
知识图谱基本概念
这是我阅读知乎专栏https://zhuanlan.zhihu.com/knowledgegraph上的文章做的一些笔记。详细的内容可以去原文了解。
语义网络(semantic networks)
用相互连接的节点和边来表示知识。节点表示对象、概念,边表示节点之间的关系。
优点:
1、容易理解和展示; 2、相关概念容易聚类
缺点:
1、 节点和边的值没有标准,完全是由用户自己定义。
2、 多源数据融合比较困难,因为没有标准。
3、 无法区分概念节点和对象节点。
4、 无法对节点和边的标签(label)进行定义。
RDF解决了1和2两个缺点,在节点和边的取值上做了约束,制定了统一标准,为多源数据的融合提供了便利。
RDFS和OWL克服了3和4两个缺点,
语义网(semantic web)和链接数据(linked data)
语义网正是为了使得网络上的数据变得机器可读而提出的一个通用框架。“Semantic”就是用更丰富的方式来表达数据背后的含义,让机器能够理解数据。“Web”则是希望这些数据相互链接,组成一个庞大的信息网络,正如互联网中相互链接的网页,只不过基本单位变为粒度更小的数据。
知识图谱(knowledge graph)
知识图谱是由本体(Ontology)作为Schema层,和RDF数据模型兼容的结构化数据集。
知识图谱的基石:RDF
1、RDF的表现形式
RDF(Resource Description Framework),即资源描述框架,其本质是一个数据模型(Data Model)。它提供了一个统一的标准,用于描述实体/资源。简单来说,就是表示事物的一种方法和手段。RDF形式上表示为SPO三元组,有时候也称为一条语句(statement),知识图谱中我们也称其为一条知识,如下图。
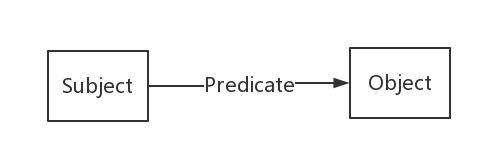
RDF由节点和边组成,节点表示实体/资源、属性,边则表示了实体和实体之间的关系以及实体和属性的关系。
2、RDF序列化方法
RDF的表示形式和类型有了,那我们如何创建RDF数据集,将其序列化(Serialization-怎么存储和传输RDF数据)呢?目前,RDF序列化的方式主要有:RDF/XML,N-Triples,Turtle,RDFa,JSON-LD等几种。
- RDF/XML,顾名思义,就是用XML的格式来表示RDF数据。之所以提出这个方法,是因为XML的技术比较成熟,有许多现成的工具来存储和解析XML。然而,对于RDF来说,XML的格式太冗长,也不便于阅读,通常我们不会使用这种方式来处理RDF数据。
- N-Triples,即用多个三元组来表示RDF数据集,是最直观的表示方法。在文件中,每一行表示一个三元组,方便机器解析和处理。开放领域知识图谱DBpedia通常是用这种格式来发布数据的。
- Turtle, 应该是使用得最多的一种RDF序列化方式了。它比RDF/XML紧凑,且可读性比N-Triples好。
- RDFa, 即“The Resource Description Framework in Attributes”,是HTML5的一个扩展,在不改变任何显示效果的情况下,让网站构建者能够在页面中标记实体,像人物、地点、时间、评论等等。也就是说,将RDF数据嵌入到网页中,搜索引擎能够更好的解析非结构化页面,获取一些有用的结构化信息。读者可以去这个页面感受一下RDFa,其直观展示了普通用户看到的页面,浏览器看到的页面和搜索引擎解析出来的结构化信息。
- JSON-LD,即“JSON for Linking Data”,用键值对的方式来存储RDF数据。感兴趣的读者可以参考此网站。
结合罗纳尔多的例子,给出其N-Triples和Turtle的具体表示。
