2、java文件系统io
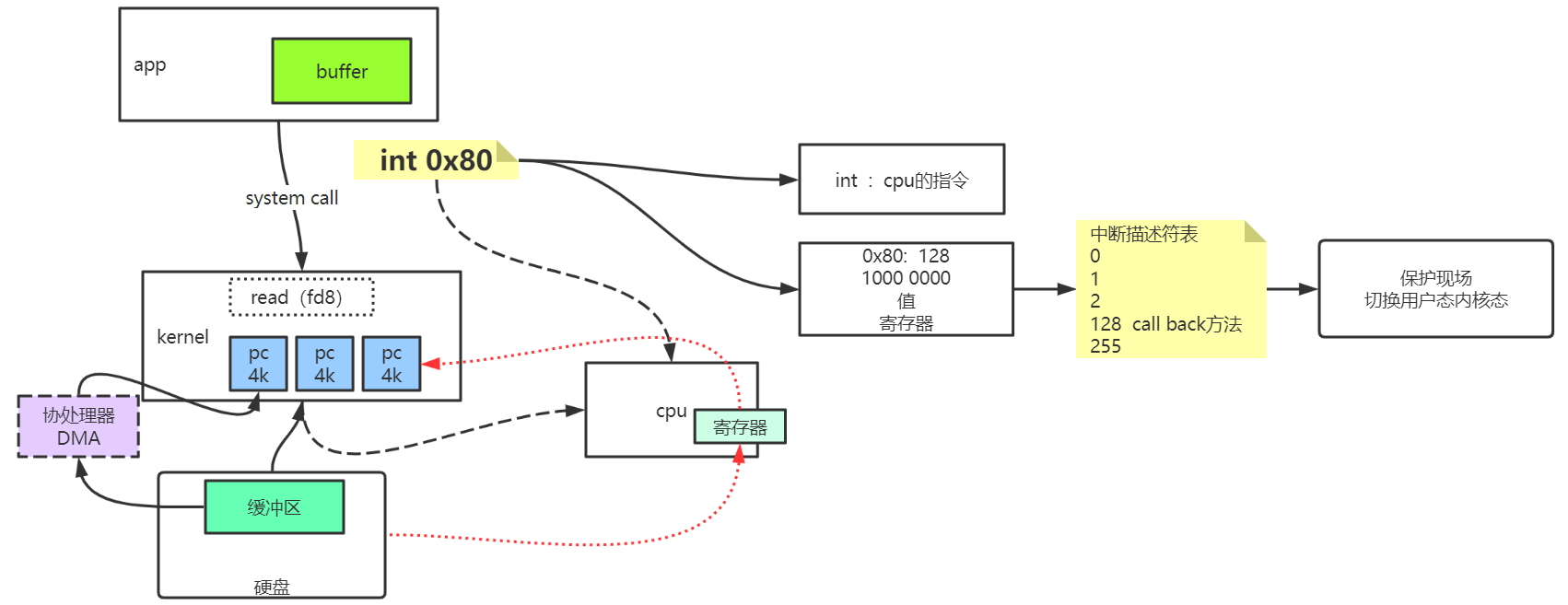
app是一个应用程序,应用程序有缓冲区,我们在写代码的时候,都用过Buffer。
应用程序肯定要访问内核,内核其实也是一个程序,应用程序和内核通信的时候,会调用一个system call(系统调用)。
system call 的实现是int 0x80,int是cpu的指令,0x80是16进制的,所以它的值是128,如果是二进制的话,就是10000000,它是一个值,这个值放在cpu的寄存器,然后和中断描述符(和中断控制器应该是一个意思)去匹配,终端描述符的128表示的就是call back方法,去调用的这个方法。
所以应用程序调用某一个系统调用的时候,其实完成了一个int 0x80,这条指令一但被cpu读到以后,就开始调用内核里的call back方法,然后就开始保护现场,从用户态切换到内核态。
cpu读应用程序去执行,也会去读内核里的指令去执行,中间不停的切换读取用户态(用户空间,应用程序)和内核态(内核空间),然后从哪开始读取指令呢?由这个call back方法告诉cpu,然后执行调度。
比如cpu要调用kernel去读取硬盘上面的数据给读取到,调用的read,其实调用的是它的文件描述符(fd),读的时候比如数据很多,会分成很多个4k大小的pagecache,这是内核的缓冲区,pagecache会分成消耗内存去压榨内存,是不会主动释放的。
数据从硬盘读取到内核缓冲区,硬盘里也有缓冲区,读取的时候有个东西叫协处理器(DMA),这是什么?
如果没有协处理器,cpu读取数据的时候,从硬盘读取一个字节放在cpu自己的寄存器里,然后再交给内核,然后再拷贝到buffer,数据拷贝这么多次,这种做法是很缓慢的。
协处理器可以直接把数据拷贝到内核里,这样的话cpu和协处理器可以交叉使用,都可以去读取硬盘的数据到内存里,并且这个时候cpu还可以去做其他事情,不至于说直接停在那里只在拷贝数据,这样会快很多。所以叫做协处理器。
linux正常关机和断电
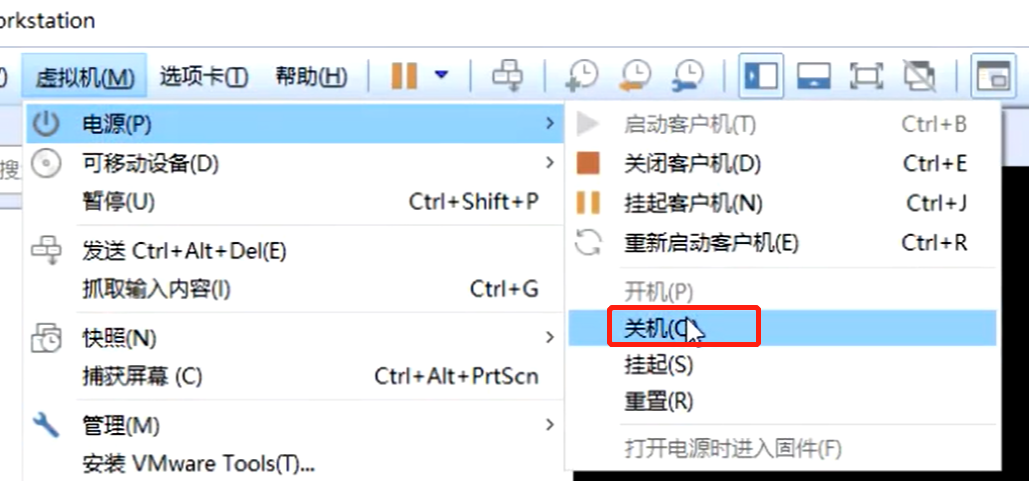
linux虚拟机有2种关机方式,如果是图下这种方式,属于是正常关机,就等于是点了一个关机键。这个电源会产生一个中断,会告诉cpu,你的主人要关机了,然后开始调用关机的过程,会把脏数据,pagecache缓存,有一个回写磁盘的过程,会保存数据。
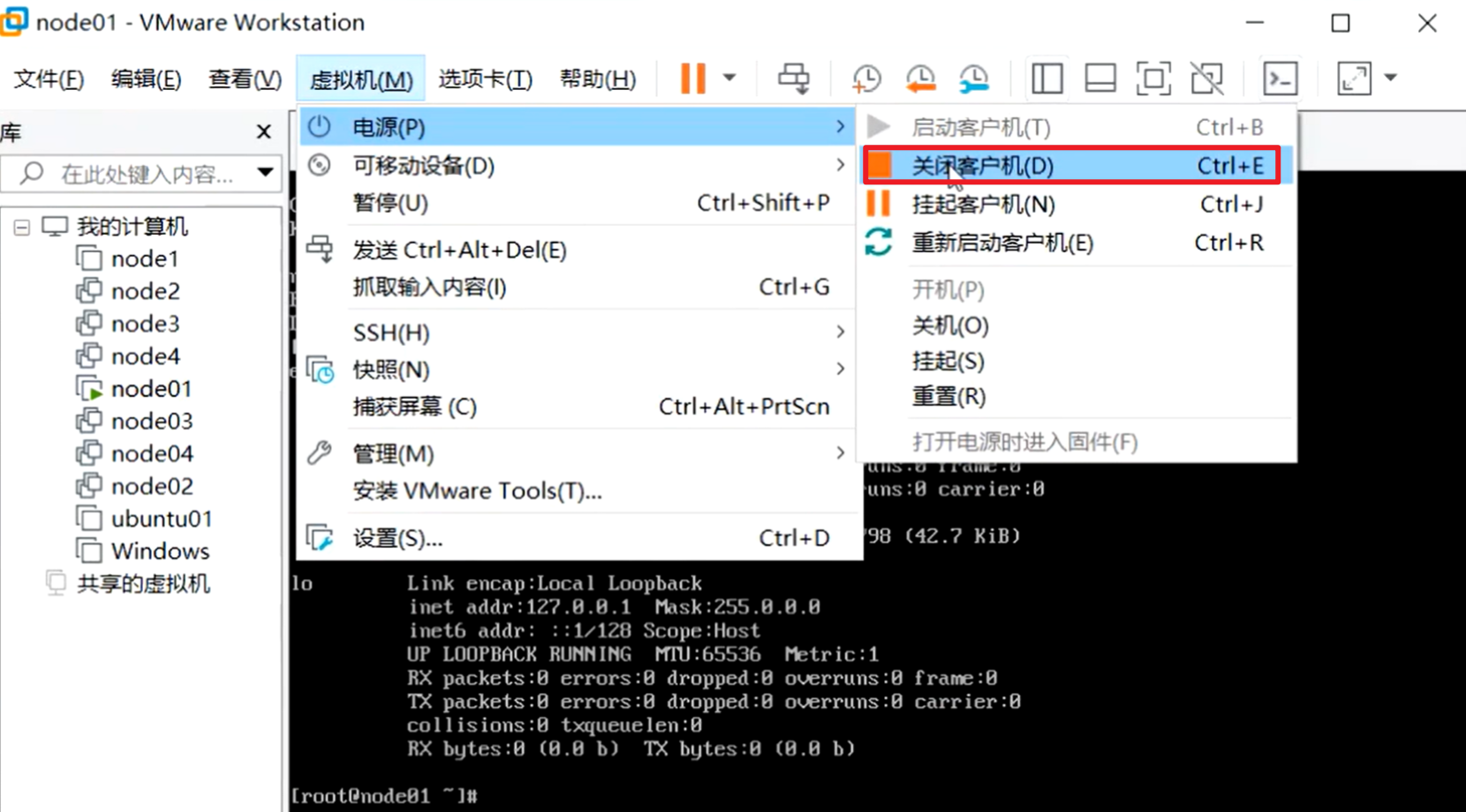
如下图这个关机,等同于直接把断电了,这样的话来不及把内存的脏数据和pagecache缓存的数据给刷出去。
验证:
打开虚拟机,查看mysh这个文件内容
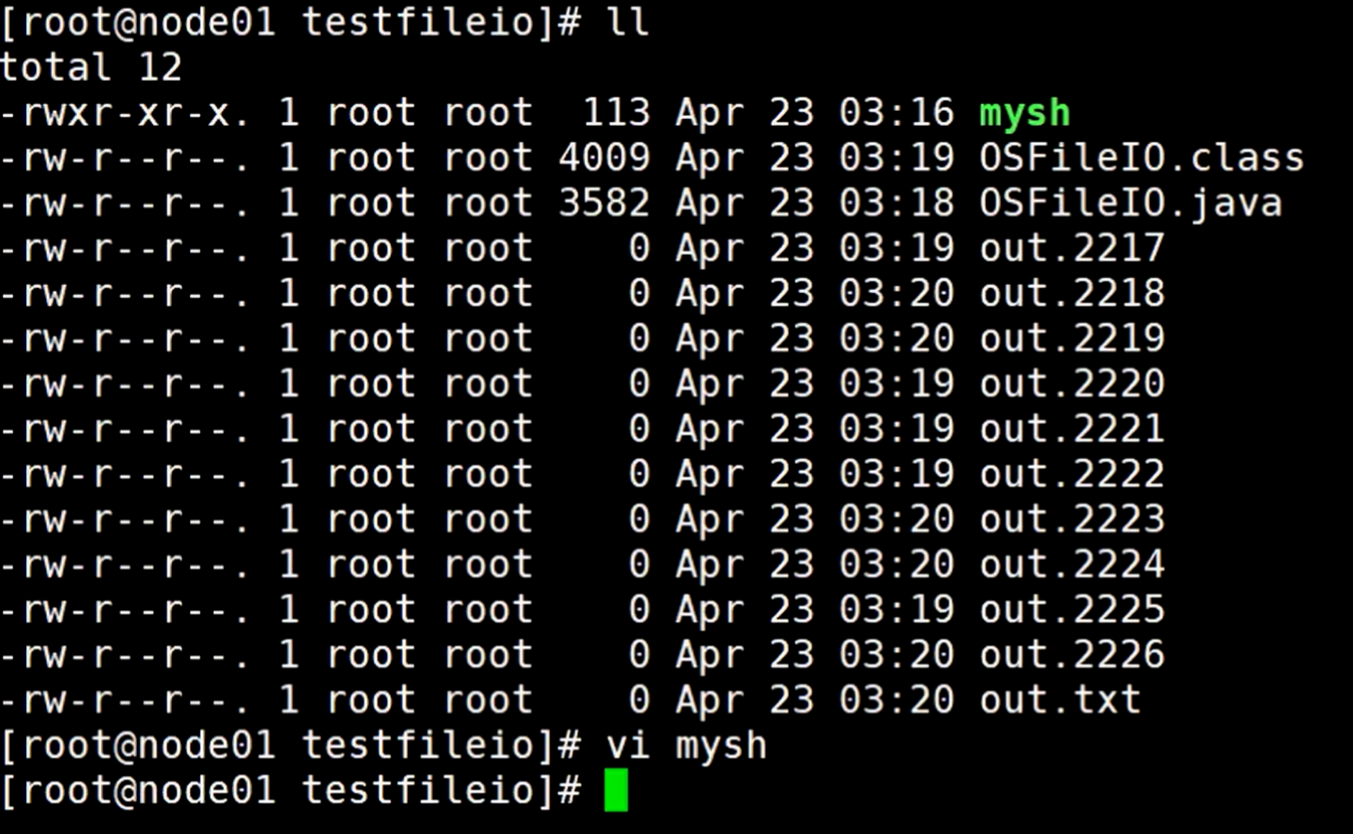
这个文件是个脚本,内容如下:

删除当前目录包含out的所有文件,并且用jdk1.8 javac编译 OSFileIO.java 这个文件,然后启动这个OSFileIO.java 这个类,传进入一个参数1
然后查看一下这个OSFileIO.java 类的代码:
源代码:
import org.junit.Test;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class OSFileIO {
