数据采集第二次作业
作业链接:https://gitee.com/cnmz6/cmy_project/tree/master/%E4%BD%9C%E4%B8%9A2
作业①:
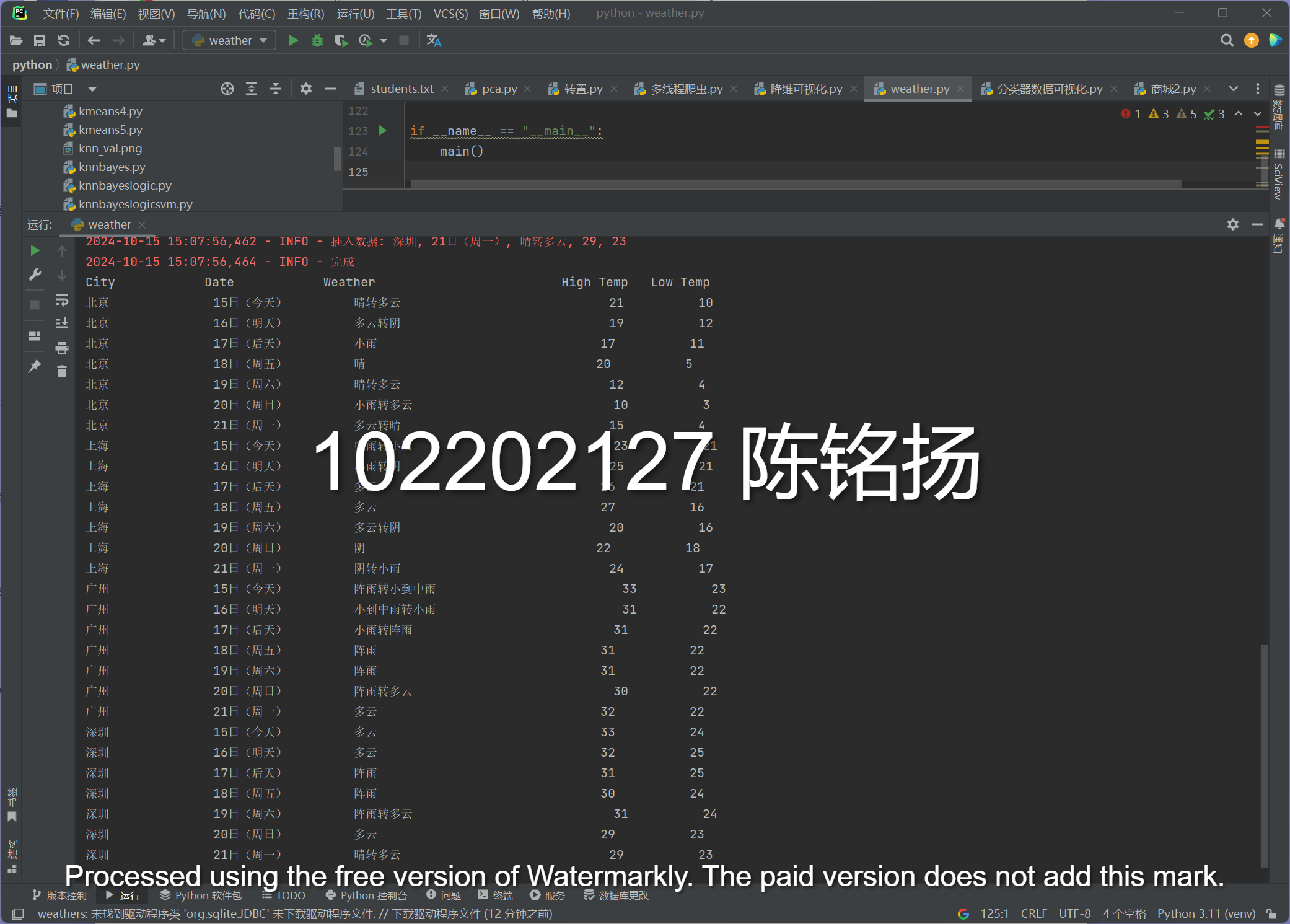
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
完成代码:
点击查看代码
class WeatherDB:
def __init__(self, db_name: str = "weathers.db"):
self.db_name = db_name
def __enter__(self):
self.con = sqlite3.connect(self.db_name)
self.cursor = self.con.cursor()
self.create_table()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
if exc_type:
logging.error(f"An error occurred: {exc_val}")
self.con.rollback()
else:
self.con.commit()
self.con.close()
def create_table(self):
create_table_sql = """
CREATE TABLE IF NOT EXISTS weathers (
wCity TEXT NOT NULL,
wDate TEXT NOT NULL,
wWeather TEXT,
wHighTemp TEXT,
wLowTemp TEXT,
PRIMARY KEY (wCity, wDate)
)
"""
self.cursor.execute(create_table_sql)
logging.info("确保数据库表已创建")
def insert(self, city: str, date: str, weather: str, high_temp: str, low_temp: str):
try:
self.cursor.execute("""
INSERT INTO weathers (wCity, wDate, wWeather, wHighTemp, wLowTemp)
VALUES (?, ?, ?, ?, ?)
