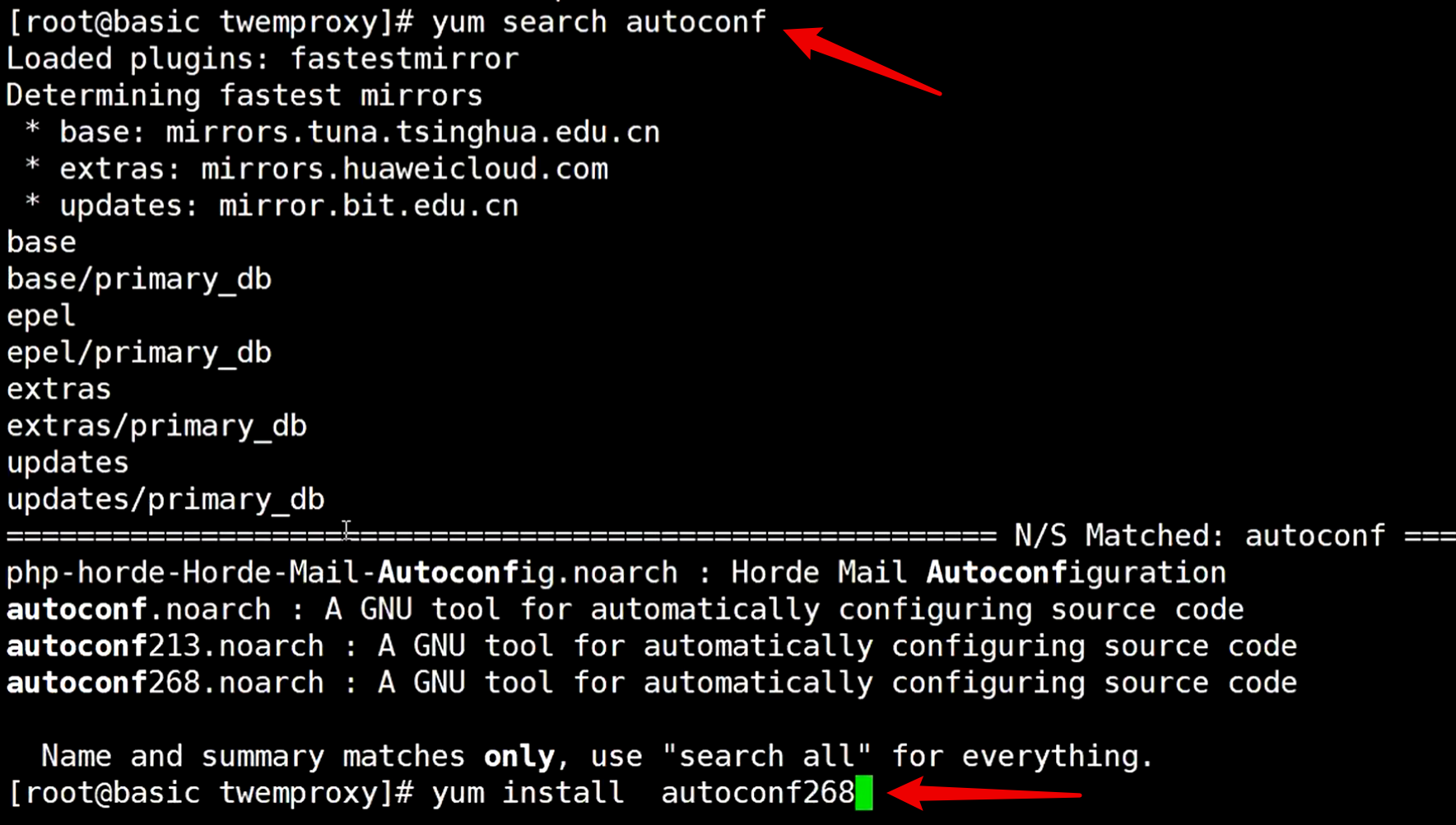
然后执行autoreconf268 -fvi 命令,autoreconf268是刚刚下载的那个版本,执行后就多出一个configure文件
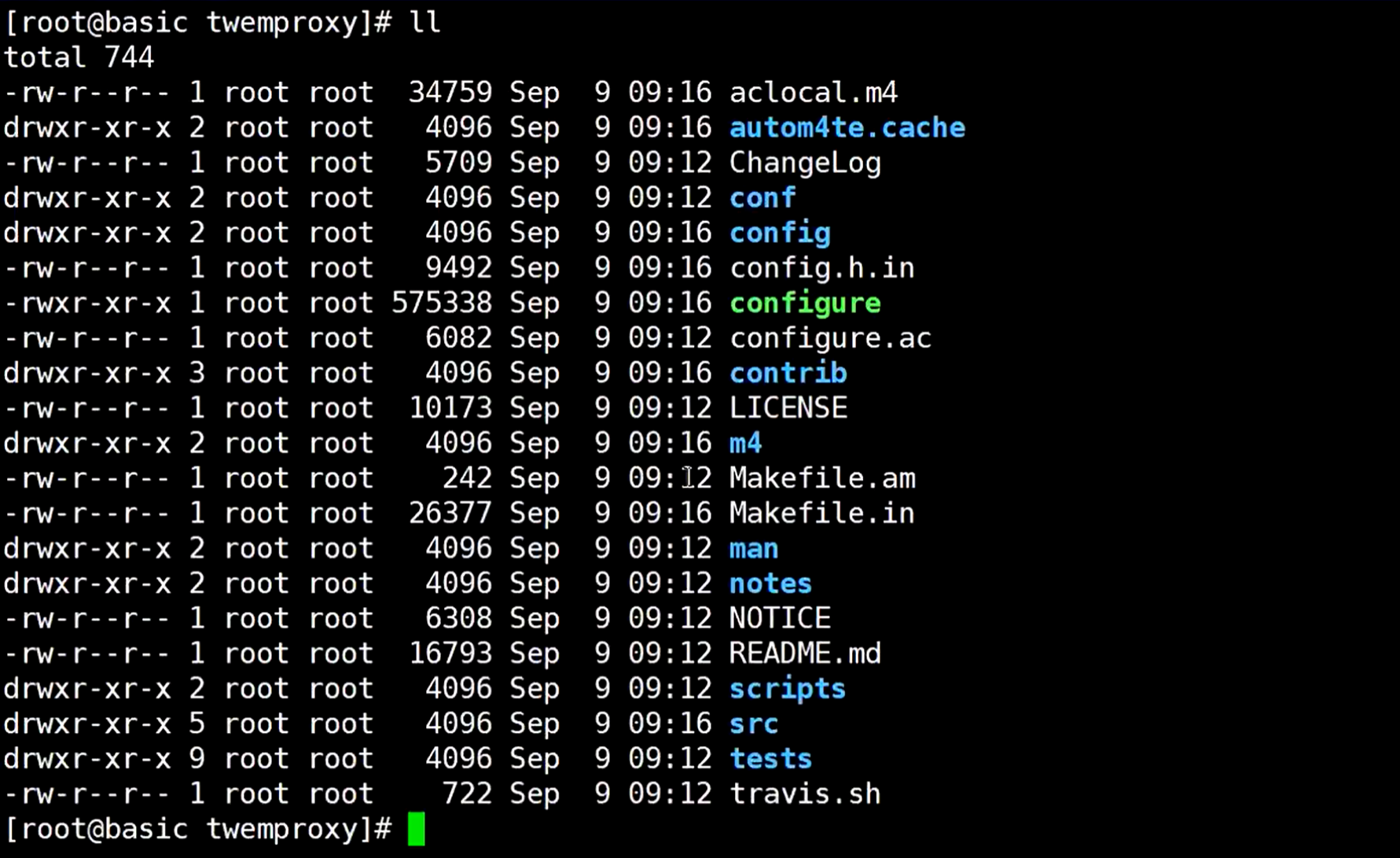
执行./configure

