
第四十天线程的进阶
1.进程之间是有守护进程的,那么线程之间是否有守护进程那:


from threading import Thread import time def func(): while True: time.sleep(2) print('执行一次') t=Thread(target=func,) t.start() print('主进程执行结束')
结果为
主线程进行结束以后,子线程无休止的进行下去,
from threading import Thread import time def func(): while True: time.sleep(2) print('执行一次') t=Thread(target=func,) t.daemon=True #设置守护进程 t.start() time.sleep(4) print('主进程执行结束') 结果为 C:\pycharm\python.exe D:/python练习程序/第四十天/Thread_project.py 执行一次 主进程执行结束 Process finished with exit code 0
2看下面程序和现象说明原因:
from threading import Thread import time def func(): while True: time.sleep(2) print('执行一次') def func2(): time.sleep(10) print('进程2执行结束') t=Thread(target=func,) t.daemon=True t.start() t1=Thread(target=func2) t1.start() time.sleep(4) print('主进程执行结束') 结果为: C:\pycharm\python.exe D:/python练习程序/第四十天/Thread_project.py 执行一次 执行一次 主进程执行结束 执行一次 执行一次 进程2执行结束
从结果我们可以看出主线程结束之后,守护进程并没有结束,而是等到子线程2结束时,子线程1(守护线程)才结束
原因:
1.对于主进程来说:运行完毕指的是主进程代码运行完毕
2.对于主线程来说,运行完毕指的是主线程所在的进程内所有的非守护线程统统执行完毕后,主线程才算运行完毕。
1。主进程在其代码执行结束后就已经算执行完成了(守护进程此时会被回收)然后主进程会一直等待非守护进程的子进程都执行结束才回子进程的资源(否则会生成僵尸进程),才会结束。
2.主线程在其他非守护进程运行完毕后才算运行完毕(守护进程在此时才会被回收)。因为主线程的结束才意味着进程的结束,进程整体的资源将被回收,而进程必须保证非守护进程的线程都执行结束才能结束。
3.数据抢占问题:
3.1科学家吃面问题:3个科学家同时在一个桌子上吃面,桌子上有一碗面和一个叉子,每次只有一个人吃完之后才能下一个人进行继续吃,但是如果其中人拿到叉子另一个人拿到·面,则此程序无法进行下去只能进入死锁状态,要进行此方法只能使用加锁:
3.2数据抢占问题:
from threading import Lock lock=Lock() lock.acquire()#拿到一把钥匙 lock.acquire()#由于上一把钥匙没有归还,所以无法进行拿到钥匙,进行堵塞状态 print(123)#无法进行输出
from threading import Thread import time def func(): global n temp=n time.sleep(0.1) n=temp-1 t_list=[] n=10 for i in range(10): t=Thread(target=func) t.start() t_list.append(t) for i in t_list:i.join() print(n) 结果为 C:\python\python.exe D:/python练习程序/第三十九天2/practise.py 9
虽然线程在执行过程中会有GIL(全局解释器锁)但是当程序获取数据未执行时,时间片轮转时间到,轮到下一个进程执行,然后拿到的数据还是上一次的所以多个线程执行时,执行的数据操作都是同样的过程,这样会造成数据的不安全性。
解决办法:在线程中加锁:
from threading import Thread,Lock import time def func(lock): global n lock.acquire() temp=n time.sleep(0.1) n=temp-1 lock.release() t_list=[] n=10 lock=Lock() for i in range(10): t=Thread(target=func,args=(lock,)) t.start() t_list.append(t) for i in t_list:i.join() print(n) 结果 0
这样虽然可以解决问题,但是使得异步进行的线程变成了同步,使得进行的时间有所增强,但是保证了数据的安全。
3.4看下面程序的死程序应该怎么解决:
from threading import Thread,Lock import time fork=Lock() noodle=Lock() class MyThread(Thread): def run(self): self.func1() self.func2() def func1(self): fork.acquire() print('%s拿到叉子'%self.name) noodle.acquire() print('%s拿到面条'%self.name) noodle.release() fork.release() def func2(self): noodle.acquire() print('%s拿到面条'%self.name) time.sleep(2) fork.acquire() print('%s拿到叉子'%self.name) fork.release() noodle.release() for i in range(3): t=MyThread() t.start()
