寒假作业(2/2)
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/FZUSESPR21 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/FZUSESPR21/homework/11672 |
| 这个作业的目标 | 对《构建之法》提出几个具体问题以及对词频统计作业的描述 |
| GitHub地址 | https://github.com/aaagx/PersonalProject-Java |
| 其他参考文献 | 无 |
关于《构建之法》提出的几个具体问题
具体问题
1.我看了这一段文字(和任何武功和战术一样, 敏捷有它最适用的范围)有这个问题(不同的开发方法适用于不同的场景,但如果一个项目开发周期较长,场景可能有所改变,比如一个项目一开始属于个人爱好或者解决一些小问题,采用的是敏捷开发的方法。然后这个项目在不断进化,改变,开始商业化或者需要提高可靠性和质量要求(就像linux),这时候我认为敏捷开发的方法就不适合了。那么怎么才能高效的实现开发方法的转换呢?)。我查了资料,有这些说法(Linux的开发工作并没有象“代码封闭论者”所妄言的那样“最终消失在一片混乱之中”。正相反,Linux的开发是有组织有秩 序的,它采用的是一种精心设计并被细心维护的开发模式。在这一高效开发模式下,数以千计的开发者们把各种各样的应用软件注入到Linux平台中来。),根据我的实践,我得到这些经验(可能是提前预见了这种情况及时转变了模式)。但是我还是不太懂,我的困惑是(多久就要对一个项目进行评估,决定是否要转变开发的方法和团队合作的模式,又如何进行一个无痛的转变?)
2.我看了这一段文字(竞争分几个阶段, 当大家都拥有类似的技术, 大家都能够搭云梯越过别人的护城河, 在各自的城堡中短兵相接, 竞争进入了白热化, 大家比的就是执行力。这时候, 竞争者有好几个选择: a) 进入一个封闭的天地去卖魔方, 例如一个用 GFW 高墙围起来的神奇小学, 那里的同学不知道外面的世界。 b) 依赖自己别的优势或垄断, 把魔方绑定在优势项目上销售, 例如团支书要求团员必须去团支部购买魔方。 c) 开发有差异化的新东西, 体现独特的价值。 ),有这个问题(A,B方法的成功是否是对于坚持C的人的一种打击,国内的环境似乎更倾向于A和B方法,对于真正的创新反而不这么友好,创新创业是否更应该追逐前两种 才更容易成功?)。我查了资料,有这些说法(国内现在较为成功的,像腾讯全家桶,新浪微博,都是借鉴起家的。把外国现有的东西经过”本地化“搬运回国),根据我的实践,我得到这些经验(我认为A,B往往与创新无关了,需要的是别的能力,像A方法就需要准确分析用户的痛点,把合适的东西”搬运““改装”才会成功,B方法则需要人脉和别的优势。还有就是书中VCD的那个例子,虽然做出了创新,但马上被大公司赶超,得不到市场)。 但是我还是不太懂,我的困惑是(如果前两种方法更容易成功而且费力更少,我何必追求创新呢?还是说A,B两种方法是另一种层面的“创新”)。
3.我看了这一段文字(测试只是被动地接受别人的产出, 然后开始自己的工作, 比较被动, 不能发挥创造性。也许狭义定义下的 测试用例 是要等开发人员的代码, 然后开始测试。 但是整个质量保证工作(QA)需要前瞻性, 主动性, 创造性的工作。当你在项目后期发现了问题,问题的根源往往是项目早期的一些决定和设计,这时候,再要对其进行修改就比较困难了。Weinberg 说过: “也许没有任何一项测试技术比前瞻性更有价值”),有这个问题(身为一个测试 我要如何取得前瞻性)。我查了资料,有这些说法(这要求测试人员从项目开始就要积极介入,从源头防止问题的发生。),根据我的实践,我得到这些经验(就算从一开始就介入项目,身为一个测试人员而非代码的作者,也只能根据需求写出测试,很难预见到一些情况)。 但是我还是不太懂,我的困惑是(大部分测试方法的编写都是根据之前测试的结果和需求,有没有能够增强”前瞻性“的方法)。
4.我看了这一段文字(我们大家平时都说要向某某大师或某某产品学习, 把最重要的功能做好交给用户,把那些无关紧要的功能藏起来, 做减法...),有这个问题(怎么样做减法才能提高用户体验)。我查了资料,有这些说法(事实上对于功能做减法也不是总是好的,就拿ipod来说,因为界面过于简洁,导致一些自定义的部分难以调整,对于深度用户体验反而下降了。),根据我的实践,我得到这些经验(事实上任何改动都有好处和坏处,对于用户来说,做减法或者做加法都可能取得好的或者坏的效果)。 但是我还是不太懂,我的困惑是(怎么控制做减法的度才能使大多数人满意,可能这需要去了解用户需求,绘制用户肖像,但是往往只有软件发出之后才能真正获得反馈,所以是保持中庸还是剑走偏锋?)。
