1、虚拟文件系统,文件描述符,IO重定向、管道

一个系统从宏观角度来讲,有CPU,有内存,剩下的都是io设备。
然后从在程序维度来讲,有kernel(内核)说白了kernel就是一个程序,剩下的都是用户空间的程序(如图中app表示),
每个程序都是逻辑的,线性的 一个内存地址,通过MMU转到CPU的物理地址,一个程序模拟使用整个内存,它的空间肯定也包含了kernel的一个引用,
一个系统肯定也包含了一些物理地址,比如CPU、io设备(磁盘)、网卡等等。
一般情况下,一个程序想要调用数据,肯定不能直接调用物理地址,要通过内核来调用,内核既管内存分配,也管io,它什么都管的。
VFS(虚拟文件系统,目录树)
内核虚拟出来的一个虚拟文件系统,其实也就是一个目录树,一一映射在物理地址
FD(文件描述符)
一份数据加载在内存中,供所有程序访问,那么不同程序访问不同的文件,涉及到一个偏移量的问题,这个就要说到FD(文件描述符)。
文件描述符最终是交给程序用的,程序在拿到对应文件描述符的时候,比如一个程序读取文件的偏移量是20,一个程序读取文件的偏移量是8,它们读取的是文件的不同位置,它们通过各自的偏移找到对应的文件pagecache,所以它们如果修改的数据不是同一个地方的数据,那是不用加锁的。当然了,如果它们文件偏移量是一样的,说明修改的是同一个数据,肯定是要加锁的。
inode
虚拟文件系统下有个inode号,在虚拟文件系统当中,尤其在使用磁盘的某一系列的时候,它的每一个文件在打开的时候,都有一个inode号来代表它。
当打开一个文件的时候,首先要加载代表这个文件的inode号,内核会把文件加载到内存里面,开辟一个所谓的pagecache。
pagecache(页缓存)
pagecache默认大小是4k,如果打开多个程序,这些程序是共享pagecache,当其中一个程序读取数据的时候,如果找到对应的内存数据,其实就可以返回了。
pagecache是内存里的一个缓存,数据开始时候从磁盘读取在内存,因为这样的话对这个数据操作就会很快,但是如果数据被修改,这个数据就会有一个标识'脏',那就是脏数据。
这些脏数据因为是被修改的,所以要决定什么时候把这些数据同步在磁盘中。这些数据是由内核维护的,它管理的是整个系统的所有程序的数据,而不是针对某一个。
它会等到时候把整个数据都给刷到磁盘中,但如果脏数据还没有等到来得及刷到磁盘中,这个时候断电了,那么这些数据就丢失了。
挂载:
打开一个服务器,查看根目录
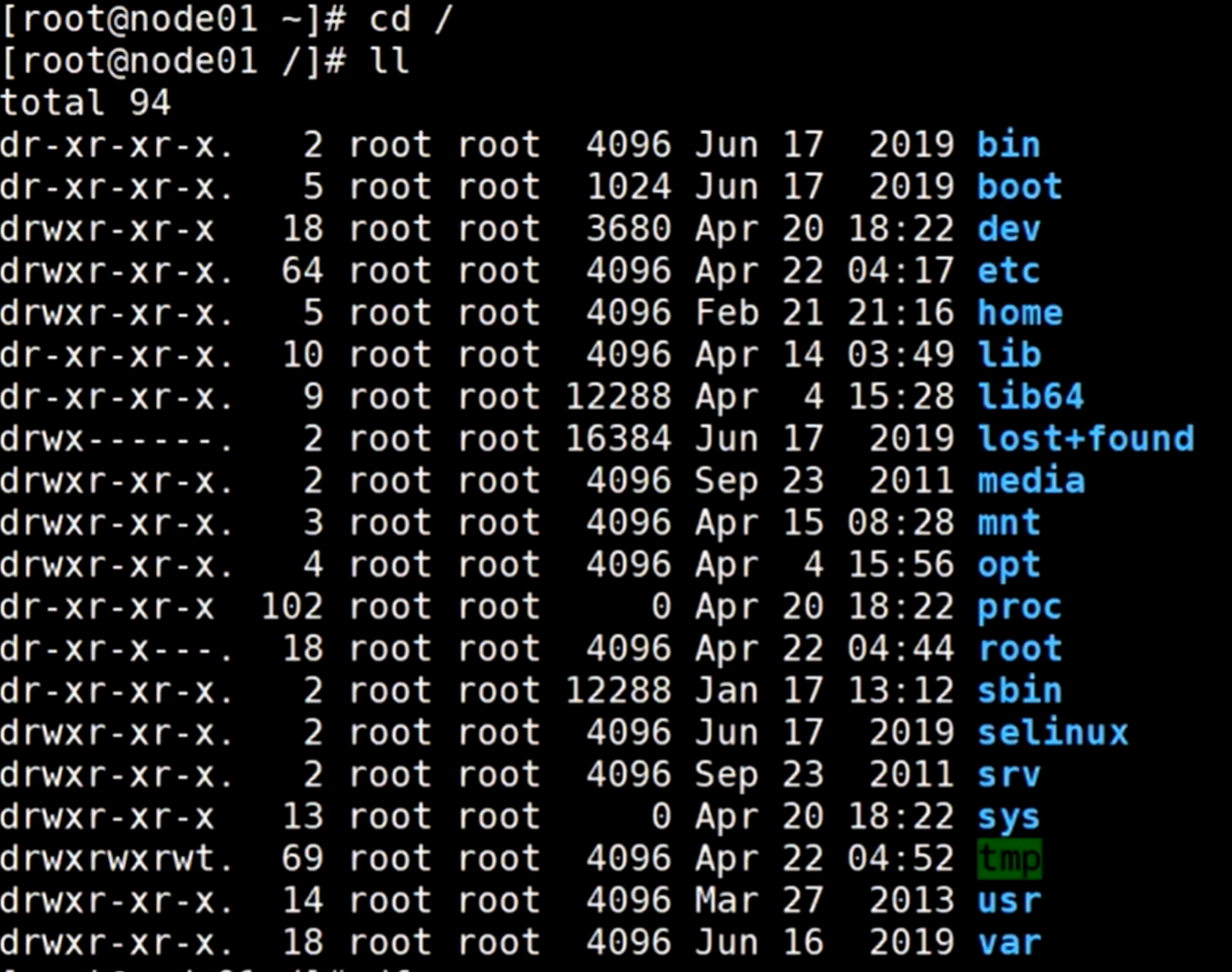
这些都在根目录下,就相当于是一个目录树,这些都是子节点。
查看df命令

看到一些目录的信息,比如哪些目录挂载的是哪个位置,可以看到3个目录,根目录挂载的是/dev/sda3目录,dev是设备目录,里面的sda(表示分区)的3分区,其他两个目录都是子节点目录的挂载。
这个分区的意思就是:
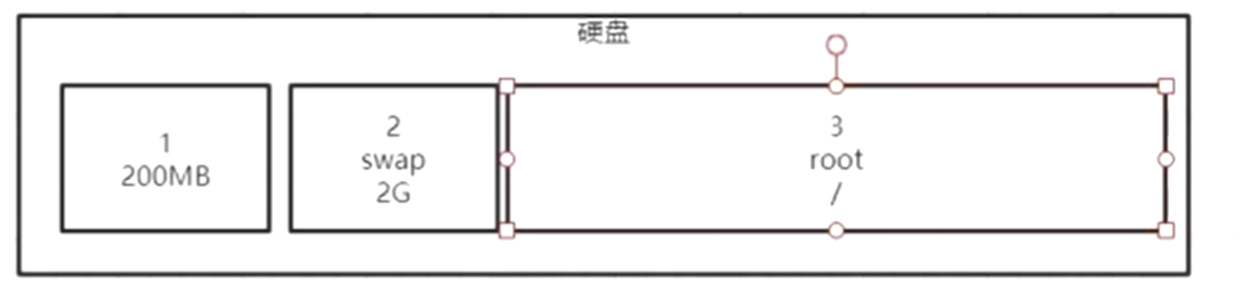
因为windows系统的分区是可以看的到的,但是linux系统是看不到的,比如自己给硬盘分区了3份,1分区是200m大小,2分区是swap交换分区,3分区是root分区,root有2个意思:1、表示管理员用户,2、表示root目录
如上图根目录,感觉上根目录下的所有目录都在同一个地方,其实并不是!
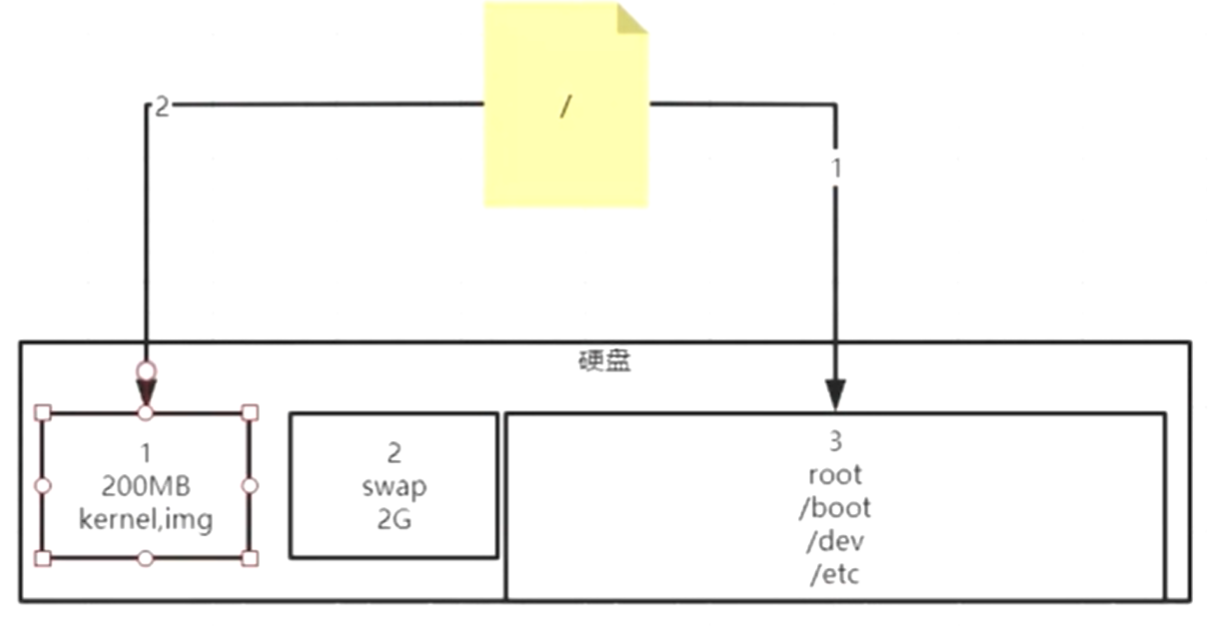
比如那个/boot目录,可以看到前面显示的是1分区,所以这个boot目录有两个,一个是原来根本的boot目录,另一个是1分区的目录。
其实起开始操作系统是把这两个boot目录都在加载出来了,但是最原来的boot目录挂在了1分区的boot目录,为了让它显示出来,所以覆盖了原来的根目录下的boot目录
查看现在这个boot目录:
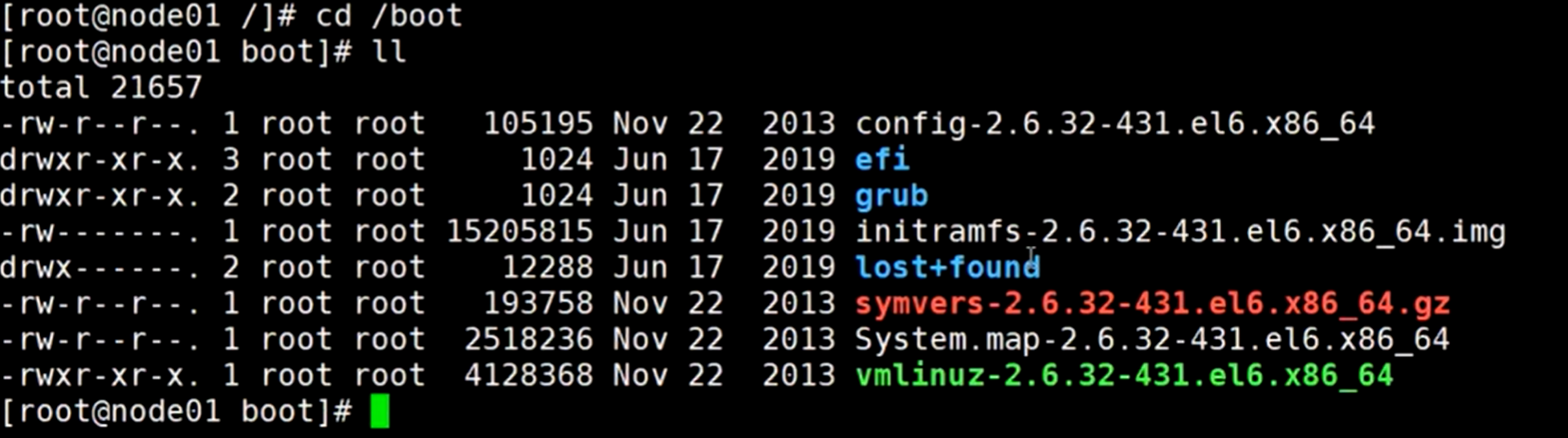
退出boot目录到上级目录,然后使用命令umount卸载掉这个boot目录的挂载

