
第三十九天 进程返回值和线程的基础
1.在进程池中的map函数中,其属于异步,并且自带close和join函数
解释下面一个程序:


from multiprocessing import Pool import time def func(n): time.sleep(1) return n*n if __name__=='__main__': p=Pool() for i in range(10): ret=p.apply_async(func,args=(i,)) print(ret.get())#gei会让这一步进入堵塞状态当func执行完成后才去拿结果
2回调函数的使用情况:有时候我们一次性处理多个网站,在进程数据爬虫时,我们把从网站上读取和下载过程的程序放入子进程进行,这个时候主进程一直处于
等待状态(休闲状态)cpu利用率降低,这个时候就可以使用回调函数把子进程中获取到的值供主进程就去处理。

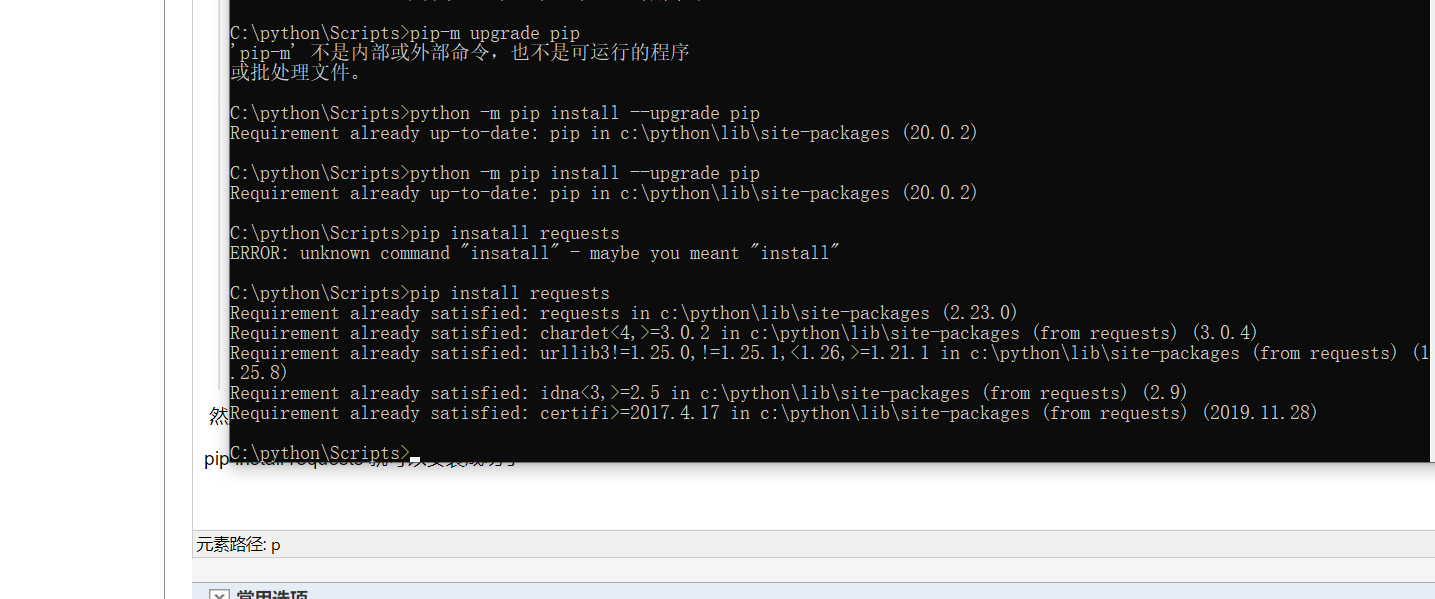
3.怎么安装requests模块:
首先打开cmd,进行磁盘切换就是再命令行输入磁盘号加上:,进入装有python的磁盘目录下,然后找到pythonpip的安装文件路径,(一般都在Scripts下)如果忘记安装位置可以右击软件,属性然后打开文件位置,找到文件的安装目录,然后在进入cmd命令框,输入cd C:\python\Scripts,再使用dir进行查看是否有如下命令

然后在使用pip install requests命令进行安装模块,如果出现报错,则需要对pip进行更新,需要输入python -m pip install --upgrade pip,之后会进入自动更新状态,更新完成以后,在输入
pip install requests 就可以安装成功了
4.怎么再使用的p'y'charm 中跟换python的版本:
打开file中setting——然后找到project——再找到project intrepretation

5.使用requests写程序:
import requests respone=requests.get('http://www.baidu.com') print(respone) print(respone.status_code)#打印网页的状态码 print(respone.content) 结果位 <Response [200]> 200 b'<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80\xe4\xb8\x8b\xef\xbc\x8c\xe4\xbd\xa0\xe5\xb0\xb1\xe7\x9f\xa5\xe9\x81\x93</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80\xe4\xb8\x8b class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>\xe6\x96\xb0\xe9\x97\xbb</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>\xe5\x9c\xb0\xe5\x9b\xbe</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>\xe8\xa7\x86\xe9\xa2\x91</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>\xe8\xb4\xb4\xe5\x90\xa7</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>\xe7\x99\xbb\xe5\xbd\x95</a> </noscript> <script>document.write(\'<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=\'+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ \'" name="tj_login" class="lb">\xe7\x99\xbb\xe5\xbd\x95</a>\');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">\xe6\x9b\xb4\xe5\xa4\x9a\xe4\xba\xa7\xe5\x93\x81</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>\xe5\x85\xb3\xe4\xba\x8e\xe7\x99\xbe\xe5\xba\xa6</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>\xe4\xbd\xbf\xe7\x94\xa8\xe7\x99\xbe\xe5\xba\xa6\xe5\x89\x8d\xe5\xbf\x85\xe8\xaf\xbb</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>\xe6\x84\x8f\xe8\xa7\x81\xe5\x8f\x8d\xe9\xa6\x88</a> \xe4\xba\xacICP\xe8\xaf\x81030173\xe5\x8f\xb7 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>\r\n'
从结果来看,此网页的状态是200,并且网页状态为200时属于正常,若状态值为404或者502、504时,说明网页故障,登陆不上去。
import requests from multiprocessing import Pool def get(url): respone=requests.get(url) if respone.status_code==200: return url,respone.status_code def print_url(m): print('%s\t%s'%(m[0],m[1])) if __name__=='__main__': p=Pool() url_list=[ 'https://www.baidu.com', 'https://www.sohu.com/' 'https://www.sogou.com/' 'https://pinyin.sogou.com/' ] for url in url_list: p.apply_async(get,args=(url,),callback=print_url) p.close() p.join() 结果为 https://www.baidu.com 200 https://www.sohu.com/https://www.sogou.com/https://pinyin.sogou.com/ 200
6.线程:
已经有进程了,为什么还要使用进程:
进程有很多优点,它提供了多道编程,让我们觉得我们每个人都拥有字节的cpu和其他资源,可以提高cpu的利用率。但是在使用进程的时候,我们可以发现微观上,进程同一时间只能干一件事情。如果想要同时干两个或者多件事情就无能为力了。进程再执行的过程当中,如果遇到堵塞,列如:等待输入,整个进程就会进入挂起状态,即使进程中某些工作不依赖于输入的数据,也将无法执行。
举一个列子:上课的时候:我们既要竖起耳朵听老师讲课,手上还要记笔记,脑子还要思考问题,这样上课的效率才会很高。如果把上述三件事情比成三个进程 ,那么上面三件事情在同一时间内只能做一件事情,听德时候就不能记笔记和思考。进行其中任何一个环节中老师做不下去,都会进入堵塞状态。他在那边思考着,我们这边只能等待,甚么事情也做不了。即使想要思考以下刚才没有听懂德问题都不行。
