2、字节码和类加载器
Class文件结构
通过字节码看执行细节
示例1
测试代码:
public class IntegerTest {
public static void main(String[] args) {
Integer x = 5;
int y = 5;
System.out.println(x == y);
Integer i1 = 10;
Integer i2 = 10;
System.out.println(i1 == i2);//true
Integer i3 = 128;
Integer i4 = 128;
System.out.println(i3 == i4);//false
}
}
运行代码后:
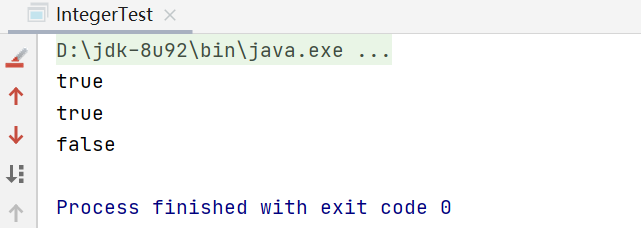
为什么会这样?
使用jclasslib 打开测试类,找到main方法
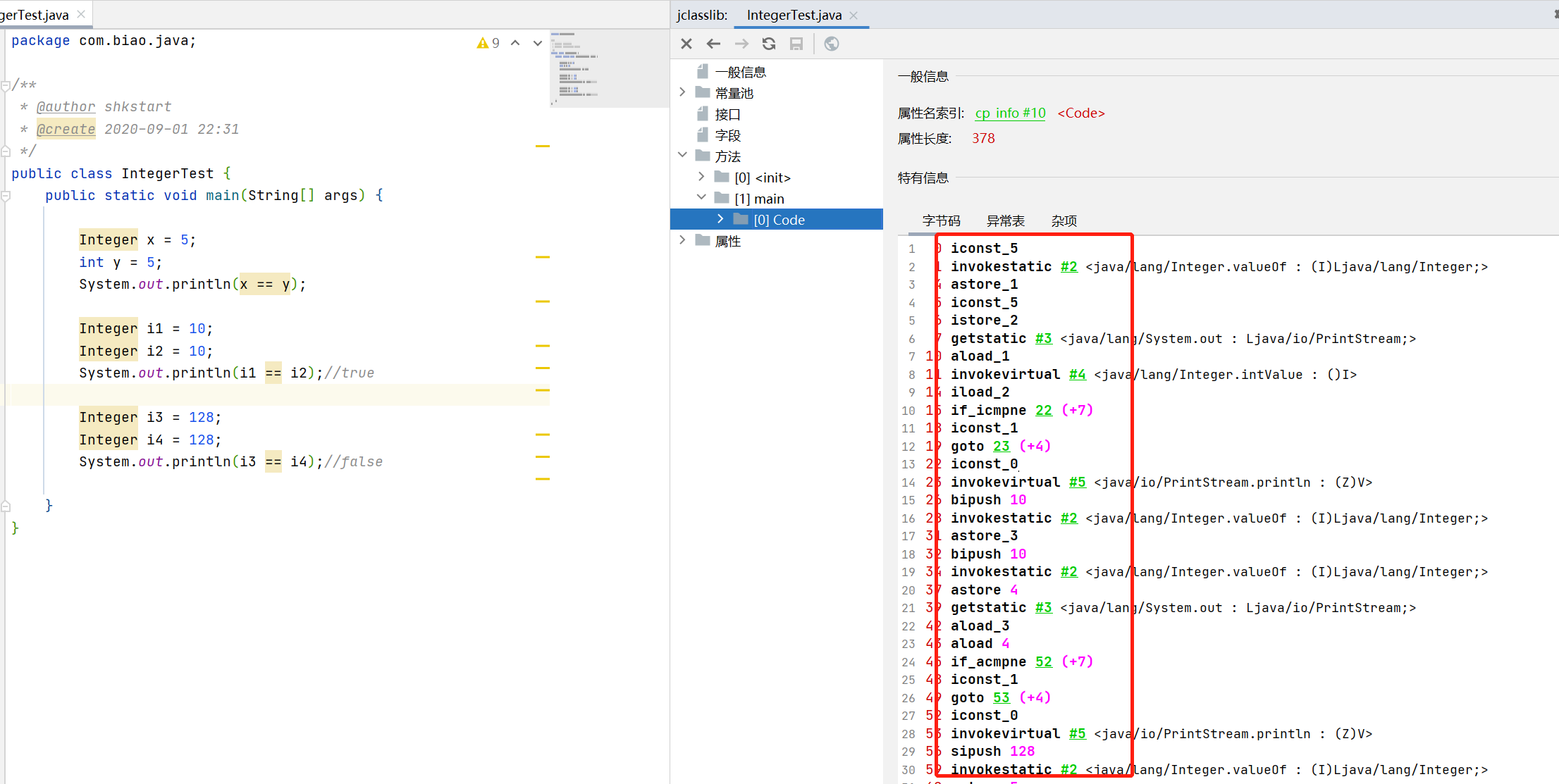
可以看到指令,先定义了一个常量5,放在栈帧的操作数栈里面,然后调用了Integer.valueOf 方法,这个Integer.valueOf方法是干嘛的呢?
找到这个Integer.valueOf的源码
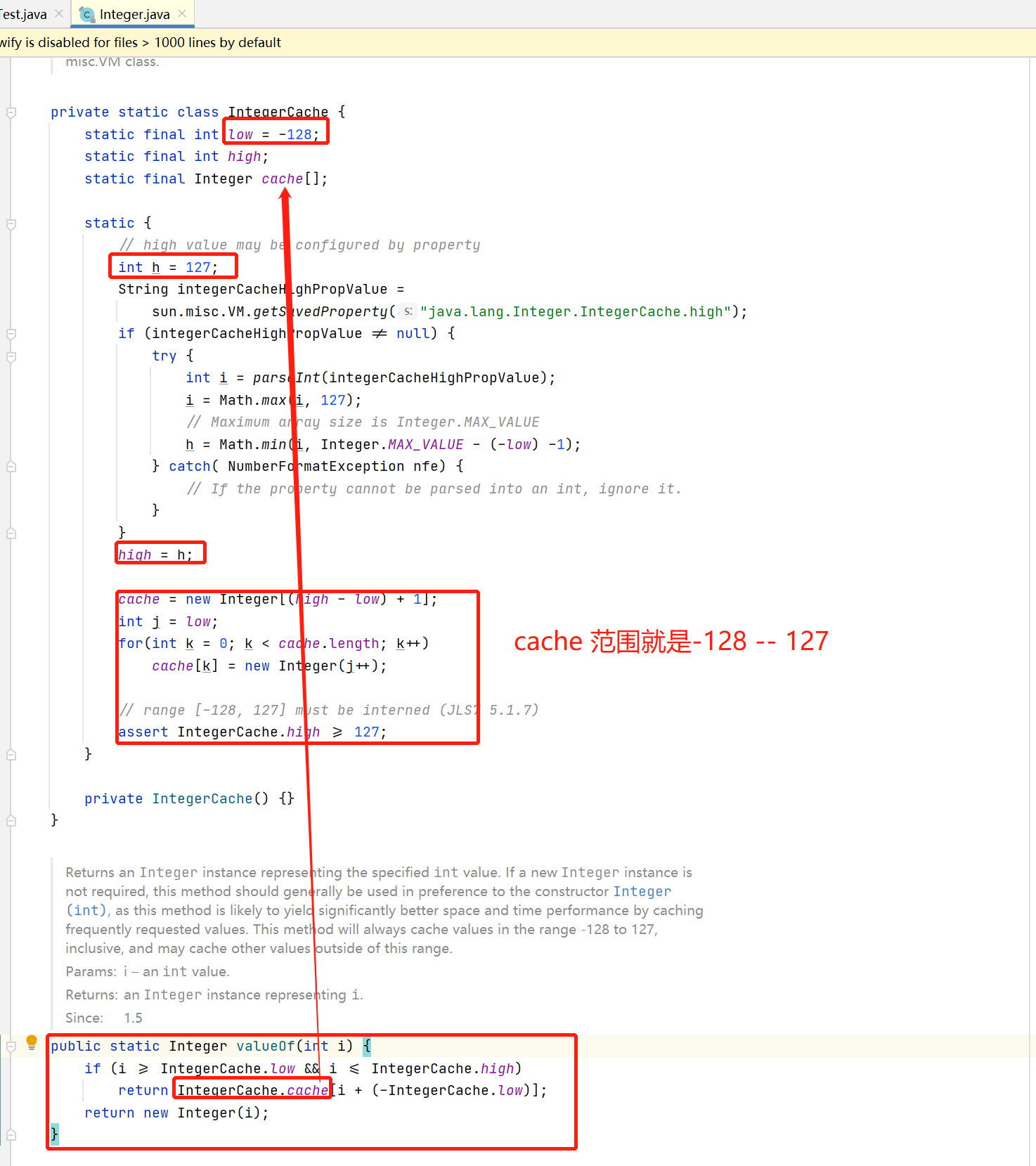
valueOf 方法表示参数值是在cache范围内的话,就把这个值返回出去,否则就重新new了一个Integer
因为i3 和 i4 是128,超出了cache 范围,所以重新new了一个Integer,所以是false
因x = 5,没有超出cache范围,所以定义x 的时候,使用Integer.valueOf方法直接返回,然后保存在局部变量表索引为1 的位置(astore_1),索引为0 的位置存放的是args 参数。
然后定义基本数据类型(int) y为5,存放在局部变量表索引为2的位置(istore_2),本来引用地址和基本数据类型是不可以用 == 比较的,但是涉及到自动拆箱机制(调用的intValue方法),所以直接把X 取出内容基本数据类型的5 来比较,所以为true
示例2
测试代码:
public class StringTest {
public static void main(String[] args) {
String str = new String("hello") + new String("world");
String str1 = "helloworld";
System.out.println(str == str1);
}
}
执行后

使用jclasslib打开,找到main方法
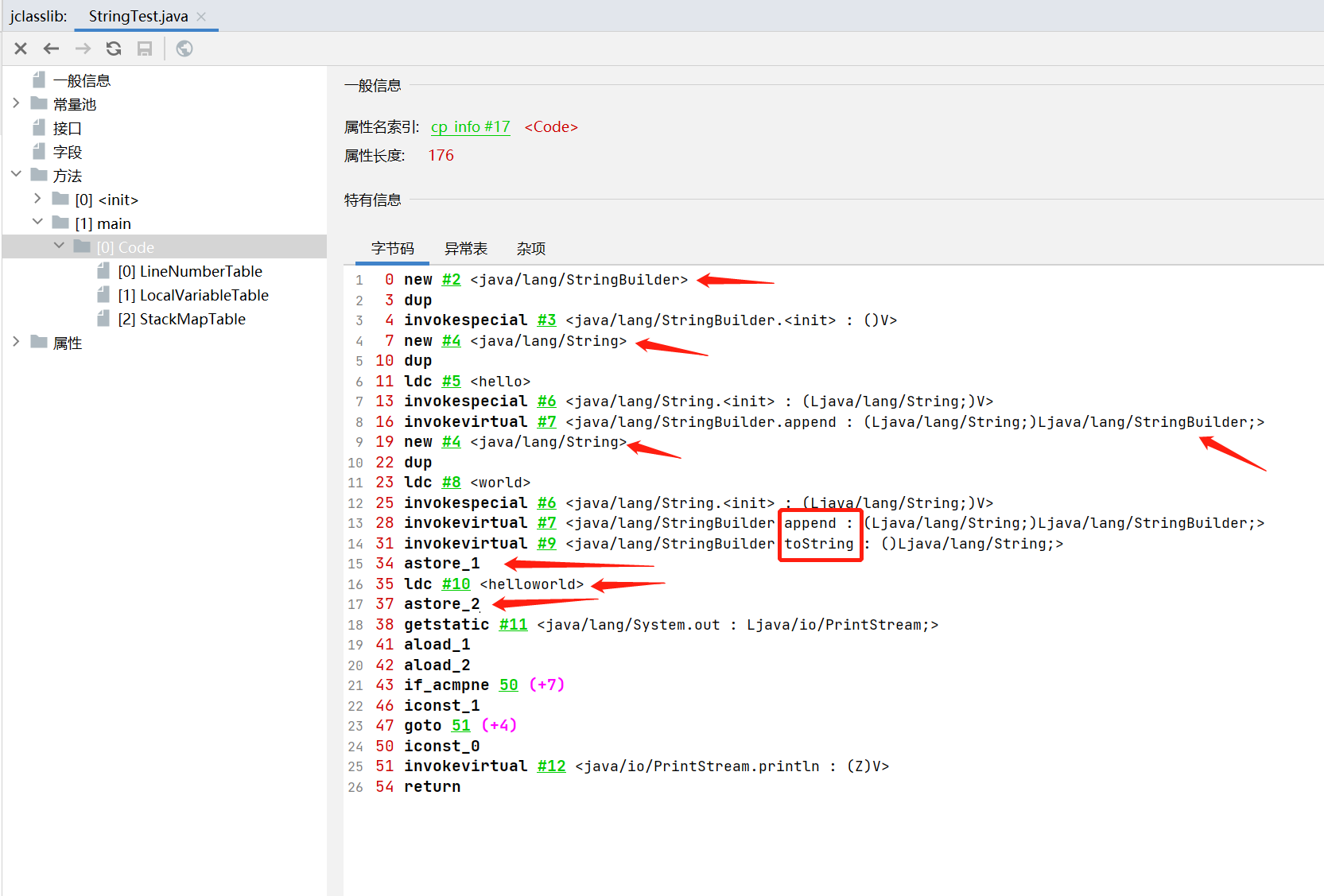
可以看到new 的String,但实际上使用的是StringBuilder,因为返回的是String类型,所以调用了toString()方法,可以看一下StringBuilder的toString()方法,返回的就是String类型
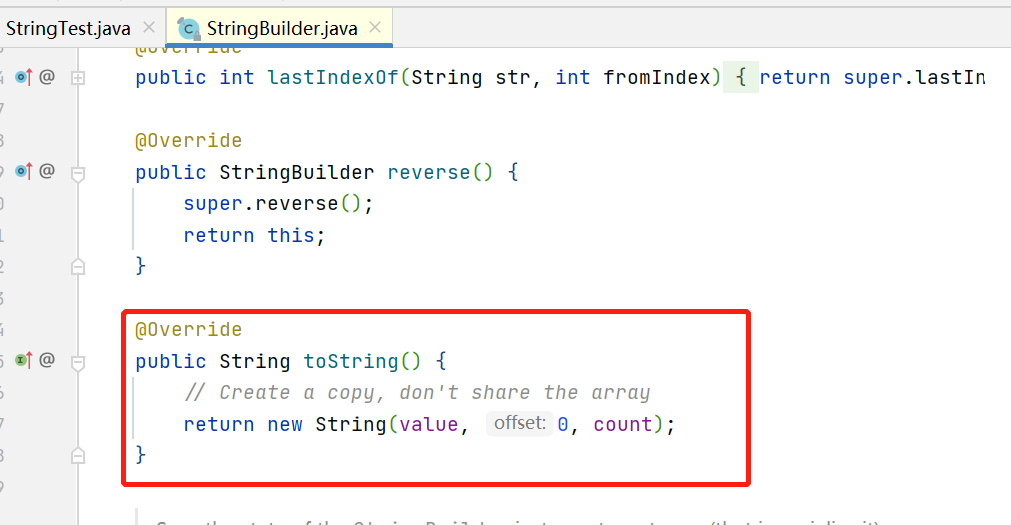