执行make
然后到src目录,可以看到可执行程序nutcracker

退出来到scripts目录,拷贝nutcracker.init文件,到/etc/init.d目录下,起个就叫twemproxy

这个文件还没有执行权限,使用chmod命令给加上权限

打开这个文件,可以看到它期望在哪个目录下有可执行文件
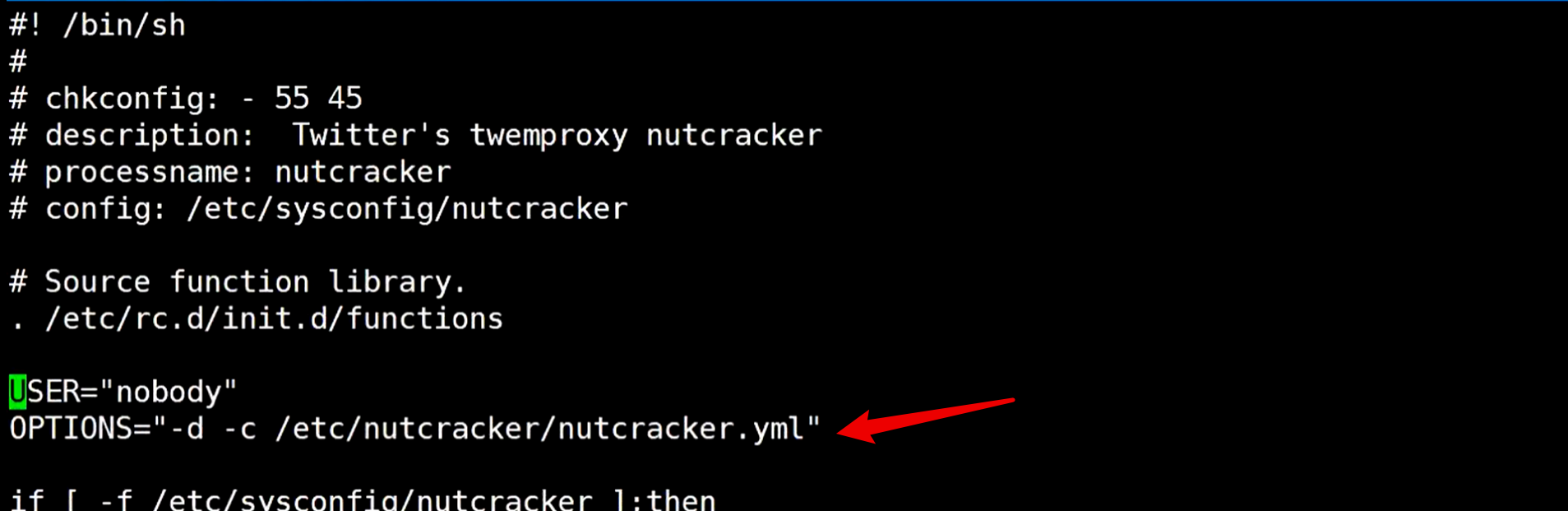
创建指定的目录
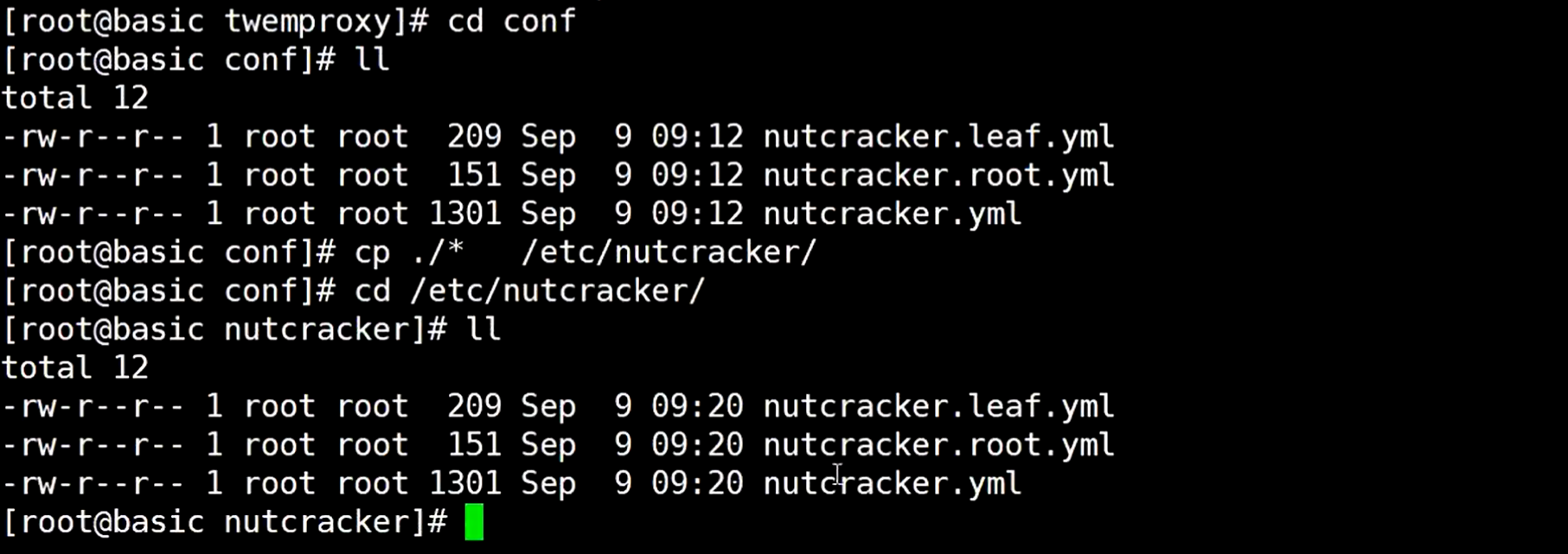
然后去到源码目录的conf目录下,拷贝文件到那个指定的目录
去到源码的src目录下,拷贝可执行程序到/usr/bin 目录下

