向量数据库简介
2024-01-29 10:52 abce 阅读(352) 评论(0) 收藏 举报学习一下什么是向量数据库,原文地址:https://www.percona.com/blog/an-introduction-to-vector-databases/
设想一下,地球的南半球即将进入冬季,而你想要去 Patagonia 旅行,因此你需要买几件舒适的衣服。你打开谷歌浏览器,并在搜索框输入"适合 Patagonia 天气的夹克衫 ",并没有考虑特定的品牌,但搜索结果却是那个特定的品牌。这是怎么回事?可能是缺乏语境上下文( Patagonia 是一个品牌还是一个地方?) 有人可能会说,可以通过给名称添加类别来完善数据库,这样就可以把"苹果"作为一种水果和一家公司来存储,或者把" Patagonia "作为一个地方和一个品牌来存储。这会增加数据库模型的复杂性,而且可能需要更多时间来执行查询,但这是可行的。
现在,你在网上看到了一件漂亮夹克的图片,并想通过图片进行搜索。当搜索条件是图片时,数据库的面罩下会发生什么样的神奇变化,才能解决查询问题?图像的哈希版本?但如何比较形状和颜色?如何知道它是夹克而不是白大褂?如何以高效和可搜索的方式存储所有这些数据?请进入向量数据库。

Math detour
