023 python3 BeautifulSoup模块使用与Python爬虫爬取博客园作业
BeautifulSoup就是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据。官方解释如下:
Beautiful Soup提供一些简单的、Python式的函数来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为UTF-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的Python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
所以说,利用它可以省去很多烦琐的提取工作,提高了解析效率。
一、模块安装
使用之前,需要确保已经安装好了BeautifulSoup和lxml模块。
pip install beautifulsoup4 lxml
二、解析器选择
Beautiful Soup在解析时实际上依赖解析器,它除了支持Python标准库中的HTML解析器外,还支持一些第三方解析器(比如lxml)。下表为BeautifulSoup支持的解析器:
|
解析器 |
使用方法 |
优势 |
劣势 |
|---|---|---|---|
|
Python标准库 |
|
Python的内置标准库、执行速度适中、文档容错能力强 |
Python 2.7.3及Python 3.2.2之前的版本文档容错能力差 |
|
lxml HTML解析器 |
|
速度快、文档容错能力强 |
需要安装C语言库 |
|
lxml XML解析器 |
|
速度快、唯一支持XML的解析器 |
需要安装C语言库 |
|
html5lib |
|
最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 |
速度慢、不依赖外部扩展 |
通过以上对比可以看出,lxml解析器有解析HTML和XML的功能,而且速度快,容错能力强,所以推荐使用它。
如果使用lxml,那么在初始化Beautiful Soup时,可以把第二个参数改为lxml即可:
from bs4 import BeautifulSoup soup = BeautifulSoup('<p>Hello</p>', 'lxml') print(soup.p.string)
三、基本用法
from bs4 import BeautifulSoup import requests, re req_obj = requests.get('https://www.baidu.com') soup = BeautifulSoup(req_obj.text, 'lxml') '''标签查找''' print(soup.title) # 只是查找出第一个 print(soup.find('title')) # 效果和上面一样 print(soup.find_all('div')) # 查出所有的div标签 '''获取标签里的属性''' tag = soup.div print(tag['class']) # 多属性的话,会返回一个列表 print(tag['id']) # 查找标签的id属性 print(tag.attrs) # 查找标签所有的属性,返回一个字典(属性名:属性值) '''标签包的字符串''' tag = soup.title print(tag.string) # 获取标签里的字符串 tag.string.replace_with("哈哈") # 字符串不能直接编辑,可以替换 '''子节点的操作''' tag = soup.head print(tag.title) # 获取head标签后再获取它包含的子标签 '''contents 和 .children''' tag = soup.body print(tag.contents) # 将标签的子节点以列表返回 print([child for child in tag.children]) # 输出和上面一样 '''descendants''' tag = soup.body [print(child_tag) for child_tag in tag.descendants] # 获取所有子节点和子子节点 '''strings和.stripped_strings''' tag = soup.body [print(str) for str in tag.strings] # 输出所有所有文本内容 [print(str) for str in tag.stripped_strings] # 输出所有所有文本内容,去除空格或空行 '''.parent和.parents''' tag = soup.title print(tag.parent) # 输出便签的父标签 [print(parent) for parent in tag.parents] # 输出所有的父标签 '''.next_siblings 和 .previous_siblings 查出所有的兄弟节点 ''' '''.next_element 和 .previous_element 下一个兄弟节点 ''' '''find_all的keyword 参数''' soup.find_all(id='link2') # 查找所有包含 id 属性的标签 soup.find_all(href=re.compile("elsie")) # href 参数,Beautiful Soup会搜索每个标签的href属性: soup.find_all(id=True) # 找出所有的有id属性的标签 soup.find_all(href=re.compile("elsie"), id='link1') # 也可以组合查找 soup.find_all(attrs={"属性名": "属性值"}) # 也可以通过字典的方式查找
更多详细使用可参考:https://cuiqingcai.com/5548.html
要求
第一部分:
第二部分:
正题
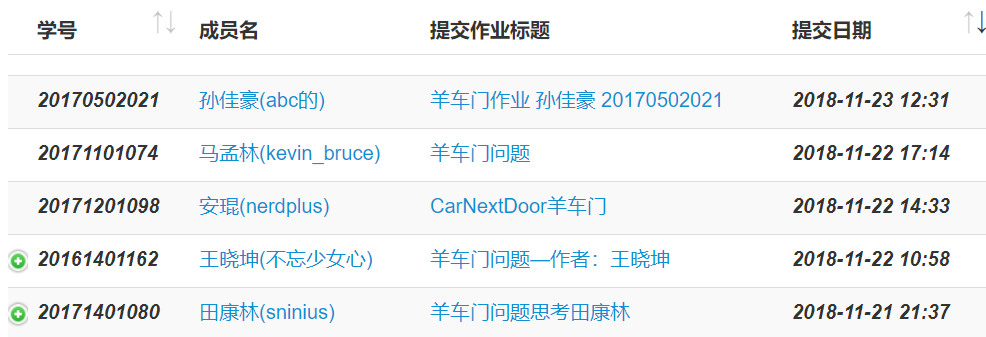
分析一下他们的代码,我在浏览器中对应位置右键,然后点击检查元素,可以找到对应部分的代码。但是,直接查看当前网页的源码发现,里面并没有对应的代码。我猜测这里是根据服务器上的数据动态生成的这部分代码,所以我们需要找到数据文件,以便向服务器申请,得到这部分资源。

在刚才查看元素的地方接着找数据文件,在Network里面的文件中很顺利的就找到了,并在报文中拿到了URL和请求方法。
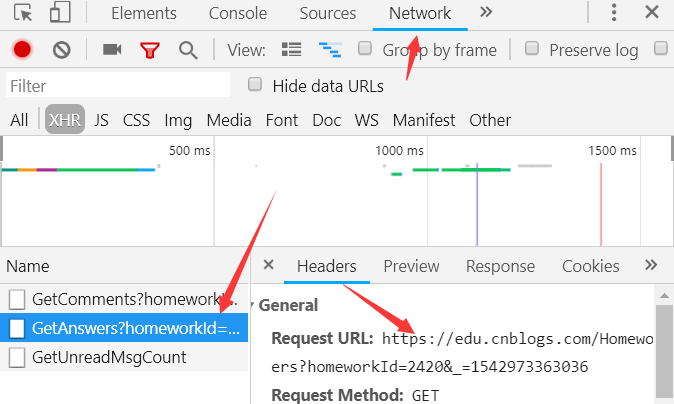
查看一下这个文件发现是JSON文件,那样的话难度就又降低了,因为Python中有json库,解析json的能力很强。可以直接将json转换为字典和列表类型。

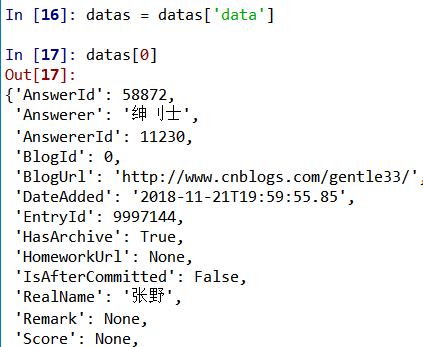
在这里我简单介绍一下数据解析的过程吧。首先,我将爬取到的json文本转换成某种数据类型,具体由数据决定,一般不是字典就是列表。查看类型发现是字典,且字典中有三个key值,而我们需要的key在一个叫data的key中。
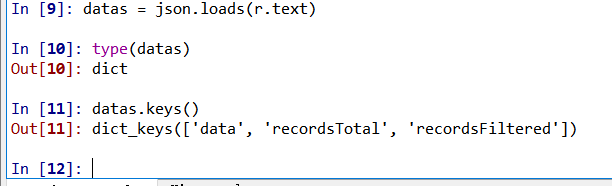
而data中的数据是一个学生信息的列表类型,列表的每个元素都是一个字典,包括学生姓名,学号等信息。可以利用下标获取列表元素,并用key值得到你想拿到的信息。比如,利用Url得到网页链接。
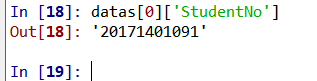
这时候我们爬取需要的信息的准备工作可以说是结束了,我们拿到了数据的URL,并且知道了数据类型和数据结构。于是,我们只需要用requests库爬一下这个页面,然后用json解析一下,并且筛选有用的信息就好了。
(没用到BeautifulSoup和re库有点小失落)
接下来就是创建文件,就没有什么难度了。只是在为每个学生创建文件的时候注意一下,创建好以后及时的回到上层目录,否则,可能会让文件一层层的嵌套下去。
代码
# -*- coding:utf-8 -*- import requests import json import os #抓取页面 url = 'https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1542959851766' try: r = requests.get(url,timeout=20) r.raise_for_status() r.encoding = r.apparent_encoding except: print('网络异常或页面未找到,请重试') #利用json拿到数据列表,每个列表元素都是字典 datas = json.loads(r.text)['data'] result = "" #数据处理 for data in datas: result += str(data['StudentNo'])+','+data['RealName']+','+data['DateAdded'].replace('T',' ')+','+data['Title']+','+data['Url']+'\n' #写入文件 with open('hwlist.csv','w') as f: f.write(result) #创建文件夹hwFolder os.mkdir('hwFolder') os.chdir('hwFolder') #创建每个学生的作业文件 for data in datas: #创建目录 os.mkdir(str(data['StudentNo'])) os.chdir(str(data['StudentNo'])) #抓取页面 try: webmsg = requests.get(data['Url'],timeout=20) webmsg.raise_for_status() webmsg.encoding = webmsg.apparent_encoding except: print('网络异常或页面未找到,请重试') #保存抓到的页面 with open(str(data['StudentNo'])+'.html','wb') as f: f.write(webmsg.content) os.chdir(os.path.pardir)
部分结果展示

上图是hwlist.csv文件的部分结果(Excel下打开)
玩个稍复杂点的
像之前那样爬取页面的话,其实是有点问题的。首先,我们只是爬取了页面的内容,但是并没有抓取到页面的样式,页面显示会不太正常,排版混乱。其次,页面中还有图片等元素都不会显示出来。而且,如果遇到网络问题代码需要再次运行的时候还会遇到一个问题,那就是目录已经存在了,我们在创建目录就会失败。除此之外还是有不少问题的,此处我先解决之前说到的几个问题。即显示问题和目录问题。
如何解决我提到的这些问题呢,目录问题我使用了一种比较容易实现的方案,那就是先判断当前目录是否存在,如果不存在就创建目录,否则就什么都不做。至于文件,暂定的方法是直接覆盖。显示问题也比较好解决,抓取网页和抓取样式或者网页其实都一样,就是用URL发送一个请求,来获得这个资源,其实和抓取HTML相比,就是文件格式不太一致。
以抓取样式表(CSS)为例,样式的URL怎么获取呢?有一些样式是在一个叫做Link的标签的href属性里,这里面就是外联样式存储的位置。把它提取出来,请求这个样式,并且修改原来的href属性为抓到的文件在自己电脑上的保存位置即可。这样的话即可保证抓到的CSS可以正常使用,确保排版正确。
当然了,即使这样,和原本的网页也是有差别的,因为抓取到的资源还是不够,和浏览器中获得的元素对比一下就会发现还差不少。鉴于本人能力有限,这里就补充一下爬取外联CSS和图片的内容,感兴趣的可以看一看。
Tips:这里解析HTML页面借助了强大的BeautifulSoup4库(解析标签和玩一样)和re库,使工作量减少了不少。(安装bs4库: pip install BeautifulSoup4)
# -*- coding:utf-8 -*- import requests import json import os import re from bs4 import BeautifulSoup def getHtml(url,timeout=110): try: res = requests.get(url,timeout) res.raise_for_status() res.encoding = res.apparent_encoding return res except: print('网络异常,'+url+"爬取失败") def saveFile(name,content,mode='w'): try: with open(name,mode) as f: f.write(content) except: print("文件"+name+"创建失败") def getSource(text): #抓取样式 root_url = 'https://www.cnblogs.com' soup = BeautifulSoup(text,'html.parser') for i in soup('link'): css_list = [css for css in i['href'].split('/') if 'css' in css] if css_list!=[]: filename = re.search(r'.