所以hello + world 最后返回的值放在了局部变量表索引为1的位置(astore_1)
后面直接把helloworld 字符串放进了常量表里面,在局部变量表索引为2的位置(astore_2)
两个不同的地址使用 == 比较,当然返回的是false
示例3
测试代码:
class Father {
int x = 10;
public Father() {
this.print();
x = 20;
}
public void print() {
System.out.println("Father.x = " + x);
}
}
class Son extends Father {
int x = 30;
public Son() {
this.print();
x = 40;
}
public void print() {
System.out.println("Son.x = " + x);
}
}
public class SonTest {
public static void main(String[] args) {
Father f = new Son();
System.out.println(f.x);
}
}
执行后:
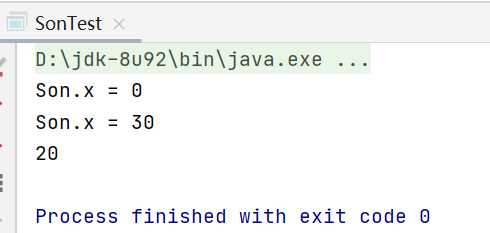
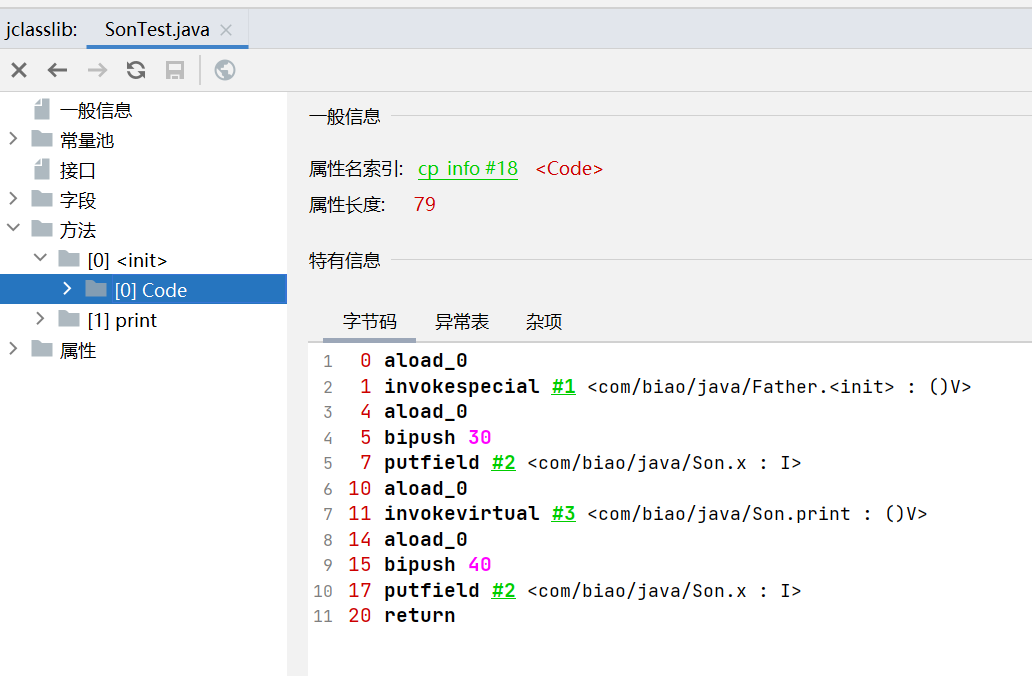
new 的是Son类的对象,返回的是Father,
Son要先去初始化,初始化的话要调用父类Father的print方法,new的是子类Son,Son重写的print方法,所以刚开始打印的x为0 是初始化的值,30是在下面才赋的值
然后父类的x赋值为20了,但是调用的是Son类的print方法,Son类的x为30,这时候以及赋上值了,所以打印为30
最后打印的是父类Father的x的值,为20
解读class文件
字节码文件是什么
源代码经过前端编译器编译之后,生成一个字节码文件,字节码文件是一个二进制文件,内容是JVM的指令,而不像C、C++ 经过编译直接就是机器码。
什么是字节码指令
字节码指令是一个字节长度的、代表某种特定操作含义的操作码,以及跟随其后的零至多个代表此操作所需要的操作数所构成。虚拟机中许多指令并不包括操作数,只有一个操作码。
比如:
Class类的本质
任何一个Class文件都对应着唯一一个类或接口的定义信息,但反过来说,Class文件实际并不一定以磁盘方式存在。Class文件是一组以8位字节为基础的二进制流。
class文件数据类型
| 数据类型 | 定义 | 说明 |
|---|---|---|
| 无符号数 | 无符号数可以用来描述数字、索引引用、数量值或按照utf-8编码构成的字符串值。 | 其中无符号数属于基本的数据类型。 以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和8个字节 |
| 表 | 表是由多个无符号数或其他表构成的复合数据结构。 | 所有的表都以“_info”结尾。 由于表没有固定长度,所以通常会在其前面加上个数说明。 |
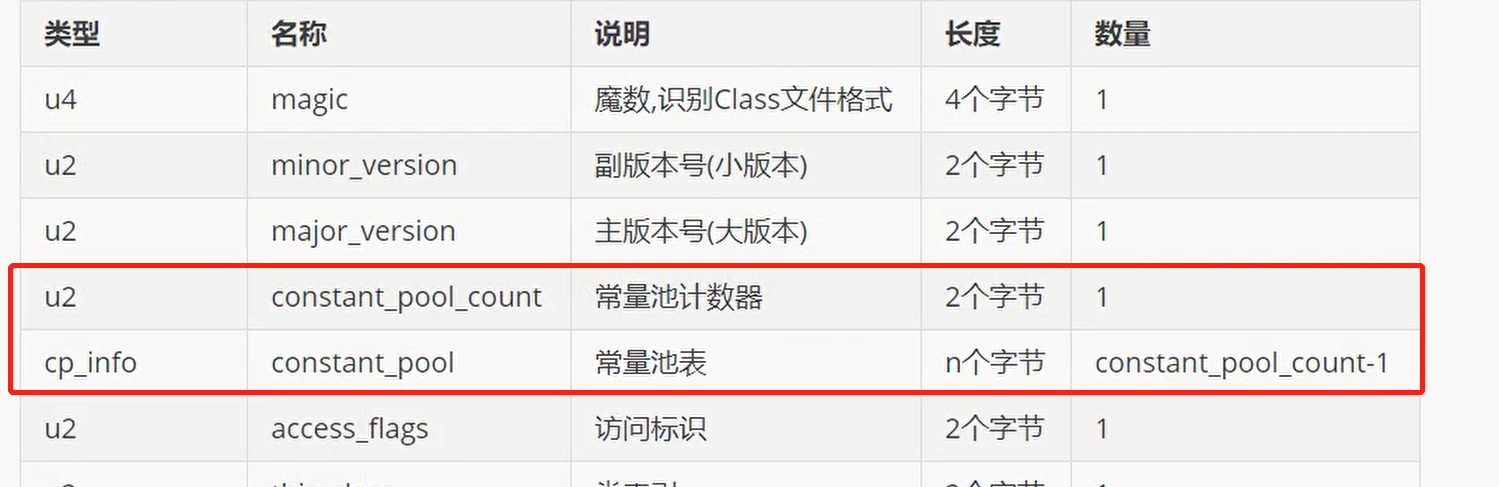