static byte[] data = "123456789\n".getBytes();
static String path = "/root/testfileio/out.txt";
public static void main(String[] args) throws Exception {
switch ( args[0]) {
case "0" :
testBasicFileIO();
break;
case "1":
testBufferedFileIO();
break;
case "2" :
testRandomAccessFileWrite();
case "3":
// whatByteBuffer();
default:
}
}
//最基本的file写
public static void testBasicFileIO() throws Exception {
File file = new File(path);
FileOutputStream out = new FileOutputStream(file);
while(true){
Thread.sleep(10);
out.write(data);
}
}
//测试buffer文件IO
// jvm 8kB syscall write(8KBbyte[])
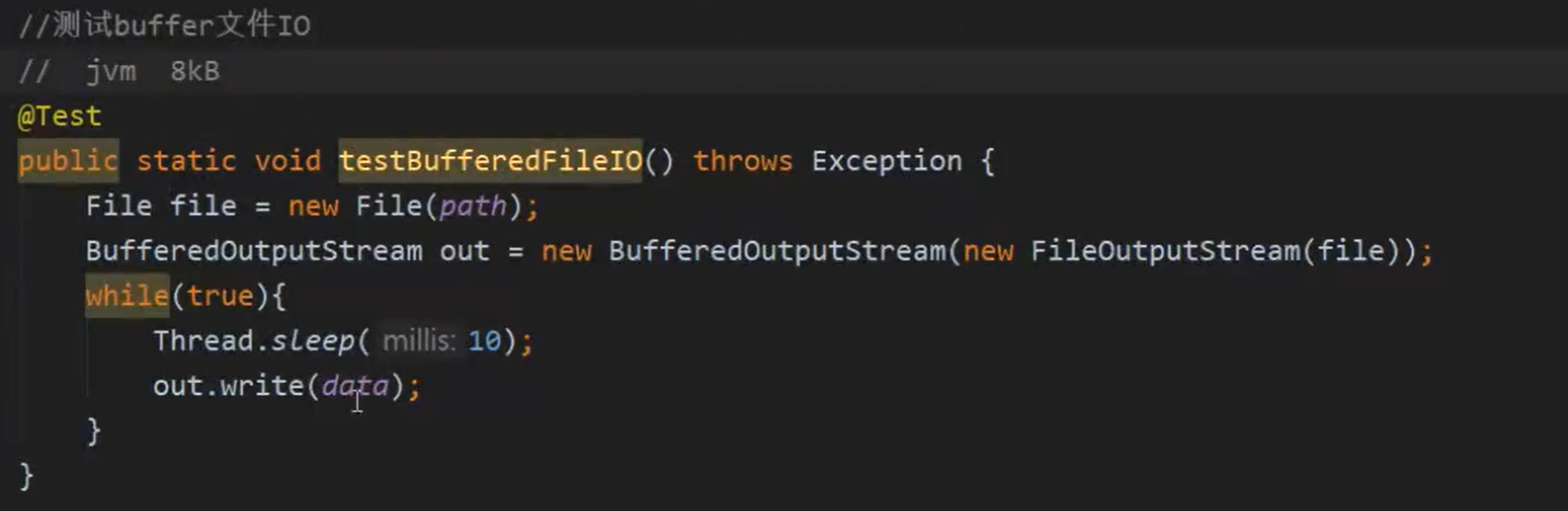
public static void testBufferedFileIO() throws Exception {
File file = new File(path);
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(file));
while(true){
Thread.sleep(10);
out.write(data);
}
}
//测试文件NIO
public static void testRandomAccessFileWrite() throws Exception {
RandomAccessFile raf = new RandomAccessFile(path, "rw");
raf.write("hello mashibing\n".getBytes());
raf.write("hello seanzhou\n".getBytes());
System.out.println("write------------");
System.in.read();
raf.seek(4);
raf.write("ooxx".getBytes());
System.out.println("seek---------");
System.in.read();
FileChannel rafchannel = raf.getChannel();
//mmap 堆外 和文件映射的 byte not objtect
MappedByteBuffer map = rafchannel.map(FileChannel.MapMode.READ_WRITE, 0, 4096);
map.put("@@@".getBytes()); //不是系统调用 但是数据会到达 内核的pagecache
//曾经我们是需要out.write() 这样的系统调用,才能让程序的data 进入内核的pagecache