*css',css_list[0]).group(0) r = requests.get(root_url+i['href']) saveFile(filename,r.content,'wb') text = text.replace(i['href'],'Source/'+filename) #抓取图片 用户自己插入的图片和网站自己生成的图片都抓 #用户自己插的那些格式很乱……用户自己搞的东西就是个坑 for i in soup('img'): try: img_list = [img for img in i['src'].split('/') if 'gif' in img or 'png' in img or 'jpeg' in img] except KeyError :#某用户自己改了HTML代码 得让我单独判断一下 img_list = [] if img_list!=[]: filename = img_list[0] try: r = requests.get(root_url+i['src']) r.raise_for_status() except: if not 'http' in i['src']: r = requests.get("https:"+i['src']) else:#又是某用户写博客用了HTML编辑器,写的还不对 r = requests.get(i['src']) saveFile(filename,r.content,'wb') text = text.replace(i['src'],'Source/'+filename) #text用于修改原始的页面链接,保证本地可以正常查看页面 return text #############################主程序############################ #抓取页面 并得到数据 r = getHtml('https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1542959851766') datas = json.loads(r.text)['data'] #处理数据并将数据写入文件 result = "" for data in datas: result += str(data['StudentNo'])+','+data['RealName']+','+data['DateAdded'].replace('T',' ')+','+data['Title']+','+data['Url']+'\n' saveFile('hwlist.csv',result,'w') #创建文件夹hwFolder if not os.path.exists('hwFolder'): os.mkdir('hwFolder') os.chdir('hwFolder') #创建每个学生的作业文件 for data in datas: #创建目录 if not os.path.exists(str(data['StudentNo'])): os.mkdir(str(data['StudentNo'])) os.chdir(str(data['StudentNo'])) #抓取页面 webmsg = requests.get(data['Url']) print('当前的URL:'+data['Url'])#等待的过程有字出来不会无聊 #页面的一些资源 if not os.path.exists('Source'): os.mkdir('Source') os.chdir('Source') webtext = getSource(webmsg.text) os.chdir(os.path.pardir) saveFile(str(data['StudentNo'])+'.html',webtext.encode(),'wb') os.chdir(os.path.pardir)
如果你的网络没问题,讲道理,应该不会抛异常。接下来找个页面看看效果吧:

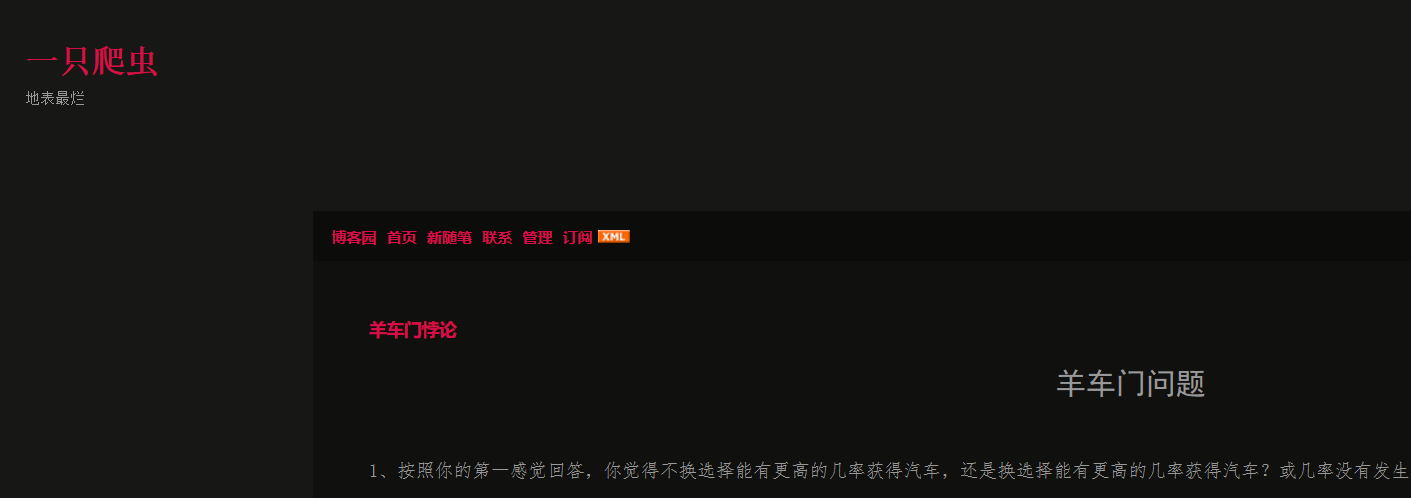
排版抓出来了,挺炫的,当然,图片也抓了。
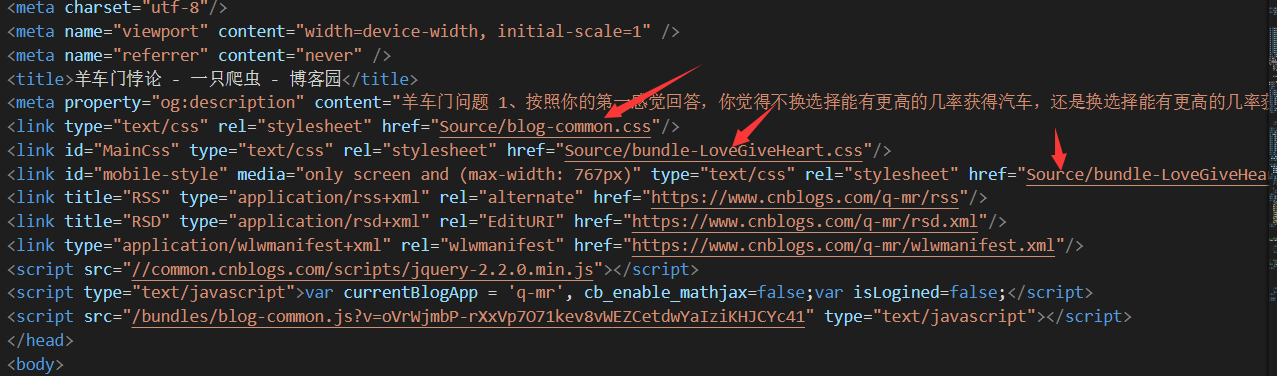
考虑到有人会HTML,我把被程序调整后的HTML代码找一个给大家看看,箭头指向的地方都是程序自己改过的地方:
其实,虽然现在又和原页面接近了不少,但是……我暂时没有时间继续完善了,以后还会继续完善。给大家一个原博客的图片,你会我先我还是少了些东西。暂时先这样吧。