数据采集第三次作业
作业Gitee链接:作业3
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息:
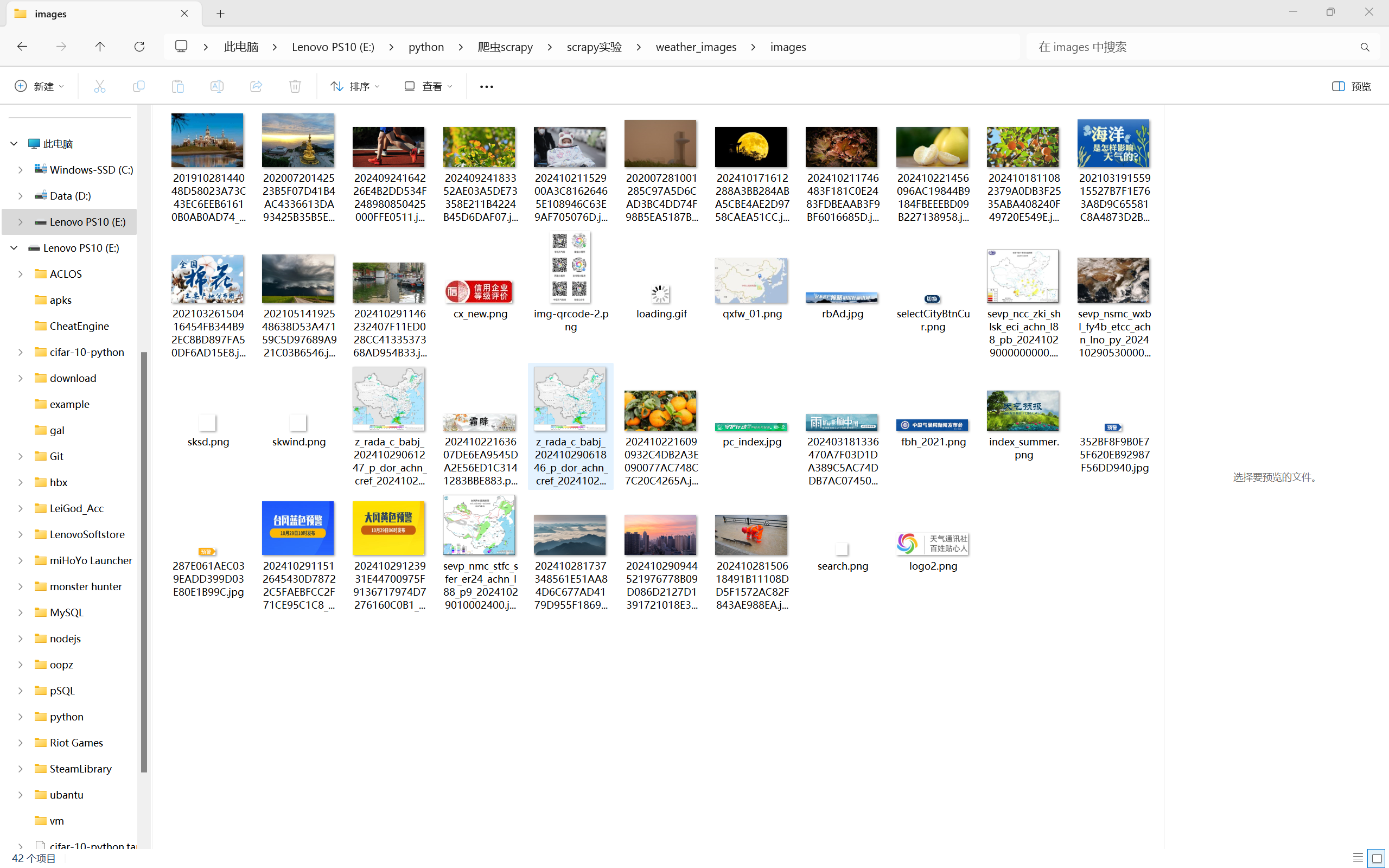
实现代码:
weather_spider.py:
点击查看代码
import scrapy
from scrapy.pipelines.images import ImagesPipeline
class WeatherSpider(scrapy.Spider):
name = "weather_spider"
start_urls = ["http://www.weather.com.cn"]
page_count = 0 # 页数计数器
max_pages = 27 # 最大页数
def parse(self, response):
if self.page_count < self.max_pages:
# 提取图片链接
image_urls = response.css("img::attr(src)").getall()
# 输出图片 URL
for img_url in image_urls:
self.log(img_url)
# 生成完整的 URL 并返回
yield from response.follow_all(image_urls, self.save_images)
# 增加页数计数器
self.page_count += 1
# 查找下一页的链接并继续爬取
next_page = response.css("a.next::attr(href)").get() # 更新选择器
if next_page:
yield response.follow(next_page, self.parse)
def save_images(self, response):
# 保存图片
self.log(f"Downloading image: {response.url}")
yield {
'image_urls': [response.url],
}
piplines.py:
点击查看代码
class WeatherImagesPipeline:
def process_item(self, item, spider):
return item
from scrapy.pipelines.images import ImagesPipeline
class WeatherImagesPipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
return request.url.split("/")[-1] # 保持图片原始文件名
单线程与多线程的转换:
点击查看代码
CONCURRENT_REQUESTS = 1 # 单线程
CONCURRENT_REQUESTS = 16 # 多线程
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:

实现代码:
stock_spider.py:
点击查看代码
import scrapy
import json
class StocksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
latestprice = scrapy.Field()
change_amount = scrapy.Field()
Rise_and_fall = scrapy.Field()
trading_volume = scrapy.Field()
turnover_value = scrapy.Field()
amplitude = scrapy.Field() # 振幅
max = scrapy.Field()
min = scrapy.Field()
open_today = scrapy.Field()
received_yesterday = scrapy.Field()
pass
class StocksSpider(scrapy.Spider):
name = "stock_spider"
start_urls = [
"http://65.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124008516432775777205_1697696898159&pn=1&pz=100&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1697696898163"
]
def parse(self, response):
data = self.parse_json(response.text)