可以再使用df命令查看,可以看到少了一条规则,那就再进到boot目录查看一下:
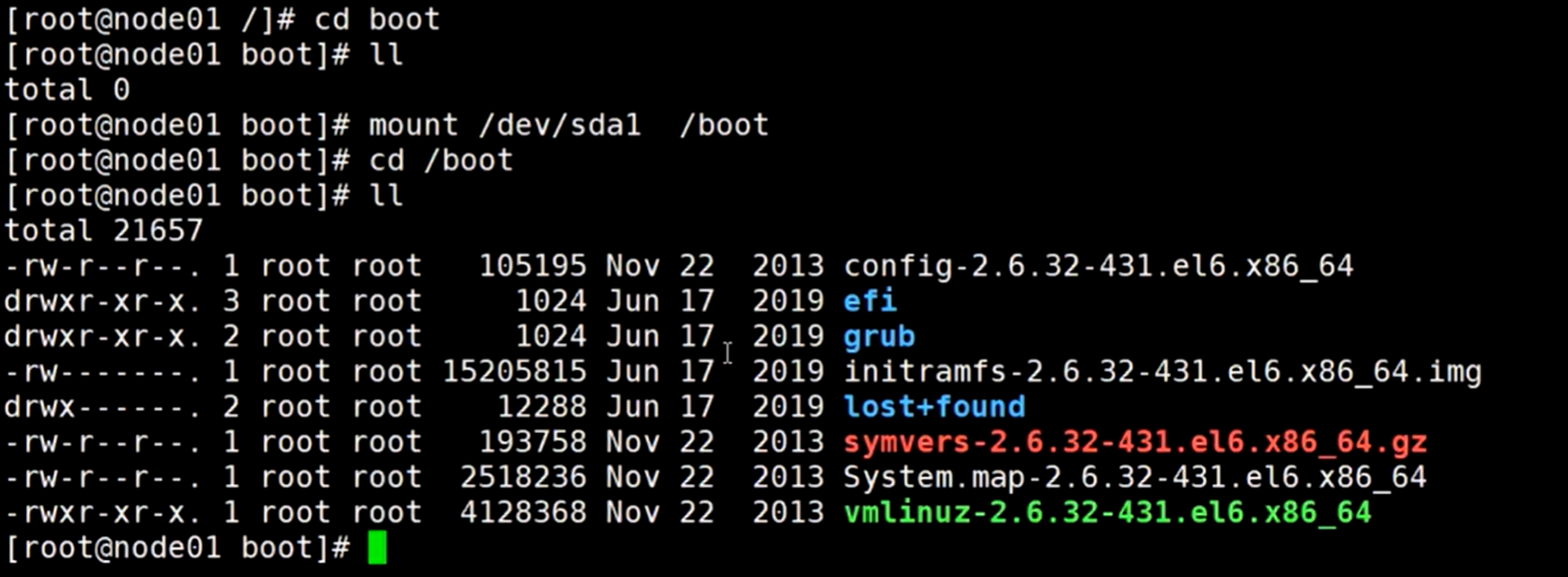
再次进入到boot目录查看已经变成空的了,那么再使用命令mount重新挂载一下1分区,再次查看boot目录,下面的文件又回来了。
文件类型
冯诺依曼定义服务器一个概念:计算器,控制器、主存储器、输入输出设备 I/O,除了这些外,还有一个抽象:一切皆文件。
既然什么都可以当初文件,那么就可以通过IO传输。
文件类型有很多很多,比如:
- -:普通文件(可执行,图片,文本)REG
- d: 目录
- l:连接
- b:块设备
- c:字符设备 CHR
- s:socket
- p: pipeline
- [eventpoll]:内核提供的eventpoll内存区域
连接
硬连接
随便编写一个文件,比如:msb.txt