这样就可以在任何地方使用这个可执行程序的命令了
改配置文件,怕万一改错了,所以备份一份
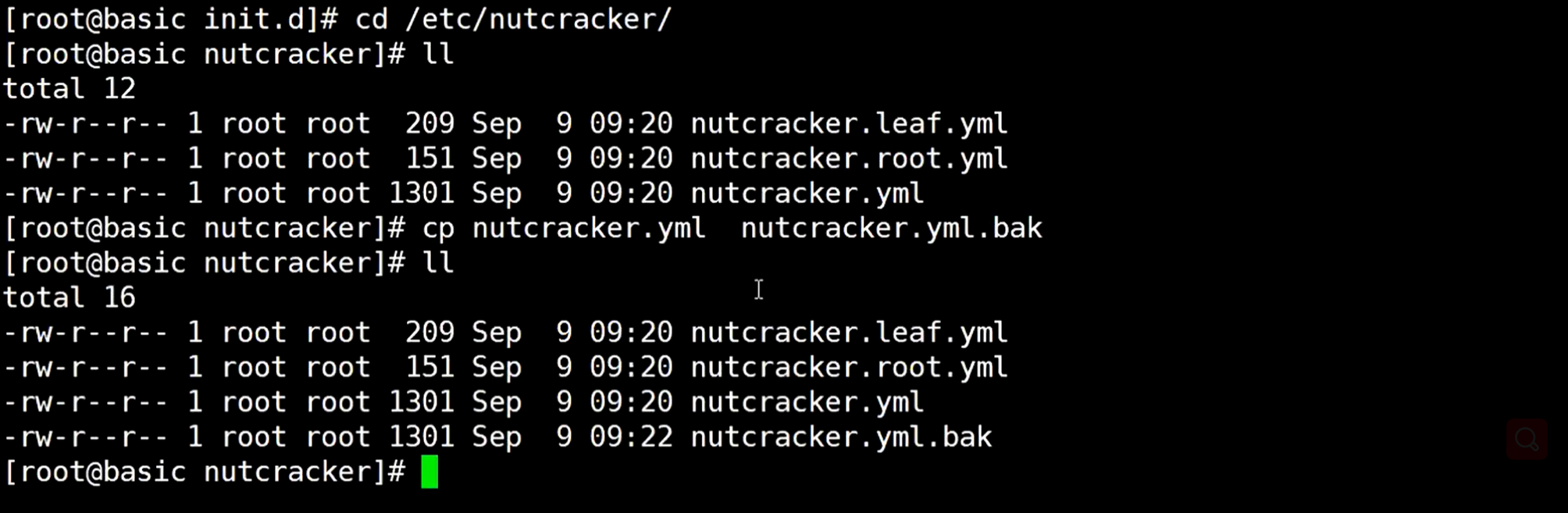
修改文件,因为只用代理redis就行了,所以只保留这些,配置2个redis服务(这些都可以通过github上去找怎么使用)

然后启动2个redis实例,创建目录,然后先启动6379
再启动6380
redis启动的当前目录,就是作为持久化目录
然后启动twemproxy,它的端口是22121,在配置文件中可以看到

使用redis连接22121,命令redis-cli -p 22121
然后在这个代理服务的连接客户端执行命令添加数据到redis
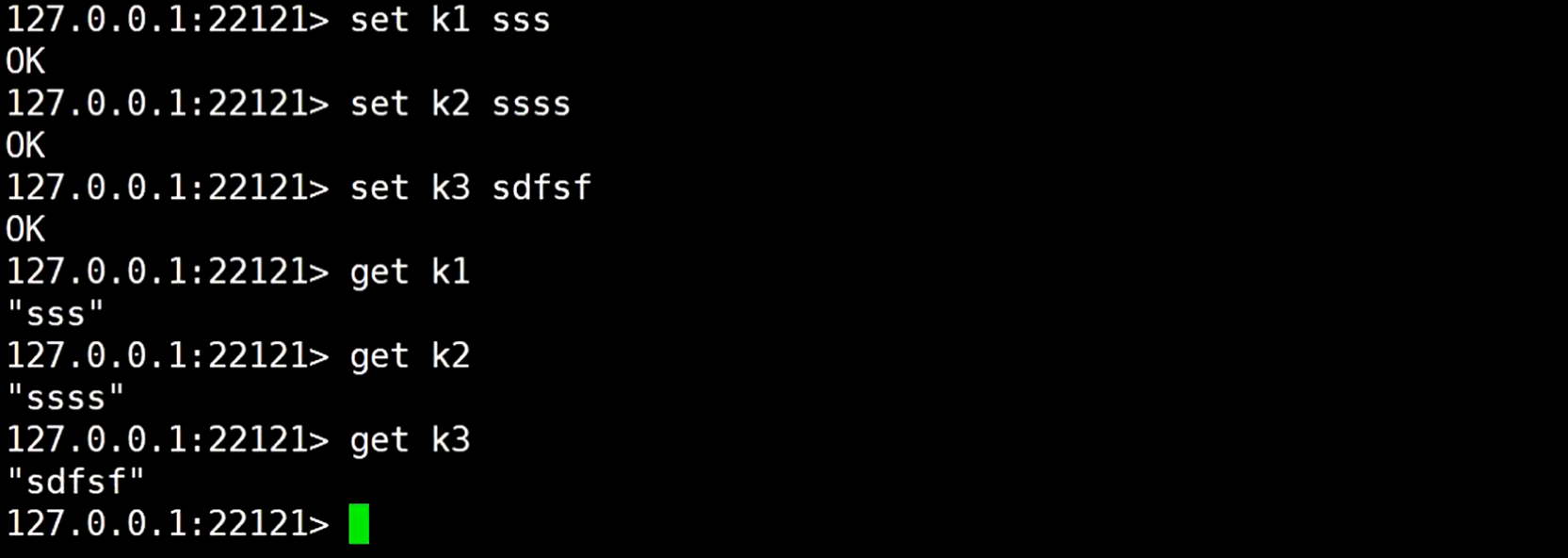
然后直接连接redis,查找是否能查到数据
查看6379 服务,发现没查到

