PostgreSQL 高级SQL(一)分组集
2020-07-12 13:27 abce 阅读(2409) 评论(0) 收藏 举报本文是转载,原文地址是:https://www.jianshu.com/p/fa620e2d9f1b
作为一名开发者,平时工作中用到最多的可能就是SQL了,简单的SQL我们平时基本都用的差不多了,今天我们介绍一下PG的一些高级SQL,主要是PG SQL的分组集,这些SQL主要用于一些报表任务的开发。
本文章以及后续几章节的数据案例来源于 TWB(世界银行中国区官网),有兴趣的读者可以在世界银行主站的搜索框里面搜索GDP,选择现价美元,进入文章(https://data.worldbank.org.cn/indicator/NY.GDP.MKTP.CD)后有可以下载数据,数据格式有cvs,excel,xml格式可以下载
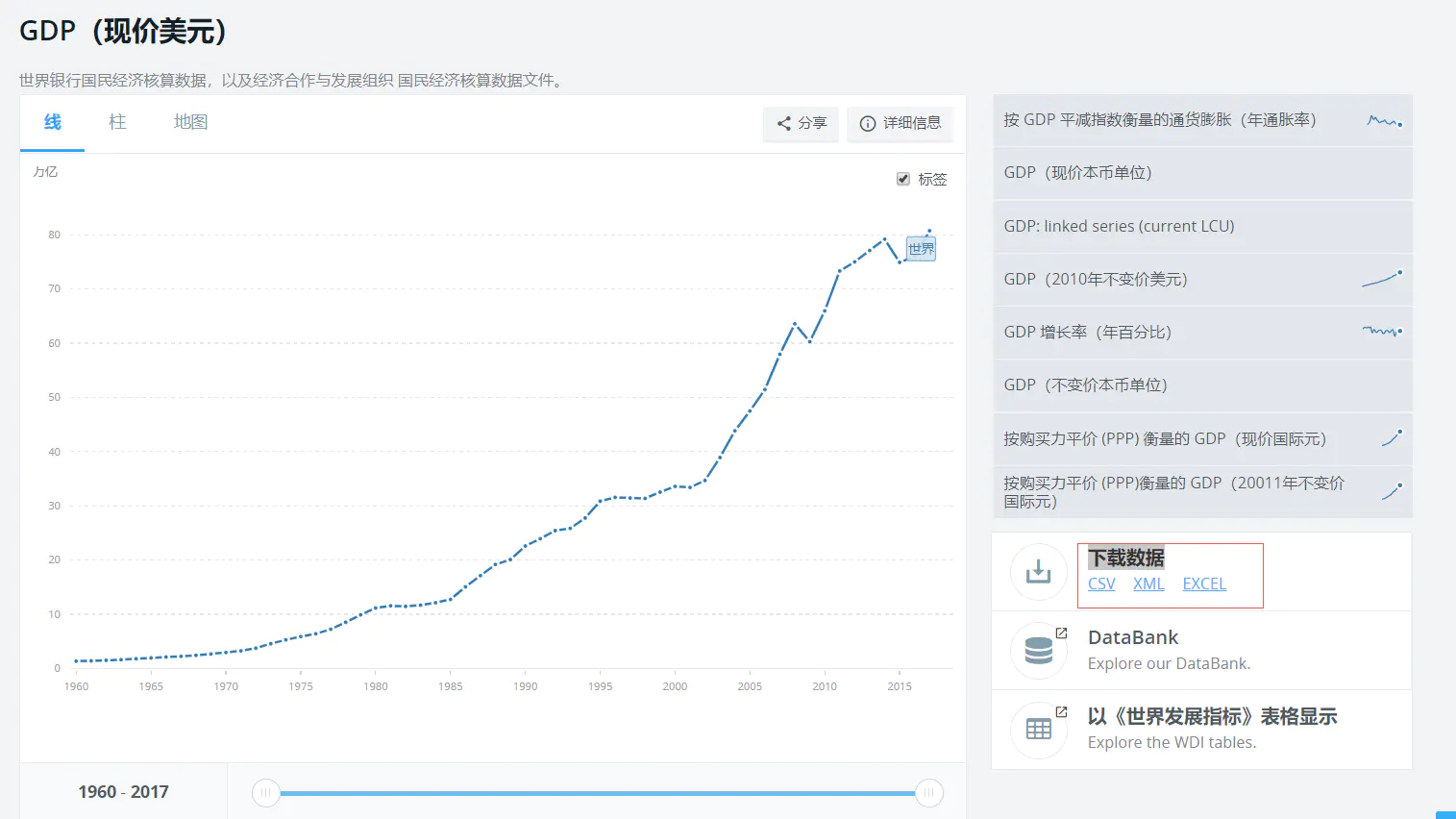
博主的数据是下载的CVS+XML,借助pg copy命令和java解析xml的方式导入数据路的,在博主提供生成好的sql脚本以及java代码和copy导入过程俩种方式,有兴趣的读者可以自己尝试,代码在码云上(https://gitee.com/zhengxianlei/PGAdvanceSQL);
案例数据是关于世界所有国家(或地区)从1960年到2018年的GDP,以及国家所属的消费层次级别,国家所在的大洲或者地区;
SELECT region, round( AVG ( gdp ), 0 ) FROM country_gdp_year_final WHERE YEAR = '2017' GROUP BY region ORDER BY 2 DESC;

group by非聚合函数可以很容易让我们看到2017年世界GDP均值最高地区是:北美洲,GDP最低地区是:撒哈拉以南非洲,group by 子句将很多行变成每组一行显示,