class文件结构
| 类型 | 名称 | 说明 | 长度 | 数量 |
|---|---|---|---|---|
| u4 | magic | 魔数,识别Class文件格式 | 4个字节 | 1 |
| u2 | minor_version | 副版本号(小版本) | 2个字节 | 1 |
| u2 | major_version | 主版本号(大版本) | 2个字节 | 1 |
| u2 | constant_pool_count | 常量池计数器 | 2个字节 | 1 |
| cp_info | constant_pool | 常量池表 | n个字节 | constant_pool_count-1 |
| u2 | access_flags | 访问标识 | 2个字节 | 1 |
| u2 | this_class | 类索引 | 2个字节 | 1 |
| u2 | super_class | 父类索引 | 2个字节 | 1 |
| u2 | interfaces_count | 接口计数器 | 2个字节 | 1 |
| u2 | interfaces | 接口索引集合 | 2个字节 | interfaces_count |
| u2 | fields_count | 字段计数器 | 2个字节 | 1 |
| field_info | fields | 字段表 | n个字节 | fields_count |
| u2 | methods_count | 方法计数器 | 2个字节 | 1 |
| method_info | methods | 方法表 | n个字节 | methods_count |
| u2 | attributes_count | 属性计数器 | 2个字节 | 1 |
| attribute_info | attributes | 属性表 | n个字节 | attributes_count |
魔数(Magic Number)
每个class文件开头的4个字节无符号整数称为魔数
它的唯一作用是确定这个文件是否为一个能被虚拟机接受的有效合法class文件,魔数就是class文件的标识。
魔数值固定是 0 * CA FE BA BE,不会改变。
如果一个class文件不是0 * CA FE BA BE开头,虚拟机进行文件校验时候直接抛异常:

使用魔数,而不是扩展名标识class文件,来进行识别基于安全方面的考虑,因为文件的扩展名是可以随便修改的。

class文件版本
魔数(0 * CA FE BA BE)后面紧接着的4个字节是class文件的版本号,
第5、6 个字节表示编译的副版本号minor_version,
第7、8 个字节是编译的主版本号major version
它们共同组成了class文件格式的版本号,比如class文件主版本号是M,副版本号是m,这个class文件格式的版本号就是M.m
版本号和java编译器对应关系如下:
| 主版本(十进制) | 副版本(十进制) | 编译器版本 |
|---|---|---|
| 45 | 3 | 1.1 |
| 46 | 0 | 1.2 |