查看6380服务,发现数据都存在这个6380服务了
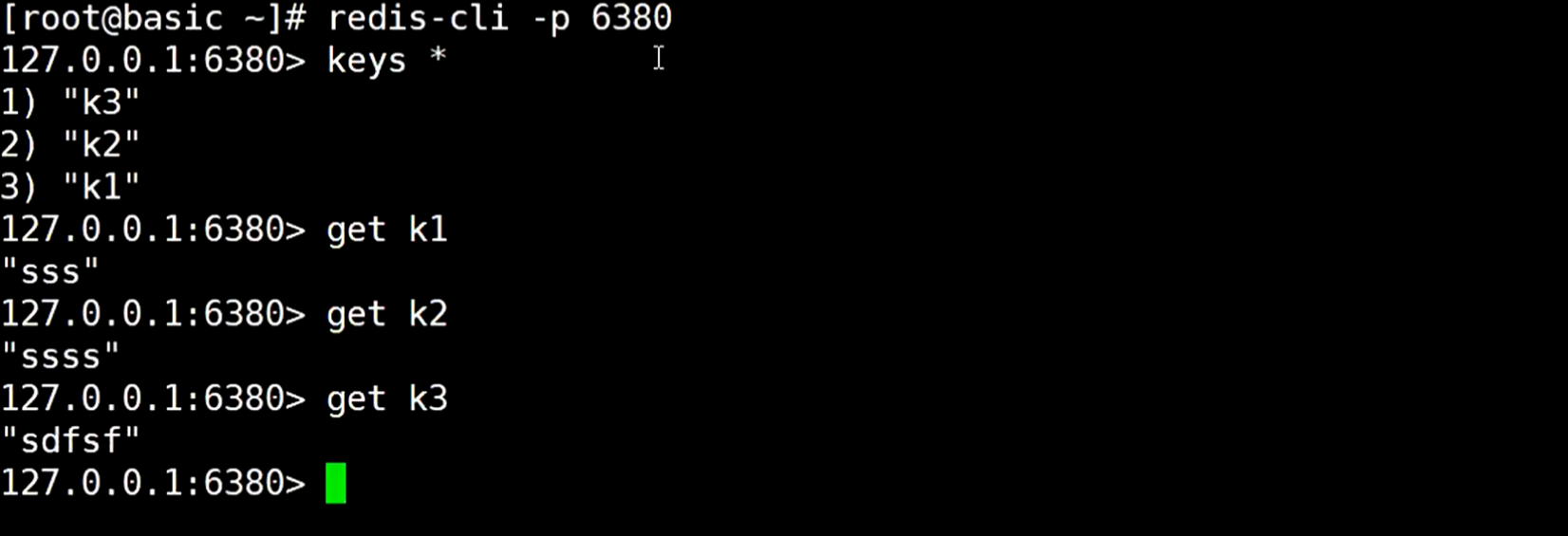
到twemproxy服务执行一些命令,发现都是不支持的,因为数据分置到不同的代理redis服务里

predixy
参考:https://github.com/joyieldInc/predixy
安装,新建目录predixy,然后使用wget 命令

解压完以后,找到它的conf 目录,发现有很多的配置文件,有cluster.conf、sentinel.conf,还有predixy.conf 它自己的配置
打开这个predixy.conf 文件查看
打开注释绑定的7617

往下找,找到SERVERS 配置

sentinel 和 cluster 模式的两种,只能开启一种模式,先来试一下哨兵的
修改完后保存文件,然后修改sentinel.conf 文件
复制下面的一段到最下面,然后打开注释,修改哨兵的配置

ooxx 和 xxoo 表示两套哨兵,它是可以监控多套集群的,所以哨兵里肯定会有名字叫这两个的
保存配置文件,然后去把哨兵给跑起来
修改26379.conf 的哨兵配置文件,master肯定也不一样,应该有两个master

