Redis-Linux-高级
手动分槽参考:https://blog.csdn.net/weixin_40960410/article/details/106166582/
上一篇:https://www.cnblogs.com/abiu/p/13440919.html 的redis 基础知识已经看完了以后,就可以接着看这篇文章了
打开Linux 命令窗口,使用root权限,然后下载redis 的压缩包,这里下载4.0.0 版本的,
redis 是C 语言写的,要先确定 虚拟机安装有 gcc 没有的话下载安装: yum install gcc
步骤:
1、先 cd / 切换到 根目录
2、输入命令: wget http://download.redis.io/releases/redis-4.0.0.tar.gz
3、然后解压: tar zxvf redis-4.0.0.tar.gz
4、进入解压好的文件夹里: cd redis-4.0.0
// 可以先看看系统默认安装目录,和redis 要安装到的目录 cat Makefile
// 编译:make
5、可以直接编译 并安装: make install
6、 安装完以后, cd src 进到里面的src 目录,然后ll 可以看到安装好的redis
7、 redis-server 直接回车,就启动了redis
8、 启动以后,就不用管了,再复制一个会话,打开客户端去连服务端 试试:
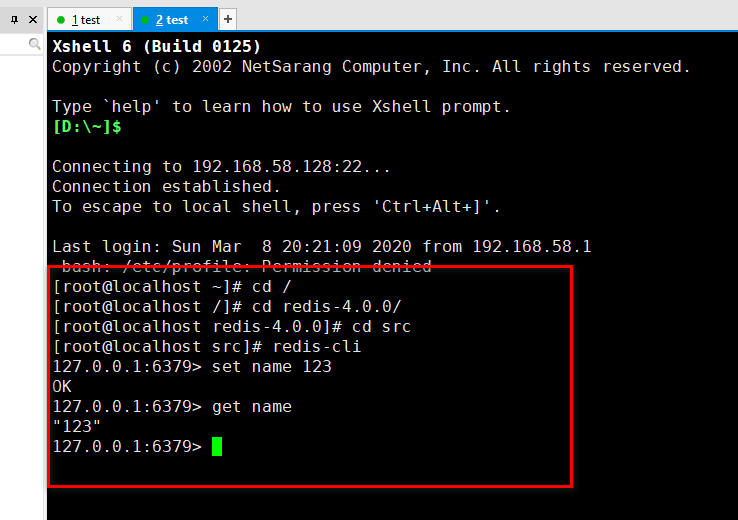
正常使用,连接成功
如果要启动多台redis 解决办法:src的redis 安装目录 下执行命令: redis-server --port 6380 回车
这样redis 的端口就变成6380 了,再去用客户端连接就会失败,要连接的是: redis-cli -p 6380 就能连接成功了
上面两种方式不推荐,一般在企业里启动的是:
先 cd redis-4.0.0 目录下,找到一个redis.conf 的redis 配置文件,
然后输入命令: cat redis.conf | grep -v "#" |grep -v "^$" > redis-6379.conf
就是复制一份redis.conf ,取名redis-6379.conf ,当然,都在在同一目录下,然后编辑这个redis-6379.conf 文件,只留下:
port 6379 daemonize yes logfile "6379.log" dir /redis-4.0.0/data
中间出错的话,就先提前在redis-4.0.0 目录下新建一个data ,然后再 保存这个redis-6379.conf 文件
然后就可以输出命令: redis-server redis-6379.conf 启动redis 服务
redis-cli 启动客户端小试一下
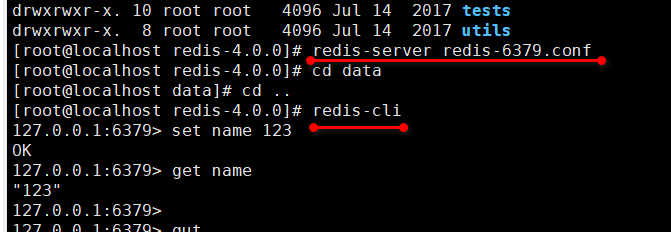
redis 的安装目录下应该再见一个文件夹 conf ,不然以后要起多个redis 服务,岂不是好多的配置文件,太乱了:
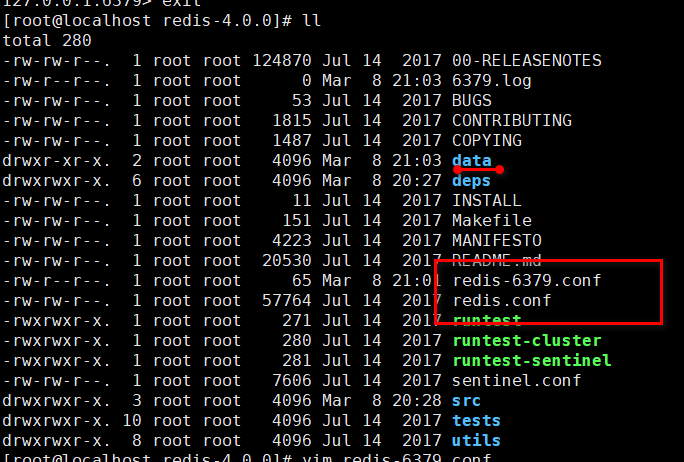
使用命令: mkdir conf 新建一个conf 目录
然后把这个 6379 的配置文件剪切到 conf 目录里: mv redis-6379.conf conf
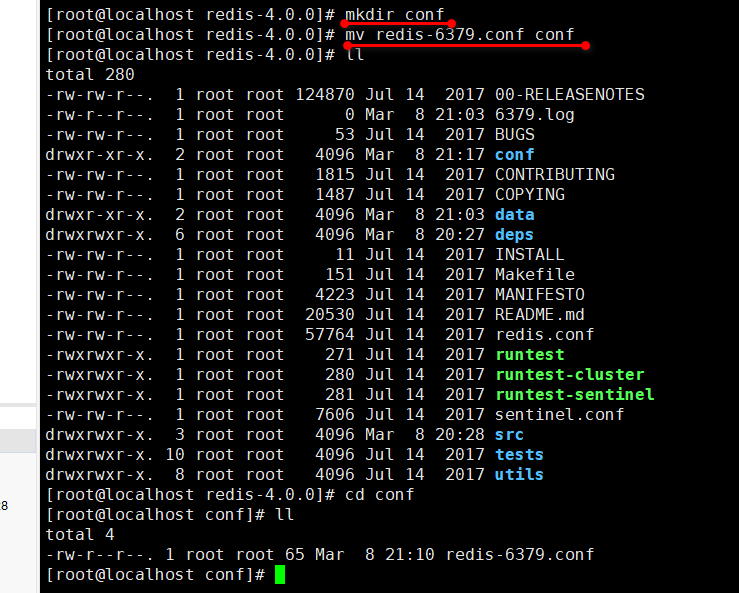
这样的话,启动redis 服务命令是: redis-server conf/redis-6379.conf
启动多个redis 服务:
先 cd conf 到conf 目录下,然后: cp redis-6379.conf redis-6380.conf 复制一个6379 的文件 6380
然后 vim redis-6380.conf 编写6380 的配置:
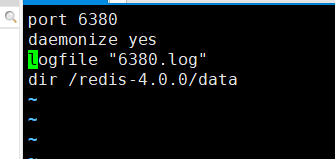
只需要改这些,然后保存退出就可以了,这样的话 redis-server conf/redis-6380.conf 就启动了
客户端启动的话, redis-cli -p [端口号] 指定端口号
redis-cli -h [IP地址] 指定IP地址
持久化
RDB:快照方式,执行一次命令,就保存一次
执行保存命令: save 每次set 数据时候每保存一次,就会再那个data 文件里的rdb 文件生出一条信息,要手动执行的。。
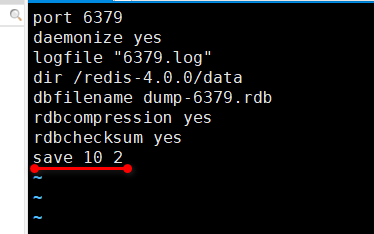
比如要设置 6379 这个端口的rdb 文件保存,先去把 redis-6379.conf 这个文件编写一下:
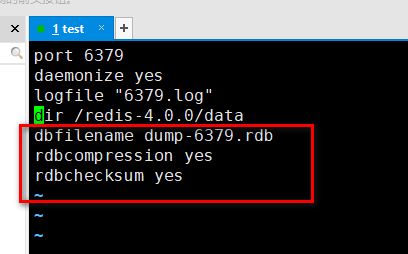
然后就可以正常使用了,比如这个 dump-6379.rdb 文件会在data 目录下生成,
这样就把数据持久化了,比如把6379 的这个服务的内存清除,然后重新启动6379 这个端口,
然后去客户端一样能查询之前保存过的数据,因为当6379 重新启动时候,数据就已经被加载了
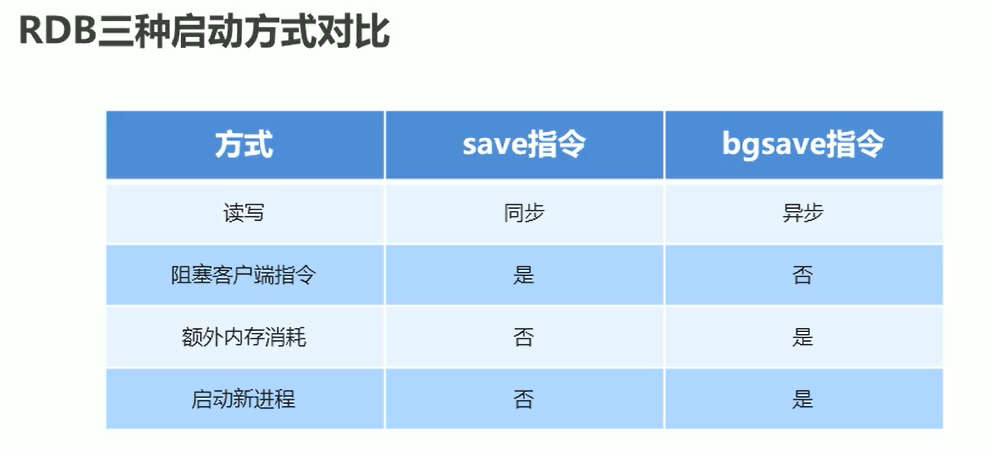
save 指令的工作原理
当多个客户端 访问服务 时候,是有先后顺序的,因为redis 是单线程的,这样就类似于消息队列那种的吧。。。
如果有一个save 指定执行过长,其他客户端就会等着这个 save 指令,
所以线上环境不建议使用save 指令,因为会很拉低服务器的性能,可能造成严重的阻塞!
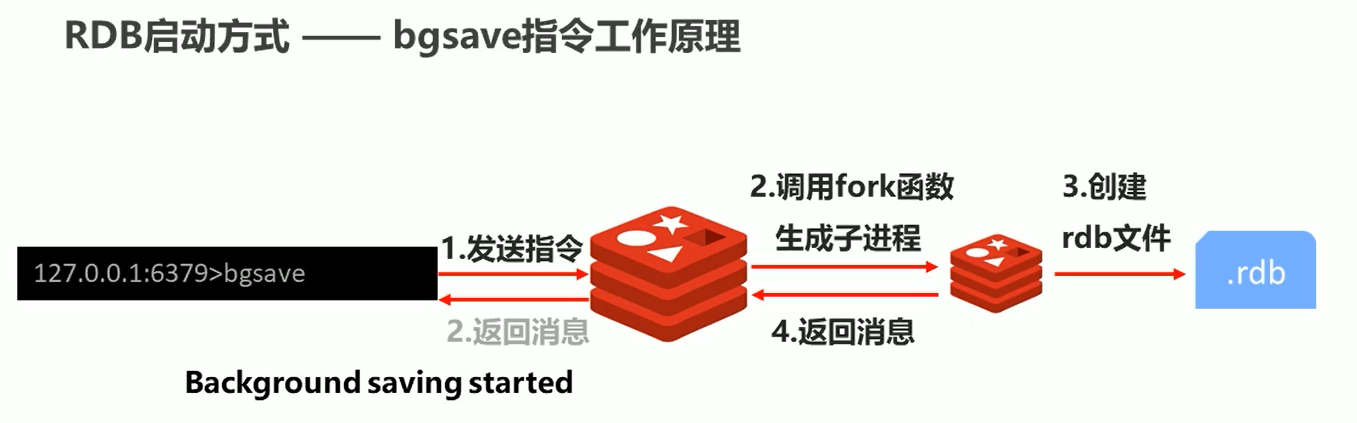
解决方法:bgsave 指令:手动启动后台保存操作,但不是立即执行的
bgsave 使用:一样是在客户端操作,比如set 完数据然后就 bgsave ,然后会给提示信息:Background saving started 后台执行, save 是马上执行,
bgsave 执行原理
自动执行持久化命令:
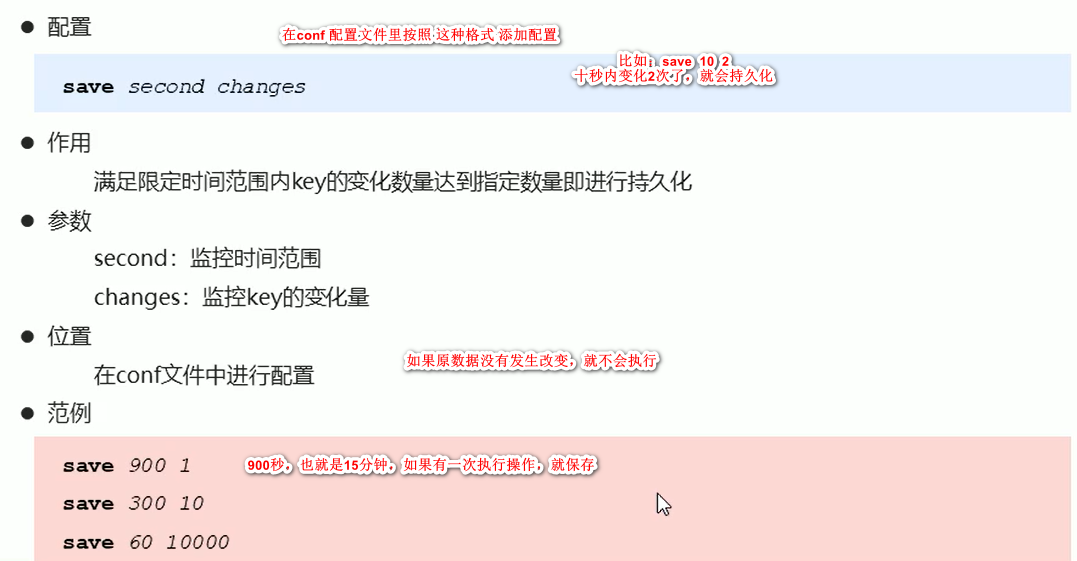
找到相对应要配置的服务端 配置文件:
rdb 的启动方式:
1、服务器 运行过程中重启会启动 命令: debug reload
2、关闭服务器时候指定保存数据 命令: shutdown save
3、主从复制时候,后面才会讲到
RDB 的缺点:
存储数据量大,效率就低,
基于快照思想,IO 性能较低,
基于fork 创建子进程,内存额外消耗,
宕机可能带来的数据丢失风险
AOF:不写入全数据,记录部分数据,记录操作过程,对所有操作记录,排除数据丢失风险
aof 是Redis 持久化的主流方式
AOF 功能开启:默认是不开启的。。。
配置: appendonly yes | no 先打开配置 AOF
AOF 写数据策略 配置: appendfsync always | everysec | no 然后根据选择使用方式持久化
always 是有一个命令就保存一次,拉低了cpu 的性能,不推荐使用,no 是系统默认,是没办法控制的
everysec 这种的是一秒保存一次,不管有多少命令一秒保存一次,推荐使用,就算丢失也只有一秒的数据
操作配置:
vim 打开conf 配置文件夹里的 6379 配置,然后加上AOF 的配置:
appendonly yes
appendfsync everysec