程序中启动了3个线程,执行run方法,加入线程1首先·抢到fork锁,此时线程1没有释放fork锁,接着执行代码抢到了noodle锁,在抢b琐时并没有其他线程和其进行竞争,因为fork没有释放,其他线程只能等待,然后fork执行完func1中的代码,然后继续执行func2中的代码,在执行func2时执行代码noodle抢到了面条进入休眠状态,在线程1执行完成之后释放两把锁,其余线程也开始抢a锁,由于线程2处于休眠状态,线程1抢到a锁,线程2抱着noodle不妨,都没有办法继续往下执行,形成了死锁
解决·办法:使用递归锁:Rlock
from threading import RLock ret=RLock() ret.acquire() ret.acquire() print(124) 结果为 C:\pycharm\python.exe D:/python练习程序/第四十天/Thread_project.py 124
RLock是拿到一串钥匙,只要拿到一把就可以执行子线程里的代码,但是若有多个acquire,没有对应的release,则其他的线程中即使有acquire也没有办法获得数据,只有等哪一个线程release完成后才能进行获取
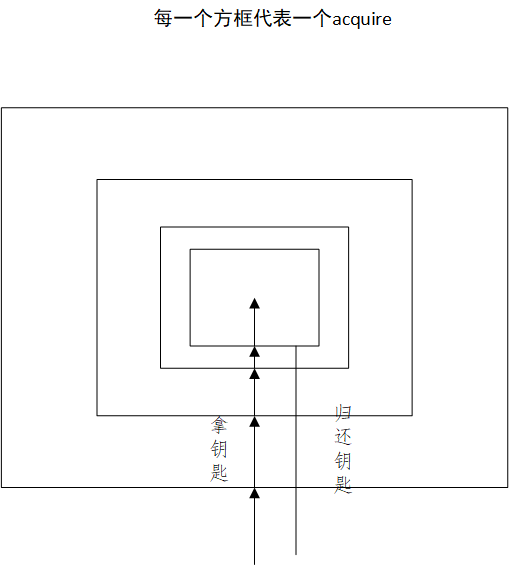
from threading import RLock,Thread ret=RLock() def work(): ret.acquire() ret.acquire() print(124) ret.release() def work2(): ret.acquire() print(12354) ret.release() Thread(target=work).start() Thread(target=work2).start()
结果为

第一个线程中的有没有释放的锁,所以第二个线程无法进行执行。
4进程中有信号量,那么线程中是否有信号量:
from threading import Thread,Semaphore import time def work(sem,a,b): sem.acquire() time.sleep(1) print(a+b) sem.release() sem=Semaphore(5)#实例化一个信号量,并设置5吧锁 for i in range(20): Thread(target=work,args=(sem,i,9)).start()
5.线程中的事件操作:运行机制和进程一样:运用线程的事件指令写一个连接数据库的操作:
from threading import Thread,Event import time,random def e_wait(e): count=3 while count: e.wait(0.5) if e.is_set()==True: print('第%s数据库连接成功'%(4-count)) break else: count-=1 else: print('数据库连接失败') def connection(e): time.sleep(random.randint(0,1)) e.set() e=Event() Thread(target=connection,args=(e,)).start() Thread(target=e_wait,args=(e,)).start()
from threading import Thread,Event import time,random def e_wait(e): count=3 while count: e.wait(1) if e.is_set()==True: print('第%s数据库连接成功'%(4-count)) break else: count-=1 else: print('数据库连接失败') def connection(e): time.sleep(random.randint(5,10)) e.set() e=Event() Thread(target=connection,args=(e,)).start() Thread(target=e_wait,args=(e,)).start()
6.线程中独有的condition(条件和lock差不多)
from threading import Thread,Condition def work(con): con.acquire() con.wait()#等待钥匙的到来 print('hello') con.release() con=Condition() for i in range(10): Thread(target=work,args=(con,)).start() while True: num=int(input('>>>'))#先输入数据 con.acquire()#在进行acquire con.notify(num)#进行钥匙的配置 con.release()
注在使用条件的时候,无论是wait还是notify都是在前后都是要加上acquire和release
7.线程中的时间同步:(如果我们想要主线程进行2s之后子线程在启动怎么写)
from threading import Timer def func(): print('子线程是2s之后执行的') Timer(2,func).start()
8如果我想每隔5s执行一次子线程应该怎么写:
from threading import Timer import time def func(): print('子线程是5s之后执行的') while True: Timer(5,func).start()#此模块和主线程是异步执行的 time.sleep(5)
9.线程中的队列和进程中的队列功能和用法是一致的
10线程中队列的衍生:
10.1栈:先进后出
from queue import LifoQueue q=LifoQueue() q.put(3) q.put(5) print(q.get()) 结果为 5
10.2优先级队列:
from queue import PriorityQueue q=PriorityQueue() q.put((20,'1')) q.put((5,'c'))#前面放优先级,后面放存储的数据 print(q.get())#数值越小,优先级越高 print(q.get()[1])#数值越小,优先级越高 结果为 (5, 'c') 1
