PostgreSQL的参数:用户应了解的作用域和优先级
2023-09-04 16:26 abce 阅读(929) 评论(0) 收藏 举报
PostgreSQL允许用户在不同的作用域设置参数,同一个参数可以在不同的地方用不同的方法设置。这可能会产生冲突。有人可能想知道为什么某些更改没有生效,因此了解/收集设置的作用域和优先级很重要。
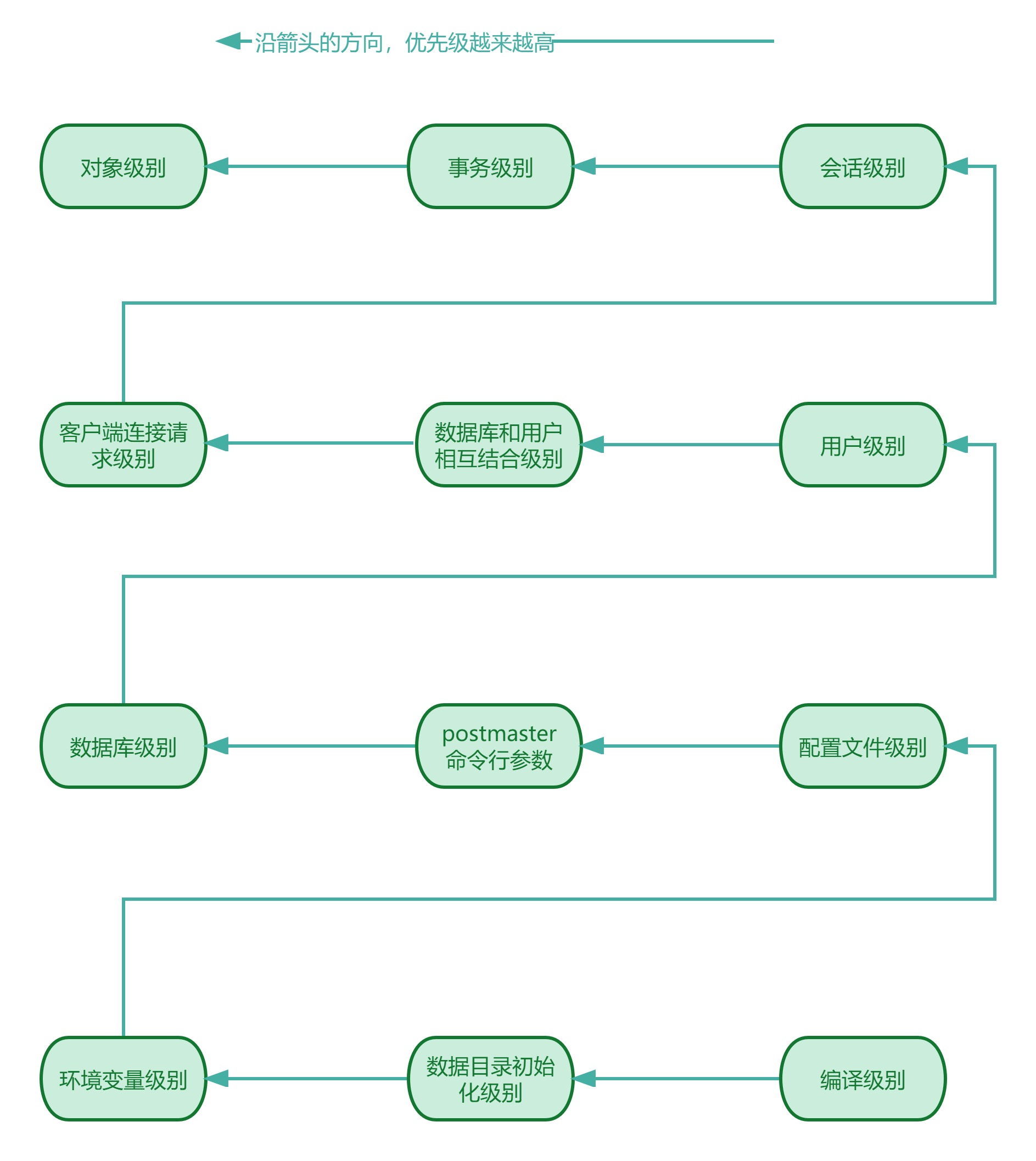
这里将试图列出用户可用的选项,并按照优先级递增的顺序排列。目的是为用户提供一个高层次的视角。
1.编译时参数设置
编译时设置的参数集是PostgreSQL的默认值。可以在pg_settings的boot_val列中查看这些值。例如:
postgres=# select name,boot_val from pg_settings;
比如,在我使用的PostgreSQL 11.12环境中,有290条记录。
这些编译时设置的参数的优先级最低,可以被任何其它级别的设置覆盖。不过,其中一些参数不能通过任何其他的方式修改。在编译时更改这些值不适合普通用途。如果PostgreSQL用户想更改这些值,需要从源代码重新编译PostgreSQL。有些配置选项是通过configure命令行选项公开的。这些配置选项包括:--with-blocksize=<BLOCKSIZE>以kB为单位设置表块大小,默认值为8kB;--with-segsize=<SEGSIZE>以GB为单位设置表段大小,默认为1GB。这意味着当表的大小超过1GB时,PostgreSQL会在数据目录中创建一个新文件;--with-wal-blockize=<BLOCKSIZE>以kB为单位设置WAL块大小,默认为8kB。
大多数参数都有编译时的默认值。这就是为什么我们只需指定极少量的参数值就能开始运行PostgreSQL的原因。
2.数据目录/初始化特定参数设置
在初始化数据目录时也可以设定参数。其中有些参数无法通过其他方式更改,或者很难更改。
例如,决定WAL段文件的wal_segment_size就是这样一个参数。PostgreSQL默认生成16MB的WAL段文件,而且只能在初始化时指定。
这也是决定是否使用data_checksums的级别。稍后可以使用pg_checksum工具对其进行修改,但这对大型数据库来说是一项艰巨的任务。
可以在这一级指定要使用的默认字符编码和本地设置。但也可以在后续级别中指定。更多信息请参阅initdb选项:https://www.postgresql.org/docs/current/app-initdb.html。
从数据目录初始化中获取的参数会优先于内置参数,可以通过以下检查:
postgres=# select name,setting from pg_settings where source='override';
name | setting
------------------------+-----------------------------------------
config_file | /etc/postgresql/11/main/postgresql.conf
data_checksums | off
data_directory | /var/lib/postgresql/11/main
hba_file | /etc/postgresql/11/main/pg_hba.conf
ident_file | /etc/postgresql/11/main/pg_ident.conf
lc_collate | en_US.UTF-8
lc_ctype | en_US.UTF-8
server_encoding | UTF8
transaction_deferrable | off
transaction_isolation | read committed
transaction_read_only | off
wal_buffers | 512
wal_segment_size | 16777216
(13 rows)
postgres=#
这里的override包含了自动调优估算出的值。
3.环境变量设置的PostgreSQL参数
包括postmaster在内的PostgreSQL可执行程序都在使用许多环境变量,但它们一般由客户端工具使用。
