java中的Set
概述
Set集合类似于一个罐子,程序可以依次把多个对象“丢进”Set集合,而Set集合通常不能记住元素的添加顺序。实际上Set就是Collection只是行为略有不同(Set不允许包含重复元素)。
Set集合不允许包含相同的元素,如果试图把两个相同元素加入同一个Set集合中,则添加操作失败,add()方法返回false,且新元素不会被加入。
HashSet类
常用方法:
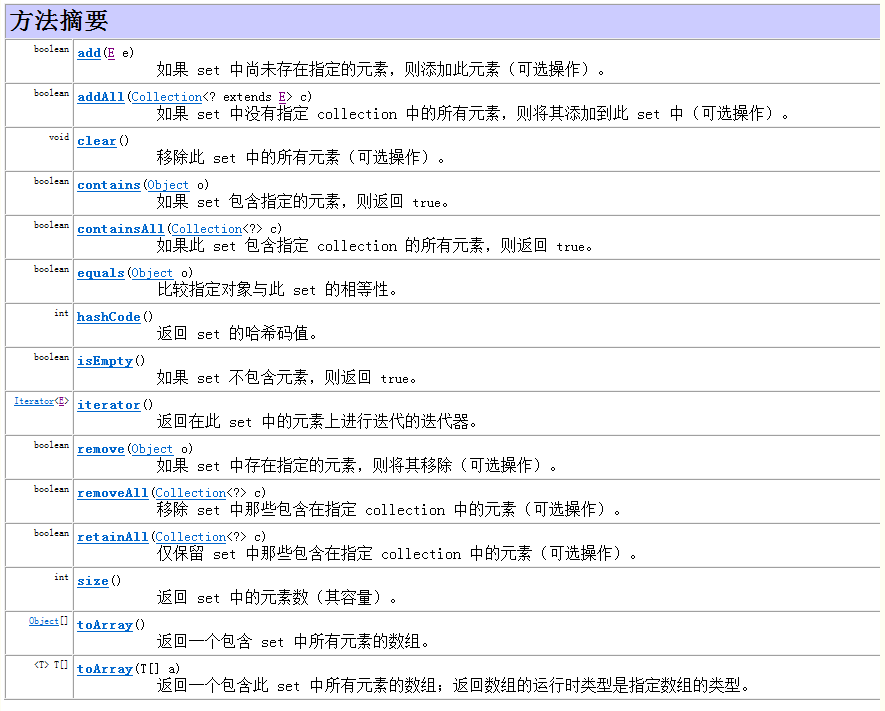
HashSet是Set接口的典型实现,大多数时候使用Set集合时就是使用这个实现类。HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。底层数据结构是哈希表。
哈希表
一个元素为链表的数组,综合了数组与链表的优点。
HashSet具有以下特点:
- 不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也可能发生变化;
- HashSet不是同步的;
- 集合元素值可以是null;
内部存储机制
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode方法来得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置。如果有两个元素通过equals方法比较true,但它们的hashCode方法返回的值不相等,HashSet将会把它们存储在不同位置,依然可以添加成功。
也就是说。HashSet集合判断两个元素的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode方法返回值也相等。
靠元素重写hashCode方法和equals方法来判断两个元素是否相等,如果相等则覆盖原来的元素,依此来确保元素的唯一性
实例:
没有重写hashCode和equals方法
1 Student s1 = new Student("小龙女", 23); 2 Student s2 = new Student("任盈盈", 24); 3 Student s3 = new Student("小龙女", 23); 4 Student s4 = new Student("东方不败", 25); 5 Student s5 = new Student("伊琳", 29); 6 Student s6 = new Student("周芷若", 30); 7 HashSet<Student> hashSet = new HashSet<>(); 8 hashSet.add(s1); 9 hashSet.add(s2); 10 hashSet.add(s3); 11 hashSet.add(s4); 12 hashSet.add(s5); 13 hashSet.add(s6); 14 for (Student student : hashSet) { 15 System.out.println(student.getName()+"=="+student.getAge()); 16 }
1 public class Student { 2 private String name; 3 private int age; 4 5 public Student() { 6 } 7 8 public Student(String name, int age) { 9 this.name = name; 10 this.age = age; 11 } 12 public String getName() { 13 return name; 14 } 15 public void setName(String name) { 16 this.name = name; 17 } 18 public int getAge() { 19 return age; 20 } 21 public void setAge(int age) { 22 this.age = age; 23 } 24 @Override 25 public String toString() { 26 return "Student{" + 27 "name='" + name + '\'' + 28 ", age=" + age + 29 '}'; 30 } 31 }
没有重写这两个方法,运行结果:
可以看到由重复元素出现在集合中。
在元素类中重写hashCode和equals方法:
Student.class
1 //判断判断两个对象是否相等,对象是否存在,对象的name和age是否相等 2 @Override 3 public boolean equals(Object o) { 4 if (this == o) return true; 5 if (o == null || getClass() != o.getClass()) return false; 6 Student student = (Student) o; 7 return age == student.age && 8 Objects.equals(name, student.name); 9 } 10 11 //返回对象的name和age的hash值 12 @Override 13 public int hashCode() { 14 return Objects.hash(name, age); 15 }
