MySql索引概述
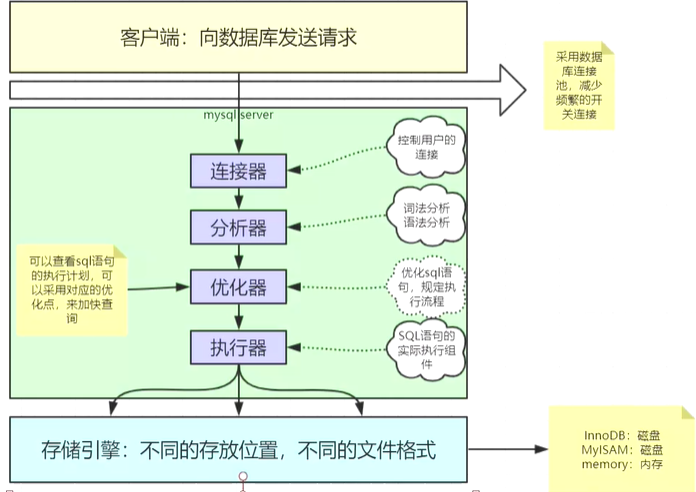
mysql基本架构:
为什么mysql使用b+树
为什么不使用hash表

hash表既然不合适,就考虑用树,用什么树?
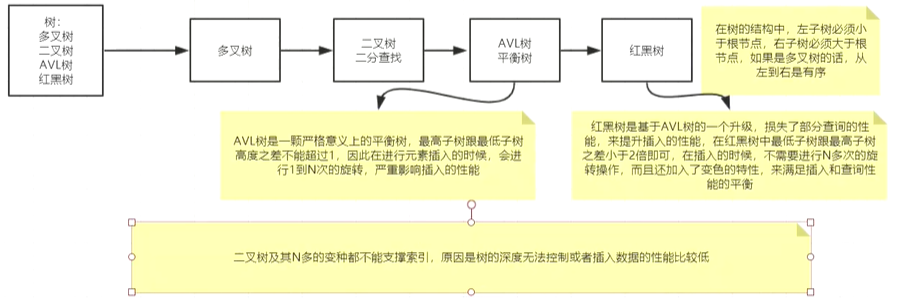
二叉树不能考虑,所以考虑多叉树
B树就是多叉树:
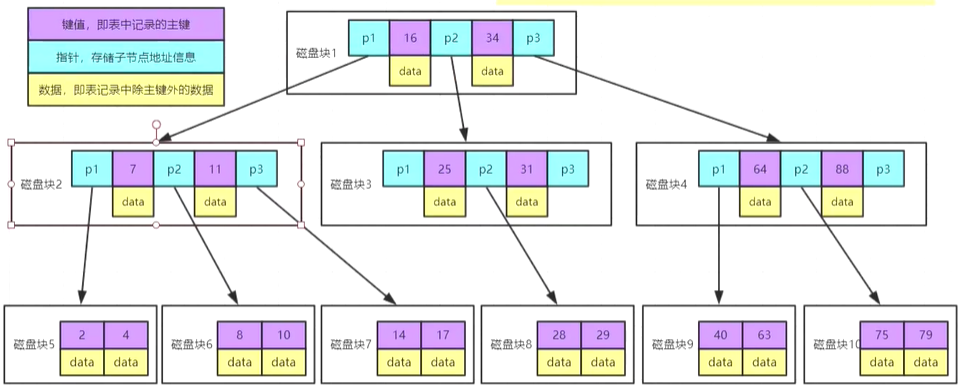
都知道每个磁盘大小是4k,如果正常查数据的话,这种数据接口3次就可以查到了,也就是用了12k,但是B树不好的是非节点上也存data数据,如果查找的时候可能一次就查到了数据直接就返回,本质上是没错。但是如果data的数据存的是个大的数据,就占用了很多的数据空间,这样还是会影响树的深度,所以考虑把data另外单独存,就出现了B+树。
B+树(innodb):
 B+树就是只有叶子节点才可以存放data,同样是查询三次绝对就可以查到数据,并且这样不会占用数据存储空间,存的多的多,效率也可以。
B+树就是只有叶子节点才可以存放data,同样是查询三次绝对就可以查到数据,并且这样不会占用数据存储空间,存的多的多,效率也可以。
MyISAM 的b+树:
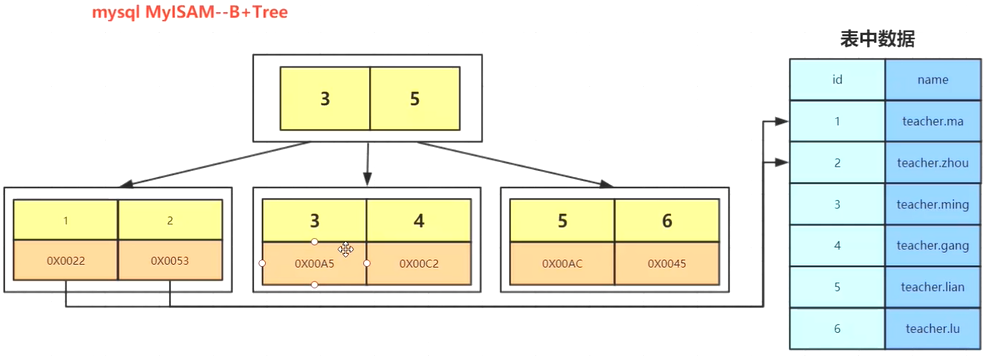
MyISAM的b+树和innodb的不同时,MyISAM存的数据和索引是分开的,所以它是先从b+树查找,查到对应的一个地址的值,再去查找对应的数据
索引的分类
- 主键索引
主键是一种唯一性索引,但是必须指定主键。
就是根据主键创建的索引,就算自己不设置主键索引,它会自己创建主键索引,(rowId),这个rowId是我们不可见的,但是存在。
工作中我们有时会有多对多的关系,就会有多个列作为索引,这个叫联合主键。
- 唯一索引
- 索引列的值只能出现一次,必须唯一,值可以为空。