这个配置就是说,26379的哨兵,要去监控36379的redis的master,和46379的redis的master
修改26380 的哨兵配置文件

修改26381的哨兵配置文件

修改保存好哨兵的3个配置文件
接下来准备启动哨兵
先启动26379

启动26380

启动26381

启动两套主从复制的redis集群
先创建4个目录,36379 、 36380 、46379 、46380
到36379目录启动36379 master

到36380目录启动36380 slave,让它去跟随36379

启动另一对redis集群
到46379目录启动46379 master

到46380目录启动46380 slave,让它去跟随46379

都启动完了以后,再回来启动predixy
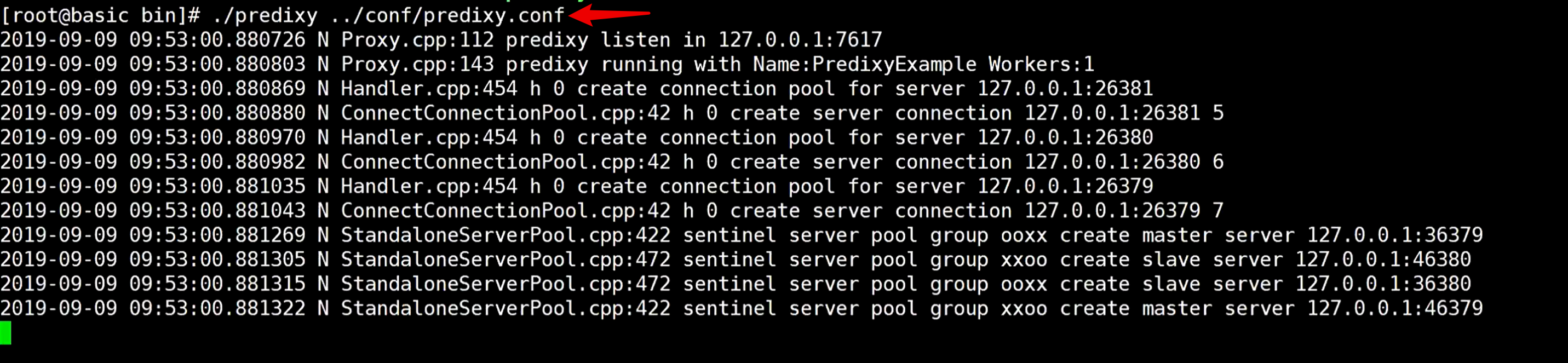
再去新开窗口,测试存入数据,发现正常

这些数据存在哪里?
连接36379,查询数据发现只有k1

连接46379,发现只有k2数据

数据是分放在了连个redis集群里了
在predixy服务里开始redis事务的命令,发现报错,因为它只支持一个的redis事务

修改哨兵配置文件sentinel.conf,这样他就只会往一个redis集群中添加数据了
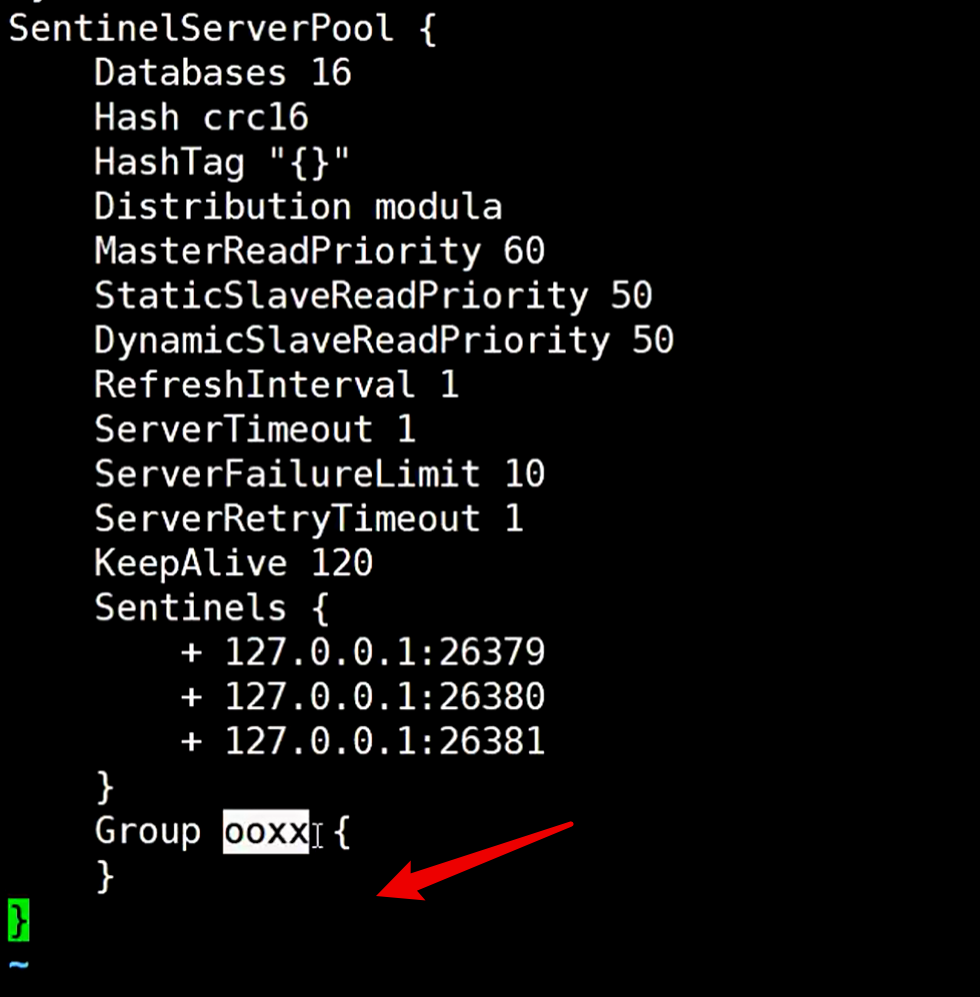
保存后再重新启动predixy,发现只有36379 和36380