""", (city, date, weather, high_temp, low_temp))
logging.info(f"插入数据: {city}, {date}, {weather}, {high_temp}, {low_temp}")
except sqlite3.IntegrityError:
logging.warning(f"数据已存在,跳过插入: {city} on {date}")
except Exception as e:
logging.error(f"插入数据时出错: {e}")
def show(self):
try:
self.cursor.execute("SELECT * FROM weathers")
rows = self.cursor.fetchall()
print(f"{'City':<16}{'Date':<16}{'Weather':<32}{'High Temp':<12}{'Low Temp':<12}")
for row in rows:
print(f"{row[0]:<16}{row[1]:<16}{row[2]:<32}{row[3]:<12}{row[4]:<12}")
except Exception as e:
logging.error(f"查询数据时出错: {e}")
# 天气预报类
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/90.0.4430.93 Safari/537.36"
}
self.city_code = {
"北京": "101010100",
"上海": "101020100",
"广州": "101280101",
"深圳": "101280601"
}
def forecast_city(self, city: str, db: WeatherDB):
if city not in self.city_code:
logging.error(f"{city} 的代码无法找到")
return
url = f"http://www.weather.com.cn/weather/{self.city_code[city]}.shtml"
try:
response = requests.get(url, headers=self.headers, timeout=10)
response.raise_for_status()
dammit = UnicodeDammit(response.content, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul.t.clearfix li")
for li in lis:
try:
date = li.select_one('h1').get_text(strip=True)
weather = li.select_one('p.wea').get_text(strip=True)
high_temp_tag = li.select_one('p.tem span')
low_temp_tag = li.select_one('p.tem i')
high_temp = high_temp_tag.get_text(strip=True) if high_temp_tag else "N/A"
low_temp = low_temp_tag.get_text(strip=True).replace('℃', '') if low_temp_tag else "N/A"