重写之后不是判断两个对象hashCode是否相等,而是判断对象的name和age是否同时相等,如果同时相等则判断为同一对象,不能重复出现在集合中。
再次遍历结合,运行结果:

可以看到重复的元素已经被覆盖,保证了集合中元素的唯一性。
如果需要把某个类的对象保存到HashSet集合中,重写这个类的equals方法和hashCode方法时,应尽量保证两个对象通过equals方法比较返回true时,他们的hashCode方法返回值也相等。
为什么不直接使用数组,而用HashSet呢?
因为数组的索引是连续的而且数组的长度是固定的,无法自由增加数组的长度。而HashSet就不一样了,HashCode表用每个元素的hashCode值来计算其存储位置,从而可以自由增加HashCode的长度,并根据元素的hashCode值来访问元素。而不用一个个遍历索引去访问,这就是它比数组快的原因。

HashCode中每个存储元素的“槽位”通常称为“桶”,如果多个元素的hashCode值相同,但它们通过equals方法比较返回false,就需要在桶里放多个元素,这样会导致性能下降。
hash表
- 容量:hash表中桶的数量;
- 初始化容量:创建hash表时桶的数量;
- 尺寸:当前hash表中记录的数量;
- 负载因子:负载因子等于0表示空的hash表,0.5表示半满的hash表,轻负载的hash表具有冲突少、适宜插入与查询等特点。
- 负载极限:负载极限是一个0~1之间的数值,决定了hash表的最大填满程度。当hash表的负载因子达到指定负载极限时,hash表会自动成倍地增加容量,并将原有的对象重新分配,放入新的桶中。HashSet、HashMap、Hashtable默认的负载极限是0.75。
当向HashSet中添加可变对象时,必须十分小心。如果修改HashSet集合中的对象,有可能导致该对象与集合中的其他对象相等,从而导致HashSet无法准确访问该对象。
LinkedHashSet类
HashSet还有一个子类LinkedList、LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的,也就是说当遍历集合LinkedHashSet集合里的元素时,集合将会按元素的添加顺序来访问集合里的元素。
输出集合里的元素时,元素顺序总是与添加顺序一致。但是LinkedHashSet依然是HashSet,因此它不允许集合重复。
TreeSet类
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。
内部存储机制
TreeSet内部实现的是红黑树,默认整形排序为从小到大。
与HashSet集合相比,TreeSet还提供了几个额外方法:
Comparator comparator():如果TreeSet采用了定制顺序,则该方法返回定制排序所使用的Comparator,如果TreeSet采用自然排序,则返回null;Object first():返回集合中的第一个元素;Object last():返回集合中的最后一个元素;Object lower(Object e):返回指定元素之前的元素。Object higher(Object e):返回指定元素之后的元素。SortedSet subSet(Object fromElement,Object toElement):返回此Set的子集合,含头不含尾;SortedSet headSet(Object toElement):返回此Set的子集,由小于toElement的元素组成;SortedSet tailSet(Object fromElement):返回此Set的子集,由大于fromElement的元素组成;
用法:
1 TreeSet<Integer> nums = new TreeSet<>(); 2 //向集合中添加元素 3 nums.add(5); 4 nums.add(2); 5 nums.add(15); 6 nums.add(-4); 7 //输出集合,可以看到元素已经处于排序状态 8 System.out.println(nums);//[-4, 2, 5, 15] 9 10 System.out.println("集合中的第一个元素:"+nums.first());//集合中的第一个元素:-4 11 System.out.println("集合中的最后一个元素:"+nums.last());//集合中的最后一个元素:15 12 System.out.println("集合小于4的子集,不包含4:"+nums.headSet(4));//集合小于4的子集,不包含4:[-4, 2] 13 System.out.println("集合大于5的子集:"+nums.tailSet(2));//集合大于5的子集:[2, 5, 15] 14 System.out.println("集合中大于等于-3,小于4的子集:"+nums.subSet(-3,4));//集合中大于等于-3,小于4的子集:[2]