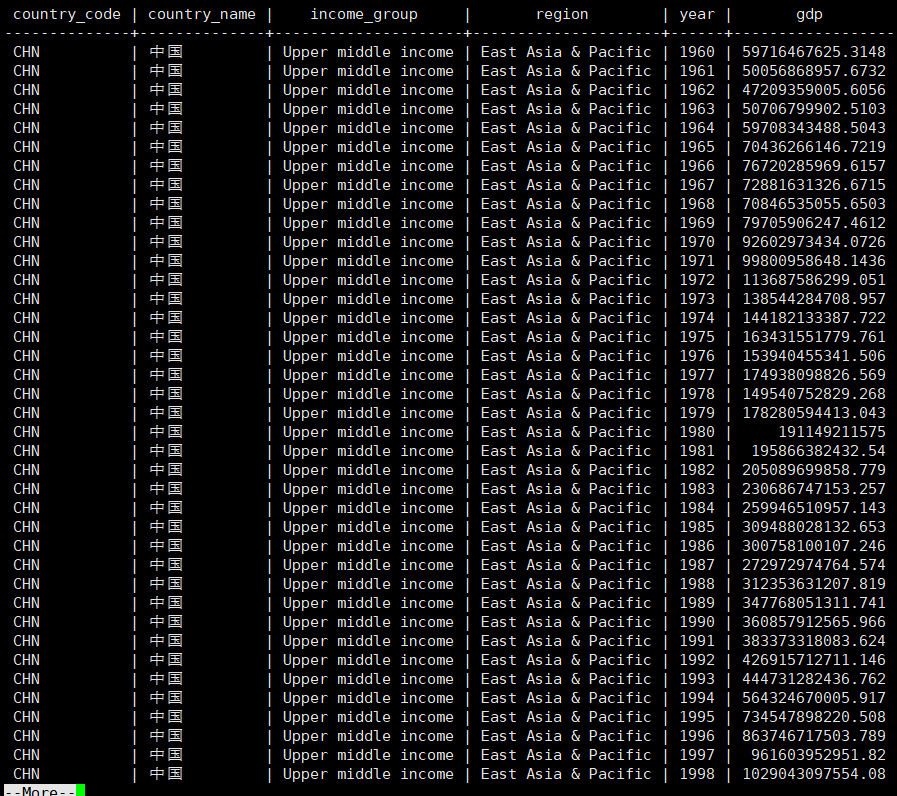
2、如果我们想要上面的报表带有全世界各国GDP平均值的话我们大部分人可能会出下面类似的SQL:
( SELECT region, round( AVG ( gdp ), 0 ) AS sumCount FROM country_gdp_year_final WHERE YEAR = '2017' GROUP BY region ORDER BY 2 DESC ) UNION ALL SELECT NULL AS region, sumCount FROM ( SELECT round( SUM ( gdp ) / COUNT ( 1 ), 0 ) AS sumCount FROM country_gdp_year_final WHERE YEAR = '2017' ) AS P
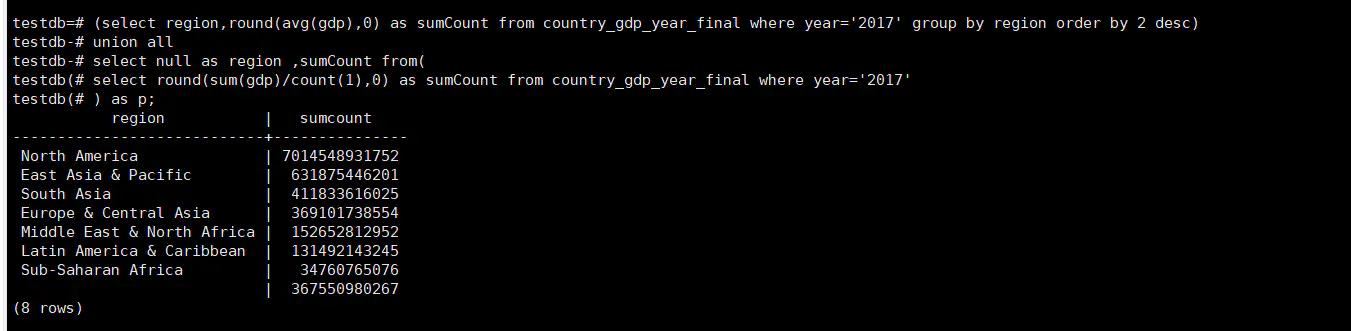
SELECT region, round( AVG ( gdp ), 0 ) AS sumCount FROM country_gdp_year_final WHERE YEAR = '2017' GROUP BY ROLLUP ( region ) ORDER BY 2 DESC;

group by rollup(column) 除了计算column字段分组下的聚合结果以外,还会计算整体的聚合结果,本例就是计算世界2017年GDP所有国平均值(这些国家有着一个共同的region叫做:世界),无需运行俩个查询;
rollup也可以通过不止一列的方式来使用,比如计算中日德法美六国的1960-2018年年均GDP:
SELECT region, country_name, round( AVG ( gdp ), 0 ) FROM country_gdp_year_final WHERE country_code IN ( 'CHN', 'JPN', 'USA', 'DEU', 'CAN', 'FRA' ) GROUP BY ROLLUP ( region, country_name );

从上图我们可以看出一共多出了四行行数据,rollup(region,country_name)的数据是,group by region,country_name+ group by region+总体的均值;
3、group by cube子句
SELECT region, country_name, round( AVG ( gdp ), 0 ) FROM country_gdp_year_final WHERE country_code IN ( 'CHN', 'JPN', 'USA', 'DEU', 'CAN', 'FRA' ) GROUP BY CUBE ( region, country_name );
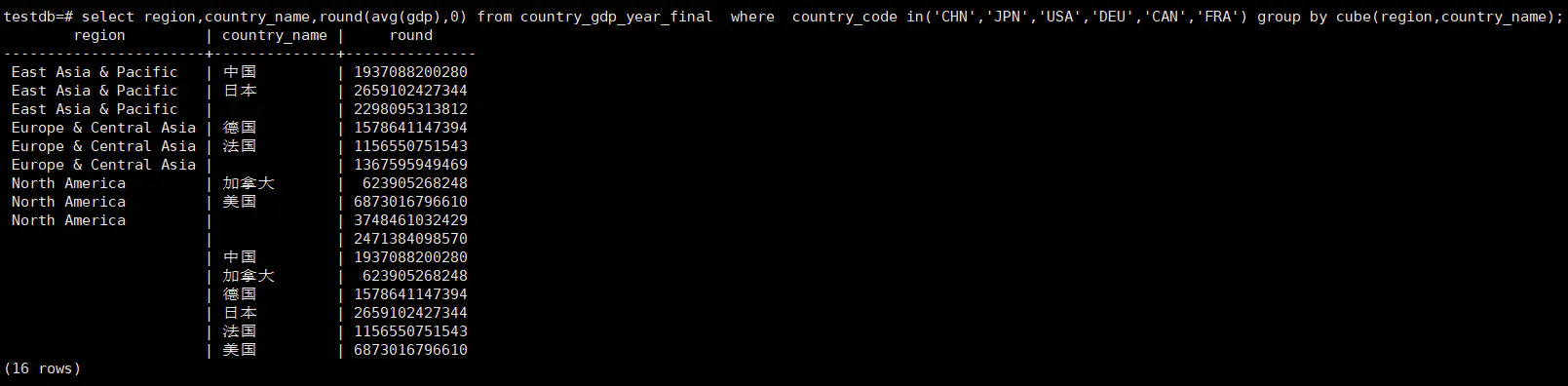
cube:在英文里面是是立方体的意思,上面的句子group by cube(region,country_name)比group by rollup(region,country_name)多出了六行数据:
group by country_name 的六行,从上面的数据我们可以知道cube(region,country_name)的总行数=group by region,country_name+group by region+group by country_name+总体均值,其整体思想是抽取各个层面的聚合集结果。
4、group by grouping sets子句