为了解决听写思三个独立的过程,让其并行起来。这样很明显效率就有所提高,从而实际德操作系统中也引入了这样的机制-线程
7.进程是资源分配的最小单位,线程是cpu调度的最小单位,每一个进程中至少有一个线程。
8.那生产螺丝的例子来说,cpu属于生产螺丝的机器,进程就属于每一个车间,而线程就属于车间里的每一个工人,对于cpu来说,调用每次进行调度时,调用工人,要比调用车间花费的时间和资源都要少。
9.进程与线程之间的关系及区别:
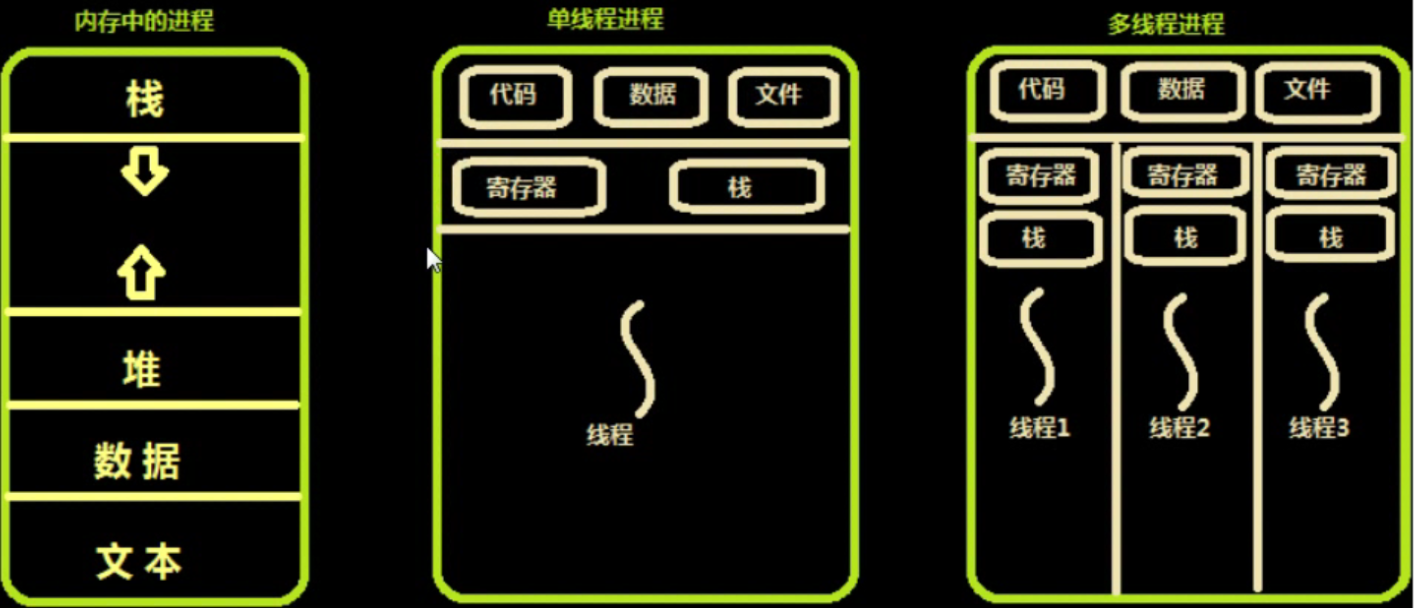
进程与线程的区别:
1.地址的空间和其他资源*(打开文件)进程之间是相互独立的,统一进程之间各线程之间的数据是共享的,某进程内的线程再其他进程内不可见。
2. 通信:进程之间使用IPC 线程之间可以直接读写进程中的数据段(如全局变量)来进行通讯
3.调度和切换:线程上下文切换要比进程上下文切换快的多
4.在多线程操作系统中,进程不是一个可执行的实体。
10.线程的特点:
在多线程的操作系统中,通常在一个进程中要包含多个线程,每个线程都是可以作为cpu利用的基本单位。是花费最少的实体。线程具有以下属性:
1.轻型实体:
线程中的实体基本上不拥有系统资源,只有一点必不可少,能保证独立运行的资源。
线程的实体剥开哦程序、数据和tcb 。线程是动态概念,他的动态特性有线程控制块TCB(Thread Control Block')
2独立调度和分派的基本单位:在多线程的os中,线程是cpu能独立运行的基本单位,因而可以进行独立调度和分派的基本单位。由于线程很轻,故县城切换非常迅速,且开销很小
3共享进程中的资源:线程中同一个进程中的各个线程,都可以共享该进程中所拥有的所有资源,所有的线程都拥有相同的进程id,这就意味着线程可以访问进程的每一个内存资源,此外,线程还可以访问已拥有的以打开的文件,定时器、信号量机构等。由于同一个进程内的线程共享内存和文件,所以线程之间通信不需要调用内核。
4可以并发执行:
11 2.TCB主要包含的内容有:
1.线程的状态
2.线程不运行时,被保存的线程资源
3.一组执行的堆栈
4.存放每个进程的局部变量和主存区
5.访问同一个进程中的主存和其他资源。
12.用户级线程和内核及线程:

13.python中经常使用的线程模块:Threading
14线程的第一个列子:(他的使用方式和进程方式一样)
import time from threading import Thread def func(n): time.sleep(1) print(n) for i in range(10): t=Thread(target=func,args=(i,))#和进程方法一样 t.start() 结果为 03 2 1 47 9 86 5
15:使用类来调用线程:
import time from threading import Thread class Func(Thread): def __init__(self,args): super().__init__() self.args=args def run(self): time.sleep(1) print(self.args) for i in range(10): t=Func(i) t.start() 结果为 43 1 5 20 9 6 7 8
16.multprocessing在使用上模仿了Threading
17.看一下每个线程进行时的进程号:
import time import os from threading import Thread def func(n): time.sleep(1) print(os.getpid()) for i in range(10): t=Thread(target=func,args=(i,))#和进程方法一样 t.start() 结果为 3130031300 31300 31300 31300 31300 31300 31300 31300 31300
从结果来看,线程的进程号都一样,而且和主线程一致。
18.