加上配置以后 :wq 保存,然后运行 6379 的端口: redis-server redis-6379.conf
就可以发现 data 文件夹里多了一个appendonly.aof 文件
为了避免以后的aof 持久化文件过多,建议使用appendonly-xxx端口号.aof 的这种格式
AOF 重写:提高效率
手动重写: bgrewriteaof 执行这个命令以后,会返回结果通知,后台已经开始重写了
自动重写: auto-aof-rewrite-min-size [size]
auto-aof-rewrite-percentage [percentage]
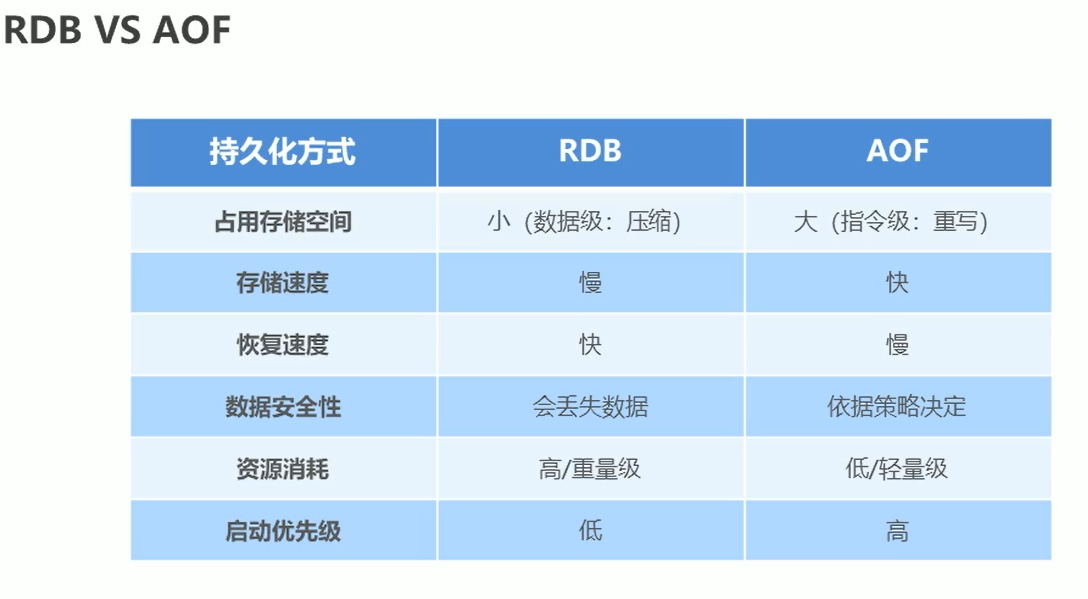
RDB 和 AOF 的区别:
事务 redis 事务就是一个命令执行的队列,将一系列预定义的命令包装成一个整体,一次性按添加顺序执行,直接不被打断或干扰
一个队列中、一次性、顺序性、不被打断干扰
事务基本操作:
开启事务: multi 设定事务开启位置,后面的所有指令都加在了事务里
执行事务: exec 设定事务结束位置,同时执行事务,和multi 成对使用,成对出现
在multi 和 exec 中间这一段的所有命令,都在事务里,操作非常简单。。
取消事务: discard 终止当前事务,在multi 之后 和 exec 之前使用!
注意:如果在事务中输入指令错误,那么事务里将会解析命令错误,就会报错,比如:set 写成了 est ,就会报错
如果命令的类型不匹配,也不行,比如:lpush xx 虽然不会报错,但是结束,执行事务时候就会报错。但是后面的指令还是会执行!
所以redis 的事务不支持回滚,如果真的出错了,推荐思路:百度把。。。 因为redis 的事务在企业中用的比较少
事务锁
用于业务场景:开始事务以后,如果在执行事务之前,被另一个客户端 或者 其他方法更改或执行了命令 事务里指定的key ,那个这个事务不会执行了,返回nil 空
watch [key1] [key2]... 只能用在开始事务multi 的前面,不能写在事务里面!就是只能在执行事务之前加 锁
unwatch 如果在watch key1 key2... 后面加上uwatch 命令,那么这个锁就取消了
分布式锁 比如三个人同时买一个东西,这个东西只有一个,那么其他两个人就买不到了
由于数值一直在改变,因为东西在一直卖出去嘛,所以watch 事务锁已经不能解决这个问题了
解决方案: 使用 setnx 设置一个公共锁,就是锁住了公共的方法后,别人都不能用了
setnx lock-key [value]: 比如:set num 10 命令以后,setnx lock-num 1,这个值无所谓,
然后可以incrby num -1 就等于10-1了,然后再释放锁:del lock-num
死锁:比如:正在锁住的情况下,宕机了,可是锁还是锁住了,就像上厕所把门锁住了,可你却睡着了。。。。哈哈
解决方案:设置规定时间,长时间不释放锁,就把锁给砸了。。。
expire lock-key [second] 在setnx lock-key value 的下面用expire lock-key second ,比如:expire lock-num 10 十秒后锁就失效了,当然也可以提前释放锁。
pexpire lock-key [milliseconds] 这个是毫秒
一般使用毫秒执行业务比较多,不适合锁住太长时间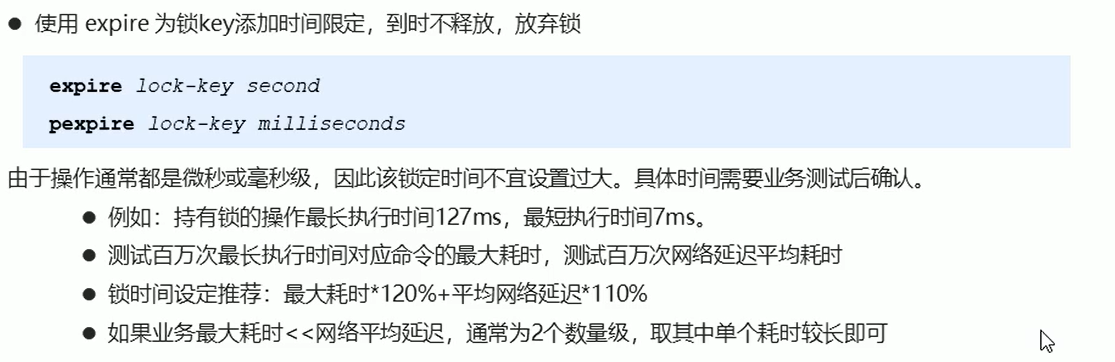
删除策略
过期数据 就是以前redis 里面定义的有效期的数据,但是过多,影响了cpu 的性能,给cpu 增加了压力,但是这些数据又不急着操作
数据删除策略:
1、定时删除
创建一个定时器,当 key 设置的有效时间过了时候,由定时器操作,优点就是节约内存,缺点就是增加了cpu 的压力,因为到点了就删除
总结:定时删除就是拿处理器的性能换取了内存储存空间,拿时间换空间
2、惰性删除
和定时删除对比鲜明,数据的设置时间到期了也不删除,等到下次再调用这个数据时候,提示你数据不存在,这个时候才删除
优缺点也很明显,节约了cpu 的性能,但是内存压力就大了
总结:就是拿存储空间换取处理器性能,拿空间换时间
3、定期删除
以上两种策略都太极端了,这里的定期删除时折中的方案
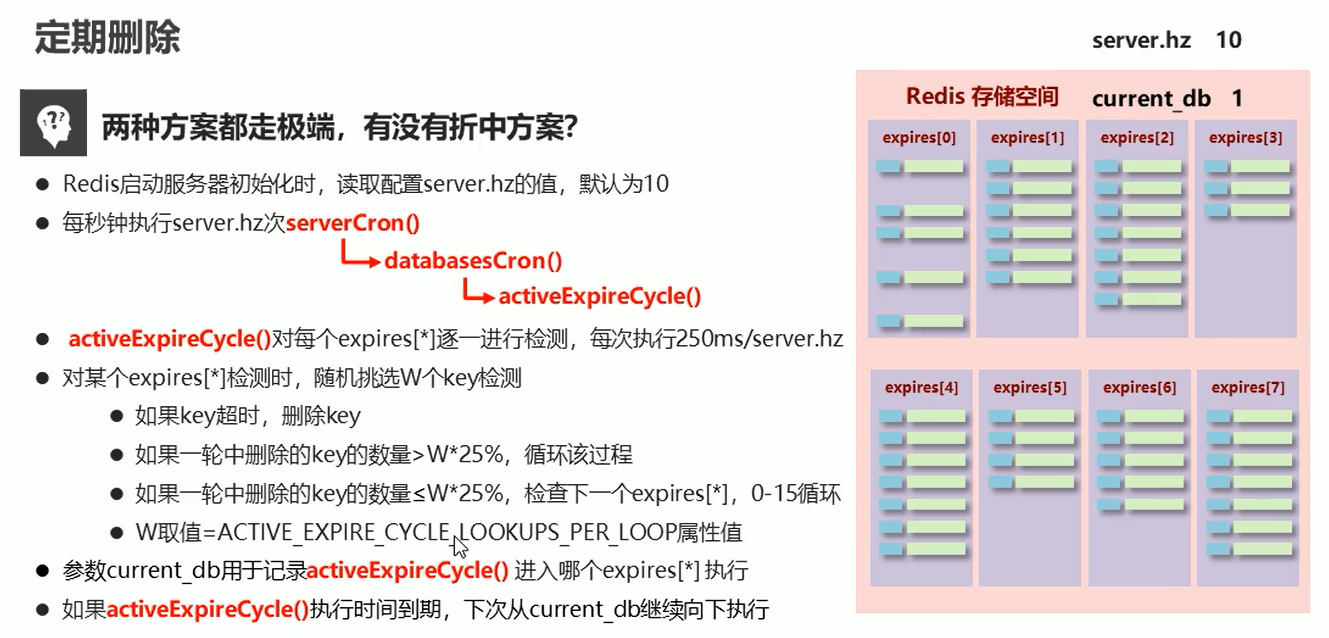
redis 里使用的时惰性删除 和 定期删除 这两种方案
逐出算法

