

第二十天序列化模块和模块的调用:
1.序列化模块指的就是把其他的数据类型转换成字符串数据类型;序列化的数据类型必须是有序的,主要方法有三种:json、pickle、shelve
2为啥要用序列化模块:1.写文件时只能写入字符串文件,在文件的传输时,只能传输bytes类型。
3.从其他数据类型到字符串叫做序列化,反之叫做反序列化。
4.json 成为程序语言界通用的语言:所使用的数据类型主要是:整型、字符串、列表、元组(要把元组转换成列表在进行计算)
4.1json dumps序列化方法,loads反序列化方法:


import json dic={'k1':'v1','k2':'v2'} print(type(dic),dic) ret=json.dumps(dic) print(ret,type(ret)) 结果 <class 'dict'> {'k1': 'v1', 'k2': 'v2'} {"k1": "v1", "k2": "v2"} <class 'str'>
ret1=json.loads(ret) print(ret1,type(ret1)) 结果为 {'k1': 'v1', 'k2': 'v2'} <class 'dict'>
4.2dump和load操作:对文件操作时进行的修改:
import json dic={1:'a',2:'b'} f=open('fff','w',encoding='utf-8') json.dump(dic,f) f.close() f=open('fff') res=json.load(f) f.close() print(res) 结果为 {'1': 'a', '2': 'b'}
4.3dump和load操作时要先全部写入,然后再全部读取:会占据很大内存;
import json dic={1:'中国',2:'高工'} f=open('fff','w',encoding='utf-8') json.dump(dic,f)

改变这种:
import json dic={1:'中国',2:'高工'} f=open('fff','w',encoding='utf-8') json.dump(dic,f,ensure_ascii=False)