编写好以后,使用命令ln硬连接这个文件
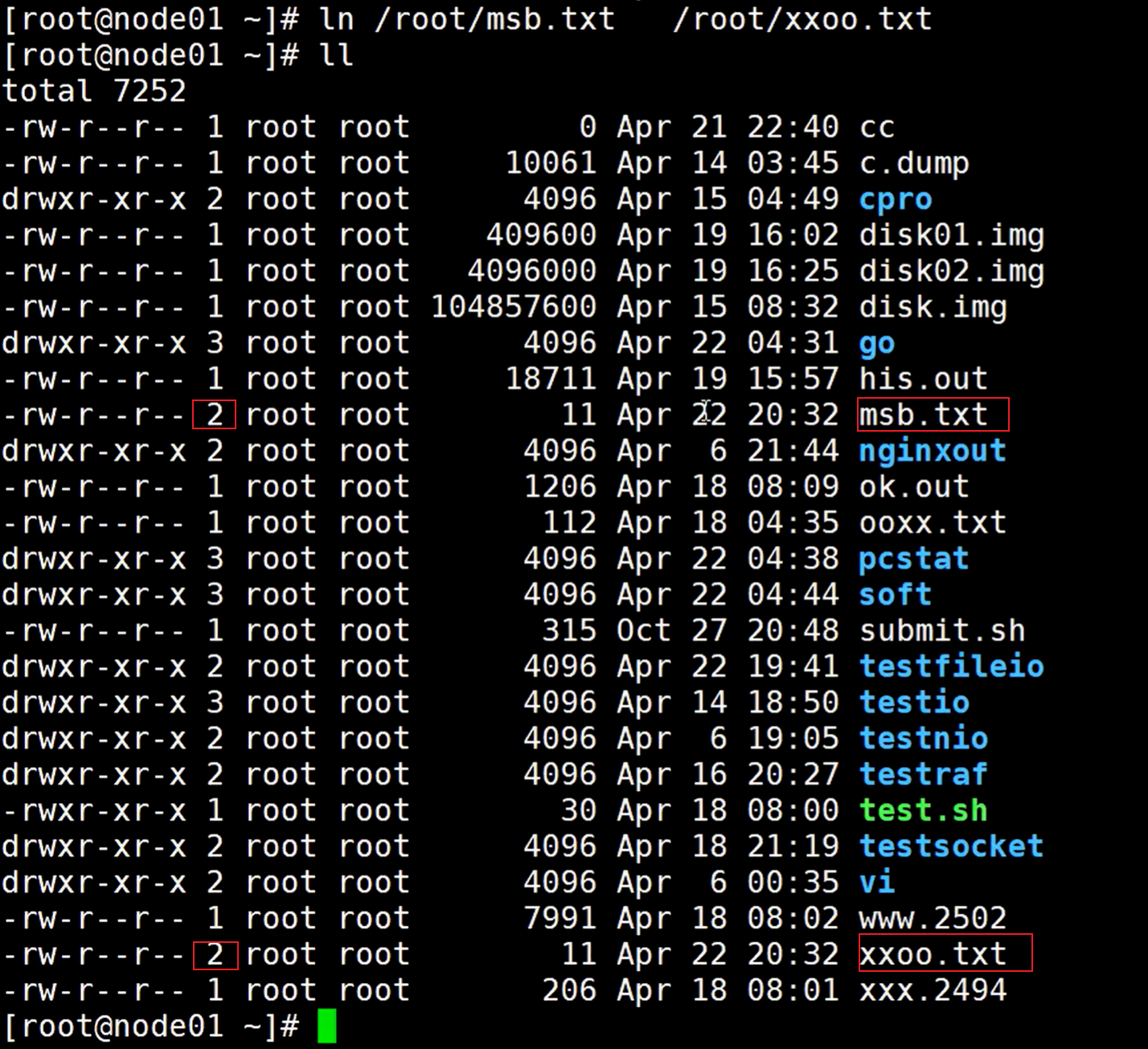
可以看到多出来了这个硬连接xxoo.txt文件,前面的2表示硬连接数量
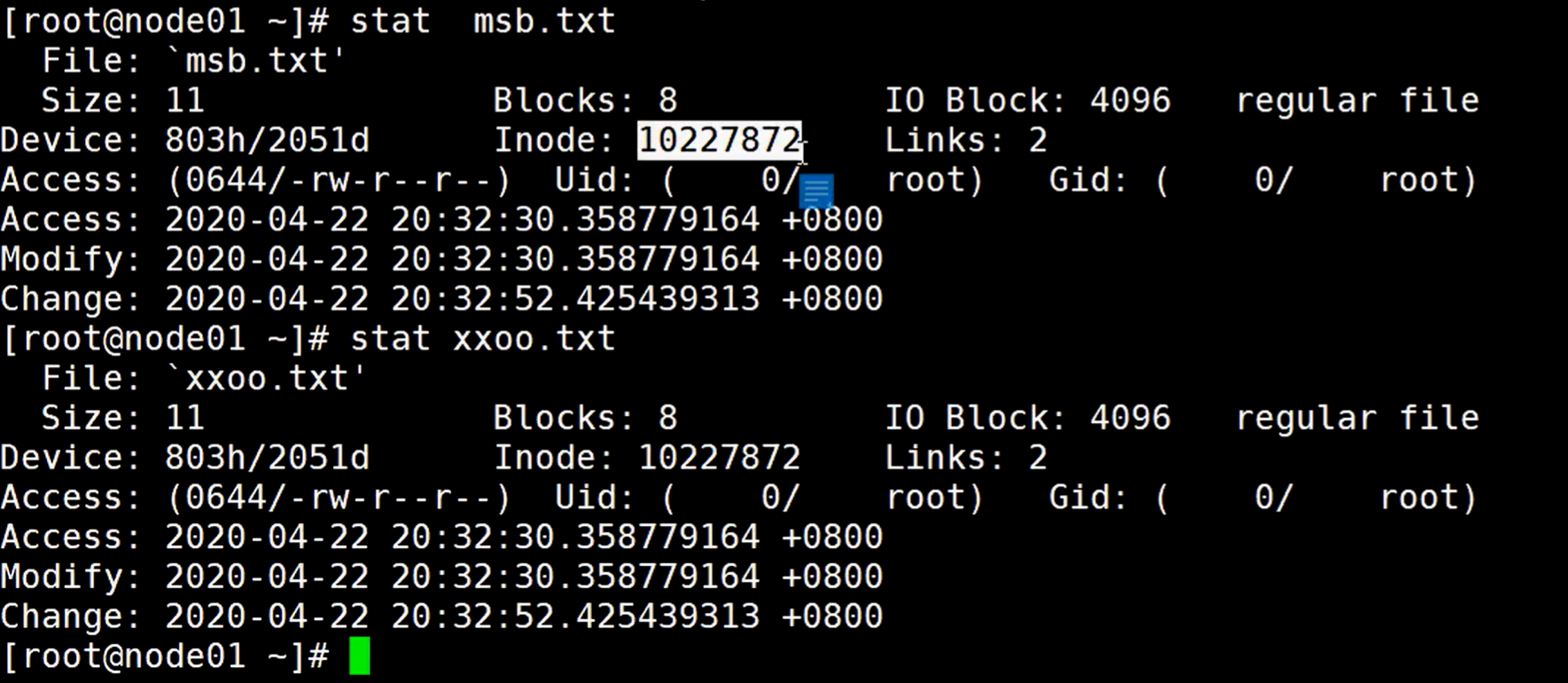
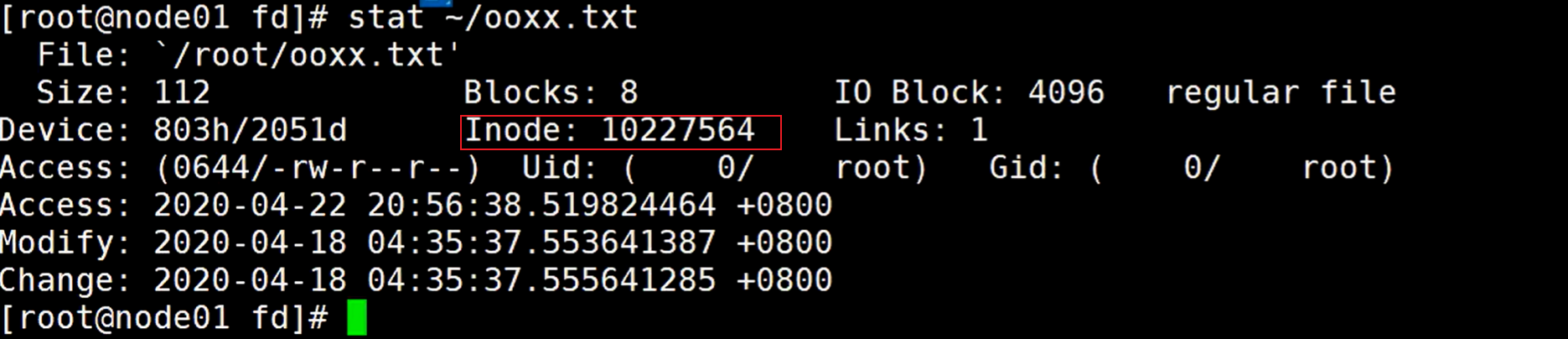
使用stat命令可以看到这个文件的原数据信息,可以通过Inode号判断指向的是同一个文件,所以其实系统上就这么一个文件
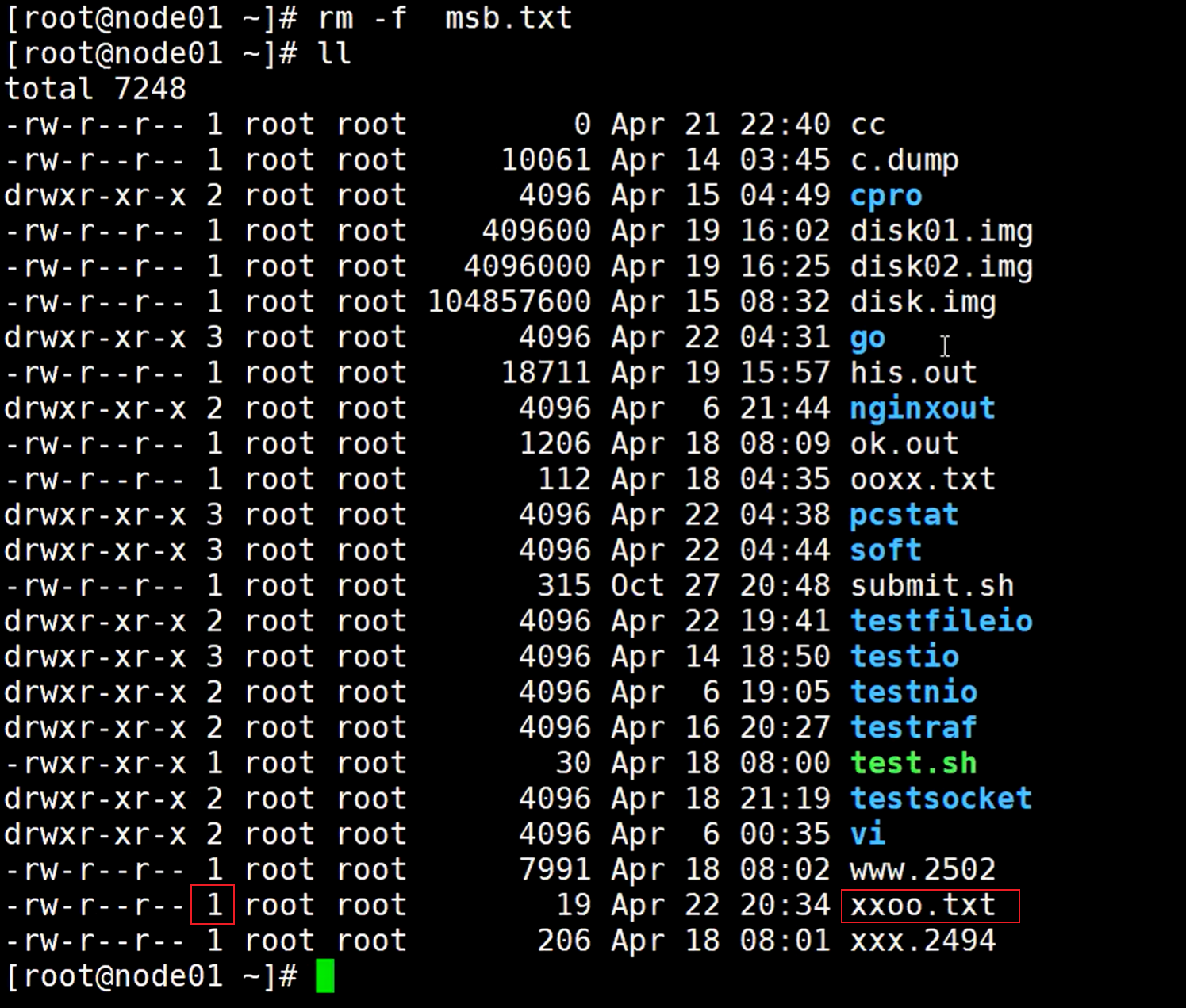
如果删除其中一个文件,只是少了一个对这个文件的连接,硬连接数量也变成了1,只是把这个文件的引用给删掉了
软连接
使用ln -s命令
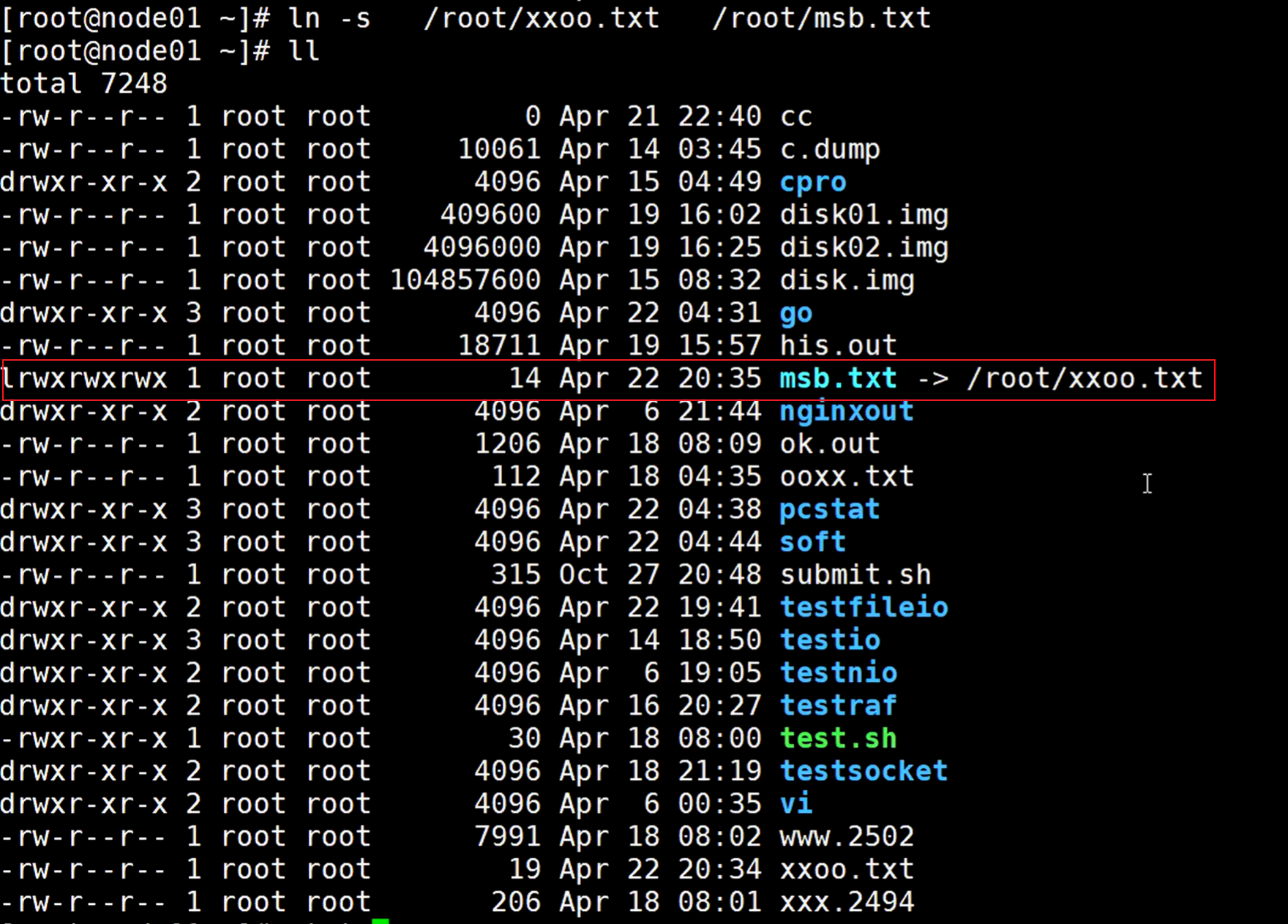
使用stat查看这两个文件:
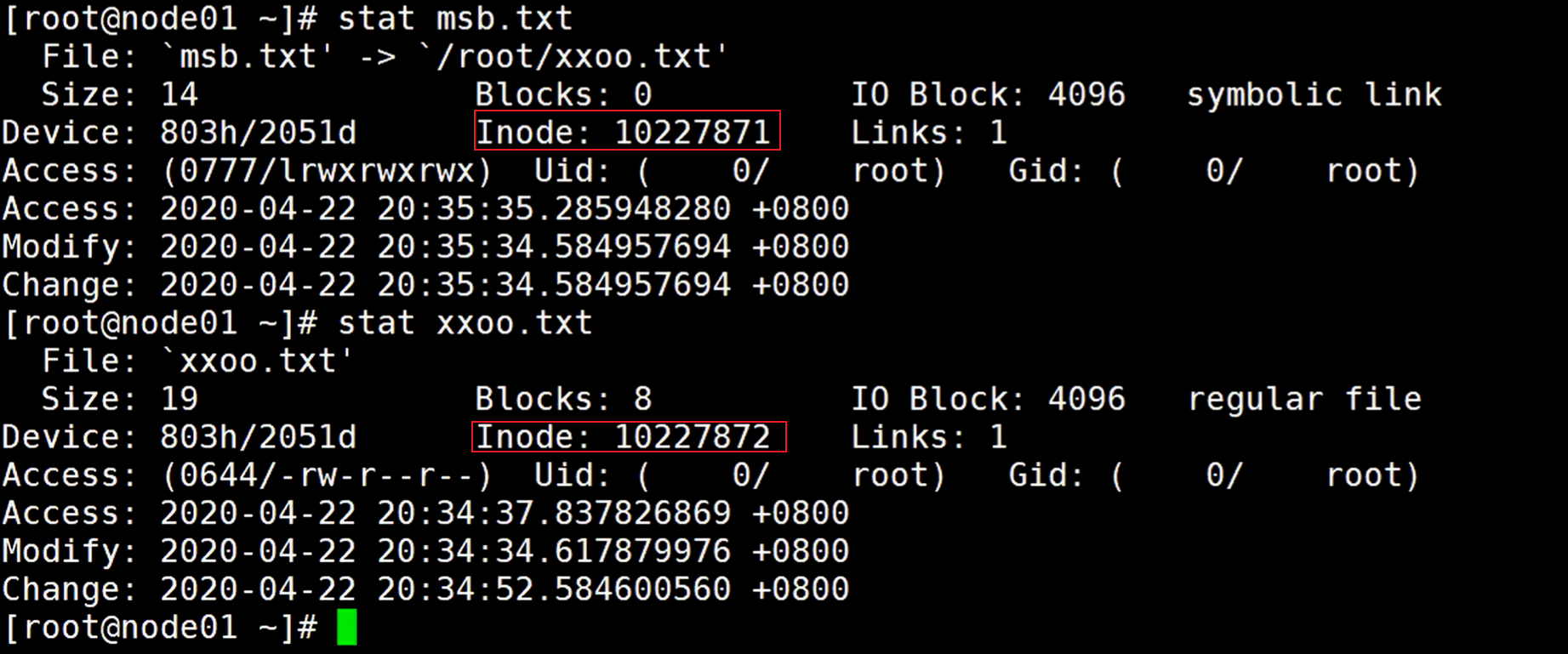
可以看到Inode是不一样的
如果把这个原文件给删除了
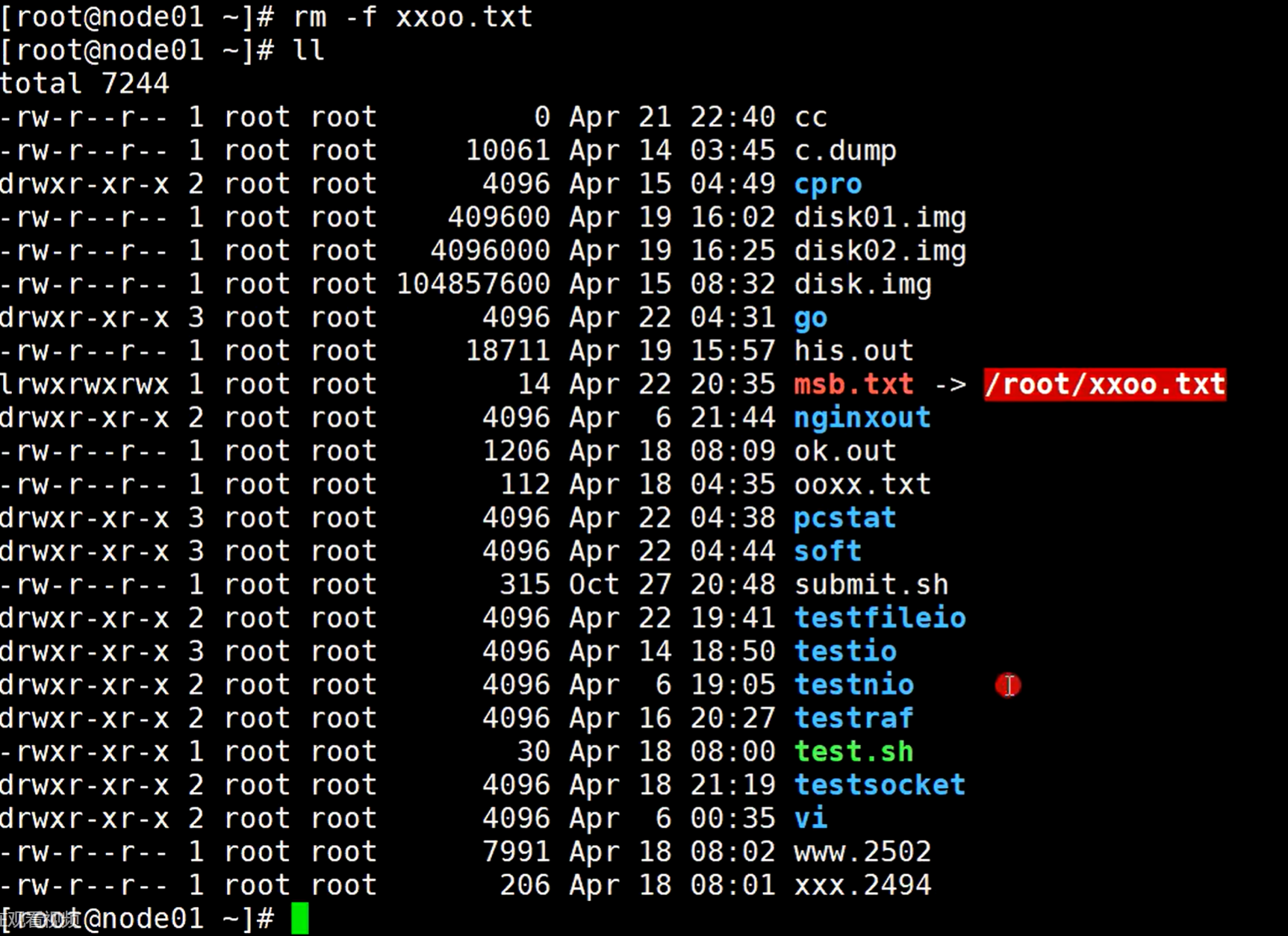
可以看到这个软连接报错了,因为它没有了这个文件引用的指向
块设备
- /proc目录:内核映射的目录,映射的内核的变量属性等等。只有开机之后,这个目录下才会有东西的,比如内核里面有进程管理等。如果关机了,这个目录就又变成空的了。所以进程id号或者网络等等内核管理,都是这里的文件,一切皆文件。
创建一个目录:

这个目录是刚创建的空目录
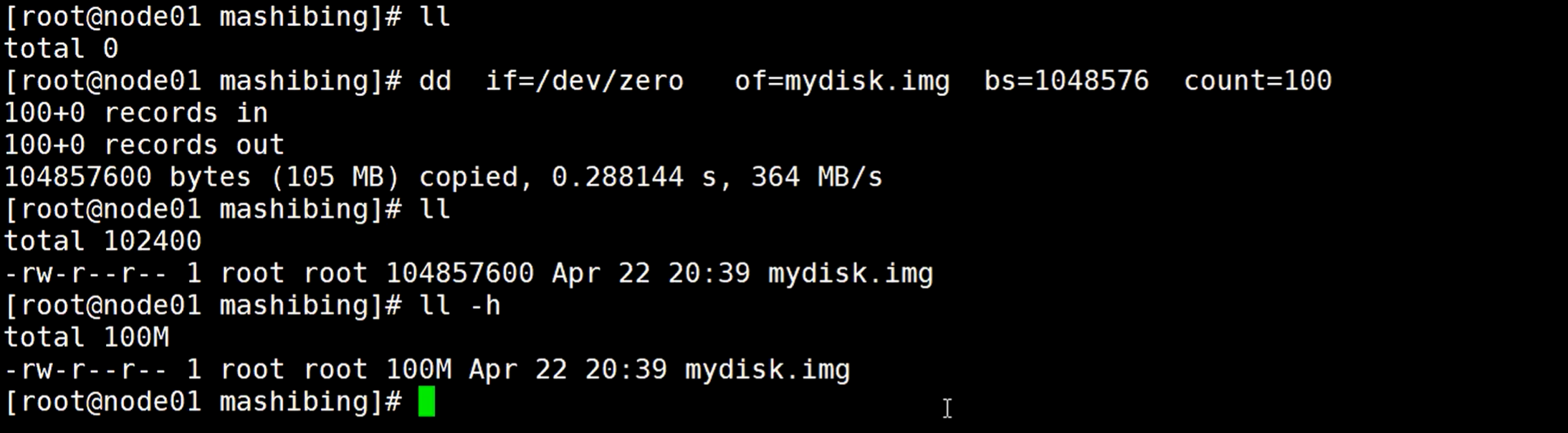
dd命令:主要是拷贝数据,生成文件或块设备等等
- /dev下面的zero:dev目录下有一个类似于无限大的黑洞,就是这个zero,里面可以存放很多东西,但是不会占用太多物理内存。
- of=mydisk.img: 生成的文件名,of就是outFile的意思,同理,if就是inputFile的意思
- bs: blockSize的意思,块的大小
- count=100:表示乘以100的大小,用bs的值乘以count的值
这样可以得到一个文件,ll -h可以查看文件带单位的大小
得到这个文件以后,可以挂在到磁盘文件
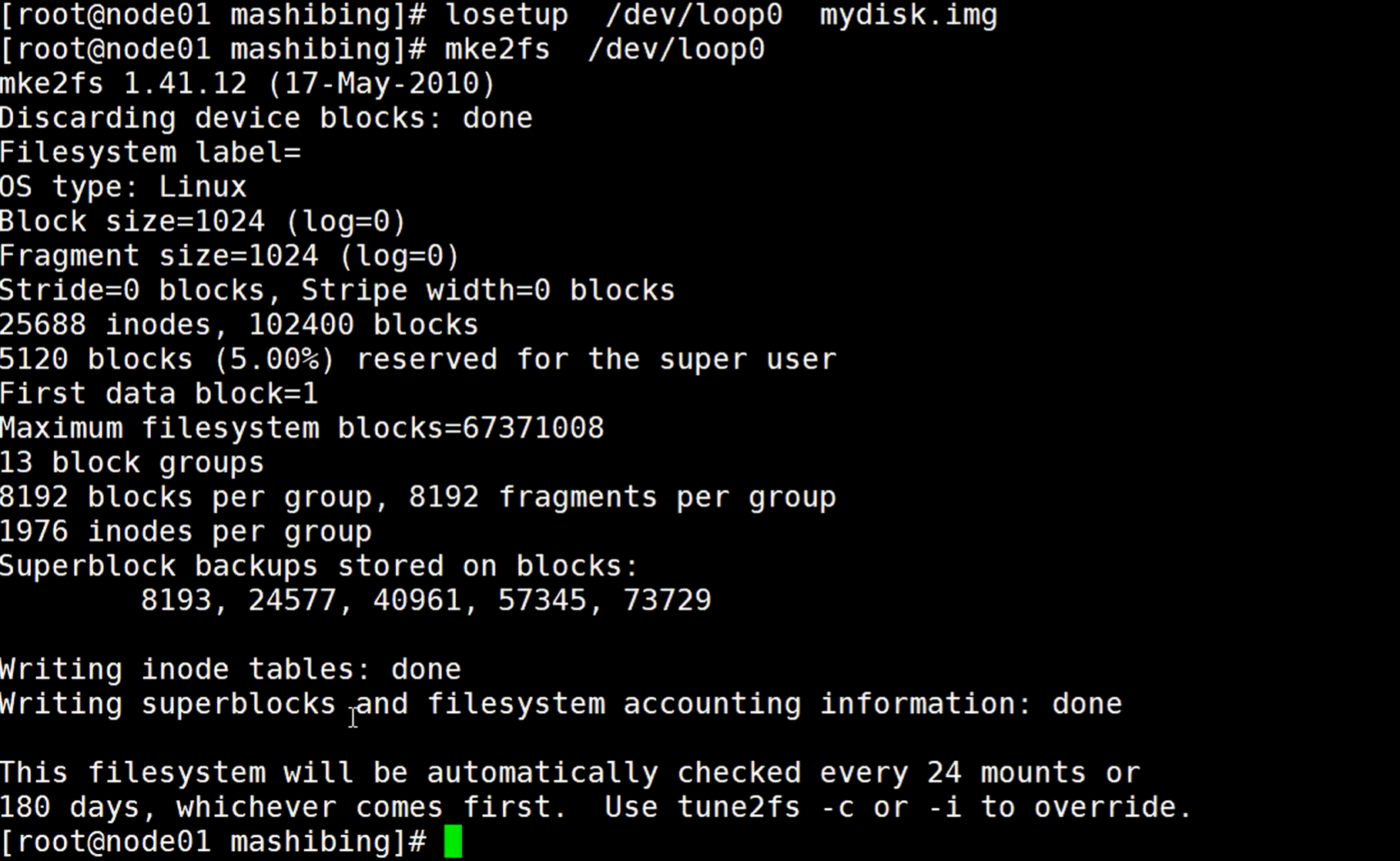
losetup命令表示挂载,把dev目录下的loop0这个设备挂载到mydisk.img文件,这样访问这个loop0这个设备,就等于访问到了这个文件。
mke2fs是格式化命令,格式化这个loop0这个目录,会变成一个ext2 的一个文件类型
然后把这个文件挂载到/mnt/ooxx目录下
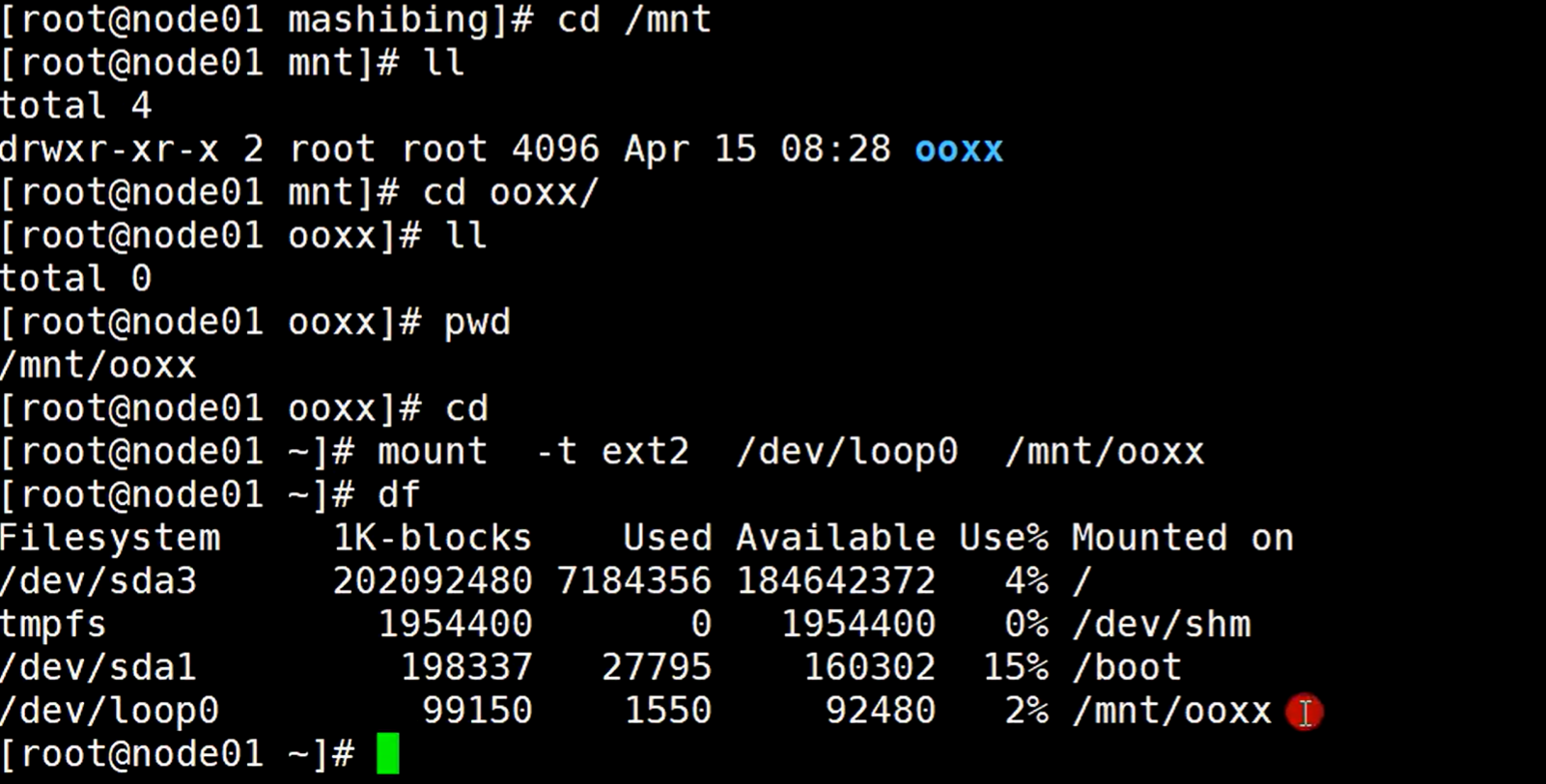
使用mount命令挂载到/mnt/ooxx(这个是随便创建的一个空目录,也就是根目录3分区里面的)目录
这样的话,访问到/mnt/ooxx目录,就不是访问3分区的目录了,而是访问到了loop0这个设备上面了
这个时候ooxx 这个目录是空的,创建一个bin 目录,然后查看一下bash的可执行程序
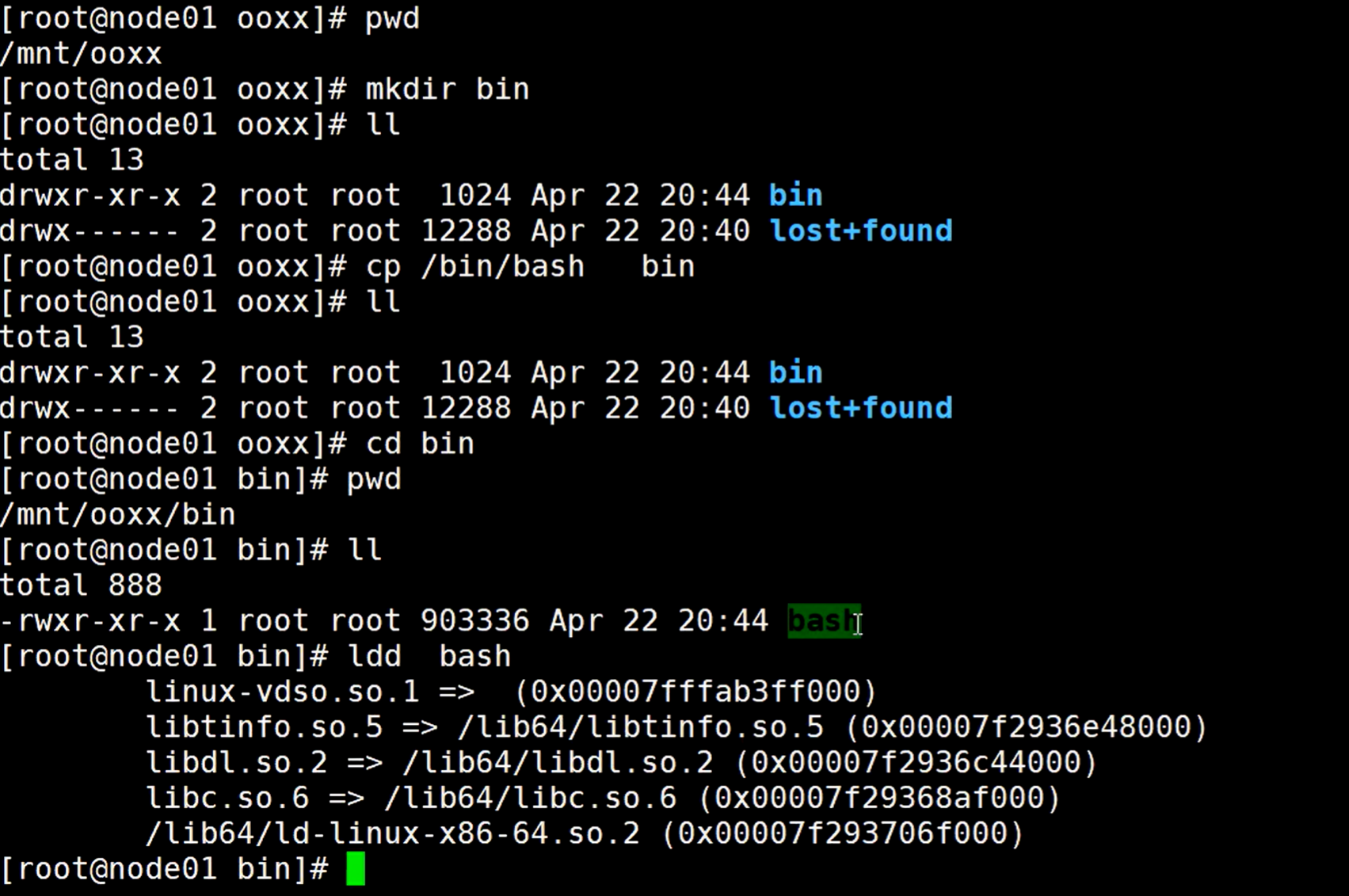
bash 就是一个解释程序,比如解析linux上面的字符信息,whereis 就是告诉我bash在哪
cp 拷贝/bin/bash 到当前的bin目录
ldd命令接上程序,会告诉它的动态链接库有哪些。
知道了它的连接都是在根目录lib64的目录下里面的几个文件,那一样的创建一个lib64目录,拷贝对应的那几个连接文件,使用花括号{} 可以选择指定的哪几个文件,因为lib64目录下有很多文件,不能全都拿过来。
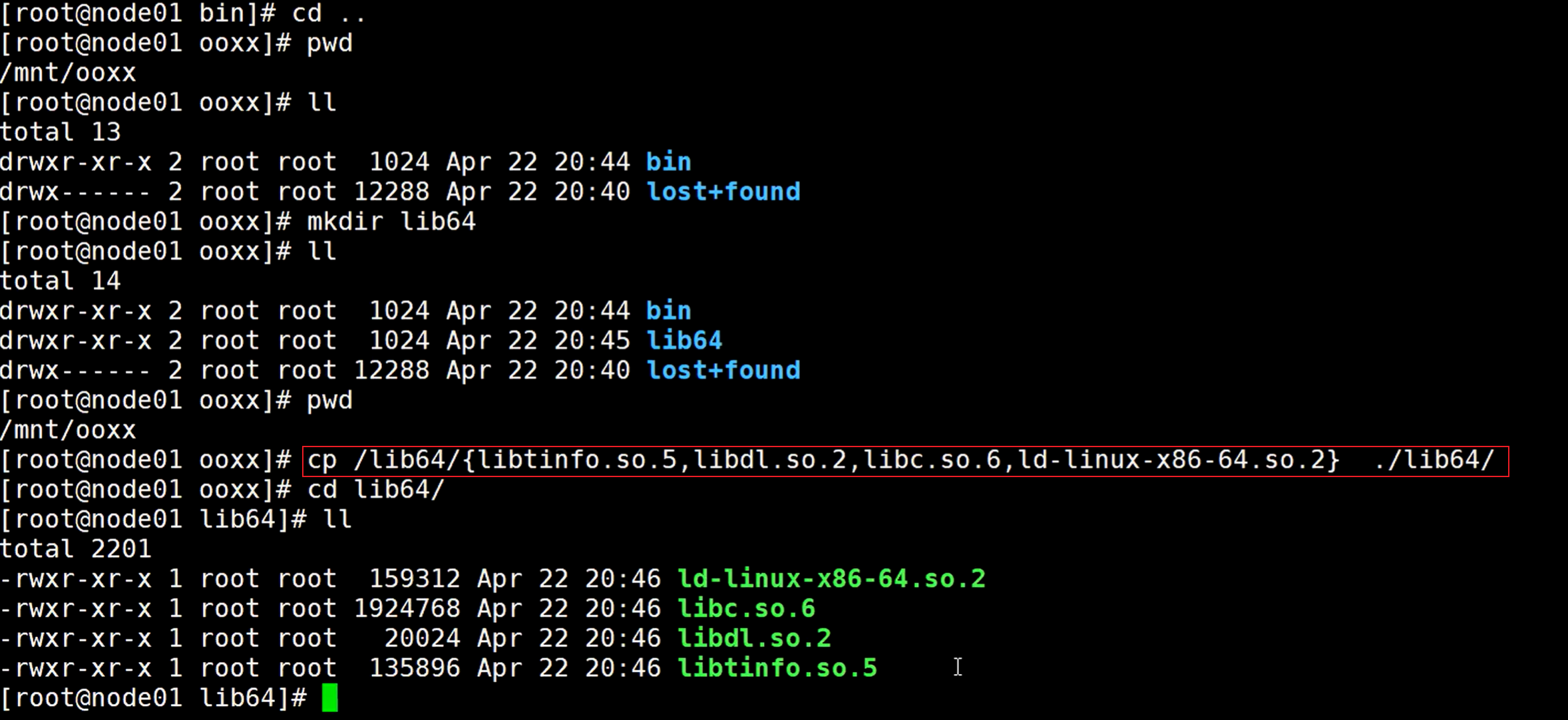
这样就暂时的完成了自定义的根目录,
使用命令chroot ./,把根目录切换到当前目录,并把bash启动
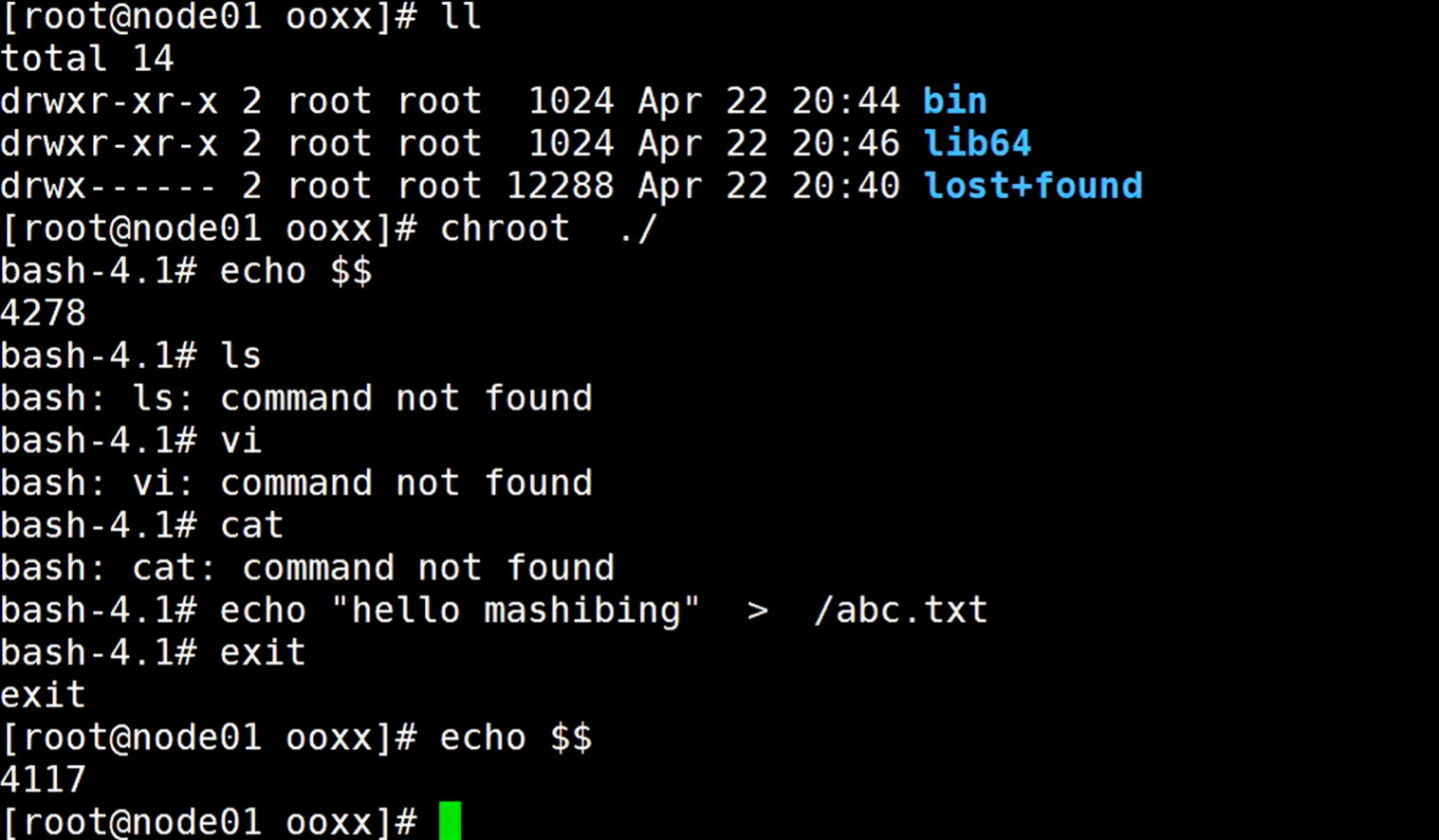
除了自带的echo命令,其他命令都是没有的,但是可以通过打印字符输出到一个指定的文件,就是这个abc.txt,
那么这个abc.txt文件就会在自定义的这个根目录下产生,但肯定不在原linux系统下的根目录
再到自定义的根目录下查看
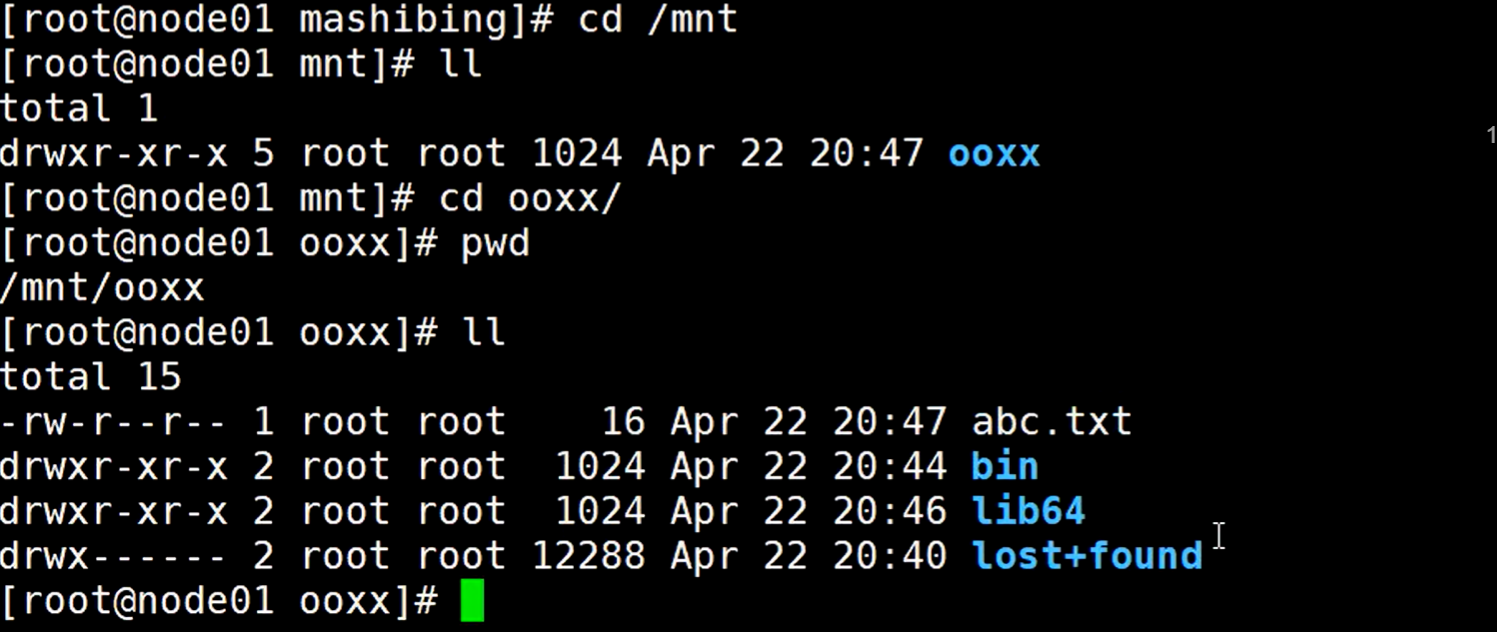
可以看到生成的这个abc.txt文件
如果把挂载的这个给卸载掉,就看不到了,再访问就可以看到是空的了