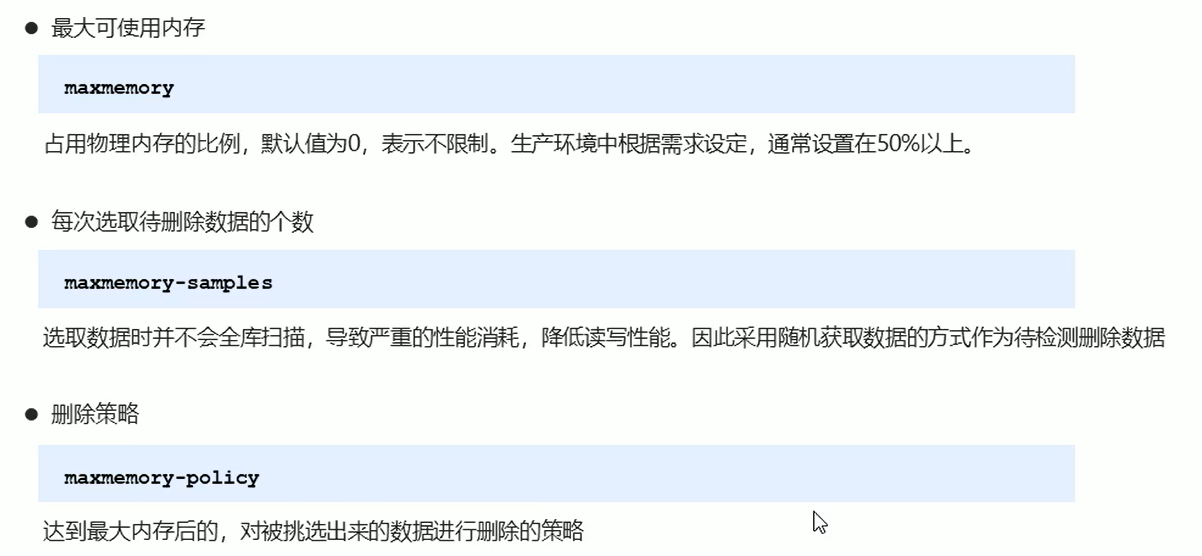
逐出算法的8 种配置:

服务器配置:redis.conf 平常可能用不到,用的很少
设置服务器守护进程方式运行: daemonize yes | no
绑定主机地址: bind 127.0.0.1
设置服务器端口号: port 6379
设置数据库数量: databases 16
这些都是再conf 的各个配置文件里加上就行了
日志配置:
服务器指定日志记录级别: loglevel debug | verbose | notice | warning 默认的是verbose
日志记录文件名: logfile 端口号.log
客户端配置:
设置最大连接客户端数量,默认是无限制的: maxclients 0 达到上限,redis 就关闭新的连接了
客户端空闲等的时间: timeout 300 300 秒后如果客户端没有任何操作,就给关了。取消该功能就设置为 0
高级数据类型: Bitmaps、HyperLogLog、GEO
Bitmaps 是以String 类型二进制中存储的位 进行存储,是做状态统计的
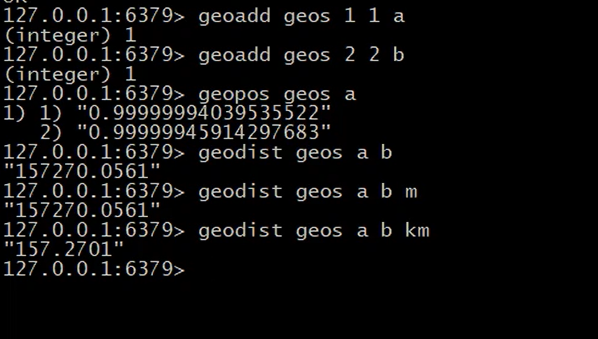
setbit [key] [二进制下标位置] [设置数值] 比如:setbit bits 0 1 或者setbit bits 100 1 二进制长度不要过长,影响性能
获取:getbit bits 0 返回1