PostgreSQL服务器(postmaster)最常用的参数是PGDATA,它设置了data_directory参数。这些参数可以由systemd等服务管理器指定。
$ cat /usr/lib/systemd/system/postgresql-14.service ... Environment=PGDATA=/var/lib/pgsql/14/data/ … Environment=PG_OOM_ADJUST_FILE=/proc/self/oom_score_adj Environment=PG_OOM_ADJUST_VALUE=0
对于许多自动化/脚本,这将非常方便。例如:
$ export PGDATA=/home/postgres/data $ export PGPORT=5434 $ pg_ctl start waiting for server to start....2023-08-04 06:53:09.637 UTC [5787] LOG: starting PostgreSQL 15.3 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit 2023-08-04 06:53:09.637 UTC [5787] LOG: listening on IPv6 address "::1", port 5434 2023-08-04 06:53:09.637 UTC [5787] LOG: listening on IPv4 address "127.0.0.1", port 5434 2023-08-04 06:53:09.639 UTC [5787] LOG: listening on Unix socket "/tmp/.s.PGSQL.5434"
这里使用的端口是5434
4.配置文件
这可能是每个新手用户都知道的方法。基本配置文件是postgresql.conf,这是最常用的全局设置文件。
PostgreSQL默认在PGDATA中查找配置文件,但也可以使用postmaster的命令行参数config_file指定其他位置。
由于Postgresql支持在配置文件中使用include和include_dir指令,因此参数说明可以分割成多个文件和目录。因此,可以有嵌套/级联配置。
如果收到SIGHUP信号,PostgreSQL会重新读取所有配置文件。如果在多个位置设置了相同的参数,则会考虑最后读取的配置文件。在所有配置文件中,postgresql.auto.conf的优先级最高,因为它是最后读取的文件。所有"ALTER SYSTEM SET/RESET "命令都在该文件中保存信息。
5. postmaster的命令行参数
postmaster又名Postgres,具有将参数设置为命令行参数的功能(也具有获取参数值的功能)。这是许多管理PostgreSQL服务的外部工具使用的最可靠方法之一。
例如,高可用性解决方案Patroni将一些最关键的参数设置为命令行参数。下面是带有命令行选项的Postgres进程在Patroni环境中的样子
/usr/pgsql-14/bin/postgres -D /var/lib/pgsql/14/data --config-file=/var/lib/pgsql/14/data/postgresql.conf --listen_addresses=0.0.0.0 --port=5432
--cluster_name=kc_primary_cluster --wal_level=replica --hot_standby=on --max_connections=100 --max_wal_senders=5 --max_prepared_transactions=0
--max_locks_per_transaction=64 --track_commit_timestamp=off --max_replication_slots=10 --max_worker_processes=8 --wal_log_hints=on
这样,Patroni就能确保本地配置不会出错,从而不会对集群的可用性和稳定性造成不利影响。但只有在服务器启动时才能更改。显然,这比配置文件中的值优先。
这个范围是在实例级别。这就回答了许多Patroni用户的问题,即为什么他们不能直接更改参数文件中的某些参数。PostgreSQL用户可以检查那些作为命令行参数的参数,如
