What’s the Difference Between Deep Learning Training and Inference?
That’s how to think about deep neural networks going through the “training” phase. Neural networks get an education for the same reason most people do — to learn to do a job.
More specifically, the trained neural network is put to work out in the digital world using what it has learned — to recognize images, spoken words, a blood disease, predict the next word or phrase in a sentence, or suggest the shoes someone is likely to buy next, you name it — in the streamlined form of an application. This speedier and more efficient version of a neural network infers things about new data it’s presented with based on its training. In the AI lexicon this is known as “inference.”
Inference can’t happen without training. Makes sense. That’s how we gain and use our own knowledge for the most part. And just as we don’t haul around all our teachers, a few overloaded bookshelves and a red-brick schoolhouse to read a Shakespeare sonnet, inference doesn’t require all the infrastructure of its training regimen to do its job well.
So let’s break down the progression from AI training to AI inference, and how they both function.
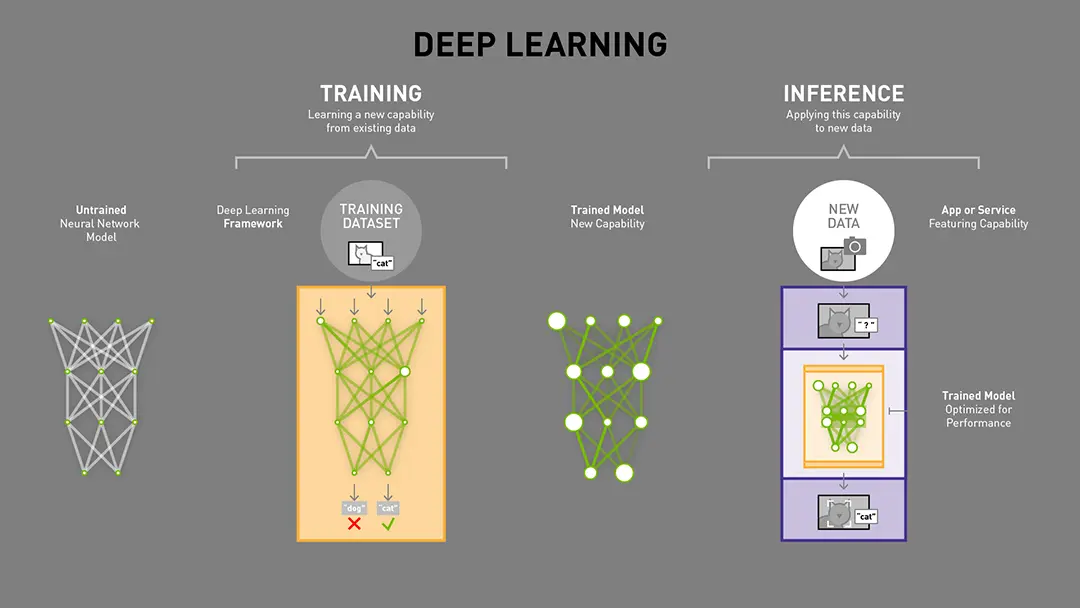
Training Deep Neural Networks
While the goal is the same – knowledge — the educational process, or training, of a neural network is (thankfully) not quite like our own. Neural networks are loosely modeled on the biology of our brains — all those interconnections between the neurons. Unlike our brains, where any neuron can connect to any other neuron within a certain physical distance, artificial neural networks have separate layers, connections, and directions of data propagation.
When training a neural network, training data is put into the first layer of the network, and individual neurons assign a weighting to the input — how correct or incorrect it is — based on the task being performed.
To learn more, check out NVIDIA’s AI inference solutions for the data center, self-driving cars, video analytics and more.
In an image recognition network, the first layer might look for edges. The next might look for how these edges form shapes — rectangles or circles. The third might look for particular features — such as shiny eyes and button noses. Each layer passes the image to the next, until the final layer and the final output determined by the total of all those weightings is produced.
But here’s where the training differs from our own. Let’s say the task was to identify images of cats. The neural network gets all these training images, does its weightings and comes to a conclusion of cat or not. What it gets in response from the training algorithm is only “right” or “wrong.”
Deep Learning Training Is Compute Intensive
And if the algorithm informs the neural network that it was wrong, it doesn’t get informed what the right answer is. The error is propagated back through the network’s layers and it has to guess at something else. In each attempt it must consider other attributes — in our example attributes of “catness” — and weigh the attributes examined at each layer higher or lower. Then it guesses again. And again. And again. Until it has the correct weightings and gets the correct answer practically every time. It’s a cat.

Now you have a data structure and all the weights in there have been balanced based on what it has learned as you sent the training data through. It’s a finely tuned thing of beauty. The problem is, it’s also a monster when it comes to consuming compute. For example, GPT-3 with 175 billion parameters requires roughly 300 zettaflops, which is 300,000 billion billion math operations across the entire training cycle. Try getting that to run on a smartphone.
That’s where inference comes in.
Congratulations! Your Neural Network Is Trained and Ready for Inference
What you had to put in place to get your properly weighted neural network to learn — in our education analogy all those pencils, books, teacher’s dirty looks — is now way more than you need to get any specific task accomplished.
If anyone is going to make use of all that training in the real world, and that’s the whole point, what you need is a speedy application that can retain the learning and apply it quickly to data it’s never seen. That’s inference: taking smaller batches of real-world data and quickly coming back with the same correct answer (really a prediction that something is correct).
There are two main approaches to taking that hulking neural network and modifying it for speed and improved latency in applications that run across other networks.
How AI Inferencing Works
The first approach looks at parts of the neural network that don’t get activated after it’s trained. These sections just aren’t needed and can be “pruned” away. The second approach looks for ways to fuse multiple layers of the neural network into a single computational step.
It’s akin to the compression that happens to a digital image. Designers might work on these huge, beautiful, million pixel-wide and tall images, but when they go to put it online, they’ll turn into a jpeg. It’ll be almost exactly the same, indistinguishable to the human eye, but at a smaller resolution. Similarly with inference you’ll get almost the same accuracy of the prediction, but simplified, compressed and optimized for runtime performance.
What that means is we all use inference all the time. Your smartphone’s voice-activated assistant uses inference, as do image search and spam filtering applications. Facebook’s image recognition and Amazon’s and Netflix’s recommendation engines all rely on inference.
GPUs, thanks to their parallel computing capabilities — or ability to do many things at once — are good at both training and inference.
Systems trained with GPUs allow computers to identify patterns and objects as well as — or in some cases, better than — humans (see “Accelerating AI with GPUs: A New Computing Model”).
After training is completed, the networks are deployed into the field for “inference” — classifying data to “infer” a result. Here too, GPUs — and their parallel computing capabilities — offer benefits, where they run billions of computations based on the trained network to identify known patterns or objects.
The parallel computing of GPUs also provides multi-factor speedups in traditional machine learning, using algorithms like gradient-boosted decision trees, for both training and inference.
You can see how these models and applications will just get smarter, faster and more accurate. Inference will bring new applications to every aspect of our lives. It seems the same admonition applies to AI as it does to our youth — don’t be a fool, stay in school. Inference awaits.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号