| 47 | 0 | 1.3 |
| 48 | 0 | 1.4 |
| 49 | 0 | 1.5 |
| 50 | 0 | 1.6 |
| 51 | 0 | 1.7 |
| 52 | 0 | 1.8 |
| 53 | 0 | 1.9 |
| 54 | 0 | 1.10 |
| 55 | 0 | 1.11 |

java的版本号是从45开始的,jdk1.1之后每个jdk大版本发布主版本号,向上+1,
不同版本java编译器编译的class文件对应的版本是不一样的,高版本的java虚拟机可以执行低版本虚拟机编译的class文件,
但是低版本虚拟机不能执行高版本虚拟机编译的class文件 (向下兼容)
否则抛异常:java.lang.UnsupportedClassVersionError

常量池
版本号过后,紧跟着的是常量池的数量,以及若干个常量池选项(constant_pool)。
常量池数量不是固定的,所以常量池入口需要u2类型的无符号数,表示常量池容量计数值。这个容量计数是从1开始的,不是从0开始的。

常量池表中用于存放编译时期生产的各种字面量和符号引用,这部分内容在类加载后,进入方法区的运行时常量池中存放。
之前已经知道:字符串常量在1.8及以后在堆中,其他常量在元空间的运行时常量池,而1.7及之前都叫方法区
常量池计数器

如:常量池计数器值为 0 * 0016,算一下,也就是22,
但是实际上只有21项常量,索引范围是1-21,它的索引下标从1开始的,
因为它把第0索引的位置给空出来了,为了满足之后某些常量池索引的数据在特殊情况下,需要表达不引用任何一个常量池的含义,这种情况用索引0表示。
所以常量池计数器的值 = 常量池计数器值 - 1,要有一个 -1 的操作
常量池主要放两大类常量:字面量 和 符号引用
字面量
- 文本字符串 如:
Stirng a = "abc" - 声明final的常量值 如:
final int NUM = 10
符号引用
- 类和接口的全限定名
仅仅是把包名的.替换成/,为了是连续的多个全限定名不产生混淆,使用时最后一般会加上;,表示全限定名结束 - 字段的名称和描述符 比如字段的类型
- 方法的名称和描述符 比如返回值类型,形参
类型描述符:
| 标志符 | 含义 |
| ------ | ---------------------------------------------------- |
| B | 基本数据类型byte |
| C | 基本数据类型char |
| D | 基本数据类型double |
| F | 基本数据类型float |
| I | 基本数据类型int |
| J | 基本数据类型long |
| S | 基本数据类型short |
| Z | 基本数据类型boolean |
| V | 代表void类型 |
| L | 对象类型,比如:Ljava/lang/Object;|
| [ | 数组类型,代表一维数组。比如:double[][][] is [[[D|
常量池类型
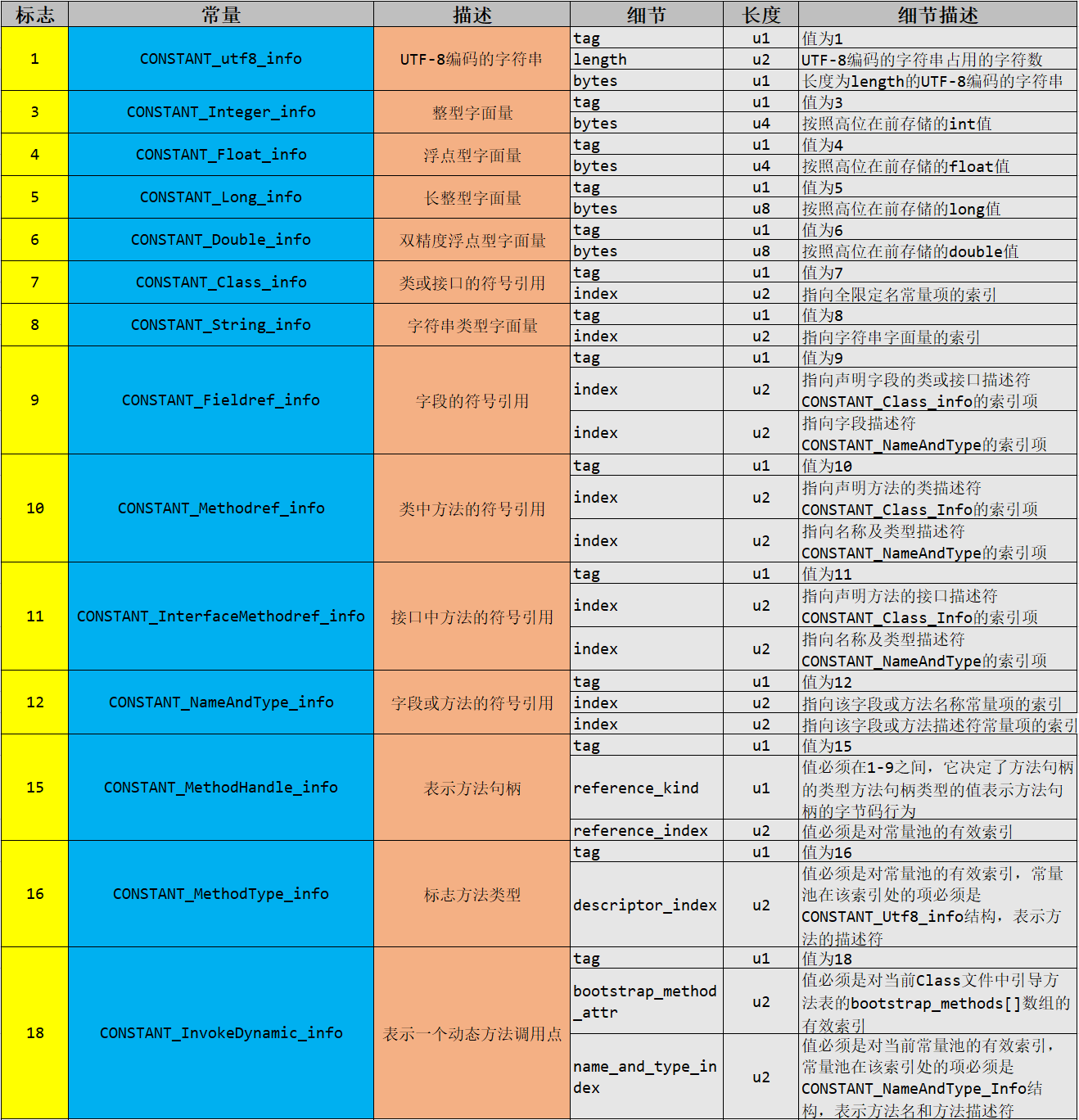
可以根据这个慢慢解读class文件常量池部分内容!