postgres=# select name,setting from pg_settings where source='command line';
name | setting
------------------------------+--------------------
cluster_name | perconapg_cluster
hot_standby | on
listen_addresses | 0.0.0.0
max_connections | 100
max_locks_per_transaction | 64
max_prepared_transactions | 0
max_replication_slots | 10
max_wal_senders | 5
max_worker_processes | 8
port | 5432
track_commit_timestamp | off
wal_level | replica
wal_log_hints | on
(13 rows)
这一级别的参数指定可以有"postmaster"上下文。下一节将讨论"上下文"的概念。
6.数据库级设置
到目前为止,讨论的所有选项都具有全局范围。也就是说,它们适用于整个实例。但是,PostgreSQL用户可能出于某种原因,希望在特定数据库级别上进行更改。
例如,其中一个数据库可能正在处理OLTP工作负载,在这种情况下,可能并不真正需要查询并行性,而且可能会产生不利影响。但另一个数据库可能是OLAP系统。
postgres=# ALTER DATABASE newdb SET max_parallel_workers_per_gather = 4; ALTER DATABASE
上下文概念
在这一阶段,我们应该记住另一个概念,即参数的"上下文"。例如,PostgreSQL监听的网络端口不能在单个数据库层面更改。更改此类参数需要重启PostgreSQL。因此,我们说参数"port"的上下文是postmaster。更改此类参数需要重启PostgreSQL的主进程postmaster。我们将不允许更改这一级别的参数集;任何尝试都将被阻止。
postgres=# ALTER DATABASE db1 SET max_connections=100; ERROR: parameter "max_connections" cannot be changed without restarting the server
最大连接数(max_connections)是由postmaster在全局(实例)级别上指定的,而且需要重启。
还有其他一些参数集仅需要通过postmaster进行通信,尽管它们可以在不重启服务器的情况下进行更改。这种情况被称为sighup。我们可以向postmaster发出信号,让它重新读取这些参数,并将相同的参数传播给所有子进程,这样就可以防止在数据库级别更改这些参数。
postgres=# ALTER DATABASE db1 SET log_filename='postgresql-DB1.log'; ERROR: parameter "log_filename" cannot be changed now
7.用户级设置
每个用户都可以有自己偏好的参数设置,这样该用户创建的所有会话都将使用该设置。请记住,用户级设置比数据库级设置具有更高的优先级。用户可以像这样检查自己的用户级设置:
select name,setting,source,context from pg_settings where source='user';
8.数据库-用户组合
PostgreSQL允许我们在特定用户/角色连接到特定数据库时进行参数设置。
例如:
ALTER USER admin IN DATABASE db1 SET max_parallel_workers_per_gather=6;
在这一级别进行设置的优先级甚至高于前面提到的所有设置级别。
select name,setting,source,context from pg_settings where name='max_parallel_workers_per_gather';
name | setting | source | context