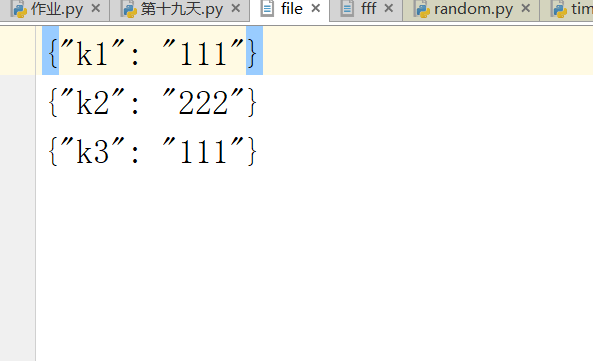
import json l=[{'k1':'111'},{'k2':'222'},{'k3':'111'}] f=open('file','w') import json for dic in l: str_dic=json.dumps(dic) f.write(str_dic+'\n') f.close() 结果为
import json f=open('file','r',encoding='utf-8') l=[] for line in f: l.append(dic) f.close() print(l)
5.pickle是将所有的python数据类型转换成字符串数据类型。pickle序列化只有python能理解,且部分反序列依赖pyton代码。
import pickle dic={'k1':'v1','k2':'v3','k3':'v3'} str_dic=pickle.dumps(dic) print(str_dic) dic2=pickle.loads(str_dic) print(dic2) 结果为 b'\x80\x03}q\x00(X\x02\x00\x00\x00k1q\x01X\x02\x00\x00\x00v1q\x02X\x02\x00\x00\x00k2q\x03X\x02\x00\x00\x00v3q\x04X\x02\x00\x00\x00k3q\x05h\x04u.' {'k1': 'v1', 'k2': 'v3', 'k3': 'v3'}
5.5
import time import pickle struct_time1=time.localtime(1000000000) struct_time2=time.localtime(000000000) f=open('pickle_file','wb') pickle.dump(struct_time1,f) pickle.dump(struct_time2,f) f.close() f=open('pickle_file','rb') ret1=pickle.load(f) ret2=pickle.load(f) print(ret1,ret2) f.close() 结果为 time.struct_time(tm_year=2001, tm_mon=9, tm_mday=9, tm_hour=9, tm_min=46, tm_sec=40, tm_wday=6, tm_yday=252, tm_isdst=0) time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=8, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=1, tm_isdst=0)
5.6pikle可以进行文件一行一行的写入和一行一行的读取,并且进行文件的读取和写入时必须以二进制的方式:
import pickle dic={'k1':'v1','k2':'v2'} f=open('file1','wb') pickle.dump(dic,f) pickle.dump(dic,f) f.close() f=open('file1','rb') ret1=pickle.load(f) ret2=pickle.load(f) f.close() print(ret1) print(ret2) 结果为 C:\pycharm\python.exe D:/python练习程序/第十七天/第二十一天.py {'k1': 'v1', 'k2': 'v2'} {'k1': 'v1', 'k2': 'v2'}
6.shelve模块:操作简单,使用时相当于拿到一个shelve句柄,可以随便使用:
import shelve f=shelve.open('shelve_file') f['key']={'int':10,'float':4.5,'string':'sample data'} f.close()
6.1由于shelve在默认情况下是不会记录持久化对象的任何修改记录,所以我们在shelve.open时要修改默认参数,否则对象的修改不会保存(可以对key进行修改,但是不能
添加值)
import shelve f=shelve.open('shelve_file') f['key']={'int':10,'float':4.5,'string':'sample data'} f.close() f1=shelve.open('shelve_file') f1_num=f1['key'] print(f1_num) 结果为 {'int': 10, 'float': 4.5, 'string': 'sample data'}
import shelve f=shelve.open('shelve_file') f['key']={'int':10,'float':4.5,'string':'sample data'} f.close() f1=shelve.open('shelve_file') f1['key']['nueer']='fkdjdkfje' f.close() f1=shelve.open('shelve_file') f1_num=f1['key'] print(f1_num) f.close() 结果为 {'int': 10, 'float': 4.5, 'string': 'sample data'}
6.2报错没有成功:
import shelve f=shelve.open('shelve_file') f['key']={'int':10,'float':4.5,'string':'sample data'} f.close() f1=shelve.open('shelve_file',writeback=True) f1['key']['fdkj']=134 print(f1['key']) print(f1['key']['fdkj']) f1.close() f2=shelve.open('shelve_file') f2_num=f2['key'] print(f2_num) 结果为 {'int': 10, 'float': 4.5, 'string': 'sample data', 'fdkj': 134} 134 {'int': 10, 'float': 4.5, 'string': 'sample data', 'fdkj': 134}
7.其实我们平时调用的模块就i是一个py文件。(即一些通用的功能写成一个文件,进行封装,等用的时候再去调用)
8.调用模块的第一种方法:import
import file1# import 函数名 file1.get() 结果为 fjdfji 100
9.如果多次调用多次模块,只执行一次:(原因是:调用时,先从sys.modules里查看是否已经倍导入,如果(没有就导入)已经导入就依据sys.path路径寻找模块,如果找到就导入,创建命名空间,执行文件,把文件中的名字都放入到命名空间里:
10.怎么查看是否存在次模块:
import sys print(sys.modules.keys())#查看调入内存中的模块 print(sys.path)#查看寻找模块的文件路径
11.import 模块名 as 重命名:主要用在使用不同的模块,但是有相同操作的时候:
if '数据库'=='oracle': import oracle as db elif '数据库'=='mysql': import mysql as db 连接数据库 db.connect 登陆认证 增删改查 关闭数据库
12 可以一次性调用多个模块,之间用逗号进行隔开:
import time, sys,collections
13.调用模块的第三种方式:from 模块 import 函数名
from time import sleep sleep(1)
14.如果调用模块中的名字与全局变量中的名字相同则会使用全局变量的名字:
mokey=200 from file1 import money print(mokey) 结果 200
15.调用模块的另一种方法:from 模块名 import *
from file1 import * print(money) get() 结果为 100 fjdfji 100
16.ifrom 模块名 import *中 all的用法:
from file1 import * print(money) get() 模块中: money=100 def get(): print('fjdfji',money) def func(): print('hello world') __all__=['func']#如果__all__里面有的才可以被调用 结果为 Traceback (most recent call last): File "D:/python练习程序/第二十天/module.py", line 24, in <module> get() NameError: name 'get' is not defined
17.所有内置函数都应该尽量往上写,写的顺序是:内置模块、扩展模块、自定义模块
print(__name__) 结果为 __main__
18.如果有些程序调用时不执行,但执行函数在执行,方法如下:
if __name=='__main__': #要执行的语句
