MongoDB中执行批操作
2022-12-15 08:43 abce 阅读(894) 评论(0) 收藏 举报和大多数数据库系统类似,MongoDB也提供了api,支持在单个操作中插入或检索多个文档。
通过减少客户端和MongoDB之间的交互次数,可以提高数据库的性能。
使用.batchsize()优化批量读
当使用游标检索数据,可以使用batchSize来指定每次操作读取的行数。
比如,下面的游标中使用limit限定了处理的所有行数;而arraySize控制了每次网络请求从mongodb中检索的文档数。
cursor = useDb.collection('millions').find().limit(limit).batchSize(arraySize);
for (let doc = await cursor.next(); doc != null; doc = await cursor.next()) {
counter++;
}
batchSize操作符不会真正给程序返回一个数组,只是控制每次网络交互中检索的文档数量。
默认情况下,MongoDB为.batchSize设置了一个相当高的值,如果你随意更改它,可能会很容易降低性能。
但是,如果你从远程表取回大量的小的行,增加该选项的值会显著提升性能。
以下是我们的测试结果,将batchSize设置成小于1000,性能会很糟糕,有时会特别糟糕。设置大于1000后,会有显著的性能提升。
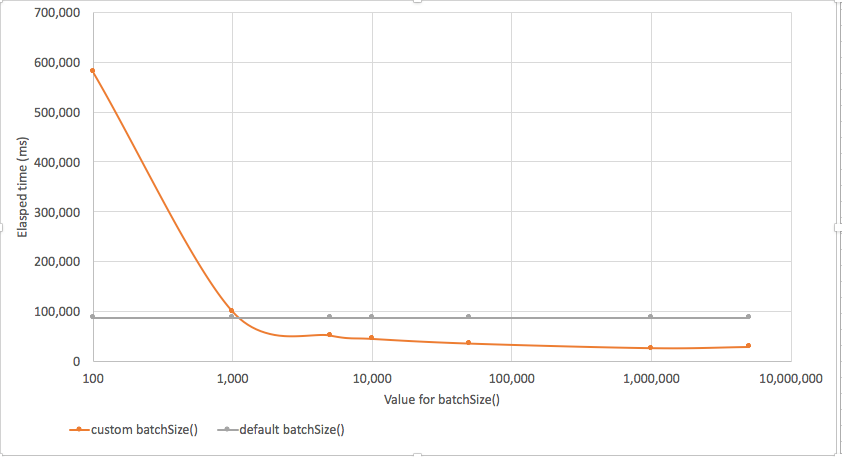
代码中要避免过量的网络交互(Network Round Trips)
batchSize()可以帮助减少网络开销。有时候,唯一可以优化网络来回开销的方法是优化代码逻辑。比如:
for (i = 1; i < max; i++) {
//console.log(i);
if ((i % 100) == 0) {
cursor = useDb.collection(mycollection).find({
_id: i
});
const doc = await cursor.next();
counter++;
}
}
我们正在从MongoDB集合中每100个文档中取出一个。如果集合很大,那就是大量的网络往返。此外,这些请求中的每一个都将通过索引查找来满足,并且所有这些索引查找次数是非常多的。
或者,我们可以在一个操作中提取整个集合,然后提取我们想要的文档。
const cursor = useDb.collection(mycollection).find().batchSize(10000);
for (let doc = await cursor.next(); doc != null; doc = await cursor.next()) {
if (doc._id % divisor === 0) {
counter++;
}
}
直觉上,可能会认为第二种方法会花费更长的时间。毕竟,我们现在从MongoDB中检索的文档多了100倍,对吧?但是,由于游标在每个批处理中(在底层)要拉过数千个文档,因此第二种方法实际上网络强度要小得多。如果数据库位于一个较慢的网络上,那么第二种方法将会快得多。
下面我们将看到本地服务器(例如,在我的笔记本电脑上)和远程服务器(Altas)两种方法的性能。
当数据在我的笔记本电脑上时,第一种方法要快一些。但是当服务器是远程的时,在一次操作中调出所有数据要快得多。

批量插入
就像我们想要批量地从MongoDB中取出数据一样,我们也想批量地插入数据——如果我们有很多数据要插入的话。批量插入的代码比find()示例要复杂一些。下面是一个批量插入数据的示例。
if (orderedFlag == 1)
bulk = db.bulkTest.initializeOrderedBulkOp();
else
bulk = db.bulkTest.initializeUnorderedBulkOp();
for (i = 1; i <= NumberOfDocuments; i++) {
//Insert a row into the bulk batch
var doc = {
_id: i,
i: i,
zz: zz
};
bulk.insert(doc);
// Execute the batch if batchsize reached
if (i % batchSize == 0) {
bulk.execute();
if (orderedFlag == 1)
bulk = db.bulkTest.initializeOrderedBulkOp();
else
bulk = db.bulkTest.initializeUnorderedBulkOp();
}
}
bulk.execute();
在第2行或第4行,我们为bulkTest集合初始化一个bulk对象。有两种方法可以做到这一点——我们可以创建有序的或非有序的。Ordered保证集合按照它们呈现给bulk对象的顺序被插入。否则,MongoDB可以优化插入到多个流,这些流可能不是按顺序插入的。
在第9行,我们将文档添加到"bulk"对象。当达到适当的批处理大小(第11行)时,执行批处理(第12行)并重新初始化bulk对象(第14或16行)。我们在最后(第19行)进一步执行,以确保插入了所有文档。
我使用不同的"批处理"大小(例如,在execute()调用之间插入的文档数量)将100,000个文档插入到我笔记本电脑上的一个集合中。我尝试了有序和无序的批量操作。结果如下图所示:
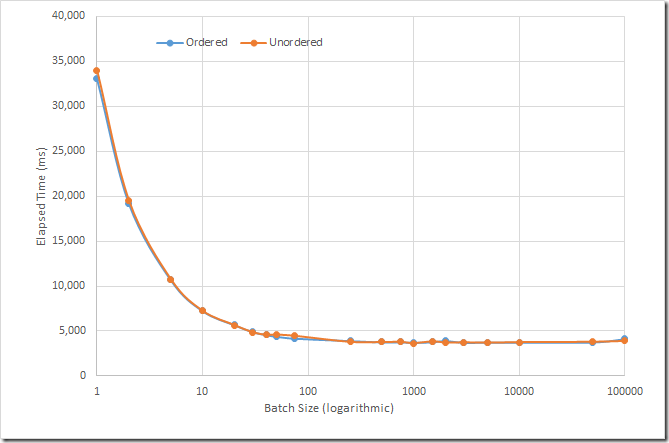
结果非常明显——批量插入可以显著提高性能。最初,批处理大小的每一次增加都会降低性能,但最终性能会趋于稳定。
我相信MongoDB无论如何都将每个操作的批数限制在1000个,但在此之前,你的网络数据包也有可能被填满,并且你不会看到通过增加批大小可以减少运行时间。因为文档大小不同,可能网络包已经满了。
https://dzone.com/articles/bulk-operations-in-mongodb


 浙公网安备 33010602011771号
浙公网安备 33010602011771号