logging.info(f"{city} {date} {weather} 高温: {high_temp} 低温: {low_temp}")
db.insert(city, date, weather, high_temp, low_temp)
except Exception as parse_err:
logging.error(f"解析数据时出错: {parse_err}")
except requests.RequestException as req_err:
logging.error(f"请求错误: {req_err}")
def process(self, cities: List[str]):
with WeatherDB() as db:
for city in cities:
self.forecast_city(city, db)
db.show()
完成结果:
第二题:作业②
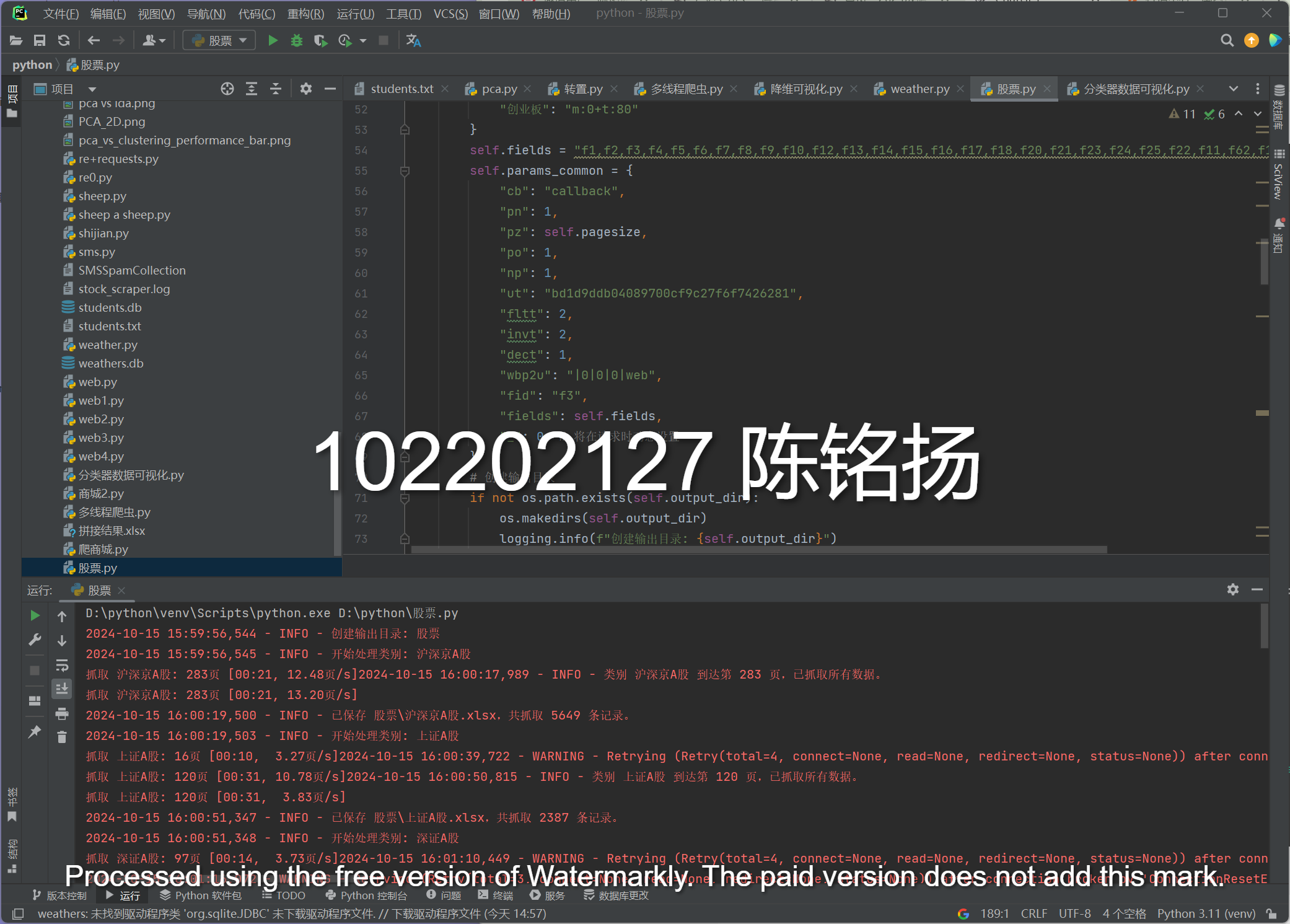
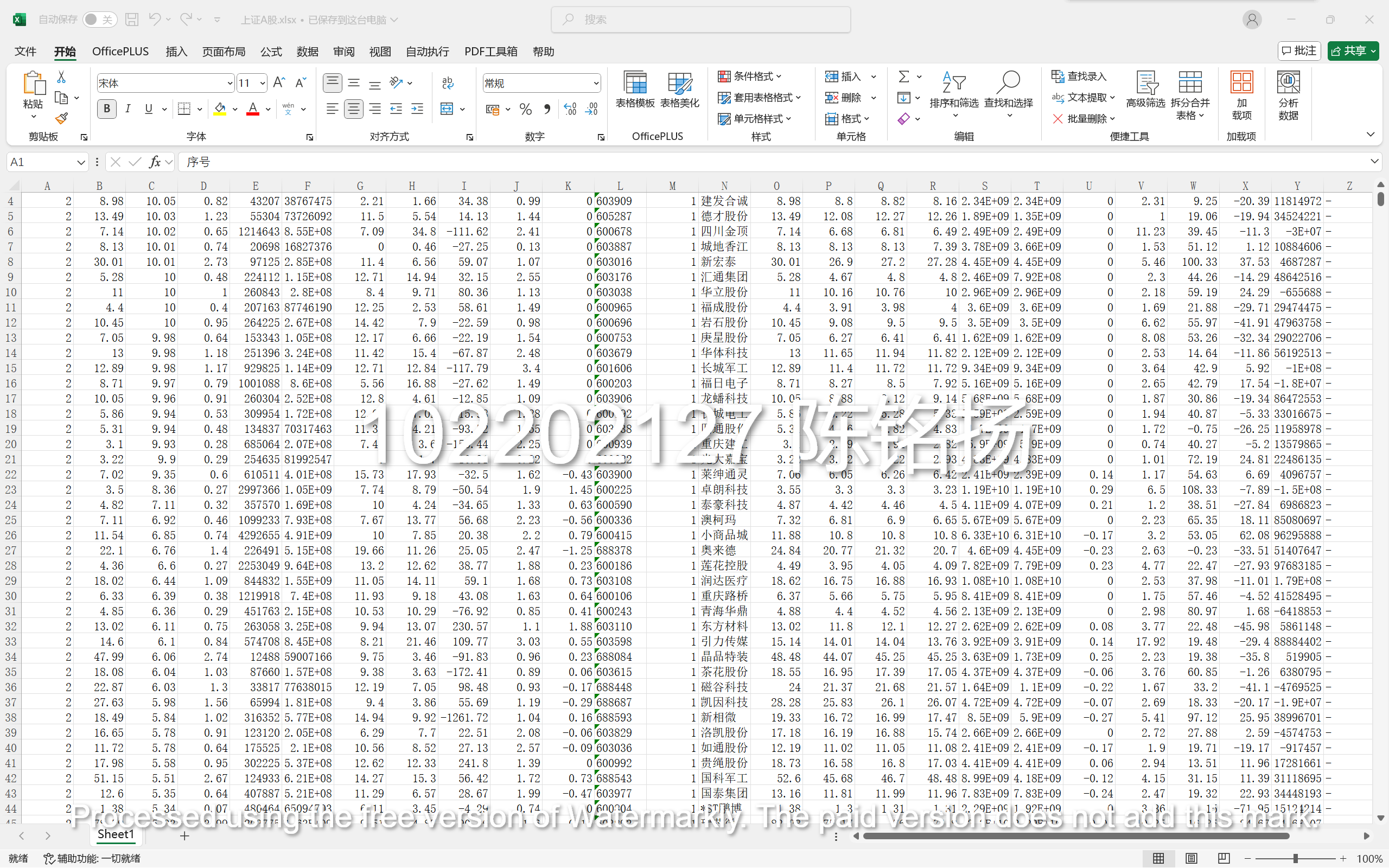
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
先通过F12寻找其中的url,在修改其中pn与fs的信息,从而完成翻页以及对所有的信息进行读取的操作;
完成代码:
点击查看代码
class StockScraper:
def __init__(self, output_dir: str = "股票", pagesize: int = 20, max_retries: int = 5, backoff_factor: float = 0.3):
self.base_url = "https://48.push2.eastmoney.com/api/qt/clist/get"
self.session = requests.Session()
retries = Retry(
total=max_retries,
backoff_factor=backoff_factor,
status_forcelist=[500, 502, 503, 504],
allowed_methods=["GET"] # 从 method_whitelist 改为 allowed_methods
)
adapter = HTTPAdapter(max_retries=retries)
self.session.mount('http://', adapter)
self.session.mount('https://', adapter)
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/90.0.4430.93 Safari/537.36"
}
self.output_dir = output_dir
self.pagesize = pagesize
self.cmd = {
"沪深京A股": "m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
"上证A股": "m:1+t:2,m:1+t:23",
"深证A股": "m:0+t:6,m:0+t:80",
"北证A股": "m:0+t:81+s:2048",
"新股": "m:0+f:8,m:1+f:8",
"创业板": "m:0+t:80"
}