5.我看了这一段文字(解决大问题固然让然感觉美妙, 但是把小问题真正解决好, 也不容易, 我们回头看看博客园, csdn 等IT 人士云集的网站, 每天都有很多巨大的新想法、惊世骇俗的评论冒出来, 争论美女/张飞/巨石的重构问题, 对一些通用的框架/平台发出一些人云亦云的评论, 等等。 这些文字, 大多数会转化为墨水, 把扇面涂黑, 让后人在上面写下金字。),有这个问题(如何在实践生活中发现小问题并且保持去解决他的问题,甚至更进一步,将这件事情变大造福更多的人)。我查了资料,有这些说法(就是在做项目的时候多思考多想,这里是否还能做的更好,而不是止步于解决这个问题),根据我的实践,我得到这些经验(一开始我很热衷于思考,但是由于要干的事情实在太多了,我逐渐变成只想把这个问题解决了就行,没有再去优化)。 但是我还是不太懂,我的困惑是(如何评估一个问题是值得投入时间去优化的呢?而又有什么问题是解决了就好的了)。
附加题
图灵在“布雷契莱园”工作期间,骑一辆旧自行车上下班。那辆车经常掉链子,图灵却懒得修理。他发现只要骑到一定的圈数,链子就会掉下来,于是每次骑车时他都计算圈数,在链子将要掉下的瞬间刹车,倒一下脚蹬,然后上车再骑。后来他设计出一个计数器,装在脚蹬旁,提醒他下车倒脚蹬。但在旁人看来,实际上完全不需要那么麻烦,只需要去把链子修好就行,所以对于用户的需求一定要准确,切合痛点,最好能一劳永逸的解决问题,有时候跳脱出习惯思维也不一定是好事。
关于词频统计作业的描述
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 80 |
| • Estimate | • 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 420 | 530 |
| • Analysis | • 需求分析 (包括学习新技术) | 20 | 50 |
| • Design Spec | • 生成设计文档 | 60 | 60 |
| • Design Review | • 设计复审 | 10 | 20 |
| • Design | • 具体设计 | 20 | 40 |
| • Coding | • 具体编码 | 180 | 200 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Code Review | • 代码复审 | 40 | 40 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 180 | 200 |
| Reporting | 报告 | 90 | 90 |
| • Test Repor | • 测试报告 | 30 | 30 |
| • Size Measurement | • 计算工作量 | 20 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 1280 | 1550 |
解题思路描述
功能需求分析
首先拿到题目,我先写出需要做什么
-
1.读取文件,将文件内容。
-
2.统计文件内容,含有多少个ASCII码。
-
3.将文件内容按行分割,并且统计行数。
-
4.找出文件中的单词,并且统计其出现频率。
-
5.将结果输出至对应的输出文件。
初步分析设计
-
1.首先对于文件读写,我直接选用BufferedReader和BufferedWriter 较普通的输入输出流有较好的性能。
-
2.对于读入文件的方式,我的设计是直接使用BufferedReader.read()方法按字符读取,然后拼合成一个字符串进行处理。
-
3.将文件分割直接使用乐String自带的String.split()方法。然后对结果集中的每一个对象使用trim()方法将空白字符去掉再判断是否是空行。这样就统计出了非空行的数目。
-
4.最后就是单词的统计,我对于每行都使用正则表达式取出有效的单词,然后将单词加入hashmap统计个数。
-
5.最后使用优先队列对hashmap中的单词按照其出现次数排序,取出出现次数最多的10个单词。
-
6.向文件写出结果。
代码规范链接,即github中的codestyle
模块接口的设计与实现过程
(已经精简过代码数量 一部分是通过代码界面书写的结构)
然后按照模块功能分类,可以设计两个模块。
一个是文件模块,主要负责读取文件内容和输出结果到文件中。
一个是计算模块,主要负责统计和计算得出结果。
将两个模块分离的好处是提高可复用性。
文件模块可以搭配不同的计算模块使用。