当然,正常我们搞java开发的人一般不会自己一个一个字节解读,都是用javap命令 或者 jclasslib工具
访问标志
常量池后面,紧跟着的是访问标记。
标记使用2个字节表示,用于识别一些类或接口层次的访问信息,包括是否定义为public,是否是抽象的,类的话是否是final声明的。
各种访问标记如下:
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 标志为public类型 |
| ACC_FINAL | 0x0010 | 标志被声明为final,只有类可以设置 |
| ACC_SUPER | 0x0020 | 标志允许使用invokespecial字节码指令的新语义,JDK1.0.2之后编译出来的类的这个标志默认为真。(使用增强的方法调用父类方法) |
| ACC_INTERFACE | 0x0200 | 标志这是一个接口 |
| ACC_ABSTRACT | 0x0400 | 是否为abstract类型,对于接口或者抽象类来说,次标志值为真,其他类型为假 |
| ACC_SYNTHETIC | 0x1000 | 标志此类并非由用户代码产生(即:由编译器产生的类,没有源码对应) |
| ACC_ANNOTATION | 0x2000 | 标志这是一个注解 |
| ACC_ENUM | 0x4000 | 标志这是一个枚举 |
类索引、父类索引、接口索引
访问标记后面,会指定类的类别、父类类别,以及实现的接口:
| 长度 | 含义 |
|---|---|
| u2 | this_class |
| u2 | super_class |
| u2 | interfaces_count |
| u2 | interfaces[interfaces_count] |
-
类索引
2个字节无符号整数,指向常量池的索引,提供类的全限定名,this_class的值必须是常量池表中某项的一个有效索引值。 -
父类索引
2字节无符号整数,指向常量池的索引,提供当前类父类的全限定名。
如果没有继承父类,默认继承是Object,同时不支持多继承,所以只有一个父类。 -
interfaces
指向常量池索引集合,提供一个符号引用到所有以实现的接口。
因为类可以实现多个接口,所有需要以数组形式保存接口的索引。
字段表集合
就是类中的属性,就是声明的变量,但不包括方法内部,代码块内部,声明的局部变量。
字段叫什么名,被定义什么类型,都是无法固定的,只能引用常量池中的常量来描述。
是指向常量池索引的集合,描述每个字段的完整信息。比如:字段的标识符,是否是静态的,是否是常量等
方法表集合