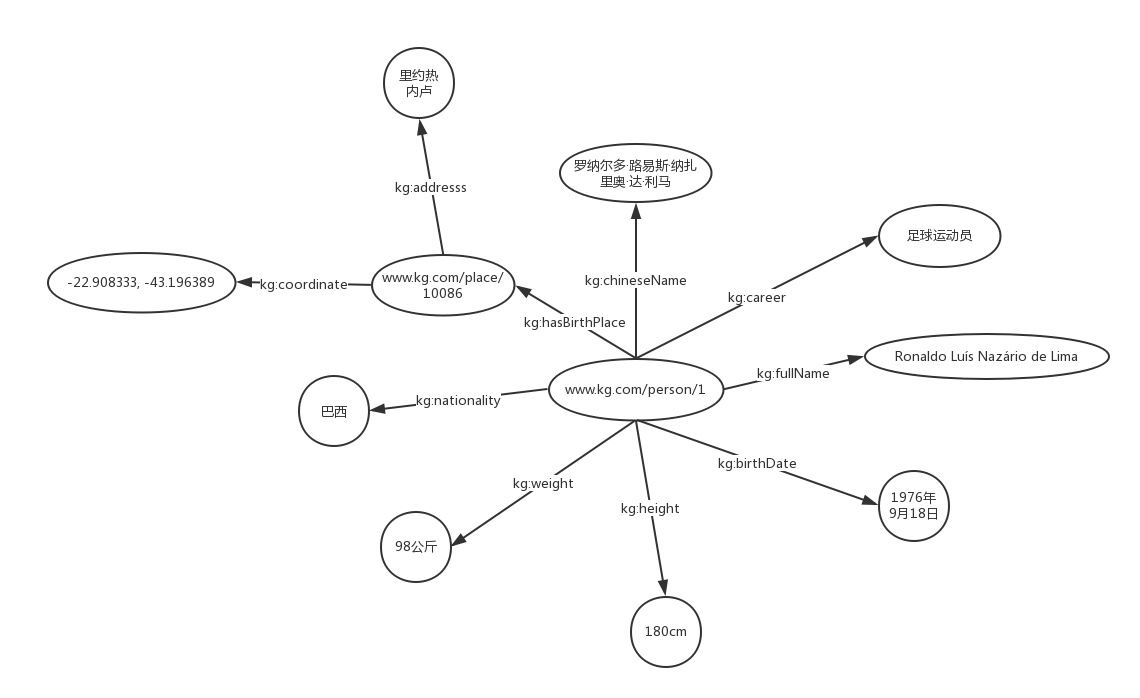
example 1: N-Triples:
1 <http://www.kg.com/person/1> <http://www.kg.com/ontology/chineseName> "罗纳尔多·路易斯·纳萨里奥·德·利马"^^string. 2 <http://www.kg.com/person/1> <http://www.kg.com/ontology/career> "足球运动员"^^string. 3 <http://www.kg.com/person/1> <http://www.kg.com/ontology/fullName> "Ronaldo Luís Nazário de Lima"^^string. 4 <http://www.kg.com/person/1> <http://www.kg.com/ontology/birthDate> "1976-09-18"^^date. 5 <http://www.kg.com/person/1> <http://www.kg.com/ontology/height> "180"^^int. 6 <http://www.kg.com/person/1> <http://www.kg.com/ontology/weight> "98"^^int. 7 <http://www.kg.com/person/1> <http://www.kg.com/ontology/nationality> "巴西"^^string. 8 <http://www.kg.com/person/1> <http://www.kg.com/ontology/hasBirthPlace> <http://www.kg.com/place/10086>. 9 <http://www.kg.com/place/10086> <http://www.kg.com/ontology/address> "里约热内卢"^^string. 10 <http://www.kg.com/place/10086> <http://www.kg.com/ontology/coordinate> "-22.908333, -43.196389"^^string.
用Turtle表示的时候我们会加上前缀(Prefix)对RDF的IRI进行缩写。
example 2: Turtle:
@prefix person: <http://www.kg.com/person/> . @prefix place: <http://www.kg.com/place/> . @prefix : <http://www.kg.com/ontology/> . person:1 :chineseName "罗纳尔多·路易斯·纳萨里奥·德·利马"^^string. person:1 :career "足球运动员"^^string. person:1 :fullName "Ronaldo Luís Nazário de Lima"^^string. person:1 :birthDate "1976-09-18"^^date. person:1 :height "180"^^int. person:1 :weight "98"^^int. person:1 :nationality "巴西"^^string. person:1 :hasBirthPlace place:10086. place:10086 :address "里约热内卢"^^string. place:10086 :coordinate "-22.908333, -43.196389"^^string.