从上面的运行结果可以看出输出的集合已经按从小到大排好了,但是问题来了,只能从小到大排序吗?如果是字符对象应按该怎样的顺序排序?如果是一个学生对象又按怎样的顺序排序呢?遵循怎样的排序规则呢?
针对这个问题,TreeSet支持两种排序方法:自然排序和定制排序,在默认情况下,采用的是自然排序。
自然排序
TreeSet会调用集合元素的compareTo(Objec obj)方法来比较元素之间的大小关系,然后将集合元素按升序排列,这就是自然排序。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类必须实现该方法,实现接口的类就可以比较大小了。当调用一个一个对象调用该方法与另一个对象进行比较时,obj1.compareTo(obj2)如果返回0表示两个对象相等;如果返回正整数则表明obj1大于obj2,如果是负整数则相反。
案例:
实现存储学生类的集合,排序方式,按年龄大小,如果年龄相等,则按name字符串长度,如果长度相等则比较字符。如果name和age都相等则视为同一对象。
元素对象Student.class
1 package org.westos.demo2; 2 3 import java.util.Comparator; 4 5 public class Student implements Comparable<Student> { 6 private String name; 7 private int age; 8 9 public Student(String name, int age) { 10 this.name = name; 11 this.age = age; 12 } 13 14 public String getName() { 15 return name; 16 } 17 18 public void setName(String name) { 19 this.name = name; 20 } 21 22 public int getAge() { 23 return age; 24 } 25 26 public void setAge(int age) { 27 this.age = age; 28 } 29 30 @Override 31 public String toString() { 32 return "Student{" + 33 "name='" + name + '\'' + 34 ", age=" + age + 35 '}'; 36 } 37 38 @Override 39 public int compareTo(Student o) { 40 //比较age 41 int num=this.age-o.age; 42 //如果age相等则比较name长度 43 int num1=num==0?this.name.length()-o.name.length():num; 44 //如果前两者都相等则比较name字符串 45 int num2=num1==0?this.name.compareTo(o.name):num1; 46 return num2; 47 } 48 }
集合类
1 package org.westos.demo2; 2 3 import java.util.TreeSet; 4 5 public class TreeSetDemo4 { 6 public static void main(String[] args) { 7 TreeSet<Student> tree = new TreeSet<>(); 8 9 //向集合中添加元素 10 tree.add(new Student("孙悟空",16)); 11 tree.add(new Student("孙悟空",17)); 12 tree.add(new Student("孙悟空",16)); 13 tree.add(new Student("唐僧",16)); 14 tree.add(new Student("沙悟净",23)); 15 tree.add(new Student("唐僧",30)); 16 17 //遍历 18 System.out.println(tree); 19 /*[Student{name='唐僧', age=16}, 20 Student{name='孙悟空', age=16}, 21 Student{name='孙悟空', age=17}, 22 Student{name='沙悟净', age=23}, 23 Student{name='唐僧', age=30}] 24 */ 25 26 } 27 }
从运行结果可以看到满足定义的排序规则。
当把一个对象添加进集合时,集合调用该对象的CompareTo(Object obj)方法与容器中的其他对象比较大小,然后根据红黑树结构中找到它的存储位置。如果两个对象相等则新对象无法加入到集合中。
