
网络爬虫—作者:王晓坤
网络爬虫作业
一、题目
羊车门作业已发布,很快就会有同学提交作业,在此作业基础上,我们发布本网络爬虫作业。
本作业共分两部分,第一部分必做,第二部分选作。
第一部分:
请分析作业页面,爬取已提交作业信息,并生成已提交作业名单,保存为英文逗号分隔的csv文件。文件名为:hwlist.csv 。
文件内容范例如下形式:
学号,姓名,作业标题,作业提交时间,作业URL
20194010101,张三,羊车门作业,2018-11-13 23:47:36.8,http://www.cnblogs.com/sninius/p/12345678.html
20194010102,李四,羊车门,2018-11-14 9:38:27.03,http://www.cnblogs.com/sninius/p/87654321.html
*注1:如制作定期爬去作业爬虫,请注意爬取频次不易太过密集;
*注2:本部分作业用到部分库如下所示:
(1)requests —— 第3方库
(2)json —— 内置库
第二部分:
在生成的 hwlist.csv 文件的同文件夹下,创建一个名为 hwFolder 文件夹,为每一个已提交作业的同学,新建一个以该生学号命名的文件夹,将其作业网页爬去下来,并将该网页文件存以学生学号为名,“.html”为扩展名放在该生学号文件夹中。
二、源代码
import requests import json import os import shutil import datetime import time #———————————————————————————————————————————————————————————————————————————————————————————————————————————————————— def GetUrl(url): '''爬取网页内容函数.参数:网址''' try: r = requests.get(url) #获取网页内容 r.raise_for_status() #返回异常,r.status_code是200,返回 None r.encoding = r.apparent_encoding # 转化编码, 根据r.apparent_encoding的结果转码 print('网页内容读取成功!') return r #返回网页内容 except: print("产生异常") #———————————————————————————————————————————————————————————————————————————————————————————————————————————————————— def CreatFolder(FolderName): ''' 创建文件夹函数,参数文件夹的名称(字符串)''' exist=os.path.exists(FolderName) #判断是否存在,存在返回真,否则返回假。 if not exist: os.mkdir(FolderName) print('{}文件夹创建成功!'.format(FolderName)) else: shutil.rmtree(FolderName) CreatFolder(FolderName) print('{}文件夹已存在,将其删除后重建!\n'.format(FolderName)) #————————————————————————————————————————————————————————————————————————————————————————————————————————————————— def HW(url): r0=GetUrl(url) #调用函数爬取网页 data0=json.loads(r0.text) #将json格式数据转换为字典 #创建hwlist.csv with open ('hwlist.csv','w')as f: zero=('学号',',','姓名',',','作业标题',',','作业提交时间',',','作业URL','\n') #写入第一行内容 f.writelines(zero) for i in data0['data']: xuehao=str(i['StudentNo'])+"\t" #在时间和日期后加上“\t”,转换为格式 date=i['DateAdded'].replace('T',' ')+"\t" #用EXCEL打开的时候,不会出现错误的形式 one=(xuehao,',',i['RealName'],',',i['Title'],',',date,',',i['Url'],'\n') f.writelines(one) #创建hwFolder文件夹 FolderName='hwFolder' CreatFolder(FolderName) os.chdir(FolderName) #进入hwFolder文件夹 #创建学生的文件夹和文件 for i in data0['data']: name=str(i['StudentNo']) #得到学号 CreatFolder(name) #创建以学号命名的文件夹 os.chdir(name) #进入以学号命名的文件夹 with open (name+'.html','wb') as fp: #覆盖写模式和二进制文件模式,对以学号命名.html文件 进行操作(必须以二进制文件模式) Url=i['Url'] r1=GetUrl(Url) #获取该学号同学羊车门作业的网页 fp.write(r1.content) #r1.content获取网页的内容,并写入以该同学学号命名.html文件中 #a=type(r1.content) #print(a) print("{}.html文件内容创建成功。\n".format(name)) os.chdir('..') #返回上一层目录,即hwFolder文件夹 #———————————————————————————————————————————————————————————————————————————————————————————————————————————————————— #定时爬取网页内容 #if __name__=='__main__': flag=0 #设定一个值 now=datetime.datetime.now() print(now) sched_timer=datetime.datetime(now.year, now.month, now.day, now.hour, now.minute, now.second) + datetime.timedelta(seconds=5) print(sched_timer) while (True): url="https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543326450118" now=datetime.datetime.now() if sched_timer<now<sched_timer+datetime.timedelta(seconds=5): time.sleep(1) HW(url) #运行函数 flag=1 else: if flag==1: sched_timer=sched_timer+datetime.timedelta(minutes=2) #2分钟后运行 flag=0 print("程序执行完成!!")
三、结果
第一次读取文件
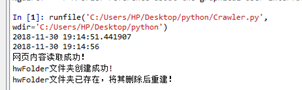
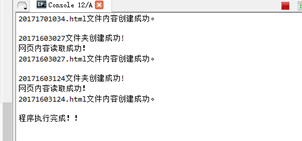
第二次读取文件
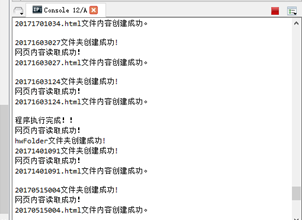
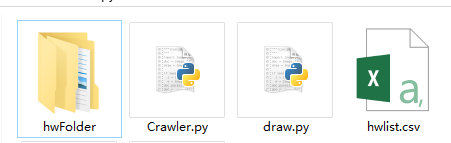
创建hwlist.csv文件,hwFloder文件夹
hwlist.csv文件内容