但是这个镜像文件还在

不同的进程维护不同inode号
lsof命令显示进程打开了哪些文件
- -p:表示告诉指令哪些文件,$$ 表示bash进程
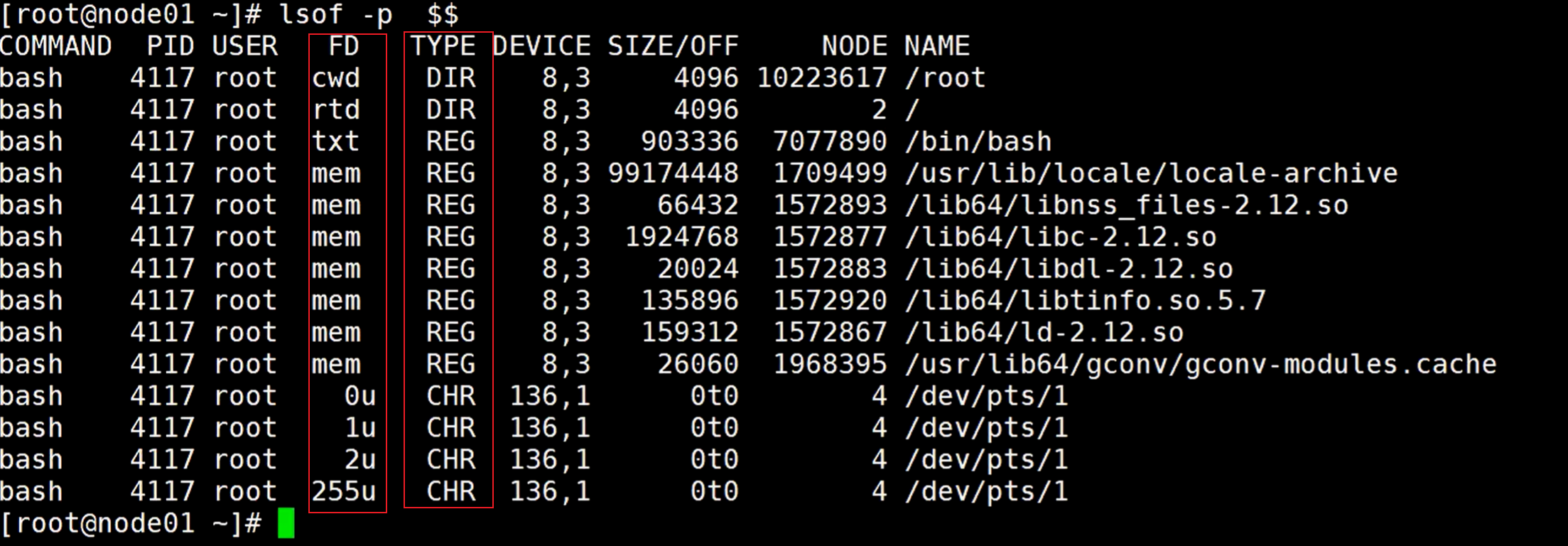
FD列 表示文件描述符,里面包含:
- cwd:当前工作目录是哪里
- rtd:根目录在哪
- txt:文本域
- mem:分配的内存空间,挂载内容
- 0、1、2 分别表示:标准输入,标准输出、异常输出,u表示读写都可以,r表示读,任何程序都有0、1、2
TYPE列:表示文件类型:
- DIR: 说明是个目录
- REG:普通文件
- CHR:字符设备
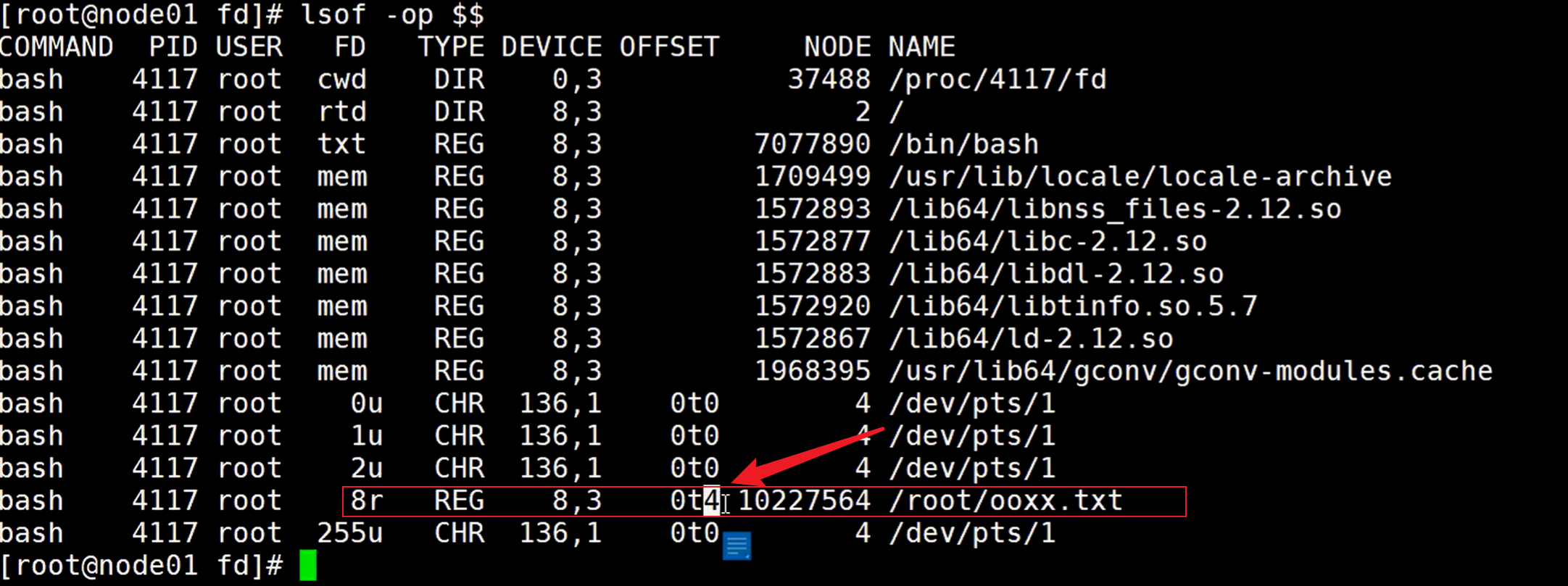
定义了8去读取ooxx.txt文件,然后查看文件描述符,可以看到这个8