注意问题
- 大部分类在实现CompareTo(Object o)方法时,都需要将被比较对象obj强制类型转换成相同类型,因为只有相同的两个实例才会比较大小。
- 加入集合的类都必须实现Comparable接口,否则会引发ClassCastException异常。
- 向TreeSet集合中添加元素时,只有第一个元素无须实现Comparable接口,后面添加的所有元素都必须实现Comparable接口。当然这也不是一种好做法,当试图从TreeSet中取出元素时,依然会引发ClassCastException异常。
- 不要修改已经存入集合的实例变量,这将导致它与其他对象的大小顺序发生改变,但TreeSet集合不会再次调整它们的顺序,这点和HashSet一样。
总结:如果希望TreeSet能正常工作,TreeSet只能添加同一种类型的对象
对于TreeSet集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过compareTo(Object obj)方法比较是否返回0,如果是0则认为对象相等,否则认为不相等。
修改上述案例:
重写equals方法,更改compareTo(Object obj)的返回值总是返回1;
1 @Override 2 public int compareTo(Student o) { 3 return 1; 4 } 5 6 @Override 7 public boolean equals(Object o) { 8 return true; 9 }
1 TreeSet<Student> tree = new TreeSet<>(); 2 3 Student s1 = new Student("李明",23); 4 5 tree.add(s1); 6 //遍历 7 System.out.println(tree);//[Student{name='李明', age=23}] 8 tree.add(s1); 9 System.out.println(tree);//[Student{name='李明', age=23}, Student{name='李明', age=23}] 10 11 //更改第一个元素的age 12 tree.first().setAge(33); 13 System.out.println(tree.last().getAge());//33
虽然equals总是返回true,但是TreeSet总认为添加的两个对象不相等,可以看到修改第一个元素的age,最后一个元素的age也被修改。这是因为集合中存储的只是对象的引用,这两个对象的引用指向同一个对象,所以age变量也被随之改变。
定制排序
TreeSet的自然排序是根据集合元素的大小,TreeSet将它们以升序排列。如果需要实现定制排序,例如降序排序,则可通过Comparator接口的帮助。该接口里包含一个int compare(T o1,T o2)方法,用于比较o1和o2的大小。由于Comparator是一个函数式接口,因此还可以使用Lambda表达式来代替Comparator子类对象。
1 TreeSet<Integer> nums = new TreeSet<>(new Comparator<Integer>() { 2 @Override 3 public int compare(Integer o1, Integer o2) { 4 return o1-o2; 5 } 6 }); 7 //向集合中添加元素 8 nums.add(5); 9 nums.add(2); 10 nums.add(15); 11 nums.add(-4); 12 //输出集合,可以看到元素已经处于排序状态 13 System.out.println(nums);//[-4, 2, 5, 15]
如果需要更改排序方式,则更改Comparator对象的返回值;
1 TreeSet<Integer> nums = new TreeSet<>(new Comparator<Integer>() { 2 @Override 3 public int compare(Integer o1, Integer o2) { 4 return -(o1-o2); 5 } 6 }); 7 //向集合中添加元素 8 nums.add(5); 9 nums.add(2); 10 nums.add(15); 11 nums.add(-4); 12 //输出集合,可以看到元素已经处于排序状态 13 System.out.println(nums);//[15, 5, 2, -4]
使用Lambda表达式来实现:
1 TreeSet<Integer> nums = new TreeSet<>((a,b)->-(a-b)); 2 //向集合中添加元素 3 nums.add(5); 4 nums.add(2); 5 nums.add(15); 6 nums.add(-4); 7 //输出集合,可以看到元素已经处于排序状态 8 System.out.println(nums);//[15, 5, 2, -4]