self.fields = "f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152"
self.params_common = {
"cb": "callback",
"pn": 1,
"pz": self.pagesize,
"po": 1,
"np": 1,
"ut": "bd1d9ddb04089700cf9c27f6f7426281",
"fltt": 2,
"invt": 2,
"dect": 1,
"wbp2u": "|0|0|0|web",
"fid": "f3",
"fields": self.fields,
"_": 0 # 将在请求时动态设置
}
# 创建输出目录
if not os.path.exists(self.output_dir):
os.makedirs(self.output_dir)
logging.info(f"创建输出目录: {self.output_dir}")
def get_html(self, cmd: str, page: int) -> Dict:
params = self.params_common.copy()
params.update({
"pn": page,
"fs": cmd,
"_": int(pd.Timestamp.now().timestamp() * 1000) # 动态时间戳
})
try:
response = self.session.get(self.base_url, headers=self.headers, params=params, timeout=10)
response.raise_for_status()
# 处理JSONP格式的响应
json_str = response.text
json_str = json_str[json_str.find('(')+1 : json_str.rfind(')')]
data = json.loads(json_str)
return data
except requests.RequestException as e:
logging.error(f"请求错误: {e}")
return {}
except json.JSONDecodeError as e:
logging.error(f"JSON解析错误: {e}")
return {}
def get_one_page_stock(self, cmd: str, page: int) -> List[List[str]]:
data = self.get_html(cmd, page)
if not data or 'data' not in data or 'diff' not in data['data']:
logging.warning(f"没有获取到数据,cmd: {cmd}, page: {page}")
return []
stocks = []
for item in data['data']['diff']:
stock = [
item.get("f1", ""), # 序号
item.get("f2", ""), # 代码
item.get("f3", ""), # 名称
item.get("f4", ""), # 最新价格
item.get("f5", ""), # 涨跌额
item.get("f6", ""), # 涨跌幅
item.get("f7", ""), # 成交量