//曾经必须有用户态内核态切换
//mmap的内存映射,依然是内核的pagecache体系所约束的!!!
//换言之,丢数据
//你可以去github上找一些 其他C程序员写的jni扩展库,使用linux内核的Direct IO
//直接IO是忽略linux的pagecache
//是把pagecache 交给了程序自己开辟一个字节数组当作pagecache,动用代码逻辑来维护一致性/dirty。。。一系列复杂问题
System.out.println("map--put--------");
System.in.read();
// map.force(); // flush
raf.seek(0);
ByteBuffer buffer = ByteBuffer.allocate(8192);
// ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
int read = rafchannel.read(buffer); //buffer.put()
System.out.println(buffer);
buffer.flip();
System.out.println(buffer);
for (int i = 0; i < buffer.limit(); i++) {
Thread.sleep(200);
System.out.print(((char)buffer.get(i)));
}
}
@Test
public void whatByteBuffer(){
// ByteBuffer buffer = ByteBuffer.allocate(1024);
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
System.out.println("postition: " + buffer.position());
System.out.println("limit: " + buffer.limit());
System.out.println("capacity: " + buffer.capacity());
System.out.println("mark: " + buffer);
buffer.put("123".getBytes());
System.out.println("-------------put:123......");
System.out.println("mark: " + buffer);
buffer.flip(); //读写交替
System.out.println("-------------flip......");
System.out.println("mark: " + buffer);
buffer.get();
System.out.println("-------------get......");
System.out.println("mark: " + buffer);
buffer.compact();
System.out.println("-------------compact......");
System.out.println("mark: " + buffer);
buffer.clear();
