
mahout入门实例2-Mahout单机开发环境介绍(参考粉丝日志)
原文链接:http://blog.fens.me/hadoop-mahout-maven-eclipse/#gsc.tab=0,在此非常感谢作者的详细解读
本文与前面一篇http://www.cnblogs.com/abc123456789/p/3504853.html
是同一时间完成的,可能有些东西是相互引用的,因此如果有些写的不够明白的,可以参考这篇。
下面进入操作环节。
步骤:
1) 使用maven创建一个标准的java项目
同样有两种方法:一种是命令行敲命令新建项目,一种是在eclipse可视化创建,各有好处,命令行命令:
mvn archetype:generate -DarchetypeGroupId=org.apache.maven.archetypes
-DgroupId=org.conan.mymahout -DartifactId=myMahout -DpackageName=org.conan.mymahout -Dversion=1.0-SNAPSHOT -DinteractiveMode=false
下面主要以eclipse下为例:
点击New – Other – Maven Project,如下图

Next后出现如下图,可以随便选个

点击next,如下图输入

点击finish,结果报错如下图(后记:在学校里整个新建项目过程一点问题都没有,下面出现的各种问题都是因为在公司某些文件下载不下来导致,如果这里创建没有问题请直接跳到步骤2)。)

从控制台可以看出问题是下载不了该模板。
解决方案:
下载模板包,去
http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/maven/archetypes/maven-archetype-quickstart/下载最新版(如maven-archetype-quickstart-1.1.jar),然后在cmd窗口执行mvn install:install-file -DgroupId=org.apache.maven.archetypes -DartifactId=maven-archetype-quickstart -Dversion=1.1 -Dpackaging=jar -Dfile=maven-archetype-quickstart-1.1.jar(换成所在的路径),如下图所示

同样需要到http://search.maven.org下载maven-install-plugin并使用mvn install安装。
重启eclipse,再次创建结果又报错could not calculate build plan, 如下图

在这个问题上折腾了一天后,终于发现问题还是缺少依赖包,到http://search.maven.org下载maven-resources-plugin-2.5.jar,执行mvn install命令,如下

然后右键项目,选择Maven – Update Project,发现进度有所前进,同样又报错

重复上面操作下载maven-jar-plugin并安装。
再次新建maven project终于成功。里面的porn.xml可能会有错,基本都是上面的错误(可以在maven的本地库目录(如我的是D:/maven-dependencies)下查找.lastUpdate文件,这些都是未下载成功的,删除这些文件同时一一下载更新,如下图)。
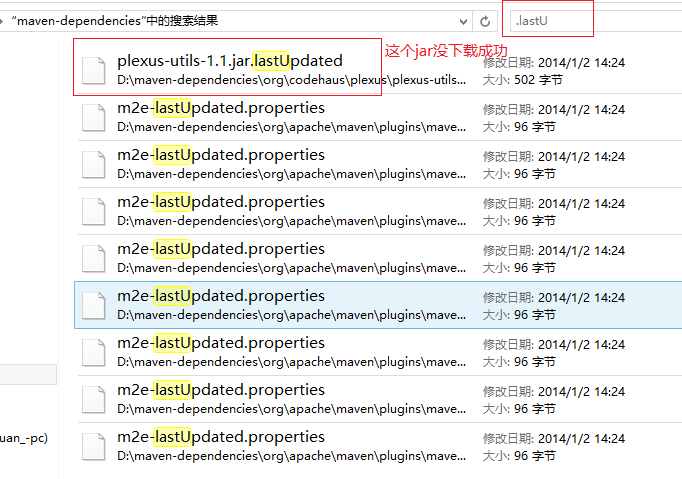
Eclipse中创建项目结束后,进入项目文件夹执行mvn clean install,效果如下

刷新eclipse项目,发现porn.xml文件有错,项目目录如下

下面修改pom.xml文件,首先安装plexus-utils-1.1.jar,但是接下来总是报如下错误

上网查了一通,终于发现一个管用的

(后记:这里不再补充,因为从后来的使用中这些奇怪的问题基本都是因为依赖包未正确下载成功,由于要手动安装的包太多,准备配置goagent代理,结果坑爹的始终失败,只好作罢。在学校里一切顺利未遇上以上问题,所以不再细究。直接将maven的本地库复制过去就行)
2) eclipse新建一个maven project后,项目效果应该如下(在学校里直接新建成功后的效果,接上面后记的说明)