HyperLogLog 做计数统计的

GEO 是做地理位置,心机计算的。用于坐标,计算坐标点距离,比如地图软件、附近人什么的功能这些里都用到了
横坐标 纵坐标 名字

单位
GEO 算的是水平位置,比如地图上平面的,如果是比如:山上到山下的位置,在地图上就是垂直的了,这个是不能计算距离的
测试:
集群 主从复制、哨兵模式、集群
主从复制
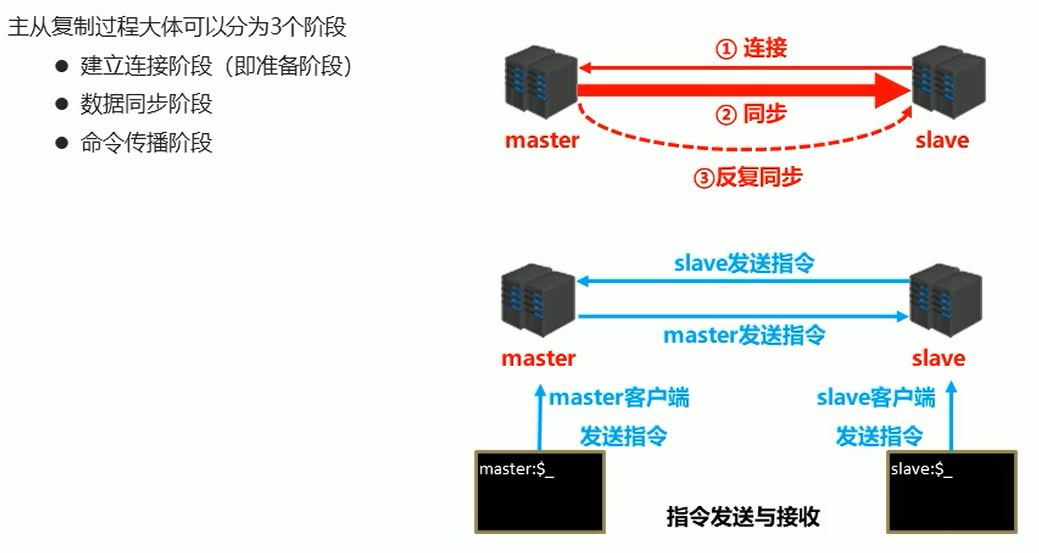
1、建立连接 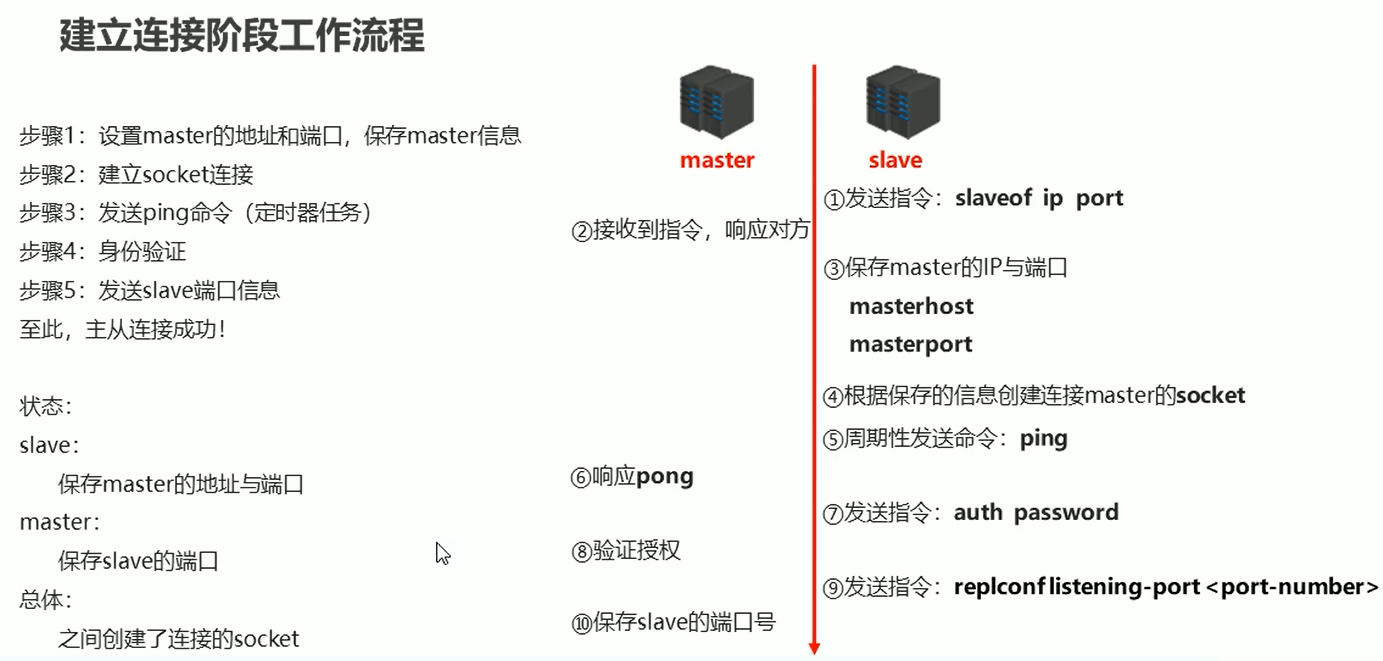