System.out.println("-------------clear......");
System.out.println("mark: " + buffer);
}
}
编辑一下
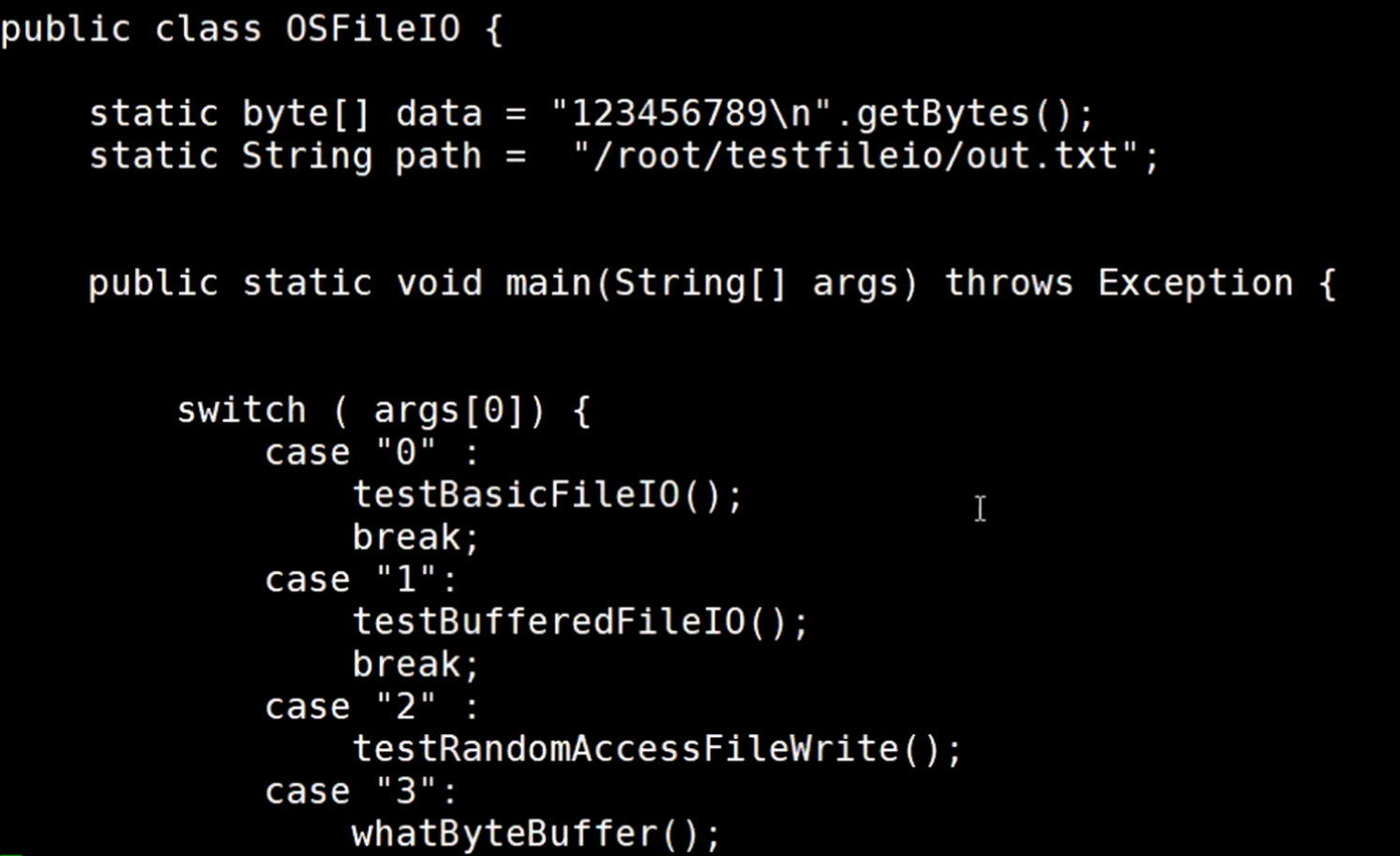
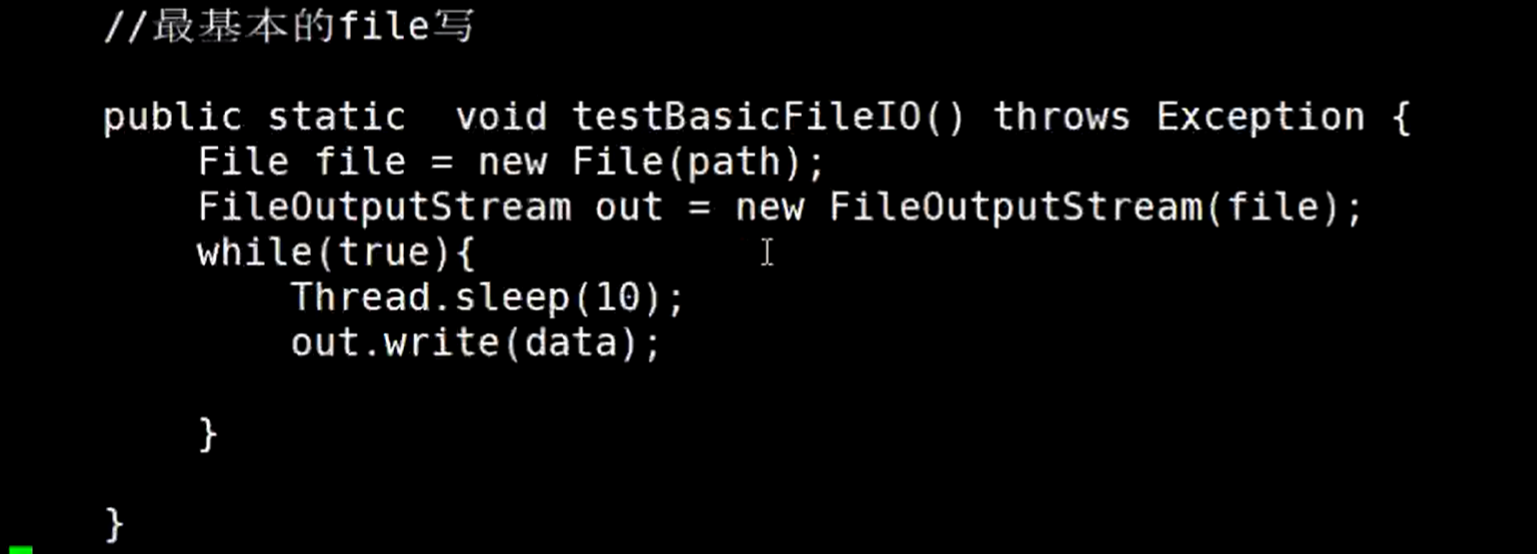
定义了data 和 path 两个属性,然后main方法有个switch,如果参数为0,就调用testBasicFileIO()方法,
testBasicFileIO()方法中写的是,通过new File() 获取一个文件,然后往这个文件输出data的数据,data是在上面定义好了的,在while死循环中不停的写入数据。
查看完代码以后,调用这个mysh脚本,传入参数0,就可以调用testBasicFileIO()方法了

启动后,不停的使用ll 命令查看out.txt文件,
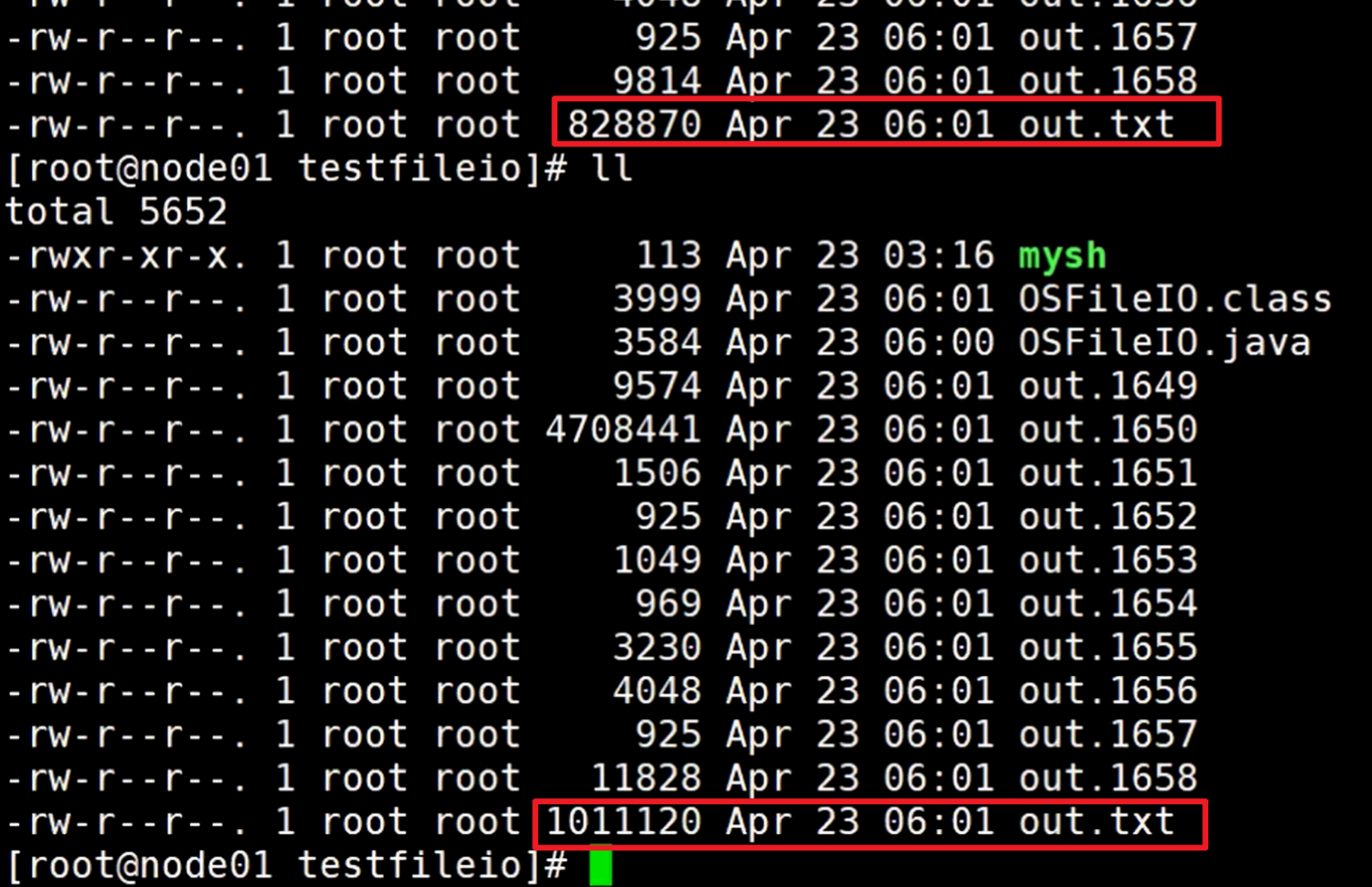
上图可以看见内容大小在不断的变大,在这个时候直接点击这个关机,等于蒿掉电源,直接断电了
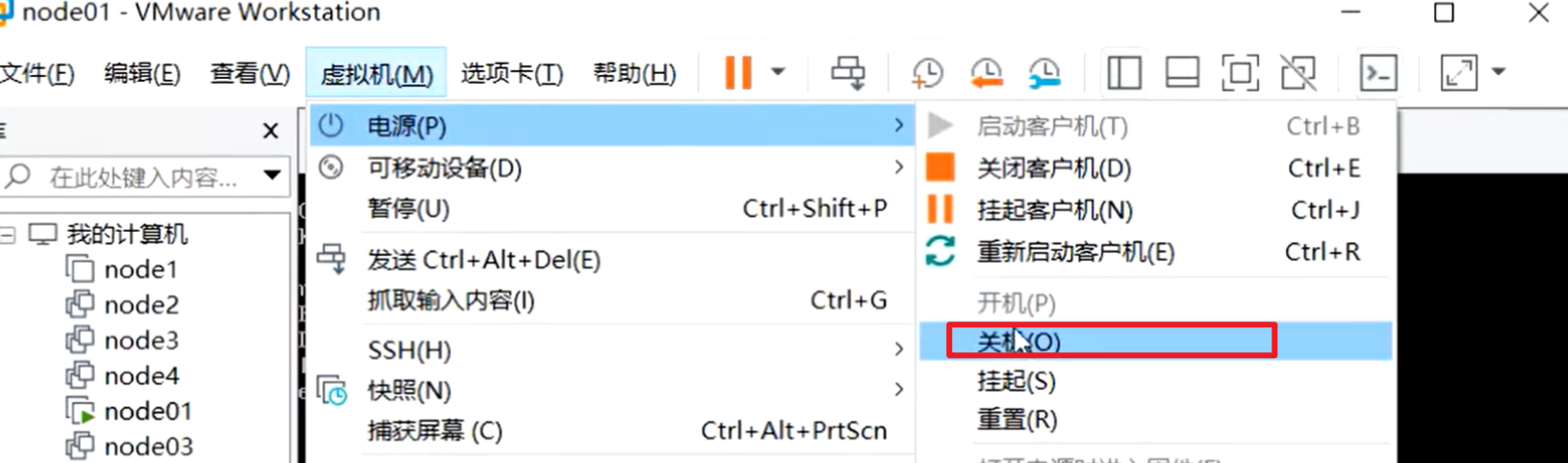
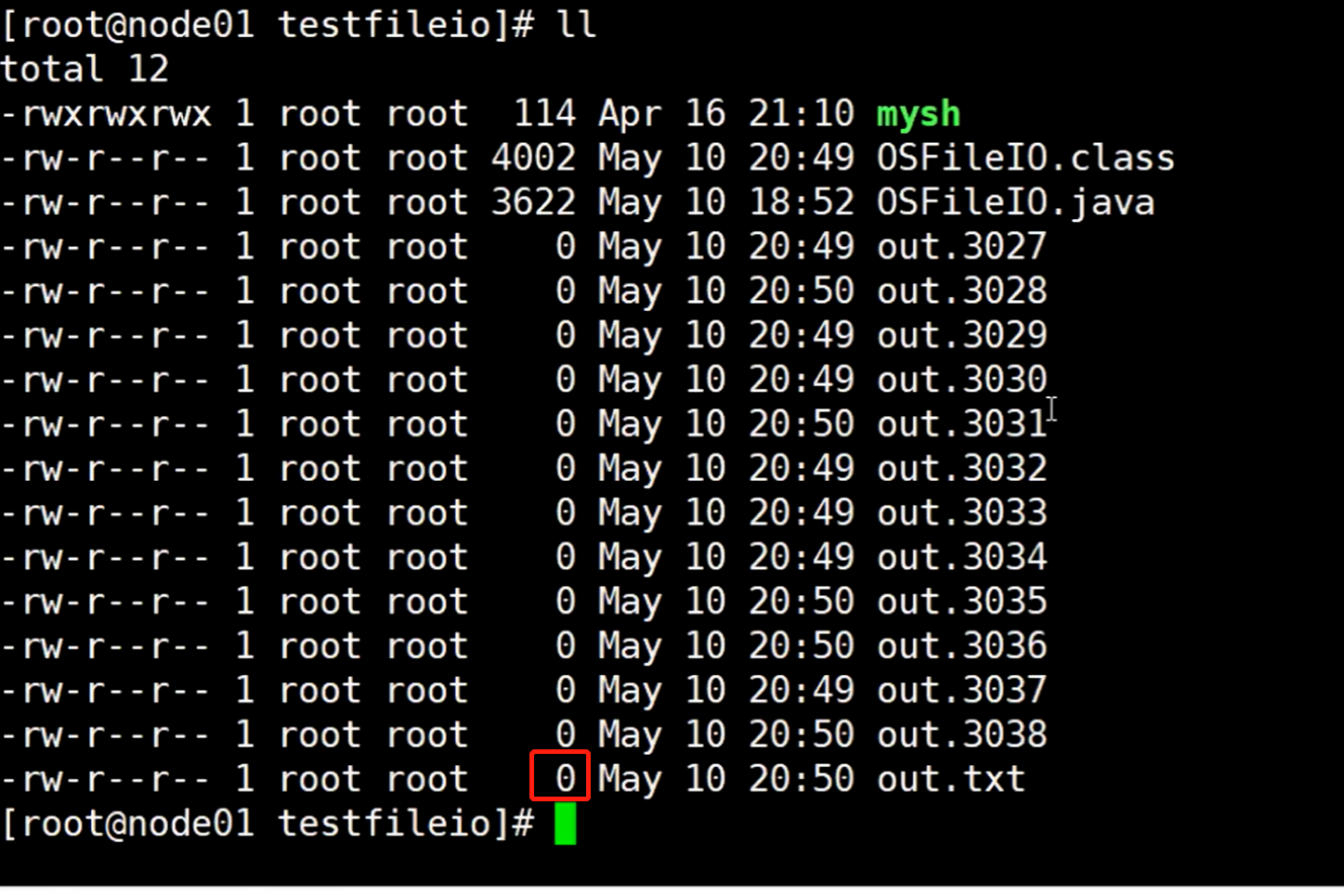
关机以后在重启启动这个虚拟机,查看out.txt文件可以看到,这个文件大小为0
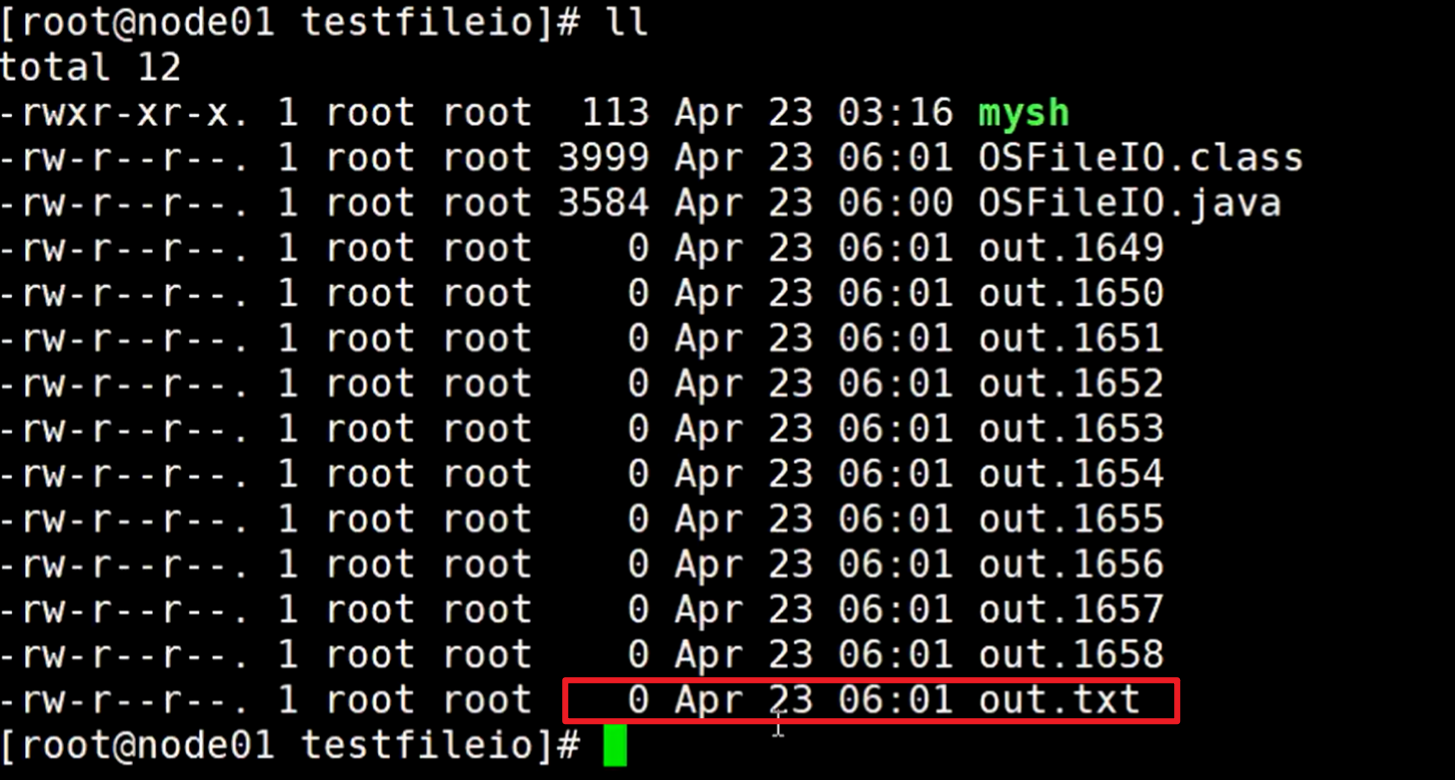
所以就验证了,数据在内存中pagecache不停的修改写入数据,在它还没有来得及把数据刷出去保存到磁盘上面的时候,直接给他断电,数据就丢失了。
配置pagecache的数据写入磁盘
sysctl -a | grep dirty:通过管道查询dirty的配置项
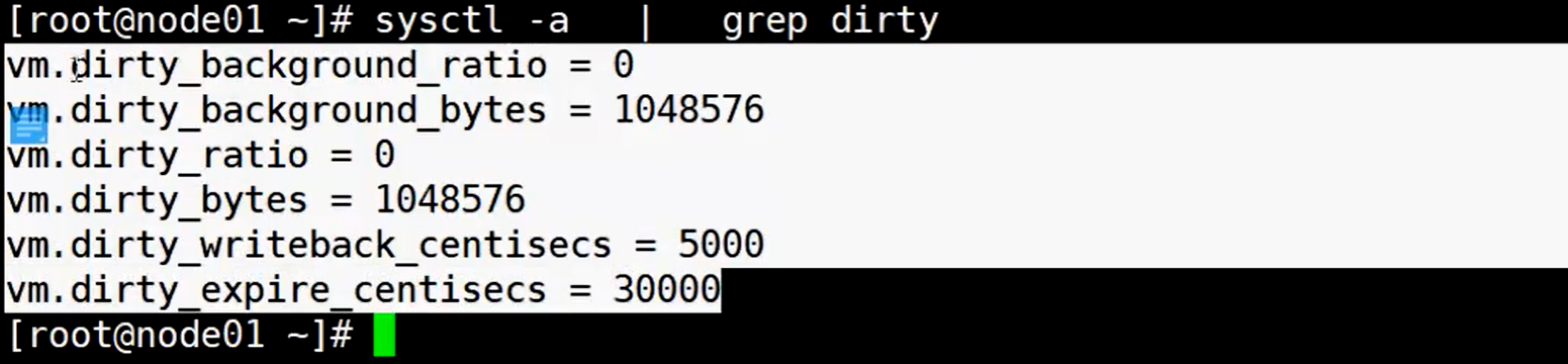
这些配置项都是阈值 对应着字节数
接下来给这个配置项做一个修改,这个配置项在/etc/sysctl.conf
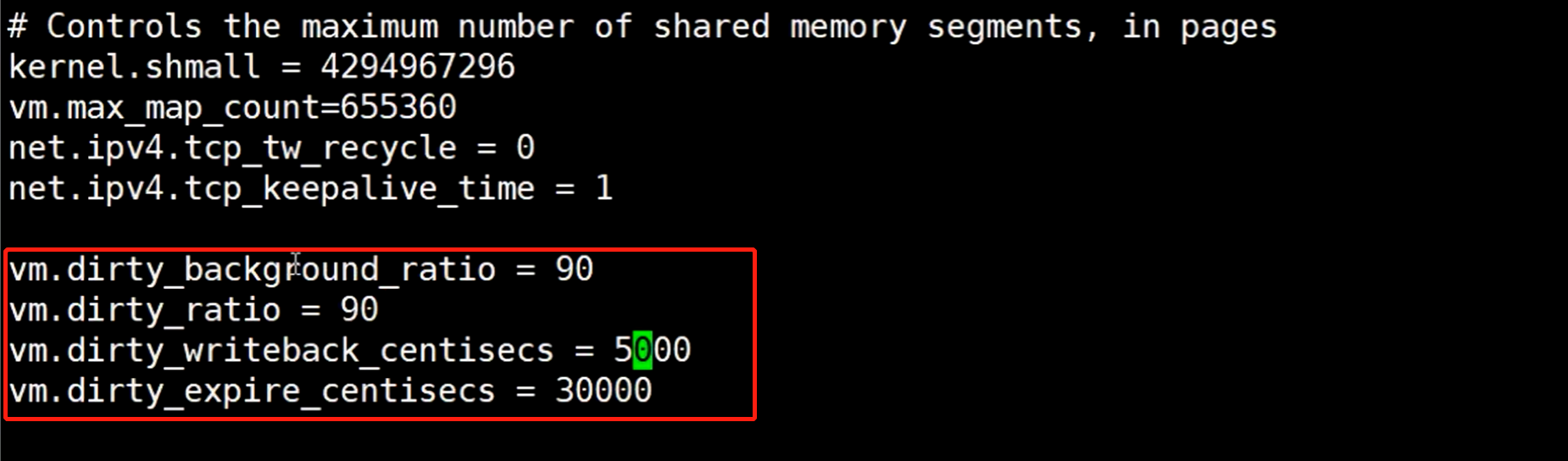
- vm.dirty_background_radio:90 表示90%,内核内存比如有10G,当pagecache占用了9G时候,内核会有里另一个线程把数据同步到磁盘,剩下的10%内存会接着给用户程序使用。但如果写入的数据很快,可能会报错,因为内核还没来得及把数据写入磁盘。
- vm.dirty_ratio:这个90表示pagecache的容量达到了内存90%,直接阻塞,用户程序不允许继续往内存写数据,会先把数据同步到磁盘,然后继续允许用户写数据。
- vm.dirty_writeback_centisecs:单位是1%秒,表示多久写入一次数据到磁盘,5000就是50秒
- vm.dirty_expire_centisecs:单位是1%秒,数据在pagecache存放时间,3000就是30秒
改完sysctl.conf 文件以后,sysctl -p执行一下,不然不生效
想象一下redis的日志保存和mysql的binLog保存信息,它们有3种方式保存数据:每秒钟保存一次、每操作一次保存一次、根据内核来保存。
为什么要有这3种方式?因为数据写入在pagecache,不会立马写入磁盘,发生意外有可能会丢失很多数据!
