理解linux的IOWait
2023-06-14 21:01 abce 阅读(442) 评论(0) 收藏 举报看到许多Linux性能工程师将CPU使用的"IOWait"部分视为系统何时处于I/O瓶颈的标识。本文将解释为什么这种方法是不可靠的,以及你可以使用哪些更好的指标。
从运行一个小实验开始——在系统上产生大量的I/O使用:
sysbench --threads=8 --time=0 --max-requests=0 fileio --file-num=1 --file-total-size=10G --file-io-mode=sync --file-extra-flags=direct --file-test-mode=rndrd run
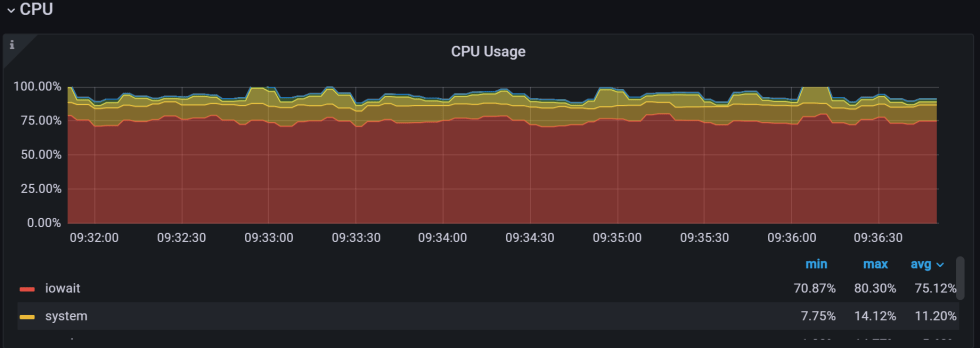
以下是PMM监控中CPU使用图示:
root@iotest:~# vmstat 10 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 3 6 0 7137152 26452 762972 0 0 40500 1714 2519 4693 1 6 55 35 3 2 8 0 7138100 26476 762964 0 0 344971 17 20059 37865 3 13 7 73 5 0 8 0 7139160 26500 763016 0 0 347448 37 20599 37935 4 17 5 72 3 2 7 0 7139736 26524 762968 0 0 334730 14 19190 36256 3 15 4 71 6 4 4 0 7139484 26536 762900 0 0 253995 6 15230 27934 2 11 6 77 4 0 7 0 7139484 26536 762900 0 0 350854 6 20777 38345 2 13 3 77 5
目前为止,一切顺利,我们看到I/O密集型工作负载明显对应了高IOWait (vmstat中的"wa"列)。
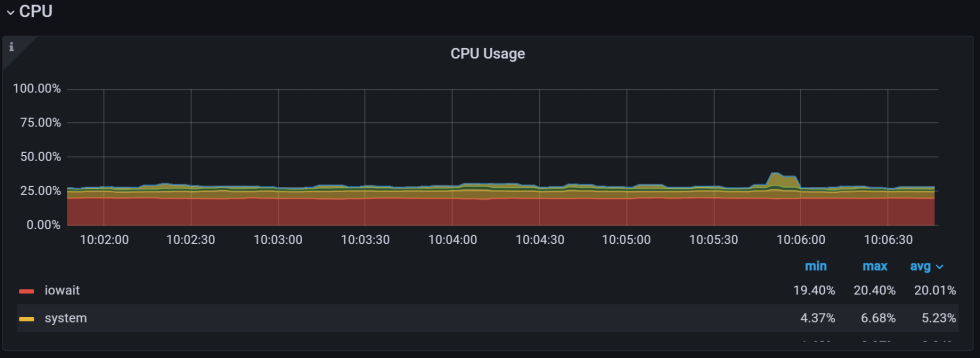
继续运行高I/O的工作负载,并添加一个繁重的cpu绑定负载:
sysbench --threads=8 --time=0 cpu run

root@iotest:~# vmstat 10 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 12 4 0 7121640 26832 763476 0 0 48034 1460 2895 5443 6 7 47 37 3 13 3 0 7120416 26856 763464 0 0 256464 14 12404 25937 69 15 0 0 16 8 8 0 7121020 26880 763496 0 0 325789 16 15788 33383 85 15 0 0 0 10 6 0 7121464 26904 763460 0 0 322954 33 16025 33461 83 15 0 0 1 9 7 0 7123592 26928 763524 0 0 336794 14 16772 34907 85 15 0 0 1 13 3 0 7124132 26940 763556 0 0 386384 10 17704 38679 84 16 0 0 0 9 7 0 7128252 26964 763604 0 0 356198 13 16303 35275 84 15 0 0 0 9 7 0 7128052 26988 763584 0 0 324723 14 13905 30898 80 15 0 0 5 10 6 0 7122020 27012 763584 0 0 380429 16 16770 37079 81 18 0 0 1
发生了什么事?IOWait完全消失了,现在这个系统看起来完全没有I/O限制!
实际上,我们的第一个工作负载没有任何变化——它仍然是I/O限制的;当我们看"IOWait"时,它就变得不可见了!
