数据采集第一次作业
作业①:
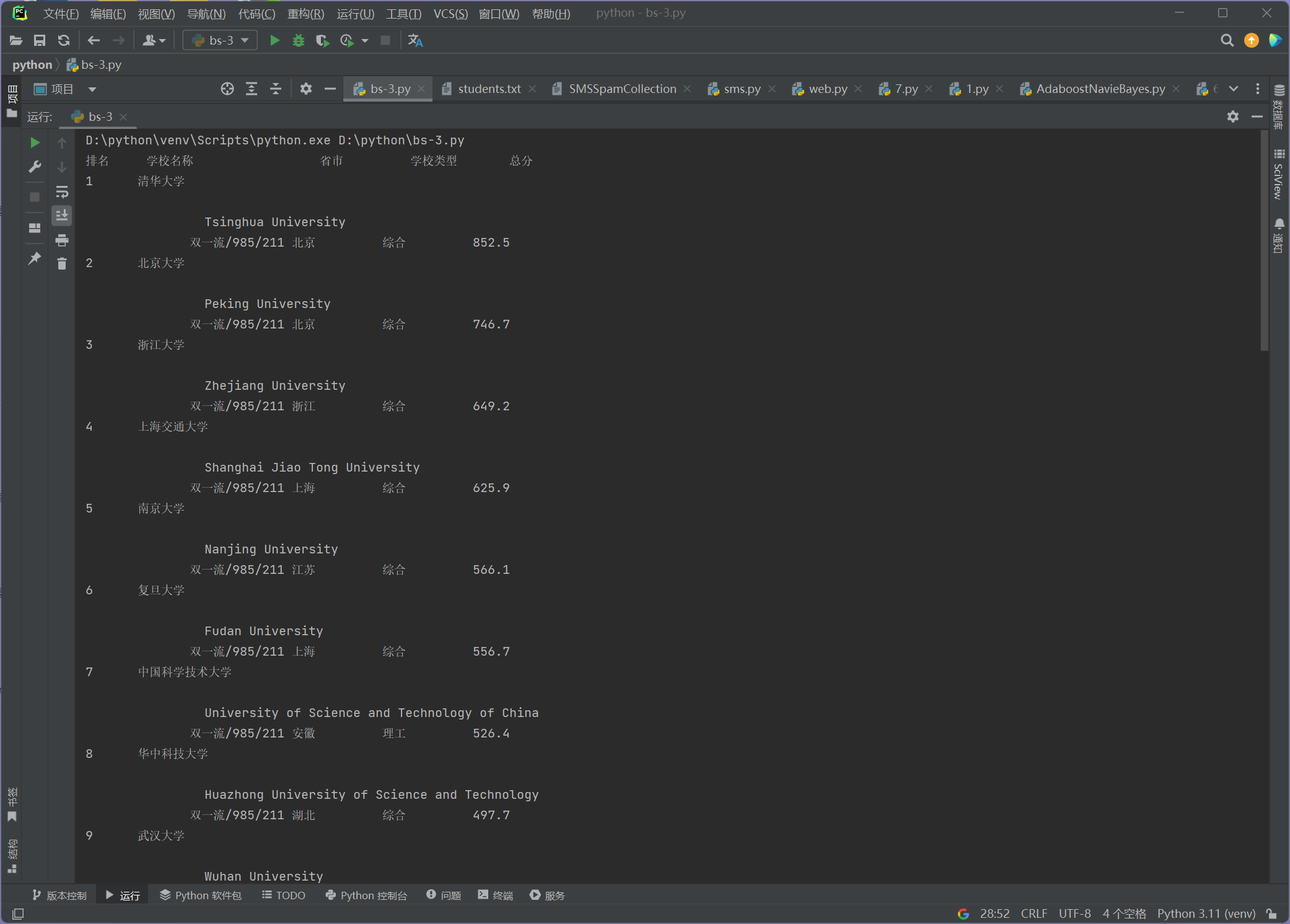
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
实现关键代码:
点击查看代码
response = urllib.request.urlopen(url)
html = response.read()
# 使用BeautifulSoup解析网页
soup = BeautifulSoup(html, 'html.parser')
# 找到包含大学排名的表格
table = soup.find('table', {'class': 'rk-table'})
# 打印表头
print(f"{'排名':<6} {'学校名称':<20} {'省市':<10} {'学校类型':<10} {'总分':<6}")
# 遍历表格中的每一行
for row in table.find('tbody').find_all('tr'):
cols = row.find_all('td')
# 提取每列数据
rank = cols[0].get_text().strip() # 排名
name = cols[1].get_text().strip() # 学校名称
province = cols[2].get_text().strip() # 省市
category = cols[3].get_text().strip() # 学校类型
score = cols[4].get_text().strip() # 总分
# 打印排名信息
print(f"{rank:<6} {name:<20} {province:<10} {category:<10} {score:<6}")
完成图片:
心得:
这个任务增强了我对网页爬虫基本流程的理解,也让我意识到网络数据的结构化与清理是数据分析中非常重要的一步。
作业②:
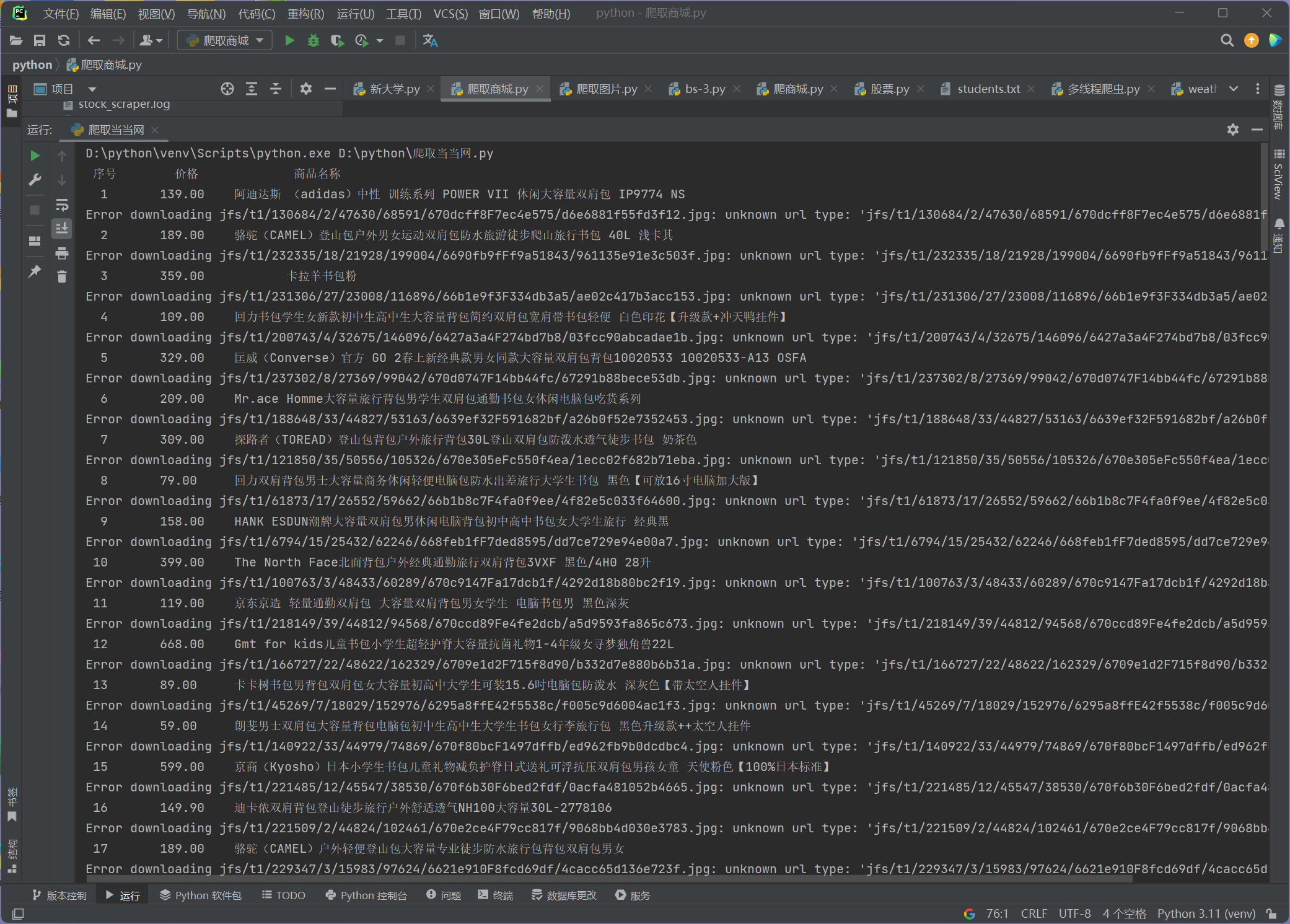
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码:
点击查看代码
def getHTMLText(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
try:
req = urllib.request.Request(url, headers=headers)
with urllib.request.urlopen(req) as response:
data = response.read().decode()
return data
except Exception as err:
print(f"Error fetching data from {url}: {err}")
return ""
def parsePage(uinfo, data):
plt = re.findall(r'"sku_price":"([\d.]+)"', data) # 商品价格
tlt = re.findall(r'"ad_title_text":"(.*?)"', data) # 商品名称
img_urls = re.findall(r'"image_url":"(.*?)"', data) # 商品图片URL
base_url = "https://img1.360buyimg.com/n6/" # 基础 URL
min_length = min(len(plt), len(tlt), len(img_urls))
for i in range(min_length):
price = plt[i].replace('"', '') # 去掉引号
name = tlt[i].strip('"') # 去掉引号
img_url = img_urls[i].replace('"', '') # 去掉引号
uinfo.append([len(uinfo) + 1, price, name, img_url]) # 添加信息到uinfo列表
return uinfo
def downloadImage(img_url, save_path):
try:
if img_url and img_url != '无图片':
urllib.request.urlretrieve(img_url, save_path)
print(f"Downloaded image to {save_path}")
else:
print(f"No image found for URL: {img_url}")
except Exception as e:
print(f"Error downloading {img_url}: {e}")
def printGoodslist(uinfo):
tplt = "{0:^5}\t{1:^10}\t{2:^20}"
print(tplt.format("序号", "价格", "商品名称"))
for item in uinfo:
print(tplt.format(item[0], item[1], item[2]))
downloadImage(item[3], os.path.join("书包", f"{item[0]}.jpg")) # Download image with index as filename
def main():
base_url = 'https://re.jd.com/search?keyword=%E4%B9%A6%E5%8C%85&enc=utf-8&page='