import time import os from threading import Thread def func(a,b): n=a+b time.sleep(1) print(n,os.getpid()) for i in range(10): t=Thread(target=func,args=(i,5))#和进程方法一样 t.start() print('主进程',os.getpid()) 结果为 主进程 19760 59 19760 8 1176 10 19760 19760 19760 19760 19760 19760 12 1976014 19760 13 19760

19.再同一个进程中,进程中的数据,多个线程是共享的
20.进程是内存分配的最小单位;线程是cpu操作的最小单位。线程是被cpu执行了,每一个进程中至少包含一个线程;进程中至少可以开启多个线程;开启一个线程所消耗的时间要远远低于开启一个进程消耗的时间。
21.多个线程内部都有自己的数据栈,数据之间不共享;全局变量里的多个线程之间数据是共享的
22.在开启多个进程的过程中进行数据的处理,有时候会出现抢数据的情况,造成数据的不安全现象,因此在进程执行过程中使用了加锁程序;那么线程执行过程当中是否也会出现这样的问题,应该怎么解决:
在线程执行过程中也会出现这种问题:为了解决这种问题,cpython解释器做了一个全局解释器(GIL)同一时间只允许一个进程访问cpu(虽然这样·的执行又变成了同步执行,但是数据变得又安全起来)
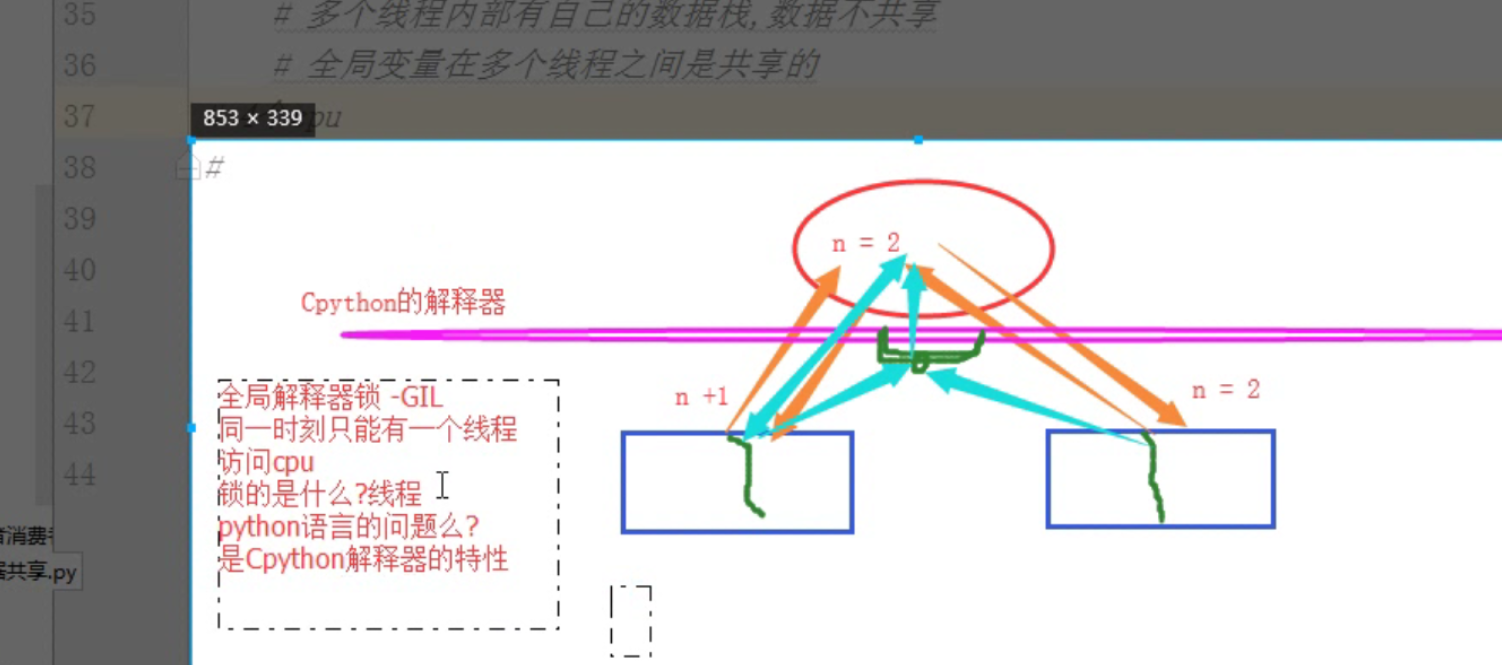
执行顺寻:
设置GIL——切换到一个线程进行执行——运行到指定数量的字节码指令或者线程主动让出控制(可以调用time.sleep(0)),把线程设置程睡眠状态;执行另一个进程——一次重复。
23 高cpu 计算类数据——高cpu利用率
24:高IO :爬取网页:200个网页;qq聊天 send 、recv;处理日志文件、读文件;处理web请求;读数据库、写数据库;
25.比较进程时间和线程时间:
from threading import Thread from multiprocessing import Process import time def work (n): n+1 if __name__=='__main__': t_list=[] start=time.time() for i in range(30): t=Thread(target=work,args=(i,)) t.start() t_list.append(t) for i in t_list: i.join() t1=time.time()-start print(t1) p_list=[] start=time.time() for i in range(30): p=Process(target=work,args=(i,)) p.start() p_list.append(p) for i in p_list:i.join() t2=time.time()-start print(t2)
注:当既有线程又有进程挂起时,我们需要把线程也要写到if里面否则也会报错
26.在开启多个进程的过程中,我们无法进行输入,只能进行其他的操作,但是在多个线程的执行过程中,是可以进行输入操作的:
from threading import Thread def func(i): msg= input('请输入%s'%i) print(msg) for i in range(10): t=Thread(target=func,args=(i,)) t.start() 结果为 请输入0请输入1请输入2请输入3请输入4请输入5请输入6请输入7请输入8请输入9 1 1 2 2 3 3 456 456 66 66
27使用多个线程进行tcp协议通信:
server端程序:
from threading import Thread import socket def func(conn): info=input('>>>').encode('utf-8') conn.send(info) msg=conn.recv(1024).decode('utf-8') print(msg) conn.close() sk=socket.socket() sk.bind(('127.0.0.1',8080)) sk.listen()
client端程序:
import socket sk=socket.socket() sk.connect(('127.0.0.1',8080)) msg=sk.recv(1024).decode('utf-8') print(msg) info=input('》》》').encode('utf-8') sk.send(info) sk.close()
28.进程是可以打印进程号的,那么线程应该怎样打印线程号那:
import threading def work(i): print('%s'%i,threading.current_thread()) for i in range(10): threading.Thread(target=work,args=(i,)).start() print(threading.current_thread()) 结果为 0 <Thread(Thread-1, started 16600)> 1 <Thread(Thread-2, started 17804)> 2 <Thread(Thread-3, started 15488)> 3 <Thread(Thread-4, started 10912)> 4 <Thread(Thread-5, started 16528)> 5 <Thread(Thread-6, started 20848)> 6 <Thread(Thread-7, started 12212)> 7 <Thread(Thread-8, started 13564)> 8 <Thread(Thread-9, started 10900)> 9 <Thread(Thread-10, started 3908)> <_MainThread(MainThread, started 20124)>
29进程中又pid号,那么线程的号应该怎么进行获取:
from threading import Thread,current_thread,get_ident def work(i): print('%s'%i,current_thread(),get_ident())#后面哪个使用来获取线程号的 for i in range(10): Thread(target=work,args=(i,)).start() print(current_thread(),get_ident()) #前面一个可以得到线程的名字