---------------------------------+---------+---------------+---------
max_parallel_workers_per_gather | 6 | database user | user
(1 row)
9.客户端连接请求参数
在建立新连接时,有一个指定参数的选项。它可以作为连接字符串的一部分传递给PostgreSQL。
例如,我想连接到数据库执行一些批量数据加载和操作(ETL),我不想等待任何WAL写入。如果中间出现任何崩溃,我可以再次执行ETL。因此,我要请求关闭同步提交连接(synchronous_commit=off)。
$ psql "host=localhost user=postgres options='-c synchronous_commit=off'"
psql (14.8)
Type "help" for help.
postgres=# select name,setting,source,context from pg_settings where name='synchronous_commit';
name | setting | source | context
--------------------+-----------+--------+---------
synchronous_commit | off | client | user
(1 row)
10.会话级设置
每个会话都可以决定该会话在该时间点或执行时的设置。允许会话在需要时修改会话级设置。
postgres=# set jit=off; SET postgres=# select name,setting,source,context from pg_settings where name='jit'; name | setting | source | context ------+---------+---------+--------- jit | off | session | user (1 row)
一个很好的用例是,假设我们要重建一个大索引。我们知道这将耗费大量的maintenance_work_mem。在会话级别设置维护工作内存,可以在不影响其他会话的情况下简化我们的工作。
postgres=# set maintenance_work_mem = '4GB';
11.事务级设置
PostgreSQL允许我们在事务级等很小的范围内指定参数。
下面是一个不鼓励在特定事务块中进行顺序扫描的示例。
postgres=# BEGIN; BEGIN postgres=*# SET LOCAL enable_seqscan=off; SET
我更喜欢事务级设置,因为这些更改对事务来说是非常局部的,一旦事务完成,它们就会被还原回来。这是设置work_mem的最佳位置,可以将影响降到最低。
12. 对象级设置
PostgreSQL允许我们指定一个程序块(如 PL/pgSQL 函数)的特定参数。因此,设置是函数定义的一部分。
下面是测试函数级设置的函数定义示例。
CREATE OR REPLACE FUNCTION checkParams() RETURNS BOOLEAN as $$ DECLARE nm TEXT; setng TEXT; cntxt TEXT; src TEXT; BEGIN SELECT name,setting,context,source INTO nm,setng,cntxt,src from pg_settings where name='enable_partitionwise_join'; RAISE NOTICE 'Parameter Name: % value:% Context:% Source:%',nm,setng,cntxt,src; RETURN true; END; $$ LANGUAGE plpgsql SET enable_partitionwise_join = 'on' SET enable_seqscan = 'off';
PostgreSQL参数规范非常灵活且功能强大,因此了解其作用域、上下文和优先级对每个用户都很重要。经验法则是范围越广,优先级越低。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号