uinfo = []
# 循环爬取3-4页
for page in range(3, 5):
url = f"{base_url}{page}"
data = getHTMLText(url)
if data:
parsePage(uinfo, data)
printGoodslist(uinfo)
完成结果:
完成心得:
通过使用正则表达式提取商品名称和价格,让我更熟悉了如何使用 re 库进行模式匹配。这个任务让我对电商网站的爬虫策略有了更深入的理解,同时也增强了我对数据抓取中可能遇到的技术挑战的应对能力。
作业③:
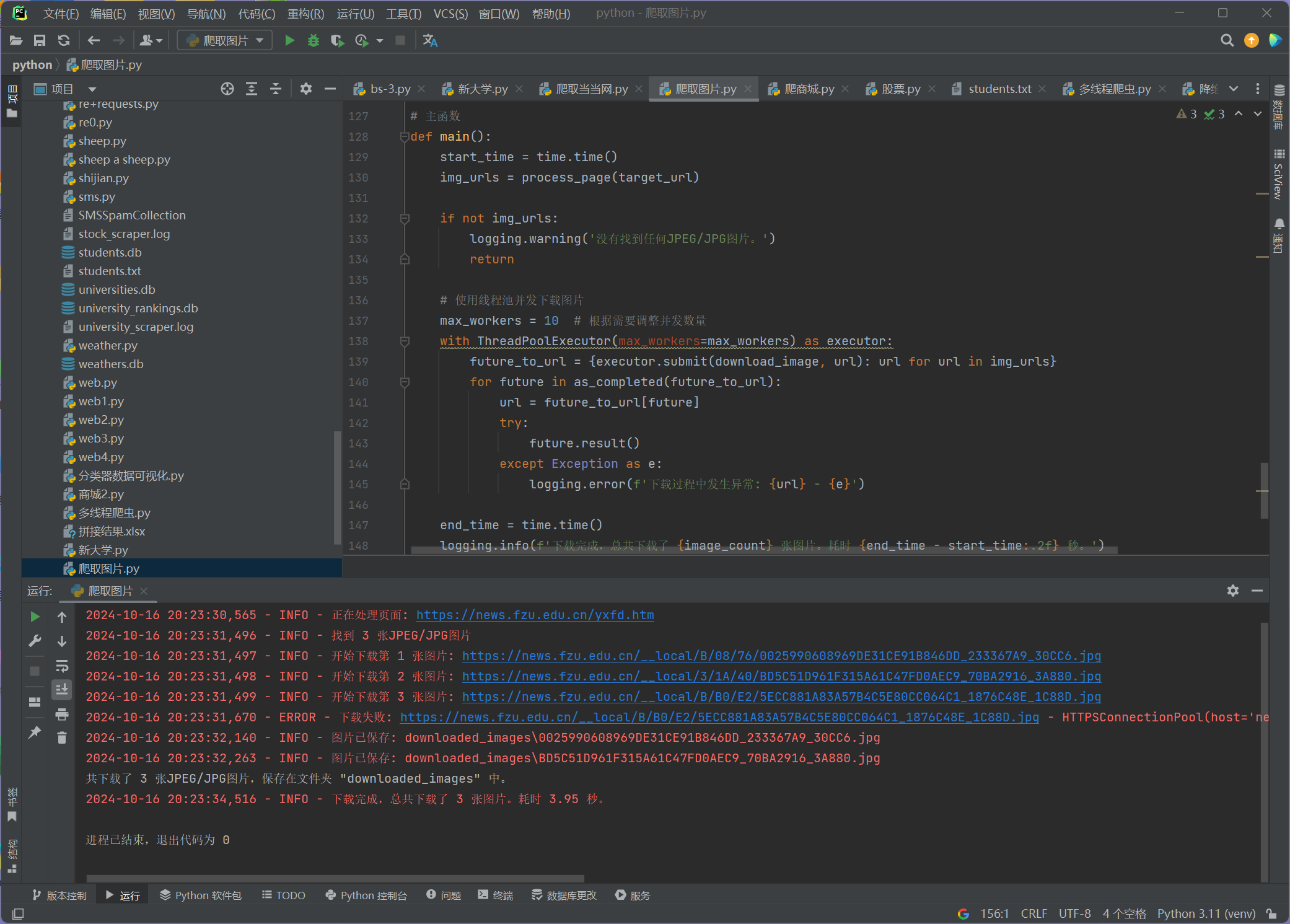
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件
完成代码:
点击查看代码
def download_image(img_url):
global image_count
with lock:
if image_count >= max_images:
return # 超过限制,直接返回
# 获取图片的文件名
parsed_url = urllib.parse.urlparse(img_url)
file_name = os.path.join(output_folder, os.path.basename(parsed_url.path))
# 检查图片是否已经下载
if img_url in downloaded_images:
logging.info(f'图片已存在,跳过下载: {file_name}')
return # 如果图片已存在,则跳过下载
# 将图片 URL 添加到已下载集合
downloaded_images.add(img_url)
image_count += 1 # 更新图片计数
logging.info(f'开始下载第 {image_count} 张图片: {img_url}')
try:
response = session.get(img_url, timeout=15)
response.raise_for_status()
with open(file_name, 'wb') as img_file:
img_file.write(response.content)
logging.info(f'图片已保存: {file_name}')
except requests.RequestException as e:
logging.error(f'下载失败: {img_url} - {e}')
finally:
# 休眠随机时间以避免被封
time.sleep(random.uniform(1, 3)) # 调整休眠时间为1到3秒
