模块与包
在编程语言中,代码块、函数、类、模块,一直到包,逐级封装,层层调用。在Python中,一个.py文件就是一个模块,模块是比类更高一级的封装。在其他语言,被导入的模块也通常称为库。
模块可以分为自定义模块、内置模块和第三方模块。自定义模块就是你自己编写的模块,如果你自认水平很高,也可以申请成为Python内置的标准模块之一!如果你在网上发布自己的模块并允许他人使用,那么就变成了第三方模块。内置模块是Python“内置电池”哲学的体现,在安装包里就提供了跨平台的一系列常用库,涉及方方面面。第三方模块的数量非常庞大,有许多非常有名并且影响广泛的模块,比如Django。
使用模块有什么好处?
-
首先,提高了代码的可维护性。
-
其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他的模块引用。不要重复造轮子,我们简简单单地使用已经有的模块就好了。
-
使用模块还可以避免类名、函数名和变量名发生冲突。相同名字的类、函数和变量完全可以分别存在不同的模块中。但是也要注意尽量不要与内置函数名(类名)冲突。
为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package),包是模块的集合,比模块又高一级的封装。没有比包更高级别的封装,但是包可以嵌套包,就像文件目录一样,如下图:
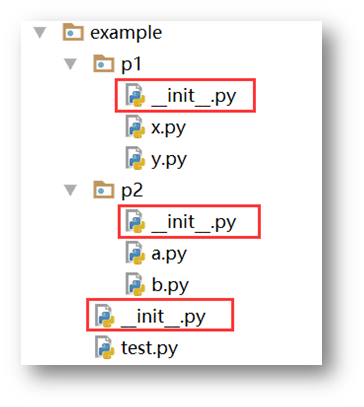
最顶层的Django包封装了contrib子包,contrib包又封装了auth等子包,auth又有自己的子包和一系列模块。通过包的层层嵌套,我们能够划分出一个又一个的命名空间。
包名通常为全部小写,避免使用下划线。
要在我们的程序中,使用其它的模块(包、类、函数),就必须先导入对应的模块(包、类、函数)。在Python中,模块(包、类、函数)的导入方式有以下四种:
import xx.xxfrom xx.xx import xxfrom xx.xx import xx as renamefrom xx.xx import *
对于xx.xx的说明:
由于一个模块可能会被一个包封装起来,而一个包又可能会被另外一个更大的包封装起来,所以我们在导入的时候,需要提供导入对象的绝对路径,也就是“最顶层的包名.次一级包名.(所有级别的包名).模块名.类名.函数名”。类似文件系统的路径名,只是用圆点分隔的。
有时候,模块名就在搜索路径根目录下,那么可以直接import 模块名,比如Python内置的一些标准模块,os、sys、time等等。
大多数时候,我们不需要直接导入到函数的级别,只需要导入到模块级别或者类的级别,就只需要使用import Django.contrib.auth.models导入models模块,以后使用models.User来引用models模块中的类。
总之,对于xx.xx,你想导入到哪个级别,取决于你的需要,可以灵活调整,没有固定的规则。
1. import xx.xx
这会将对象(这里的对象指的是包、模块、类或者函数,下同)中的所有内容导入。如果该对象是个模块,那么调用对象内的类、函数或变量时,需要以module.xxx的方式。
比如,被导入的模块Module_a:
# Module_a.py
def func():
print("this is module A!")
在Main.py中导入Module_a:
# Main.py
import module_a
module_a.func() # 调用方法
2. From xx.xx import xx.xx
从某个对象内导入某个指定的部分到当前命名空间中,不会将整个对象导入。这种方式可以节省写长串导入路径的代码,但要小心名字冲突。
在Main.py中导入Module_a:
# Main.py
from module_a import func
module_a.func() # 错误的调用方式
func() # 这时需要直接调用func
3. from xx.xx import xx as rename
为了避免命名冲突,在导入的时候,可以给导入的对象重命名。
# Main.py
from module_a import func as f
def func(): ## main模块内部已经有了func函数
print("this is main module!")
func()
f()
4. from xx.xx import *
将对象内的所有内容全部导入。非常容易发生命名冲突,请慎用!