推荐使用方法三
比如在 6380端口的服务器(从表)要连 6379端口号的服务器(主表),
打开6380 的配置文件,加上配置: slaveof 127.0.0.1 6379
主 从 断开连接: slaveof no one 从 从服务器客户端 输入这个命令就断开和主机的连接了
2、数据同步
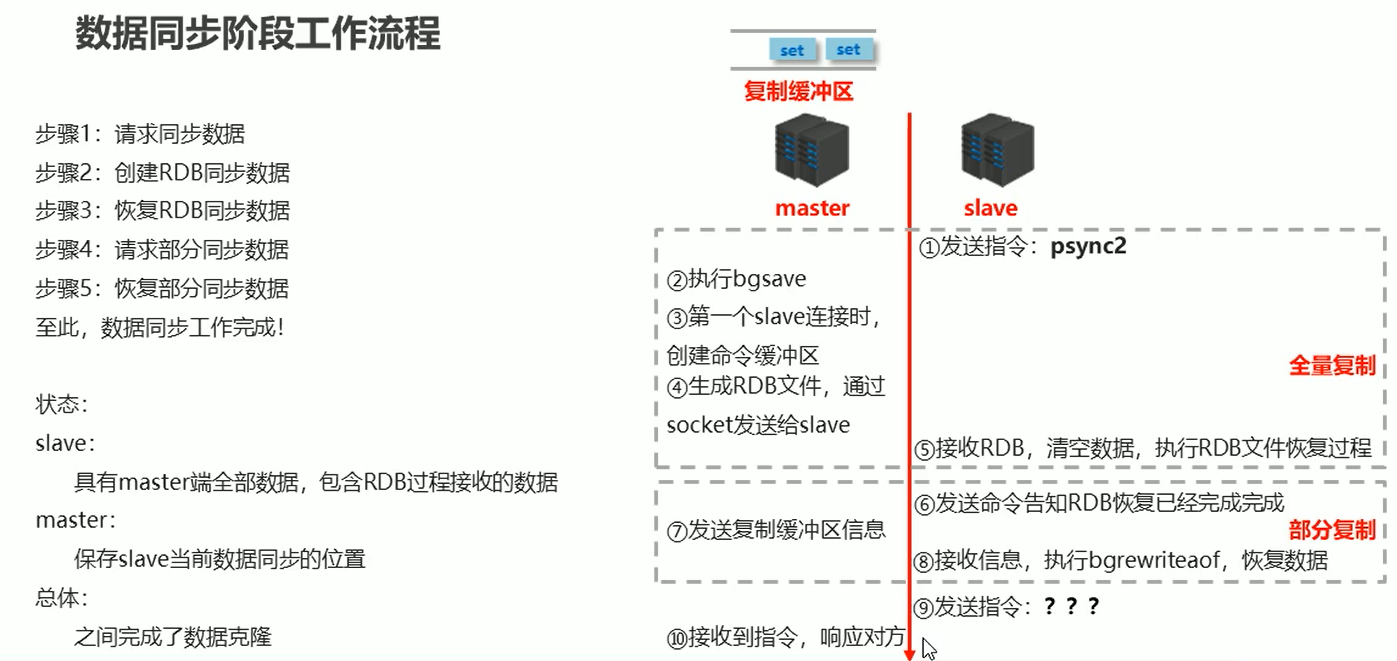
如果由于master 的缓冲区过小,所以导致缓冲区一直存在数据,就会一直主从复制,就造成了死循环
解决办法:在master 服务器设置一下 缓冲区的大小,多少合适呢?:

运行id:
比如说突然断电了,或者闪连了,中间断开了一些时间,那么在重新连接时候,master 会验证 之前连接的slave 的运行id ,
从而来判断是不是刚刚连接的那台slave ,如果是,那就继续链接,如果不是,就会连接失败连接不上的。
运行id 是一个 40位的字符。

偏移量:主要用于部分复制

3、命令传播
细化全量复制 + 部分复制

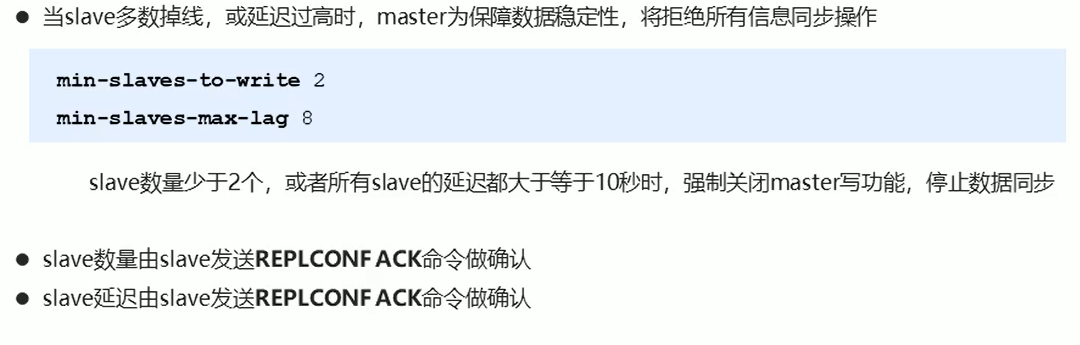
心跳机制:主要就是看主、从 服务器是不是还连接上的,有没有断开短接,就是隔一会就ping,然后那边 pong