这个时候就支持事务了
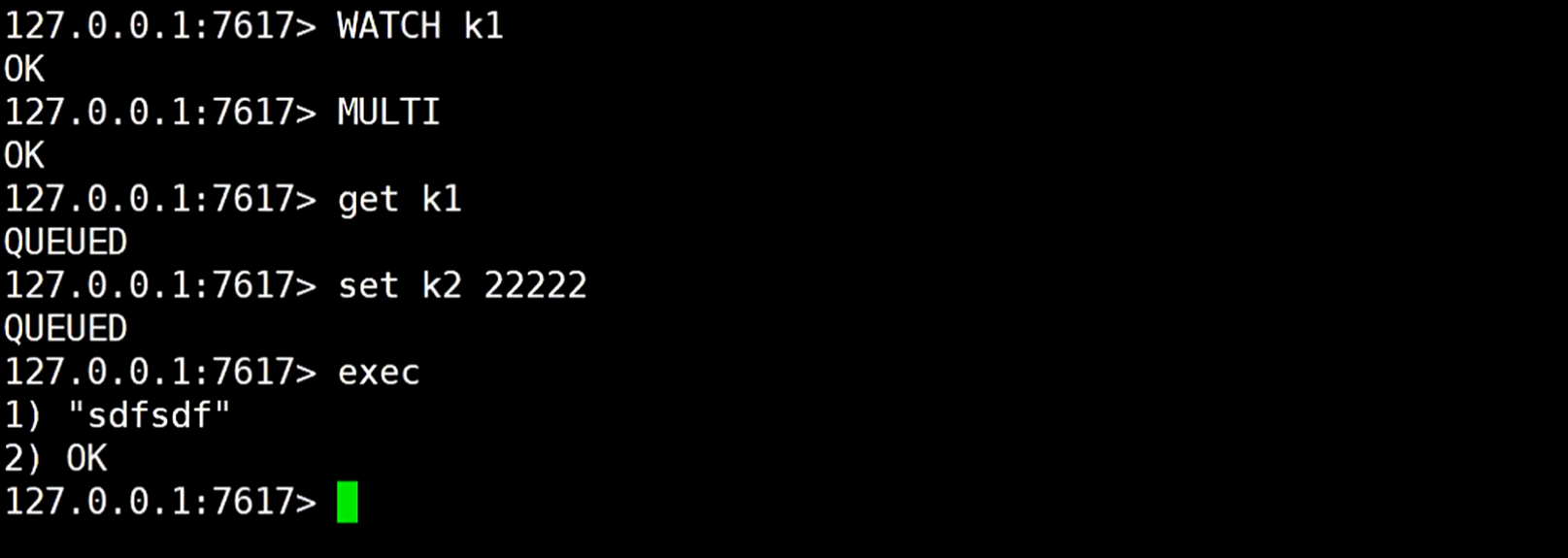
cluster
这种模式是cluster这种的无主模式,并且自己定义分配槽位
找到redis的utils 目录,进入create-cluster 目录,找到create-cluster 文件
修改这个create-cluster 配置文件
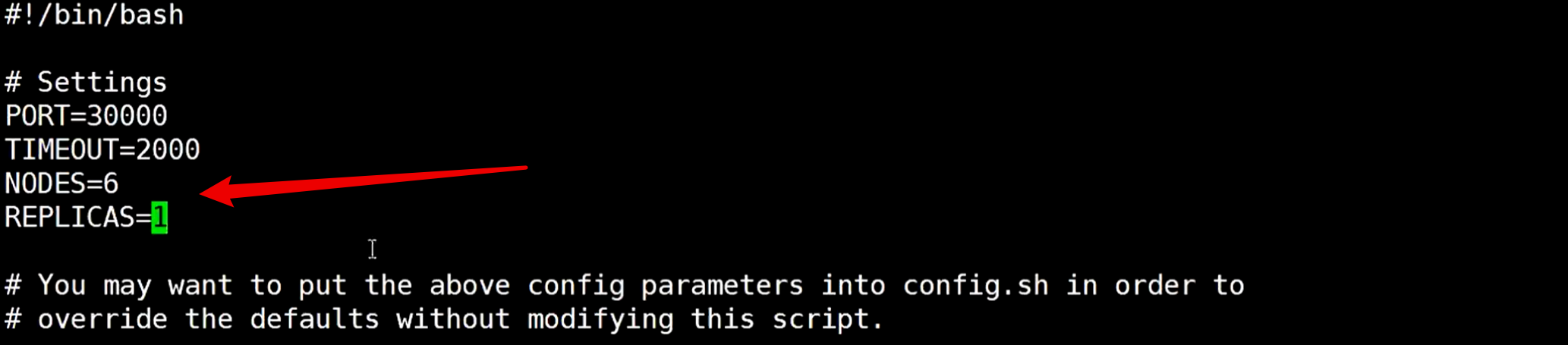
表示一共6个节点,replicas节点是1,那就是3主3从
保存配置文件后,启动启动
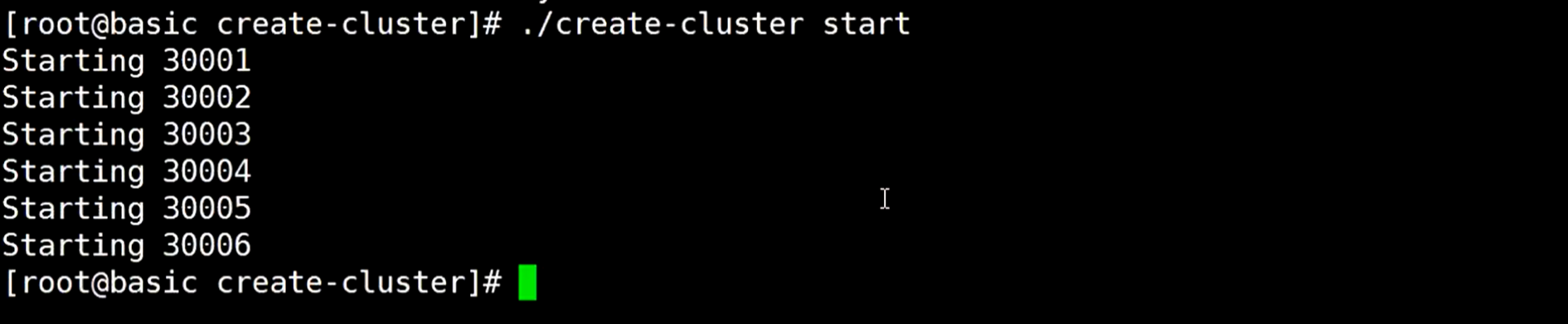
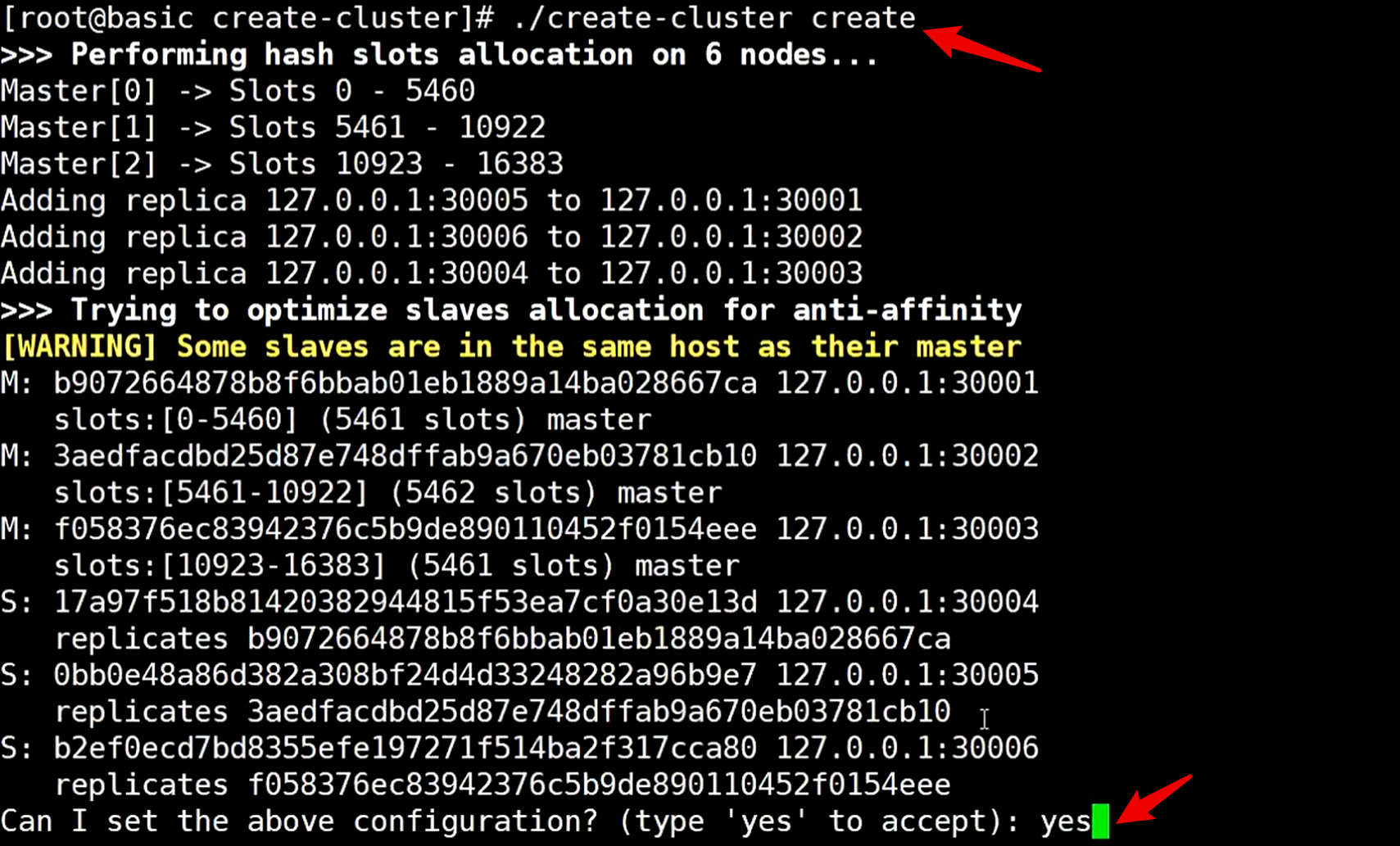
启动后执行命令./create-cluster create,给redis分槽
连接其中的一个redis主节点,存放数据,发现报错,说让移动到30003端口的redis,因为这个槽位在那个redis服务上