SELECT region, country_name, round( AVG ( gdp ), 0 ) FROM country_gdp_year_final WHERE country_code IN ( 'CHN', 'JPN', 'USA', 'DEU', 'CAN', 'FRA' ) GROUP BY GROUPING SETS ( ( ), region, country_name, ( region, country_name ) );
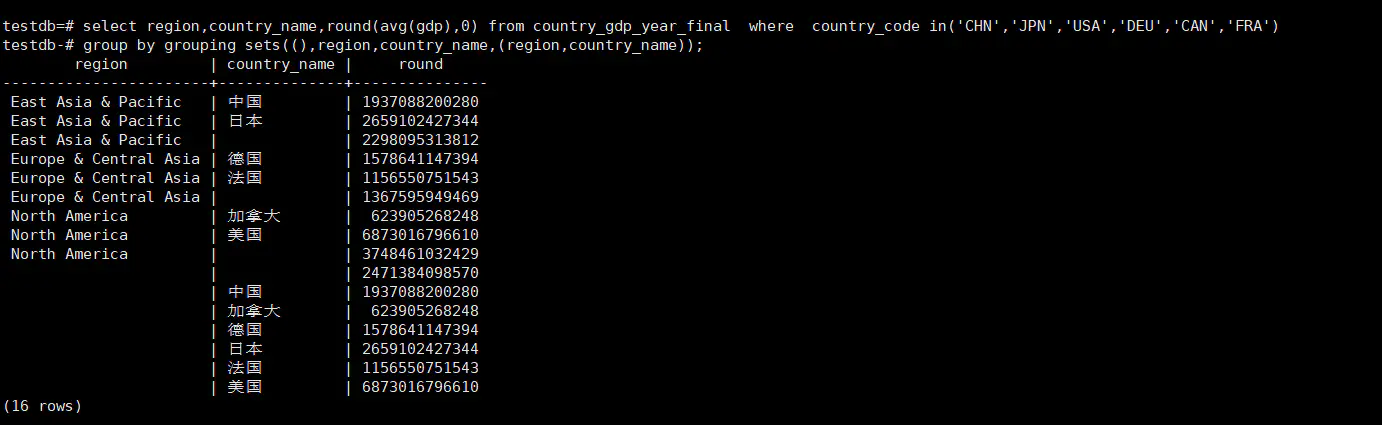
可以看到上面的group by grouping sets((),region,country_name,(region,country_name))=group by cube(region,country_name)
看到这儿有人可能对于上面的sets()括号里面的内容有点犯糊涂了尤其是(),(region,country_name)到底是什么,对于结果集的产生到底有什么影响呢,我们不妨单独测试一些
A、
SELECT region, country_name, round( AVG ( gdp ), 0 ) FROM country_gdp_year_final WHERE country_code IN ( 'CHN', 'JPN', 'USA', 'DEU', 'CAN', 'FRA' ) GROUP BY GROUPING SETS ( ( region, country_name ) );

从结果我们可以看出来上面的查询和select region,country_name,round(avg(gdp),0) from country_gdp_year_final where country_code in('CHN','JPN','USA','DEU','CAN','FRA') group by region,country_name 是等价的;