向量是一种数学对象,用于表示具有大小和方向的量。它可以表示为数字数组,其中每个元素对应一个特定维度:
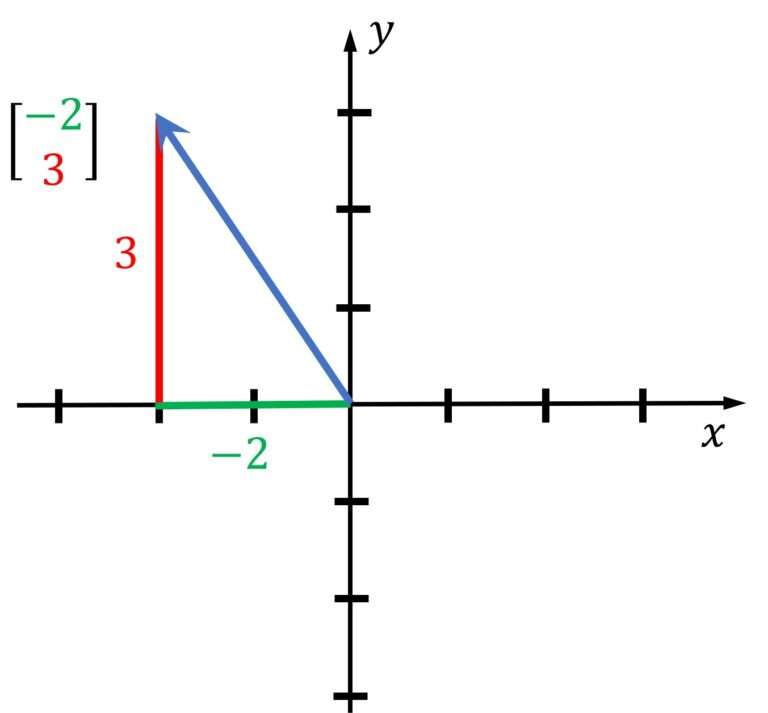
例如,上述向量用 (-2,3) 表示。这是一个二维向量,也可以是三维向量:
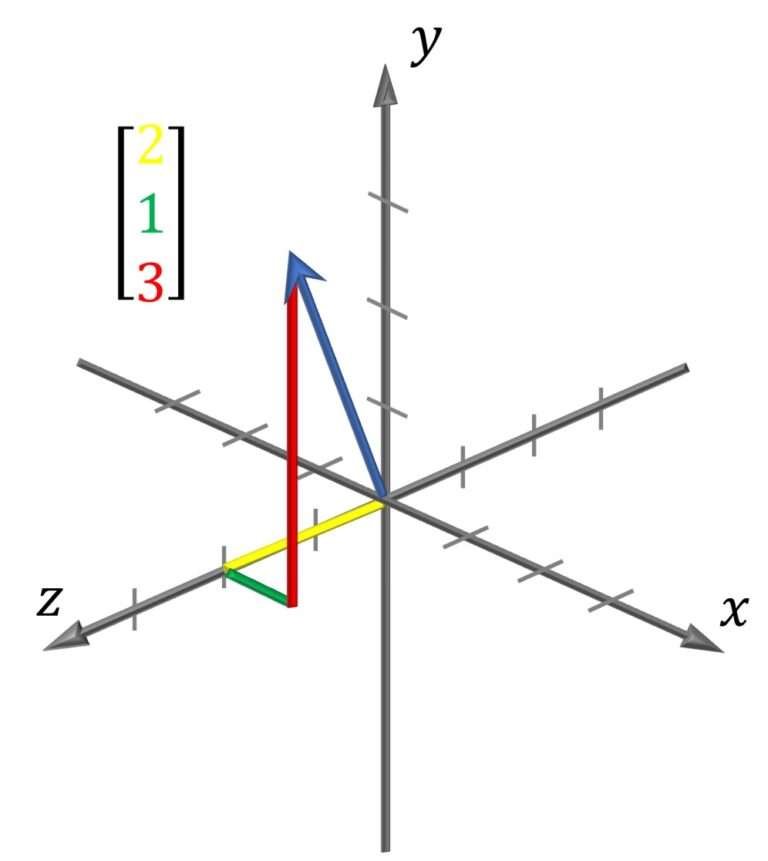
这个代表(2,1,3)。正如你所看到的,这里多了一个维度,但实际上你可以从 N 个维度进行计算!这就是线性代数所涵盖的主题。
但这和数据库有什么关系呢?实际上,这不是数据库本身的问题,而是用向量表示的数据的问题。而这些数据都存储在数据库中。
向量和数据库
在向量数据库中,向量以机器可以理解的格式表示文本、图像、声音等复杂数据。它将定性属性转化为定量特征,可以通过数学运算轻松进行比较。
如果我们回到夹克的例子,夹克的每个定性属性,如尺码:M、颜色:蓝色、袖子:长、面料:棉,等等,都可以被机器理解:都可以成为整个向量的一个值,也可以成为一个数字。
另一个很好的例子是面部识别。

将每个面部特征想象成一个维度(嘴、鼻子、眼睛、你隐藏的皱纹)。每个人的这些特征的独特组合就形成了他们的面部向量。
当你把照片上传到未来的面部识别系统时,系统会将其向量与存储的已知人物向量进行比较。如果找到一个接近的匹配,Bingo! 人就被识别出来了!