当优先级相同的时候,就要比较传入的数据,谁的数据ascii小,先输出谁:
from queue import PriorityQueue q=PriorityQueue() q.put((20,'1')) q.put((5,'c'))#前面放优先级,后面放存储的数据 q.put((5,'a')) print(q.get())#数值越小,优先级越高 结果为 (5, 'a')
11.线程池:
1.使用concurrent。futures模块,提供异步调用的方法:
2。基本方法:submit(fn,*args,**kwargs)异步提交任务
3.map(function,*iterable)取代for循环submit的操作,但是没有返回值
4.shutdown(wait=Ture)相当于进程池中的close和join:wait=True是等待线程池中的所有任务执行完成以后才会回收资源,wait=False立即返回,并不会等待线程的任务执行完毕,但不管wait为何值,整个程序都会等所有任务执行完毕后才执行完毕。submit和map必须在shutdo之前
5.取结果使用result
6.回调函数:add_done_callback(fn)
from concurrent.futures import ThreadPoolExecutor import time def work(i): print(i) time.sleep(1) t=ThreadPoolExecutor(max_workers=5)#一般设置数量不超过cpu*5 for i in range(20): t.submit(work,i)
12.如果想要线程池中的程序执行完毕以后,才执行主线程里的内容应该怎么进行写:
from concurrent.futures import ThreadPoolExecutor import time def work(i): print(i) time.sleep(1) t=ThreadPoolExecutor(max_workers=5)#一般设置数量不超过cpu*5 for i in range(20): t.submit(work,i) t.shutdown() print('主进程执行结束')
13.线程池返回值的问题:
from concurrent.futures import ThreadPoolExecutor import time def work(i): return i*i t=ThreadPoolExecutor(max_workers=5)#一般设置数量不超过cpu*5 ret=[] for i in range(20): msg=t.submit(work,i) ret.append(msg) t.shutdown() for i in ret:print(i.result()) 结果为 C:\pycharm\python.exe D:/python练习程序/第四十天/Thread_project.py 0 1 4 9 16 25 36 49 64 81 100 121 144 169 196 225 256 289 324 361
为什么线程在执行的过程中,进行顺序会乱,但是在输出数据过程中数据是正常的:
线程执行的时候,都有线程号,在数据进行放的时候,会按照序号一次放入到列表中
14.看下面一个程序:
from concurrent.futures import ThreadPoolExecutor import time def work(i): return i*i t=ThreadPoolExecutor(max_workers=5)#一般设置数量不超过cpu*5 ret=[] start=time.time() for i in range(20): msg=t.submit(work,i) ret.append(msg) t.shutdown() for i in ret:i.result() print(time.time()-start) 结果为C:\pycharm\python.exe D:/python练习程序/第四十天/Thread_project.py 0.0009963512420654297
from concurrent.futures import ThreadPoolExecutor import time def work(i): return i*i t=ThreadPoolExecutor(max_workers=5)#一般设置数量不超过cpu*5 ret=[] start=time.time() for i in range(20): msg=t.submit(work,i) ret.append(msg) for i in ret:i.result() print(time.time()-start) 结果为 C:\pycharm\python.exe D:/python练习程序/第四十天/Thread_project.py 0.001994609832763672
第二种程序使用的时间相对时间少一点,第一种方法是子线程在执行的过程中,主线程一直在等待子线程的结束,才进行工作,而第二种是子线程执行完一次命令之后,主线程也在执行
两个工作属于异步执行,这样效率高。
15回调函数:
from concurrent.futures import ThreadPoolExecutor import time def work(i): return i*i def work2(m): print('%s'%m.result()) t=ThreadPoolExecutor(max_workers=5)#一般设置数量不超过cpu*5 start=time.time() for i in range(20): t.submit(work,i).add_done_callback(work2) 结果为 0 1 4 9 16 25 36 49 64 81 100 121 144 169 196 225 256 289 324 361

