
SciTech-BigDataAIML-TensorFlow-Model模型的 建立与训练 与 Layer层的inputs/outputs参数可自适应训练建模(投入产出)
TensorFlow 模型建立与训练
TensorFlow 模型建立与训练
本章介绍如何使用 TensorFlow 快速搭建动态模型。
- 模型的构建: tf.keras.Model 和 tf.keras.layers
- 模型的损失函数: tf.keras.losses: cost成本(error误差)不止一种方式, 如diff=(y_true-y_pred), diff^2, abs(diff), ..., ,但总之是为更好的适用当前模型应用的当前场合。
- 模型的优化器: tf.keras.optimizer
- 模型的评估: tf.keras.metrics
前置知识
- Python -{zh-hant: 物件導向;zh-hans: 面向對象;}- 编程 :
- Python 定义 类和方法、类的继承、构造和析构函数,
- 使用 super () 函数调用父类方法 ,
- 使用__call__() 方法对实例进行调用 等);
- 多层感知机、卷积神经网络、循环神经网络和强化学习(每节之前给出参考资料)。
- Python 的函数装饰器 (非必须)
模型(Model)与层(Layer)
- 在 TensorFlow 中,推荐使用 Keras( tf.keras )构建模型。
Keras 是一个广为流行的高级神经网络 API,简单、快速而不失灵活性,现已得到 TensorFlow 的官方内置和全面支持。 - Keras 有两个重要的概念: 模型(Model) 和 层(Layer) 。
- 层将各种计算流程和变量进行了封装(例如基本的全连接层,CNN 的卷积层、池化层等),
- 模型则将各种层进行组织和连接,并封装成一个整体,描述了如何将输入数据通过各种层以及运算而得到输出。
- 在需要模型调用的时候,使用
y_pred = model(X)的形式即可。 - Keras 在
tf.keras.layers下内置有深度学习用的大量常用的预定义层; - Keras同时也允许我们自定义层。
- Keras 模型以类的形式呈现,我们可以通过继承
tf.keras.Model这个Python 类来定义自己的模型。在继承类中,我们需要重写__init__()(构造函数,初始化)和call(input)(模型调用)两个方法,同时也可以根据需要增加自定义的方法.
class MyModel(tf.keras.Model):
def __init__(self):
super().__init__()
# Python 2 下使用 super(MyModel, self).__init__()
# 此处添加初始化代码(包含 call 方法中会用到的层),例如
# layer1 = tf.keras.layers.BuiltInLayer(...)
# layer2 = MyCustomLayer(...)
def call(self, input):
# 此处添加模型调用的代码(处理输入并返回输出),例如
# x = layer1(input)
# output = layer2(x)
return output
# 还可以添加 自定义的方法
- 继承 tf.keras.Model 后,我们同时可以使用父类的若干方法和属性,例如在实例化类
model = Model()后,可以通过model.variables这一属性直接获得模型的所有变量,免去我们一个个显式指定变量的麻烦。 - Keras 的 Model模型类 定义示意图:
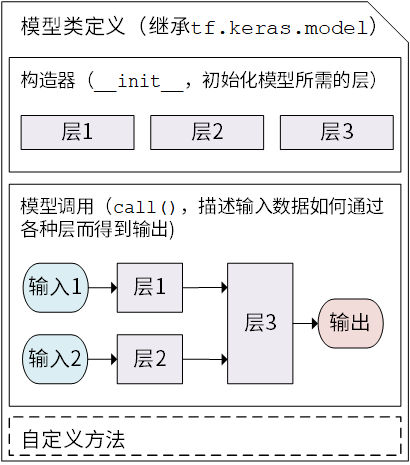
上一章中简单的线性模型 y_pred = a * X + b ,我们可以通过模型类的方式编写如下:
import tensorflow as tf
X = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
y = tf.constant([[10.0], [20.0]])
class Linear(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense = tf.keras.layers.Dense(
units=1,
activation=None,
kernel_initializer=tf.zeros_initializer(),
bias_initializer=tf.zeros_initializer()
)
def call(self, input):
output = self.dense(input)
return output
# 以下代码结构与前节类似
model = Linear()
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
for i in range(100):
with tf.GradientTape() as tape:
y_pred = model(X)
# 调用模型 y_pred = model(X) 而不是显式写出 y_pred = a * X + b
loss = tf.reduce_mean(tf.square(y_pred - y))