指向常量池的索引集合,描述每个方法的签名,对应一个类或接口中方法的信息,比如:方法的修饰符,参数等。
只描述当前类或接口中声明的方法,不包括父类中继承过来的。
属性表集合
方法表集合后面是属性表集合,表示class文件携带的辅助信息,比如class源文件的名称。这类信息被用于虚拟机验证和运行以及调试。
字节码指令集解析
大部分指令没有支持整数类型的bute、char 和 short,甚至没有支持boolean类型,在栈帧里面操作数栈上,都是以槽(slot)为单位的,一个槽是4个字节,所以大多数对于boolean、byte、char、short类型的操作,实际上都是使用相应的int类型作为运算类型。
字节码指令集按用途大致分为9类:
- 加载与存储指令
- 算术指令
- 类型转换指令
- 对象创建和访问指令
- 方法调用与返回指令
- 操作数栈管理指令
- 比较控制指令
- 异常处理指令
- 同步控制指令
加载与存储指令
作用:加载和存储指令用于数据从栈帧的 局部变量表 和 操作数栈 之间来回传递。
常用指令:
- 局部变量表指令(局部变量表加载到操作数栈)
xload: 其中x为i、l、f、d、axload_<n>: n为下标索引的值

示例代码:
//1.局部变量压栈指令
public void load(int num, Object obj,long count,boolean flag,short[] arr) {
System.out.println(num);
System.out.println(obj);
System.out.println(count);
System.out.println(flag);
System.out.println(arr);
}
使用jclasslib 对照着验证一下

- 常量入栈指令(一个常量加载到操作数栈)
bipush、sipush、ldc、ldc_w、ldc2_w、aconst_null、iconst_m1、iconst_<i>、lconst_<1>、fconst_<f>、dconst_<d>
如:iconst_<i>: i为具体的数值
示例:
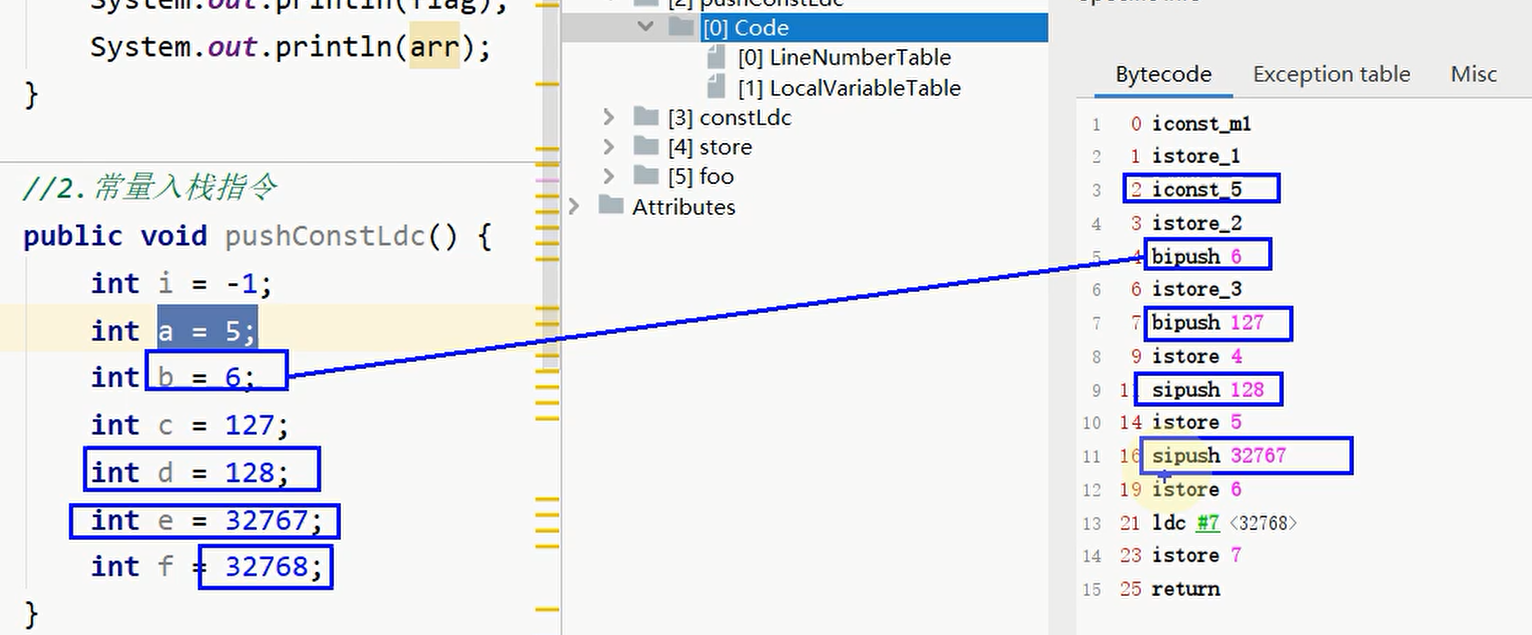
- 出栈到局部变量表指令(从操作数栈存储到局部变量表)
xstore、xstore_<n>、xastore
n表示索引的位置

算术指令
-
加:iadd,ladd,fadd,dadd
-
减:isub,lsub,fsub,dsub
-
乘:imul,lmul,fmul,dmul
-
除:idiv,ldiv,fdiv,ddiv
-
余数:irem,lrem,frem,drem
-
取负(反):ineg,lneg,fneg,dneg
-