在建表时候如果指定列是唯一的,此时创建索引自动就是唯一索引了。
- 普通索引(索引覆盖)
- 基本索引类型,值可以为空,没有唯一限制。
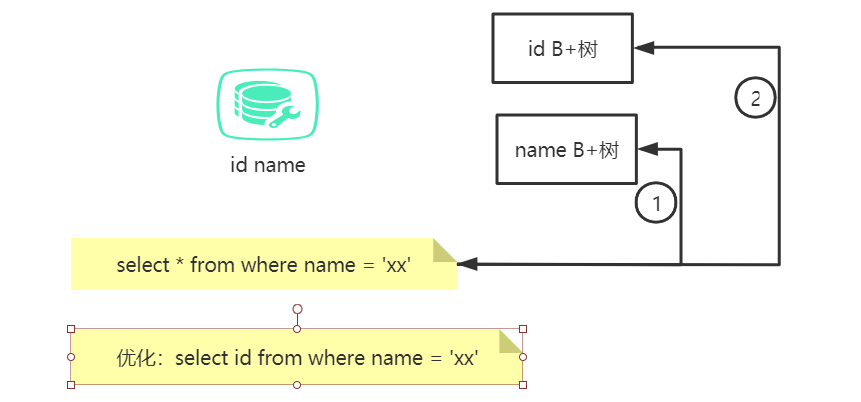
现在有个表,字段有id和name,如果用select * from where name = '' 想去查id,会有回表步骤,先去查id,又去id的B+树去查,走了两次索引。
如果用select id from where name = '' 去查id,直接就把id给返回回来了,不会再走第二次索引。
因为innoDB 方式数据和索引是在一起的,所以可以直接把数据返回,一般回表说的是InnoDB,MyISAM 存的是地址,所以一般不存在回表。不懂B+树结构的先去补一补。。。
索引下推
就是在回表时候,进行一个判断,如果条件满足,就不会执行回表后的索引操作,直接就返回了,达到效率提高的目的。
- 全文索引(MyISAM支持,Innodb在5.6之后支持)
- 全文索引可以在各个字段数据类型上创建。 比如搜索百度时候。。。用的是搜索引擎的倒排索引,通过访问量判断排行名次
- 组合索引(最左匹配原则)
- 多个列组合成的一个索引,用于组合搜索。比如查询时候根据多个列字段。。
在建表时候,考虑字段顺序,比如name 和age,哪个在前,根据实际查询情况判断,
如果name排在age面前的字段,想要查age,就必须经过name,所以如果单独要查age的话,就要单独再创建一个age索引。这样会有多种情况,比如name和age两个字段的话:

情况1和情况2的索引上,age+name 和 name+age 索引空间大小是一样的,但是name 比 age 索引空间肯定大,所以情况2这种索引更好。
MySql存储引擎

锁的机制:粒度越细,效率越高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号