item.get("f8", ""), # 成交额
item.get("f9", ""), # 振幅
item.get("f10", ""), # 最高
item.get("f11", ""), # 最低
item.get("f12", ""), # 今开
item.get("f13", ""), # 昨收
item.get("f14", ""), # 量比
item.get("f15", ""), # 换手率
item.get("f16", ""), # 市盈率
item.get("f17", ""), # 市净率
item.get("f18", ""), # 总市值
item.get("f20", ""), # 流通市值
item.get("f21", ""), # 涨停价
item.get("f22", ""), # 跌停价
item.get("f23", ""), # 涨速
item.get("f24", ""), # 最高52周
item.get("f25", ""), # 最低52周
item.get("f62", ""), # 每股收益
item.get("f128", ""), # 每股净资产
item.get("f136", ""), # 股东户数
item.get("f115", ""), # 市销率
item.get("f152", "") # 时间
]
stocks.append(stock)
return stocks
def process_category(self, category_name: str, cmd: str):
logging.info(f"开始处理类别: {category_name}")
page = 1
all_stocks = []
pbar = tqdm(desc=f"抓取 {category_name}", unit="页")
while True:
stocks = self.get_one_page_stock(cmd, page)
if not stocks:
logging.info(f"类别 {category_name} 到达第 {page} 页,无更多数据。")
break
all_stocks.extend(stocks)
pbar.update(1)
# 检查是否达到最后一页
if len(stocks) < self.pagesize:
logging.info(f"类别 {category_name} 到达第 {page} 页,已抓取所有数据。")
break
page += 1
pbar.close()
if all_stocks:
df = pd.DataFrame(all_stocks, columns=[
"序号", "代码", "名称", "最新价格", "涨跌额", "涨跌幅", "成交量", "成交额",
"振幅", "最高", "最低", "今开", "昨收", "量比", "换手率", "市盈率",
"市净率", "总市值", "流通市值", "涨停价", "跌停价", "涨速",
"最高52周", "最低52周", "每股收益", "每股净资产", "股东户数",
"市销率", "时间"
])
# 清理数据(如去除空行、转换数据类型等)
df.dropna(subset=["代码"], inplace=True)
# 保存为Excel文件
safe_category_name = "".join(c for c in category_name if c not in r'\/:*?"<>|')