# Main.py
from module_a import *
def func():
print("this is main module!")
func() # 从module导入的func被main的func覆盖了
执行结果:this is main module!
模块搜索路径
不管你在程序中执行了多少次import,一个模块只会被导入一次。这样可以防止一遍又一遍地导入模块,节省内存和计算资源。那么,当使用import语句的时候,Python解释器是怎样找到对应的文件的呢?
Python根据sys.path的设置,按顺序搜索模块。
>>> import sys
>>> sys.path
['', 'C:\\Python36\\Lib\\idlelib', 'C:\\Python36\\python36.zip', 'C:\\Python36\\DLLs', 'C:\\Python36\\lib', 'C:\\Python36', 'C:\\Python36\\lib\\site-packages']
当然,这个设置是可以修改的,就像windows系统环境变量中的path一样,可以自定义。 通过sys.path.append('路径')的方法为sys.path路径列表添加你想要的路径。
import sys
import os
new_path = os.path.abspath('../')
sys.path.append(new_path)
默认情况下,模块的搜索顺序是这样的:
- 当前执行脚本所在目录
- Python的安装目录
- Python安装目录里的site-packages目录
其实就是“自定义”——>“内置”——>“第三方”模块的查找顺序。任何一步查找到了,就会忽略后面的路径,所以模块的放置位置是有区别的。
实例讲解
在自定义模块的时候,对模块的命名一定要注意,不要和官方标准模块以及一些比较有名的第三方模块重名,一有不慎,就容易出现模块导入错误的情况发生。
- 在Pycharm里建个py文件
abc.py,写入代码:
def my_abs():
print("my_abs!")
if __name__ == '__main__':
my_abs()
- 同级目录下再建个
main.py,代码如下:
from abc import my_abs
my_abs()
- 运行main.py,出错了,错误信息如下:
Fatal Python error: Py_Initialize: can't initialize sys standard streams Traceback (most recent call last): File "C:\Python36\lib\io.py", line 72, in <module> AttributeError: module 'abc' has no attribute 'ABCMeta'
怎么会抛出一个属性错误异常,提示模块abc没有属性ABCMeta呢?我们的代码很简单,根本没有什么ABCMeta。
再到命令行界面中,执行一下看看吧。
D:\>python abc.py
my_abs!
D:\>python main.py
Traceback (most recent call last):
File "main.py", line 2, in <module>
from abc import my_abs
ImportError: cannot import name 'my_abs'
D:\>python
Python 3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 18:41:36) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from abc import my_abs
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: cannot import name 'my_abs'
问题变成了ImportError,无法导入my_abs。
到底是什么原因呢?让我们分析一下!
-
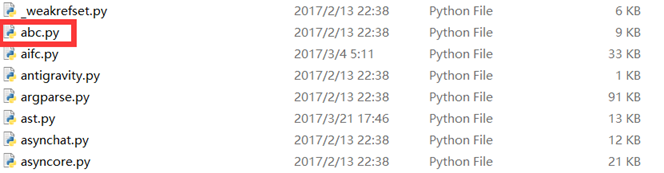
Python有个内置模块
abc.py,是不是这个原因呢?在Python的lib文件夹中可以找到如下图的内置标准模块abc.py文件。 -
可是我们是在同级目录下导入
abc的,按照前面的模块查询顺序,不是先找本地目录吗? -
按照2的分析,自定义的
abc.py文件会短路掉Python内置的abc模块,不应该有问题。(虽然这是不好的做法,但从程序角度上没问题。) -
通过查看源码发现真实的原因是print语句需要调用io模块,而io模块又要调用Python内置的abc模块,但此时的abc命名空间被自定义的模块覆盖了,因而发生错误。
总结:千万不要和内置模块或常用第三方模块同名!否则,哪怕你认为自己掌控着一切,也有可能会发生各种意想不到的结果!
包(Package):
前面我们已经介绍过,包是一种管理模块的手段,采用“包名.子包名.....模块名”的调用形式,非常类似文件系统中的文件目录。但是包不等于文件目录!
只有包含__init__.py文件的目录才会被认作是一个包!