为了理解正在发生的事情,我们确实需要了解"IOWait"是什么以及它是如何计算的。
有一篇文章详细介绍了这个主题,但基本上,"IOWait"是一种空闲的CPU时间。如果CPU因为没有工作可做而处于空闲状态,则该时间被视为"空闲"。但是,如果由于进程在磁盘上等待而使它空闲,则I/O时间计入"IOWait"。
但是,如果一个进程正在等待磁盘I/O,而系统上的其他进程可以使用CPU,则该时间将作为user/system时间计入其CPU使用率。
由于这种计算方式,其他有趣的行为是可能的。现在,让我们在四核VM上运行一个I/O绑定进程,而不是运行8个I/O绑定线程:
sysbench --threads=1 --time=0 --max-requests=0 fileio --file-num=1 --file-total-size=10G --file-io-mode=sync --file-extra-flags=direct --file-test-mode=rndrd run
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 3 1 0 7130308 27704 763592 0 0 62000 12 4503 8577 3 5 69 20 3 2 1 0 7127144 27728 763592 0 0 67098 14 4810 9253 2 5 70 20 2 2 1 0 7128448 27752 763592 0 0 72760 15 5179 9946 2 5 72 20 1 4 0 0 7133068 27776 763588 0 0 69566 29 4953 9562 2 5 72 21 1 2 1 0 7131328 27800 763576 0 0 67501 15 4793 9276 2 5 72 20 1 2 0 0 7128136 27824 763592 0 0 59461 15 4316 8272 2 5 71 20 3 3 1 0 7129712 27848 763592 0 0 64139 13 4628 8854 2 5 70 20 3 2 0 0 7128984 27872 763592 0 0 71027 18 5068 9718 2 6 71 20 1 1 0 0 7128232 27884 763592 0 0 69779 12 4967 9549 2 5 71 20 1 5 0 0 7128504 27908 763592 0 0 66419 18 4767 9139 2 5 71 20 1
尽管这个进程完全是I/O限制的,但我们可以看到IOWait (wa)并不是特别高,小于25%。在拥有32、64或更多核的大型系统上,这种完全io瓶颈的进程几乎是不可见的,只产生个位数的IOWait百分比。
因此,高IOWait表示系统中有许多进程在等待磁盘I/O,但即使低IOWait,系统上的一些进程的磁盘I/O也可能出现瓶颈。
如果IOWait不可靠,可以使用什么来提供更好的可见性?
首先,看看特定于应用程序的可观察性。如果对应用程序进行了充分的测试,那么往往清楚它何时受到磁盘的约束,以及哪些特定的任务受到I/O约束。
如果只能访问Linux指标,请查看vmstat中的"b"列,它对应于在磁盘I/O上阻塞的进程。这将显示这样的进程,即使是并发的cpu密集型负载,也会屏蔽IOWait:

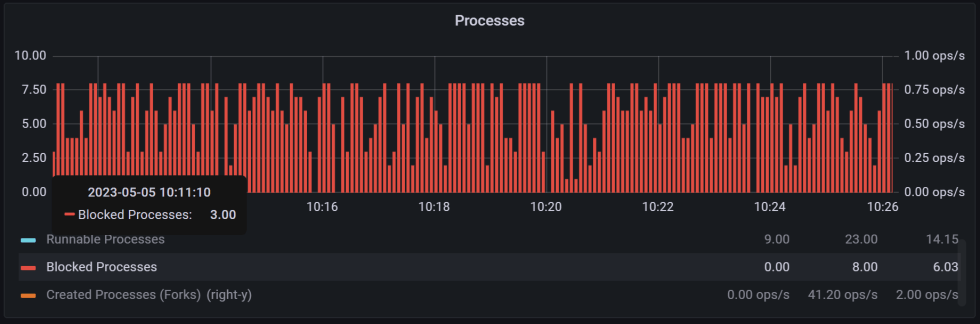
最后,可以查看每个进程的统计信息,以查看哪些进程正在等待磁盘I/O。对于PMM,你可以安装一个插件。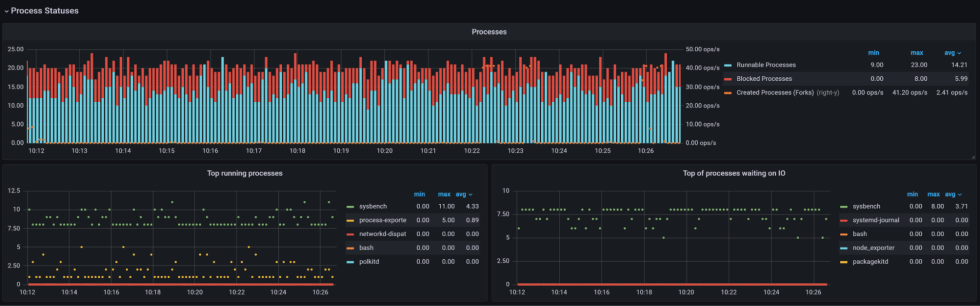
有了这个扩展,我们可以清楚地看到哪些进程是可运行的(在CPU可用性上运行或阻塞),哪些进程正在等待磁盘I/O!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号