使用直接io和buffer的区别
普通io
使用ll -h && pcstat out.txt命令,查看这个out.txt 文件大小,和在内核中的分页情况
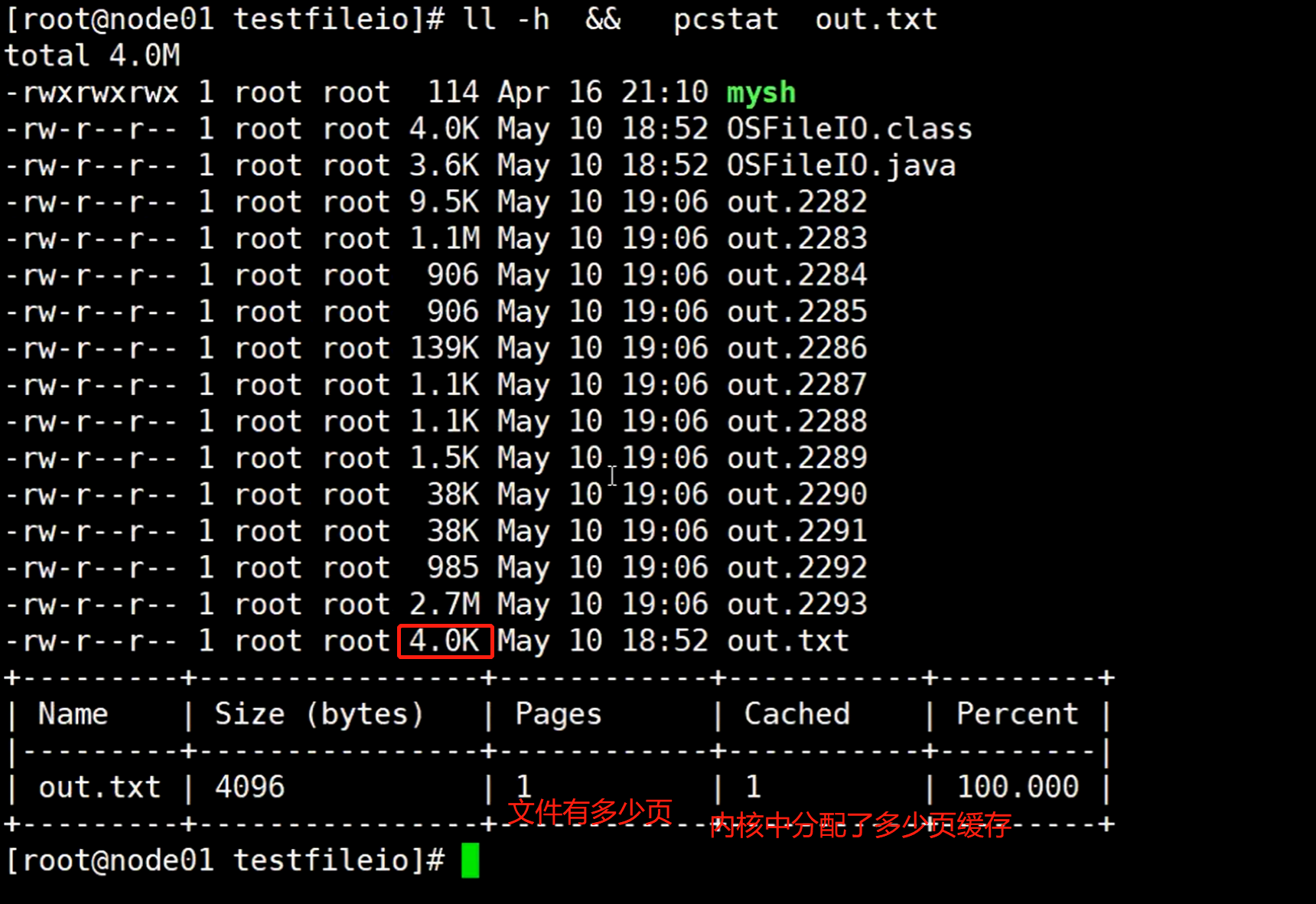
最好的100.000 表示百分比是多少(文件总页和内核中分配的页数量占比)
查看mysh 文件内容:

然后执行这个mysh 执行文件

执行后一直不停的使用ll -h && pcstat out.txt命令查看文件大小情况
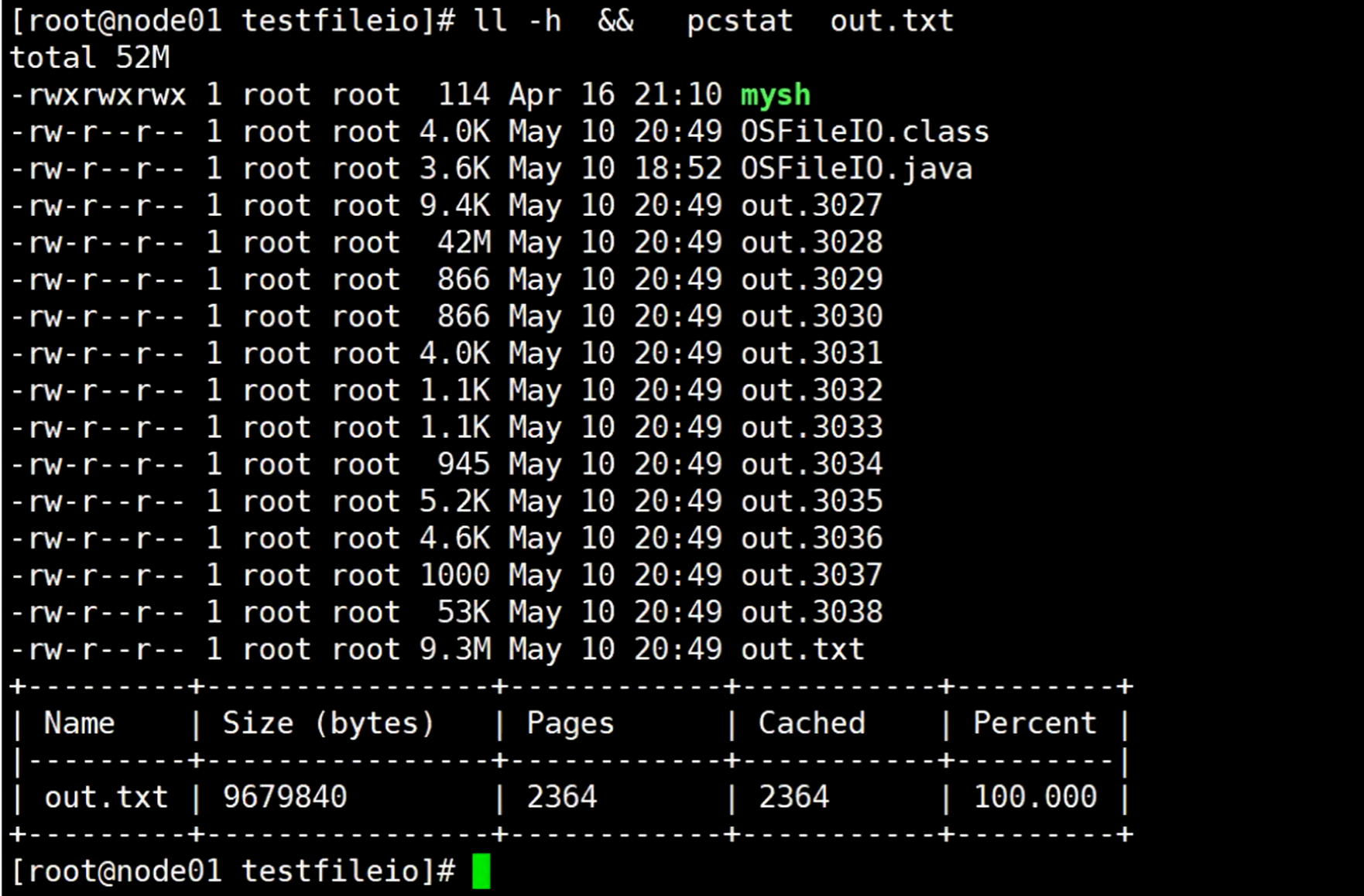
这个就等于有一个字节就立马写入服务器的内存,所以会一直不断的切换核态,pagecache使用情况也一直都是100%。
如果这个时候给它断电,数据是整个都丢失了,不会保存到磁盘。
然后开机,继续查看那个out.txt文件,发现刚刚写的好几M大小的文件变成了0大小,数据丢失了
使用buffer
接下来调用这个testBufferedFileIO()方法
使用mysh这个执行文件,参数1表示调用这个testBufferedFileIO()方法

然后不停的在另一个窗口查看out.txt文件大小信息
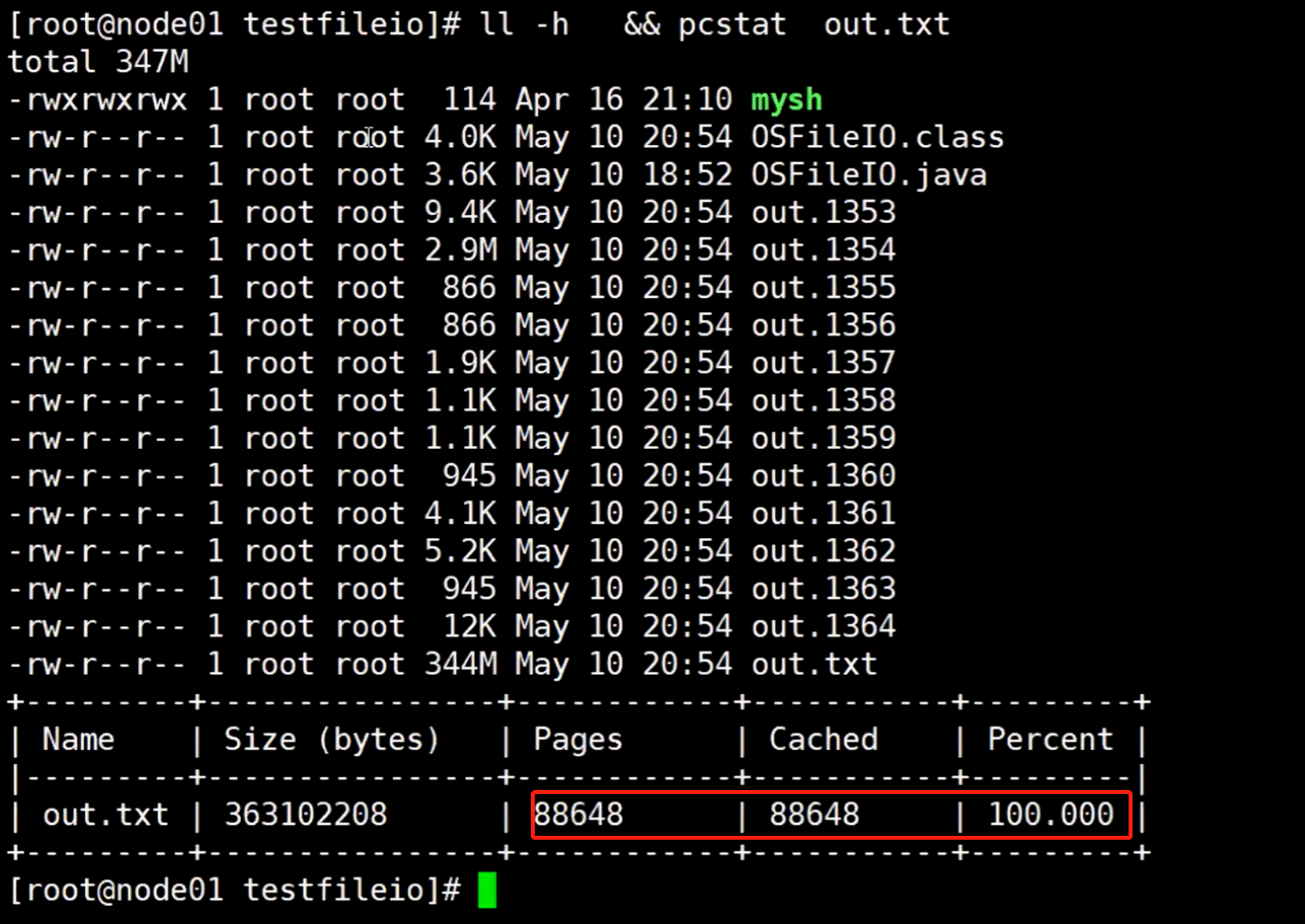
这个等于使用buffer,可以很明显的发现这个out.txt 文件大小增长的非常快(这也说明了为什么java一定要用buffer的io),它使用了buffer,每攒够10个字节的数据就调用一次操作系统内核,所以相比较使用直接io的话,减少了调用内核的次数,避免了不停的切换核态。
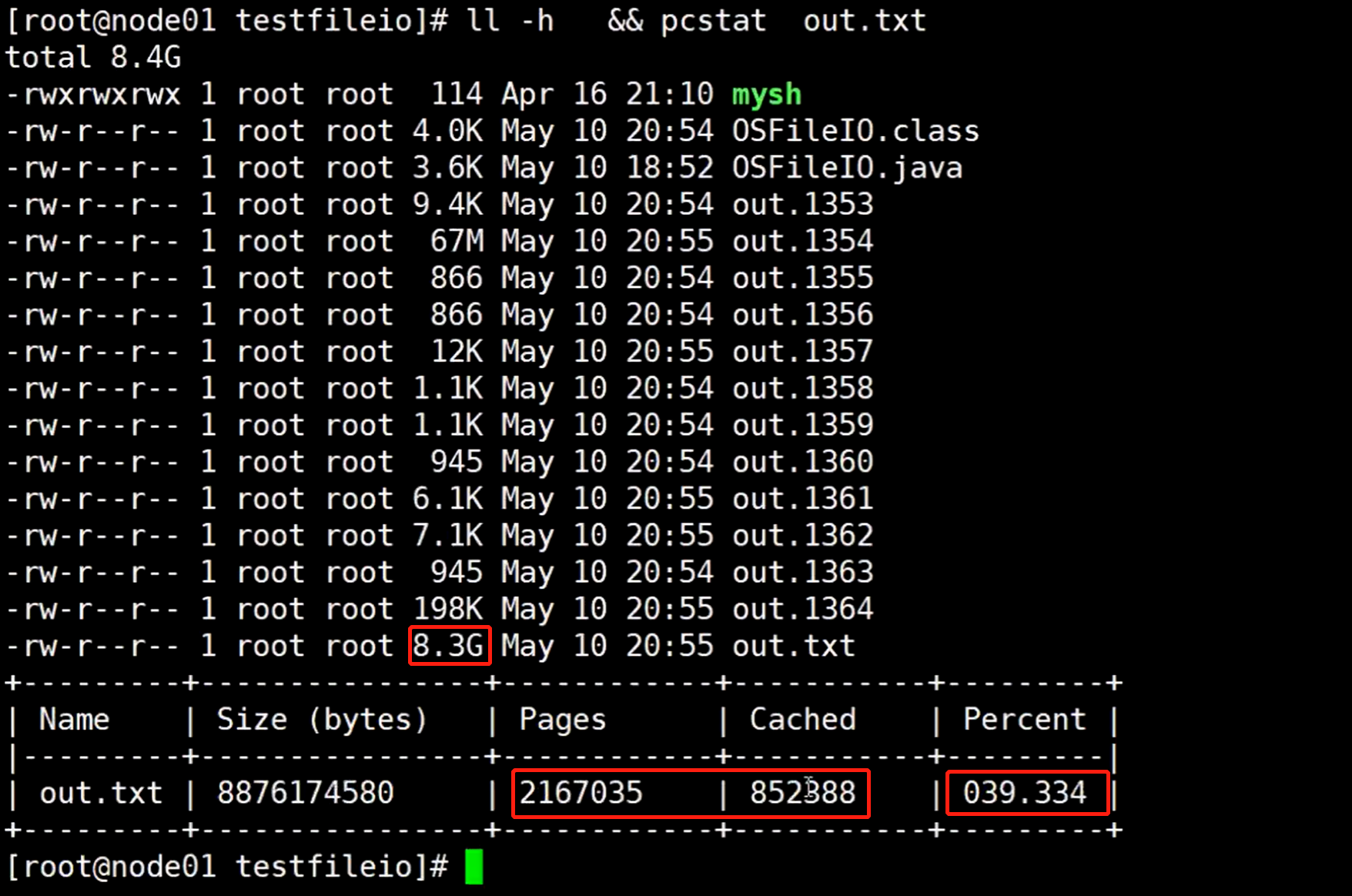
刚开始发现pagecache使用率也是100%,但是等到写入数据的大小超过内存的3G大小以后,pagecache使用率慢慢的变小,因为这个时候说明已经在往磁盘写入数据了。
如果把这个文件改名为OOXX.txt 文件,可以查看到pagecache里面还是有和这个文件的关联数据。
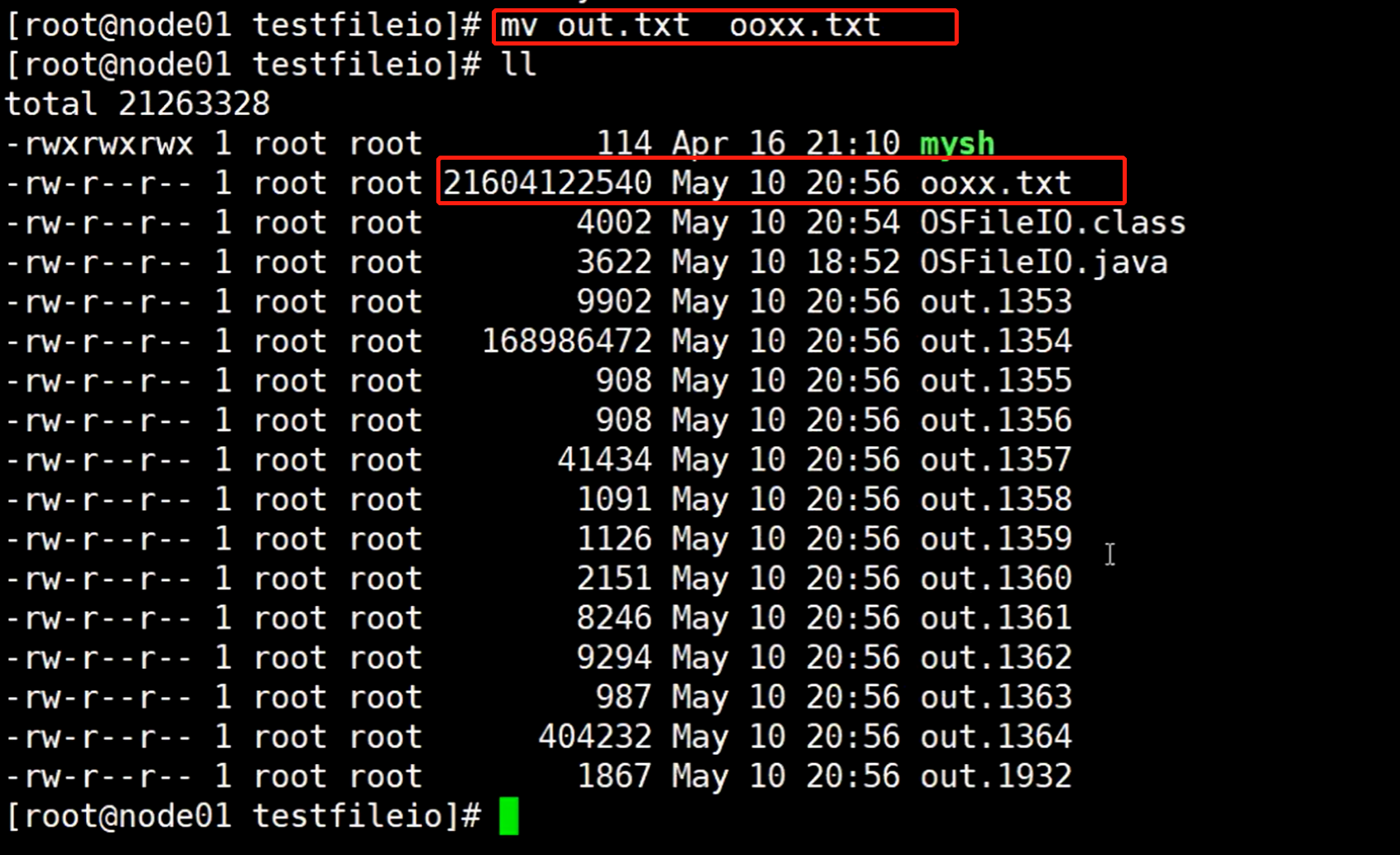
如果这个时候再重新启动这个buffer的io,那它肯定会重新写入一个新的out.txt文件,然后疯狂的给内核缓冲区分配页缓存,肯定会占用那个OOXX.txt 文件之前的页缓存
可以看到这个ooxx.txt 文件现在的页缓存比例,说明还是有缓存很多东西在内核缓冲区的
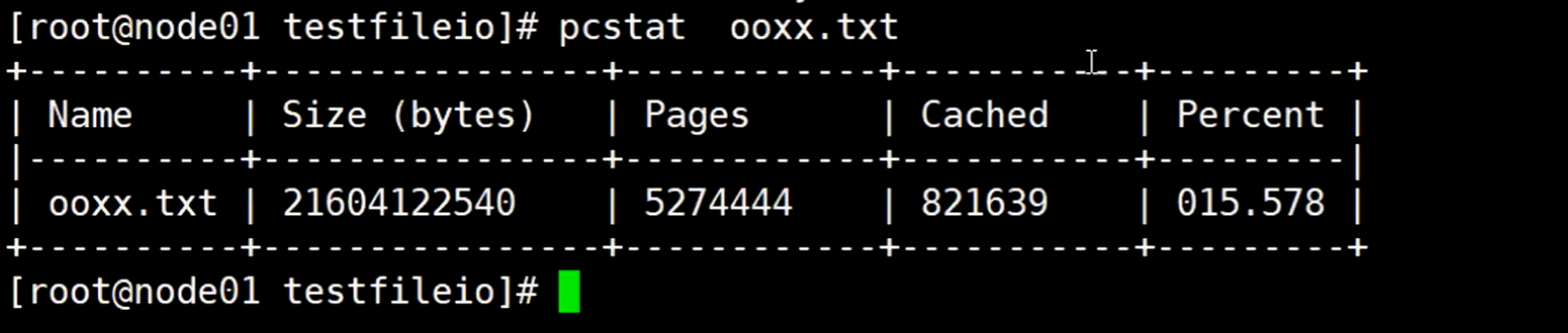
然后再次启动mysh执行文件,重新向一个新的out.txt文件写入
然后使用pcstat out.txt && pcstat ooxx.txt命令,同时查看这两个文件的页缓存情况
不停的查看
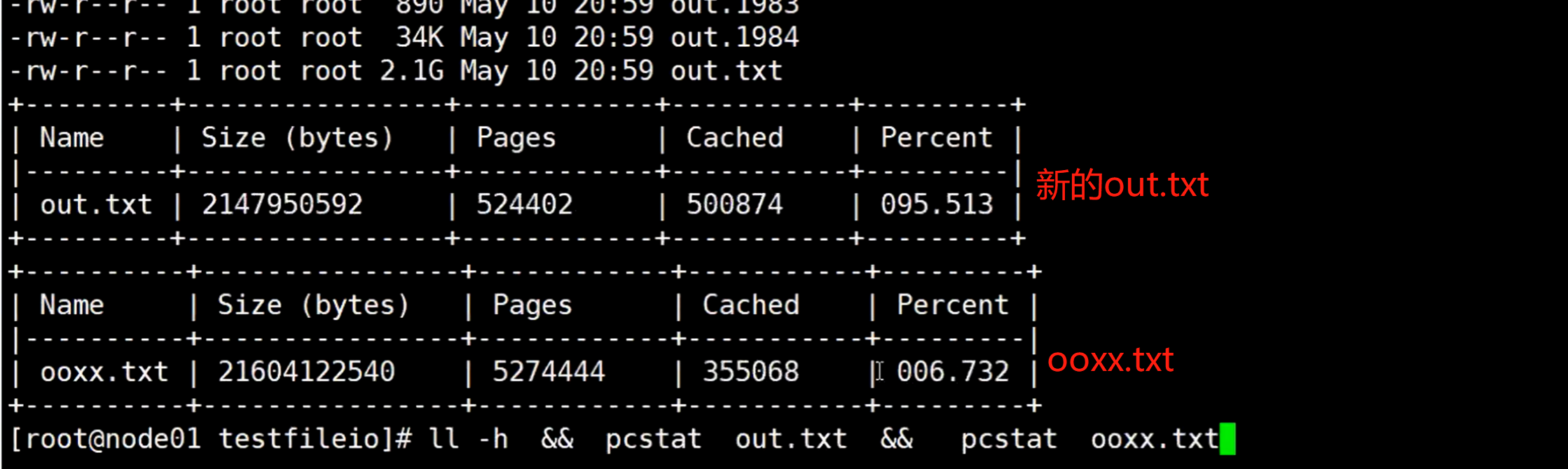
但这个时候可以发现之前这个OOXX.txt 文件的pagecache使用率慢慢减少,被淘汰掉了(淘汰掉之前会把数据同步到磁盘),从而保证这个新的out.txt文件有相对应的文件页缓存