file_path = os.path.join(self.output_dir, f"{safe_category_name}.xlsx")
try:
df.to_excel(file_path, index=False)
logging.info(f"已保存 {file_path},共抓取 {len(all_stocks)} 条记录。")
except Exception as e:
logging.error(f"保存文件时出错: {e}")
else:
logging.warning(f"类别 {category_name} 没有抓取到任何数据。")
def run(self):
for category, cmd in self.cmd.items():
self.process_category(category, cmd)
logging.info("所有类别数据抓取完成。")
完成结果:
第三题:作业③:
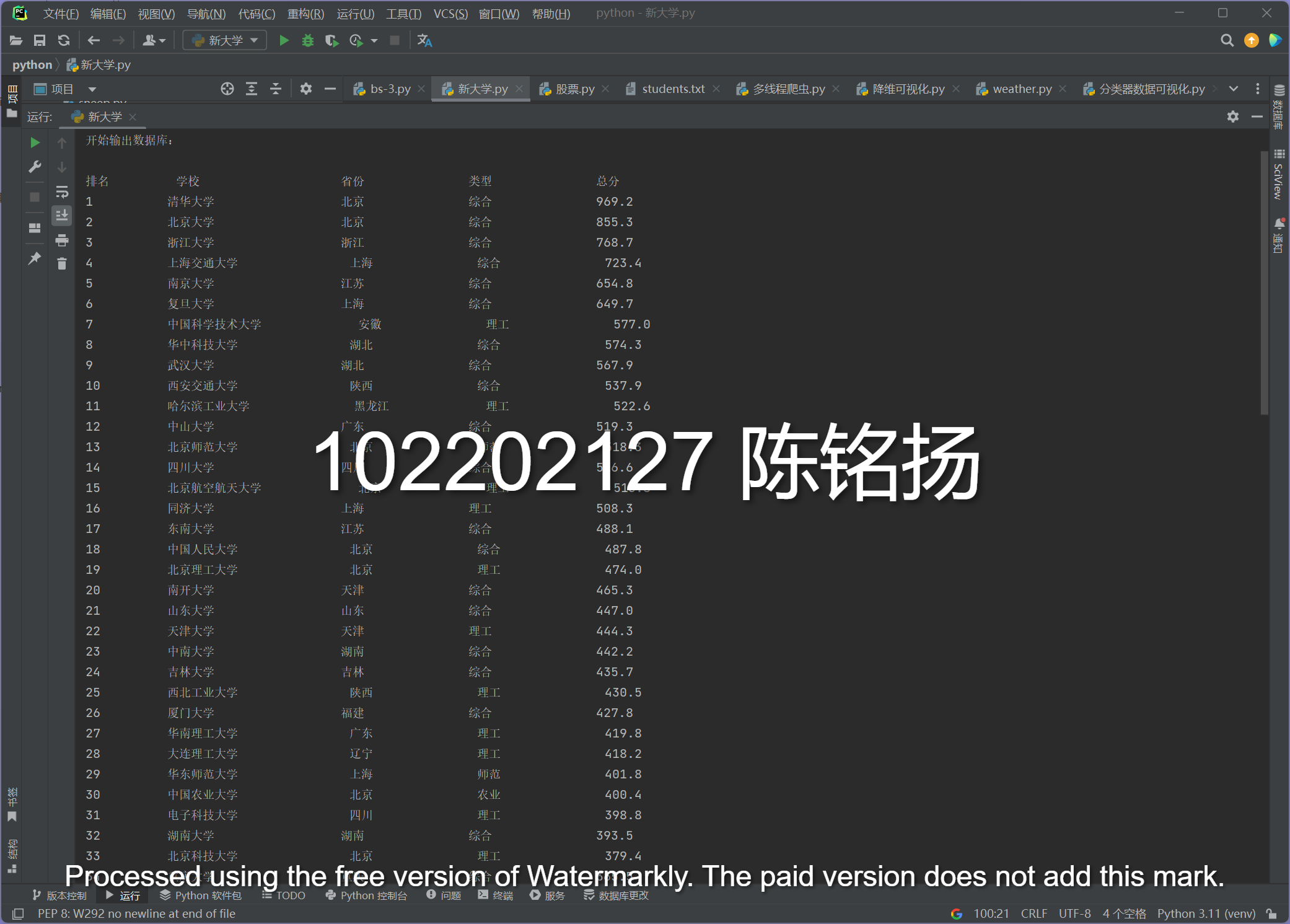
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。###
完成代码:
点击查看代码
class UniversityDB:
def __init__(self):
self.con = sqlite3.connect("universities.db")
self.cursor = self.con.cursor()
self.create_table()
def create_table(self):
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS universities (
id INTEGER PRIMARY KEY AUTOINCREMENT,
rank INTEGER,
name TEXT,
province TEXT,
category TEXT,
score REAL
)
""")
self.con.commit()
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, rank, name, province, category, score):
self.cursor.execute("""
INSERT INTO universities (rank, name, province, category, score)
VALUES (?, ?, ?, ?, ?)
""", (rank, name, province, category, score))
def show(self):
self.cursor.execute("SELECT * FROM universities")
rows = self.cursor.fetchall()
print("{:<10} {:<20} {:<15} {:<15} {:<10}".format("排名", "学校", "省份", "类型", "总分"))
for row in rows:
print("{:<10} {:<20} {:<15} {:<15} {:<10}".format(row[1], row[2], row[3], row[4], row[5]))
class UniversityForecast:
def __init__(self):
self.db = UniversityDB()
def fetch_data(self, url):