hwFloder文件夹
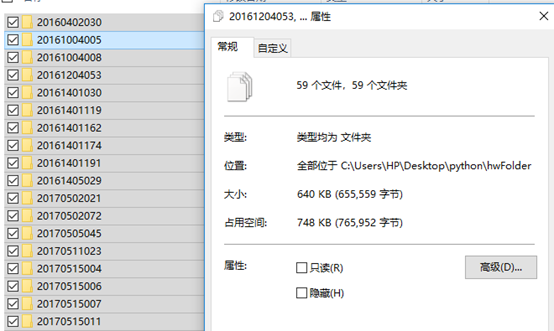
hwFloder文件夹,子文件夹中文件及内容

四、思考与总结
1.后缀为.csv的文件
最终的结果存储在一个.csv文件下。.csv文件默认以EXCLE打开,
但是,打开后结果显示,学号列没有完全显示,时间列没有显示年/月/日。

解决方法:
在学号和日期后面连接一个”\t”,(必须是双引号),可以将学号和日期显示出来。
更改后结果:
Excel中

记事本

拓展:
1.为什么选用后缀为.csv的文件?
(1)写csv文件的效率很高。2. csv文件的大小远远小于生成的Excel文件。并且随着Excel文件的变大存储效率会降低的。
(参见网页:http://www.blogjava.net/hongqiang/archive/2012/07/10/382668.html)
(2)有一个csv的模块
推荐网页(https://www.cnblogs.com/pyxiaomangshe/p/8026483.html)
2.用到一个shutil模块,shutil模块和os模块是对文件,文件夹操作的。
os.remove ——删除文件
os.mkdir ——删除空的文件夹
shutil. rmtree ——递归删除非空文件夹,
网址:https://blog.csdn.net/huilaojia123/article/details/53939845
https://www.aliyun.com/jiaocheng/480630.html
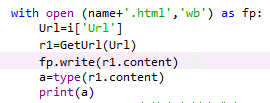
3.with open (name+'.html','wb') as fp:
注:只能用”wb”写,b:二进制文件模式.因为r1.content,他的类型是<class 'bytes'>

4.Requests库
爬取网页内容可以自定义一个函数,增加判断条件,增强代码健壮性!

https://www.cnblogs.com/hanbb/p/7221659.html?utm_source=itdadao&utm_medium=referral
4. if __name__ == '__main__' 的解释
https://blog.csdn.net/yjk13703623757/article/details/77918633/
5.定时爬取网页内容参考的网页
https://blog.csdn.net/qq807237096/article/details/78794039
6. datetime模块
https://blog.csdn.net/cmzsteven/article/details/64906245
https://www.cnblogs.com/wenBlog/p/6023742.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号