不需要重新设计。
文件模块
public class FileTool {
public BufferedReader InputReader;
public BufferedWriter OutputWriter;
BufferedReader getReader(String filePath)//初始化并获得一个BufferedReader
BufferedWriter getWriter(String filePath)//初始化并获得一个BufferedWriter
boolean closeReader()//关闭BufferedReader
boolean closeWriter()//关闭BufferedWriter
String getFileString()//读取文件内容并生成为字符串
public void writeResult(int CharNums, int RowNums, int WordNums, ArrayList<Map.Entry<String, Integer>> TopList)//输出结果
}
对于文件的接口基本功能设计考虑的非常简单 ,绝对不出现任何和文件读写相关的代码,保证复用性。
至于初始化Reader和Writer的代码较简单 这里就不贴了。
需要特别一提的是将文件内容存到字符串的部分
由于数据是使用\n分割的 使用readline()方法会有问题,所以就改为逐字符读取,将分行和统计行数的逻辑和工作交给计算模块,尽量不让和计算有关的功能出现在这个模块里。
改为逐字符读取也更具有泛用性。
String getFileString()
{
StringBuilder Builder = new StringBuilder();
int AsciiChar;
try {
//按字符读取
while ((AsciiChar = InputReader.read()) != -1)
{
Builder.append((char) AsciiChar);
}
} catch (IOException e) {
e.printStackTrace();
}
return Builder.toString();
}
然后是往文件中写结果的这个函数的参数一一对应底下计算模块暴露出的公共参数,方便传递参数输出结果
public void writeResult(int CharNums, int RowNums, int WordNums, ArrayList<Map.Entry<String, Integer>> TopList);
计算模块
首先先放一下模块的简单结构
public class ComputeTool {
//计算需要用到的属性
private String TargetString;
private ArrayList<String> Rows;
private ArrayList<String> ValidRows;
private ConcurrentHashMap<String, Integer> ValidWords;
//用于保存结果的属性
public int RowNums;//行数
public int CharNums;//字符数
public int WordNums;//单词数量
public ArrayList<Map.Entry<String, Integer>> TopList;//出现频率高的单词集合
public ComputeTool(String TargetString)//构造函数 接受文件内容并且生成对象
{
this.TargetString=TargetString;
}
//计算模块
private int countCharNums()//计算字符数
private int countRowNums()//计算行数
private int countWordTypeNums()//计算单词种类数量
private int CountWordNums(int k)//计算单词出现次数
public void compute()
}
计算功能的设计思路也很简单,一句话能够概括:接受一个包含文件内容的字符串并且处理并计算,获得所需的结果。
根据需求分析我们可知需要三个功能就可以得到答案
- 1.统计文件内容,含有多少个ASCII码。
- 2.将文件内容按行分割,并且统计行数。
- 3.找出文件中的单词,并且统计其出现频率。
分别对设计为三部分函数
1.private int countCharNums()//计算字符数
2.private int countRowNums()//计算行数
