单输出感知机及其梯度
recap
-
y=XW+by=XW+b
-
y=∑xi∗wi+by=∑xi∗wi+b
Perceptron
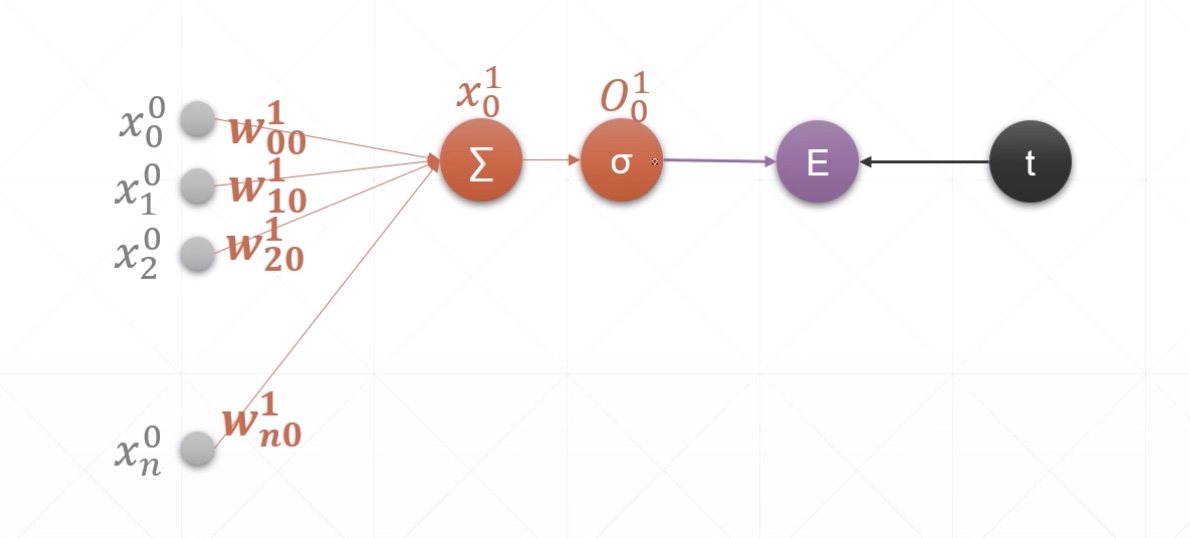
- x0ixi0 i表示当成第i个节点
- w0ijwij0 表示当层的第i个节点,j表示下一个隐藏层的第j个节点
- σσ 表示激活函数后的节点
- E表示error值
- t表示target值
Derivative
- E=12(O10−t)2E=12(O01−t)2
import tensorflow as tf
x = tf.random.normal([1, 3])
w = tf.ones([3, 1])
b = tf.ones([1])
y = tf.constant([1])
with tf.GradientTape() as tape:
tape.watch([w, b])
prob = tf.sigmoid(x @ w + b)
loss = tf.reduce_mean(tf.losses.MSE(y, prob))
grads = tape.gradient(loss, [w, b])
[<tf.Tensor: id=203, shape=(3, 1), dtype=float32, numpy=
array([[-0.00047306],
[-0.00288958],
[-0.00280226]], dtype=float32)>,
<tf.Tensor: id=201, shape=(1,), dtype=float32, numpy=array([-0.00275796], dtype=float32)>]
grads[0]
<tf.Tensor: id=203, shape=(3, 1), dtype=float32, numpy=
array([[-0.00047306],
[-0.00288958],
[-0.00280226]], dtype=float32)>
grads[1]
<tf.Tensor: id=201, shape=(1,), dtype=float32, numpy=array([-0.00275796], dtype=float32)>