创建向量,也称为"嵌入"(EMBEDDINGS)
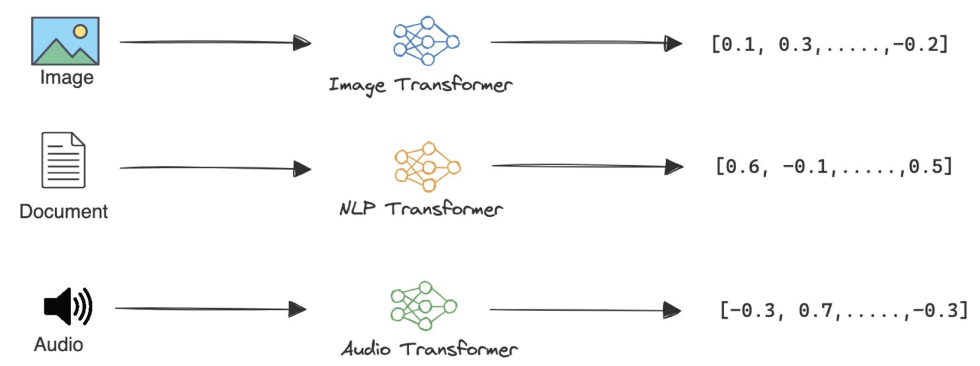
嵌入(EMBEDDINGS)是数据点的向量表示,可以捕捉其语义。关键是"语义"。为什么?因为这样你就可以使用文本的含义与图像的含义进行比较!这就是机器如何判定"冬季夹克"这个短语正确描述了冬季夹克的图片。这就是所谓的"语义搜索"。
嵌入如何生成?机器学习。嵌入过程的实际重任是在一个训练有素的模型中完成的。用户可以创建自己的模型,也可以使用适合自己需要的预训练模型。"Sentence Transformer"是一个很好的嵌入文本和图片的开源库。不过,其用法不在本文讨论范围之内。
嵌入的存储和搜索
现在我们知道,向量数据库存储的是......向量。但这些向量代表实体,包含描述和意义。为了尽可能详细地描述对象,我们可能需要尽可能多的维度。这就是所谓的高维空间。
高维数据
这是指具有大量属性的数据。一首歌可以用节奏、乐器、速度、音高、长度、主题、音调等来描述。每一个属性都是一个新的维度。
随着维数的增加,向量空间的体积也随之增大。增长幅度很大。高维度可以存储大量的细节,但在管理和搜索这些数据时也会付出代价。这就是所谓的"维度诅咒"。随着维度的增加,数据点之间的距离变得意义不大。搜索相似点的计算复杂度会变得非常昂贵,以至于不合理。要缓解这一问题,降维技术是关键。像"特征选择"、"哈希"和"主成分分析(PCA)" 等技术都能很好地解决这个问题。
距离度量(Distance metrics)
好了,我的向量数据库中有了嵌入。现在怎么办?就是现在: 更多数学。
距离度量是确定向量空间中两点之间"距离"的数学函数。不同的距离度量可以表示数据不同方面之间的关系。最常用的有:
·欧氏距离(Euclidean Distance): 对向量的大小非常敏感
·曼哈顿距离(Manhattan Distance): 适用于图像检索和金融分析
·余弦距离(Jaccard Similarity): 非常适合评估文本相似性,在这种情况下,单词的频率没有实际意义那么重要。
·Jaccard 相似度: 用于根据购买历史查找相似客户
搜索相似度:最终目标
Source: https://weaviate.io/blog/distance-metrics-in-vector-search
归根结底,所有这些都是为了找到相似的东西,快速、准确。这可以通过 K-近邻(KNN)和近似近邻(ANN)等算法来实现,每种算法都各有利弊。这些算法是数据库引擎的一部分,已经实现并可随时使用。但与其他数据库一样,索引是缩短执行时间的关键。
通过在特定维度上创建索引,向量数据库可以大大加快相似性搜索操作。一些常用的索引选项包括:
·Flat index ·Inverted File Index (IVF) ·Approximate Nearest Neighbors Oh Yeah (ANNOY) ·Product Quantization (PQ) ·Hierarchical Navigable Small World (HNSW)
向量数据库和向量存储
向量数据库从零开始设计,用于存储、索引和查询向量数据。例如 Pinecone 和 Quadrant。
向量存储是一种用于常规传统存储和搜索的数据库,但也能存储和检索向量数据:
ClickHouse (https://clickhouse.com/blog/vector-search-clickhouse-p1) 和使用 pg_vector 扩展的 PostgreSQL(请参阅此处的精彩演示:https://www.percona.com/blog/create-an-ai-expert-with-open-source-tools-and-pgvector/)。
总结
人工智能和机器学习正在推动技术的发展,这不仅体现在最终用户所看到的突破性成就上(ChatGPT、Bard、Copilot 等),还体现在其背后所发生的事情上。经过 ML 训练的模型需要特定的数据库来满足其需求,而该行业正在跟上这些要求。摆在我们面前的是一场持久的考验,以及与开源领域的融合,是激动人心的时刻!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号