修改下pom.xml,内容如下
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>test</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<mahout.version>0.8</mahout.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>${mahout.version}</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>${mahout.version}</version>
<exclusions>
<exclusion>
<groupId>org.mortbay.jetty</groupId>
<artifactId>jetty</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.cassandra</groupId>
<artifactId>cassandra-all</artifactId>
</exclusion>
<exclusion>
<groupId>me.prettyprint</groupId>
<artifactId>hector-core</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
</project>
效果如下
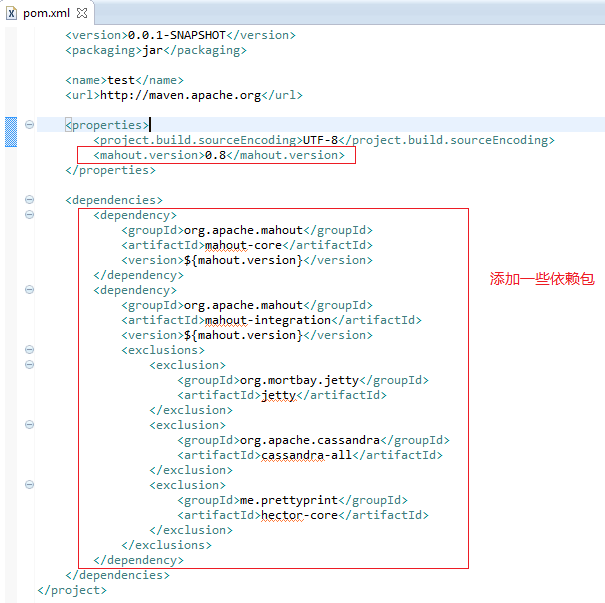
然后cmd进入该项目执行mvn clean install后项目正常如下图