data_values = data['data']['diff']
items = self.parse_data_values(data_values)
yield from items
def parse_json(self, jsonp_response):
json_str = jsonp_response[len("jQuery1124008516432775777205_1697696898159("):len(jsonp_response) - 2]
return json.loads(json_str)
def parse_data_values(self, data_values):
return [StocksItem(
code=data_value['f12'],
name=data_value['f14'],
latestprice=data_value['f2'],
change_amount=data_value['f4'],
Rise_and_fall=data_value['f3'],
trading_volume=data_value['f5'],
turnover_value=data_value['f5'],
amplitude=data_value['f7'],
max=data_value['f15'],
min=data_value['f16'],
open_today=data_value['f17'],
received_yesterday=data_value['f18']
) for data_value in data_values]
piplines.py:
点击查看代码
from itemadapter import ItemAdapter
import pymysql
class StocksPipeline:
def open_spider(self, spider):
self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='350102', charset='utf8')
self.conn.autocommit(True)
with self.conn.cursor() as cursor:
cursor.execute('CREATE DATABASE IF NOT EXISTS stocks')
cursor.execute('USE stocks')
cursor.execute("""
CREATE TABLE IF NOT EXISTS stocks (
股票代码 VARCHAR(255),
股票名称 VARCHAR(255),
最新报价 VARCHAR(255),
涨跌幅 VARCHAR(255),
涨跌额 VARCHAR(255),
成交量 VARCHAR(255),
成交额 VARCHAR(255),
振幅 VARCHAR(255),
最高 VARCHAR(255),
最低 VARCHAR(255),
今开 VARCHAR(255),
昨收 VARCHAR(255)
)
""")
def process_item(self, item, spider):
sql = """
INSERT INTO stocks (股票代码, 股票名称, 最新报价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 最高, 最低, 今开, 昨收)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
data = (
item["code"], item["name"], item["latestprice"], item["change_amount"], item["Rise_and_fall"],
item["trading_volume"], item["turnover_value"], item["amplitude"], item["max"], item["min"],
item["open_today"], item["received_yesterday"]
)
with self.conn.cursor() as cursor:
try:
cursor.execute(sql, data)
except Exception as e:
print(e)
return item
def close_spider(self, spider):
self.conn.close()
print("信息已保存至数据库中")
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:
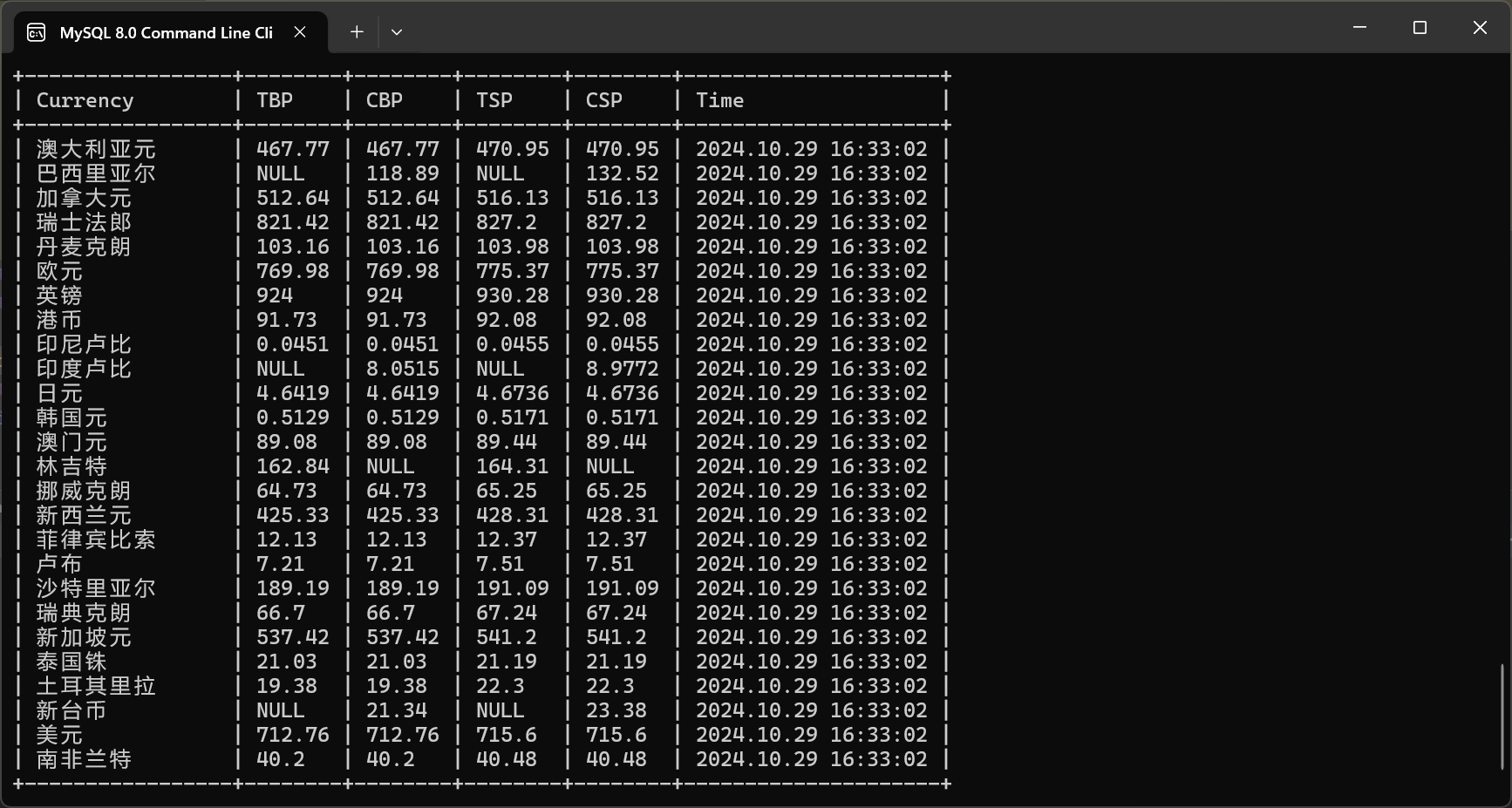