grads = tape.gradient(loss, model.variables)
# 使用 model.variables 这一属性直接获得模型中的所有变量
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
print(model.variables)
这里,我们没有显式地声明 a 和 b 两个变量并写出 y_pred = a * X + b 这一线性变换,而是建立一个继承 tf.keras.Model 的模型类 Linear :
- 这个类在初始化部分实例化了一个 全连接层(
tf.keras.layers.Dense), - 在 call 方法中对这个层进行调用,实现线性变换的计算。
- 如果需要显式地声明自己的变量并使用变量进行自定义运算,或者希望了解 Keras 层的内部原理,请参考 自定义层。
Layer的“矩阵变换函数”与“投入产出自适应训练参数的建模”
-
数学角度,可将Layer视为“矩阵变换函数”,即将inputs张量 变换到 outputs张量;
为什么要以“数学”建模?:
数量值化:宏观的规律与策略,必须要与微观的度与量,有严谨的统一:
易于变换:inputs输入张量,outputs输出张量 都是数量值,通过数学变换函数;
无量纲化:数量许多时候"有量纲"即是"相对"、"现象"的,
而"无量纲"时是"绝对"与"本质规律"的; 无量纲 与 绝对(普遍适用) 的,本质与度量联系的,才会是可"模型"(通用规律化)的;
概率统计: Event -> Samples -> Population, Phenomenon->Measure->Nature -
实现角度,为“智能”的将inputs张量 变换到 outputs张量,
-
需要总结出kernel张量:
supervised: 用样本数据,自适应的预训练好参数,例如分类,
unsupervised: 直接由inputs提取 参数kernel,例如聚类, -
统一的
数据与过程建模:- 数据上,设立inputs/outputs数学建模:
inputs输入张量,outputs输出张量 都是数量值,
有目标的 投入产出效能建模,评估每一次的 目标值 与 真实值 之间的效能提升; - 过程上,epoches(一轮轮)的以一定的
调整策略``尝试改变参数, 通过outputs的变化量(真实值y_true与y_pred的变化量), 一步步的选取最优的参数。
- 数据上,设立inputs/outputs数学建模:
-
Loss(error) Function: 就是由 目标值 与 真实值 提取出 变参的效果度量数值 的函数:
例如:
abs_Loss_function = abs(y_pred - y_true),
mse_Loss_function = (y_pred - y_true)^2
...
事实上keras.metrics已经集成许多常用到的Loss Function:
-
[
[
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError(),
],
[keras.metrics.CategoricalAccuracy()],
],
- Optimizer: 优化器是拿到 loss(error)后,进行“优化”的;
Layer 之 Dense(tf.keras.layers.Dense)全连接层:线性变换 + 激活函数
- Fully-connected Layer(
tf.keras.layers.Dense)是 Keras 中最基础和常用的层之一.
之所以叫"全连接层",是因为线性变换tf.matmul(input, kernel) + bias用的,
是"tf.matmul矩阵乘法", 将inputs张量视为行向量组(每个行向量都有input_dim列的特征维度), 将kernel视为列向量组(每个列向量都有input_dim行),则outputs张量的每一个元素都与inputs张量全部(input_dim维度数)的特征有"连接"。 Dense对输入矩阵A进行f(AW + b)的 线性变换 + 激活函数 操作。
如果不指定激活函数,即只进行线性变换AW + b。Dense的实现:
给定 输入张量input = [batch_size, input_dim],
首先进行tf.matmul(input, kernel) + bias的线性变换(kernel和bias是层中可训练的变量),
然后对线性变换后张量的每个元素通过激活函数activation,从而输出形状为[batch_size, units]的二维张量。
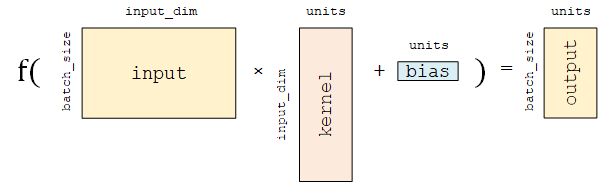
Dense包含的主要参数如下:units:输出张量的维度;activation:激活函数,
对应于f(AW + b)的f,默认为转发激活(即a(x) = x, 转发x)。
常用的有tf.nn.relu,tf.nn.tanh和tf.nn.sigmoid;use_bias:
是否加入偏置向量bias,即f(AW + b)的b. 默认为True;kernel_initializer、bias_initializer:
权重矩阵kernel和偏置向量bias两个变量的初始化器。
默认为tf.glorot_uniform_initializer.