再使用lsof命令查看进程文件描述符,-op 表示显示详细信息
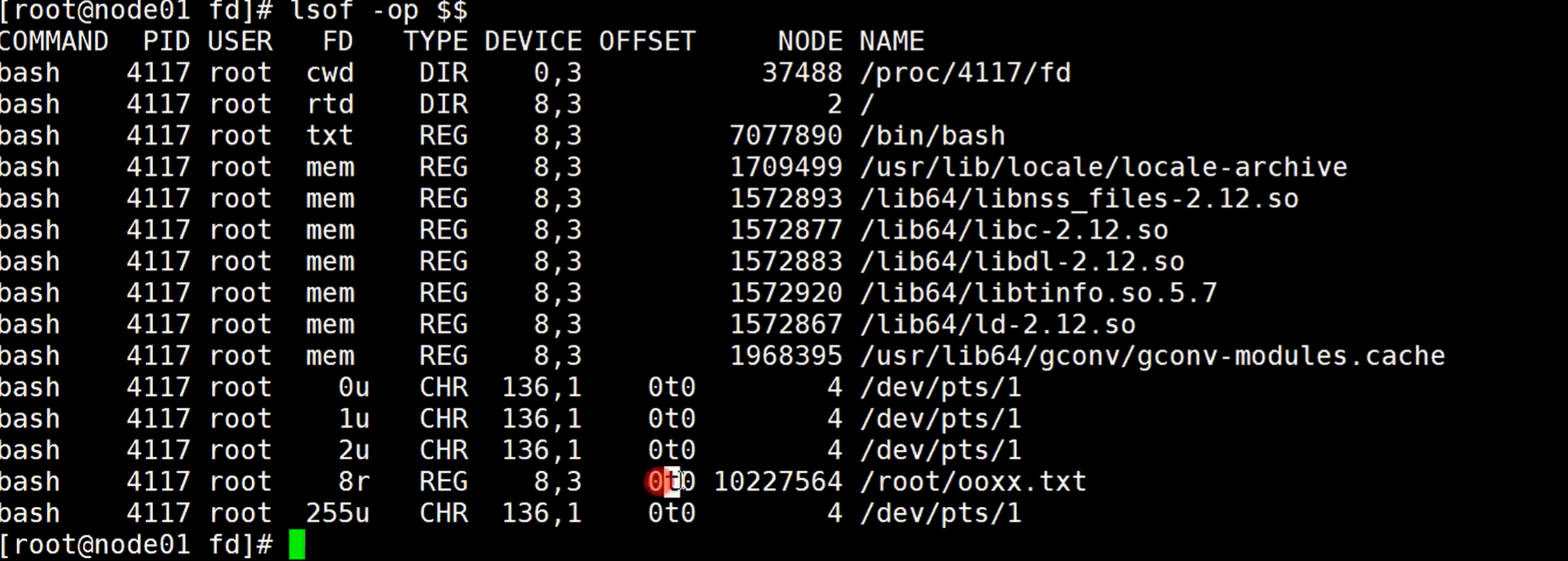
可以看到inode号是7564结尾,使用stat命令查看是否正确
使用read命令去读取文件描述符8,这个read命令读取到换行符的时候,就不读取了,所以只会读取第一行
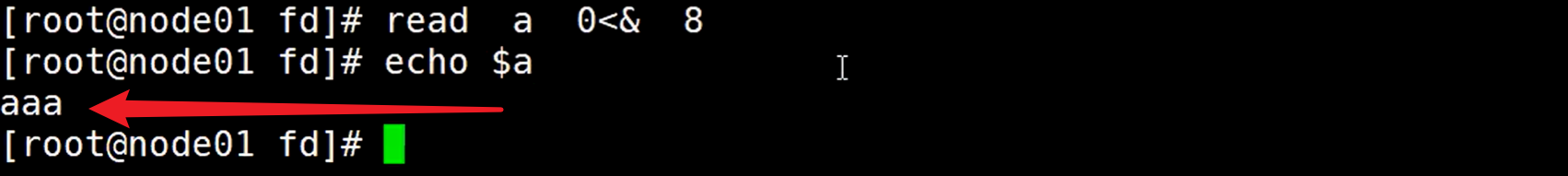
查看这个ooxx.txt文件的内容可以确认一下
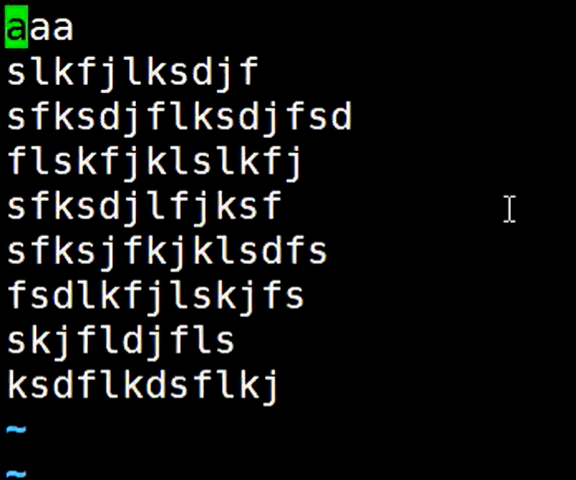
读取这个文件后再查看它的偏移量,可以看到偏移量变成了换行符对应的偏移量的值,也就是4
如果重新打开一个bash,再打开一个窗口会发现它的偏移量指针变成了0,
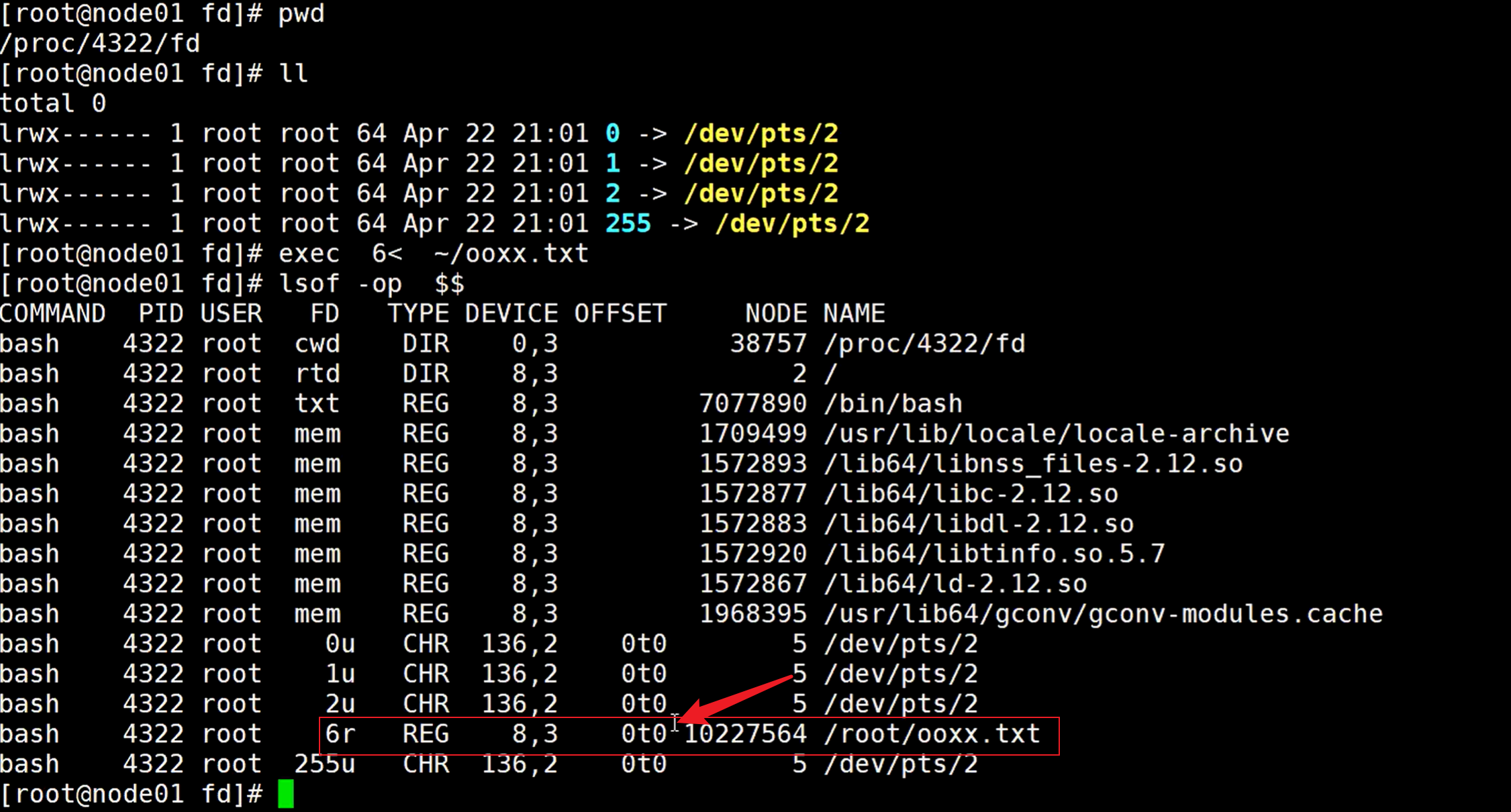
说明了什么?(不同等进程inode号是隔离的维护的)
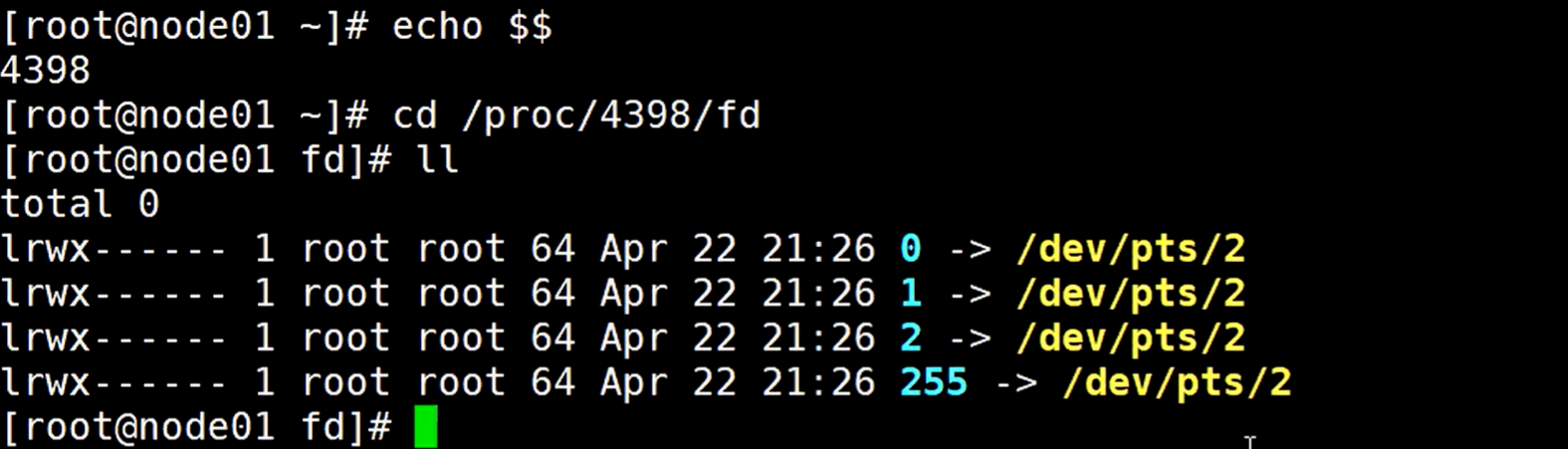
socket
打开一个进程连接,查看进程号以后,进去到这个进程的字符描述符查看,默认只有0、1、2 和255
定义一个8,输入输出/dev/tcp目录,加上百度的地址,tcp目录是不可见的,看不到的,但实际是存在的
执行后再次查看文件描述符,可以看到这个定义的8执行一个socket连接,可以使用lsof命令查看一下进程的文件描述符
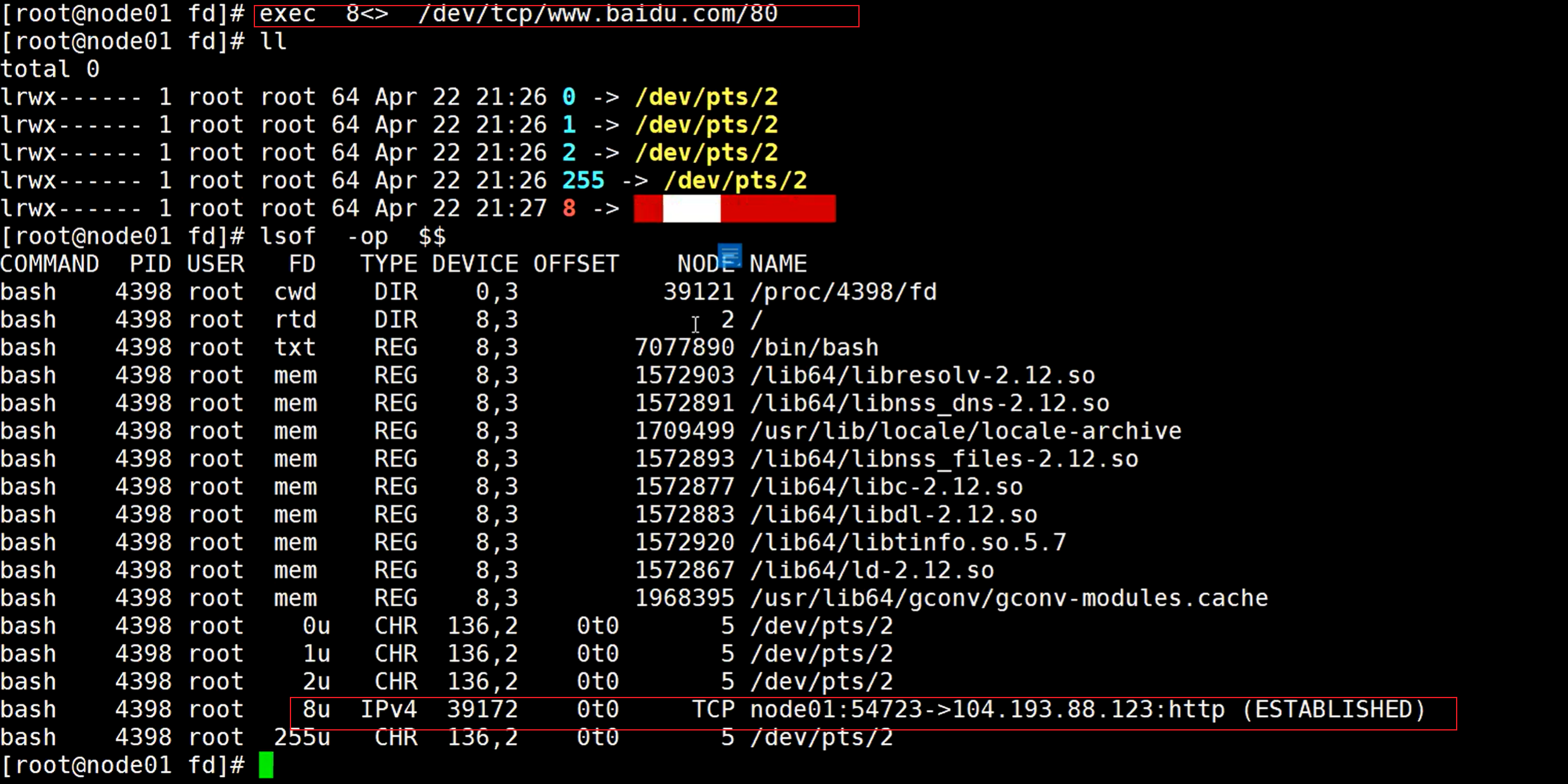
可以看到TCP连接,连接到了百度,已经建立了和百度IP的连接
所以这些都是文件,一切皆文件,所有的一切都可以使用文件去描述。
重定向
重定向不是命令,是一种机制。
如下这段伪代码:
File ifile = new File("/ooxx.txt")
out (fd) = new outputstream(ifile)
out.write("fdsfsdf")
我们正常写代码获取一个文件,然后往这个文件输出内容,在我们看来这个文件路径是写死的,但其实在linux操作系统并不是,它是可以给重定向到别的方法的,得到的这个out属性,其实就获取了它的fd(文件描述符),这样的话就可以对它进行操作。
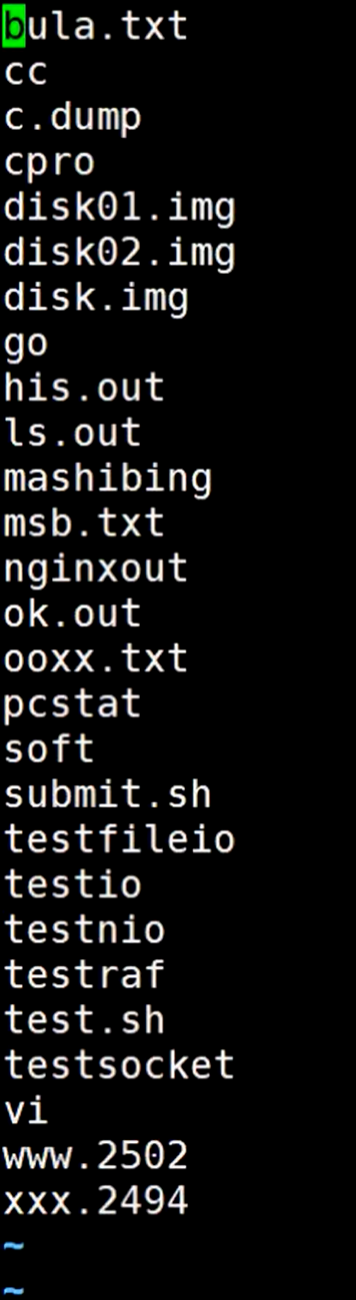
示例1
比如:ls ./打印目录信息,然后就会显示出来目录信息,ls进程默认打印到屏幕上的信息,使用1>(输出)到指定位置

