处理器管理与进程管理
1.用图文描述组成进程的要素,并说明其作用。
一般来说Linux系统中的进程都具备下列诸要素:
(1)有一段程序供其执行。
(2)有进程专用的系统堆栈空间。
(3)在内核有task_struct数据结构。
(4)有独立的存储空间,拥有专有的用户空间。
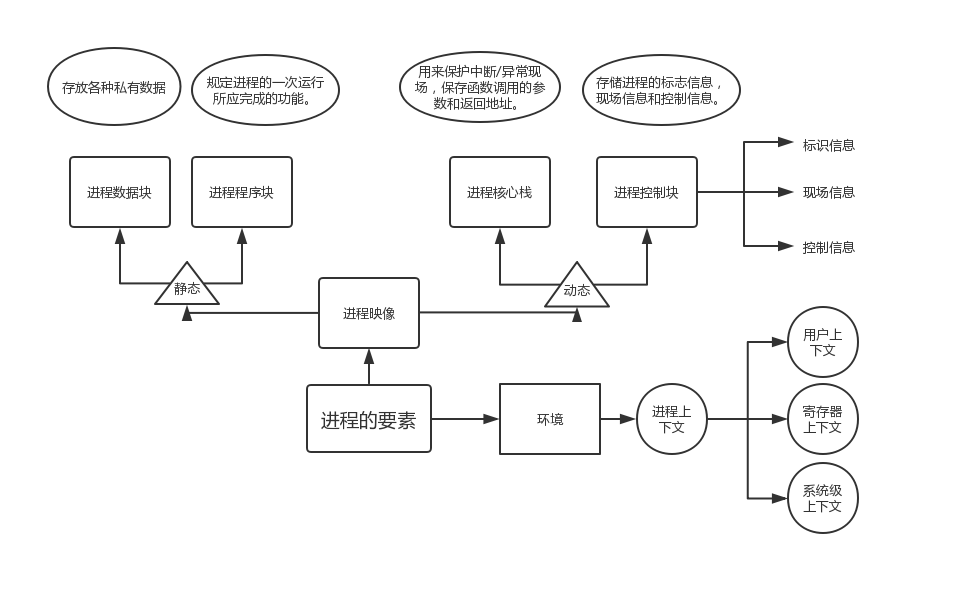
如果只具备前面三条而缺第四条,那就称为“线程”。如果完全没有用户空间,就称为“内核线程”;而如果共享用户空间则就称为“用户线程”。
Linux系统运行时,第一个进程是在初始化阶段“捏造”出来的(init_task)。而此后的进程或线程都是由一个已经存在的进程像细胞分裂那样通过系统调用复制出来的。成为“fork”(分叉)或“clone”(克隆)。
内核为每个进程分配一个task_struct结构时,实际分配两个连续的物理页面(共8192字节)。这两个页面的底部用作进程的task_struct结构,而在结构的上面就用作进程的系统空间堆栈。数据结构task_struct的大小约1K字节,进程的系统空间堆栈的大小约为7K字节(不能扩展,是静态确定的)。
task_struct 中重要的几个成员:
volatile long state; //表示进程当前的运行状态。
状态TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE均表示进程处于睡眠状态。TASK_UNINTERRUPTIBLE表示进程处于“深度睡眠”而不受“信号”的打扰。深度睡眠一般只用于临界区和关键性的部位。当进程在“阻塞性”(blocking)的系统调用中等待某一件事件发生时,应该进入“可中断”睡眠而不应深度睡眠。
TASK_RUNNING状态表示这个进程可以被调度执行而成为当前进程。当进程处于这样可执行(或就绪)的状态时,内核就会将该进程的task_struct结构通过其队列头run_list挂入一个“运行队列”。
TASK_STOPPED主要用于调试目的。进程接收到一个SIGSTOP信号后就将运行状态改成TASK_STOPPED而进入“挂起”状态,然后在接收到一个SIGCONT信号时又恢复继续运行。
每个进程都不是独立地存在于系统中,是要按不同的目的和性质将每个进程纳入不同的组织中。
第一个组织,是由每个进程“家庭与社会关系”形成的“家谱”。通过p_opptr、p_pptr指向父进程的task_struct数据结构;p_cptr指向最年轻的子进程,而p_ysptr和p_osptr则分别指向其“哥哥”和“弟弟”,从而形成一个子进程链。
第二个组织,一个以杂凑表为基础的进程队列的阵列。当给定一个pid要找到该进程时,先对pid实行杂凑计算,以计算结果为下标在杂凑表中找到一个队列,再顺着该队列就可以较轻松的找到特定的进程。
2.用图文描述什么是进程切换,为什么进行进程切换,进程切换的步骤?
2.用图文描述什么是进程切换,为什么进行进程切换,进程切换的步骤?
进程切换就是从正在运行的进程中收回处理器,然后再使待运行进程来占用处理器;
进程切换是当今多任务多用户操作系统所应具有的基本功能;
进程切换:
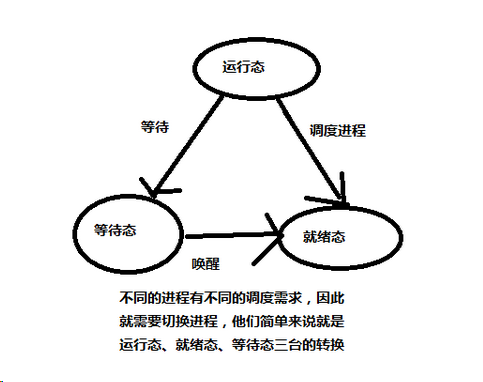
3.用图文描述模式转换、进程切换、进程状态转换三者之间的关系?
4.python练习:
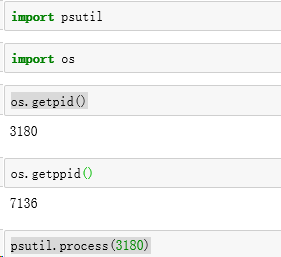
观察父进程、子进程:
os.getpid()
os.getppid()
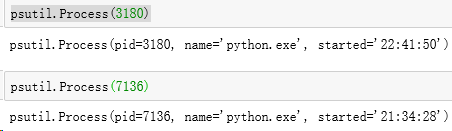
观察进程运行状态:
psutil.Process(3180)
psutil.Process(7136)
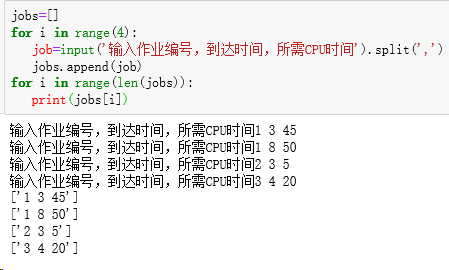
输入多个作业的作业编号,到达时间,所需CPU时间,形成列表,以备算法使用:
jobs=[]
for i in
range(4):
job =input('输入作业编号,到达时间,所需CPU时间').split(',')
jobs.append(job)
for i in
range(len(jobs)):
print(jobs[i])