3.private int countWordTypeNums()//计算单词种类数量
private int CountWordNums(int k)//计算单词出现次数
计算字符数
首先是计算字符数的模块,因为我们已经把整个文件的内容存入了一个字符串,所以只需要返回字符串的长度就可以得到整个文件的字符数
private int countCharNums()
{
return TargetString.length();
}
计算行数
然后是计算行数的模块,我们直接对整个字符串按’\n‘做分割,然后统计得到的结果的行数。
private int countRowNums()
{
Rows =new ArrayList<String>(Arrays.asList(TargetString.split("\n")));
ValidRows =new ArrayList<String>();
for (String Row:Rows)
{
if(!(Row.trim().isEmpty()))
ValidRows.add(Row);//将有效行加入集合
}
return ValidRows.size();
}
值得一提的是这里踩了一个坑,我一开始没有使用trim()方法,结果类似于”\t\r\t\t“的行也会被当作非空行被统计。后面就改用trim()方法将空格除去在判断是否为空。
计算单词数
这个模块的初步想法是做成一个函数,后来发现作为一个函数有点过于臃肿,就按照功能分为两个函数
首先是统计单词种类数目的函数
思路是按照每一行进行处理,将每一行中的单词用正则用split方法取出,再匹配正则表达式
(此处贴的代码为早期版本 不包含后续优化 仅为思路)
ValidWords = new HashMap<>();
Pattern WordPattern = Pattern.compile("^[a-zA-Z]{4}[a-zA-Z0-9]*");//使用正则表达式匹配单词
String ValidWord;
for(String ValidRow:ValidRows)
{
for(String Word:ValidRows.get(j).split("[^a-zA-Z0-9]"))//使用split方法将该行的单词分割出来
{
Matcher WordMatcher=WordPattern.matcher(Word);//对每一个单词进行匹配
if(WordMatcher.find())//判断匹配是否成功
{
ValidWord=WordMatcher.group().toLowerCase();;
if(!ValidWords.containsKey(ValidWord))
{
ValidWords.put(ValidWord,1);
}
else
{
ValidWords.put(ValidWord,ValidWords.get(ValidWord)+1);
}
}
}
然后是对单词数量进行统计并且输出频率最高的k个单词的函数
思路就是将map中的键值对取出放到优先队列中,再输出队列顶部的k个键值对
较为简单就不放全部代码了
有一个坑就是需要单词总数小于设定的k值时就应该把k更新为目前单词总数,否则导致出界错误。
if(k>Queue.size())//当单词总数小于K时 K更新为目前单词的总数
{
k=Queue.size();
}
for(int i=0;i<k;i++)
{
TopList.add(Queue.poll());
}
this.TopList=TopList;
return WordNums;
接口部分的性能改进
对于String.split的改进
使用StringTokenizer代替String.split方法,性能更加优良一些。
StringTokenizer Tokenizer=new StringTokenizer(TargetString , "\n",false);
while(Tokenizer.hasMoreTokens()){
TempRow=Tokenizer.nextToken().trim();
if(!TempRow.isEmpty())
{
ValidRows.add(TempRow);
}
}
引入了多线程
将任务分为8份 交给八个线程并发执行。
引入线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(8, 8, 200, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(8);
将任务分为8份递交给线程池
executor.execute(new Runnable() {
...