通过buffer的io写入数据虽然很快,但是如果断电的话,数据会丢失很多。
虽然看到的这个out.txt文件已经变得很大了,但实际它查询的是虚拟文件系统,并没有实际写入磁盘。
所以pagecache的优点就是提升io性能,缺点就是丢失数据。
nio
nio就理解是new io,意思是新的io体系。
新的io体系有两个概念:channel、byteBuffer
nio也是基于buffer的,channel等于是把输入输出整合到了一起。
ByteBuffer
ByteBuffer就理解成字节数组,有一些对应的api和概念。
allocate() 和 allocateDirect() 不影响最终结果,只是分配方式不一样。
测试代码:
@Test
public void whatByteBuffer(){
// ByteBuffer buffer = ByteBuffer.allocate(1024);
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
System.out.println("postition: " + buffer.position());
System.out.println("limit: " + buffer.limit());
System.out.println("capacity: " + buffer.capacity());
System.out.println("mark: " + buffer);
buffer.put("123".getBytes());
System.out.println("-------------put:123......");
System.out.println("mark: " + buffer);
buffer.flip(); //读写交替
System.out.println("-------------flip......");
System.out.println("mark: " + buffer);
buffer.get();
System.out.println("-------------get......");
System.out.println("mark: " + buffer);
buffer.compact();
System.out.println("-------------compact......");
System.out.println("mark: " + buffer);
buffer.clear();
System.out.println("-------------clear......");
System.out.println("mark: " + buffer);
}
执行结果:
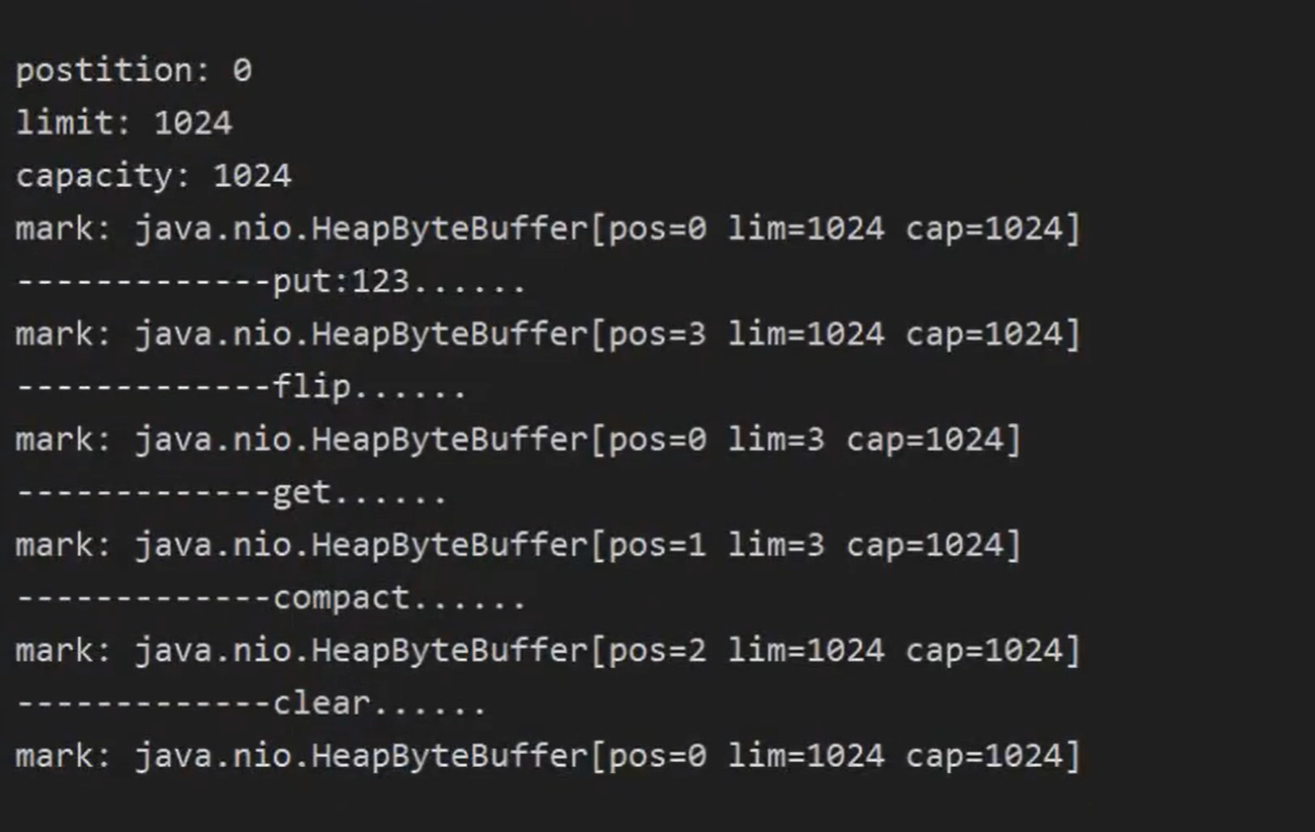
- postition: 表示写入时候的指针位置
- limit:写入和读取时候指针截止位置(写入和读取时会切换位置)
- capacity:表示buffer剩余空间,总大小。如果前面有已经读取过的字节,不能算在内。所以写入的时候需要capacity一下