更换命令使用,-c 表示cluster,集群,这样就可以添加数据成功
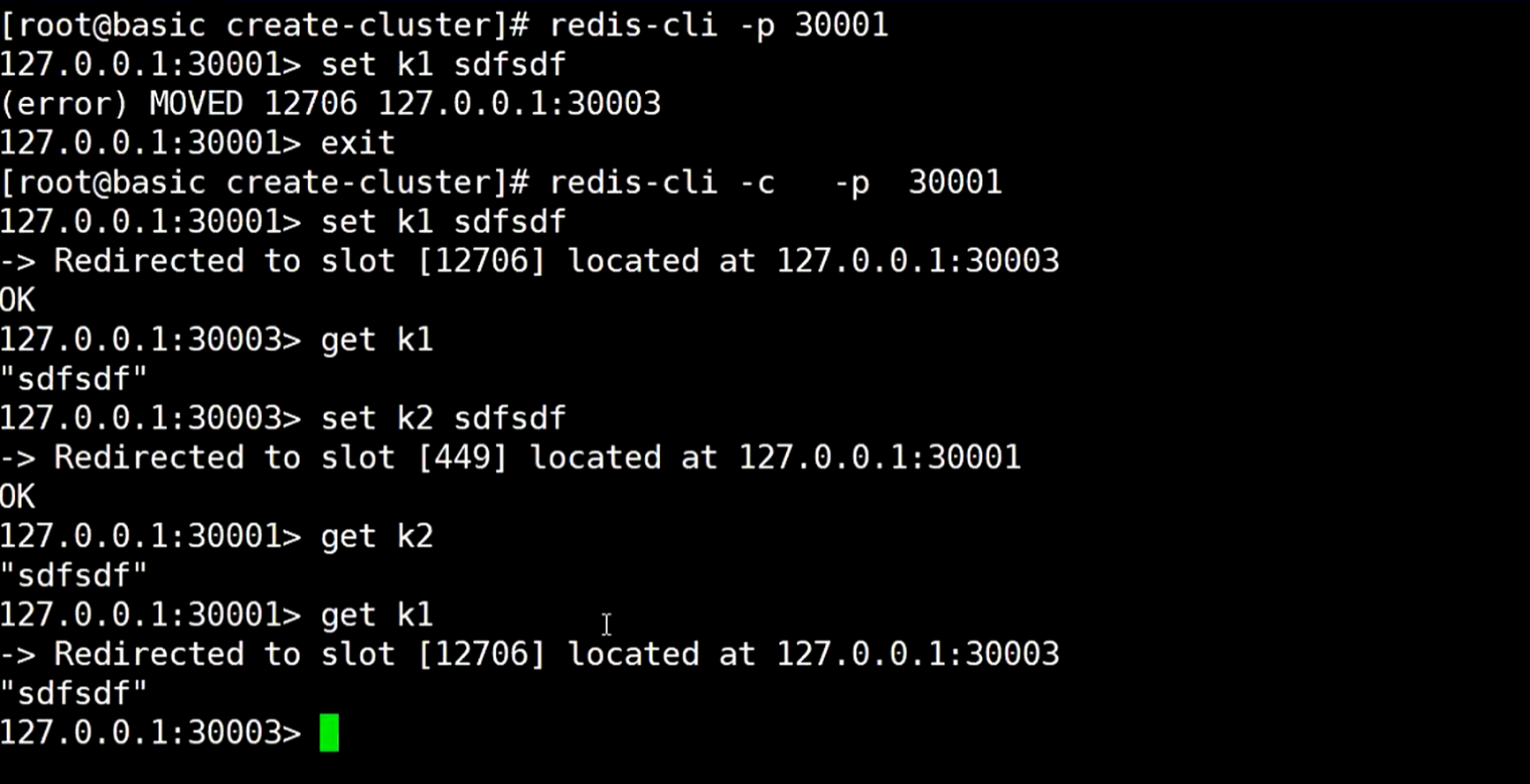
当get去获取数值的时候,会自动跳到对应的redis那个服务,会跳过来跳过去
看着可以正常使用,但这样不太支持事务
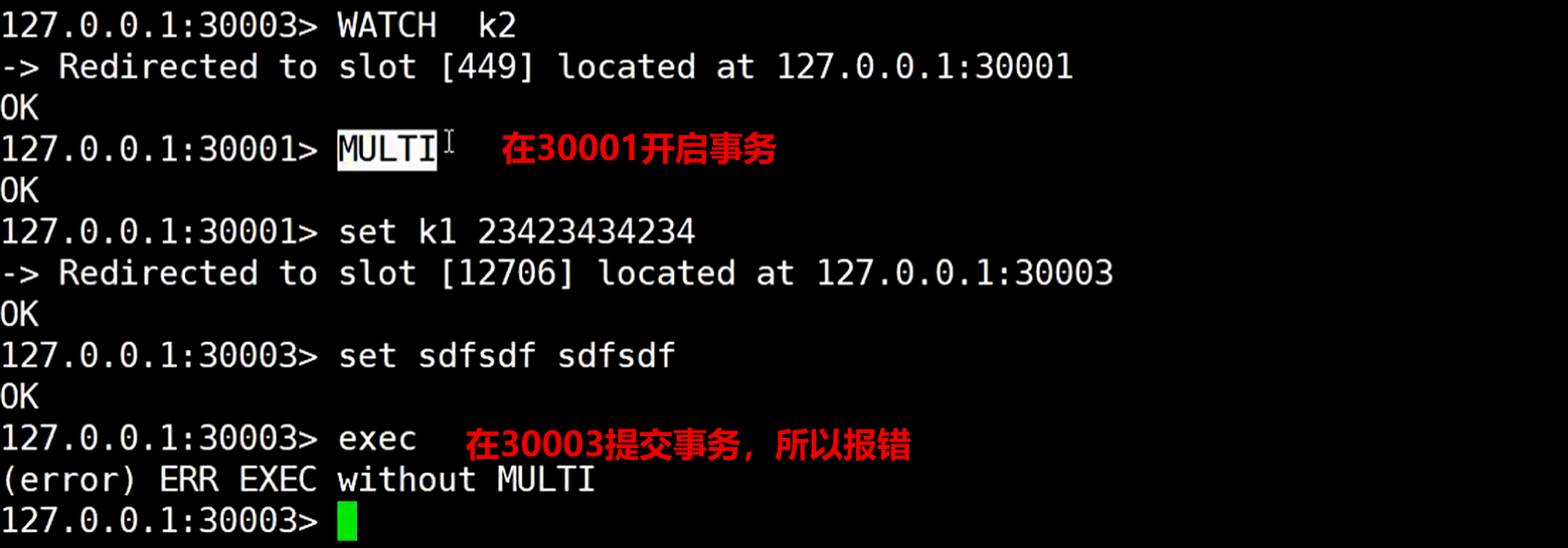
技术是死的,但人是活的,它既然这样不支持事务,我们可以在存放数据时候在key上做手脚
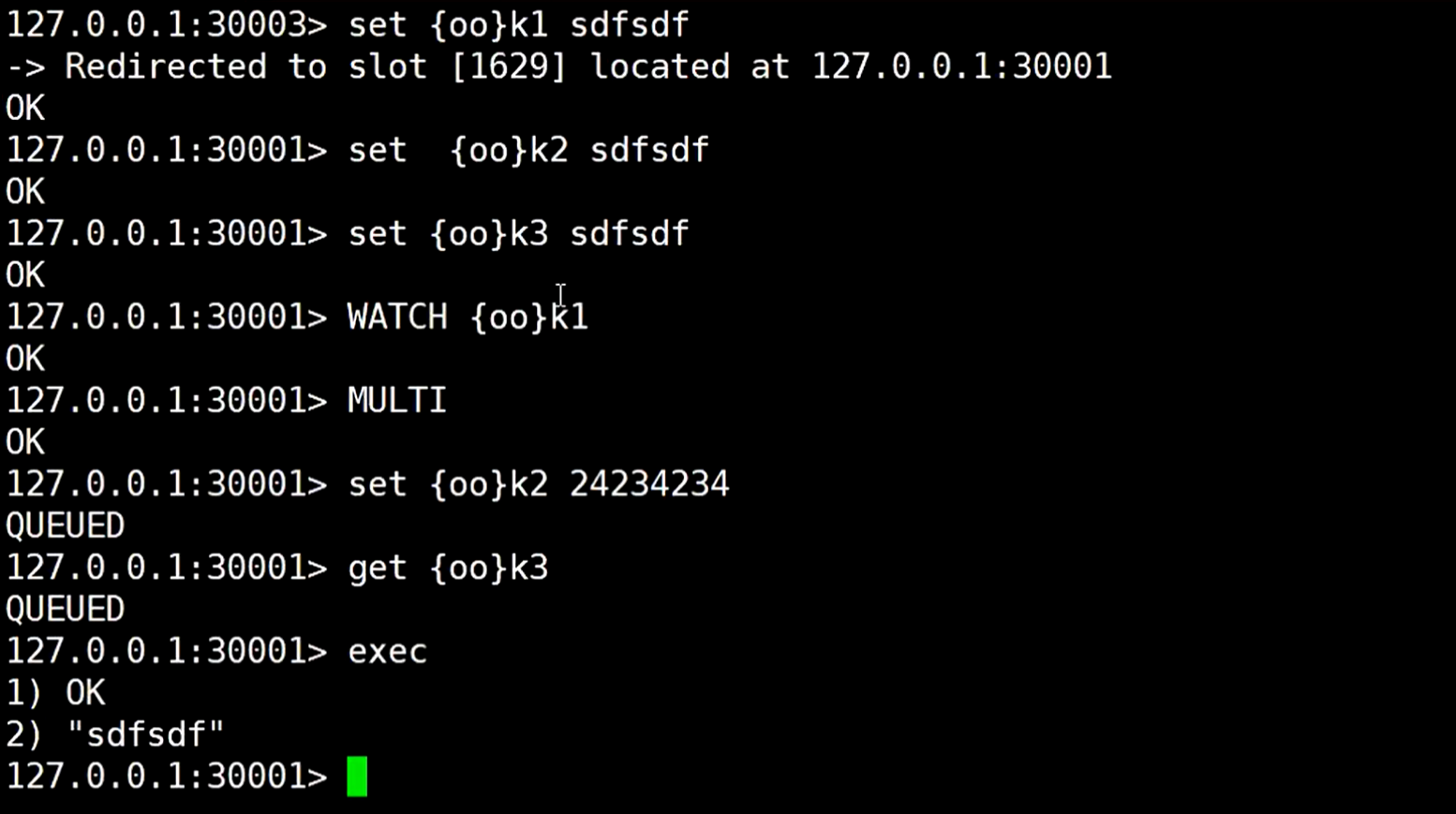