定制排序的特征和自然排序相同,不能添加相同的对象。
EnumSet类
- EnumSet是一个专门为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式或隐式地指定。EnumSet的集合元素也是有序的,EnumSet以枚举值在Enum类内的定义顺序来决定集合元素的顺序。
- EnumSet在内部以位向量的形式存储,这种存储形式非常紧凑、高效,因此EnumSet对象占用内存很小,而且运行效率很好。
- EnumSet集合不允许加入null元素。
EnumSet类没有暴露任何构造器来创建该类的实例,EnumSet类提供了以下类方法来创建EnumSet对象。
EnumSet allOf(Class elementType):创建一个包含指定枚举类里所有枚举值的EnumSet集合。EnumSet complementOf(EnumSet s):创建一个其元素类型与指定EnumSet里元素类型相同的EnumSet集合,新的集合里包含原集合不包含的枚举值。EnumSet copyOf(Collection c):使用一个普通集合来创建EnumSet集合;EnumSet copyOf(EnumSet s):复制原集合;EnumSet noneOf(Class elementType):创建一个元素类型为指定枚举类型的空EnumSet;EnumSet of(E first,E...rest):创建一个包含一个或多个枚举值的EnumSet集合。传入的枚举值必须是同一枚举类。EnumSet range(E from,E to):创建一个包含从from到to枚举值范围所有枚举值的EnumSet集合。
实例:
1 package org.westos.demo9; 2 3 public enum SeasonEnum { 4 5 //在第一行列出4个枚举实例 6 Spring,Summer,Fall,Winter; 7 }
1 package org.westos.demo9; 2 3 import java.util.EnumSet; 4 5 public class EnumSetTest { 6 public static void main(String[] args) { 7 //创建一个EnumSet集合,集合元素是Season枚举类的全部枚举值 8 EnumSet<SeasonEnum> es1 = EnumSet.allOf(SeasonEnum.class); 9 System.out.println(es1);//[Spring, Summer, Fall, Winter] 10 11 //创建一个EnumSet空集合,元素类型为Season类的枚举值 12 EnumSet<SeasonEnum> es2 = EnumSet.noneOf(SeasonEnum.class); 13 System.out.println(es2);//[] 14 15 //手动添加两个元素 16 es2.add(SeasonEnum.Spring); 17 es2.add(SeasonEnum.Summer); 18 System.out.println(es2);//[Spring, Summer] 19 20 //以指定枚举值创建EnumSet结合 21 EnumSet<SeasonEnum> es3 = EnumSet.of(SeasonEnum.Spring, SeasonEnum.Fall); 22 System.out.println(es3);//[Spring, Fall] 23 24 EnumSet<SeasonEnum> es4 = EnumSet.range(SeasonEnum.Summer, SeasonEnum.Winter); 25 System.out.println(es4);//[Summer, Fall, Winter] 26 27 //输出es4中不包含的枚举值 28 EnumSet<SeasonEnum> es5 = EnumSet.complementOf(es4); 29 System.out.println(es5);//[Spring] 30 } 31 }
复制集合
1 Collection c = new HashSet<>(); 2 c.clear(); 3 c.add(SeasonEnum.Spring); 4 c.add(SeasonEnum.Summer); 5 6 //复制集合中的元素来创建EnumSet 7 EnumSet enumSet = EnumSet.copyOf(c); 8 System.out.println(enumSet);//[Spring, Summer] 9 10 c.add("Monday"); 11 c.add("ThusDay"); 12 EnumSet enumSet1 = EnumSet.copyOf(c); 13 //出现ClassCastException异常,因为后面添加的两个元素不是枚举值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号