# 解析页面并提取图片URL的函数
def extract_image_urls(page_content, base_url):
soup = BeautifulSoup(page_content, 'html.parser')
img_tags = soup.find_all('img')
img_urls = []
for img in img_tags:
# 尝试从多个属性中获取图片URL
img_url = img.get('data-original') or img.get('data-src') or img.get('src') or img.get('data-lazy-img')
if img_url:
# 处理以 // 开头的URL
if img_url.startswith('//'):
img_url = 'https:' + img_url
elif img_url.startswith('/'):
img_url = urllib.parse.urljoin(base_url, img_url)
elif not img_url.startswith('http'):
img_url = urllib.parse.urljoin(base_url, img_url)
# 仅保留 JPEG 和 JPG 格式
if re.search(r'\.(jpe?g)$', img_url, re.IGNORECASE):
img_urls.append(img_url)
# 去重
img_urls = list(set(img_urls))
logging.info(f'找到 {len(img_urls)} 张JPEG/JPG图片')
return img_urls
# 处理页面的函数
def process_page(url):
logging.info(f'正在处理页面: {url}')
try:
response = session.get(url, timeout=15)
response.raise_for_status()
except requests.RequestException as e:
logging.error(f'请求失败,URL: {url} - {e}')
return []
page_content = response.text
img_urls = extract_image_urls(page_content, url)
return img_urls
完成结果:
作业心得:
这个任务让我意识到数据存储和管理在爬虫项目中的重要性,同时也让我体会到在真实项目中处理文件时需要注意的细节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号