还有个有意思的
先把集群停掉,然后清空一下
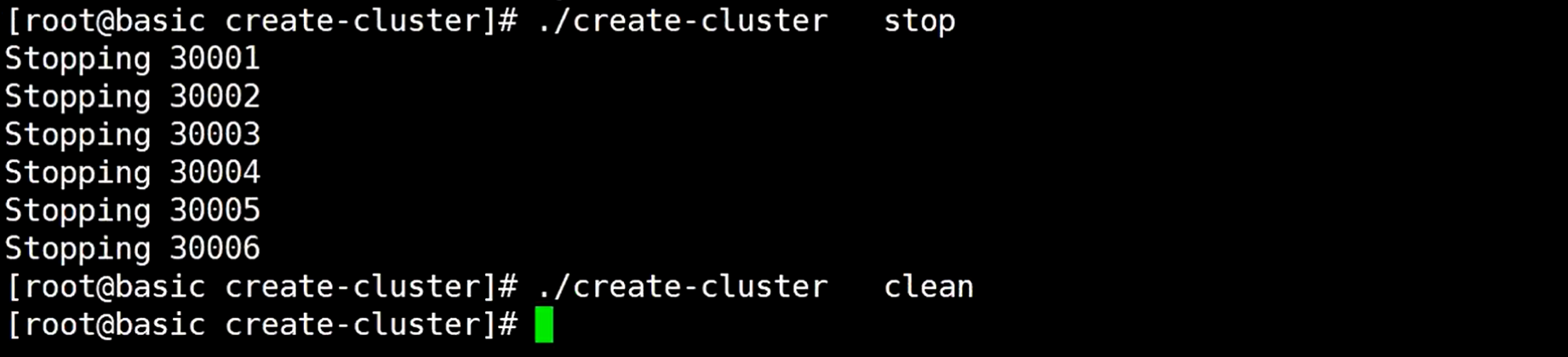
这样就还原了
启动它
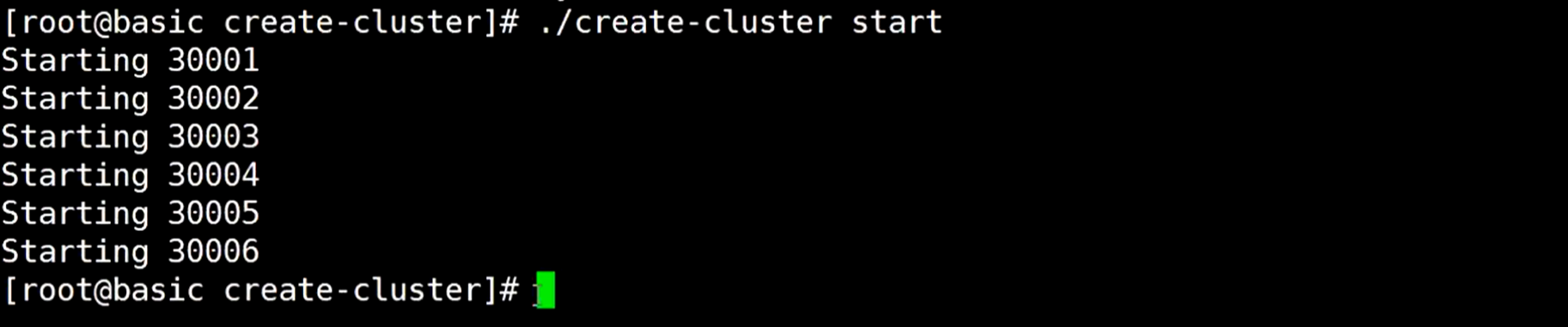
手动启动6台redis节点,这个虽然没有使用脚本启动,但这样启动更灵活,因为是通过ip指定的,所以可以这样启动分布式的集群


 浙公网安备 33010602011771号
浙公网安备 33010602011771号