B、
SELECT region, country_name, round( AVG ( gdp ), 0 ) FROM country_gdp_year_final WHERE country_code IN ( 'CHN', 'JPN', 'USA', 'DEU', 'CAN', 'FRA' ) GROUP BY GROUPING SETS ( ( ), region, country_name );
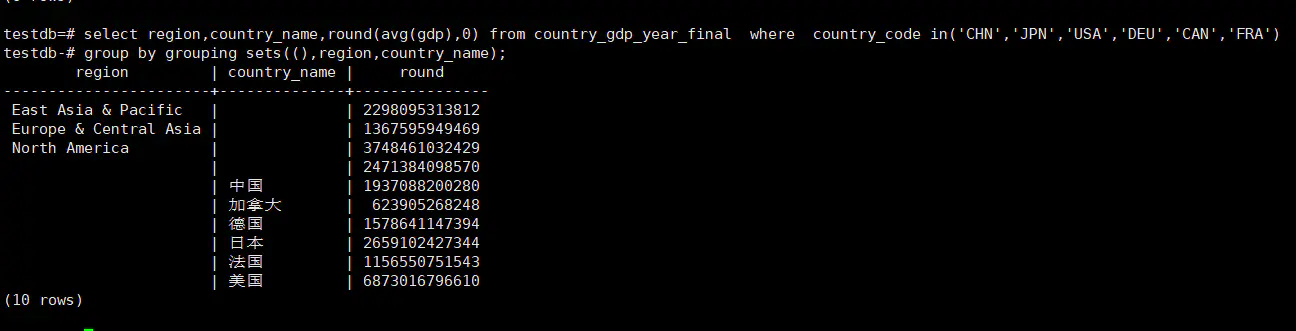
C、
SELECT region, country_name, round( AVG ( gdp ), 0 ) FROM country_gdp_year_final WHERE country_code IN ( 'CHN', 'JPN', 'USA', 'DEU', 'CAN', 'FRA' ) GROUP BY GROUPING SETS ( region, country_name );
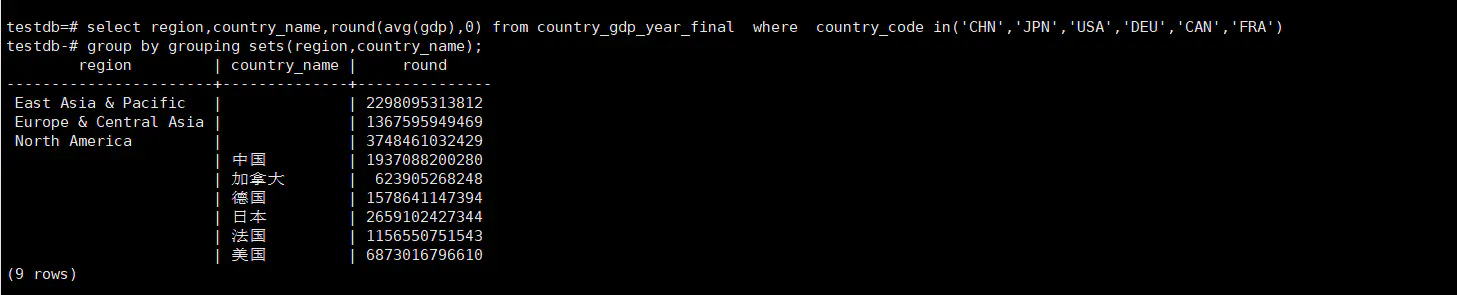
从结果集我们可以看出来group by grouping sets(region,country_name) 等价于group by region+group by country_name
综上所述,我们可以得出以下的结论: group by grouping sets 的查询结果是最全面,使用到group by、group by rollup、group by cube的地方其实使用group by grouping sets也是可以实现的


 浙公网安备 33010602011771号
浙公网安备 33010602011771号