同一个实体拥有多个属性(数据属性)或关系(对象属性),我们可以只用一个subject来表示,使其更紧凑。我们可以将上面的Turtle改为:
example 3: Turtle:
@prefix person: <http://www.kg.com/person/> . @prefix place: <http://www.kg.com/place/> . @prefix : <http://www.kg.com/ontology/> . person:1 :chineseName "罗纳尔多·路易斯·纳萨里奥·德·利马"^^string; :career "足球运动员"^^string; :fullName "Ronaldo Luís Nazário de Lima"^^string; :birthDate "1976-09-18"^^date; :height "180"^^int; :weight "98"^^int; :nationality "巴西"^^string; :hasBirthPlace place:10086. place:10086 :address "里约热内卢"^^string; :coordinate "-22.908333, -43.196389"^^string.
即,将一个实体用一个句子表示(这里的句子指的是一个英文句号“.”)而不是多个句子,属性间用分号隔开。
3、RDF的表达能力
RDF的表达能力有限,无法区分类和对象,也无法定义和描述类的关系/属性。我的理解是,RDF是对具体事物的描述,缺乏抽象能力,无法对同一个类别的事物进行定义和描述。就以罗纳尔多这个知识图为例,RDF能够表达罗纳尔多和里约热内卢这两个实体具有哪些属性,以及它们之间的关系。但如果我们想定义罗纳尔多是人,里约热内卢是地点,并且人具有哪些属性,地点具有哪些属性,人和地点之间存在哪些关系,这个时候RDF就表示无能为力了。不论是在智能的概念上,还是在现实的应用当中,这种泛化抽象能力都是相当重要的;同时,这也是知识图谱本身十分强调的。RDFS和OWL这两种技术或者说模式语言/本体语言(schema/ontology language)解决了RDF表达能力有限的困境。
RDF的衣服——RDFS和OWL
之所以说RDFS/OWL是RDF的“衣服”,因为它们都是用来描述RDF数据的。为了不显得这么抽象,我们可以用关系数据库中的概念进行类比。用过Mysql的读者应该知道,其database也被称作schema。这个schema和我们这里提到的schema language十分类似。我们可以认为数据库中的每一张表都是一个类(Class),表中的每一行都是该类的一个实例或者对象(学过java等面向对象的编程语言的读者很容易理解)。表中的每一列就是这个类所包含的属性。如果我们是在数据库中来表示人和地点这两个类别,那么为他们分别建一张表就行了;再用另外一张表来表示人和地点之间的关系。RDFS/OWL本质上是一些预定义词汇(vocabulary)构成的集合,用于对RDF进行类似的类定义及其属性的定义。
Notice: RDFS/OWL序列化方式和RDF没什么不同,其实在表现形式上,它们就是RDF。其常用的方式主要是RDF/XML,Turtle。另外,通常我们用小写开头的单词或词组来表示属性,大写开头的表示类。数据属性(data property,实体和literal字面量的关系)通常由名词组成,而对象数据(object property,实体和实体之间的关系)通常由动词(has,is之类的)加名词组成。剩下的部分符合驼峰命名法。为了将它们表示得更清楚,避免读者混淆,之后我们都会默认这种命名方式。读者实践过程中命名方式没有强制要求,但最好保持一致。
1、轻量级的模式语言——RDFS
RDFS,即“Resource Description Framework Schema”,是最基础的模式语言。还是以罗纳尔多知识图为例,我们在概念、抽象层面对RDF数据进行定义。下面的RDFS定义了人和地点这两个类,及每个类包含的属性。
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix : <http://www.kg.com/ontology/> . ### 这里我们用词汇rdfs:Class定义了“人”和“地点”这两个类。 :Person rdf:type rdfs:Class. :Place rdf:type rdfs:Class. ### rdfs当中不区分数据属性和对象属性,词汇rdf:Property定义了属性,即RDF的“边”。 :chineseName rdf:type rdf:Property; rdfs:domain :Person; rdfs:range xsd:string . :career rdf:type rdf:Property; rdfs:domain :Person; rdfs:range xsd:string . :fullName rdf:type rdf:Property; rdfs:domain :Person; rdfs:range xsd:string . :birthDate rdf:type rdf:Property; rdfs:domain :Person; rdfs:range xsd:date . :height rdf:type rdf:Property; rdfs:domain :Person; rdfs:range xsd:int . :weight rdf:type rdf:Property; rdfs:domain :Person; rdfs:range xsd:int . :nationality rdf:type rdf:Property; rdfs:domain :Person; rdfs:range xsd:string . :hasBirthPlace rdf:type rdf:Property; rdfs:domain :Person; rdfs:range :Place . :address rdf:type rdf:Property; rdfs:domain :Place; rdfs:range xsd:string . :coordinate rdf:type rdf:Property; rdfs:domain :Place; rdfs:range xsd:string .