})
因为多线程并发需要安全性 所以需要将原本的hashmap替换为ConcurrentHashMap,
ConcurrentHashMap的使用方法与hashmap有所不同
putIfAbsent会检查key对应的value在hashmap中是否存在,如果不存在则把参数的第二个值传入
computeIfPresent会检查key对应的value,如果存在则传入hashmap中的键值对执行第二个函数。
将函数的返回值赋给value。
上面这两个方法都是线程安全的 可以用于更高效的并发。
if(ValidWords.putIfAbsent(ValidWord,1)!=null)
{
ValidWords.computeIfPresent(ValidWord, (k, v) -> v + 1);
}
测试性能的测试文件(50001行 共100000000个单词 96714665个合法单词 798002988个字符 该用例过大 需要给jvm分配8g内存)
优化前:
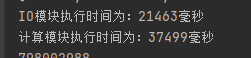
优化后

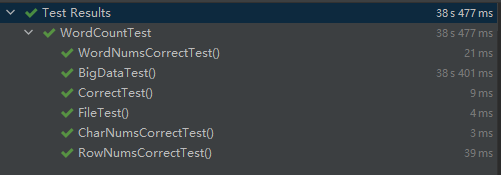
模块部分单元测试展示
测试方法
文件模块
@Test
public void FileTest()
{
FileTool Temp=new FileTool();
Assertions.assertEquals(Temp.getWriter("output.txt")!=null,true);
Assertions.assertEquals( Temp.getReader("input.txt")!=null,true);
Assertions.assertEquals(Temp.closeReader(),true);
Assertions.assertEquals(Temp.closeWriter(),true);
}
}
计算模块
我的思路针对每一个计算模块下的每一个方法单独编写不同的测试输入文件测试,测试方法采取统一格式
计算模块中有多个测试文件 每一个测试文件对应一个测试方法 方法格式如下
@Test
public void TestMethod()
{
int CharAnswer=...;//测试文件的字符数
int RowAnswer=...;//测试文件的行数
int WordAnswer=...;//测试文件的单词数
FileTool Temp=new FileTool();
Temp.getReader("cinput.txt");
Temp.getWriter("output.txt");
ComputeTool Temp1=new ComputeTool(Temp.getFileString());
Temp1.compute();
Assertions.assertEquals(CharAnswer,Temp1.CharNums);
Assertions.assertEquals(RowAnswer,Temp1.RowNums);
Assertions.assertEquals(WordAnswer,Temp1.WordNums);
Assertions.assertEquals(TopList,Temp1.TopList);
Temp.writeResult(Temp1.CharNums, Temp1.RowNums, Temp1.WordNums, Temp1.TopList);
Temp.closeReader();
Temp.closeWriter();
}
测试文件
测试整体模块正确性的测试文件(根据需求编写)
file123
123file
FILE
File
file
File
WINDOWS2000
Windows98
windows95
\r\t\r\t\r\r
测试性能的测试文件(50001行 96714665个单词 798002988个字符 该用例过大 需要给jvm分配8g内存)
测试字符数正确性测试文件示例:字母、数字、空白字符
a b c \r \t \r 22334 ad41th 0j31 ...
测试单词数正确性测试文件示例:2-3字母的词语,下划线分割的人名
示例:cooperative_participant fresh_restriction loose_surgery pregnant_acceptance strong_cat addicted_deviation cruel_game full-time_legend loyal_party primary_retreat stupid_survivor aggressive_accumulation cute_cattle...
测试行数正确的测试文件示例:空行和非空行
\r\t\r\t\r\r
\r\t\r\t\r\r
\r\t\r\t\r\r
1
\r\t\r\t\r\r
\r\t\r\t\r\r
1
\r\t\r\t\r\r
覆盖率截图:

单元测试结果:
模块部分异常处理说明
文件模块
当打开文件不存在的时候会抛出异常, 打印"File Error!,并且打印堆栈信息。
计算模块
当多线程模块运行过久时会抛出InterruptedException 打印 out of time!,并且打印堆栈信息。
结合在构建之法中学到的内容,写下心得
感想:
这次我大意了,以为是很简单的题目,没想到坑出乎意料的多,并且因为一开始结构和设计的不完善和对需求的理解错,导致后面代码过程中碰到了一些困难,甚至需要推翻重写的情况,多把时间放在设计和需求分析上这个思想确实是对的。
学到的东西:
-
1.一定不能急着写代码,要先做好需求分析和项目结构的规划。我这次就因为对需求产生了误解而导致返工多次
-
2.学会了junit的初步使用,测试一定要面面俱到,好的测试能帮我找出我不容易发现的bug。
-
3.学会了git这个强大的工具的使用,好的工具确实能帮助我节省时间。
-
4.写博客不是一件容易的事情,搞懂代码比较简单,但是怎么向别人讲清楚就有一些难了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号