哨兵模式
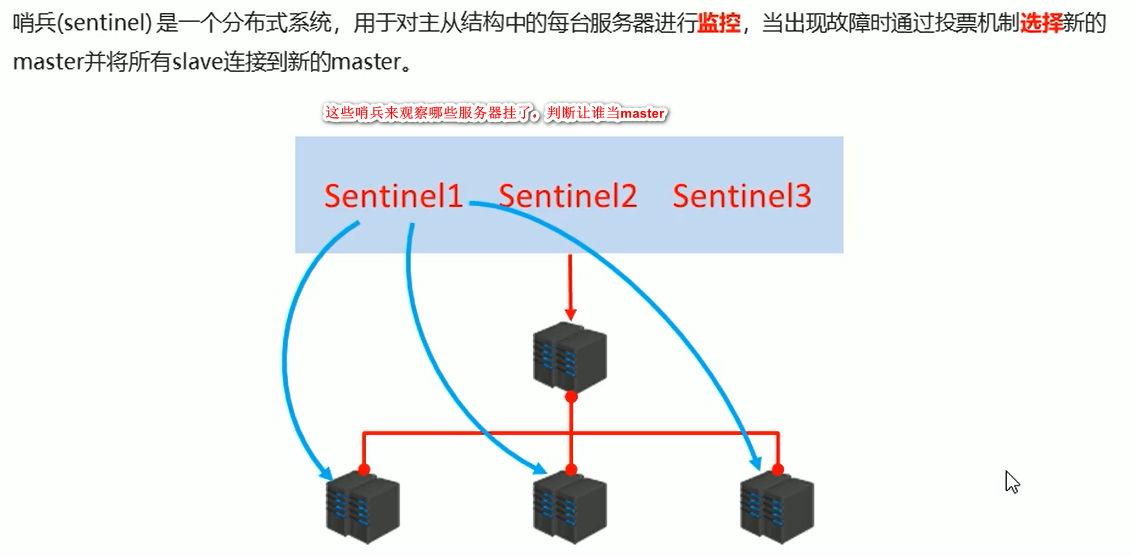

哨兵一般都是配置的奇数,多个哨兵,最少配置三个

哨兵结构搭建:
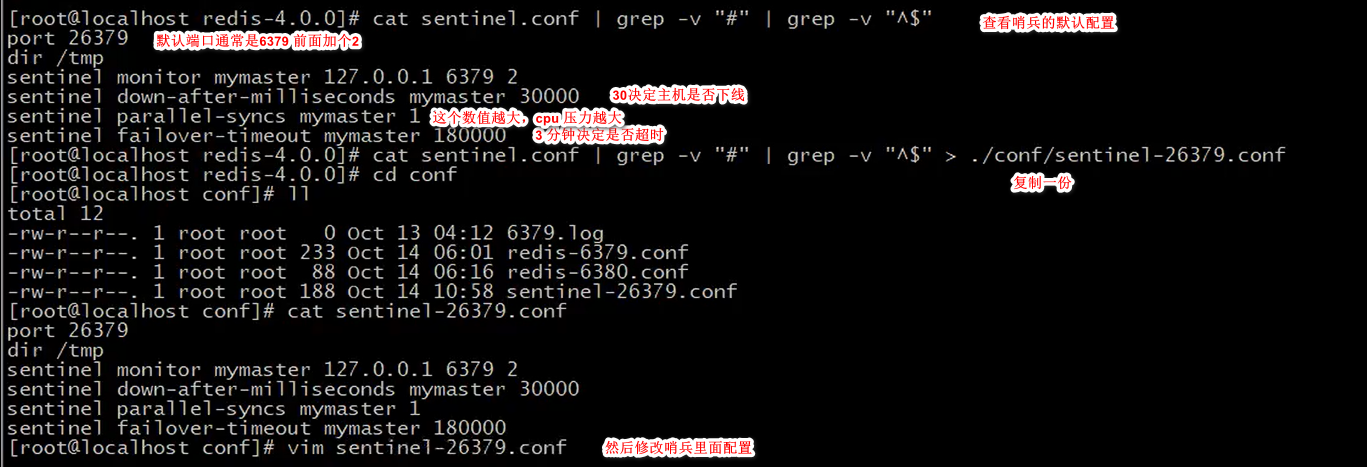
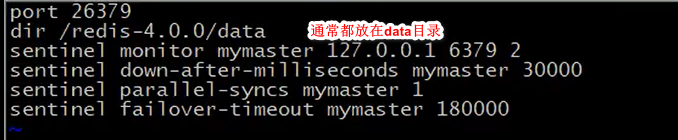
然后保存退出
然后把这个复制三份,就是三个哨兵。
这时候可以去把主、从 服务器都启动。
然后就可以先启动一个哨兵:命令: redis-sentinel sentinel-26379.conf
用这个命令把三个哨兵都启动,然后主、从服务器,客户端都正常使用
注意:如果其中master 挂掉了,会有一个哨兵发现这件事,其他哨兵一起来进行投票,决定真的挂掉了,然后再随机
挑选一个slave 来当master ,确保正常使用
集群
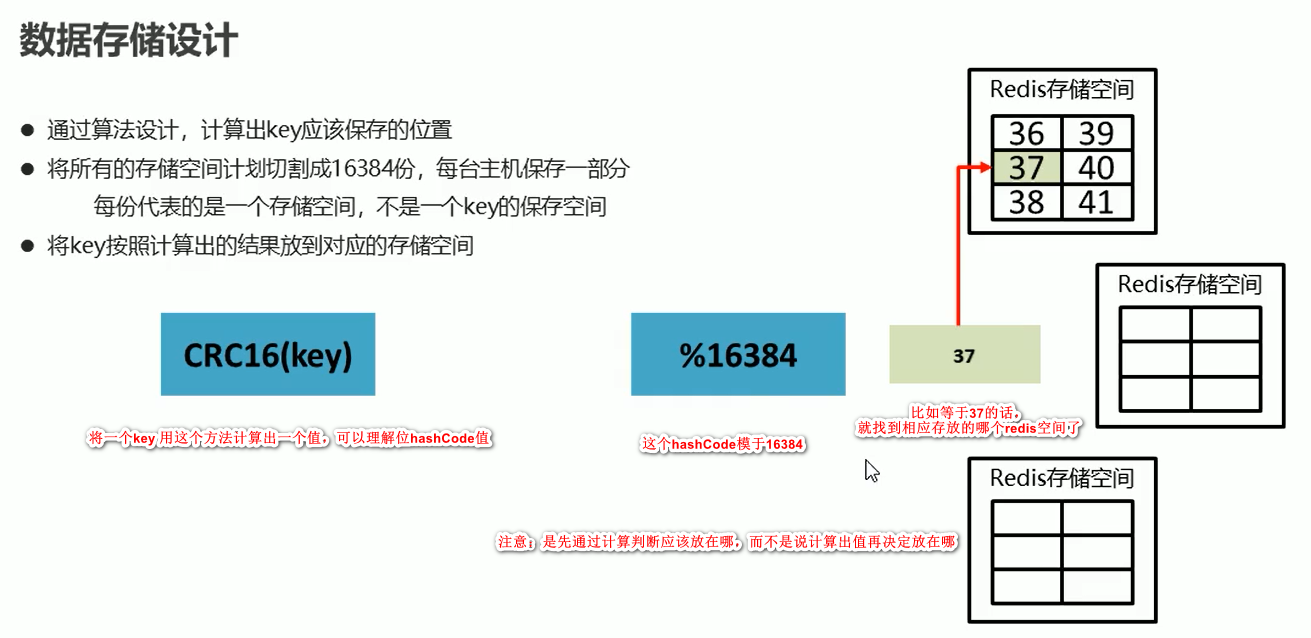
如果要加一个redis,把其他的储存的槽分一点到这个新的redis空间里,redis 集群之间相互都是联系着的,每个redis 都知道各个redis 之间
存储的槽的位置id,当客户访问数据时,如果第一次没有找对槽的位置,就会返回给服务器告诉具体的槽在哪个位置,最多两次就找到了
集群搭建
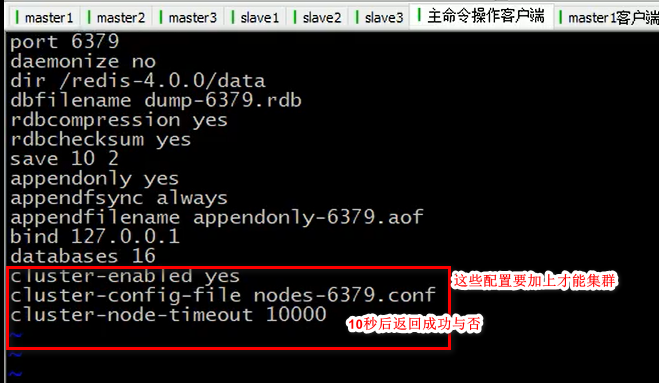
找到redis.conf 这个的redis 配置文件,然后如上图配置完成保存退出,然后把这个可以复制一份,改名字redis-6379.conf,
然后复制这个文件多份,做集群,最好都是redis-xxx端口号.conf 文件名