执行后可以看到屏幕没有显示出目录信息了,对多出来这个输出的文件,查看这个文件,确实是目录的信息,这就是重定向,它不往屏幕上打印了,换成了打印在文件里
示例2
比如cat命令,cat命令可以查看文件信息,可以理解成cat命令是先获取文件输入流,读到文件后,再把文件输出到屏幕。
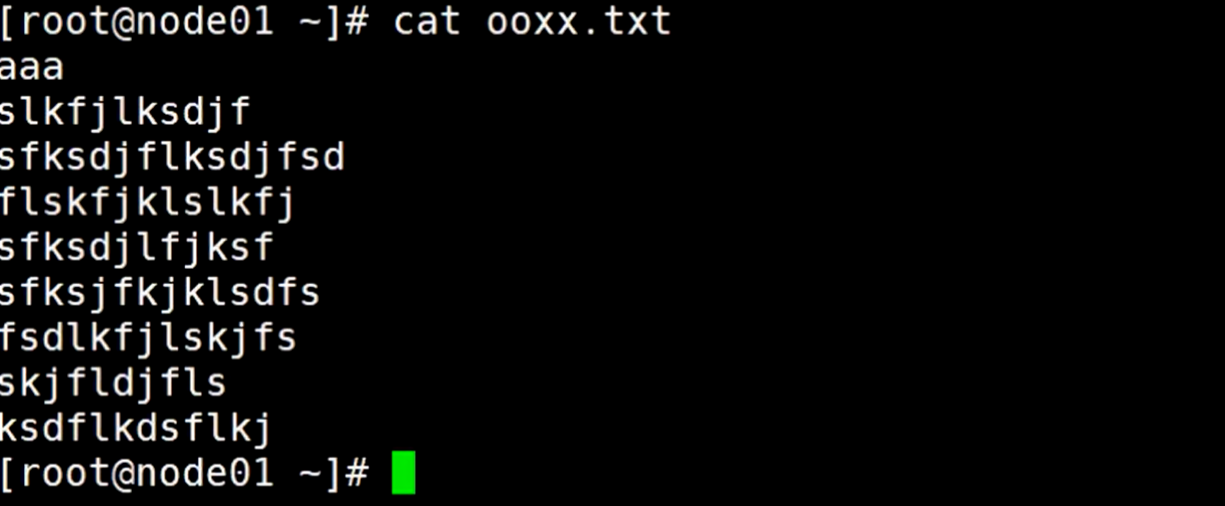
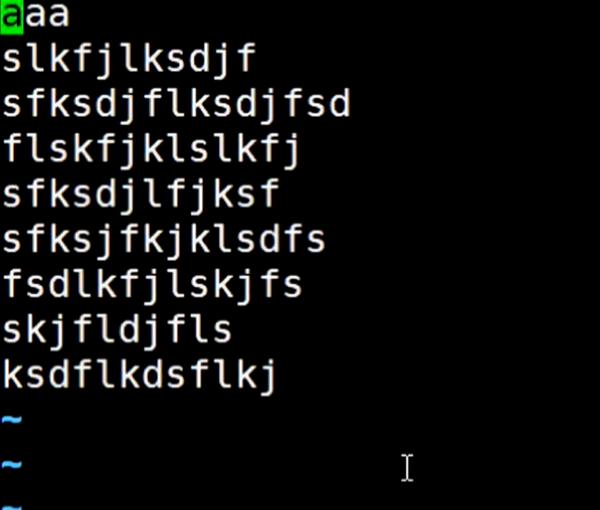
我们尝试给他强制性更改输入输出的路径

执行后发现屏幕没有显示出来,那就去查看对应的输出文件,可以看到输出到了这个文件里。
示例3
尝试报错输出到指定文件里,2> 表示报错输出,正常情况下ls 命令打印一个不存在的目录,可以看到会打印出报错信息,一样的道理可以把它的报错输出同屏幕重定向到指定的文件

如果同时打印正确的目录信息和错误的目录信息,正确的目录信息会输出到指定文件,但报错的信息还是打印在了屏幕上,因为报错输出2> 没有重定向到指定文件

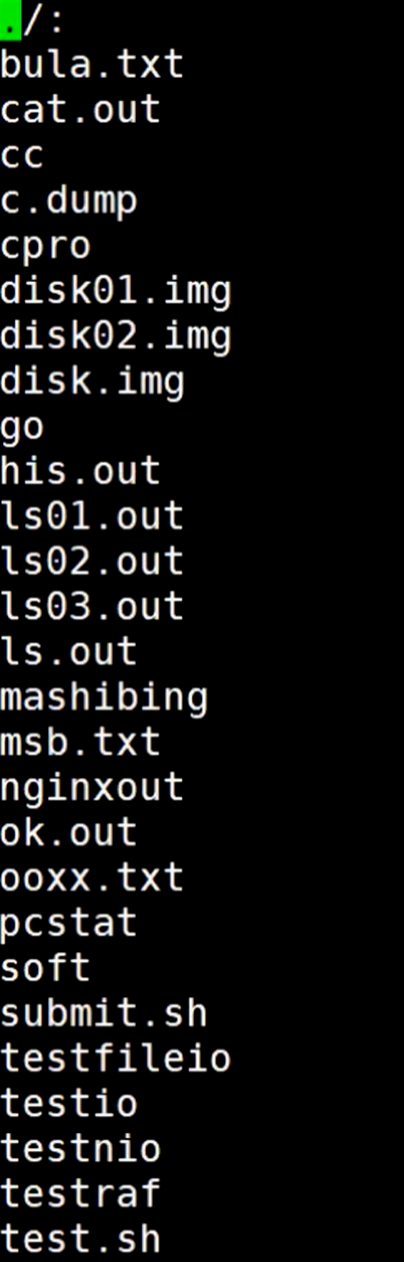
如果只指定一个文件,正确目录信息和错误信息都指向这个文件输出,

那么会出现一个问题,只会显示正确信息,错误信息是不会输出到这个文件的。
同时想象一下,能不能报错输出指向标准输出(2指向1),然后输出到一个文件,这样把正确信息和错误信息都给输出出来。
可以是可以,但是有语法问题需要注意

然后查看这个ls04.out文件,可以看到目录信息和报错信息都输出了进来
父子进程
先echo $$打印出进程id号,也就是bash的进程id,然后使用/bin/bash再启动一个bash,再查看这个bash进程id,是4463,使用pstree命令可以查看pstree这个命令来自一个bash,bash来自另一个bash,这两个bash就是一个父子关系。进程是有父子关系的,这个4398就是4463的父进程。

然后exit推出这个进程,其实是推出了子进程的bash进程,回到了父进程,还是这个4398的bash进程。
虽然是父子进程的关系,但是子进程是得不到父进程定义的值的,进程隔离。

