

雾计算和边缘计算的区别
随着物联网的发展,经常听到「雾计算」和「边缘计算」这样的单词。
雾计算这个词相对来说是最近出现的一个词。因为和云相比位置上更接近设备,所以表示为雾,它是作为实现IoT的结构为Cisco等提倡,旨在为全球范围所采用。另一方面,边缘计算这个术语,早就用于表示云和设备的边界。
为什么现在,经常听到这两个词呢。这是和「云计算」的界限有很大的关系。
在云里,如果任何时候都可以保证连接到在数据处理后能够发送到终端设备的服务器上,云计算就可以说是伟大的解决方案。
但是,比如说IoT设备要求具备可靠性来保证在出现服务故障的情况下也能执行任务,具备本地的处理和存储能力在今后也变得越来越重要。这里出场的就是雾/边缘计算。这两个单词行业总是一起被使用,但是也存在一些重要的差异。(当然视角不同观点也不一样)
为了说明这些方法是如何不同,以智能吸尘器为例来考虑一下。这个例子的话,给该吸尘器分配了一个任务,在它发现垃圾后马上就收拾,在家里遍布的传感器检测到垃圾的瞬间开始启动。
雾计算
雾计算(Fog Computing),在该模式中数据、(数据)处理和应用程序集中在网络边缘的设备中,而不是几乎全部保存在云中,是云计算(Cloud Computing)的延伸概念,由思科(Cisco)提出的。这个因“云”而“雾”的命名源自“雾是更贴近地面的云”这一名句。
雾计算和云计算一样,十分形象。云在天空飘浮,高高在上,遥不可及,刻意抽象;而雾却现实可及,贴近地面,就在你我身边。雾计算并非由性能强大的服务器组成,而是由性能较弱、更为分散的各类功能计算机组成,渗入工厂、汽车、电器、街灯及人们物质生活中的各类用品。
边缘计算
边缘计算是指在靠近物或数据源头的一侧,采用网络、计算、存储、应用核心能力为一体的开放平台,就近提供最近端服务。其应用程序在边缘侧发起,产生更快的网络服务响应,满足行业在实时业务、应用智能、安全与隐私保护等方面的基本需求。边缘计算处于物理实体和工业连接之间,或处于物理实体的顶端。而云端计算,仍然可以访问边缘计算的历史数据。
边缘计算并非是一个新鲜词。作为一家内容分发网络CDN和云服务的提供商AKAMAI,早在2003年就与IBM合作“边缘计算”。作为世界上最大的分布式计算服务商之一,当时它承担了全球15-30%的网络流量。在其一份内部研究项目中即提出“边缘计算”的目的和解决问题,并通过AKAMAI与IBM在其WebSphere上提供基于边缘Edge的服务。
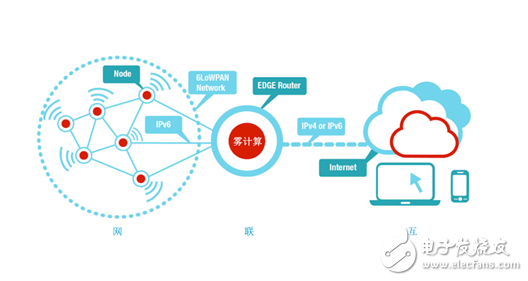
雾计算与边缘计算区别比较
首先说说「雾计算」,处理能力放在包括 IoT设备的LAN里面。这个网络内的IoT网关,或者说是雾节点用于数据收集,处理,存储。多种来源的信息收集到网关里,处理后的数据发送回需要该数据的设备。
雾计算的特点是处理能力强的单个设备接收多个端点来的信息,处理后的信息发回需要的地方。和云计算相比延迟更短。
和边缘计算相比较的话,雾计算更具备可扩展性。具有集中处理的设备,设想的网络是从多个端点发送数据的大的网络。
雾计算不需要精确划分处理能力的有无。根据设备的能力也可以执行某些受限处理,但是更复杂的处理实施的话需要积极的连接。
以吸尘器为例说明,集中化的雾节点(或者IoT网关)继续从家中的传感器收集信息,检测到垃圾的话就启动吸尘器。
边缘计算,进一步推进了雾计算的「LAN内的处理能力」的理念,处理能力更靠近数据源。不是在中央服务器里整理后实施处理,而是在网络内的各设备实施处理。
这样,通过把传感器连接到可编程自动控制器(PAC)上,使处理和通信的把握成为可能。
和雾计算相比的优点,根据它的性质单一的故障点比较少。各自的设备独立动作,可以判断什么数据保存在本地,什么数据发到云端。
以吸尘器为例说明,边缘计算的解决方案里传感器各自判断有没有垃圾,来发送启动吸尘器的信号。
虽然这2个解决方案带来的东西有点相似,但是数据的收集,处理,通信的方法确实是不同的。都有各自的长处和短处,在各种情况下也会出现适合或不适合。IoT在我们的生活中越来越广泛,将来接触的机会也会更多,只记录数据的传感器已经是明日黄花了。
源:http://m.elecfans.com/article/604491.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号