移位:ishl,lshr,iushr,lshl,lshr,lushr
-
按位或:ior,lor
-
按位与:iand,land
-
按位异或:ixor,lxor
-
比较指令
lcmp 比较long类型值
fcmpl 比较float类型值(当遇到NaN时,返回-1)
fcmpg 比较float类型值(当遇到NaN时,返回1)
dcmpl 比较double类型值(当遇到NaN时,返回-1)
dcmpg 比较double类型值(当遇到NaN时,返回1)
类型转换指令
-
宽化类型转换
小范围类型向大范围类型安全的转换,就是说不需要指令执行:比如:
int类型 -> long,或者 float类型 -> double -
窄化类型转换
就是强制类型转换,这里叫窄化,就是说大范围类型转为小范围类型:比如:
int类型 -> byte,long类型 -> int
对象创建和访问指令
-
创建类的实例:new
-
创建数组:
- newarray: 创建基本类型数组
- anewarray: 创建引用类型数组
- multianewarray: 创建多维数组
需要注意的是:
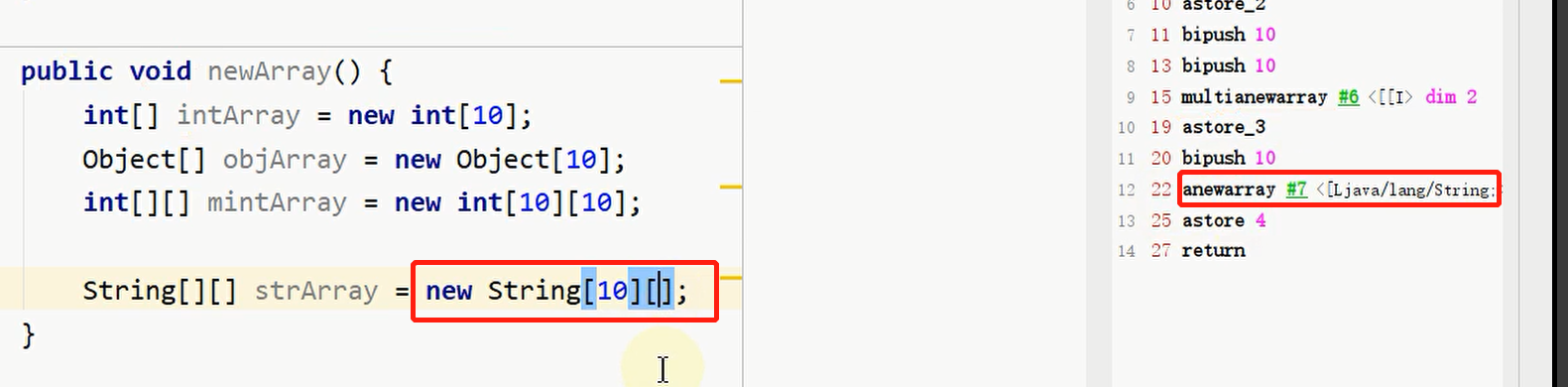
如果定义的二维数组没有给具体的定义,相当于还没有初始化,用的还是一维数组,等于定义了长度10的数组,里面存放的每个下标的值都是数组
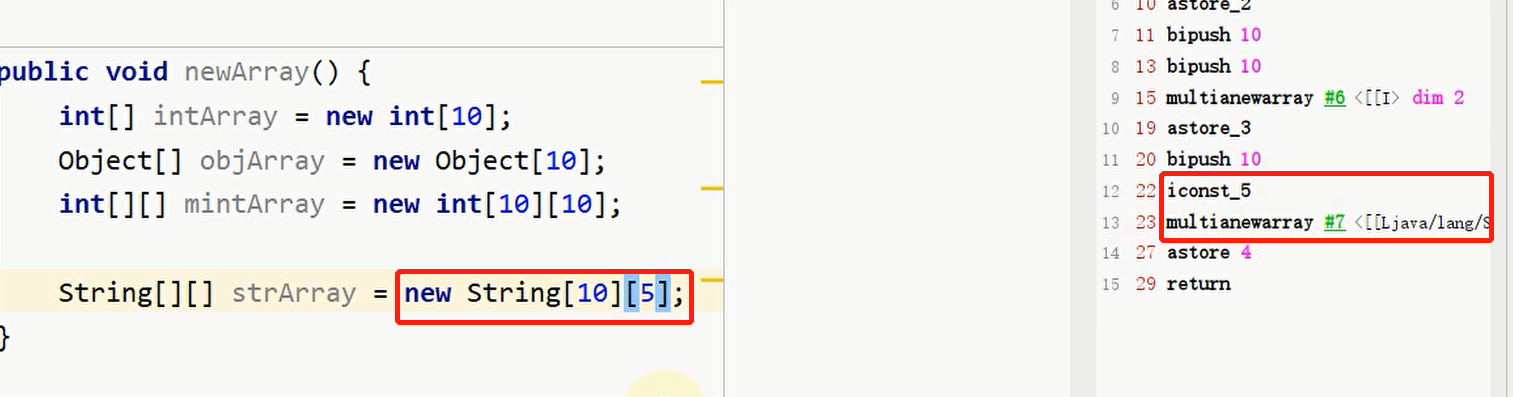
这样就会使用二维数组指令
方法调用与返回指令
调用指令:
- invokevirtual
- invokeinterface
- invokespecial
- invokestatic
- invokedynamic
返回指令:
就是返回类型,如:boolean、byte、char、short、int 类型,都是用ireturn
如果返回值是void,那就是return
操作数栈管理指令
有时候不需要操作数栈范围的指令,在操作数栈范围内就可以解决的,所有就是操作数栈管理指令
不带_x的指令是赋值压入栈顶的指令,如:dup,dup2表示压入2个solt的数据
带_x的指令是赋值栈顶数据并插入指定位置。
- dup_x1
- dup_x2
- dup2_x1
- dup2_x2
pop 和 pop2 表示出栈
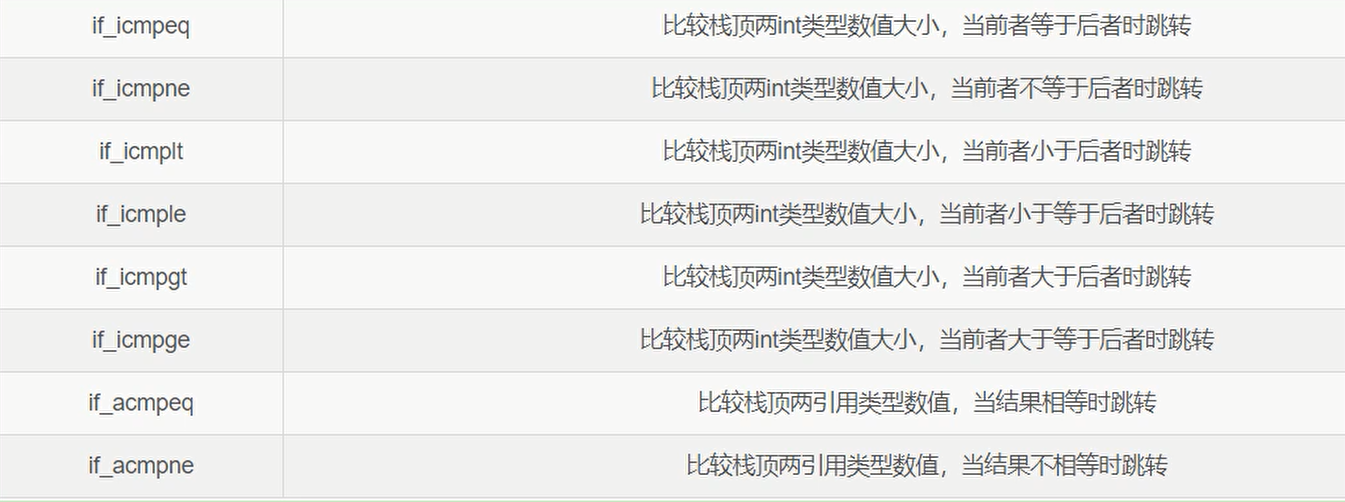
比较控制指令
比较指令只能比较数值,比如boolean、引用数据类型,都不能比较大小的。
跳转指令:
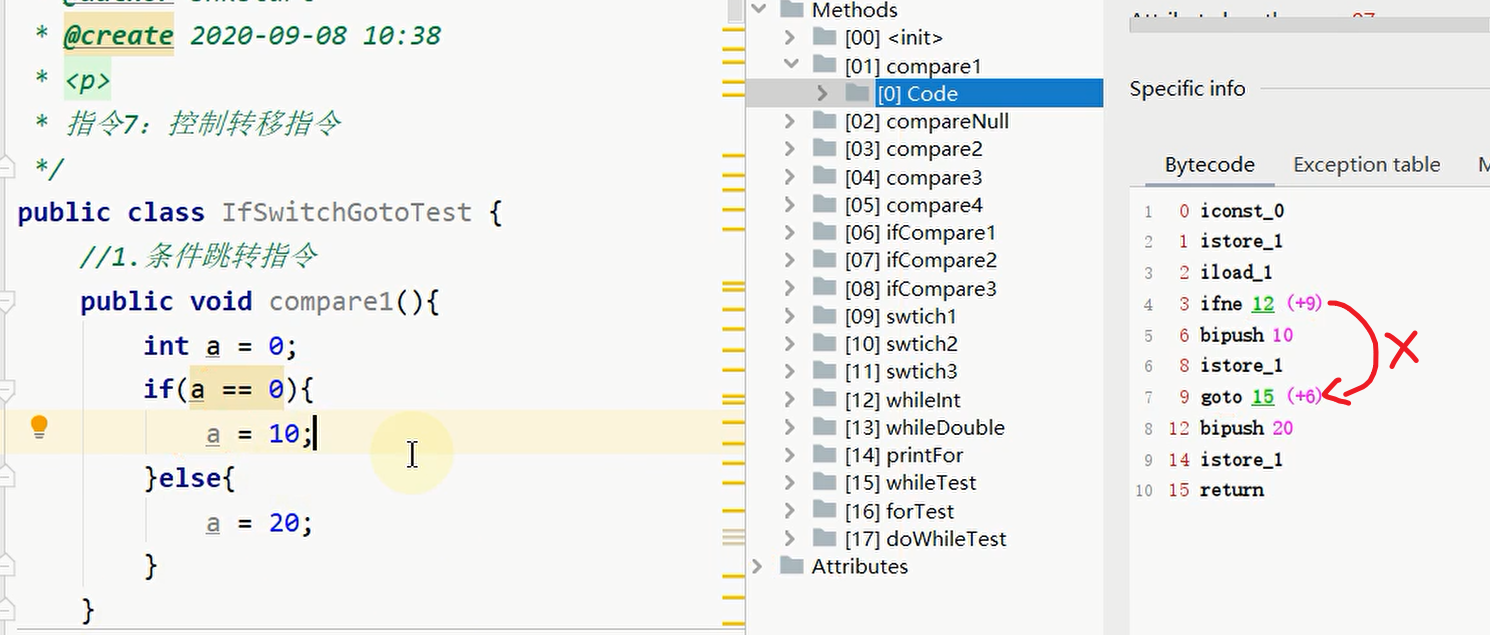
如果给条件取反:
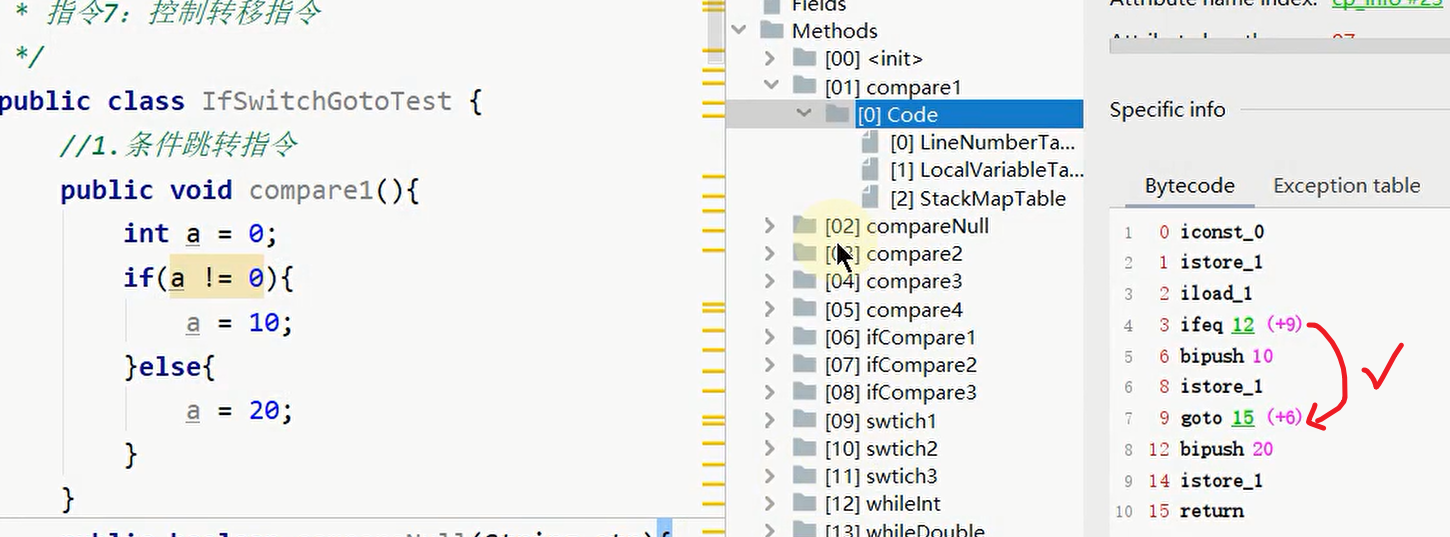
比较跳转指令:
异常处理指令
在一些程序自动抛异常的情况下,是看不到抛异常的指令的,如果手动要抛出一个异常,可以在字节码指令集看到athrow指令
如果一个方法定义try-catch 或者 try-finally 的异常处理,就会创建一个异常表,包含每个异常处理或者finally块的信息。
异常表里保存处理信息:
- 起始位置
- 结束位置
- 程序计数器记录的代码偏移地址
- 被捕获的异常类在常量池的索引
同步控制指令
1、方法级的同步:
是隐式的,无需通过字节码指令控制。
虚拟机从方法常量池的方法表结构中得知是否有ACC_SYNCHRONIZED标识,就知道是否是声明了同步方法。
2、同步代码块
如果在方法内定义了同步代码块,jvm指令集有monitorenter 和 monitorexit两条指令支持,加锁和释放锁。
类加载过程
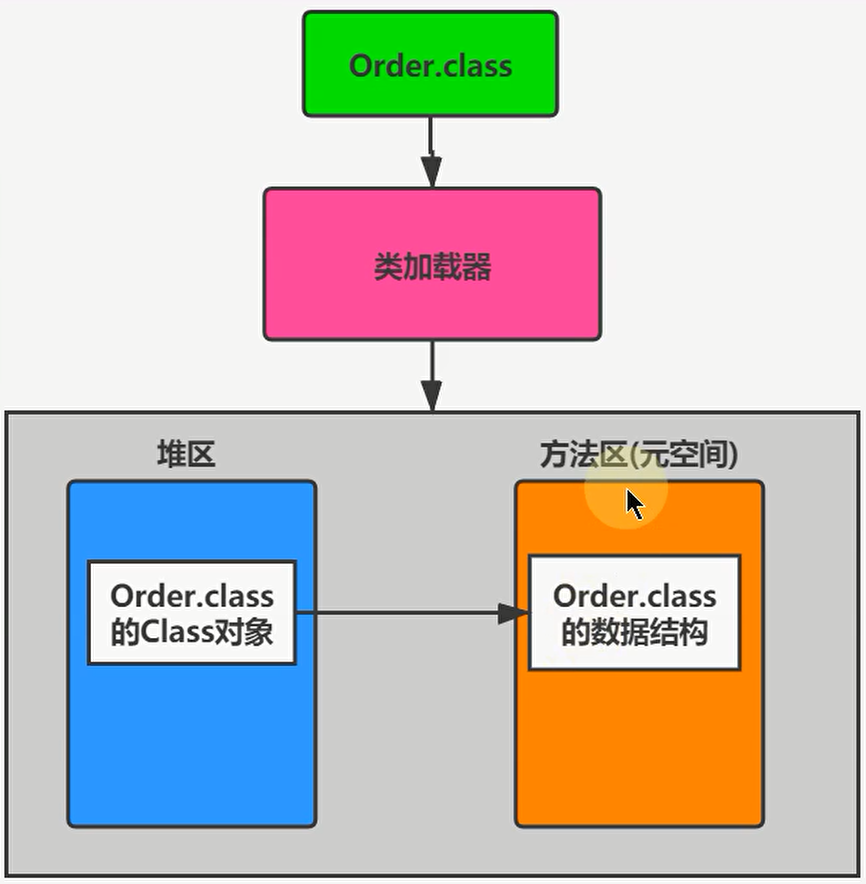
Loading(加载)阶段
所谓加载,就是java类的字节码文件加载到机器内存中,并构建出模板对象。
就是查找并加载二进制数据,生成class实例。
加载时,虚拟机通过类的全类名获取类的二进制数据流,解析二进制数据流为方法区内的数据结构,创建类的实例。
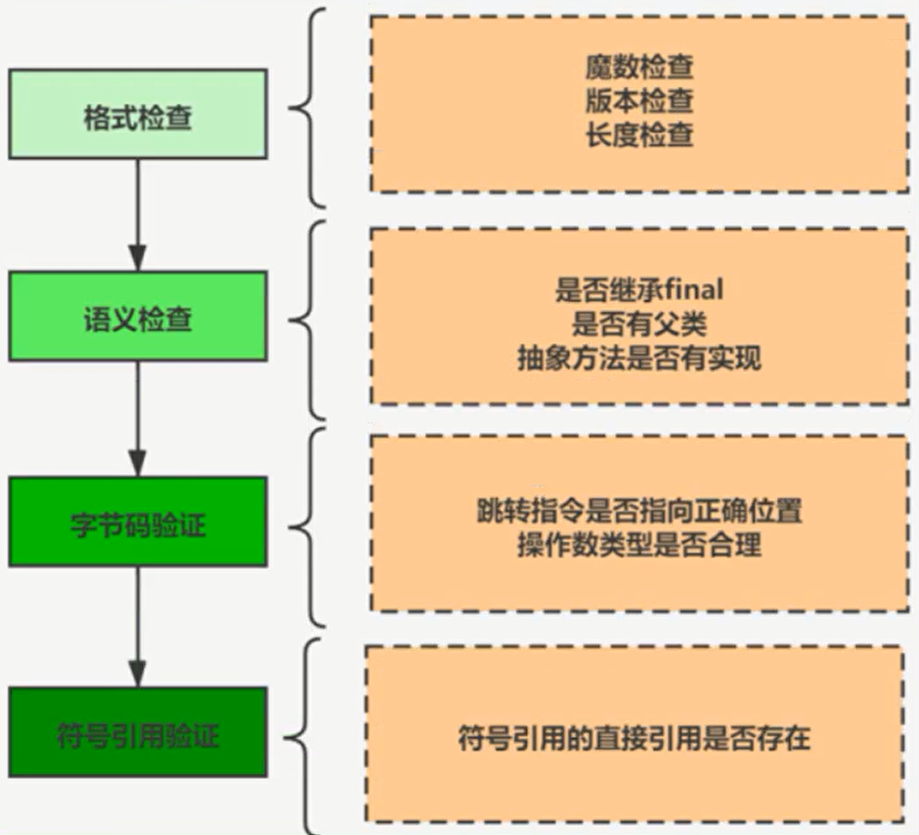
Linking(链接)阶段
验证
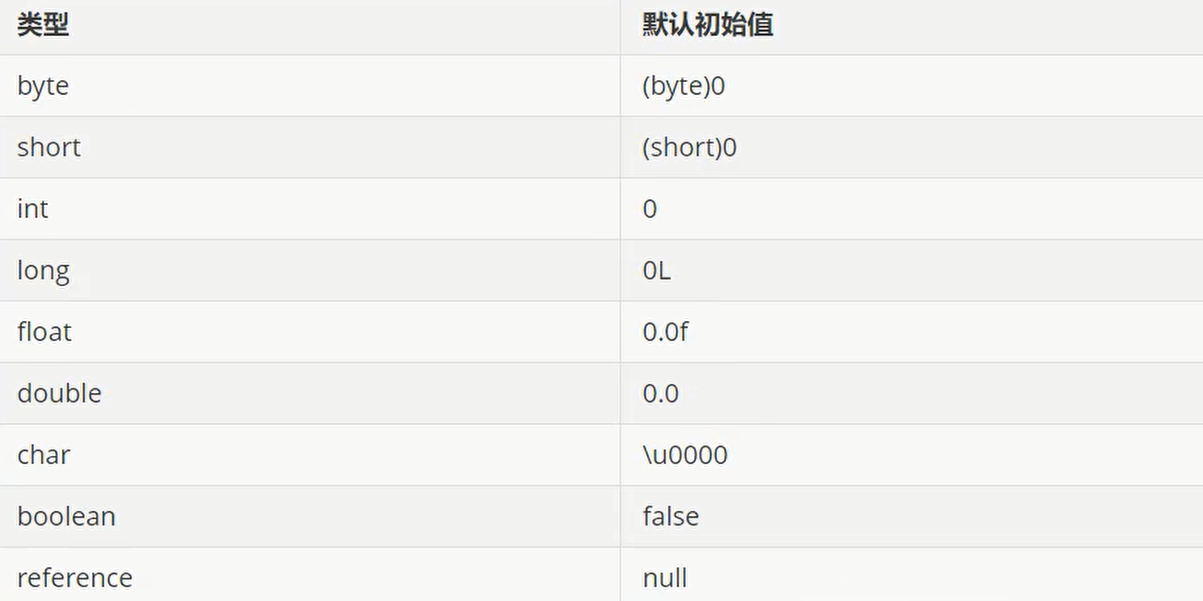
准备
就是为类的静态变量分配内存,并将其初始化为默认值。
解析
将类、接口、字段、方法 的符号引用,转为直接引用(真实的内存中的偏移量)。这样就可以直接调用。
Initialization(初始化)阶段
类初始化是类加载的最后一个阶段。
初始化阶段重要的工作是执行类的初始化方法:<clinit>()方法
然后给定义的静态属性显式赋值
在加载一个类之前,总是试图加载这个类的父类,所以父类的<clinit>()方法在子类的<clinit>()方法之前被调用,父类的静态代码块优先级高于子类。
虚拟机保证一个类的<clinit>()方法在多线程环境下被正确的加锁,如果多线程同时去初始化一个类,只会有一个线程去执行这个类的<clinit>()方法,其他线程需要阻塞。
所以一个类的<clinit>()方法会很耗时,引发死锁,并且这种死锁很难发现,因为看起来没有可用的信息。
如果一个类是主动使用,就会调用<clinit>()方法,如果是被动使用,就不会调用<clinit>()方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号