postition 和 limit 两个指针位置在读或写的时候联动发生变化
抽象逻辑图:
刚开始:
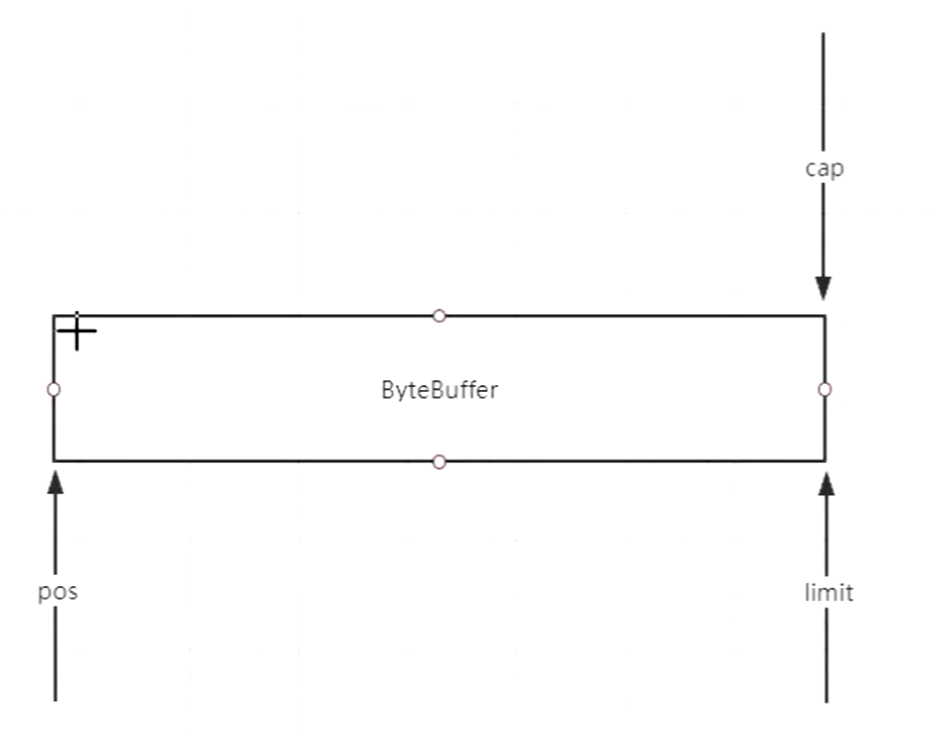
put了123,3个字节后

flip() 翻转,翻转的目的是读写交替时候
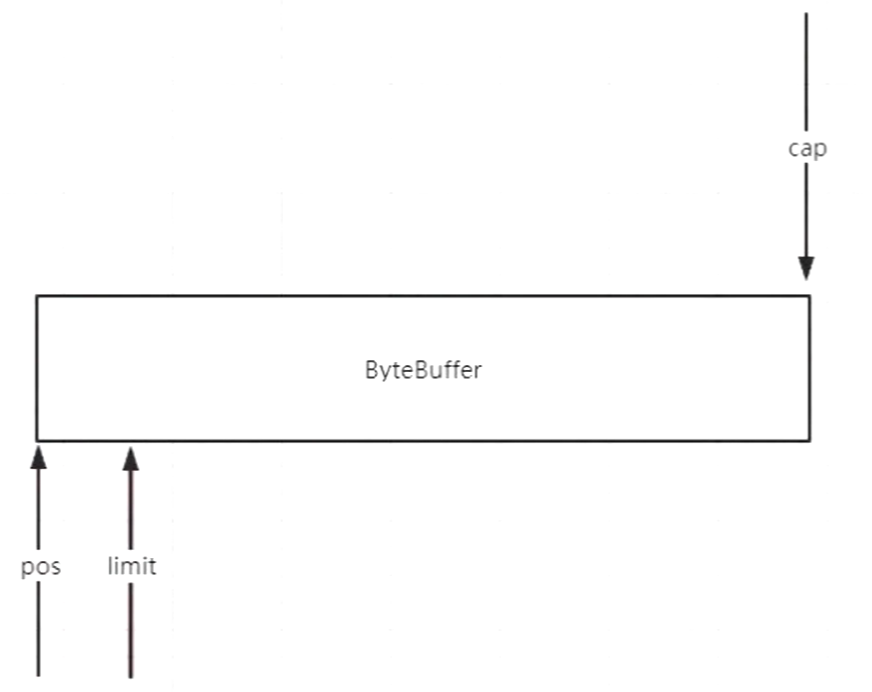
compact()后,得到的buffer剩余的空间
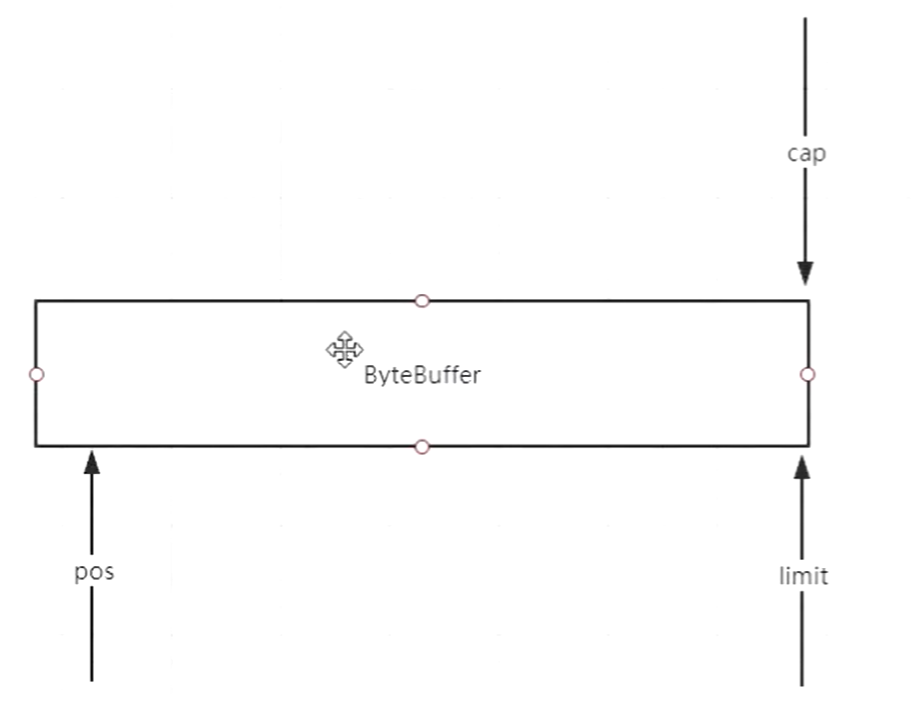
基于文件的NIO
测试代码:
//测试文件NIO
public static void testRandomAccessFileWrite() throws Exception {
// 使用RandomAccessFile(); 给出文件路径,给出权限,r表示可读,w表示可写
RandomAccessFile raf = new RandomAccessFile(path, "rw");
// write()表示普通的写,
raf.write("hello mashibing\n".getBytes());
raf.write("hello seanzhou\n".getBytes());
System.out.println("write------------");
System.in.read();
// seek()指定字符下标指针偏移位置,写的内容会覆盖掉之前的字符。
// 因为向文件写入数据的时候只能一直向后写,如果想要postition指针向前,是不行的,所以调用seek()方法可以修改postition指针指定位置。
raf.seek(4);
raf.write("ooxx".getBytes());
System.out.println("seek---------");
System.in.read();
// getChannel()获取io通道,
FileChannel rafchannel = raf.getChannel();
//mmap 堆外 和文件映射的 byte not objtect
MappedByteBuffer map = rafchannel.map(FileChannel.MapMode.READ_WRITE, 0, 4096);
// 只有文件系统有map()方法,只有map()方法返回MappedByteBuffer(堆外的,并且和文件映射的)
// 如果是ByteBuffer上面获取,只能获取堆上的和堆外的内存空间
map.put("@@@".getBytes()); //不是系统调用 但是数据会到达 内核的pagecache
//曾经我们是需要out.write() 这样的系统调用,才能让程序的data 进入内核的pagecache
//曾经必须有用户态内核态切换
//mmap的内存映射,依然是内核的pagecache体系所约束的!!!
//换言之,pagecache体系会丢数据
//你可以去github上找一些 其他C程序员写的jni扩展库,使用linux内核的Direct IO(直接io)