(下面这段关于协同过滤的介绍来自https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/)
什么是协同过滤(Collaborative Filtering)
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
协同过滤一般是在海量的用户中发掘出一小部分和你品位比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成一个排序的目录作为推荐给你。当然其中有一个核心的问题:
- 如何确定一个用户是不是和你有相似的品位?
- 如何将邻居们的喜好组织成一个排序的目录?
协同过滤相对于集体智慧而言,它从一定程度上保留了个体的特征,就是你的品位偏好,所以它更多可以作为个性化推荐的算法思想。可以想象,这种推荐策略在 Web 2.0 的长尾中是很重要的,将大众流行的东西推荐给长尾中的人怎么可能得到好的效果,这也回到推荐系统的一个核心问题:了解你的用户,然后才能给出更好的推荐。
深入协同过滤的核心
前面作为背景知识,介绍了集体智慧和协同过滤的基本思想,这一节我们将深入分析协同过滤的原理,介绍基于协同过滤思想的多种推荐机制,优缺点和实用场景。
首先,要实现协同过滤,需要一下几个步骤
- 收集用户偏好
- 找到相似的用户或物品
- 计算推荐
收集用户偏好
要从用户的行为和偏好中发现规律,并基于此给予推荐,如何收集用户的偏好信息成为系统推荐效果最基础的决定因素。用户有很多方式向系统提供自己的偏好信息,而且不同的应用也可能大不相同,下面举例进行介绍:
表 1 用户行为和用户偏好
| 用户行为 | 类型 | 特征 | 作用 |
|---|---|---|---|
| 评分 | 显式 | 整数量化的偏好,可能的取值是 [0, n];n 一般取值为 5 或者是 10 | 通过用户对物品的评分,可以精确的得到用户的偏好 |
| 投票 | 显式 | 布尔量化的偏好,取值是 0 或 1 | 通过用户对物品的投票,可以较精确的得到用户的偏好 |
| 转发 | 显式 | 布尔量化的偏好,取值是 0 或 1 | 通过用户对物品的投票,可以精确的得到用户的偏好。 如果是站内,同时可以推理得到被转发人的偏好(不精确) |
| 保存书签 | 显示 | 布尔量化的偏好,取值是 0 或 1 | 通过用户对物品的投票,可以精确的得到用户的偏好。 |
| 标记标签 (Tag) |
显示 | 一些单词,需要对单词进行分析,得到偏好 | 通过分析用户的标签,可以得到用户对项目的理解,同时可以分析出用户的情感:喜欢还是讨厌 |
| 评论 | 显示 | 一段文字,需要进行文本分析,得到偏好 | 通过分析用户的评论,可以得到用户的情感:喜欢还是讨厌 |
| 点击流 ( 查看 ) |
隐式 | 一组用户的点击,用户对物品感兴趣,需要进行分析,得到偏好 | 用户的点击一定程度上反映了用户的注意力,所以它也可以从一定程度上反映用户的喜好。 |
| 页面停留时间 | 隐式 | 一组时间信息,噪音大,需要进行去噪,分析,得到偏好 | 用户的页面停留时间一定程度上反映了用户的注意力和喜好,但噪音偏大,不好利用。 |
| 购买 | 隐式 | 布尔量化的偏好,取值是 0 或 1 | 用户的购买是很明确的说明这个项目它感兴趣。 |
以上列举的用户行为都是比较通用的,推荐引擎设计人员可以根据自己应用的特点添加特殊的用户行为,并用他们表示用户对物品的喜好。
在一般应用中,我们提取的用户行为一般都多于一种,关于如何组合这些不同的用户行为,基本上有以下两种方式:
- 将不同的行为分组:一般可以分为“查看”和“购买”等等,然后基于不同的行为,计算不同的用户 / 物品相似度。类似于当当网或者 Amazon 给出的“购买了该图书的人还购买了 ...”,“查看了图书的人还查看了 ...”
- 根据不同行为反映用户喜好的程度将它们进行加权,得到用户对于物品的总体喜好。一般来说,显式的用户反馈比隐式的权值大,但比较稀疏,毕竟进行显示反馈的用户是少数;同时相对于“查看”,“购买”行为反映用户喜好的程度更大,但这也因应用而异。
收集了用户行为数据,我们还需要对数据进行一定的预处理,其中最核心的工作就是:减噪和归一化。
- 减噪:用户行为数据是用户在使用应用过程中产生的,它可能存在大量的噪音和用户的误操作,我们可以通过经典的数据挖掘算法过滤掉行为数据中的噪音,这样可以是我们的分析更加精确。
- 归一化:如前面讲到的,在计算用户对物品的喜好程度时,可能需要对不同的行为数据进行加权。但可以想象,不同行为的数据取值可能相差很大,比如,用户的查看数据必然比购买数据大的多,如何将各个行为的数据统一在一个相同的取值范围中,从而使得加权求和得到的总体喜好更加精确,就需要我们进行归一化处理。最简单的归一化处理,就是将各类数据除以此类中的最大值,以保证归一化后的数据取值在 [0,1] 范围中。
进行的预处理后,根据不同应用的行为分析方法,可以选择分组或者加权处理,之后我们可以得到一个用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,值是用户对物品的偏好,一般是 [0,1] 或者 [-1, 1] 的浮点数值。
我们可以根据用户喜好计算相似用户和物品,然后基于相似用户或者物品进行推荐,这就是最典型的 CF 的两个分支:基于用户的 CF 和基于物品的 CF。
(上面这段关于协同过滤的介绍来自https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/)
下面首先实现协同过滤userCF(基于用户的 CF)
新建一个item.csv(这里的数据就是减噪和归一化处理后得到的数据),保存数据如下
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
数据解释:每一行有三列,第一列是用户ID,第二列是物品ID,第三列是用户对物品的打分。
接下来再修改下App.java文件,内容如下

然后运行该java程序结果如下
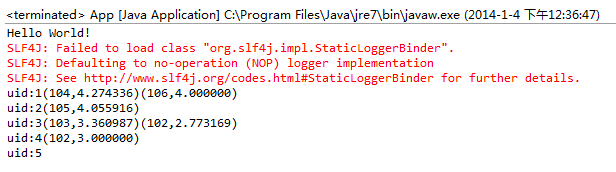
推荐结果解读
向用户ID1,推荐前二个最相关的物品, 104和106
向用户ID2,推荐前二个最相关的物品, 但只有一个105
向用户ID3,推荐前二个最相关的物品, 103和102
向用户ID4,推荐前二个最相关的物品, 但只有一个102
向用户ID5,推荐前二个最相关的物品, 没有符合的
2.用Mahout实现kmeans
新建数据文件randomData.csv(我是直接复制他的了,因为之前原文中提供的数据总是有问题,干脆直接拷贝了他的randomData.csv文件)
同时拷贝下原文源码里的MathUtil.java文件。
同时还需要修改pom.xml里的mahout.version为0.6,然后mvn clean install。
接下来添加一个Kmeans.java内容,作为主程序,内容如下
最终项目目录结构如下