我们这里只介绍RDFS几个比较重要、常用的词汇:
1. rdfs:Class. 用于定义类。
2. rdfs:domain. 用于表示该属性属于哪个类别。
3. rdfs:range. 用于描述该属性的取值类型。
4. rdfs:subClassOf. 用于描述该类的父类。比如,我们可以定义一个运动员类,声明该类是人的子类。
5. rdfs:subProperty. 用于描述该属性的父属性。比如,我们可以定义一个名称属性,声明中文名称和全名是名称的子类。
其实rdf:Property和rdf:type也是RDFS的词汇,因为RDFS本质上就是RDF词汇的一个扩展。我们在这里不罗列进去,是不希望读者混淆。RDFS其他的词汇及其用法请参考W3C官方文档。
为了让读者更直观地理解RDF和RDFS/OWL在知识图谱中所代表的层面,我们用下面的图来表示例子中的数据层和模式层。
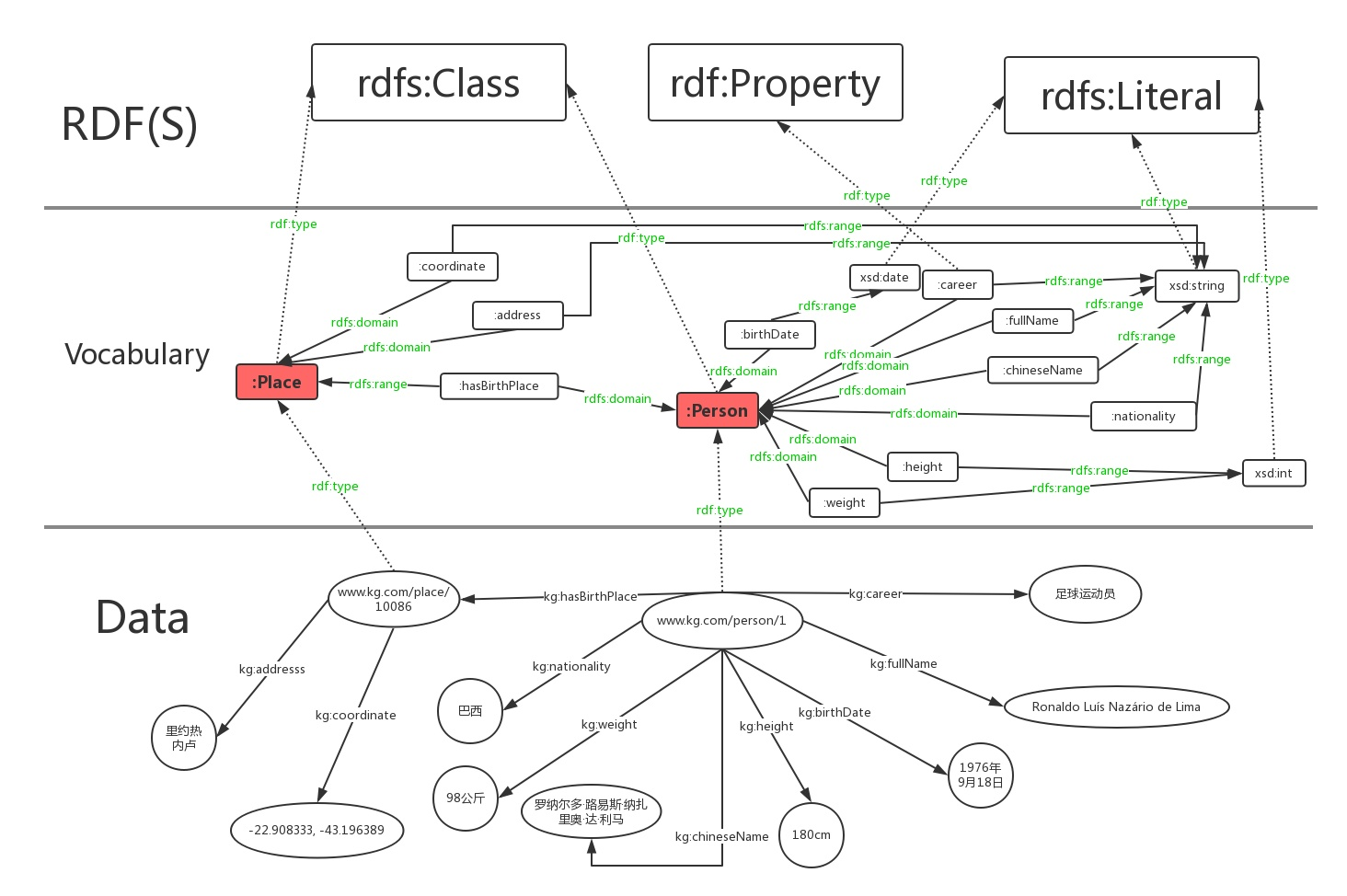
Data层是我们用RDF对罗纳尔多知识图的具体描述,Vocabulary是我们自己定义的一些词汇(类别,属性),RDF(S)则是预定义词汇。从下到上是一个具体到抽象的过程。图中我们用红色圆角矩形表示类,绿色字体表示rdf:type,rdfs:domain,rdfs:range三种预定义词汇,虚线表示rdf:type这种所属关系。另外,为了减少图中连线的交叉,我们只保留了career这一个属性的rdf:type所属关系,省略了其他属性的此关系。
2、RDFS的扩展——OWL
上面我们提到,RDFS本质上是RDF词汇的一个扩展。后来人们发现RDFS的表达能力还是相当有限,因此提出了OWL。我们也可以把OWL当做是RDFS的一个扩展,其添加了额外的预定义词汇。
OWL,即“Web Ontology Language”,语义网技术栈的核心之一。OWL有两个主要的功能:
1. 提供快速、灵活的数据建模能力。
2. 高效的自动推理。
我们先谈如何利用OWL进行数据建模。用OWL对罗纳尔多知识图进行语义层的描述:
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix : <http://www.kg.com/ontology/> . @prefix owl: <http://www.w3.org/2002/07/owl#> . ### 这里我们用词汇owl:Class定义了“人”和“地点”这两个类。 :Person rdf:type owl:Class. :Place rdf:type owl:Class. ### owl区分数据属性和对象属性(对象属性表示实体和实体之间的关系)。词汇owl:DatatypeProperty定义了数据属性,owl:ObjectProperty定义了对象属性。 :chineseName rdf:type owl:DatatypeProperty; rdfs:domain :Person; rdfs:range xsd:string . :career rdf:type owl:DatatypeProperty; rdfs:domain :Person; rdfs:range xsd:string . :fullName rdf:type owl:DatatypeProperty; rdfs:domain :Person; rdfs:range xsd:string . :birthDate rdf:type owl:DatatypeProperty; rdfs:domain :Person; rdfs:range xsd:date . :height rdf:type owl:DatatypeProperty; rdfs:domain :Person; rdfs:range xsd:int . :weight rdf:type owl:DatatypeProperty; rdfs:domain :Person; rdfs:range xsd:int . :nationality rdf:type owl:DatatypeProperty; rdfs:domain :Person; rdfs:range xsd:string . :hasBirthPlace rdf:type owl:ObjectProperty; rdfs:domain :Person; rdfs:range :Place . :address rdf:type owl:DatatypeProperty; rdfs:domain :Place; rdfs:range xsd:string . :coordinate rdf:type owl:DatatypeProperty; rdfs:domain :Place; rdfs:range xsd:string .