Keras 的很多层都默认使用tf.glorot_uniform_initializer初始化变换。
设置为tf.zeros_initializer表示将两个变量均初始化为全0;
该层包含权重矩阵kernel = [input_dim, units]和偏置向量bias = [units]两个可训练变量,对应于f(AW + b)的W和b。
这里着重从数学矩阵运算和线性变换的角度描述Dense全连接层。
基于神经元建模的描述可参考 后文介绍 。
-
Keras 中的很多层都默认使用 tf.glorot_uniform_initializer 初始化变量,关于该初始化器可参考 https://www.tensorflow.org/api_docs/python/tf/glorot_uniform_initializer 。
-
你可能会注意到, tf.matmul(input, kernel) 的结果是一个形状为 [batch_size, units] 的二维矩阵,这个二维矩阵要如何与形状为 [units] 的一维偏置向量 bias 相加呢?事实上,这里是 TensorFlow 的 Broadcasting 机制在起作用,该加法运算相当于将二维矩阵的每一行加上了 Bias 。Broadcasting 机制的具体介绍可见 https://www.tensorflow.org/xla/broadcasting 。
为什么模型类是重载 call() 方法而不是 call() 方法?
在 Python 中,对类的实例 myClass 进行形如 myClass() 的调用等价于 myClass.call() (具体请见本章初 “前置知识” 的 call() 部分)。那么看起来,为了使用 y_pred = model(X) 的形式调用模型类,应该重写 call() 方法才对呀?原因是 Keras 在模型调用的前后还需要有一些自己的内部操作,所以暴露出一个专门用于重载的 call() 方法。 tf.keras.Model 这一父类已经包含 call() 的定义。 call() 中主要调用了 call() 方法,同时还需要在进行一些 keras 的内部操作。这里,我们通过继承 tf.keras.Model 并重载 call() 方法,即可在保持 keras 结构的同时加入模型调用的代码。
n 为分类任务的类别个数。
预测概率分布与真实分布越接近,则交叉熵的值越小,反之则越大。
更具体的介绍及其在机器学习中的应用可参考 这篇博客文章 。
在 tf.keras 中,有两个交叉熵相关的损失函数 tf.keras.losses.categorical_crossentropy 和 tf.keras.losses.sparse_categorical_crossentropy 。其中 sparse 的含义是,真实的标签值 y_true 可以直接传入 int 类型的标签类别。具体而言:
loss = tf.keras.losses.sparse_categorical_crossentropy(
y_true=y,
y_pred=y_pred)
与
loss = tf.keras.losses.categorical_crossentropy(
y_true=tf.one_hot(y, depth=tf.shape(y_pred)[-1]),
y_pred=y_pred)
的结果相同。
模型的评估: tf.keras.metrics
使用测试集评估模型的性能。
使用 tf.keras.metrics 的 SparseCategoricalAccuracy 评估器来评估模型在测试集上的性能:
该评估器能够对模型的"预测结果"与""真实结果"进行比较,并输出预测正确的样本数占总样本数的比例。
我们迭代测试数据集,每次通过 update_state() 方法向评估器输入两个参数: y_pred 和 y_true,即模型预测出的结果和真实结果。
评估器具有内部变量来保存当前评估指标相关的参数数值(例如当前已传入的累计样本数和当前预测正确的样本数)。
迭代结束后,我们使用 result() 方法输出最终的评估指标值(预测正确的样本数占总样本数的比例)。
以下代码,实例化一 tf.keras.metrics.SparseCategoricalAccuracy 评估器,
并使用 For 循环迭代分批次传入的测试集数据的预测结果与真实结果,
并输出训练后的模型在测试数据集上的准确率。
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
num_batches = int(data_loader.num_test_data // batch_size)
for batch_index in range(num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict(data_loader.test_data[start_index: end_index])
sparse_categorical_accuracy.update_state(y_true=data_loader.test_label[start_index: end_index], y_pred=y_pred)
print("test accuracy: %f" % sparse_categorical_accuracy.result())
输出结果:
test accuracy: 0.947900
可以注意到,使用这样简单的模型,已经可以达到 95% 左右的准确率。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)