response = requests.get(url)
response.raise_for_status()
return response.text
def parse_data(self, text):
name = re.findall(',univNameCn:"(.*?)",', text)
score = re.findall(',score:(.*?),', text)
category = re.findall(',univCategory:(.*?),', text)
province = re.findall(',province:(.*?),', text)
code_name = re.findall('function(.*?){', text)
start_code = code_name[0].find('a')
end_code = code_name[0].find('pE')
code_name = code_name[0][start_code:end_code].split(',')
value_name = re.findall('mutations:(.*?);', text)
start_value = value_name[0].find('(')
end_value = value_name[0].find(')')
value_name = value_name[0][start_value + 1:end_value].split(",")
universities = []
for i in range(len(name)):
province_name = value_name[code_name.index(province[i])][1:-1]
category_name = value_name[code_name.index(category[i])][1:-1]
universities.append((i + 1, name[i], province_name, category_name, score[i]))
return universities
def process(self, url):
try:
text = self.fetch_data(url)
universities = self.parse_data(text)
for uni in universities:
self.db.insert(uni[0], uni[1], uni[2], uni[3], float(uni[4]))
except Exception as err:
print(f"Error processing data: {err}")
def show_database(self):
print("\n开始输出数据库:\n")
self.db.show()
def close_database(self):
self.db.closeDB()
完成结果:
寻找相关信息:

成功爬取:
心得总结:
完成这三个作业后,我在网页爬虫、数据处理和数据库管理等方面的技能得到了极大提升。这些实践让我更加自信地处理现实中的数据抓取任务,并认识到在实际应用中,遵循法律法规、确保数据安全和隐私保护是非常重要的。通过不断尝试和调试,我也提升了问题解决能力和调试技能,对未来的学习与工作充满期待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号