schema层的描述语言换为OWL后,层次图表示为:

数据属性用青色表示,对象属性由蓝色表示。
罗纳尔多这个例子不能展现OWL丰富的表达能力,我们这里简单介绍一下常用的词汇:
描述属性特征的词汇
1. owl:TransitiveProperty. 表示该属性具有传递性质。例如,我们定义“位于”是具有传递性的属性,若A位于B,B位于C,那么A肯定位于C。
2. owl:SymmetricProperty. 表示该属性具有对称性。例如,我们定义“认识”是具有对称性的属性,若A认识B,那么B肯定认识A。
3. owl:FunctionalProperty. 表示该属性取值的唯一性。 例如,我们定义“母亲”是具有唯一性的属性,若A的母亲是B,在其他地方我们得知A的母亲是C,那么B和C指的是同一个人。
4. owl:inverseOf. 定义某个属性的相反关系。例如,定义“父母”的相反关系是“子女”,若A是B的父母,那么B肯定是A的子女。
本体映射词汇(Ontology Mapping)
1. owl:equivalentClass. 表示某个类和另一个类是相同的。
2. owl:equivalentProperty. 表示某个属性和另一个属性是相同的。
3. owl:sameAs. 表示两个实体是同一个实体。
本体映射主要用在融合多个独立的Ontology(Schema)。举个例子,张三自己构建了一个本体结构,其中定义了Person这样一个类来表示人;李四则在自己构建的本体中定义Human这个类来表示人。当我们融合这两个本体的时候,就可以用到OWL的本体映射词汇。回想我们在第二篇文章中提到的Linked Open Data,如果没有OWL,我们将无法融合这些知识图谱。
<http://www.zhangsan.com/ontology/Person> rdf:type owl:Class . <http://www.lisi.com/ontology/Human> rdf:type owl:Class . <http://www.zhangsan.com/ontology/Person> owl:equivalentClass <http://www.lisi.com/ontology/Human> .
更多的OWL词汇和特性请参考[W3C官网文档](OWL Web Ontology Language Overview)。
接下来我们谈一下OWL在推理方面的能力。知识图谱的推理主要分为两类:基于本体的推理和基于规则的推理。
我们这里谈的是基于本体的推理。读者应该发现,上面所介绍的属性特征词汇其实就创造了对RDF数据进行推理的前提。此时,我们加入支持OWL推理的推理机(reasoner),就能够执行基于本体的推理了。RDFS同样支持推理,由于缺乏丰富的表达能力,推理能力也不强。举个例子,我们用RDFS定义人和动物两个类,另外,定义人是动物的一个子类。此时推理机能够推断出一个实体若是人,那么它也是动物。OWL当然支持这种基本的推理,除此之外,凭借其强大的表达能力,我们能进行更有实际意义的推理。想象一个场景,我们有一个庞大数据库存储人物的亲属关系。里面很多关系都是单向的,比如,其只保存了A的父亲(母亲)是B,但B的子女字段里面没有A,如下表。

如果在只有单个关系,数据量不多的情况下,我们尚能人工的去补全这种关系。如果在关系种类上百,人物上亿的情况下,我们如何处理?当进行关系修改,添加,删除等操作的时候,该怎么处理?这种场景想想就会让人崩溃。如果我们用inversOf来表示hasParent和hasChild互为逆关系,上面的数据可以表示为:
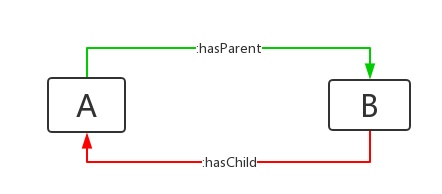
绿色的关系表示是我们RDF数据中真实存在的,红色的关系是推理得到的。通过这个例子,相信读者应该初步了解了OWL的推理功能和能力。
目前,OWL的最新版本是OWL 2,在兼容OWL的基础上添加了新的功能,有兴趣的读者可以查阅W3C文档。另外,OWL 2包含了三个标准,或者三种配置(Profile),它们是OWL 2完整标准(OWL 2/Full)的一个子集。读者目前不用考虑它们之间的差别,只有当我们要用到OWL自动推理功能的时候才需要考虑到底使用哪一种配置。且在大多数情况下,我们需要知道哪种配置才是最合适的。下面简单说说它们使用的场景:
1. OWL 2/EL 使用场景:本体结构中有大量相互链接的类和属性,设计者想用自动推理机得到里面复杂的关系。
2. OWL 2/QL 使用场景:有大量的实例数据。OWL 2 QL本体可以被改写为SQL查询,适用于使用OBDA(ontology based data access)的方式来访问关系数据库。也就是说我们不用显式地把关系数据库中的数据转为RDF,而是通过映射的方式,将数据库转为虚拟RDF图进行访问。
3. OWL 2/RL 使用场景:需要结合基于规则的推理引擎(rule-based reasoning engine)的场合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号