然后依次启动多个redis 的集群,可以靠各个端口号区分开的

启动redis 集群:要事先下载好有ruby 和 gem ,这两个东西版本要一样
然后执行 ./redis-trib.rb 这个命令,后面跟上所有的集群ip 地址:端口号
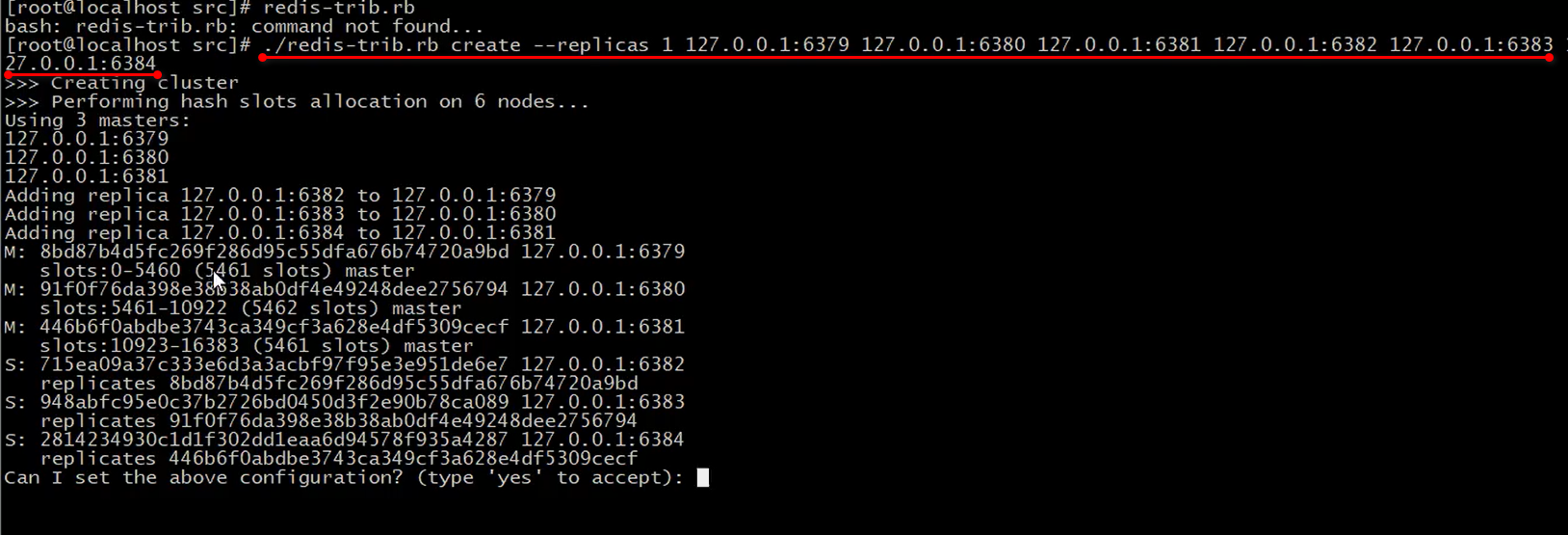
回车确定这个命令以后,发现信息打印出来了,告诉你每个redis 的空间的槽是多少,哪些是master 哪些是 slave 等等
然后输入 yes 确认
然后又会打印信息,哪些redis集群加入了,槽 的编号什么的,redis 集群搭建完成
存取数据
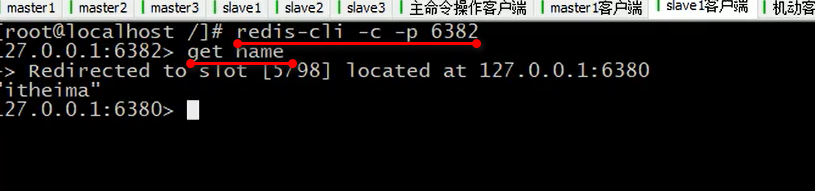
集群里面启动客户端的命令是 redis-cli -c 要加上-c 才行,然后set 指令存放一个数据,有返回结果告诉说槽的编号,redis 的端口号等
拿到数据时候,必须要指定端口才行:
主从切换:
如果有一个 从服务器下线掉线了,master 会告知整个redis 集群,某个slave 下线了
如果是 主服务器master 掉了连不上了,slave 会根据你的设置来进行等待连接,一秒连一次,直至发现连不上主服务器了,
就会有slave 自己谋朝篡位,当上了master 顶上去了,就算原来的主服务器又上来了,也不能当主服务了,只能当 从服务了
缓存预热
当服务器刚起来时候,缓存里没有数据,处理器就会加速运转导致压力过大,为了避免数据访问时候直接从数据库拿数据,然后放在
缓存里给处理器增加压力。所以提前把数据放入缓存里

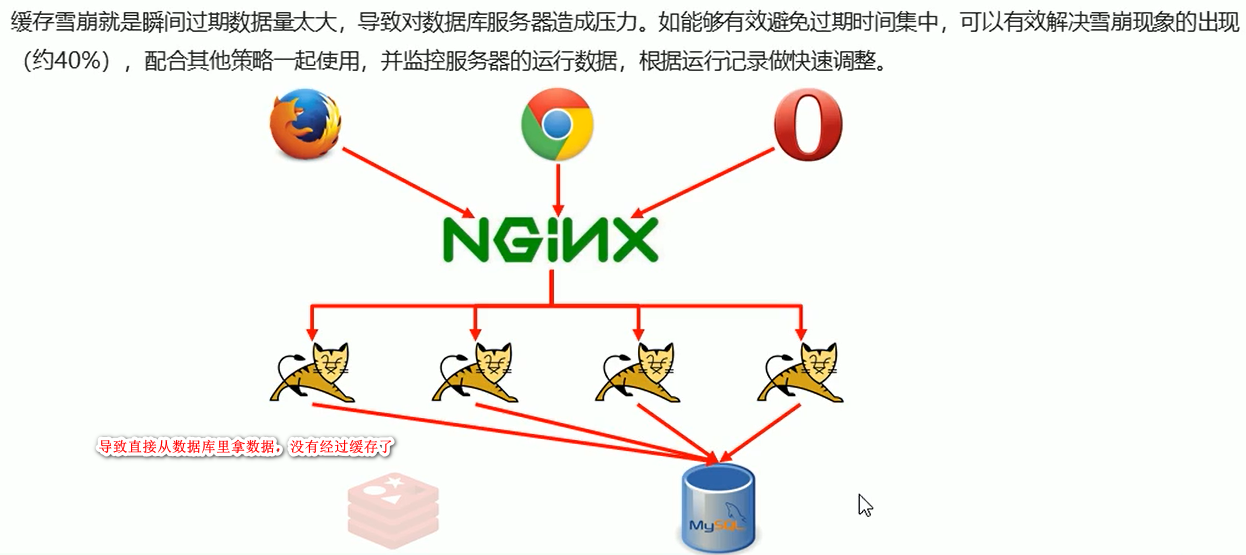
缓存雪崩
数据访问再瞬间突然变得很大,缓存里的数据跟不上,服务器也会崩了。
缓存击穿
和雪崩有一些相似,redis 内存平稳无波动,但是数据库崩溃。
一般问题是:原因是拿到的都是同一个key ,说明这个key 过期了


缓存穿透
在正常节日中,也没有抢购什么的业务,服务器突然崩了,感觉访问量比过节时候还多,
问题排查发现:redis 有大面积未命中,就是有很多key 无效了,结果发现很多非正常的URL 轮径的访问
一般的黑客攻击会想办法弄瘫痪公司的服务器,所以故意弄了很多不正确的url 访问

解决方案:还是从黑客的角度解决

性能指标监控
好了,redis 可以先告一段落啦~
期待下期吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号