//直接IO是忽略linux的pagecache
//是把pagecache 交给了程序自己开辟一个字节数组当作pagecache,动用代码逻辑来维护一致性/dirty(脏数据)。。。一系列复杂问题
System.out.println("map--put--------");
System.in.read();
// map.force(); // 等于flush,刷写数据到磁盘
raf.seek(0);
ByteBuffer buffer = ByteBuffer.allocate(8192);
// ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
int read = rafchannel.read(buffer); //buffer.put()
System.out.println(buffer);
buffer.flip();
System.out.println(buffer);
for (int i = 0; i < buffer.limit(); i++) {
Thread.sleep(200);
System.out.print(((char)buffer.get(i)));
}
}
抽象原理逻辑图:
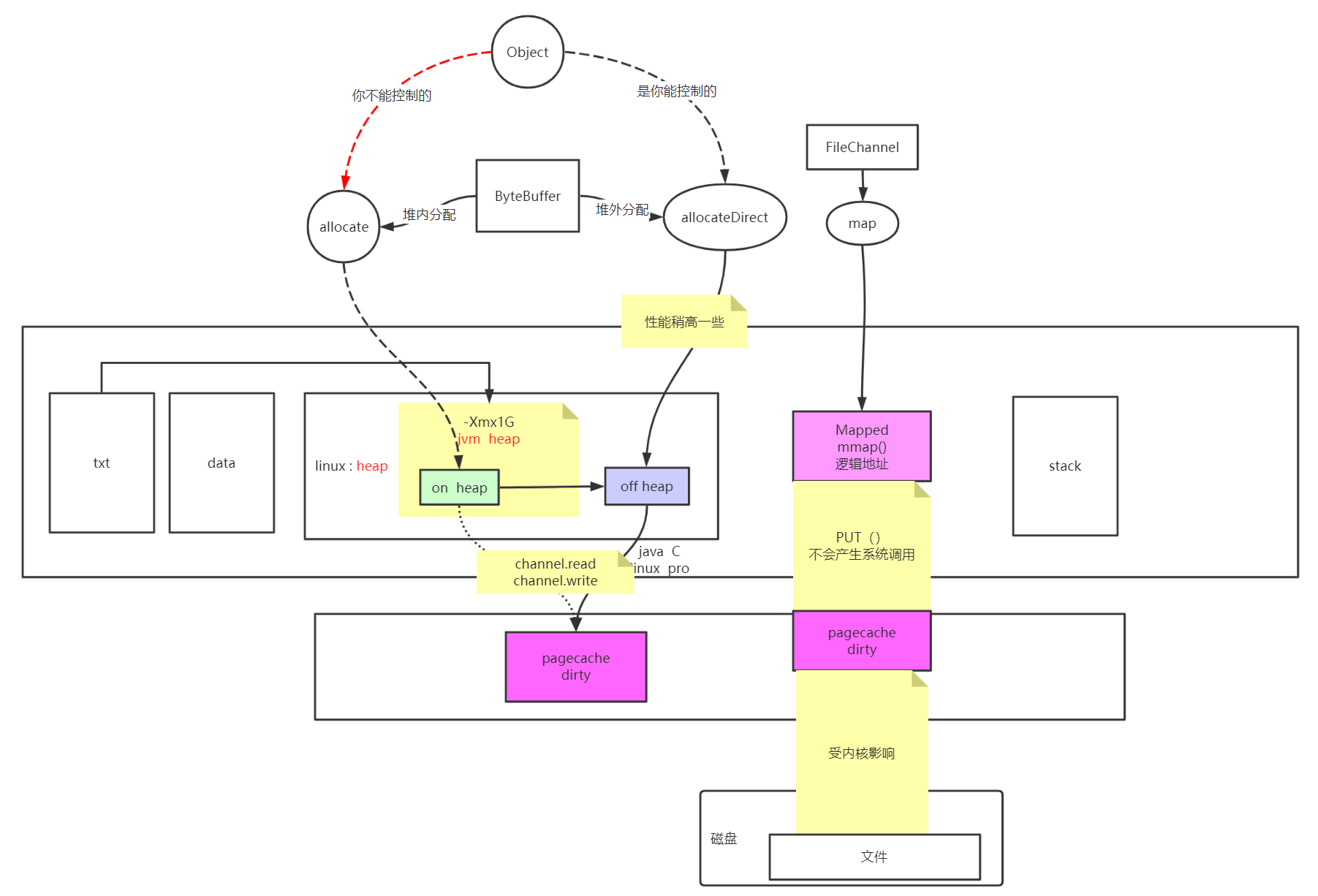
在整个操作系统中,有txt(编写的程序),data数据,堆内存(操作系统的)
txt自己编写的程序会向操作系统的堆内存分配一块空间,放在了jvm的堆里面
如果使用ByteBuffer使用allocate,相当于分配到了jvm的堆上(on heap),如果使用allocateDirect相当于分配到了java进程的堆空间里面(off heap)
FileChannel对象会有一个map方法,得到一个MappedByteBuffer,
MappedByteBuffer对象通过put方法映射到内核的pagecache,不会有系统调用。如果有脏数据,最终是写入磁盘的
但如果是通过channel的read或者write方法,都是需要系统调用的,虽然都是最终到达内核的pagecache,都会有数据丢失的可能,这个目前没法避免。
从逻辑上看allocateDirect 确实要比allocate 性能要高一些,
所以当一个对象可以自己控制的时候,就尽量使用allocateDirect方法,当这个对象自己没法得到一个具体的时候,只能使用allocate
性能对比:on heap < off heap < mapped(只限于文件系统)
既然pagecache没法确保数据不丢失,为什么还要使用?
**OS操作系统 没有觉得数据可靠性为什么设计pagecache: **
减少硬件 IO 调用,这样可以提速,优先使用内存。
即便你想要可靠性,调成最慢的方式,但是单点问题会让你的性能损耗,一毛钱收益都没有。
所以要主从复制,主备HA,kafka/ES 都有副本概念(通过socket io) (副本又分 同步/异步)。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号