实现代码:
waihui_spider.py:
点击查看代码
import scrapy
class WaihuiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency=scrapy.Field()
TBP=scrapy.Field()
CBP=scrapy.Field()
TSP=scrapy.Field()
CSP=scrapy.Field()
Time=scrapy.Field()
class WaihuiSpider(scrapy.Spider):
name = "waihui"
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
for tr in response.xpath("//div[@class='publish']/div[2]/table//tr")[2:]:
item = WaihuiItem(
Currency=tr.xpath('./td[1]/text()').extract_first(),
TBP=tr.xpath('./td[2]/text()').extract_first(),
CBP=tr.xpath('./td[3]/text()').extract_first(),
TSP=tr.xpath('./td[4]/text()').extract_first(),
CSP=tr.xpath('./td[5]/text()').extract_first(),
Time=tr.xpath('./td[7]/text()').extract_first()
)
yield item
piplines.py:
点击查看代码
import pymysql
class WaihuiPipeline:
def __init__(self):
self.conn = None
self.cursor = None
def open_spider(self, spider):
self.conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='350102',
charset='utf8'
)
self.cursor = self.conn.cursor()
self.create_database()
self.select_database()
self.create_table()
def process_item(self, item, spider):
try:
self.cursor.execute(
'INSERT INTO waihui VALUES(%s, %s, %s, %s, %s, %s)',
(item["Currency"], item["TBP"], item["CBP"], item["TSP"], item["CSP"], item["Time"])
)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
def create_database(self):
self.cursor.execute('CREATE DATABASE IF NOT EXISTS waihui')
self.conn.commit()
def select_database(self):
self.conn.select_db('waihui')
def create_table(self):
create_table_sql = """
CREATE TABLE IF NOT EXISTS waihui (
Currency VARCHAR(255),
TBP VARCHAR(255),
CBP VARCHAR(255),
TSP VARCHAR(255),
CSP VARCHAR(255),
Time VARCHAR(255)
)
"""
self.cursor.execute(create_table_sql)
self.conn.commit()
def close_spider(self, spider):
self.conn.close()
print("信息已保存至数据库中")
心得体会:
通过这三项作业,我对 Scrapy 框架有了更深的理解,掌握了爬虫的基本构建流程,包括数据提取、存储和处理。同时,对数据库操作的熟悉度也提高了,能够将爬取的数据高效地存储并进行后续分析。整个过程增强了我的编程能力和解决实际问题的能力,尤其是在数据采集与处理领域。希望在未来的学习和项目中,能够进一步探索更复杂的爬虫逻辑和数据分析方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号