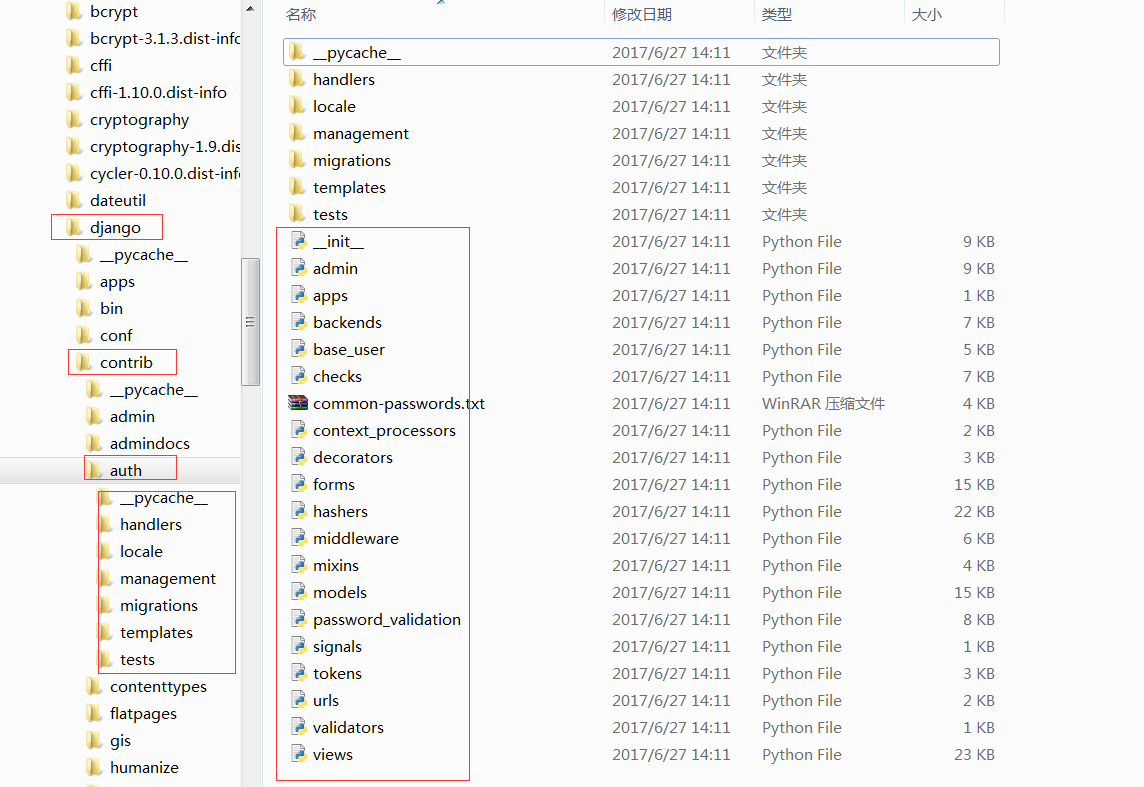
上图中的example、p1和p2都是包,因为它们目录内都有__init__.py文件,并且p1和p2是example的子包。
__init__.py可以是空文件,也可以有Python代码,__init__.py本身就是一个模块,但是要注意,它的模块名是它所在的包名而不是__init__。
就上图,举个包和模块之间调用的例子:
# example\p1\x.py
def show():
print("this is module x")
# example\p2\a.py
import example.p1.x
def show():
print("this is modula a")
example.p1.x.show()
show()
运行a.py的结果:
this is module x this is modula a
设想一下,如果我们使用from example.p1 import *会发生什么?
Python会进入文件系统,找到这个包里面所有的子模块,一个一个的把它们都导入进来。 但是这个方法有风险,有可能导入的模块和已有的模块冲突,或者并不需要导入所有的模块。为了解决这个问题,需要提供一个精确的模块索引。这个索引要放置在__init__.py中。
如果包定义文件__init__.py中存在一个叫做__all__的列表变量,那么在使用from package import *的时候就把这个列表中的所有名字作为要导入的模块名。
例如在example/p1/__init__.py中包含如下代码:
__all__ = ["x"]
这表示当你使用from example.p1 import *这种用法时,你只会导入包里面的x子模块。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号