

贝叶斯法则
机器学习的任务:在给定训练数据A时,确定假设空间B中的最佳假设。
最佳假设:一种方法是把它定义为在给定数据A以及B中不同假设的先验概率的有关知识下的最可能假设
贝叶斯理论提供了一种计算假设概率的方法,基于假设的先验概率、给定假设下观察到不同数据的概率以及观察到的数据本身
先验概率和后验概率
用P(A)表示在没有训练数据前假设A拥有的初始概率。P(A)被称为A的先验概率。
先验概率反映了关于A是一正确假设的机会的背景知识
如果没有这一先验知识,可以简单地将每一候选假设赋予相同的先验概率
类似地,P(B)表示训练数据B的先验概率,P(A|B)表示假设B成立时A的概率
机器学习中,我们关心的是P(B|A),即给定A时B的成立的概率,称为B的后验概率
贝叶斯公式
贝叶斯公式提供了从先验概率P(A)、P(B)和P(A|B)计算后验概率P(B|A)的方法
贝叶斯定理便是基于下述贝叶斯公式:

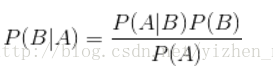
P(B|A)随着P(B)和P(A|B)的增长而增长,随着P(A)的增长而减少,即如果A独立于B时被观察到的可能性越大,那么A对B的支持度越小
朴素贝叶斯
朴素贝叶斯算法是假设各个特征之间相互独立,使用贝叶斯公式进行分类的。请参考:https://blog.csdn.net/amds123/article/details/70173402
spark NavieBayes 官方示例代码如下:
import org.apache.spark.ml.classification.NaiveBayes
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.sql.SparkSession
object NavieBayesDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("NavieBayesDemo").master("local")
.config("spark.sql.warehouse.dir", "C:\\study\\sparktest")
.getOrCreate()
// Load the data stored in LIBSVM format as a DataFrame.
val dataset=spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
// Split the data into training and test sets (30% held out for testing)
val Array(tranningData,testData)=dataset.randomSplit(Array(0.7,0.3),seed = 1234L)
// Train a NavieBayes model
val model = new NaiveBayes().fit(tranningData)
// Select example rows to display.
val predictions=model.transform(testData)
predictions.show()
// Select (prediction, true label) and compute test error
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
println(s"Test set accuracy = $accuracy")
spark.stop()
}
}
运行结果如下:
18/10/24 11:50:06 INFO SparkContext: Starting job: collectAsMap at MulticlassMetrics.scala:48
+-----+--------------------+--------------------+-----------+----------+
|label| features| rawPrediction|probability|prediction|
+-----+--------------------+--------------------+-----------+----------+
| 0.0|(692,[95,96,97,12...|[-173678.60946628...| [1.0,0.0]| 0.0|
| 0.0|(692,[98,99,100,1...|[-178107.24302988...| [1.0,0.0]| 0.0|
| 0.0|(692,[100,101,102...|[-100020.80519087...| [1.0,0.0]| 0.0|
| 0.0|(692,[124,125,126...|[-183521.85526462...| [1.0,0.0]| 0.0|
| 0.0|(692,[127,128,129...|[-183004.12461660...| [1.0,0.0]| 0.0|
| 0.0|(692,[128,129,130...|[-246722.96394714...| [1.0,0.0]| 0.0|
| 0.0|(692,[152,153,154...|[-208696.01108598...| [1.0,0.0]| 0.0|
| 0.0|(692,[153,154,155...|[-261509.59951302...| [1.0,0.0]| 0.0|
| 0.0|(692,[154,155,156...|[-217654.71748256...| [1.0,0.0]| 0.0|
| 0.0|(692,[181,182,183...|[-155287.07585335...| [1.0,0.0]| 0.0|
| 1.0|(692,[99,100,101,...|[-145981.83877498...| [0.0,1.0]| 1.0|
| 1.0|(692,[100,101,102...|[-147685.13694275...| [0.0,1.0]| 1.0|
| 1.0|(692,[123,124,125...|[-139521.98499849...| [0.0,1.0]| 1.0|
| 1.0|(692,[124,125,126...|[-129375.46702012...| [0.0,1.0]| 1.0|
| 1.0|(692,[126,127,128...|[-145809.08230799...| [0.0,1.0]| 1.0|
| 1.0|(692,[127,128,129...|[-132670.15737290...| [0.0,1.0]| 1.0|
| 1.0|(692,[128,129,130...|[-100206.72054749...| [0.0,1.0]| 1.0|
| 1.0|(692,[129,130,131...|[-129639.09694930...| [0.0,1.0]| 1.0|
| 1.0|(692,[129,130,131...|[-143628.65574273...| [0.0,1.0]| 1.0|
| 1.0|(692,[129,130,131...|[-129238.74023248...| [0.0,1.0]| 1.0|
+-----+--------------------+--------------------+-----------+----------+
only showing top 20 rows
18/10/24 11:50:06 INFO DAGScheduler: Job 6 finished: countByValue at MulticlassMetrics.scala:42, took 0.157446 s
Test set accuracy = 1.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号