如果子进程想要得到父进程的值,要使用export命令导出变量的值,这样在子进程中就可以得到父进程变量的值。
export命令在父进程使用后,子进程就可以得到

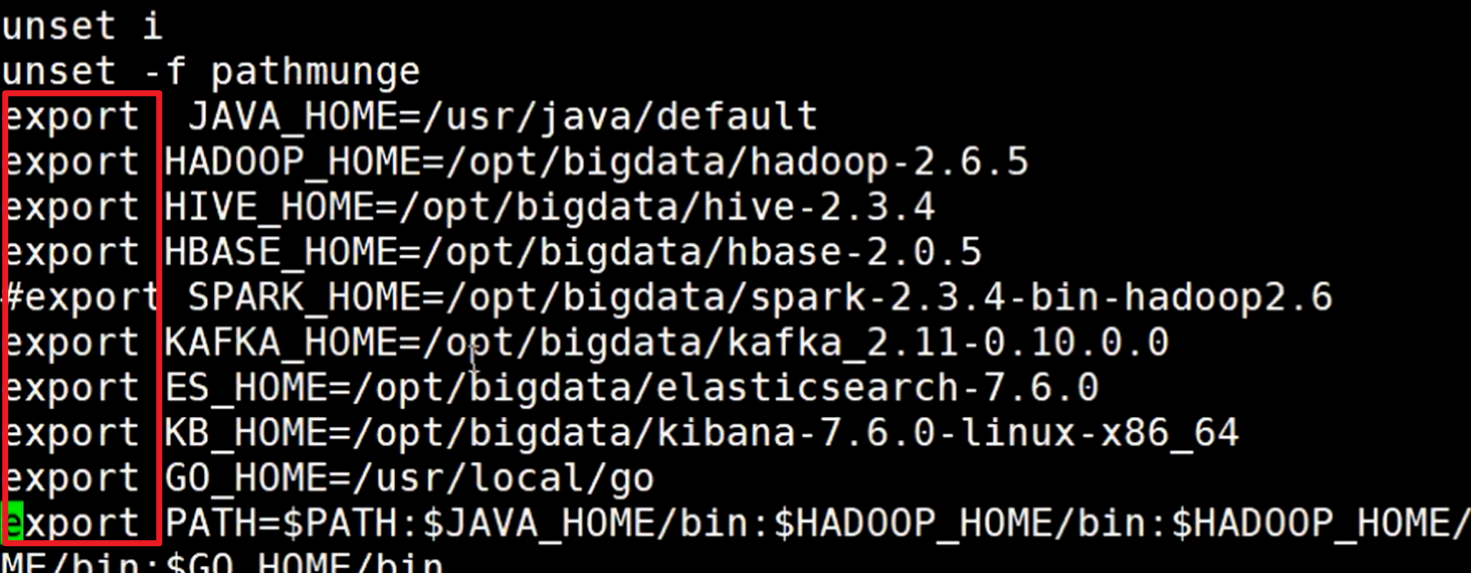
所以在定义jdk环境变量时候,需要使用export这个关键字,因为如果没有的话,定义的变量的值就只能在当前进程使用,子进程无法得到环境变量的值,这肯定不行。
pipeline(管道 | )
-
\[:表示当前bash进程号,**优先级高于管道** \]
- /proc/$$/fd: 当前bash进程的所有文件描述符
lsof -op $$:该命令查看当前bash进程的细节信息
什么是管道?就是|
比如正常使用head命令和tail命令,可以显示一个文件的头10行和末尾的10行数据
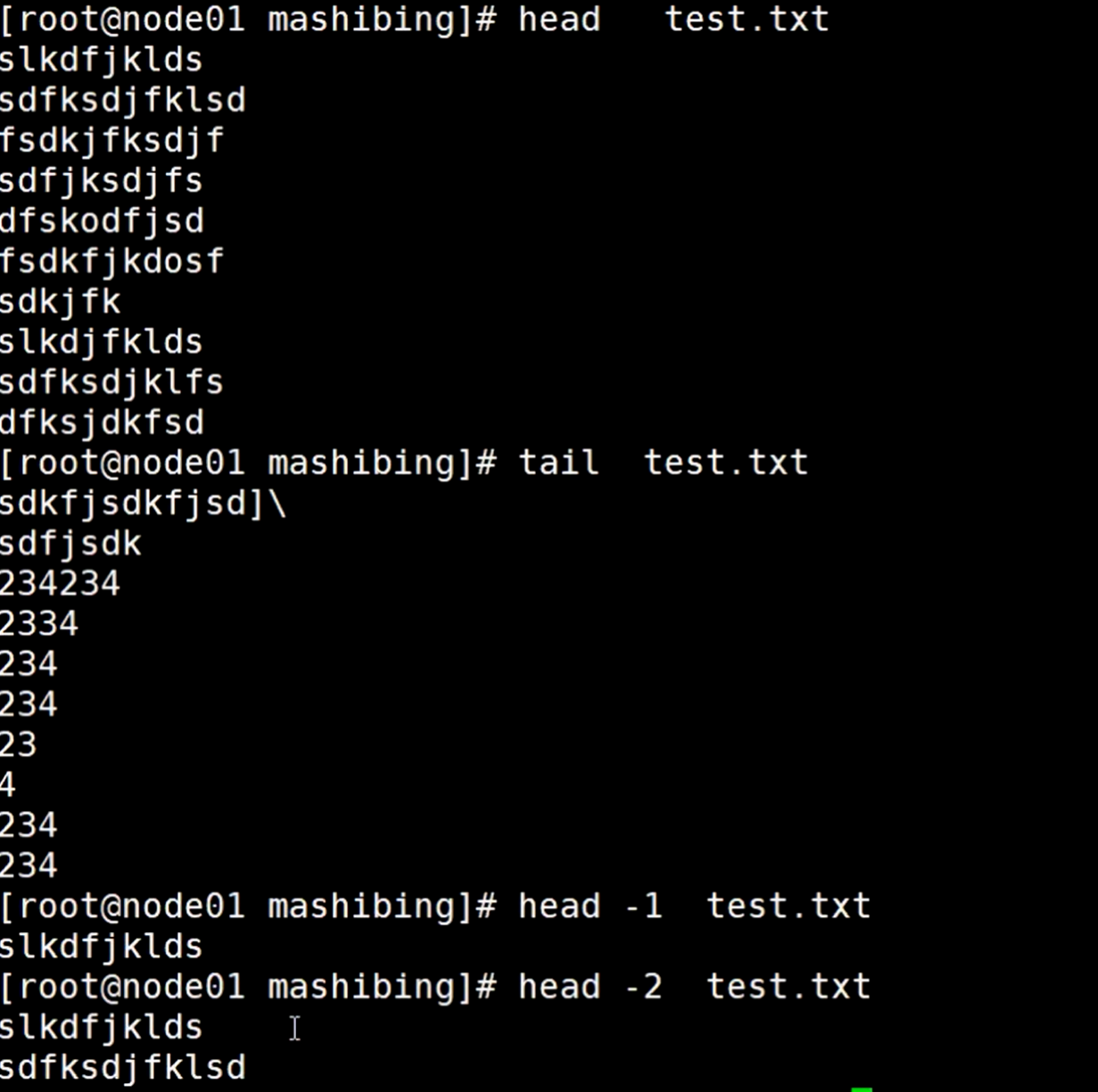
比如,现在要读取第8行数据,怎么办?使用| 选项
很简单,head -8命令读取一个文件的前8行,然后加上tail -1命令取出最后1行,输出的就只会显示第8数据,这里需要使用|管道来辅助命令

只显示了第8行
使用大括号可以执行多条指令,中间记得要加空格,大括号里面的指令都在同一个进程执行的

如果先定义一个a=1,在父进程肯定可以打印出来的,但如果用管道,就得不到这个a的值了
在指令块中把a改成9,然后输出一段字符,通过管道给了cat,cat默认输出是屏幕输出,所以会显示出来

可以看到字符输出了,但是a的值还是1
因为linux操作系统在使用管道时候,所有两边等于是新起了两个子进程来进程对接,所以 a=9 是在子进程中不能生效的
既然管道左右两边都会启动一个子进程,那么验证一下
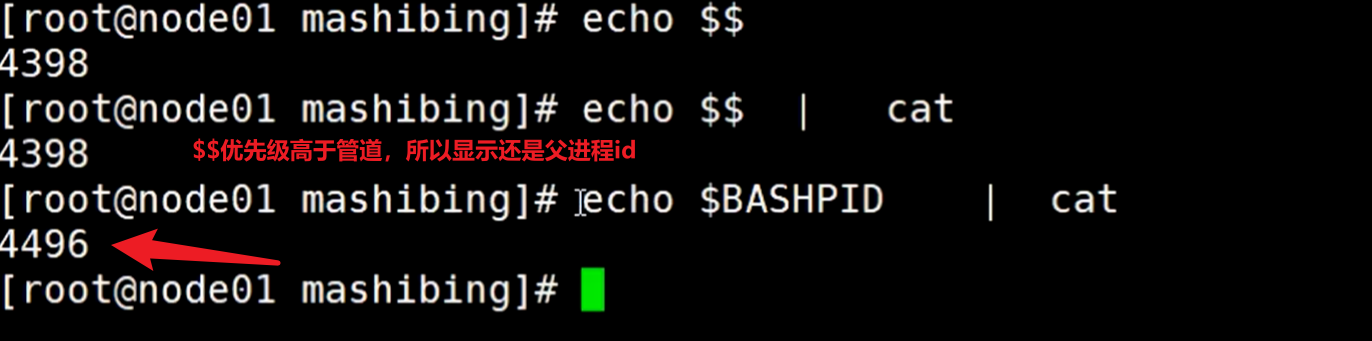
所以查看子进程id要使用$BASHPID
编写两个指令块,使用管道连接起来,打印子进程的id,然后左边读取到x,交给管道以后,右边cat读取到以后,赋值给了y

执行后查看父进程4398的信息,可以看到有两个子进程,4512和4513

然后查看子进程4512的进程信息
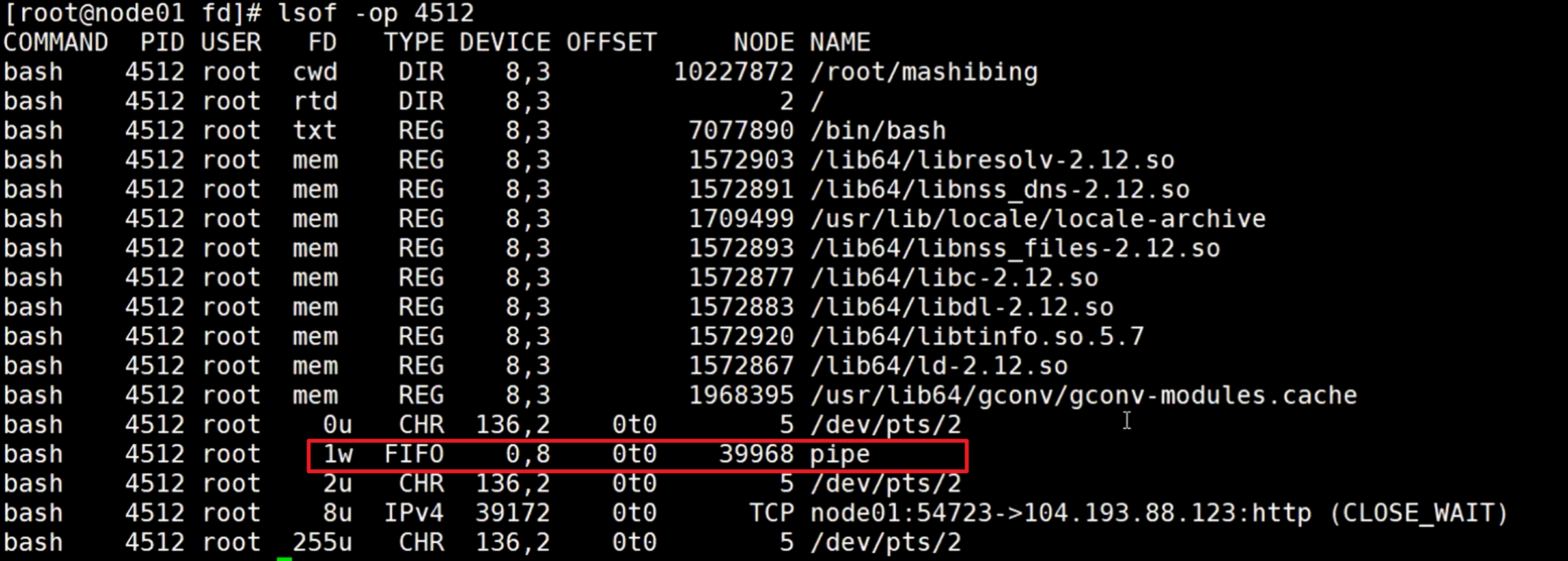
可以看到1标准输出是w写,inode号是39968,pipe管道
再查看子进程4513的进程信息
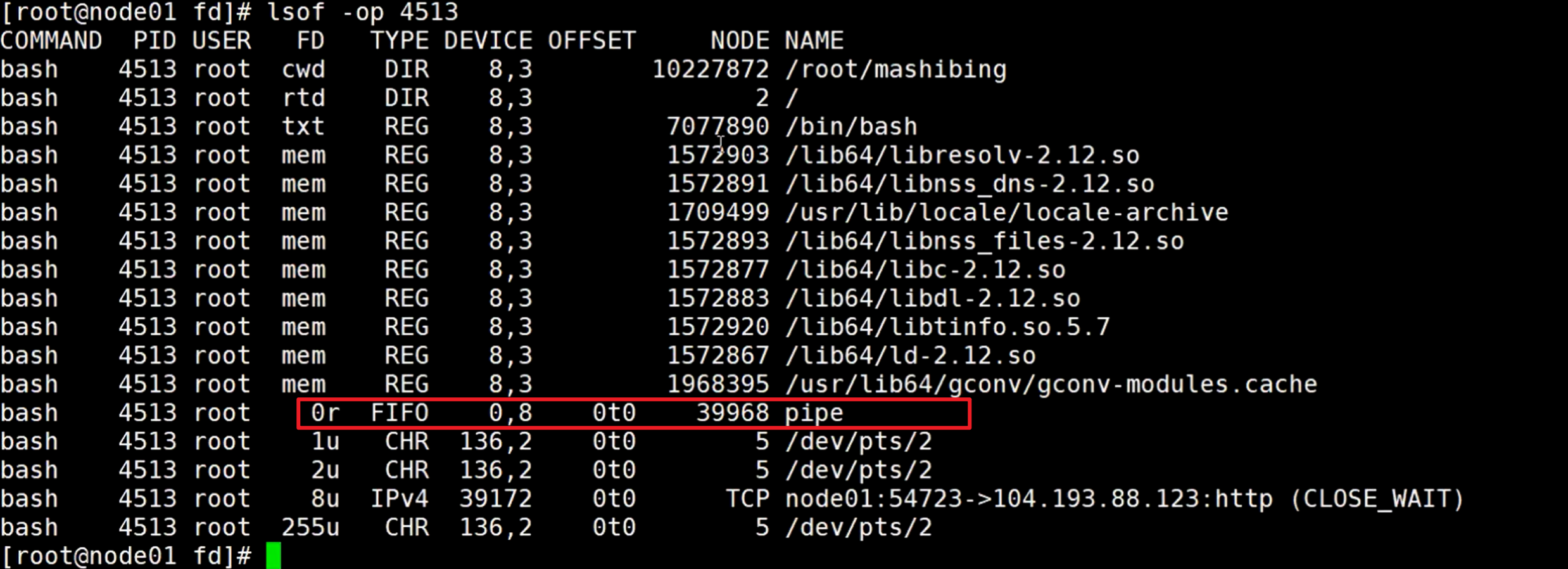
可以看到0标准输入是r读,inode号也是39968,也是pipe管道,所以就对应上了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号