基于简单模糊测试框架的需求分析与建模
0. 前言
本文针对于作者参与的一个小课题“基于机器学习的模糊测试框架的分析和改进“进行简要分析,以构建用例模型、业务模型、数据模型和形成概念模型的方式,用以对所做工作有清晰的认识
1. 用例(use case)图
1.1 什么是用例图
用例图用来描述用例与参与者之间的关系。用例图包含了谁是系统的参与者,系统需要提供什么样的服务。用例(Use Case)的核心概念中首先它是一个业务过程(business process),经过逻辑整理抽象出来的一个业务过程,这是用例的实质。什么是业务过程?在待开发软件所处的业务领域内完成特定业务任务(business task)的一系列活动就是业务过程。
1.2 用例的几个要素
A use case is initiated by (or begins with) an actor. 一个用例应该由业务领域内的某个参与者(Actor)所触发。
A use case must accomplish a business task (for the actor).用例必须能为特定的参与者完成一个特定的业务任务。
A use case must end with an actor. 一个用例必须终止于某个特定参与者,也就是特定参与者明确地或者隐含地得到了业务任务完成的结果。
1.3 用例建模步骤
第一步,从需求表述中找出用例,往往是动名词短语表示的抽象用例;
第二步,描述用例开始和结束的状态,用TUCBW和TUCEW表示的高层用例;
第三步,对用例按照子系统或不同的方面进行分类,描述用例与用例、用例与参与者之间的上下文关系,并画出用例图;
第四步,进一步逐一分析用例与参与者的详细交互过程,完成一个两列的表格将参与者和待开发软件系统之间从用例开始到用例结束的所有交互步骤都列举出来扩展用例。
其中第一步到第三步是计划阶段,第四步是增量实现阶段。
1.4 需求分析
由于所做的是安全相关的模糊测试工作,模糊测试工作包括
输入-> 解析(Parse) -> 处理(Process) -> 数据组装(Reassemble) -> 输出
不同于平常的应用,课题工作更专注于与代码和数据打交道。有别于平常应用的用户-服务提供者的一般模式。
第一部分是针对某一特定的软件,编写特定的Harness。Harness 是一个小程序,可以触发我们想要模糊测试的功能。Harness 中包含将要作为目标函数的函数。
第二部分是用这个harness小程序对特定的target进行测试,获得导致程序崩溃的测试用例。也就是说搭建起针对特定target的fuzzing
1.5 用例分析
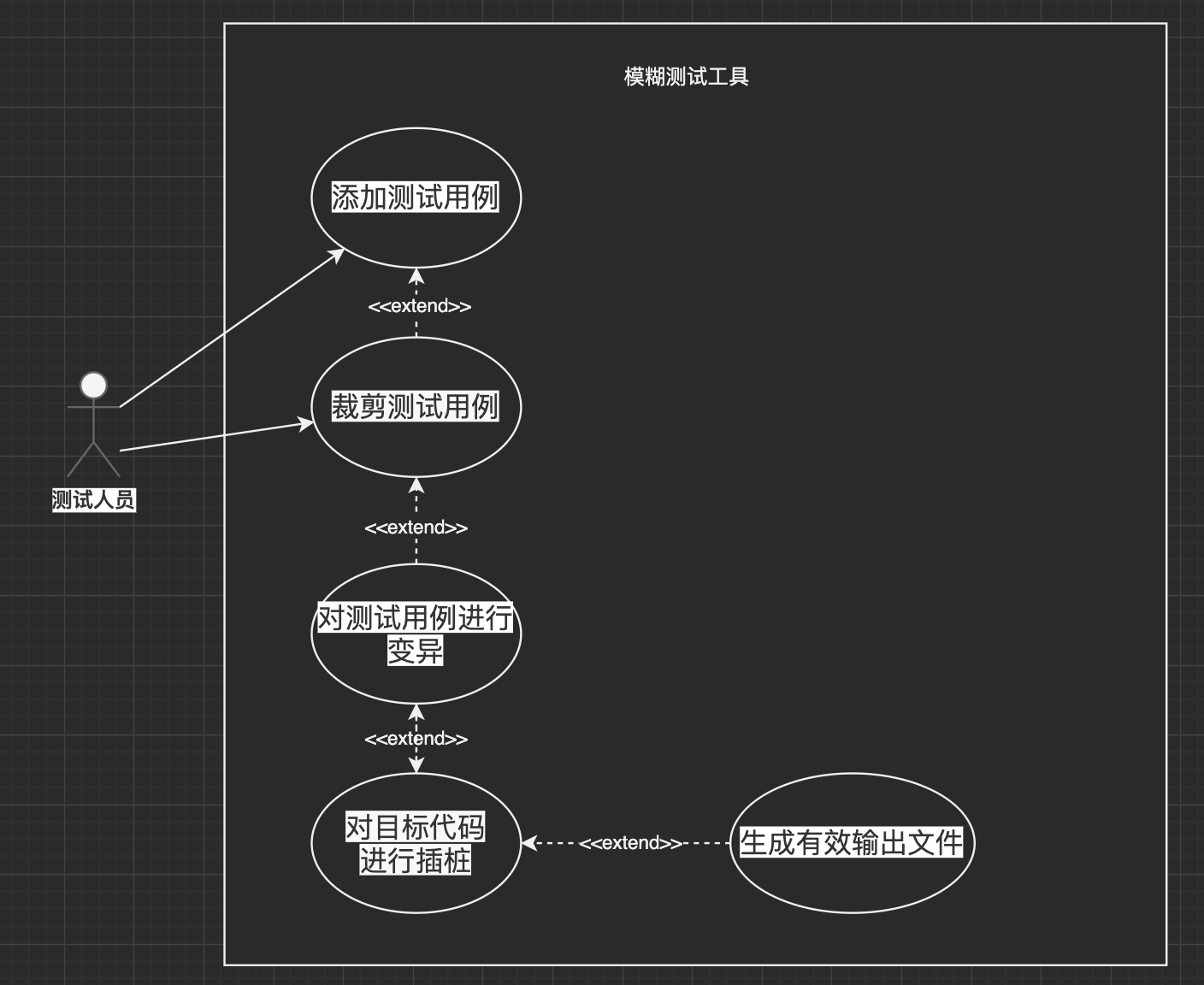
Actor:测试人员
Use Case:添加测试用例、裁剪测试用例、对测试用例进行变异、对程序进行插桩、生成有效输出文件
高层用例
描述用例开始和和结束
| 用例 | TUCBW | TUCEW |
|---|---|---|
| 添加测试用例 | 用户启动程序 | 测试用例加入队列 |
| 裁剪测试用例 | 测试用例加载到队列前 | 得到精简后的测试文件 |
| 对测试用例进行变异 | fuzzing之前 | 生成变异后的输入 |
| 对程序进行插桩 | 遇到代码分支 | 得到源码覆盖率 |
| 生成有效输出文件 | 程序崩溃时候记录 | 得到触发crash的测试用例 |
画出用例图
2. 业务领域建模(Domain Modeling)
2.1 基本步骤
