LDA模型笔记
“LDA(Latent Dirichlet Allocation)模型,模型主要解决文档处理领域的问题,比如文章主题分类、文章检测、相似度分析、文本分段和文档检索等问题。
LDA主题模型是一个三层贝叶斯概率模型,包含词、主题、文档三层结构,文档到主题服从Dirichlet分布,主题到词服从多项式分布。它采用了词袋(Bag of Words)的方法,
将每一篇文章视为一个词频向量,每一篇文档代表了一些主题所构成的概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
利用LDA模型对用户参与的话题文本进行分析,得到用户在给定虚拟主题下对每个主题感兴趣的概率分布,从而挖掘出用户的兴趣偏好。“
摘自《基于社交关系和影响力的在线社交网络用户兴趣偏好获取方法研究》
对LDA的理解,可参考:主题模型-LDA浅析
我对LDA的理解主要是抓住公式:

和图
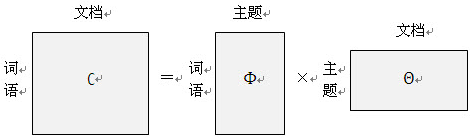
其中“给定一系列文档,通过对文档进行分词,计算各个文档中每个单词的词频就可以得到左边这边”文档-词语”矩阵。主题模型就是通过左边这个矩阵进行训练,学习出右边两个矩阵。“
左边的矩阵就是每一个词语在每篇文章中出现的频率的矩阵,“学习出右边两个矩阵“,如何学习?其实就是矩阵分解,把左边的矩阵分解为右边的两个矩阵,可以采用SVD等矩阵分解方法,得到右边的两个矩阵之后,主要是如何利用这两个矩阵?其中“文档-主题“矩阵,单看其中的一列,就是某个文档的内容讲的是各个主题的概率,例如,文档1属于主题1的概率是0.1,属于主题2的概率是0.5,属于主题3的概率是0.8,...这其中概率最大的那个主题topic X,我们就可以认为,这个文档就属于主题topic X。由此,因为我们可以通过此方法判断文档的主题类型,所以我们就能判断两个不同的文档是否属于相同的主题,也就是可以达到文档归类的目的。
至于图中,“主题-词语“矩阵、"文档-主题"矩阵中的主题到底是啥,是不可知的,这其实也是可以理解的,因为任何一个词语都有可能出现在关于任何一个主题的文章中。
其他:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号