运行Kmeans.java文件,结果如下

mahout结果解读
1. Init Point center表示,kmeans算法初始时的设置的3个中心点
2. Cluster center表示,聚类后找到3个中心点
结果不够直观,接下来用R语言实现kmeans算法(请先阅读本文最后的R语言入门教程)。
在R语言命令行运行如下命令
> y<-read.csv(file="randomData.csv",sep=",",header=FALSE)
> cl<-kmeans(y,3,iter.max = 10, nstart = 25)
> cl$centers
V1 V2
1 -0.4323971 2.2852949
2 0.9023786 -0.7011153
3 4.3725463 2.4622609
# 生成聚类中心的图形
> plot(y, col=c("black","blue","green")[cl$cluster])
> points(cl$centers, col="red", pch = 19)
# 画出Mahout聚类的中心
> mahout<-matrix(c(-2.686856800552941,1.8939462954763795,0.6334255423230666,0.49472852972602105,3.334520309711998,3.2758355898247653),ncol=2,byrow=TRUE)
> points(mahout, col="violetred", pch = 19)
截图如下

执行结果如下

比较Mahout和R的结果
从上图中,我们看到有 黑,蓝,绿,三种颜色的空心点,这些点就是原始的数据。
3个红色实点,是R语言kmeans后生成的3个中心。
3个紫色实点,是Mahout的kmeans后生成的3个中心。
R语言和Mahout生成的点,并不是重合的,原因有几点:
1. 距离算法不一样:
Mahout中,我们用的 “欧氏距离(EuclideanDistanceMeasure)”
R语言中,默认是”Hartigan and Wong”
2. 初始化的中心是不一样的。
3. 最大迭代次数是不一样的。
4. 点合并时,判断的”阈值(threshold)”是不一样的。
- R语言入门教程
R语言是一门统计编程语言。
从CRAN(The Comprehensive R Archive Network)cran.r-project.org—mirrors.html中选择一个镜像,然后下载合适的安装包(R支持Linux、Mac OS X和Windows)。
安装并运行R后,可以看到R的控制台(我的是windows7)

最后:cnblogs似乎不能添加附件啊,如果有需要的话请留言
Mahout推荐算法总结(摘自:http://blog.fens.me/mahout-recommendation-api/#gsc.tab=0)
算法及适用场景:
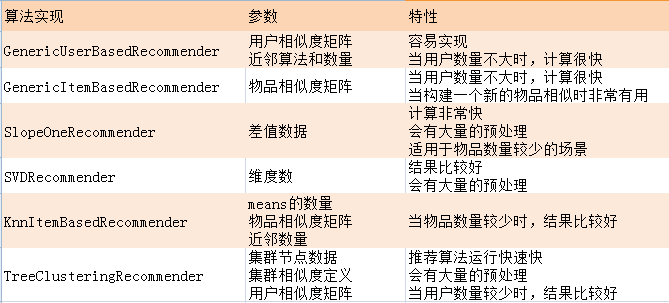
算法评分的结果:

通过对上面几种算法的一平分比较:itemCF,itemKNN,SVD的Rrecision,Recall的评分值是最好的,并且itemCF和SVD的AVERAGE_ABSOLUTE_DIFFERENCE是最低的,所以,从算法的角度知道了,哪个算法是更准确的或者会索引到更多的数据集。
另外的一些因素:
- 1. 这3个指标,并不能直接决定计算结果一定itemCF,SVD好
- 2. 各种算法的参数我们并没有调优
- 3. 数据量和数据分布,是影响算法的评分
补充(一段时间之后):
今天在导入之前的mahout项目到别的机器时,结果java文件有一堆红叉,很明显可以判断是某些jar包没加载进来,开始就很纳闷,项目是用maven来管理依赖包的,maven的路径,本地库都检查了,不应该还要手动再进行build path进行导入的啊(maven存在的理由),折腾了一会发现问题了,原来我在eclipse中import项目时习惯是使用java existing project,但这里应该是existing maven project,于是重新导入,没有报错,结果ok