- 第一步,收集应用业务领域的信息。聚焦在功能需求层面,也考虑其他类型的需求和资料;
- 第二步,头脑风暴。列出重要的应用业务领域概念,给出这些概念的属性,以及这些概念之间的关系;
- 第三步,给这些应用业务领域概念分类。分别列出哪些是类、哪些属性和属性值、以及列出类之间的继承关系、聚合关系和关联关系。
- 第四步,将结果用 UML 类图画出来。
2.2 系统中包含的结构
我们没有显示的类,但我们仍然可以尝试为我们的一些数据结构变量画图
queue_entry:
属性:名称,长度,校验和,得分
方法:给testcase打分,获取队列对象,将测试用例加入队列,修剪队列
afl-state:
属性:测试进行的阶段state,输入队列,当前队列,用户提供的测试用例
方法:初始化参数,fork子进程,运行测试,种子变异,修剪所有测试用例,保存有效输出文件
extra_data:
属性:输入buff,长度
方法:添加,加载
share_mem:
属性:id,map,大小
方法:初始化,获取

数据模型
输入队列
| 字段 | 类型 | 描述 |
|---|---|---|
| name | string | 输入队列的名称,可有可无 |
| len | int | 队列长度 |
| testcase-buff | *String | 输入文件的流 |
| perf_score | double | testcase得分 |
extra_data
| 字段 | 类型 | 描述 |
|---|---|---|
| data | *string | 用户提供的测试字典集 |
| len | int | 长度 |
share_mem
| M字段 | 类型 | 描述 |
|---|---|---|
| id | int | 共享内存结构的id |
| map | *int | 共享内存指针 |
| Map_size | int | 共享内存大小 |
afl-state
| 字段 | 类型 | 描述 |
|---|---|---|
| state | int | 测试进行到哪个阶段 |
| q | *queue_entry | 输入队列 |
| q_cur | *queue_entry | 当前的执行队列 |
| extra_data | *extra_data | 用户提供的字典集 |
| shmem | share_mem | 共享内存 |
概念原型
经过以上几个步骤,总结我们的概念原型
来看一下我们工作的主要步骤
1)将用户提供的初始测试用例加载到队列中,
2)从队列中获取下一个输入文件,
3)尝试将测试用例修剪到不会改变程序测量行为的最小尺寸,
4)使用平衡且经过充分研究的各种传统模糊测试策略反复改变文件,
5)如果任何生成的编译导致由instrumentation记录的新状态转换,则将变异输出添加为队列中的新条目。
6) 重复2,直到测试人员按下ctr+z

总结
对一个工程来讲,明确的高效的需求分析是十分重要的,只有明确的需求分析,才能为我们程序的编写提供正确方向,才能对系统建模起到帮助作用。
而系统建模,是我们从需求分析到设计对象的过程,良好的系统建模能帮助我们更快速明确的开发,同时能更好的统一开发人员的认知。
需求的建模包括用例建模、业务领域建模、数据建模等,各自职能不同,粒度由大到小。
基于已得出的用例和数据模型,就可以得出概念原型的工作过程。更好的理解我们的项目,更好的去开发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号